↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-image diffusion models often struggle to generate diverse images, especially when using high classifier-free guidance, limiting their creative potential. This problem stems from these models’ inability to effectively incorporate additional information beyond the text prompt in the image generation process. This paper addresses this issue.
The authors introduce Kaleido Diffusion, which incorporates autoregressive latent priors into the diffusion process. This enhancement allows Kaleido to produce diverse high-quality images by leveraging an autoregressive language model that encodes the text prompt and generates various abstract latent representations (e.g., textual descriptions, bounding boxes, visual tokens), enriching the diffusion model’s input. Experiments on multiple benchmarks demonstrate Kaleido’s superior performance in generating diverse, high-quality images compared to standard diffusion models, highlighting its potential for a wider range of applications requiring diverse image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation because it introduces a novel method to significantly improve the diversity of generated images while maintaining high quality, a persistent challenge in the field. The proposed autoregressive latent modeling approach offers interpretability and controllability, opening exciting new avenues for research in high-quality and diverse image synthesis. It also offers a framework that could easily integrate with other diffusion models, leading to broader adoption and advancement in the field.
Visual Insights#
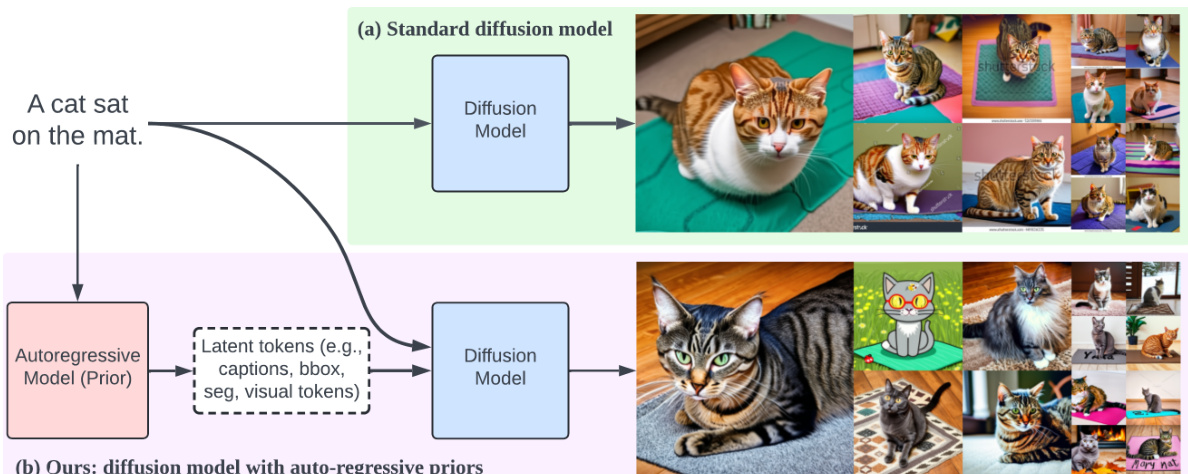
This figure compares the results of standard diffusion models and Kaleido Diffusion models. Given the same text prompt (‘A cat sat on the mat’), the standard diffusion model produces images of cats that are visually similar. In contrast, Kaleido Diffusion, which incorporates an autoregressive latent modeling technique, generates a wider variety of images, showcasing improved diversity in the generated samples.

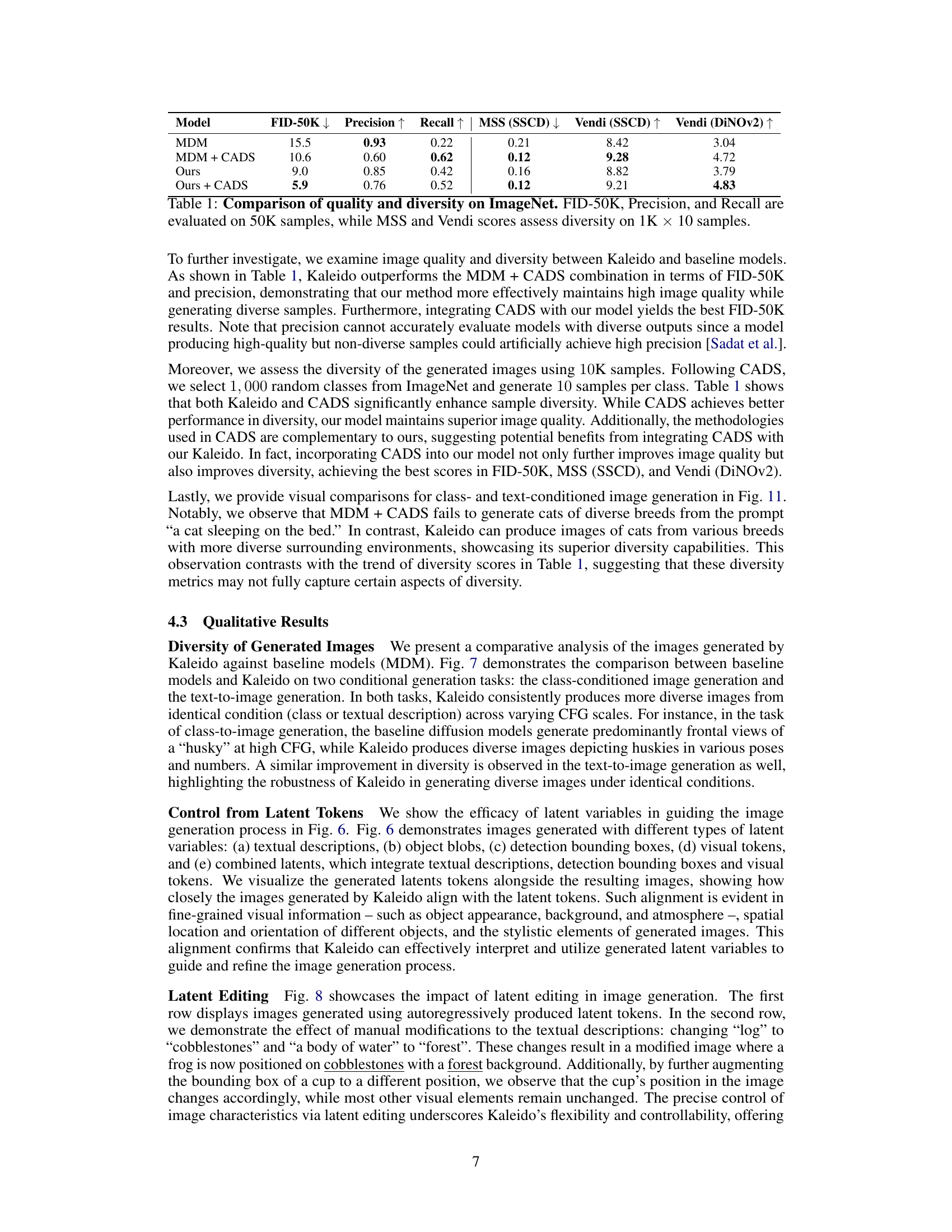
This table presents a quantitative comparison of the proposed Kaleido Diffusion model against a standard Diffusion Model (MDM) and MDM with CADS (Condition Annealed Diffusion Sampler) on the ImageNet dataset. It evaluates the models across several metrics: FID-50K (Fréchet Inception Distance), Precision, Recall, MSS (Mean Similarity Score), and Vendi score. FID-50K measures the overall quality and diversity of generated images, while Precision and Recall specifically focus on the diversity. MSS and Vendi scores provide additional quantitative measures of image diversity, computed using features extracted from two different pre-trained models (SSCD and DiNOv2). Lower FID, higher Precision and Recall, and lower MSS and higher Vendi scores indicate better performance.
In-depth insights#
Autoregressive Priors#
Autoregressive priors, in the context of generative models, offer a powerful mechanism to enhance sample diversity and control. By incorporating an autoregressive model (like an LLM) before the main generative process (e.g., diffusion), we can generate latent representations that capture high-level abstractions. These latent variables serve as richer conditioning signals for the subsequent generation stage, guiding it towards more diverse and nuanced outputs. This approach addresses the limitations of techniques like classifier-free guidance (CFG), which, while improving fidelity, often reduces the variety of