↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current blind face restoration techniques often struggle to accurately reflect a person’s true appearance. The generated images may lack the fine details or even represent a different person entirely. This paper tackles this problem by incorporating additional high-quality reference images of the same individual into the restoration process.
The researchers propose ReF-LDM, a new model based on Latent Diffusion Models (LDMs) that utilizes these reference images. They introduced two key innovations: CacheKV, a mechanism to efficiently use the references, and a timestep-scaled identity loss to focus on identity preservation during the restoration process. The results demonstrate significant improvements in the accuracy of face restoration and demonstrate the superior performance compared to other approaches.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of current blind face restoration methods by incorporating reference images. This leads to more accurate and realistic restorations, which is crucial for various applications. The proposed CacheKV mechanism and timestep-scaled identity loss are novel contributions that improve the efficiency and effectiveness of latent diffusion models for face restoration. The creation of the FFHQ-Ref dataset provides a valuable resource for future research, advancing the field significantly.
Visual Insights#

This figure shows a comparison of face image restoration results using different methods. The input is a low-quality (LQ) image (a). A standard Latent Diffusion Model (LDM) produces a high-quality (HQ) image (b), but it doesn’t perfectly match the person’s identity. The proposed ReF-LDM method, which uses additional reference HQ images (d), achieves a much better result (c) with more accurate facial details and identity preservation.

