↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly used in various applications, but their tendency to produce overconfident predictions hinders their reliability, particularly in high-stakes scenarios. Existing methods for uncertainty estimation either require extensive prompting or are computationally expensive. This lack of reliable uncertainty estimates poses a significant challenge to the safe and effective deployment of LLMs.
This research introduces a novel approach to address this issue. By fine-tuning LLMs on a relatively small dataset of correctly and incorrectly answered questions, the researchers significantly improved uncertainty calibration. This method proves efficient and generalizes well to diverse question types, surpassing the performance of baseline methods. Moreover, it unveils the possibility of using LLMs as general-purpose uncertainty estimators, applicable to both their own predictions and the predictions of other models. The findings are validated through a user study, showcasing the benefits of uncertainty estimates in human-AI collaborative decision-making.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs because it addresses the critical issue of uncertainty quantification, a major obstacle for deploying LLMs in high-stakes applications. The findings offer practical methods to improve the reliability and trustworthiness of LLM outputs, thus advancing the field significantly.
Visual Insights#
This figure illustrates the challenges of obtaining reliable uncertainty estimates from large language models (LLMs). It introduces a method for fine-tuning LLMs using a graded dataset of generations to improve their calibration and AUROC. The results show that fine-tuning outperforms baseline methods for uncertainty estimation on open-ended questions from the MMLU benchmark, demonstrating improved calibration and better discrimination between correct and incorrect answers.

This table presents the results of evaluating different methods for estimating uncertainty on a subset of the LeetCode coding challenge. It compares the Expected Calibration Error (ECE) and Area Under the ROC Curve (AUROC) of three language models (LLaMa-2-7B, Mistral-7B, and Mistral-7B-Instruct) using both zero-shot methods and methods fine-tuned using LoRA. The table shows that fine-tuning generally improves selective prediction (AUROC), but the impact on calibration (ECE) is model-dependent.
In-depth insights#
LLM Uncertainty#
The paper delves into the crucial area of LLM uncertainty, arguing that current methods for assessing the reliability of large language model (LLM) predictions are insufficient for high-stakes applications. It challenges the notion that simply prompting high-performance LLMs is enough to achieve well-calibrated uncertainty estimates, demonstrating that fine-tuning on a small dataset of correctly and incorrectly labeled generations is crucial for creating reliable uncertainty estimators. The study highlights the importance of using appropriate training techniques like LoRA for efficient and effective fine-tuning, particularly for large open-source models. Furthermore, it investigates the underlying mechanisms of LLM uncertainty estimation, suggesting that many models can serve as general-purpose uncertainty estimators. A key finding is that fine-tuning with a graded dataset of examples improves both calibration and generalization of uncertainty estimates significantly, outperforming standard zero-shot methods. Finally, the research underscores the importance of informing human users of LLM uncertainty through a user study, showing its potential to enhance human-AI collaboration.
Fine-tuning LLM#
Fine-tuning LLMs for uncertainty calibration involves training the model to better estimate the probability of its predictions being correct. This is achieved by providing the model with a graded dataset of generations, where each generation is labeled with its correctness. The paper explores different approaches, such as training a small feed-forward network (Probe) on the model’s features or using LoRA (Low-Rank Adaptation) to add trainable parameters to the model. LoRA is shown to be a more effective method, especially when combined with a prompt framing the task as a multiple-choice question, allowing the model to adjust its internal representations and improve the quality of uncertainty estimates. The effectiveness of fine-tuning is demonstrated across various datasets and tasks, showing that even a small set of graded examples (around 1000) can significantly improve calibration and uncertainty discrimination compared to simpler baseline methods. The study also emphasizes that fine-tuning allows for generalization to unseen question types and dataset shifts, highlighting its practical advantages.
