↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
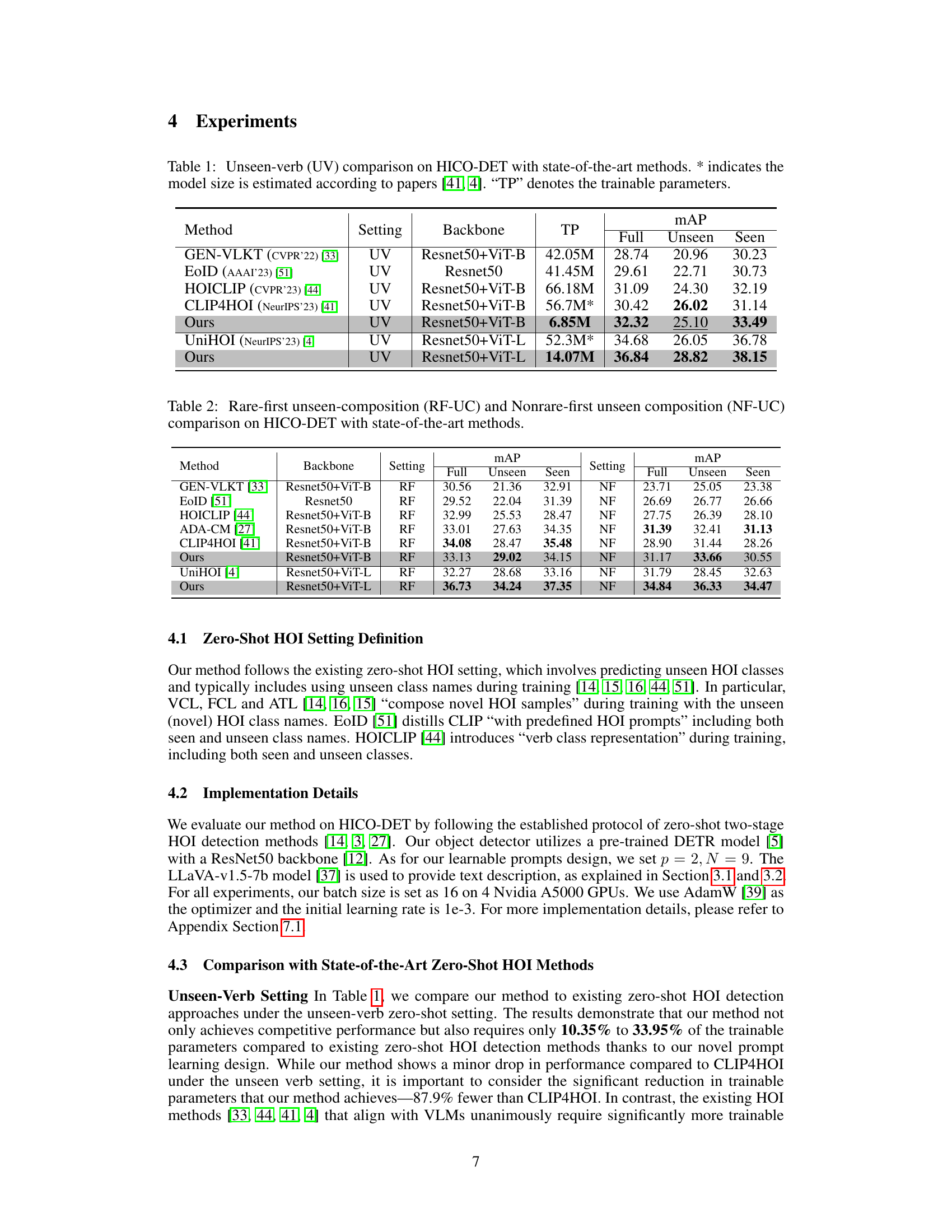
TL;DR#
Human-Object Interaction (HOI) detection faces challenges in zero-shot settings where models encounter unseen classes. Existing methods that directly align visual encoders with large Vision-Language Models (VLMs) are computationally expensive and prone to overfitting. Prompt learning offers an alternative, but existing approaches often lead to poor performance on unseen classes.
This paper introduces EZ-HOI, an efficient framework addressing these issues. EZ-HOI uses a novel prompt learning approach guided by LLMs and VLMs. It leverages information from related seen classes to learn effective prompts for unseen classes, minimizing overfitting. The results demonstrate that EZ-HOI achieves state-of-the-art performance with significantly fewer parameters, showing improved efficiency and effectiveness in zero-shot HOI detection.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in zero-shot learning and visual language models because it presents EZ-HOI, a novel and efficient framework achieving state-of-the-art performance. Its emphasis on prompt learning with foundation models, addresses the limitations of existing methods. This opens up new avenues for research in efficient VLM adaptation and zero-shot HOI detection, particularly its focus on unseen class handling, which is a significant challenge in this field. The code availability further enhances its impact, making it a valuable resource for the research community.
