↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Key Takeaways#
Why does it matter?#
This paper is crucial because it directly addresses the limitations of existing federated transfer learning methods by proposing a novel algorithm, FedGTST. Its rigorous theoretical analysis and empirical validation offer valuable insights, paving the way for more efficient and privacy-preserving federated learning systems. The findings are directly relevant to current research trends in federated learning and open new avenues for further exploration in enhancing the global transferability of models.
Visual Insights#
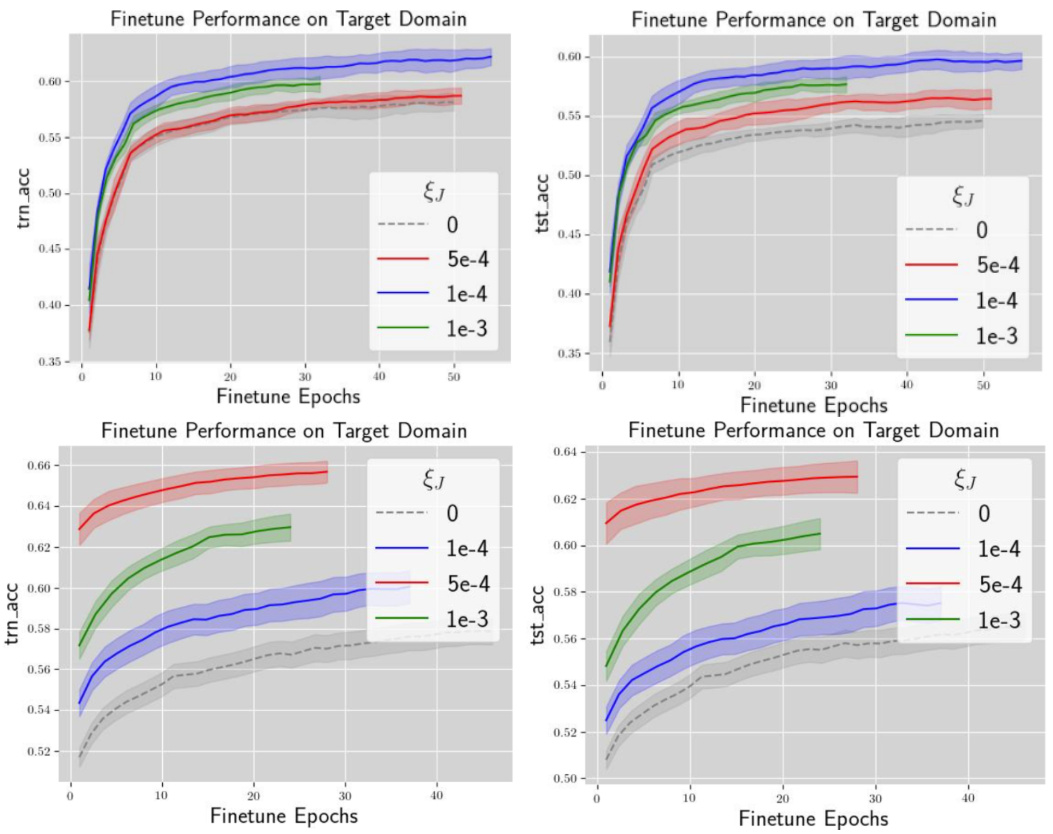
This figure visualizes the convergence behavior of FedAVG and FedGTST on the CIFAR10 to SVHN transfer task. It shows training and testing accuracy curves over finetuning epochs for different participation rates (10% and 100% of clients) and regularization coefficients (ξ). The grey dashed lines represent the baseline FedAVG, while colored lines show FedGTST with various tuned hyperparameters. The results illustrate FedGTST’s faster convergence and improved accuracy compared to FedAVG.
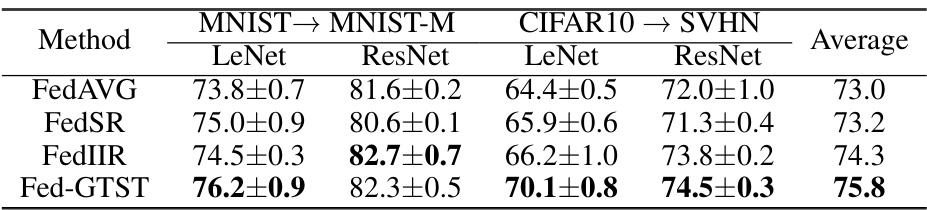
This table shows the target accuracy achieved by different federated transfer learning methods on two benchmark tasks (MNIST to MNIST-M and CIFAR-10 to SVHN) using two different backbones (LeNet and ResNet). The results demonstrate that FedGTST significantly outperforms existing methods, particularly when using a smaller number of clients (K=10). The improvement is consistently observed across different tasks and model architectures.