Calibration Tuning#
Calibration tuning, in the context of large language models (LLMs), focuses on improving the reliability of uncertainty estimates produced by these models. Standard LLMs often exhibit overconfidence, assigning high probabilities to incorrect predictions. Calibration tuning addresses this by fine-tuning the model on a dataset of correctly and incorrectly answered questions, teaching it to better discriminate between accurate and inaccurate responses. This process involves training a model (or a component of a model) to predict the correctness of the LLM’s output. The method’s effectiveness depends critically on the quality and size of the training data and the model architecture used for calibration. The key advantage is the ability to generate more reliable uncertainty scores, enabling more informed decision-making when employing LLMs in high-stakes applications. A related aspect is the exploration of different calibration methods; some use prompting techniques, others use more extensive model retraining. The study explores the generalization capabilities of calibration-tuned models across different datasets and topics, highlighting its potential societal impact through human-AI collaboration.
Human-AI Collab#
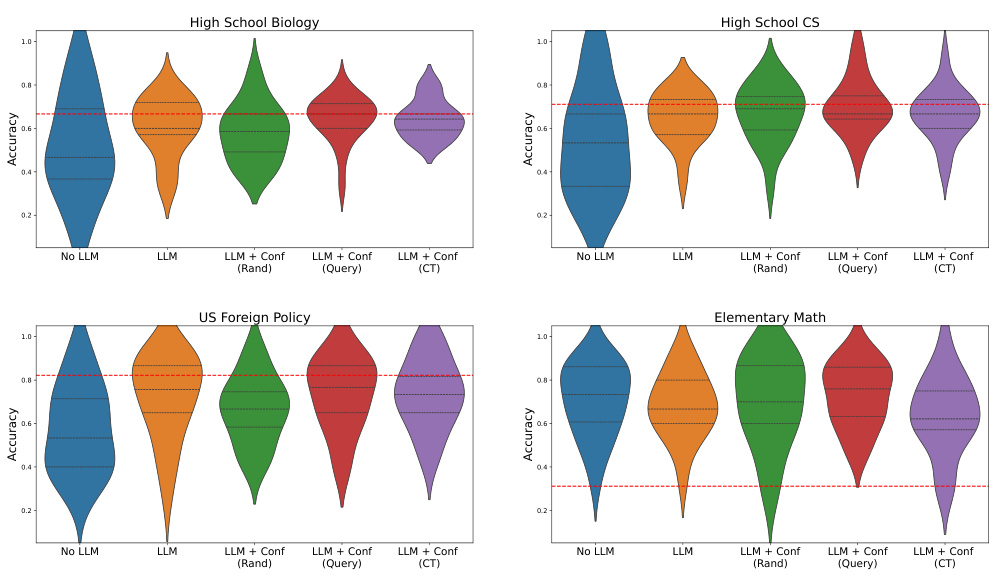
In the realm of Human-AI collaboration, a critical aspect lies in the reliable communication of uncertainty by AI systems. The research delves into this by exploring how calibrated uncertainty estimates, derived through model fine-tuning, influence human trust and decision-making. A key finding is that humans are sensitive to these confidence scores, modulating their reliance on AI accordingly. This underscores the importance of not only accurate AI predictions but also the transparent and trustworthy presentation of uncertainty. However, user behavior varies; some heavily rely on AI confidence, while others maintain independent judgment. The study also reveals the potential for generalized uncertainty estimation: models trained on one domain can effectively estimate uncertainty in others, even for different models. This has important practical implications, broadening the applicability of uncertainty calibration. Ultimately, the research suggests that effective human-AI collaboration hinges on a combination of accurate AI performance and the clear communication of uncertainty. Further research should investigate optimal ways to present uncertainty information to humans, enhancing the transparency and improving the overall effectiveness of collaborative systems.
Generalization Limits#
A section on “Generalization Limits” in a research paper would explore the boundaries of a model’s ability to apply learned knowledge to unseen data. It would likely discuss how well the model’s uncertainty estimates generalize across different datasets, tasks, or question types. Key considerations would include distribution shifts (differences between training and testing data), robustness to adversarial examples, and the impact of data biases on generalization. The analysis might involve evaluating performance metrics like calibration error and AUROC across various scenarios to assess how well uncertainty estimates transfer from one context to another. Specific challenges in achieving good generalization in large language models might be highlighted, such as the overconfidence problem and the difficulties in capturing linguistic variations. The paper could also present strategies to mitigate generalization limits, such as data augmentation, domain adaptation, or model regularization. Finally, the authors would likely discuss the practical implications of these limits for real-world applications of large language models, emphasizing the importance of careful evaluation and validation before deployment in high-stakes settings.