generated samples. The autoregressive prior acts as a mode selector, helping the model explore a broader range of possible image interpretations from a given input. Importantly, these latent representations are not limited to text; they could encode other structured information, like bounding boxes or visual tokens, providing different levels of control and interpretability to the generation process. The resulting framework, therefore, is both more diverse and more controllable, offering a promising approach to improve the capabilities of current high-quality image generation models.
Diverse Image Gen#
The concept of “Diverse Image Gen” in the context of a research paper likely refers to methods aimed at enhancing the variety and creativity of images generated by AI models. A thoughtful analysis would explore how the paper tackles this challenge, likely focusing on the limitations of existing techniques. Current diffusion models, while adept at generating high-quality images, often struggle with diversity, particularly when using high classifier-free guidance weights, resulting in similar outputs despite different input prompts. Therefore, the paper’s approach to “Diverse Image Gen” may involve novel techniques such as incorporating autoregressive latent priors, employing diverse latent representations (e.g., textual descriptions, bounding boxes, visual tokens), or introducing innovative sampling strategies. A key area of interest is the trade-off between diversity and image quality. The research may demonstrate that improved diversity is achieved without compromising the fidelity and realism of the images. Ultimately, the success of “Diverse Image Gen” would be measured by qualitative and quantitative metrics such as Fréchet Inception Distance (FID) and Recall, along with a thorough qualitative analysis of the generated images to visually confirm the diversity of styles and characteristics.
Latent Control#
The concept of ‘Latent Control’ in the context of diffusion models is crucial for steering the generation process towards desired outcomes. It involves manipulating the latent representations of data — often learned feature vectors or encoded information — to directly influence the generated output. This approach offers a powerful alternative to traditional methods of conditional generation, which might rely solely on input conditioning, such as text prompts. Effective latent control offers a degree of interpretability, allowing users to understand how specific changes in latent variables translate into changes in generated images. This is particularly important when working with complex data such as images, where direct manipulation of pixel values might prove unwieldy and unreliable. A significant advantage of latent control is the potential to enhance diversity and control over generation. By carefully selecting, modifying, or augmenting latent representations, it becomes possible to guide the model to explore different modes and generate a broader range of outputs, preventing the generation of similar or repetitive results (mode collapse). The implementation of latent control can take various forms, for example, directly editing latent vectors, leveraging autoregressive models to predict latent representations based on textual descriptions, or using pre-trained models to extract latent features. Ultimately, effective latent control enables the generation of higher quality, more diverse, and easily controllable outputs, while adding a layer of interpretability to the generation process.