This table compares the FFHQ-Ref dataset with two other datasets: FFHQ and CelebRef-HQ. It shows whether each dataset includes reference images, if it is licensed appropriately, the overall quality of the images, the number of images included, and the number of distinct identities represented in the images.
In-depth insights#
Ref-LDM Overview#
ReF-LDM, a novel latent diffusion model, presents a significant advancement in reference-based face image restoration. Its core innovation lies in the integration of a highly efficient mechanism, CacheKV, which leverages multiple high-quality reference images to guide the restoration of a low-quality input. Unlike previous methods that rely on explicit alignment or landmark detection, ReF-LDM implicitly learns the cross-image correspondences, leading to improved robustness and accuracy. Further enhancing its performance is the introduction of a timestep-scaled identity loss, which cleverly addresses the issue of identity drift often observed in diffusion models, ensuring that the restored face accurately reflects the identity of the input. The model’s effectiveness is underscored by the creation of a new dataset, FFHQ-Ref, which provides both training and evaluation data of high quality for this challenging task. Overall, ReF-LDM offers a comprehensive solution for reference-based face restoration by effectively combining innovative mechanisms with a large-scale, high-quality dataset.
CacheKV Mechanism#
The proposed CacheKV mechanism is a pivotal innovation in ReF-LDM, designed to efficiently integrate multiple reference images into the latent diffusion process. Unlike other methods that concatenate or use cross-attention, CacheKV pre-computes and caches key-value pairs (KVs) from the reference images using a single pass through the U-net. This avoids repeatedly processing the references at each diffusion timestep, significantly improving efficiency. The cached KVs are then efficiently integrated at each self-attention layer during the main diffusion process. This strategy is particularly crucial as reference images lack spatial alignment with the target image, requiring a more sophisticated integration approach than simple