More visual insights#
More on figures

This figure illustrates the challenge of large language models (LLMs) in accurately estimating their uncertainty. The authors propose using a graded dataset of LLM-generated answers to fine-tune the model, improving the accuracy of uncertainty estimation. The evaluation uses a new open-ended version of the MMLU benchmark, demonstrating that fine-tuning leads to better calibration (lower ECE) and discrimination (higher AUROC) compared to existing methods.
The figure compares different methods for estimating uncertainty in large language models (LLMs). The left panel shows that a likelihood-based approach works well for multiple-choice questions but poorly for open-ended generation. The right panel demonstrates that fine-tuning significantly improves the accuracy and calibration of uncertainty estimates compared to simple prompting methods. Different LLMs are evaluated and the results show that the benefits of fine-tuning are consistent across them.
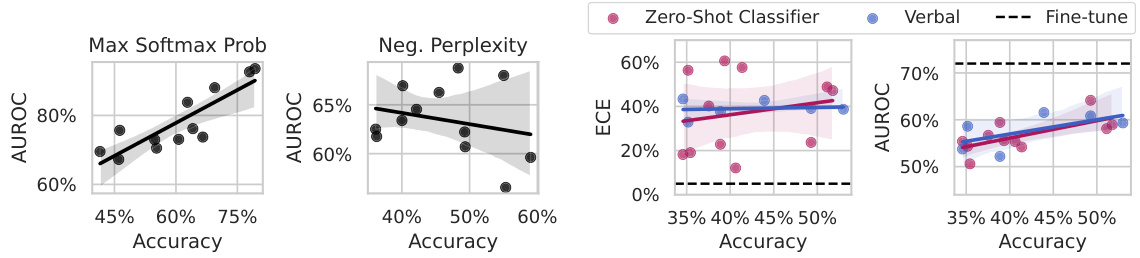
The figure compares the performance of different uncertainty estimation methods on multiple-choice and open-ended MMLU tasks. The left panel shows that supervised fine-tuning methods (Probe, LORA, LORA + Prompt) generally improve calibration and AUROC compared to baseline methods (Zero-Shot, Sampling). The right panel demonstrates that even a small number of labeled examples (around 1000) significantly improves the uncertainty estimation of large language models, exceeding the performance of unsupervised methods.

This figure shows the comparison of different methods for estimating uncertainty in large language models (LLMs) for both multiple-choice and open-ended question answering tasks. The left panel demonstrates the effectiveness of fine-tuning with various parameterizations in improving both Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). The right panel illustrates how the amount of labeled data used in fine-tuning impacts performance on open-ended tasks, suggesting that 1000 examples are sufficient to outperform baseline methods.
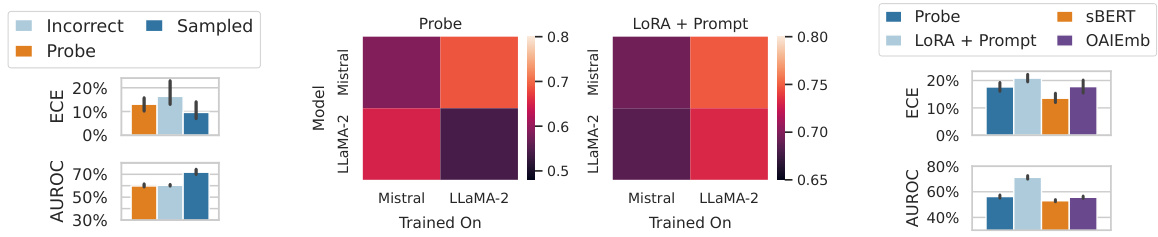
This figure presents ablation studies on the model’s ability to learn uncertainty. The left panel shows that training on incorrect answers leads to poorer performance compared to training on correct answers, suggesting that the model learns more than just simple patterns in the question and answer pairs. The central panel demonstrates that models can generalize uncertainty estimation to other models, with Mistral models performing better at estimating uncertainty for LLaMA models than LLaMA models can for themselves. The right panel shows that simple sentence embeddings can achieve comparable performance to frozen language models in uncertainty estimation, but training through the model’s features significantly enhances the performance.

