↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current neural network architectures struggle to balance efficiency and performance across diverse tasks. Hybrid approaches integrating convolutional neural networks (CNNs) and transformers aim to combine the strengths of both, but often face design challenges and suboptimal performance. Existing hybrid models frequently approximate attention mechanisms or lack optimized macro-architectures, leading to compromises in speed and accuracy.
AsCAN tackles these issues by introducing a simple yet effective asymmetric architecture. It strategically distributes convolutional and transformer blocks across different network stages, employing more convolutional blocks in earlier stages for spatial feature extraction and more transformer blocks later for global context understanding. This design leads to significant improvements in inference speed and a superior performance-latency trade-off, demonstrated on tasks like image classification, segmentation, and large-scale text-to-image generation. The research also presents a multi-stage training approach that improves training efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and deep learning due to its novel asymmetric architecture that improves the efficiency of hybrid convolutional-transformer networks. It provides a superior trade-off between performance and latency across various tasks and offers insights into optimizing the macro-architecture of hybrid models. The multi-stage training pipeline is also highly relevant for tackling large-scale tasks.
Visual Insights#

This figure showcases example images generated by the AsCAN model. The images demonstrate the model’s capability to produce photorealistic results from detailed and lengthy text prompts, highlighting its effectiveness in text-to-image generation.
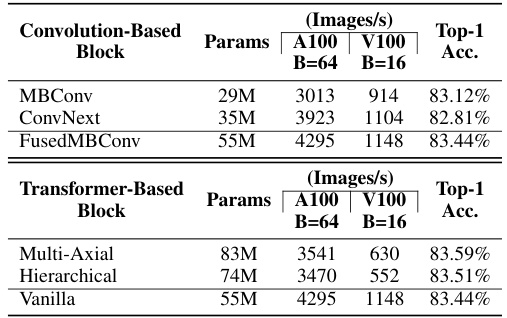
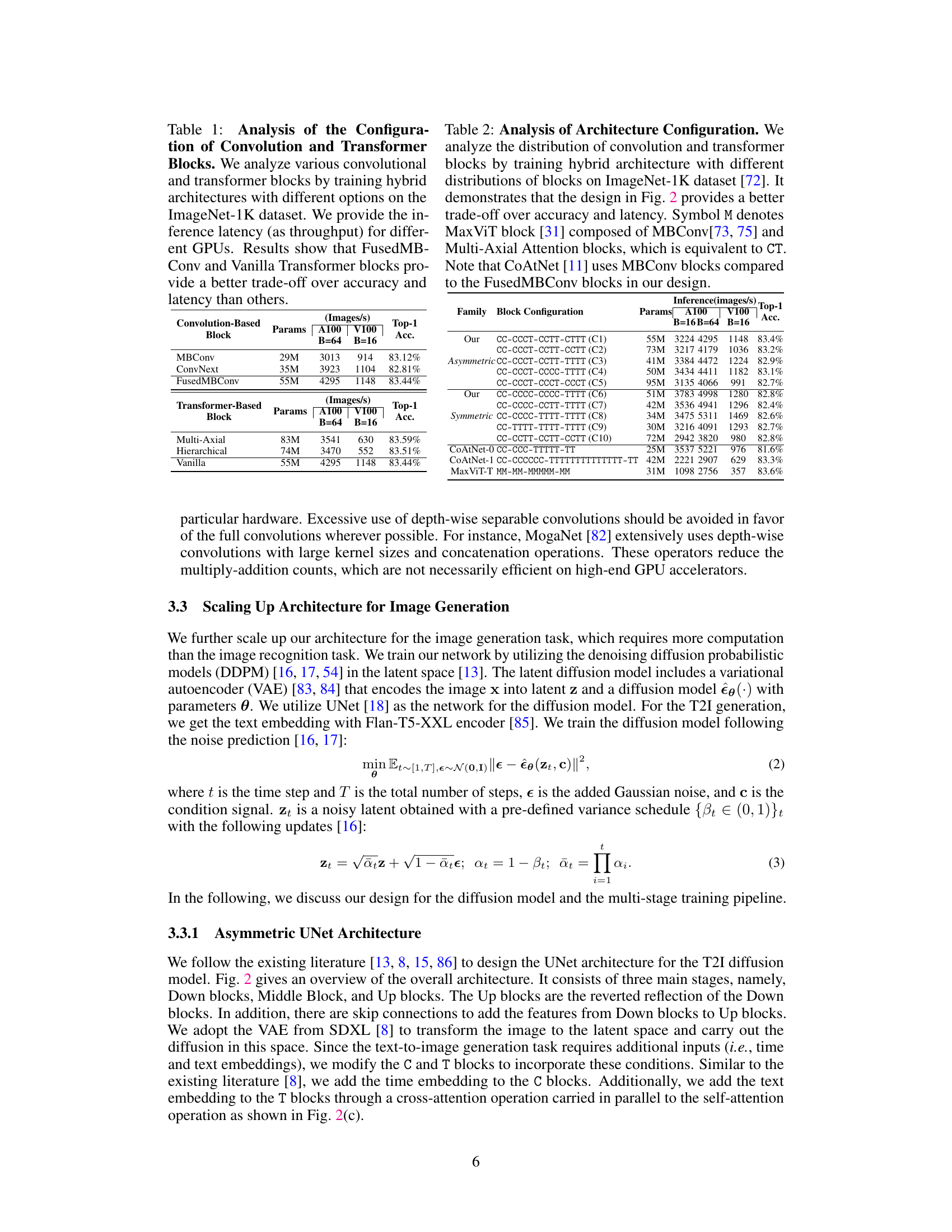
This table presents a comparison of different convolution and transformer blocks used in the AsCAN architecture. The comparison is based on inference latency (throughput) on A100 and V100 GPUs, along with the model’s top-1 accuracy on the ImageNet-1K dataset. The results highlight that FusedMBConv and Vanilla Transformer blocks provide the best balance between accuracy and latency.
In-depth insights#
Asymmetric Hybrids#
Asymmetric hybrid neural network architectures offer a compelling approach to optimizing model performance and efficiency. By strategically combining convolutional and transformer blocks, asymmetric designs deviate from the typical balanced approach, placing more convolutional layers in earlier stages where feature maps are larger, and transitioning to more transformers in later stages for global context processing. This asymmetry is advantageous because convolutional layers excel at processing local spatial information and handling high-resolution data, while transformers excel at modeling long-range dependencies. This arrangement allows for a more efficient trade-off between computational cost and the benefits of both architectures. The effectiveness hinges on the careful distribution of layers to leverage the strengths of each at the appropriate scale and to avoid redundancy. Successful implementation requires rigorous experimentation to determine the optimal asymmetric configuration for a given task and dataset, however, the potential for improved performance and reduced computational demands makes asymmetric hybrids a promising area of future research.
Efficient Tradeoffs#