Visual Insights#
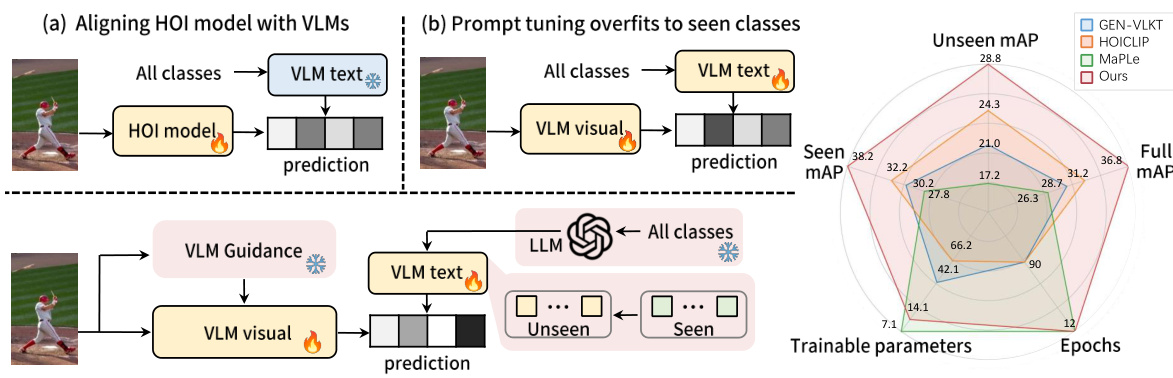
This figure compares three different approaches for zero-shot human-object interaction (HOI) detection. (a) shows traditional methods aligning HOI models with pre-trained Vision-Language Models (VLMs). (b) illustrates prompt tuning, an alternative approach where VLMs are adapted for HOI tasks. This often overfits to seen classes. (c) presents the authors’ proposed method, EZ-HOI, which efficiently adapts VLMs using a novel prompt learning approach. (d) provides a quantitative comparison of the three approaches on the HICO-DET dataset, highlighting EZ-HOI’s superior performance and efficiency in terms of trainable parameters and training epochs.
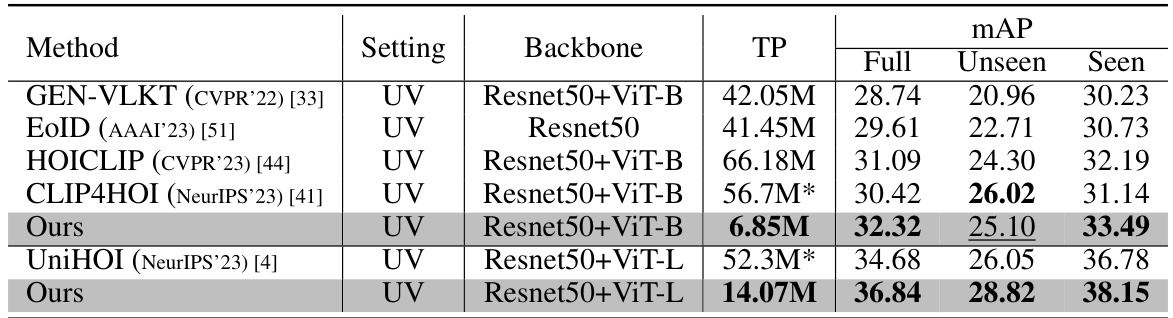
This table compares the performance of different zero-shot HOI detection methods on the HICO-DET dataset, specifically focusing on the unseen-verb setting. It shows the mean average precision (mAP) for full, unseen, and seen verb categories. The table also lists the backbone network architecture used by each method and the number of trainable parameters (TP). The asterisk (*) indicates that the model sizes for some methods are estimated based on information from the cited papers.
In-depth insights#
Zero-Shot HOI#
Zero-shot Human-Object Interaction (HOI) detection presents a significant challenge in computer vision, demanding that models accurately identify interactions between humans and objects without prior exposure to specific interaction classes. This requires robust generalization capabilities, going beyond simple visual feature matching. Existing approaches often focus on aligning visual encoders with large Vision-Language Models (VLMs) to leverage their extensive knowledge. However, this usually involves computationally expensive model training and potential overfitting to seen classes. Prompt learning, a more efficient technique, adapts VLMs for HOI tasks via fine-tuning a small set of parameters. But even prompt learning faces challenges, frequently resulting in suboptimal performance on unseen interactions because of the lack of unseen class labels in training data. The focus needs to shift to methods that effectively transfer knowledge from seen to unseen interactions, thus improving prompt learning’s generalization abilities for true zero-shot capability. Addressing this overfitting is crucial, enabling more efficient and effective zero-shot HOI systems.