In-depth insights#
FedGTST Algorithm#
The FedGTST algorithm is a novel approach to federated transfer learning that addresses the limitations of existing methods by focusing on improving global transferability. It achieves this by introducing two key features: a communication protocol that exchanges information about cross-client Jacobian norms, and a local regularizer that reduces cross-client Jacobian variance. The algorithm’s effectiveness stems from its ability to tightly control the target loss by managing these two FL-specific factors, which are directly linked to transferability. FedGTST rigorously proves its theoretical upper bound on target loss. This theoretical foundation, along with the communication efficiency of its scalar-based approach, makes FedGTST a significant advancement in the field. Unlike previous methods, which focus on indirect measures of transferability, FedGTST directly targets the target loss, offering a more accurate assessment of performance. The algorithm’s empirical validation demonstrates that FedGTST significantly outperforms existing baselines, highlighting its practicality and value for real-world applications.
Transferability Bounds#
The concept of ‘Transferability Bounds’ in federated transfer learning aims to quantify the extent to which knowledge learned in a source domain can be effectively transferred to a target domain. This is crucial because the success of transfer learning hinges on this ability. Establishing such bounds allows researchers to predict the performance of a model trained on source data when applied to unseen target data. Tight bounds are especially valuable as they provide a more precise estimate of the model’s performance. The theoretical analysis underpinning these bounds often involves measuring the discrepancy or divergence between the source and target data distributions, as well as the complexity of the model used. Factors like the cross-client Jacobian variance and the average Jacobian norm across clients in a federated setting significantly impact these bounds. Therefore, the research into transferability bounds often guides the design of algorithms that minimize data discrepancies and optimize the model’s ability to learn transferable features, ultimately improving the effectiveness and reliability of federated transfer learning models.
Cross-Client Stats#
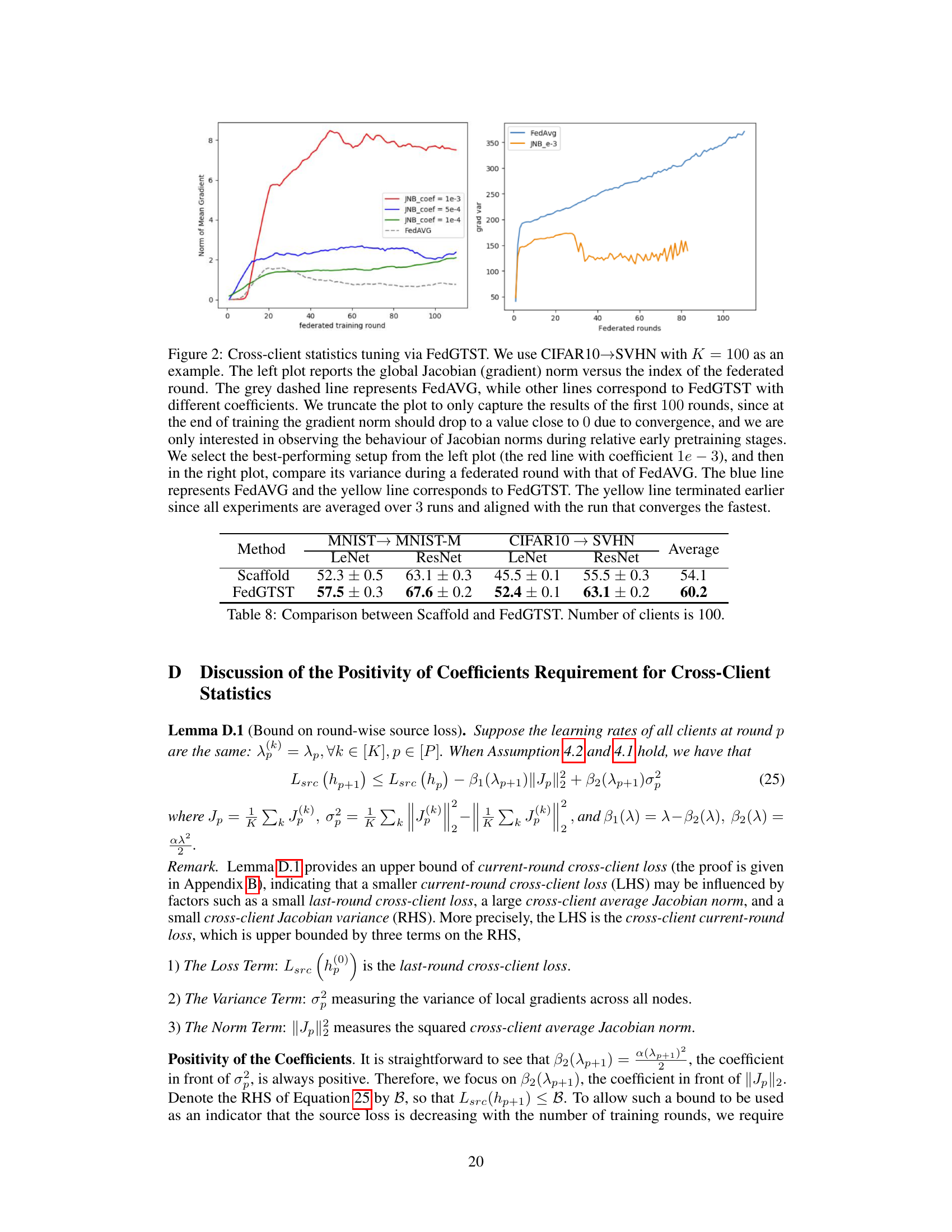
The concept of “Cross-Client Stats” in federated transfer learning (FTL) focuses on leveraging statistical information aggregated across participating clients. This approach addresses limitations of prior methods that primarily focused on optimizing transferability within individual client domains, ignoring cross-client variability. By analyzing cross-client Jacobian norms and variances, the proposed algorithm, FedGTST, directly measures and controls transferability. A smaller cross-client Jacobian variance and a larger average