Efficient tradeoffs in neural network architecture design involve balancing competing objectives like accuracy, computational cost, and memory usage. Asymmetric architectures, like the AsCAN model discussed in the paper, represent a promising approach. By strategically distributing convolutional and transformer blocks, AsCAN aims for the best of both worlds: the spatial processing efficiency of CNNs in earlier layers and the global context modeling capability of transformers in later layers. This asymmetry is key to improving latency and throughput without sacrificing accuracy. The paper highlights how this design can achieve a superior trade-off across various tasks, including image classification, segmentation, and large-scale text-to-image generation. However, the success of AsCAN hinges on appropriately choosing the building blocks and optimally distributing them throughout the network architecture. While the paper demonstrates favorable results, it also acknowledges the need for further exploration regarding optimal configurations and the potential limitations posed by the quadratic computational complexity of standard attention mechanisms. Ultimately, the concept of efficient tradeoffs underscores the importance of a holistic approach to neural architecture design that carefully considers the interplay between multiple design parameters.
Multi-Stage Training#
The concept of “Multi-Stage Training” in the context of large-scale neural network training, particularly for text-to-image models, is a powerful technique to improve efficiency and performance. It involves training a model in phases, starting with a smaller, simpler task or dataset. This initial stage allows for efficient learning of fundamental features and representations, akin to building a strong foundation. Subsequent stages then progressively increase the model’s complexity, incorporating larger datasets or more challenging objectives. This approach offers substantial cost savings by reducing the computational demands of training a massive model from scratch. The iterative nature allows for more focused optimization at each stage, reducing overfitting and enhancing generalization. Furthermore, multi-stage training facilitates the use of different hardware or resources across phases, optimizing cost and leveraging strengths at each stage. However, careful consideration is needed for the selection of suitable initial tasks and the transition between training phases, ensuring seamless integration of knowledge without disrupting learned representations.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a research paper, a well-designed ablation study would isolate the impact of key architectural decisions, such as the asymmetric distribution of convolutional and transformer blocks. By progressively removing or altering these blocks, researchers can demonstrate how each component influences overall performance. For instance, removing all transformer blocks might result in a significant drop in accuracy, indicating their importance for capturing long-range dependencies in the data. Conversely, removing convolutional blocks might lead to decreased efficiency, highlighting their role in processing spatial information effectively. A thorough ablation study not only validates the design choices made but also provides valuable insights into the underlying mechanisms of the model, leading to a more nuanced understanding of its strengths and limitations. The results typically demonstrate the importance of the specific architectural design, showcasing the superiority of the proposed model over alternative architectures and justifying the rationale behind its unique structure.
Future Directions#
Future research could explore several promising avenues. Improving efficiency remains paramount; exploring more efficient attention mechanisms or optimized convolutional operations could dramatically speed up inference. Architectural enhancements such as exploring variations in the asymmetric block distribution or integrating novel architectural components are key. Extending applications to other vision domains, including video processing and 3D vision, would showcase AsCAN’s versatility. Finally, a detailed analysis of the model’s generalization capabilities and robustness across various datasets and image types is essential. Benchmarking against a broader set of state-of-the-art models and rigorous ablation studies can further solidify its advantages.
More visual insights#
More on figures