CFG Diversity#
The concept of “CFG Diversity” in the context of diffusion models highlights a critical trade-off between image quality and sample variety. Classifier-free guidance (CFG), while improving image fidelity by sharpening the conditional distribution, often leads to a reduction in diversity, resulting in repetitive or similar outputs even from the same prompt. This limitation is especially apparent with high CFG weights. Therefore, “CFG Diversity” focuses on methods and techniques to enhance the variety of images generated despite the use of CFG. Solutions might involve modifying the sampling process, introducing latent variables or priors to enrich the model’s inputs, or adjusting the CFG mechanism itself for a more balanced approach. Successfully navigating this trade-off is crucial for creating versatile and high-quality image generation models that meet diverse user needs and creative applications. The challenge lies in developing techniques to maintain the quality-enhancing effects of CFG while simultaneously unlocking the potential for greater diversity in generated outputs.
Future of Kaleido#
The future of Kaleido, a framework enhancing conditional diffusion models via autoregressive latent modeling, is bright. Improved diversity in image generation, even with high classifier-free guidance, is a key advantage, enabling more creative and varied outputs for diverse user needs. Enhanced interpretability, through the use of discrete and human-understandable latent tokens, is another promising aspect, fostering better control and understanding of the generative process. Future work could explore more diverse latent representation types, going beyond text, bounding boxes, and visual tokens, potentially incorporating depth maps, segmentation masks or other higher-level image features for finer-grained control. Integration with more advanced LLMs would further amplify Kaleido’s potential, leading to even more sophisticated and nuanced image generation capabilities. Addressing the computational complexity of the enhanced model and optimizing its efficiency for wider accessibility and application would also be critical for future development. Exploring collaborative or interactive image generation utilizing the latent variables as user interfaces would open exciting avenues. Lastly, tackling the challenge of mode collapse within the autoregressive model itself, while maintaining diversity, remains a key area for future refinement.
More visual insights#
More on figures
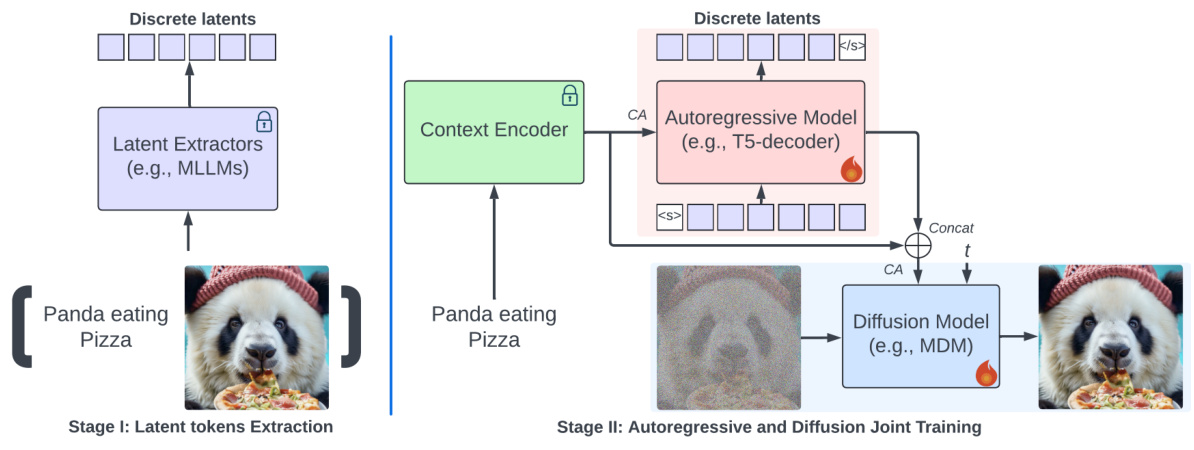
This figure illustrates the two-stage training pipeline of Kaleido diffusion. Stage I involves extracting discrete latent tokens (textual descriptions, bounding boxes, object blobs, and visual tokens) from the input image using latent extractors (e.g., Multimodal Large Language Models). These latents serve as abstract representations of the image. In Stage II, an autoregressive model (e.g., T5-decoder) generates the latents, which are then concatenated with the context encoder’s output. This combined information is fed into a diffusion model (e.g., Matryoshka Diffusion Model), which iteratively synthesizes the final image. The autoregressive model and diffusion model are jointly trained to generate high-quality images while maintaining diversity.
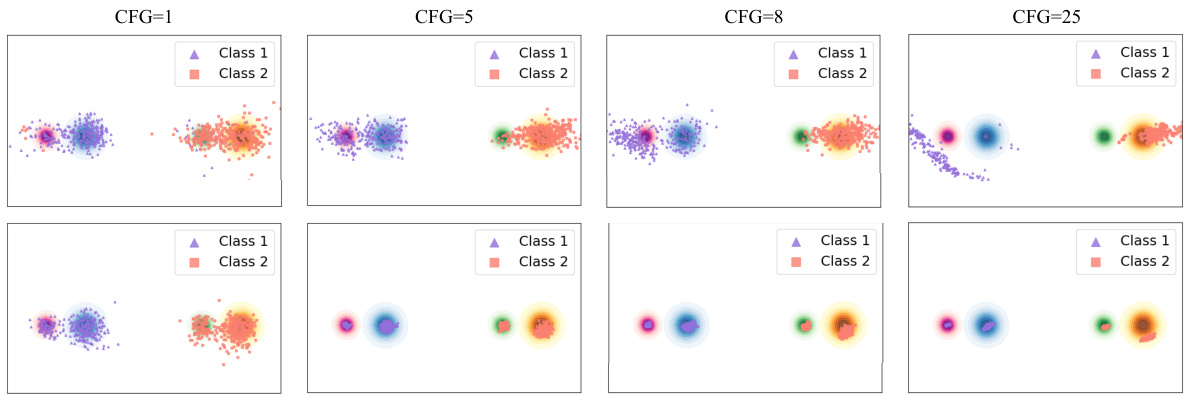
This figure demonstrates the effect of explicitly introducing latent priors in a toy dataset with two main classes, each containing two modes. It compares two models: a standard diffusion model conditioned on the major class ID, and a latent-augmented model incorporating subclass ID as priors. It shows that while the standard diffusion model tends to converge to one mode (subclass) with increased guidance, the latent-augmented model captures all modes, highlighting the benefit of latent priors for improving diversity under high guidance.