Jacobian norm indicate improved transferability. This is because low variance suggests consistent feature extraction across clients, while a high norm implies strong learned features. FedGTST uses this insight to design a regularizer that promotes the desired statistical properties, improving global model transferability without compromising privacy by only exchanging scalar values (norms). This is a significant improvement over existing methods that necessitate sharing of more complex model parameters. The theoretical analysis provides bounds on the target loss, confirming the effectiveness of the approach. Finally, the empirical results showcase FedGTST’s significant outperformance over baselines on multiple benchmark datasets.
Experimental Setup#
A well-structured ‘Experimental Setup’ section in a research paper is crucial for reproducibility and ensuring the reliability of findings. It should detail all aspects of the experiments conducted, enabling others to replicate the study. Key elements include a clear description of the datasets used, specifying their characteristics (size, distribution, etc.) and how they were pre-processed or split. The chosen model architecture(s), hyperparameters, and optimization algorithms should be explicitly defined, including the rationale behind their selection. Evaluation metrics are essential, detailing precisely how performance was assessed and the choice of statistical tests used to ascertain significance. Furthermore, the experimental environment (hardware, software, etc.) must be described to eliminate potential biases or confounding factors. Finally, the section should address any limitations or potential variations in the experimental design and highlight their potential influence on the results. A robust ‘Experimental Setup’ promotes the transparency and validity of the research, allowing readers to judge the credibility and reliability of the conclusions drawn.
Future of FedGTST#
The future of FedGTST lies in addressing its limitations and expanding its capabilities. Reducing the computational overhead of local training remains crucial for wider adoption, potentially through more efficient gradient estimation or approximation techniques. Improving the theoretical bounds on target loss is another key area for enhancement, possibly via refined analysis of cross-client Jacobian statistics or incorporating novel regularization strategies. Exploring applications beyond image classification is essential to demonstrate FedGTST’s generalizability and impact in diverse domains. This might involve adapting FedGTST for NLP, time-series analysis, or other complex data types. Finally, enhancing the algorithm’s robustness to different data distributions and network conditions will ensure its effectiveness in real-world federated learning settings. Addressing these aspects would solidify FedGTST’s position as a leading algorithm for transferable federated learning.