This figure showcases two different AsCAN architectures. The first is for image classification and illustrates the arrangement of convolutional (C) and transformer (T) blocks in a stem and four stages followed by a pooling and classifier layer. The second is designed for text-to-image generation, which employs a UNet architecture. This variation highlights the use of down and up blocks (mirrored structures), illustrating how the convolutional and transformer modules adapt to handle text embeddings and time-step components, making it different from the classification version.

This figure compares the performance of AsCAN against other state-of-the-art models for ImageNet-1K classification task. It shows that AsCAN achieves a superior trade-off between top-1 accuracy and inference latency (throughput) on both NVIDIA V100 and A100 GPUs. The size of each data point is proportional to the model’s size, providing a visual representation of the model’s complexity relative to its performance.

This figure showcases example images produced by the authors’ text-to-image generation model. The model is designed for efficiency and utilizes an asymmetric architecture (combining convolutional and transformer blocks). The examples highlight the model’s ability to create photorealistic images from lengthy and detailed text prompts.

This figure presents a comparison of the accuracy and inference latency of various state-of-the-art image classification models on the ImageNet-1K dataset. The models include convolutional neural networks (CNNs), vision transformers (ViTs), and hybrid architectures. The proposed AsCAN model demonstrates superior performance in terms of accuracy vs. latency trade-off.
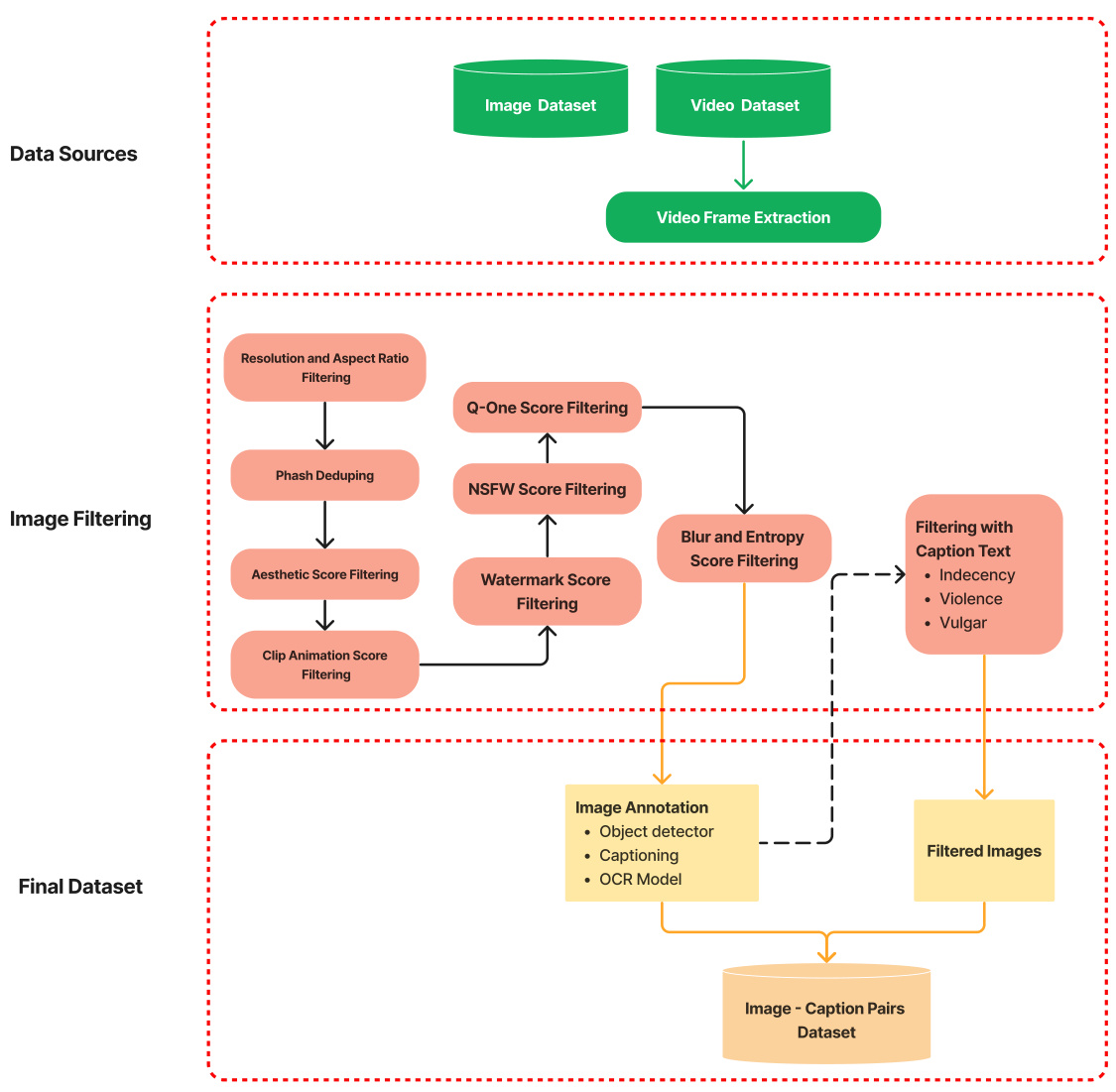
The figure illustrates the detailed steps in creating the text-to-image (T2I) dataset used in the paper. It starts with collecting data from image and video sources. Then, multiple filtering stages are applied to enhance data quality and remove unwanted content. These stages include checks for resolution and aspect ratio, NSFW content, blurriness, watermarks, and whether the image includes text, violence, or other inappropriate elements. After filtering, the images undergo annotation, adding detailed descriptions using an object detection model, captioning model, and OCR (Optical Character Recognition). The final dataset consists of image-caption pairs.
This figure compares the performance of AsCAN against other state-of-the-art image classification models using two metrics: top-1 accuracy and inference latency. It shows that AsCAN consistently achieves a better balance between high accuracy and fast inference speed across different hardware (V100 and A100 GPUs). The size of each point is proportional to the model’s size, offering a visual representation of the performance-to-complexity trade-off.