concatenation. The effectiveness of CacheKV is demonstrated by outperforming alternative methods in terms of inference speed and memory usage while maintaining high accuracy. By addressing the computational limitations of directly processing multiple reference images at each timestep, CacheKV makes ReF-LDM practical and scalable for high-quality reference-based face image restoration.
Identity Loss#
The concept of “Identity Loss” in face image restoration is crucial for preserving the identity of the subject. A simple identity loss directly compares features of a generated image with those of a real image, aiming for similarity. However, applying it naively to diffusion models, especially during early timesteps of the generation process, may hinder the generation of high-quality, realistic details. This is because the early stages are dominated by noise, making direct comparison with a clean reference image ineffective. The proposed timestep-scaled identity loss addresses this by adjusting the weight of the identity loss according to the timestep. This method allows the model to focus more on identity preservation during later stages when the image is relatively clear, while also ensuring the generation of high-quality images with details. By incorporating this modified identity loss, the ReF-LDM effectively balances identity preservation with image quality, leading to more faithful and realistic face restorations.
FFHQ-Ref Dataset#
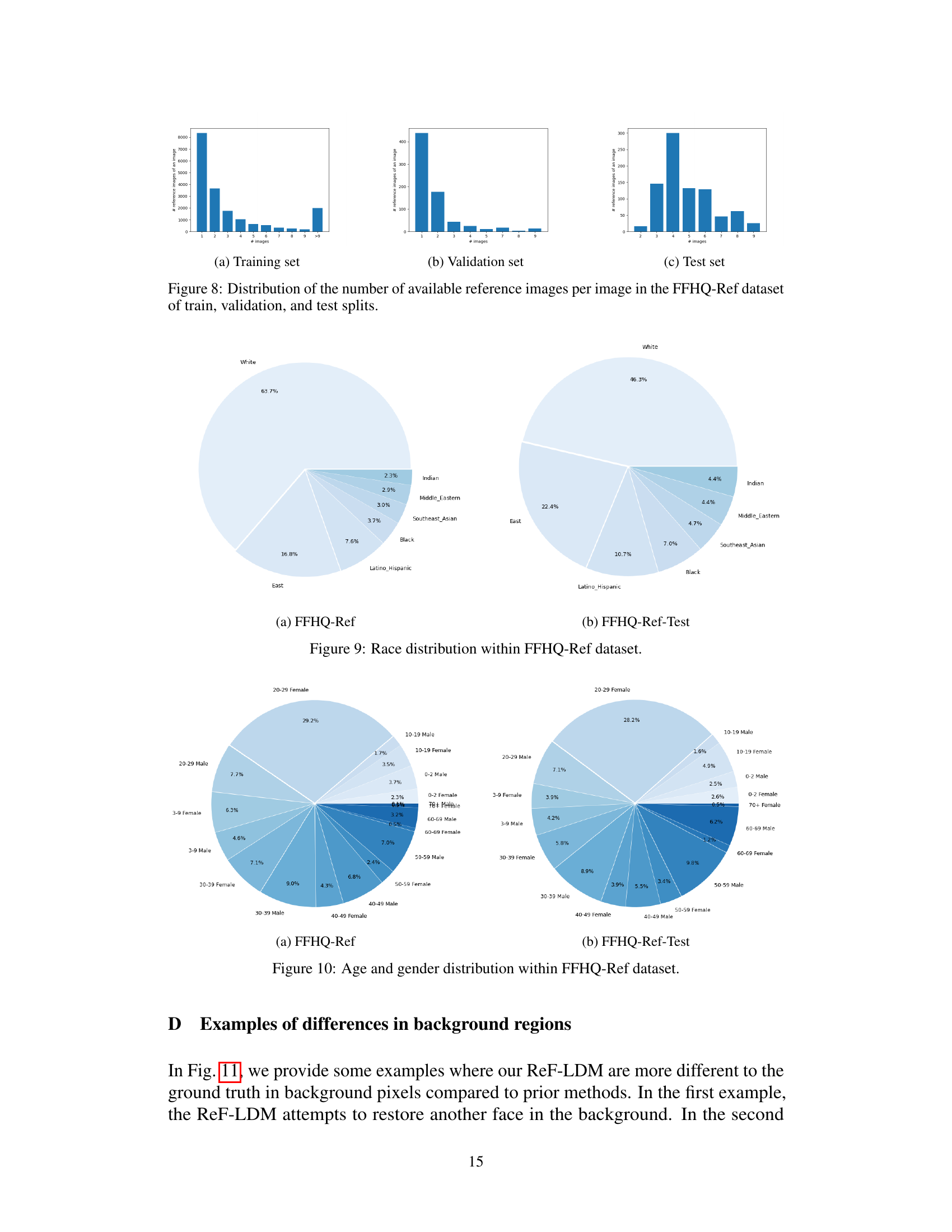
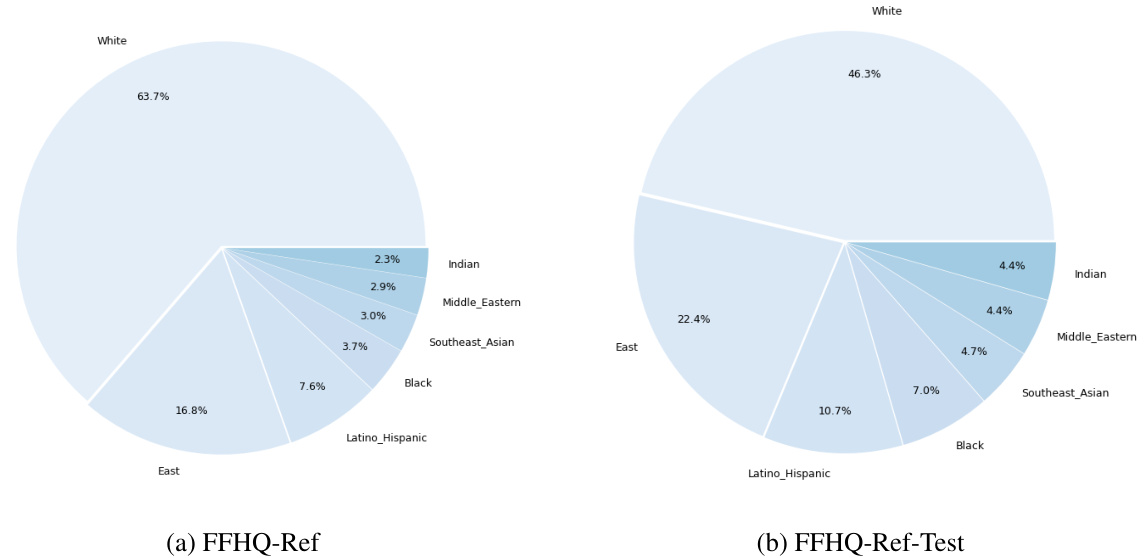
The FFHQ-Ref dataset, a crucial contribution of the research, addresses a critical limitation in reference-based face image restoration by providing a large-scale dataset with corresponding high-quality (HQ) face images and their reference images. This addresses the problem of existing datasets lacking reference image pairings, which hindered the development of accurate and identity-preserving restoration models. The meticulous process of creating FFHQ-Ref, including employing a face recognition model to identify matching images and careful data splitting to avoid identity overlap in training and testing sets, demonstrates a commitment to rigorous