↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current visual text generation methods primarily use ControlNet with standard font text images for control, often overlooking the nuanced role of control information at different stages and its unique properties compared to other control inputs. This paper investigates this critical role from three perspectives: input encoding, role at different stages, and output features, revealing distinct characteristics of text-based control information.
To address these issues, the authors propose TextGen, a novel framework that optimizes control information. They improve input features using Fourier analysis and introduce a two-stage generation framework to align control information’s varied roles at different stages. The output features are enhanced via frequency balancing. TextGen demonstrates state-of-the-art performance in both Chinese and English text generation using a novel, lightweight dataset, showing that careful consideration of control information at each step leads to significant improvements in quality. The code and dataset are publicly available.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on visual text generation and editing. It significantly advances understanding of how control information influences generation quality, offering insights into optimizing this crucial aspect and opening new avenues for improved models. The proposed methods and lightweight dataset are valuable resources for the research community. The unified framework for generation and editing is particularly impactful.
Visual Insights#
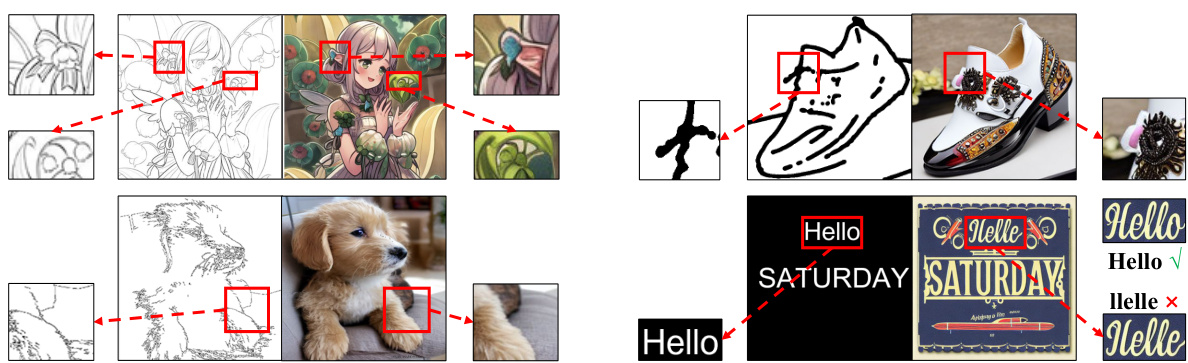
This figure showcases the differences between text control information used in visual text generation and other general control information used in ControlNet. It highlights how general controls, such as Canny edges or line drawings, focus on the overall structure of an image, allowing for minor errors in detail. In contrast, text control requires much more precise detail, as even small inaccuracies can result in unreadable or incorrect text.
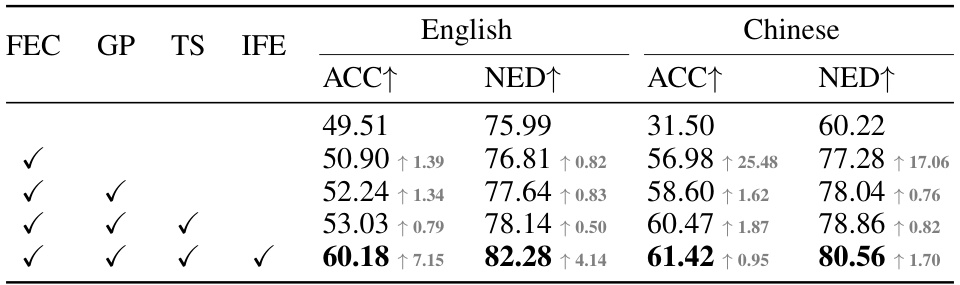