Prompt Tuning#
Prompt tuning, a core technique in adapting large vision-language models (VLMs), involves modifying the input prompts rather than directly retraining the model. This reduces computational cost and training time significantly compared to full model fine-tuning. The method’s effectiveness relies on the VLM’s pre-existing knowledge; well-crafted prompts effectively guide the VLM towards desired tasks, making it particularly valuable for zero-shot scenarios where labeled data for new classes is scarce. However, prompt engineering can be challenging and requires careful design to elicit optimal performance. The choice of prompt structure, tokenization, and the inclusion of auxiliary information are all critical factors determining success. Furthermore, overfitting to seen classes during prompt tuning remains a potential issue, particularly impacting performance on unseen classes. Therefore, effective prompt tuning necessitates not only creative prompt design but also sophisticated techniques to address overfitting, potentially via regularization or data augmentation strategies. Careful selection and integration of foundation models (like LLMs) can further improve the quality of prompts and enhance model generalization to unseen inputs.
VLM Adaptation#
The concept of ‘VLM Adaptation’ in the context of zero-shot HOI detection involves modifying pre-trained Vision-Language Models (VLMs) to effectively perform the specific task of identifying human-object interactions without requiring explicit training data for each interaction class. The core challenge lies in adapting the broad knowledge base of a VLM to a more focused and nuanced task. This often requires techniques like prompt learning, which uses carefully crafted textual prompts to guide the VLM’s understanding of the visual input and the desired interactions. A key aspect of successful VLM adaptation is mitigating overfitting to seen data, a problem that arises when the model fine-tunes too heavily on the available labeled examples. The authors likely address this by using strategies that encourage generalization to unseen data, perhaps by leveraging information from related seen classes or by employing regularization techniques. Successfully adapting VLMs for zero-shot HOI detection hinges on the ability to leverage their existing knowledge while simultaneously avoiding the pitfall of overspecialization on limited training data, making effective prompt engineering crucial.
UTPL Module#
The UTPL (Unseen Text Prompt Learning) module is a crucial innovation addressing the challenge of zero-shot HOI (Human-Object Interaction) detection. Standard prompt learning methods often overfit to seen classes due to a lack of unseen class labels during training. UTPL cleverly leverages information from related seen classes to guide the learning of prompts for unseen classes. This is achieved by first identifying semantically similar seen classes to each unseen class using cosine similarity of their text embeddings, generated by an LLM (Large Language Model). Crucially, the UTPL module further incorporates disparity information from the LLM, highlighting the key differences between the unseen and related seen classes, thereby preventing overfitting and improving generalization to unseen interactions. This approach demonstrates the power of integrating foundation models to effectively adapt VLMs (Vision-Language Models) for zero-shot learning tasks and obtain enhanced performance.
Future of EZ-HOI#
The future of EZ-HOI hinges on addressing its current limitations and exploring new avenues for improvement. Scaling EZ-HOI to handle larger datasets and more complex HOI scenarios is crucial. This might involve investigating more efficient training techniques or exploring alternative architectures that are better suited to handling high-dimensional data. Improving the model’s generalization capabilities to unseen classes and compositions is another key area for future work. This could involve incorporating more robust methods for knowledge transfer from foundation models or developing novel prompt engineering strategies. Furthermore, exploring different modalities of input, such as incorporating 3D information from depth sensors, could lead to significant gains in performance. Finally, addressing the ethical concerns of HOI detection systems is crucial to ensure responsible technology development and deployment. Researching bias mitigation techniques and establishing guidelines for fair and transparent use will be essential for building trustworthy and beneficial HOI systems.