methodology. The size and diversity of the dataset are significant advantages, allowing for robust training and evaluation of reference-based face restoration models. However, potential limitations like the imbalance in race representation within the dataset should be noted. Future work could benefit from addressing such issues to improve its inclusivity and generalization capability. The FFHQ-Ref dataset, therefore, stands as a valuable resource for future research in the field of face image restoration and related tasks.
Limitations#
The limitations section of a research paper is crucial for demonstrating academic integrity and providing a balanced perspective on the study’s findings. In this context, acknowledging limitations displays intellectual honesty, demonstrating that the authors have critically evaluated their work and understand its boundaries. Specific limitations might include issues with the dataset, such as its size, representativeness, or presence of biases; the methodology employed might have limitations in terms of generalizability or efficiency. Addressing methodological weaknesses shows careful consideration of the research process. Another common limitation is the scope of the work, acknowledging that the research may not fully address all aspects of the problem or may be limited in terms of geographic location or timeframe. By highlighting these constraints, the authors can provide a more realistic assessment of the study’s implications and pave the way for future research to build upon their work and address the remaining gaps.
More visual insights#
More on figures
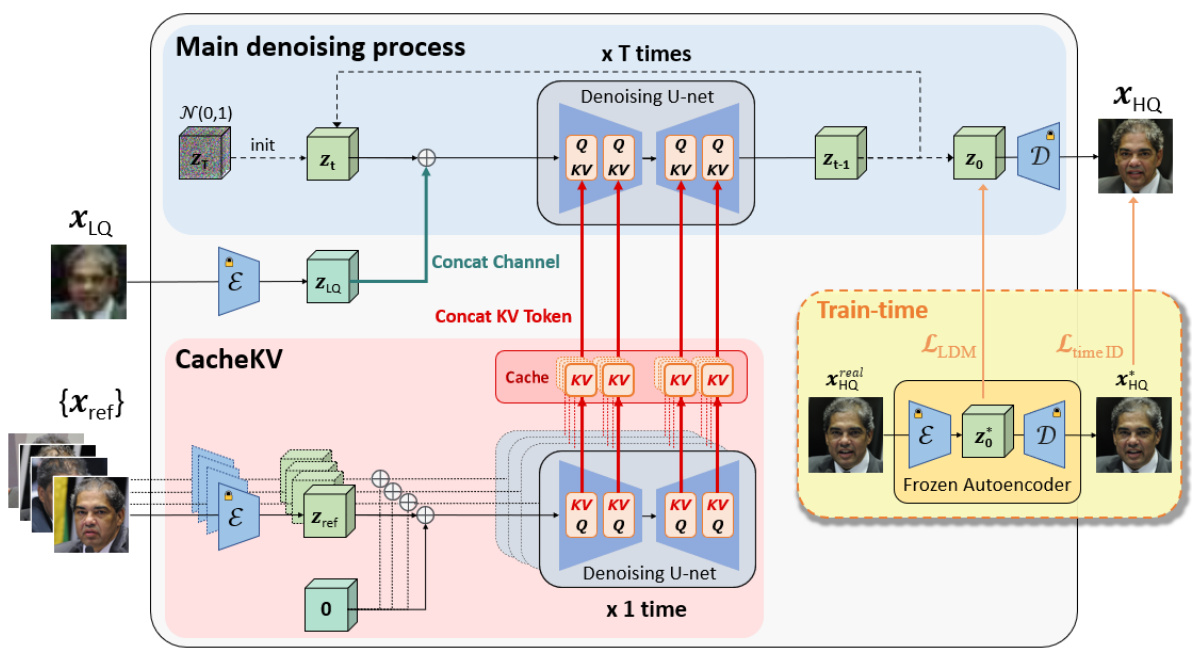
This figure illustrates the architecture of the ReF-LDM model, which consists of a main denoising process (using a U-net) and a CacheKV mechanism for efficiently integrating multiple reference images. The model takes a low-quality (LQ) input image and several high-quality (HQ) reference images as input and generates a high-quality (HQ) output image. The CacheKV mechanism stores key-value pairs extracted from the reference images to avoid redundant computations. The model uses a classic LDM loss and a timestep-scaled identity loss during training.