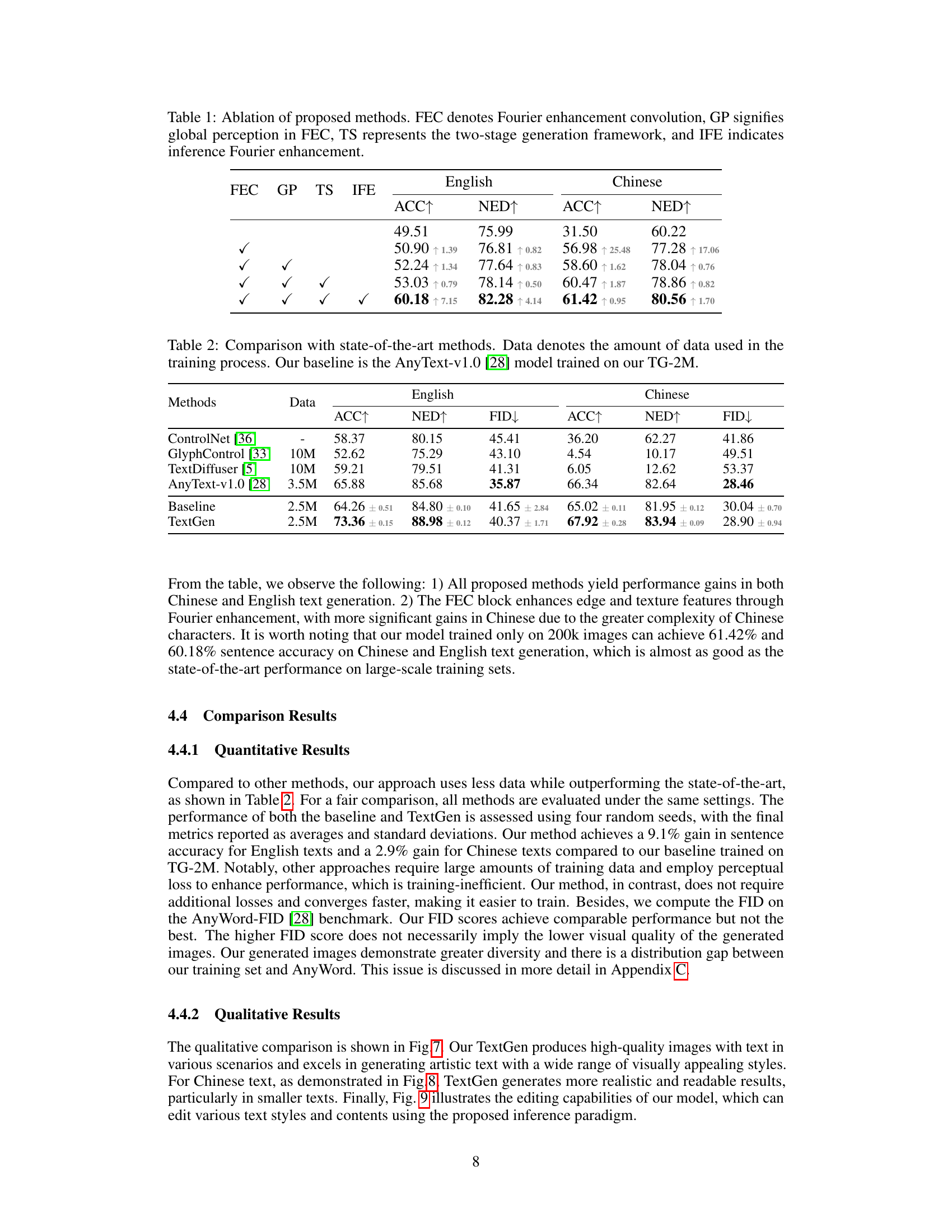
This table presents the ablation study results of the proposed TextGen model. It shows the impact of each component (FEC, GP, TS, IFE) on the performance of both English and Chinese text generation tasks, measured by ACC (accuracy) and NED (normalized edit distance). The results demonstrate the effectiveness of each component in improving the overall performance of the model.
In-depth insights#
ControlNet’s Impact#
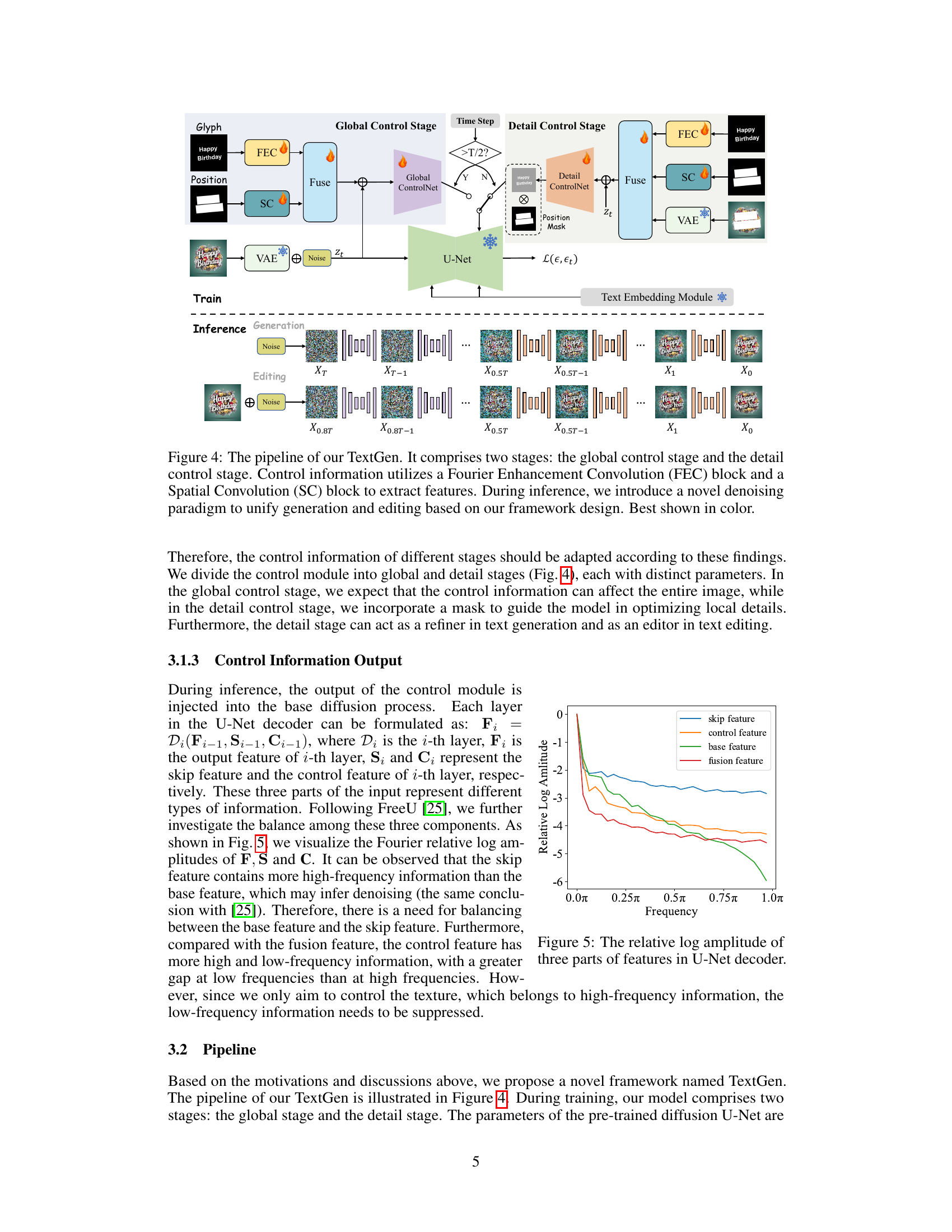
ControlNet’s impact on visual text generation is multifaceted and significant. Its introduction enabled flexible multilingual text generation and precise control over text position, which were previously challenging. ControlNet’s primary contribution is its ability to effectively integrate external control information into the diffusion process, influencing the generation of high-quality images with readable and realistic text. This significantly improved upon previous methods that struggled with fine-grained text control and accuracy. However, ControlNet’s reliance on global glyph images as control input reveals limitations. These glyph images have unique properties (high information density in specific regions, and challenging extraction of fine-grained features) that affect the overall performance and require further optimization. The challenge lies in balancing the high-density regions of information against the need to accurately generate overall structure and style. This necessitates improvements to both input encoding and output control features, as explored in the TextGen framework. By carefully considering these aspects, researchers can leverage the strengths of ControlNet while mitigating its limitations to produce even higher-quality and more diverse visual text outputs. The use of Fourier analysis for input and output features, along with a two-stage generation approach for better alignment of control information at different stages, are key innovations to enhance the overall effectiveness of this critical technology.
TextGen Framework#