More visual insights#
More on tables
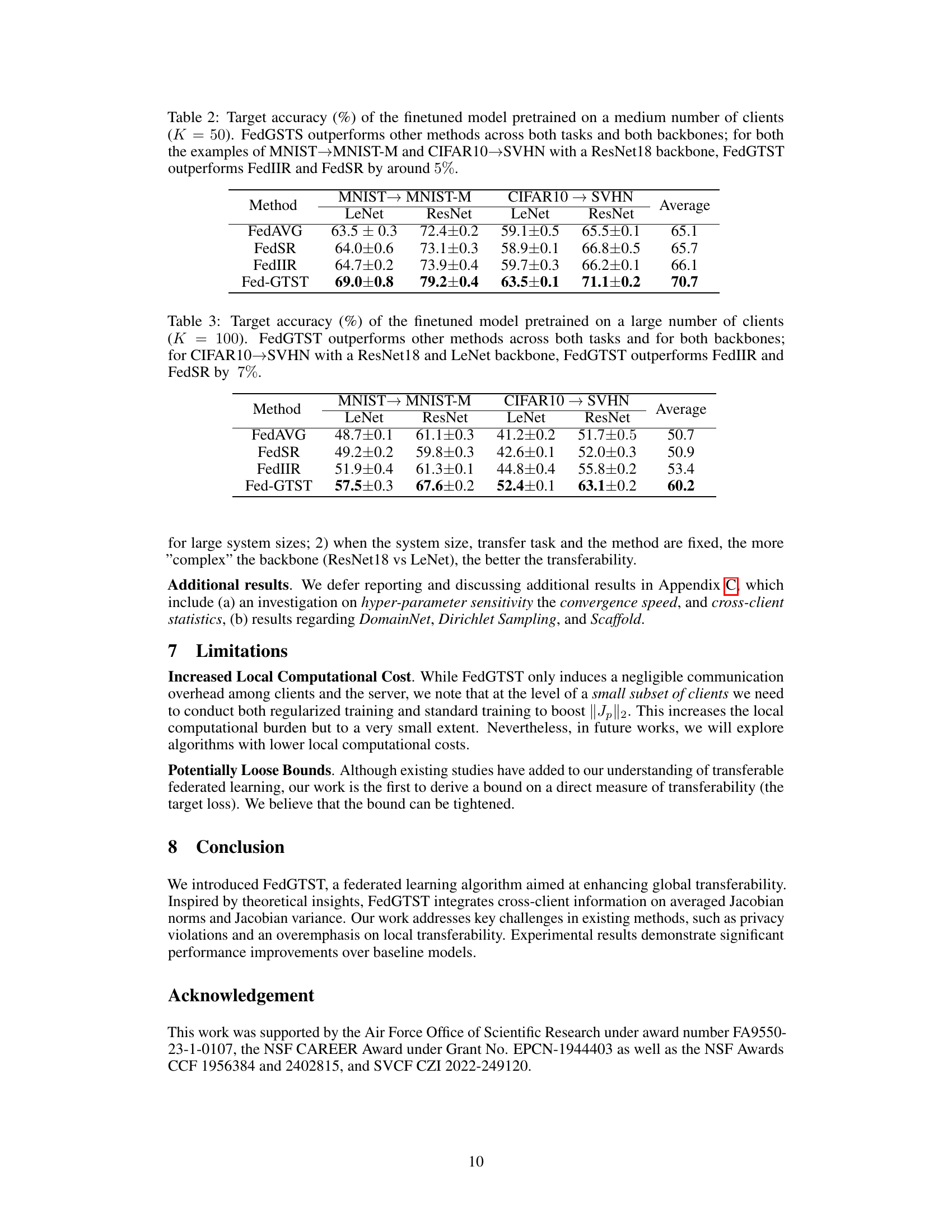
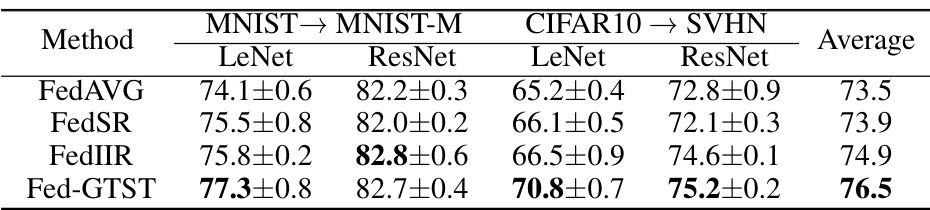
This table presents the target accuracy achieved by fine-tuning a model pretrained on a medium-sized federated learning setup (50 clients). It compares the performance of FedGTST against baseline methods (FedAVG, FedSR, and FedIIR) across two transfer learning tasks (MNIST to MNIST-M and CIFAR10 to SVHN) and two different model backbones (LeNet and ResNet18). FedGTST demonstrates a notable improvement in accuracy compared to the baselines.