This figure compares four different methods for integrating reference images into a diffusion model for image generation. (a) Channel-concatenation simply concatenates the reference image features with the main input features along the channel dimension. (b) Cross-attention uses a cross-attention mechanism to relate the reference and main features, but this is done at every timestep, which is computationally expensive. (c) Spatial-concatenation concatenates the features spatially, increasing computational cost, but more effectively leveraging the spatial alignment. (d) CacheKV (the authors’ method) caches the reference image features using the same U-net only once, then uses them repeatedly in each timestep, significantly increasing efficiency without compromising results.

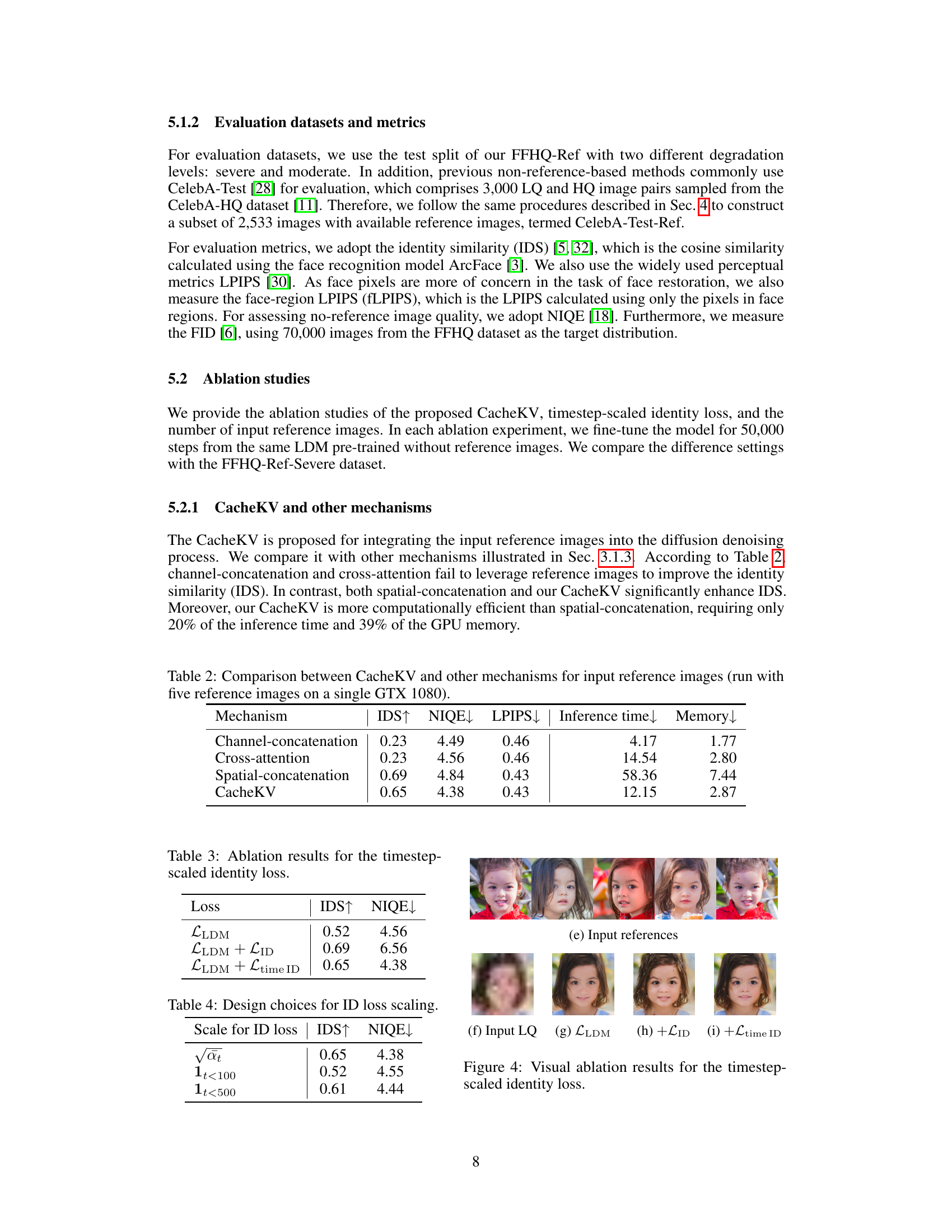
This figure shows the visual comparison of the results of three different training settings: without identity loss (LLDM), with naive identity loss (LLDM + LID), and with the proposed timestep-scaled identity loss (LLDM + Ltime ID). The input LQ image is severely blurred. The LLDM result shows a blurry image with missing details. The (LLDM + LID) result shows a relatively clear image, but it has some artifacts. The (LLDM + Ltime ID) result shows a high-quality image that is similar to the ground truth image.