More visual insights#
More on figures
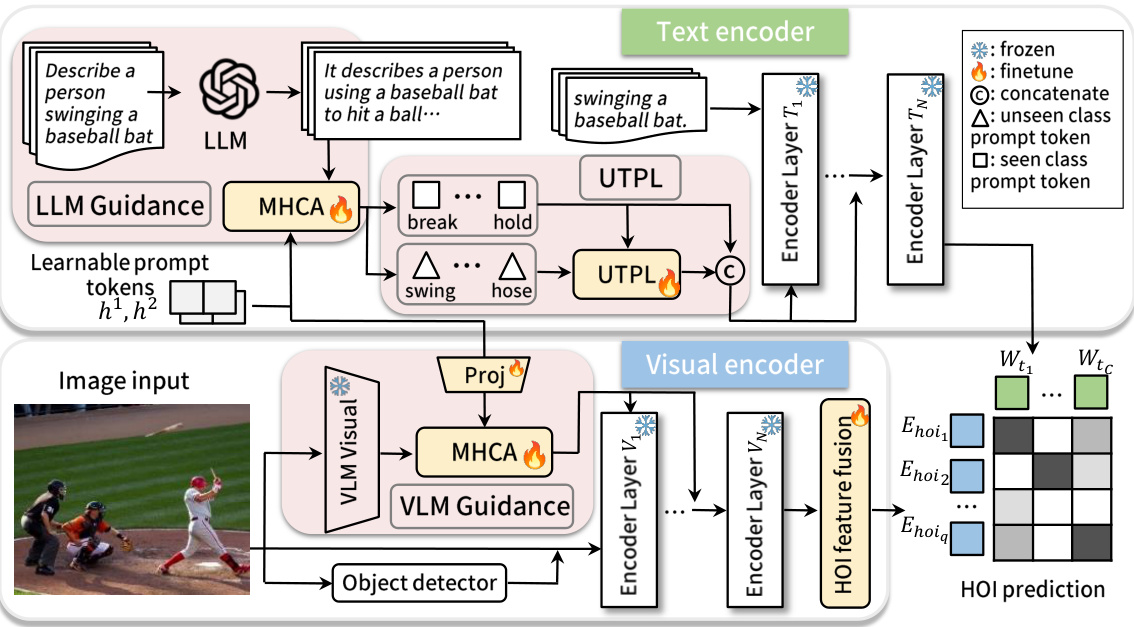
This figure illustrates the EZ-HOI framework’s architecture. It shows how learnable text and visual prompts are generated and used, with guidance from LLMs and VLMs respectively. The UTPL module is highlighted to show how unseen prompts are learned. The final prediction is made through multi-head cross-attention and cosine similarity.
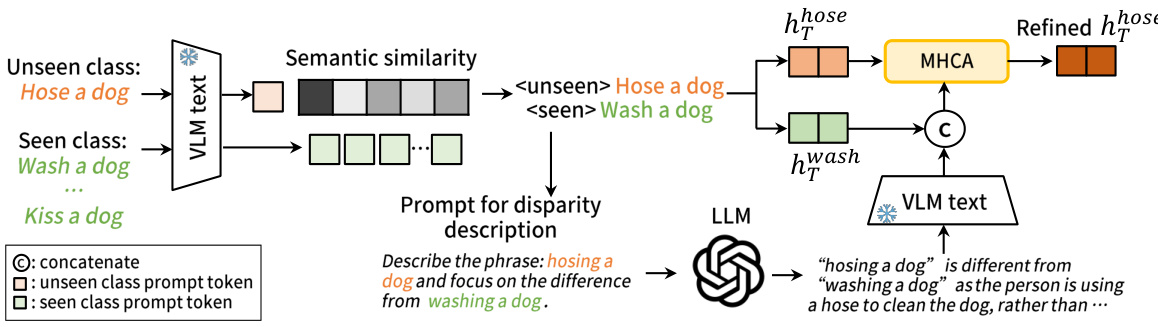
This figure details the Unseen Text Prompt Learning (UTPL) module. The UTPL module addresses the challenge of adapting Vision-Language Models (VLMs) to unseen Human-Object Interaction (HOI) classes by leveraging information from related seen classes. It uses cosine similarity to find the most similar seen class to an unseen class, then queries a Large Language Model (LLM) to highlight the differences between the seen and unseen classes. This disparity information, along with the prompt for the similar seen class, is then used to refine the prompt for the unseen class via Multi-Head Cross-Attention (MHCA).
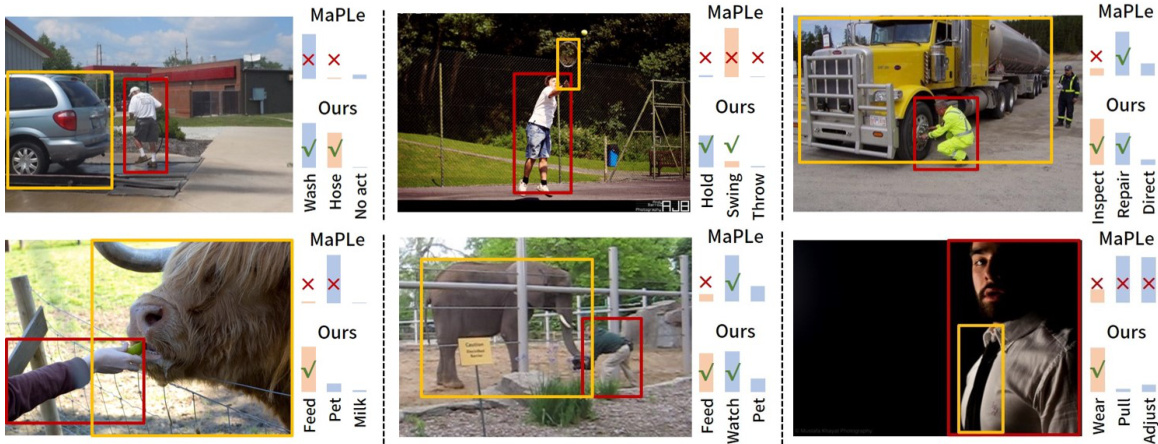
This figure compares the zero-shot human-object interaction (HOI) detection performance of the proposed EZ-HOI method against the MaPLe baseline. The images show various scenes containing HOI instances. For each image, both methods’ predictions are displayed, with correct predictions marked by a green checkmark and incorrect predictions marked by a red ‘X’. The orange color highlights predictions of unseen HOI classes, while blue indicates predictions of seen classes. The bar charts provide a visual comparison of the methods’ performance for each image.