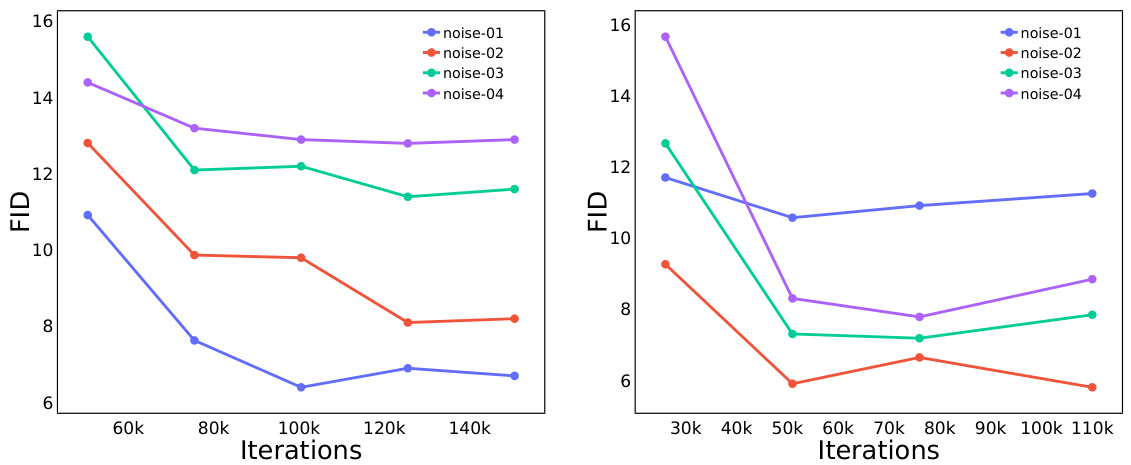
The figure shows the FID scores for 256x256 resolution training of a text-to-image model with and without pre-training on ImageNet-1K. The results indicate that pre-training improves the model’s performance, as measured by FID, especially during the early training iterations.

This figure showcases the capabilities of the AsCAN-based text-to-image generation model. It demonstrates the model’s ability to produce photorealistic images from detailed and lengthy text prompts, highlighting the model’s efficiency and effectiveness in handling complex textual instructions.

This figure showcases example images produced by the AsCAN model, highlighting its ability to create photorealistic images from detailed text descriptions, even lengthy ones.

This figure showcases example images generated by the AsCAN text-to-image model. The model is designed to efficiently produce photorealistic images from detailed, lengthy text descriptions (prompts). The images demonstrate the model’s capacity to capture intricate details and adhere closely to the input prompt.

This figure showcases the capabilities of the AsCAN model in generating photorealistic images from detailed text prompts. The examples illustrate the model’s ability to create images of diverse subjects and scenes that are visually accurate and closely match the textual description. This demonstrates its strength in text-to-image generation.

This figure showcases the capabilities of the AsCAN-based text-to-image model. It highlights the model’s ability to generate photorealistic images from detailed and lengthy text prompts, demonstrating the effectiveness of the asymmetric architecture in achieving high-quality image generation.

This figure illustrates the AsCAN architecture used for both image classification and text-to-image generation. Part (a) shows the basic convolutional and transformer blocks, as well as the four-stage architecture for image classification. Part (b) shows how this is adapted into a U-Net architecture for image generation. Finally, part (c) details the specific blocks used within the U-Net, highlighting the differences from the classification architecture.