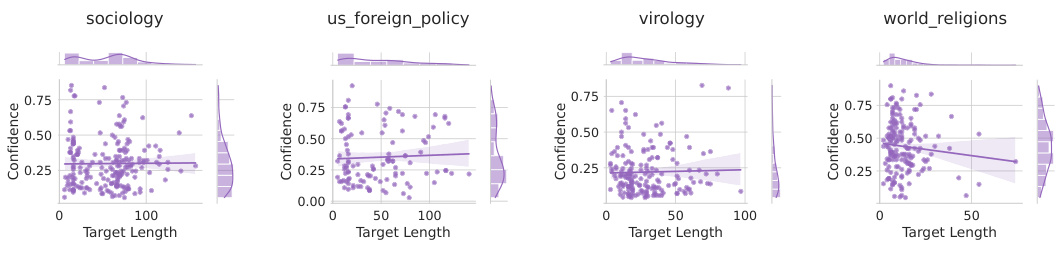
This figure shows the distribution of model confidence scores and whether users agreed with the model’s prediction for three different scenarios: zero-shot prompting, fine-tuning with LoRA and prompting, and random confidence scores. The results show that calibrated confidence scores (LoRA + Prompt) influence user reliance on the model’s predictions, unlike zero-shot and random confidence.

This figure compares the performance of different methods for estimating uncertainty in LLMs on both multiple-choice and open-ended question-answering tasks. The left panel shows that fine-tuning significantly improves both calibration and the ability to discriminate between correct and incorrect answers. The right panel illustrates that using as few as 1000 labeled examples is sufficient for good performance, and increasing the number of examples beyond that yields only marginal improvement.
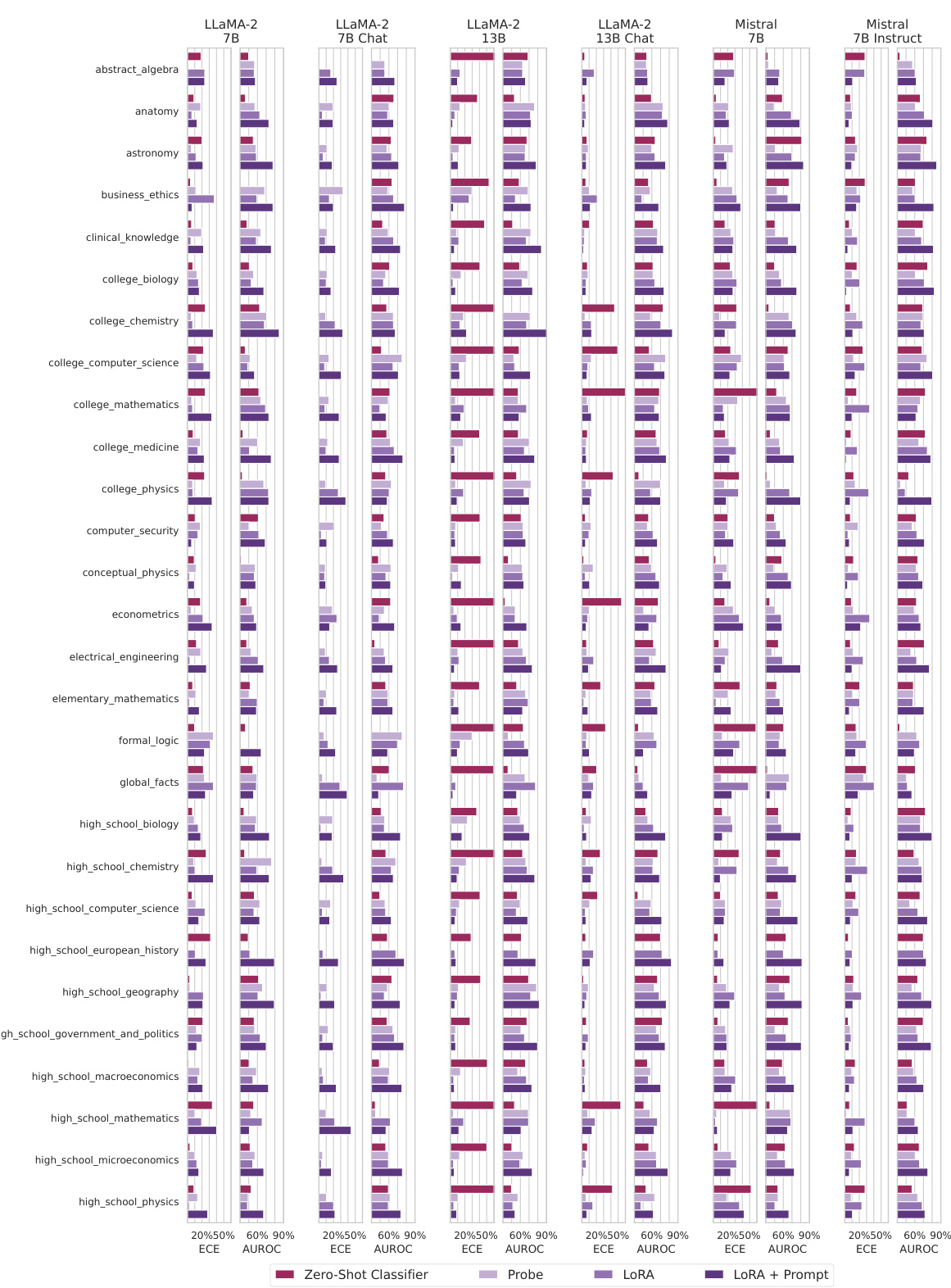
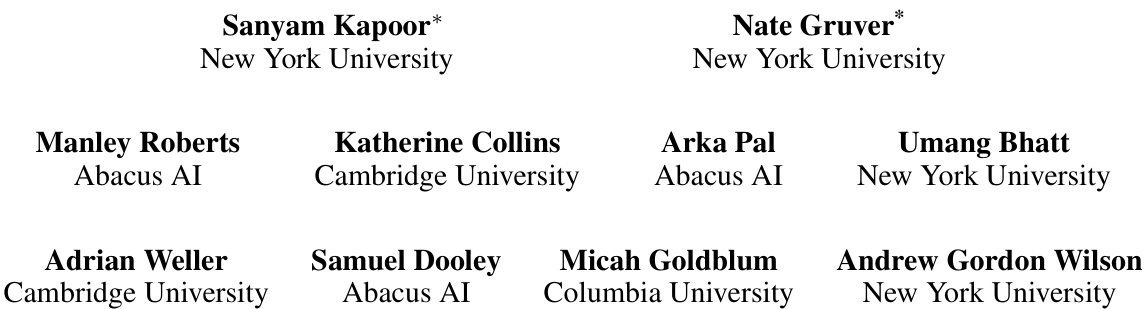
This figure compares different methods for estimating uncertainty in large language models (LLMs). The left panel shows that using maximum softmax probability for multiple-choice questions is a good indicator of uncertainty and improves with better models, unlike perplexity for open-ended generation. The right panel demonstrates that simple prompting methods are far less effective at estimating uncertainty compared to fine-tuning a model on a small dataset of graded examples.

The left panel compares uncertainty estimation methods for multiple choice and open-ended questions. It shows that maximum softmax probability is a good indicator of uncertainty for multiple choice questions, while perplexity is not suitable for open-ended generation. The right panel compares prompting methods against a fine-tuned model. It highlights that fine-tuning significantly improves uncertainty estimation, outperforming zero-shot prompting methods in both expected calibration error (ECE) and area under the ROC curve (AUROC).

This figure compares the performance of different uncertainty estimation methods on both multiple-choice and open-ended MMLU datasets. The left panel shows that supervised fine-tuning methods generally improve both calibration (ECE) and discrimination (AUROC), with LORA+Prompt outperforming other methods. The right panel demonstrates that fine-tuning performance improves with more labeled data, but that using 1000 examples already yields substantial gains.