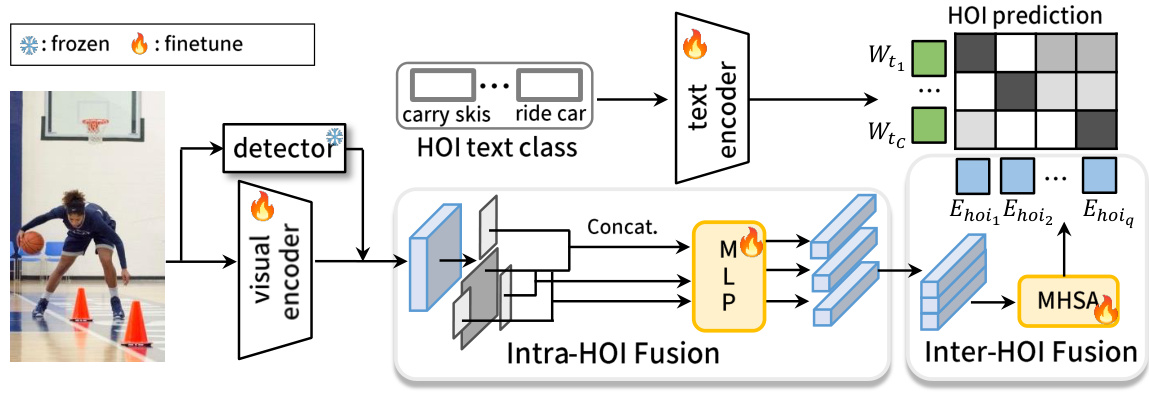
This figure illustrates the EZ-HOI framework’s architecture. It shows how learnable text prompts, guided by an LLM, capture detailed HOI class information. The UTPL module enhances the generalization of these prompts. Visual prompts are guided by a frozen VLM visual encoder. Both text and visual prompts are fed into their respective encoders, and final HOI predictions are generated based on the cosine similarity between text encoder outputs and HOI image features.

This figure compares three different approaches to zero-shot human-object interaction (HOI) detection: (a) aligning an HOI model with a Vision-Language Model (VLM), (b) prompt tuning to adapt the VLM to HOI tasks, and (c) the authors’ proposed method, EZ-HOI. It highlights the limitations of existing methods, such as high computational cost and overfitting to seen classes. The figure shows that EZ-HOI achieves state-of-the-art performance with significantly fewer parameters and training epochs. The performance comparison uses mean average precision (mAP) across unseen, seen, and all classes in the HICO-DET dataset.

This figure illustrates the EZ-HOI framework, highlighting the use of learnable text and visual prompts guided by LLMs and VLMs. The UTPL module addresses the challenge of unseen classes. The framework incorporates multi-head cross-attention (MHCA) for integrating information and generating HOI predictions.