This figure showcases example images generated by the AsCAN model, highlighting its ability to produce photorealistic images from detailed text prompts. The image generation is efficient due to the model’s asymmetric architecture, which is a key contribution of the paper.
More on tables
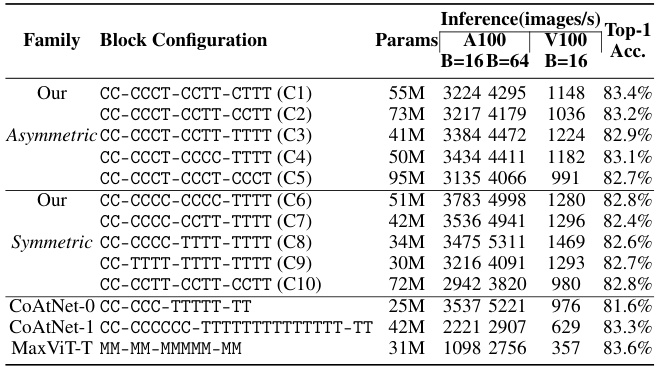
This table presents an ablation study on different configurations of convolutional and transformer blocks in a hybrid architecture for ImageNet-1K classification. It compares various arrangements of these blocks (asymmetric vs symmetric, number of blocks per stage) in terms of their performance (top-1 accuracy), inference throughput on A100 and V100 GPUs, and model size (parameters). The results demonstrate that the asymmetric configuration proposed in the paper offers superior performance and latency trade-offs.
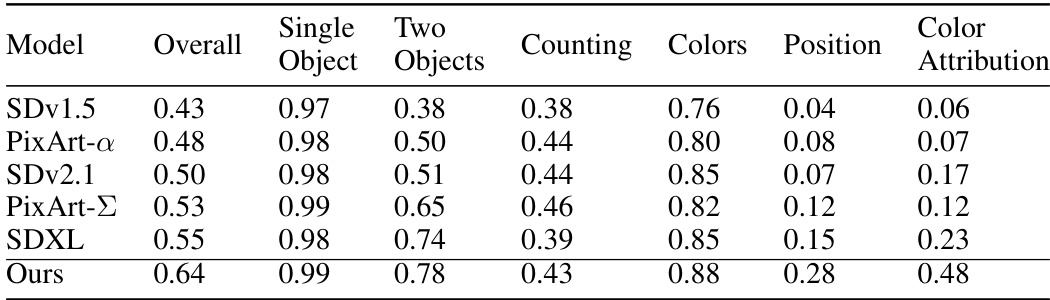
This table presents the GenEval scores for various text-to-image (T2I) models, including the proposed AsCAN model and several baselines. GenEval is a benchmark that evaluates different aspects of image generation, such as the accuracy of object counting, color and position recognition, and color attribution. The table shows that the AsCAN model outperforms the other methods across all metrics, indicating its superior performance in generating images that align well with the textual descriptions.
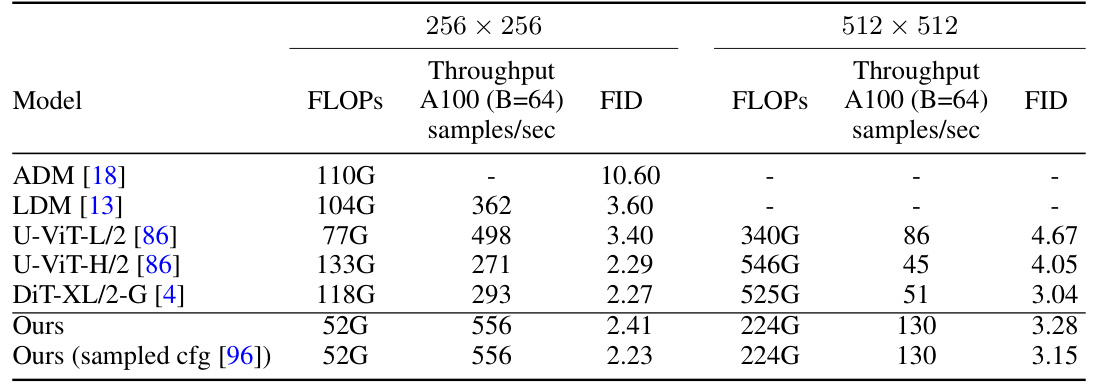
This table compares the performance of the proposed AsCAN architecture against other state-of-the-art models for class-conditional image generation on the ImageNet-1K dataset. The comparison is made at two different resolutions (256x256 and 512x512). Key metrics include the number of floating-point operations (FLOPs), throughput (samples per second on an A100 GPU with a batch size of 64), and the Fréchet Inception Distance (FID), which measures the quality of the generated images.