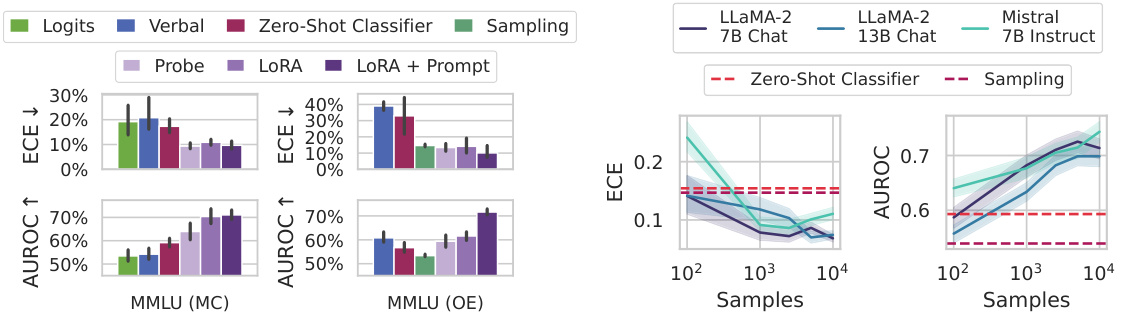
This figure demonstrates the generalization of uncertainty estimation methods across different distribution shifts. The left panel compares the composition of the fine-tuning dataset with the MMLU benchmark, showing the robustness of the method to differences in subject matter distribution. The center panel evaluates generalization across question formats (multiple-choice vs. open-ended), highlighting the superior performance of LORA+Prompt. The right panel assesses performance on unanswerable questions, illustrating the ability of the fine-tuned model to express appropriate uncertainty.

This figure shows the density plots of the model’s reported confidence and whether the user chose to agree with the model’s prediction across three different conditions: zero-shot prompt, calibrated confidence (LORA+Prompt), and random confidence. The results demonstrate that users are sensitive to calibrated confidence scores and tend to agree with high-confidence predictions from a calibrated model more often, while showing indifference to random confidence scores.
This figure compares the performance of different uncertainty estimation methods on multiple-choice and open-ended MMLU datasets. The left panel shows that supervised training methods (Probe, LORA, LORA+Prompt) generally improve both calibration (ECE) and the ability to discriminate between correct and incorrect answers (AUROC). The right panel demonstrates that even a small number (1000) of labeled examples is sufficient to improve uncertainty estimation performance, with diminishing returns for larger datasets.

This figure compares the performance of different uncertainty estimation methods (zero-shot, probing, LoRA, LoRA+Prompt) on both multiple-choice and open-ended MMLU datasets. The left panel shows the expected calibration error (ECE) and area under the ROC curve (AUROC) for each method, highlighting the improvements achieved through fine-tuning, particularly with the LoRA+Prompt approach. The right panel illustrates how the performance of fine-tuning changes as the size of the labeled training dataset increases, revealing that even 1000 examples are effective and that the marginal gain from additional data is relatively small after 5000 examples.

The figure shows the distribution of LLM confidence scores and whether users agree with the model’s prediction, comparing zero-shot prompting, calibrated and random confidence scores. It demonstrates that users are sensitive to calibrated confidence scores, adjusting their reliance on the LLM based on the reliability of the confidence estimates.
This figure shows that large language models (LLMs) have difficulty assigning reliable confidence estimates to their generated text. The authors propose a method of fine-tuning the LLMs on a graded dataset of correct and incorrect answers to improve calibration and uncertainty estimation. They evaluate their method on a modified version of the MMLU benchmark and demonstrate improved performance (lower expected calibration error, higher AUROC) compared to existing approaches. The error bars represent the standard deviation across three different LLM models and their chat variants.
The figure presents results of calibration and discrimination for different methods of uncertainty estimation on multiple choice and open-ended MMLU question answering datasets. The left panel displays the expected calibration error (ECE) and area under the ROC curve (AUROC) for several methods: zero-shot classifier, sampling, probe, LORA, and LORA+Prompt. The right panel compares the performance of supervised learning with different amounts of training data, showing that 1000 examples achieve nearly the same performance as 20000 examples.