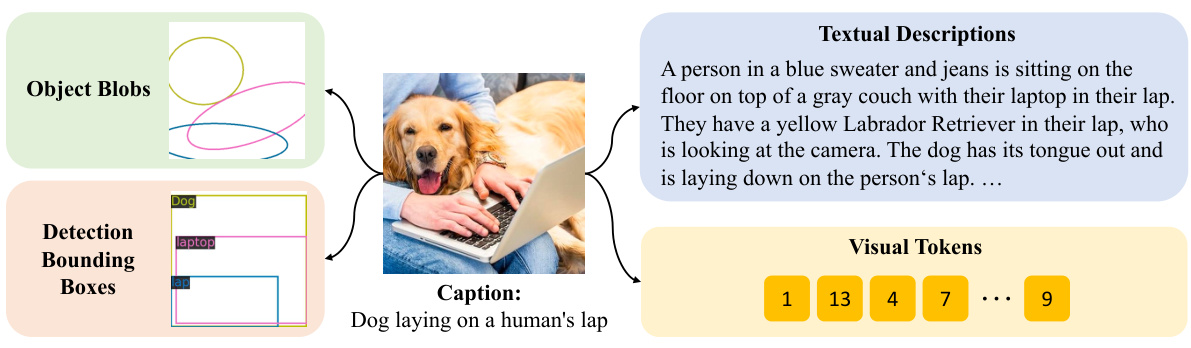
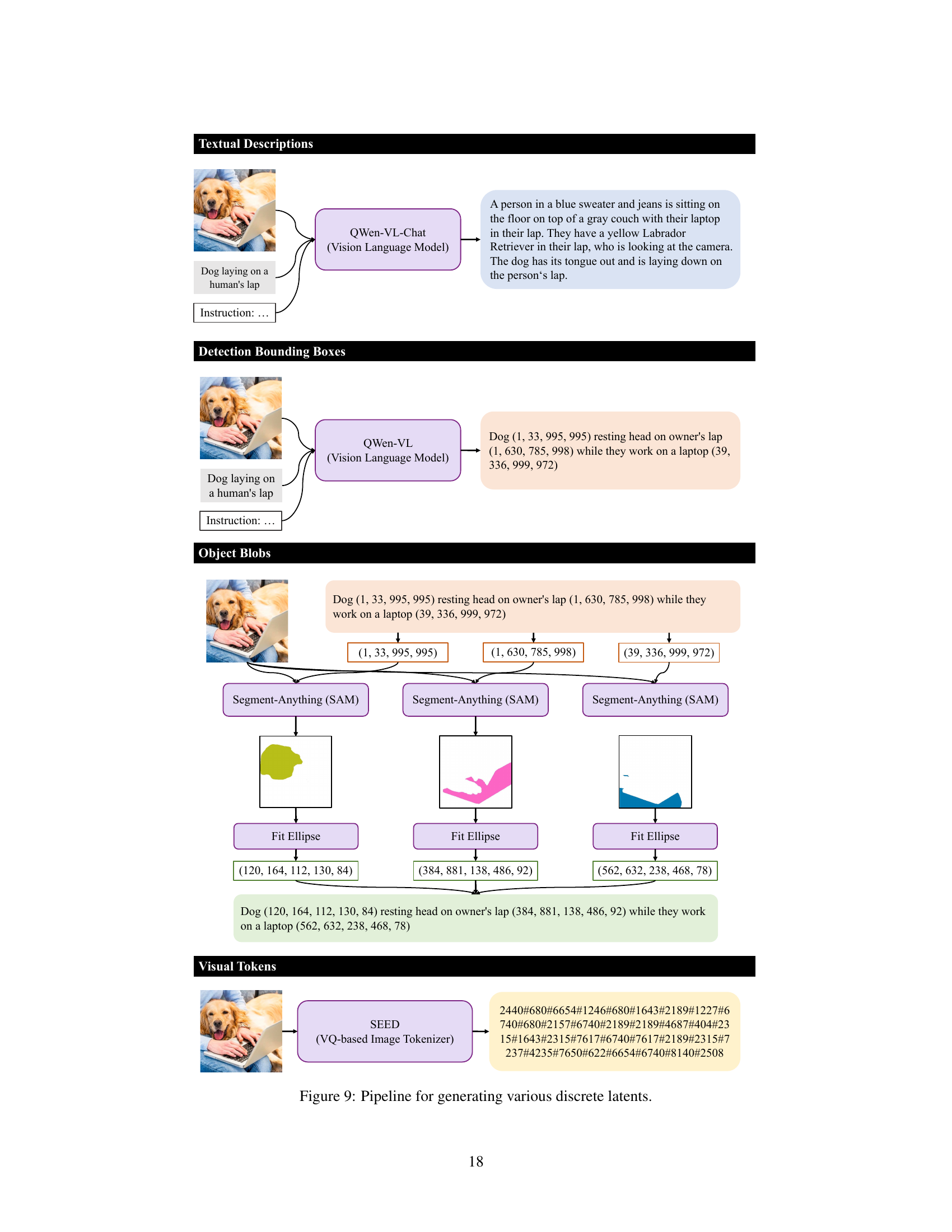
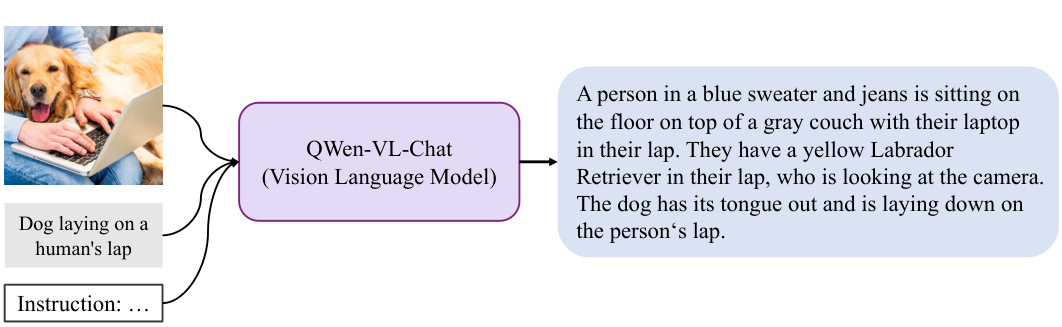
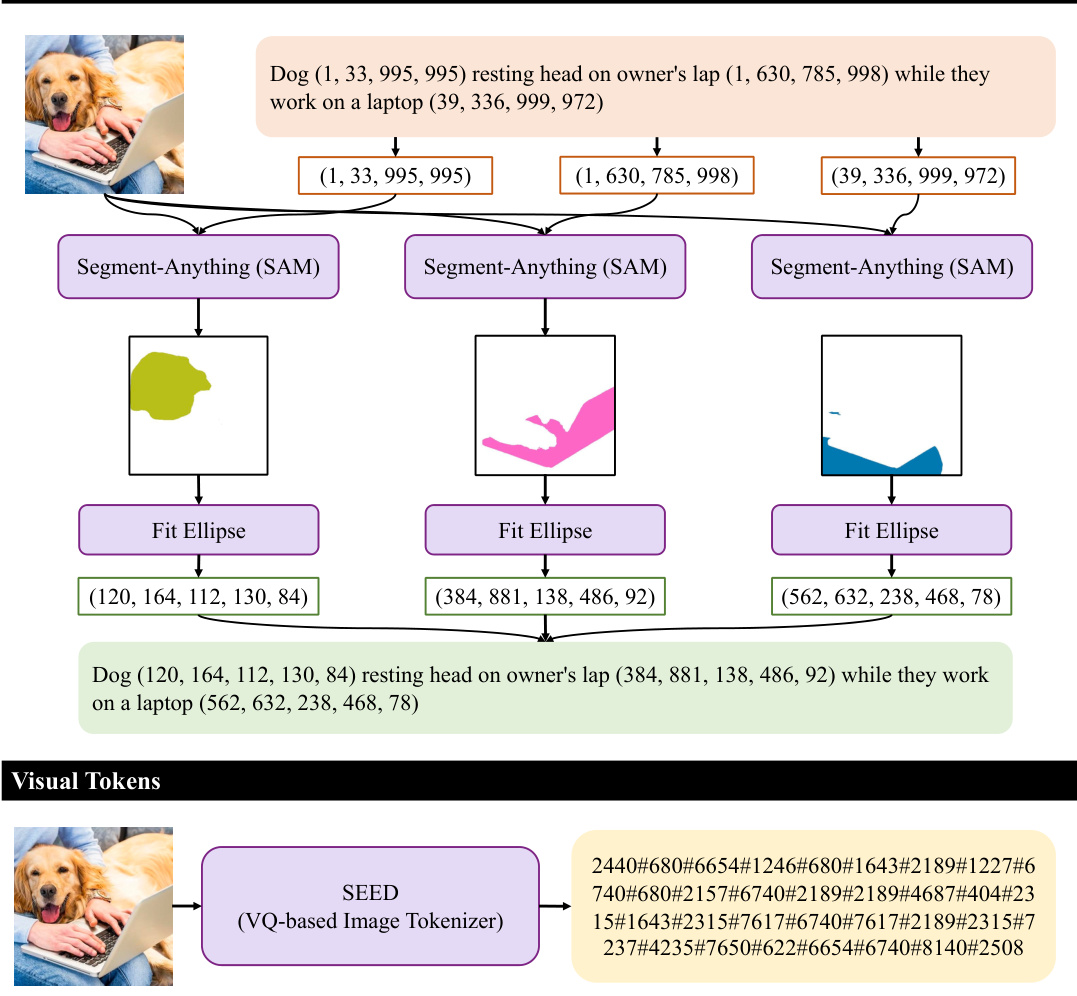
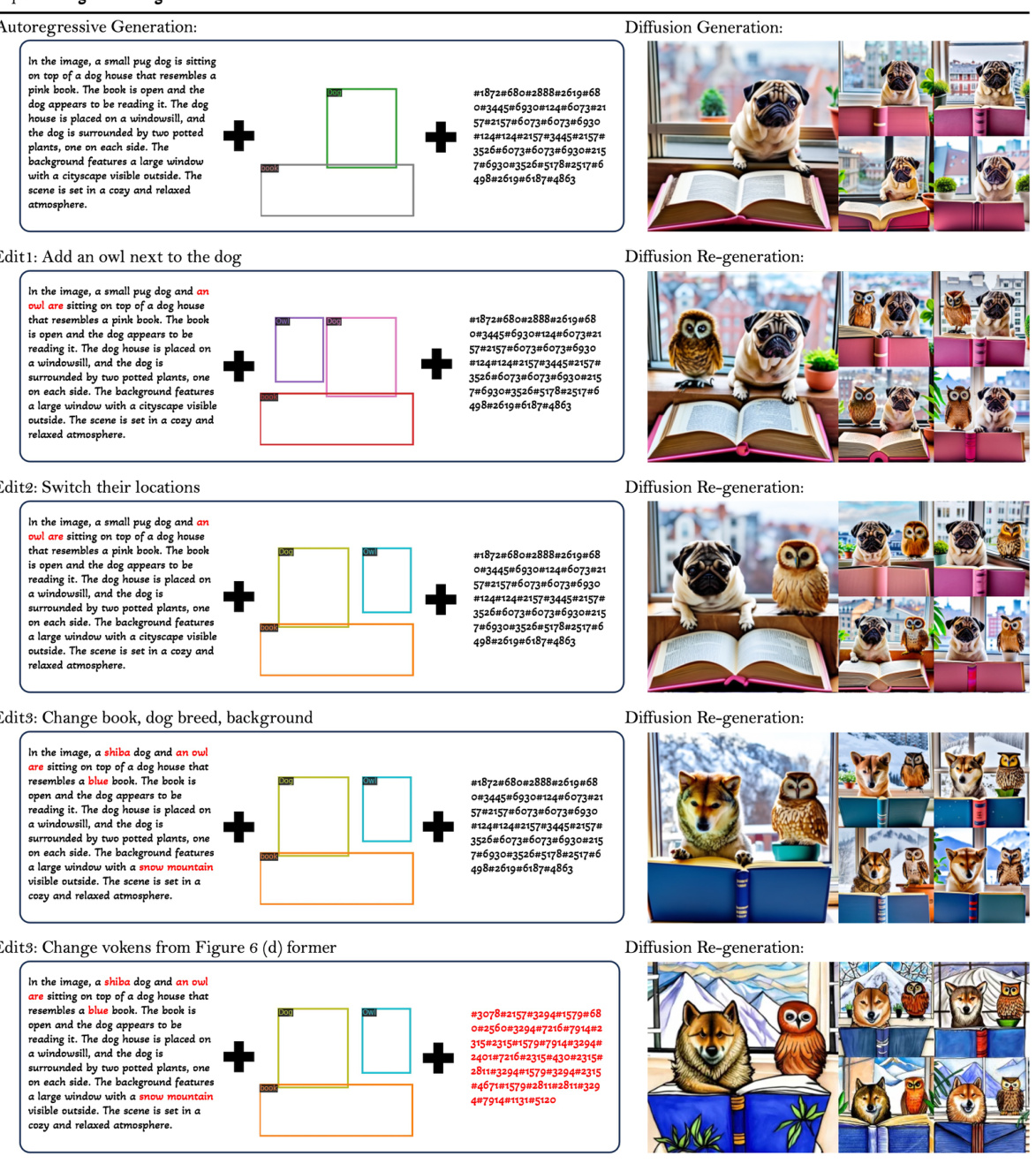
This figure shows four different types of discrete tokens that can be used as latent variables in the Kaleido Diffusion model. These tokens represent different levels of abstraction and detail about the image, such as a detailed textual description, bounding boxes around objects, visual tokens from a vector quantized model, and blob-like representations of objects. These diverse representations aim to enhance the diversity of generated images. The