More on tables
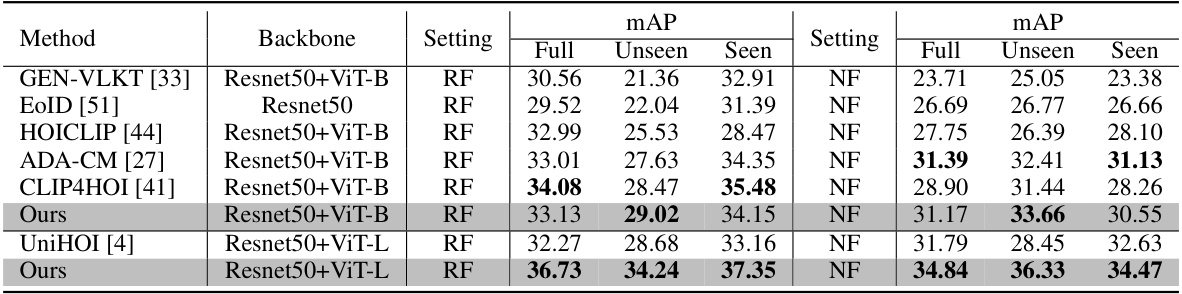
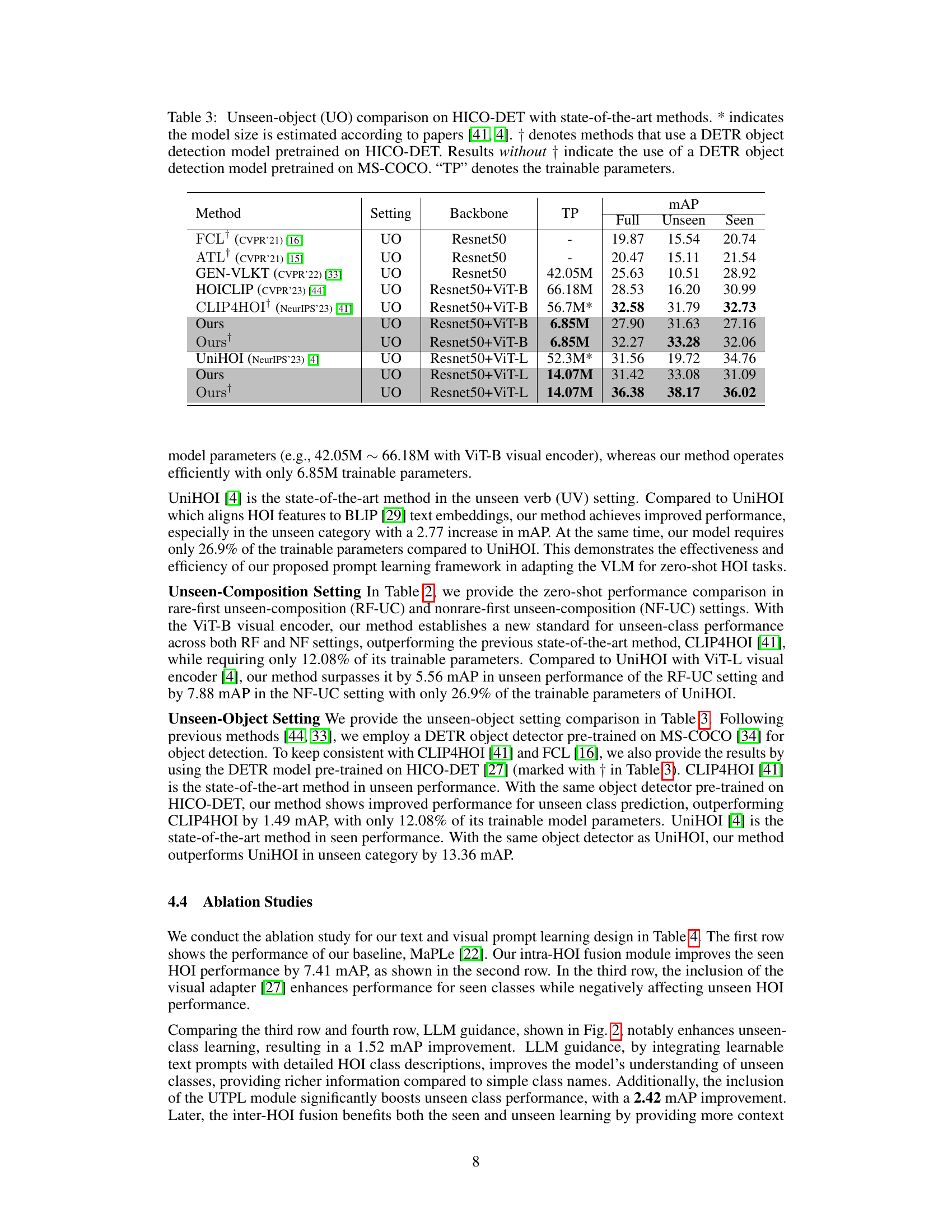
This table compares the performance of the proposed EZ-HOI method against other state-of-the-art methods on the HICO-DET dataset for two different zero-shot settings: Rare-first unseen composition (RF-UC) and Nonrare-first unseen composition (NF-UC). The comparison includes the mean Average Precision (mAP) scores for the full dataset, unseen classes, and seen classes, providing insights into the model’s ability to generalize to unseen data and handle different types of unseen compositions. The backbone network used is also specified for each method.