This figure shows a qualitative comparison of the proposed ReF-LDM model against several state-of-the-art methods for reference-based face image restoration. Three examples are shown, each with varying levels of degradation (FFHQ-Ref-Severe, FFHQ-Ref-Moderate, and CelebA-Test-Ref). For each example, the input low-quality (LQ) image is displayed, along with the ground truth (GT) image and the results from CodeFormer, DMDNet, LDM, and ReF-LDM. This allows for a visual comparison of the different methods’ ability to reconstruct high-quality images that accurately reflect the individual’s facial identity.

This figure shows a comparison of face image restoration results using different methods. The input is a low-quality (LQ) face image. A standard Latent Diffusion Model (LDM) is used for restoration, which produces a high-quality (HQ) result but one that may not accurately reflect the subject’s identity. The authors’ proposed method, ReF-LDM, uses additional high-quality reference images as input, to improve the accuracy of the restored identity. The figure visually demonstrates that ReF-LDM is able to generate higher-quality images that are more faithful to the individual’s actual appearance.

This figure shows examples of images from the CelebRef-HQ dataset that have issues with image quality. The issues include mirror padding artifacts around the edges of the faces and watermarks overlaying parts of the image. These artifacts reduce the quality of the images and demonstrate a limitation of this dataset for face restoration tasks.
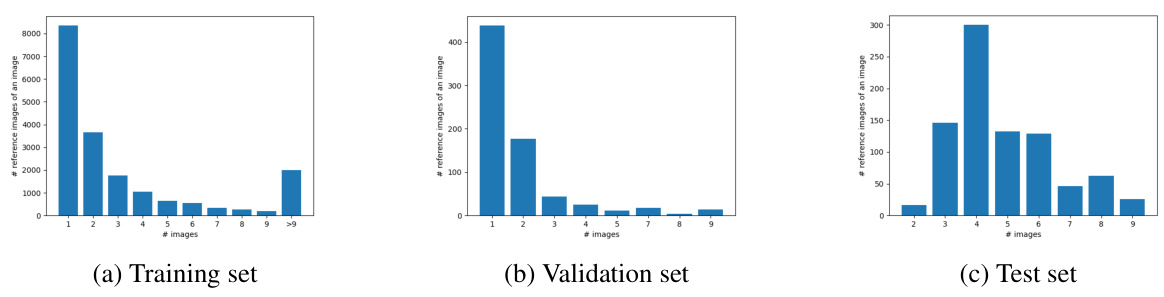
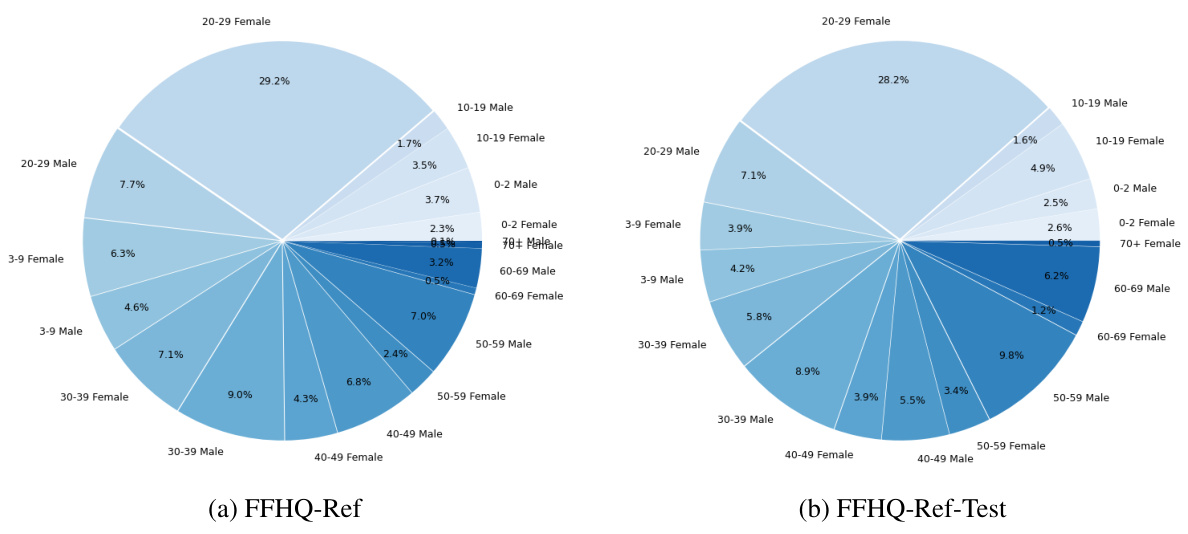
This figure shows the distribution of the number of reference images per image in the FFHQ-Ref dataset, which is used for training and testing the ReF-LDM model. The figure is broken down into three subfigures, one for each split of the data: (a) Training set, (b) Validation set, and (c) Test set. Each subfigure displays a histogram showing the frequency of images with a specific number of reference images. The x-axis represents the number of reference images (1-9, 9+), and the y-axis shows the count of images with that many reference images. The histograms provide an understanding of the distribution of reference images, highlighting which numbers of references are most common in each dataset split. This information is important because the ReF-LDM model uses multiple reference images for face image restoration, and the distribution of reference images in the dataset can influence the training and performance of the model.
This figure shows a comparison of face image restoration results using a standard Latent Diffusion Model (LDM) and the proposed ReF-LDM. The input is a low-quality (LQ) image (a). The standard LDM produces a high-quality (HQ) image (b), but it may not accurately reflect the person’s true appearance. In contrast, ReF-LDM uses additional HQ reference images (d) to generate a restored HQ image (c) that is more faithful to the original person’s identity.
This figure demonstrates the effectiveness of ReF-LDM, a reference-based face image restoration model. It shows that while a standard LDM can generate a high-quality image from a low-quality input, it may not accurately reflect the person’s true appearance. By incorporating additional high-quality reference images, ReF-LDM achieves more accurate and faithful restoration of facial features.