original caption ‘Dog laying on a human’s lap’ provides minimal context, whereas the detailed representations offer richer information for image generation, leading to more diversity.
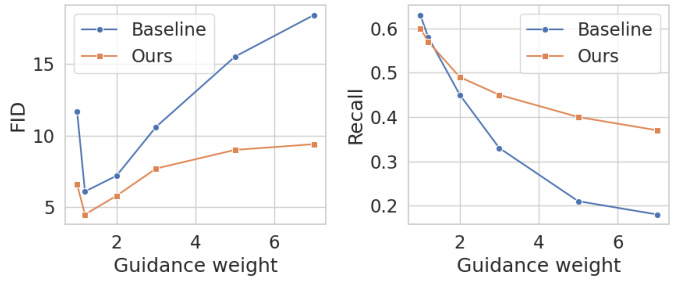
The figure shows FID and Recall scores with varying guidance weights for both the baseline model (MDM) and the proposed Kaleido Diffusion model. It demonstrates Kaleido’s improved diversity (higher Recall) and maintained quality (lower FID) across various guidance weight settings, especially showing its robustness compared to the baseline model at high guidance weights.

This figure illustrates the training pipeline of the Kaleido diffusion model. It shows two main stages: Stage I involves the extraction of latent tokens (discrete latents) using latent extractors such as Multimodal LLMs (MLLMs), and Stage II entails the joint training of an autoregressive model (e.g., T5-decoder) and a diffusion model (e.g., MDM). The autoregressive model takes the context encoder output and the discrete latents as input to generate new discrete latents. These new latents are concatenated with the context encoder output and passed to the diffusion model for image generation. The figure highlights the flow of information and the interaction between the two models in the training process.