The figure illustrates the challenge of assigning reliable confidence estimates to Large Language Model (LLM) generations. It introduces a method to improve these estimates by fine-tuning the model on a dataset of graded generations, comparing the performance against zero-shot methods and highlighting the improvement in both Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC).
More on tables
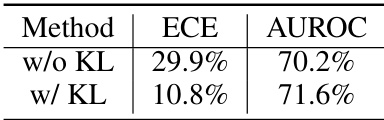
This table presents the results of an ablation study comparing the calibration and area under the receiver operating characteristic curve (AUROC) of a model with and without Kullback-Leibler (KL) divergence regularization. The results show that adding KL divergence regularization significantly improves calibration (lower ECE) while only slightly improving AUROC. The table also notes that the data represents the mean of results over six different base models and refers the reader to Appendix C.1 for further discussion.

This table presents the results of evaluating the performance of different uncertainty estimation methods on a subset of the LiveCodeBench dataset, specifically focusing on LeetCode easy questions. It compares the Expected Calibration Error (ECE), Area Under the Receiver Operating Characteristic curve (AUROC), and accuracy of three different models (LLaMa-2-7B, Mistral-7B, and Mistral-7B-Instruct) using two approaches: Zero-Shot and LoRA + Prompt. The results demonstrate the impact of fine-tuning on the calibration and predictive power of uncertainty estimation, especially highlighting the varying effects across different models.
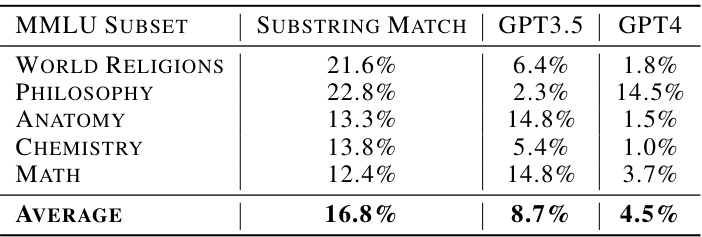
This table compares the accuracy of three different methods for grading the correctness of large language model (LLM) answers against human-provided grades. The methods compared are: (1) Substring Match (checking if the correct answer is a substring of the generated answer), (2) GPT 3.5 Turbo (using a large language model to judge the correctness), and (3) GPT 4 (similar to GPT 3.5 Turbo, but using a more powerful model). The table shows the absolute difference between the accuracy of each method and the human accuracy across different subsets of the MMLU dataset (World Religions, Philosophy, Anatomy, Chemistry, and Math). A lower percentage indicates closer agreement between the method’s grading and human grading, showing better performance by the LLM-based methods compared to the simple substring-matching approach.

This table shows the performance of different methods for estimating uncertainty on the livecodebench_generation_lite dataset, which is a subset of LeetCode easy questions. The table compares the expected calibration error (ECE) and area under the receiver operating characteristic curve (AUROC) for two methods: Zero-Shot Classifier and Lora + Prompt. Accuracy (Acc) is also provided. The results show that using Lora + Prompt consistently improves selective prediction, but its effect on calibration varies depending on the model.