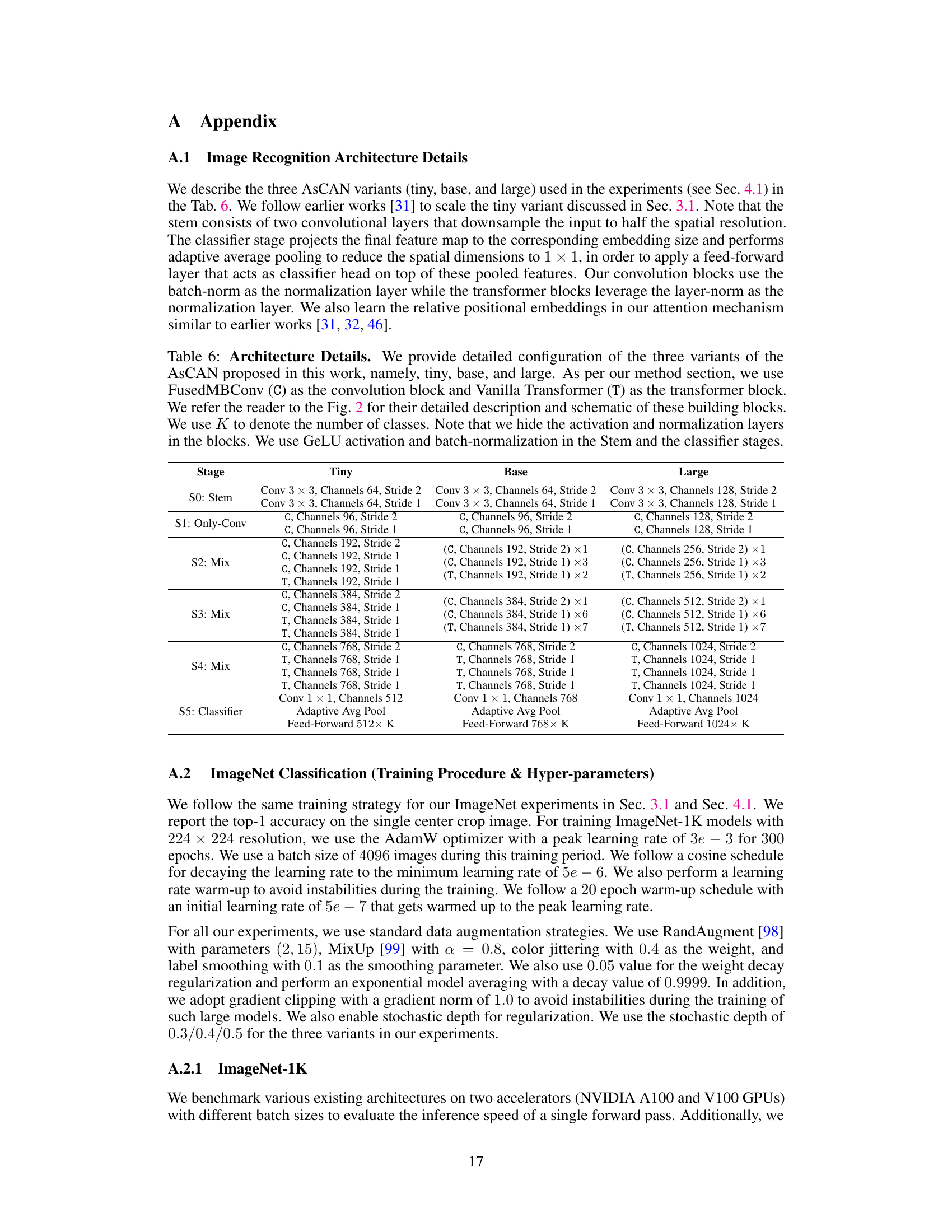
This table compares the performance of the proposed AsCAN architecture against various state-of-the-art baselines on the ImageNet-1K classification task. It shows the inference throughput (images per second) for different batch sizes (B=1, 16, 64) on both A100 and V100 GPUs. The metrics reported include model parameters, multiply-accumulate operations (MACs), and top-1 accuracy. The results highlight the superior throughput and accuracy trade-offs achieved by the AsCAN architecture compared to other convolutional, transformer, and hybrid architectures.

This table compares the performance of different CNN architectures on the ImageNet-1K image classification task. The table shows the throughput (images per second) on A100 and V100 GPUs for various batch sizes (1, 16, 64) for each architecture, and their top-1 accuracy. It highlights the performance and speed of the proposed AsCAN architecture against a variety of state-of-the-art convolutional and transformer-based networks.