This figure compares the image diversity generated by the proposed Kaleido diffusion model and a standard diffusion model under various classifier-free guidance (CFG) scales. The top two rows show samples generated from the standard diffusion model and the bottom two rows from the Kaleido model for two different tasks (class-to-image and text-to-image). As CFG increases, the standard diffusion model shows a sharp decrease in image diversity, while Kaleido maintains a consistently high level of diversity.
This figure illustrates the two-stage training pipeline of Kaleido Diffusion. Stage I focuses on extracting discrete latent tokens (e.g., textual descriptions, object blobs, bounding boxes, visual tokens) from the input image using various methods such as Multimodal Language Models (MLLMs) and autoregressive models. Stage II involves joint training of an autoregressive model (e.g., T5-decoder) to predict these latent tokens given the original caption and a latent-augmented diffusion model (e.g., MDM) to generate images conditioned on both the original caption and the autoregressively generated latent tokens. The context encoder and the autoregressive decoder share attention with the diffusion model to ensure effective integration of textual and visual information.
This figure illustrates the training pipeline of the Kaleido diffusion model. It shows two main stages: latent token extraction and autoregressive and diffusion joint training. In the first stage, discrete latents are extracted from an image using different methods (e.g., multi-modal large language models). In the second stage, an autoregressive model (e.g., T5 decoder) is used to generate the latent tokens which are then concatenated with the original context and fed into a diffusion model (e.g., MDM) to generate the final image. This architecture is designed to combine the advantages of both autoregressive and diffusion models for improved image generation.
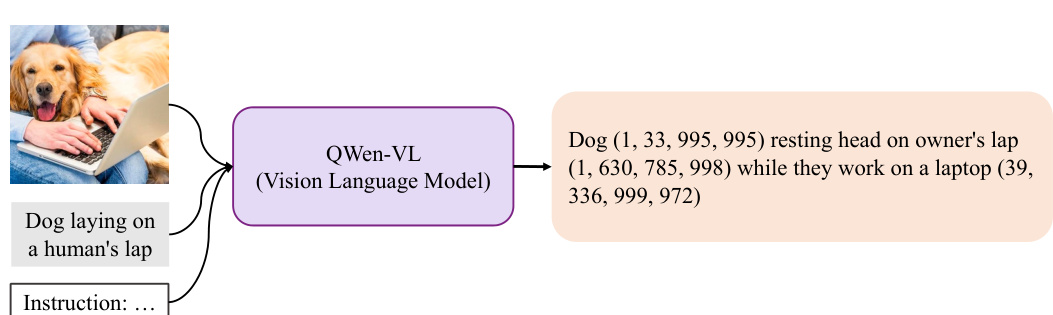
This figure illustrates the process of generating different types of discrete latent tokens from an image and caption using various models. It demonstrates how textual descriptions, bounding boxes, object blobs, and visual tokens are extracted. The process starts with an image and caption as input, which are then processed by different models (e.g., QWen-VL for captions and bounding boxes, Segment Anything (SAM) for object blobs, SEED for visual tokens) to extract the various discrete latents.
This figure illustrates the training pipeline of the Kaleido diffusion model. It shows the two main stages: Stage I, Latent tokens Extraction, which uses various latent extractors (e.g., MLLMs) to extract discrete latent tokens from the input image and caption. The output of this stage is then passed to Stage II: Autoregressive and Diffusion Joint Training. In stage II, an autoregressive model (e.g., T5-decoder) predicts discrete latents based on the contextual information from the context encoder, and these latent tokens are concatenated with the original caption as additional input to the diffusion model (e.g., MDM). The diffusion model then learns to generate images based on both the original caption and the autoregressively generated discrete latent tokens.

This figure visually compares the image generation results between the baseline model (MDM) and the proposed Kaleido model using color clusters as latent tokens. The left panel shows images generated by the baseline MDM, showcasing a limited diversity in lemon images. The middle panel displays the AR-predicted color clusters used as input to Kaleido. The right panel presents the images generated by Kaleido, demonstrating a notable increase in the diversity and variety of lemon images, highlighting the effectiveness of incorporating color clusters as latent variables.

This figure compares image diversity generated by standard diffusion models and Kaleido Diffusion under different classifier-free guidance (CFG) scales. It shows that while standard diffusion models lose diversity as CFG increases, Kaleido maintains a diverse range of images.

This figure compares the image generation results of the baseline model (MDM) and Kaleido model using different sampling strategies (DDPM and CADS) for both class-conditioned and text-conditioned image generation tasks. Each column shows samples generated with the same prompt but using different methods. It visually demonstrates that Kaleido improves image diversity compared to the baseline model, particularly with the CADS sampling strategy.

This figure shows uncurated image samples generated by both the baseline diffusion model (MDM) and the proposed Kaleido diffusion model on the ImageNet dataset. The images are 256x256 pixels, and the classifier-free guidance (CFG) scale is set to 4.0. The figure aims to visually demonstrate the diversity of generated images by each model.

This figure displays uncurated samples generated by both the baseline diffusion model (MDM) and the proposed Kaleido Diffusion model. The images showcase a variety of subjects (space shuttle, cockatoo, sea turtles) illustrating the diversity achieved by the two models, particularly when compared under the same guidance scale (4.0). Kaleido shows greater visual variety than MDM.

This figure shows uncurated samples generated by both the baseline diffusion model (MDM) and the Kaleido diffusion model. The images illustrate the diversity of samples generated by each model for three different classes from ImageNet: rhinoceros beetles, llamas, and broccoli. The guidance scale used was 4.0, a parameter that controls the balance between fidelity to the prompt and diversity in the generated images. The figure helps to visually demonstrate the improved diversity offered by the Kaleido model.