This figure demonstrates the effectiveness of the proposed ReF-LDM model in restoring high-quality face images from low-quality inputs. It shows a comparison between a standard LDM approach and the ReF-LDM approach, highlighting how the inclusion of reference images significantly improves the accuracy and fidelity of the restored image. The reference images provide additional information about the person’s appearance, enabling the ReF-LDM to reconstruct a more accurate and realistic image compared to the LDM which only uses the low-quality image.

This figure shows a comparison of face image restoration results using a Latent Diffusion Model (LDM) and the proposed ReF-LDM. The input is a low-quality (LQ) image (a). A standard LDM produces a high-quality (HQ) image (b), but the result may not accurately reflect the person’s identity. ReF-LDM incorporates multiple HQ reference images (d) to improve the restoration, producing a result (c) that is both high-quality and preserves the identity more faithfully.

This figure shows a qualitative comparison of face image restoration results from different methods: input low-quality (LQ) image, ground truth (GT), CodeFormer, DMDNet, LDM (Latent Diffusion Model), and ReF-LDM (the proposed method). The comparison is done across three different datasets: FFHQ-Ref-Severe, FFHQ-Ref-Moderate, and CelebA-Test-Ref, representing varying levels of image degradation. Each row shows the results for a different input image, illustrating the strengths and weaknesses of each method in restoring detail, preserving identity, and handling different levels of image noise and corruption.

This figure presents a qualitative comparison of face image restoration results using different methods. The top row shows an example from the FFHQ-Ref-Severe dataset, the middle row from the FFHQ-Ref-Moderate dataset, and the bottom row from the CelebA-Test-Ref dataset. For each dataset, the image sequence shows (from left to right): the low-quality (LQ) input image, the ground truth (GT) high-quality image, and the results generated by CodeFormer, DMDNet, a standard Latent Diffusion Model (LDM), and the proposed ReF-LDM. The comparison highlights ReF-LDM’s ability to better preserve the facial identity and produce more realistic high-quality images compared to other methods.