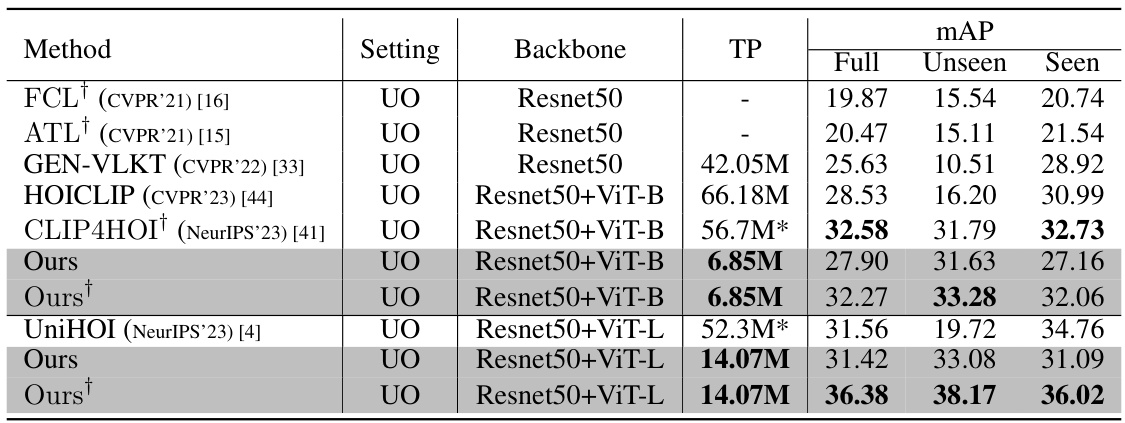
This table compares the performance of different methods on the unseen-object (UO) zero-shot setting of the HICO-DET dataset. It shows the mean average precision (mAP) achieved by various methods, broken down into full mAP, unseen mAP, and seen mAP. The table also includes the backbone network used by each method, the number of trainable parameters (TP), and notes which methods used a DETR object detector pre-trained on HICO-DET versus MS-COCO. The ‘Ours’ rows represent the proposed EZ-HOI model with different configurations.
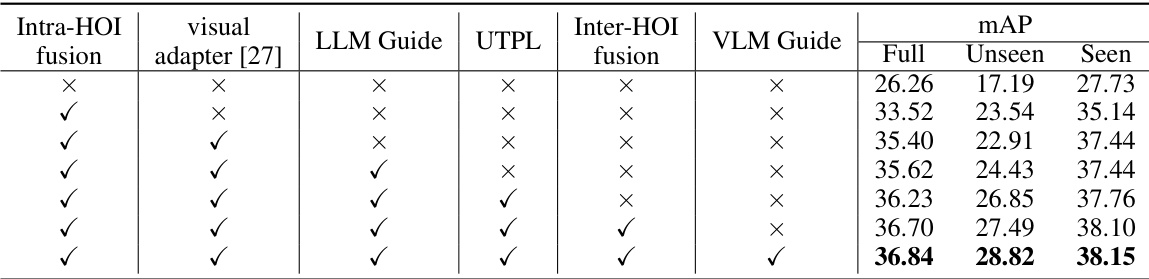
This ablation study analyzes the impact of different components of the EZ-HOI model on the zero-shot unseen verb setting of the HICO-DET dataset. It shows the effect of including or excluding: Intra-HOI fusion, the visual adapter [27], LLM guidance, UTPL, Inter-HOI fusion, and VLM guidance. The results are presented in terms of mean average precision (mAP) for the full dataset, unseen classes, and seen classes. This table helps to understand the contribution of each module to the overall performance, particularly in handling unseen data.

This table compares the performance of different prompt learning methods for zero-shot unseen verb Human-Object Interaction (HOI) detection on the HICO-DET dataset. It shows the mean average precision (mAP) across three different settings: Full (overall performance), Unseen (performance on unseen verb-object combinations), and Seen (performance on seen verb-object combinations). The methods compared are CLIP [47], MaPLe [22], MaPLe with a visual adapter [27], and the proposed EZ-HOI method. The results demonstrate the improved performance of EZ-HOI in all categories, especially for unseen HOI classes.