This table compares the performance of the proposed AsCAN architecture with several state-of-the-art baselines on the ImageNet-1K image classification task. It presents inference latency (measured as throughput in images per second) on both A100 and V100 GPUs for various batch sizes (B=1, B=16, B=64), along with the top-1 accuracy and model parameters (Params) and Multiply-Accumulate operations (MACs) for each model. The table highlights the superior performance and latency trade-offs achieved by AsCAN compared to other models.
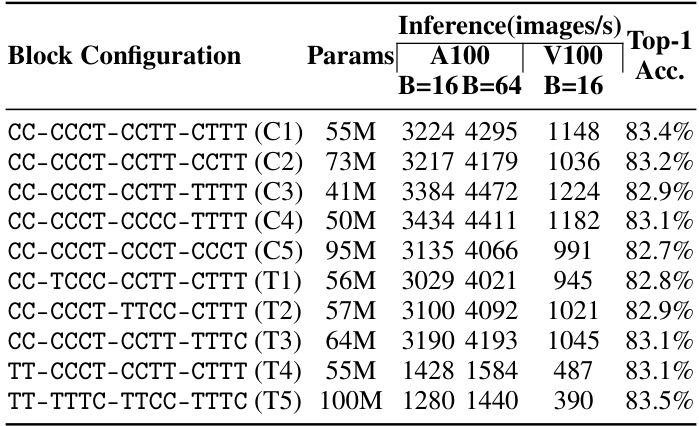
This table shows the ablation study on the architecture design by changing the order of convolutional and transformer blocks within stages. The results demonstrate that using convolutional blocks (C) before transformer blocks (T) leads to better performance in terms of accuracy and throughput.
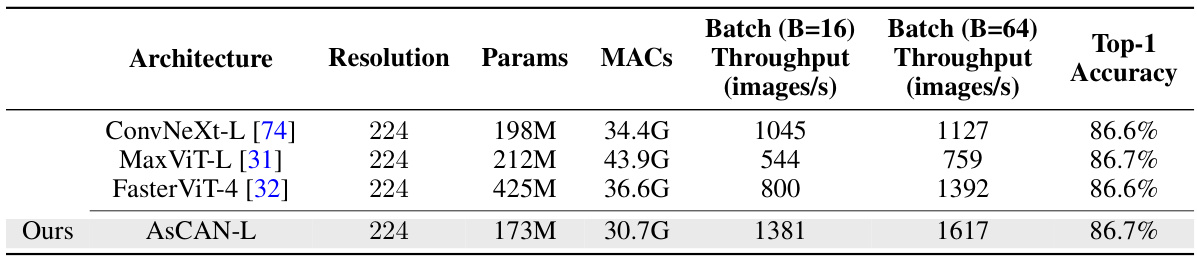
This table compares the performance of the proposed AsCAN architectures with various other state-of-the-art models on the ImageNet-1K image classification task. It shows the throughput (images per second) achieved by each model on both A100 and V100 GPUs with batch sizes of 1, 16, and 64, along with their Top-1 accuracy. The results highlight the superior performance and latency trade-offs of the AsCAN models.

This table compares the performance of different backbones (Swin-T, FasterViT-2, ASCAN-T, Swin-S, FasterViT-3, ASCAN-B, Swin-B, FasterViT-4, and ASCAN-L) on the ADE20K semantic segmentation dataset using the UPerNet architecture. It presents the latency (in frames per second) on A100 and V100 GPUs, the number of parameters, the number of multiply-accumulate operations (MACs), and the mean Intersection over Union (mIoU) achieved by each backbone.
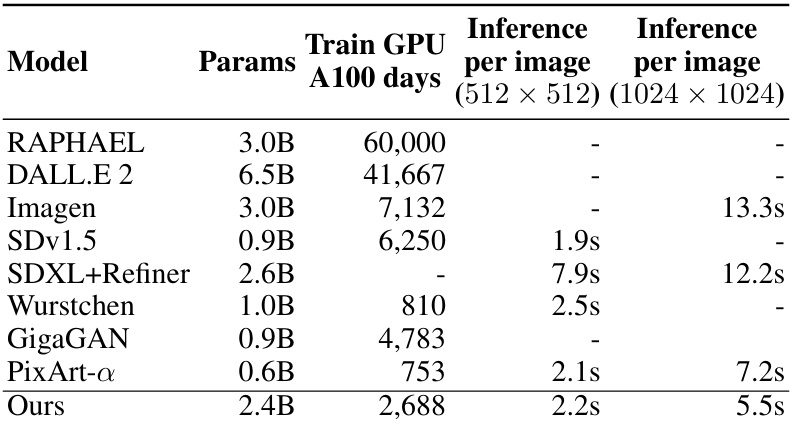
This table compares the training time (in A100 GPU days), the number of parameters, and the inference time per image (at 512x512 and 1024x1024 resolutions) for several text-to-image generation models, including the authors’ model. It highlights the computational resource requirements of different approaches, showcasing the relative efficiency of the proposed model.
Full paper#