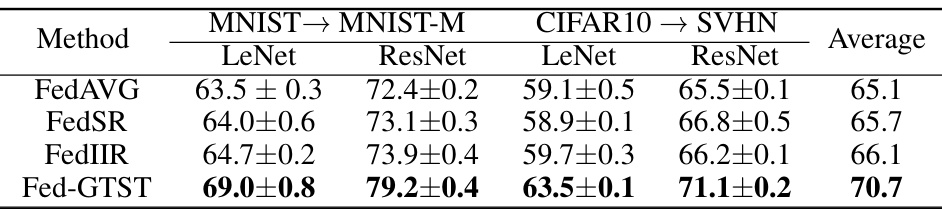
This table shows the target accuracy of a model fine-tuned on a target domain after being pre-trained using federated learning on a large number of clients (K=100). The results are compared across two tasks (MNIST to MNIST-M and CIFAR10 to SVHN) and two backbone architectures (LeNet and ResNet18). FedGTST consistently outperforms other methods (FedAVG, FedSR, FedIIR). The improvement is particularly significant for the CIFAR10 to SVHN task, where FedGTST surpasses FedIIR and FedSR by approximately 7%.

This table shows how the transferability (measured by the target accuracy) changes when varying the percentage of clients participating in each round of federated learning. The experiment uses the CIFAR-10 to SVHN transfer task with the LeNet backbone and a total of 100 clients (K=100). The results indicate that increasing client participation generally improves transferability, although even with only 10% participation, performance is relatively close to that of 100% participation.

This table compares the transferability performance (target accuracy) of FedAVG and FedGTST with different coefficient values when using 1 local epoch versus 10 local epochs for the CIFAR10 to SVHN transfer task. The results are based on the LeNet backbone and with 10% of clients participating in each round. The table shows how the number of local epochs and the coefficient value impact the transferability of the models.

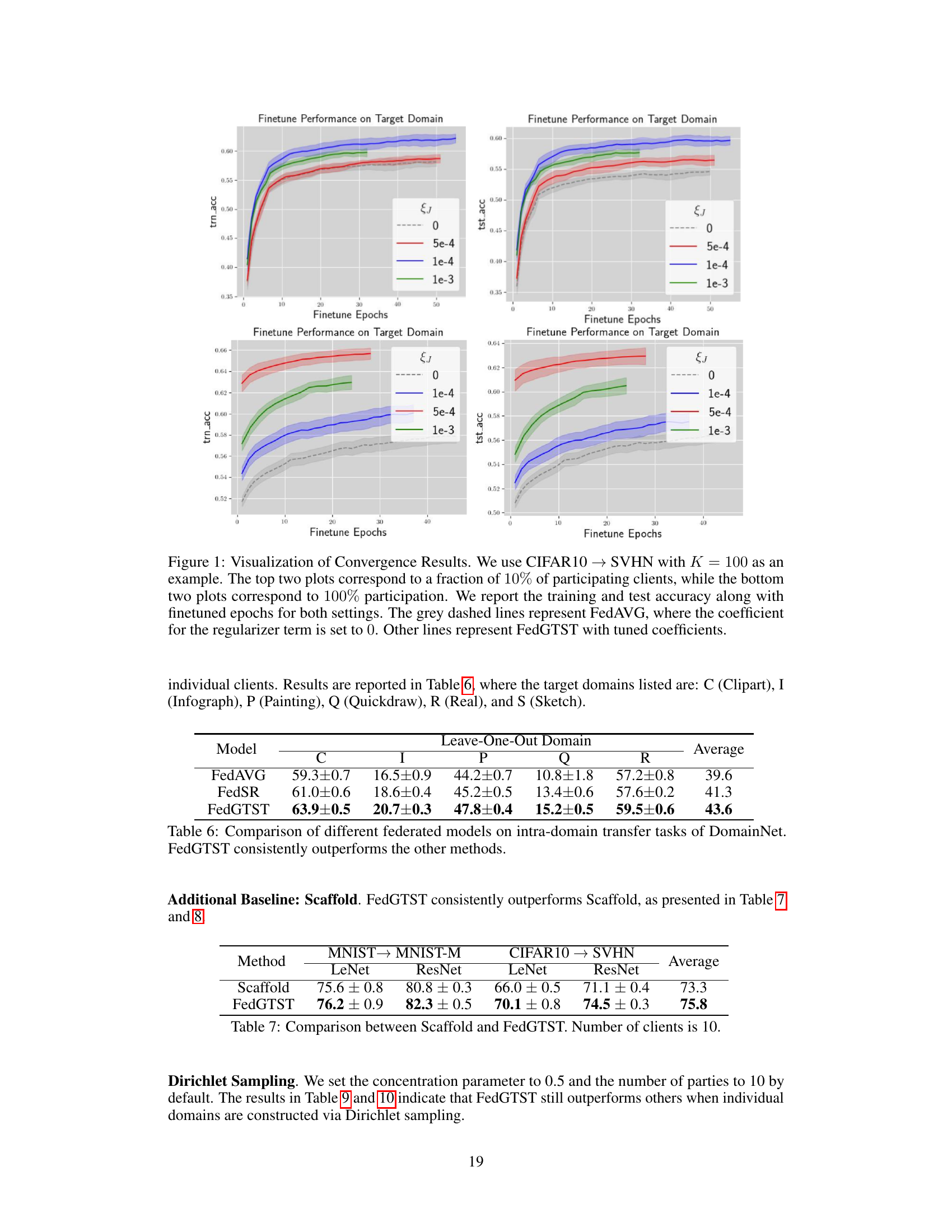
This table presents the results of the leave-one-out domain transfer experiments on the DomainNet dataset. The performance of three federated learning methods (FedAVG, FedSR, and FedGTST) is compared across six distinct domains (C, I, P, Q, R, and S). Each row represents a different method, while each column represents a target domain. The ‘Average’ column shows the average performance across all six target domains. The table highlights that FedGTST consistently outperforms both FedAVG and FedSR in terms of accuracy.