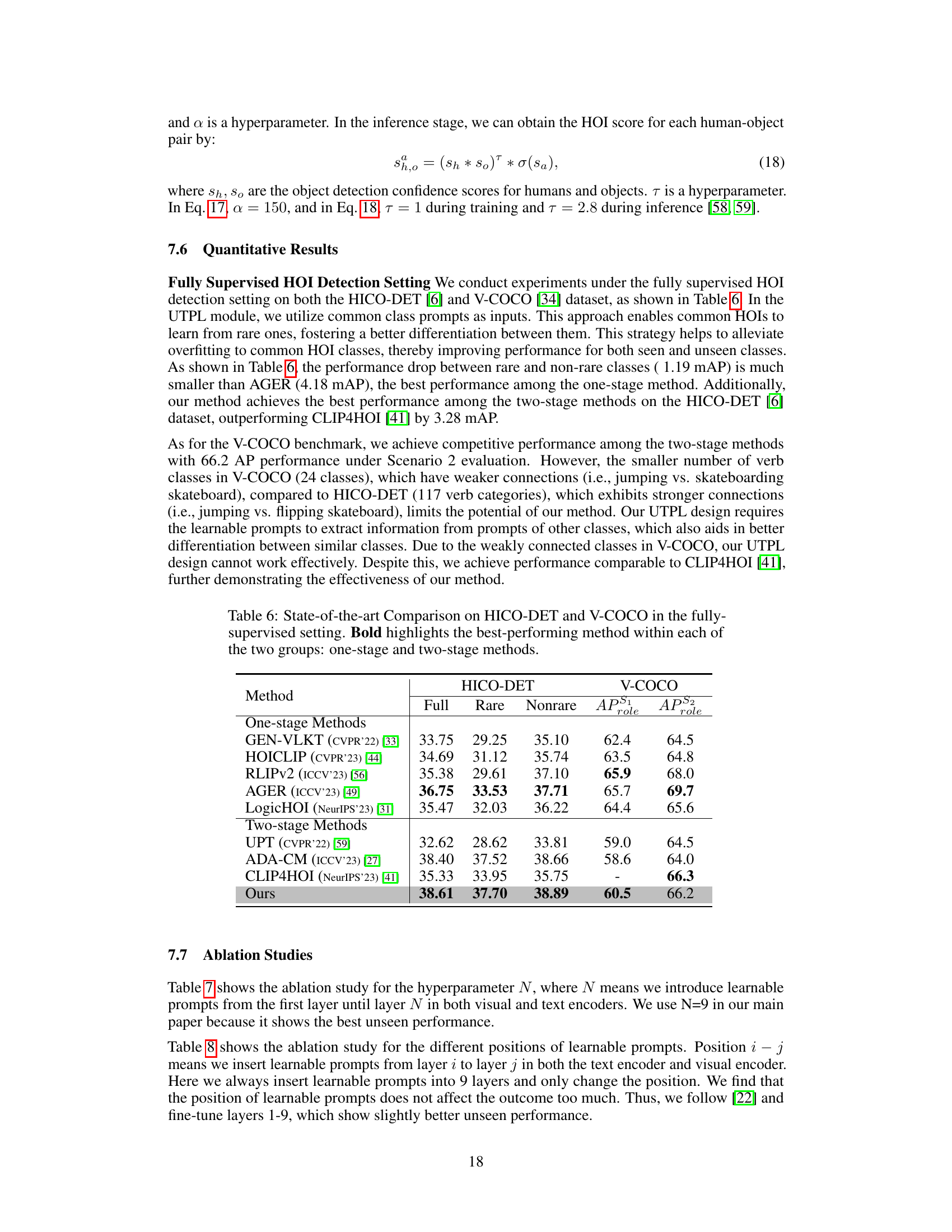
This table compares the performance of the proposed EZ-HOI method against other state-of-the-art methods on two benchmark datasets: HICO-DET and V-COCO. The comparison is done in a fully supervised setting (not zero-shot). The table shows the mean Average Precision (mAP) scores across different evaluation metrics (Full, Rare, Nonrare for HICO-DET and APs1, APs2 for V-COCO), highlighting the EZ-HOI’s superior performance, especially when compared to other two-stage methods.
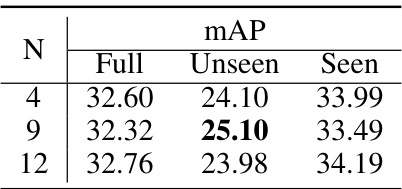
This table presents the results of an ablation study investigating the impact of the hyperparameter N on the performance of the EZ-HOI model in the unseen-verb zero-shot setting. The hyperparameter N determines the number of transformer layers in both the text and visual encoders that are fine-tuned during the prompt learning process. The table shows that using N=9 yields the best performance on the unseen classes, balancing between optimizing for unseen and seen classes.
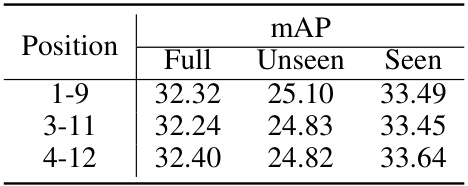
This ablation study investigates the impact of varying the number of layers (N) in the text and visual encoders on the model’s performance. The results are shown for the full, unseen, and seen mAP metrics. The study aims to determine the optimal number of layers for incorporating learnable prompts to enhance the zero-shot HOI detection.
Full paper#