This figure compares the image restoration results of different methods including ReF-LDM, CodeFormer, DMDNet, and LDM on three different datasets with varying degradation levels. It visually demonstrates ReF-LDM’s superior ability to restore high-quality images that are both realistic and maintain facial identity compared to other methods, especially in cases of severe degradation. The top row shows examples from the FFHQ-Ref-Severe dataset; the middle row shows examples from the FFHQ-Ref-Moderate dataset; and the bottom row shows examples from the CelebA-Test-Ref dataset.

This figure demonstrates the core idea of the paper by comparing the results of a standard Latent Diffusion Model (LDM) and the proposed ReF-LDM on face image restoration. It shows that while a regular LDM can generate a high-quality image from a low-quality input, it might not accurately reflect the person’s true facial identity. In contrast, ReF-LDM, by incorporating additional high-quality reference images of the same person, produces a restored image that is both high-quality and accurately represents the individual’s identity.
More on tables

This table compares the performance of four different mechanisms for integrating reference images into the diffusion denoising process: Channel-concatenation, Cross-attention, Spatial-concatenation, and the proposed CacheKV. The comparison is based on several metrics: identity similarity (IDS), natural image quality evaluator (NIQE), learned perceptual image patch similarity (LPIPS), inference time, and GPU memory usage. The results show that CacheKV significantly outperforms the other methods in terms of IDS, while maintaining comparable efficiency in inference time and memory usage.
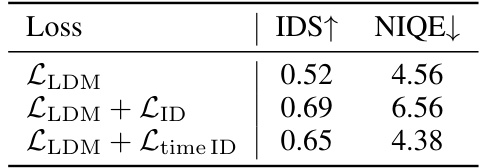
This table presents the ablation study results for the timestep-scaled identity loss. It compares three different loss settings: using only the classic LDM loss, adding a naive identity loss, and adding the proposed timestep-scaled identity loss. The results are evaluated using the Identity Similarity (IDS) metric and the Natural Image Quality Evaluator (NIQE) metric. The table shows that the timestep-scaled identity loss improves the identity similarity without sacrificing image quality.

This table presents the results of an ablation study on different scaling factors for the identity loss in the ReF-LDM model. The identity loss is designed to improve the model’s ability to accurately represent the identity of the subject in the generated image. The study compares three different scaling factors: √αt, 1t<100, and 1t<500. The results show the impact of each scaling factor on the identity similarity (IDS) and Natural Image Quality Evaluator (NIQE) scores. A lower NIQE score indicates better image quality.
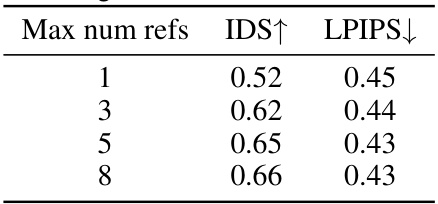
This table shows the impact of the number of reference images on the image quality. As the number of reference images increases, both the identity similarity (IDS) and the perceptual similarity (LPIPS) improve, indicating better restoration results.

This table shows the inference time taken by the ReF-LDM model with different numbers of reference images used. The inference time is measured on two different GPUs: GTX 1080 and RTX 3090. As the number of reference images increases, the inference time also increases significantly. When using 8 reference images, the model runs out of memory on the GTX 1080 GPU.

This table compares the performance of ReF-LDM against several state-of-the-art methods on three benchmark datasets: FFHQ-Ref-Severe, FFHQ-Ref-Moderate, and CelebA-Test-Ref. The metrics used for comparison are IDS (Identity Similarity), fLPIPS (face-region Learned Perceptual Image Patch Similarity), LPIPS (Learned Perceptual Image Patch Similarity), and FID (Fréchet Inception Distance). The table highlights the superior performance of ReF-LDM in terms of identity preservation, particularly on the more challenging FFHQ-Ref-Severe dataset. It also indicates potential data leakage issues in some competing methods, suggesting a possible reason for their lower performance relative to ReF-LDM.
Full paper#