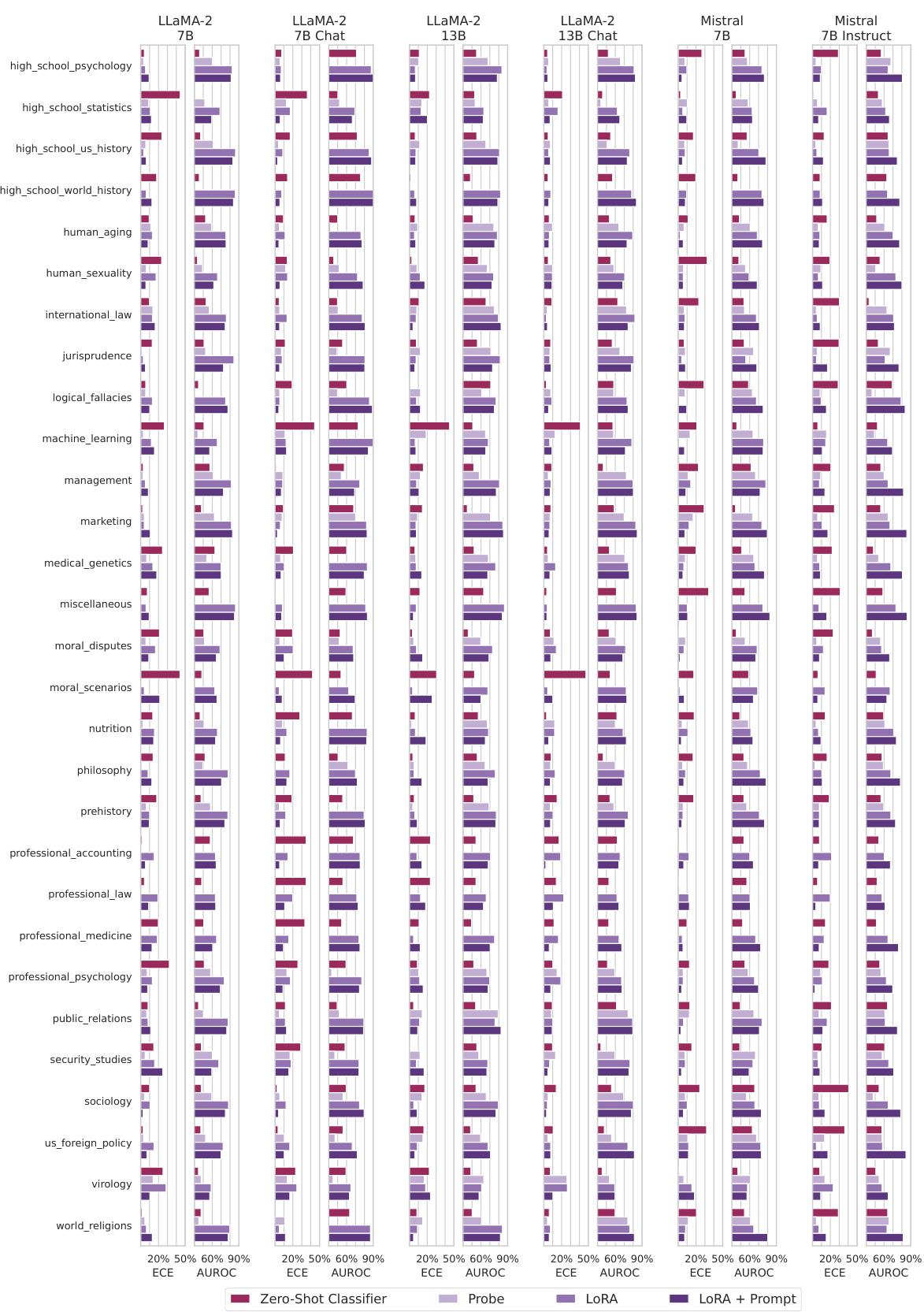
This table presents the performance of different methods for estimating uncertainty in a coding task (LeetCode easy subset). It shows expected calibration error (ECE), Area Under the Receiver Operating Characteristic curve (AUROC), and accuracy (Acc) for three language models: LLaMA-2 7B, Mistral 7B, and Mistral 7B Instruct. Two approaches are compared: zero-shot classification and fine-tuning using LoRA and prompts. The results indicate the impact of supervised training on calibration and selective prediction in this out-of-distribution task.

This table presents the results of evaluating the performance of different uncertainty estimation methods on a subset of LeetCode easy questions. The methods evaluated include zero-shot classifiers, probes, LoRA, and LoRA+Prompt. The metrics used to evaluate performance are expected calibration error (ECE) and area under the receiver operating characteristic curve (AUROC). The table also reports the task accuracy for each method. The results show that supervised training (LoRA + Prompt) generally improves selective prediction but has mixed effects on calibration, depending on the model used.
Full paper#



