This table shows the target accuracy of a model fine-tuned on a target dataset after being pre-trained using federated learning with 10 clients. The results are presented for two different datasets (MNIST to MNIST-M and CIFAR10 to SVHN) and two different model backbones (LeNet and ResNet). The table highlights that the proposed FedGTST method outperforms existing methods (FedAVG, FedSR, and FedIIR).

This table presents the target accuracy results for the finetuned model pretrained with different methods using 100 clients. FedGTST shows superior performance compared to other methods (FedAVG, FedSR, FedIIR) across both MNIST to MNIST-M and CIFAR10 to SVHN transfer tasks, with both LeNet and ResNet18 backbones.
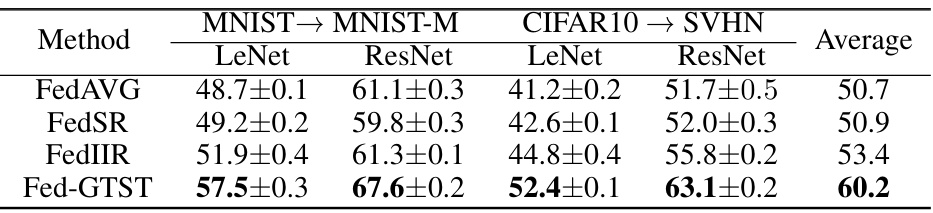
This table presents the target accuracy achieved by four different federated transfer learning methods (FedAVG, FedSR, FedIIR, and FedGTST) when pretrained on a small number of clients (K=10). The results are shown for two different transfer tasks (MNIST to MNIST-M and CIFAR10 to SVHN) and two different backbones (LeNet and ResNet). The table highlights that FedGTST consistently outperforms the other methods across all scenarios.

This table presents the target accuracy results achieved by four different federated learning methods (FedAVG, FedSR, FedIIR, and FedGTST) when the number of clients is large (K=100). The results are broken down by the transfer task (MNIST to MNIST-M and CIFAR10 to SVHN) and the backbone architecture (LeNet and ResNet18) used for the model. The table shows that FedGTST outperforms other baselines across all settings, particularly in the CIFAR10 to SVHN transfer tasks.

This table presents the target accuracy achieved by different federated learning methods (FedAVG, FedSR, FedIIR, and FedGTST) when fine-tuning a model pretrained on a small number of clients (K=10) on two different transfer tasks: MNIST to MNIST-M and CIFAR-10 to SVHN. Two different backbones, LeNet and ResNet, were used. The results show that FedGTST consistently outperforms the baselines across both tasks and backbones, with a noticeable improvement over FedIIR and FedSR on the MNIST to MNIST-M task with the LeNet backbone.
Full paper#