This figure compares image samples generated by a standard diffusion model and the proposed Kaleido diffusion model, both using the same caption prompt: ‘a cat sat on the mat’. The goal is to highlight the increased diversity of images produced by Kaleido, which incorporates autoregressive latent modeling to enhance the variety of generated samples.
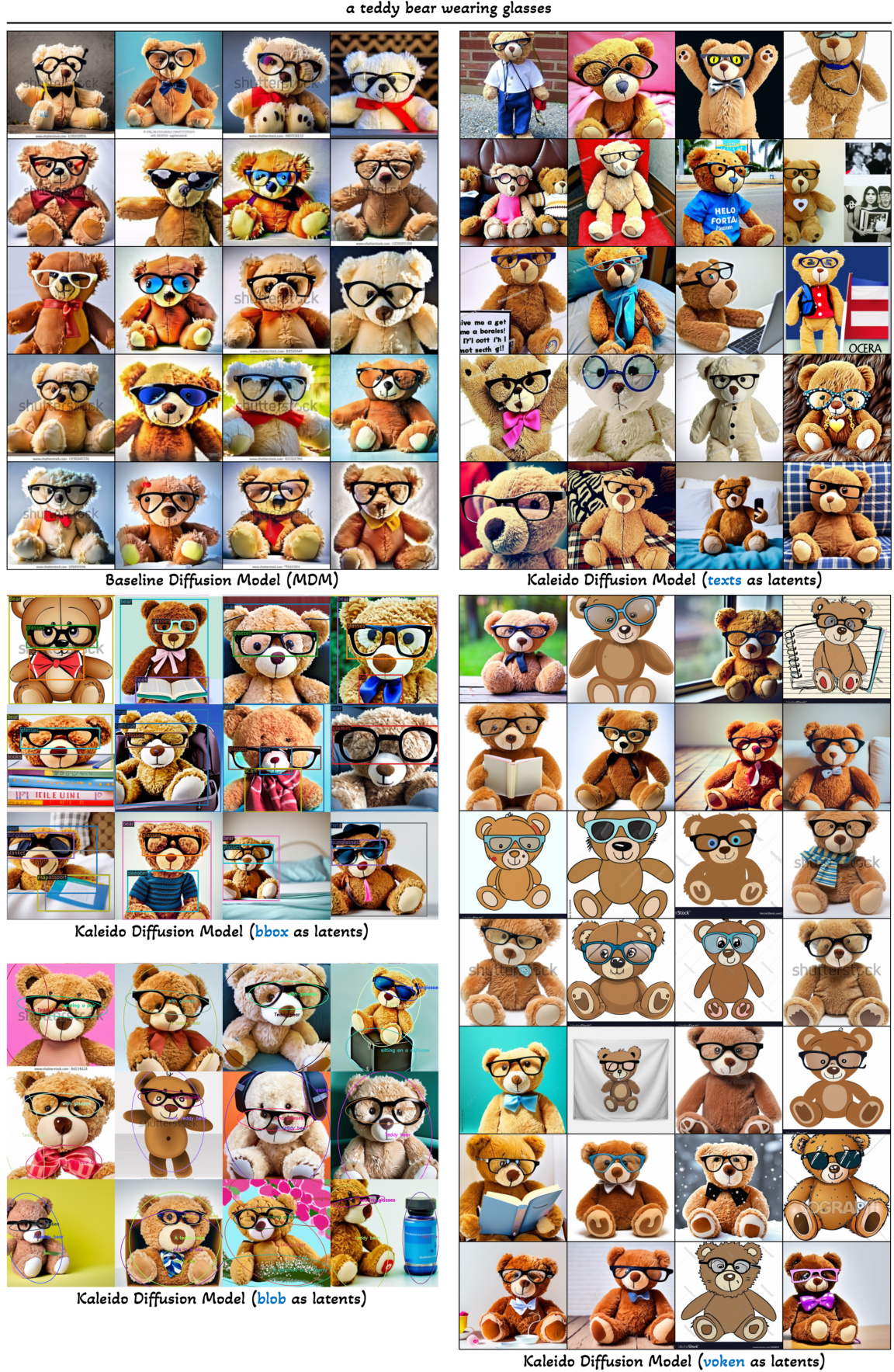
This figure compares image samples generated by the baseline diffusion model (MDM) and the Kaleido diffusion model using different types of latent variables (text, bounding boxes, object blobs, and visual tokens) for the same input condition. The goal is to illustrate the diversity of image generation achieved by Kaleido, especially in comparison to the MDM model, which shows less diversity. The guidance scale (CFG) is set to 7.0, indicating a high level of control over the generation process.

This figure displays various types of discrete tokens generated by different methods: textual descriptions, detection bounding boxes, object blobs, and visual tokens. Each row shows a different representation of the same image, demonstrating how different types of latents can capture various aspects of the image content and spatial information. The original caption is also provided for context.
This figure shows the training pipeline of the Kaleido diffusion model. It consists of two main stages: 1) Latent tokens extraction, where discrete latents are extracted from the input image using various methods such as multi-modal LLMs. 2) Autoregressive and diffusion joint training, where an autoregressive model generates latent tokens and a latent-augmented diffusion model synthesizes images based on these latents and the original condition. The pipeline combines the strengths of both autoregressive and diffusion models to enhance image generation.
Full paper#