The TextGen framework, as described, appears to be a novel approach to visual text generation and editing. Its core innovation lies in its three-pronged optimization of control information: input enhancement using Fourier analysis to emphasize relevant features, output refinement via frequency balancing to harmonize different feature components, and a two-stage generation process (global and detail) to effectively manage control information at various stages of the diffusion process. This addresses weaknesses in prior methods that relied on simpler, less nuanced handling of control information, particularly in multilingual settings. The Fourier Enhancement Convolution (FEC) block is key to extracting pertinent features from the glyph image. The two-stage framework, moving from coarse to fine-grained control, enhances both accuracy and flexibility. Finally, a novel inference paradigm unifies generation and editing, making the framework more versatile. The choice of a lightweight training dataset further suggests a focus on efficiency and potentially broader applicability. Overall, TextGen presents a significant advancement by directly tackling the limitations of existing ControlNet-based approaches, highlighting a more sophisticated understanding of the interaction between control information and the generation process.
Multi-lingual TextGen#
A hypothetical research paper section titled “Multi-lingual TextGen” would likely explore the challenges and advancements in generating and editing images containing text across multiple languages. The core of the work would probably center around improving the accuracy and quality of text rendering within images, especially considering the complexities introduced by varying character sets, scripts, and typographic conventions of different languages. The research might delve into novel techniques for handling multilingual control information, possibly employing advanced encoding schemes, enhanced attention mechanisms, or advanced fusion strategies to integrate textual data with visual features effectively. Cross-lingual transfer learning, where knowledge gained from training on high-resource languages is transferred to low-resource ones, would be a potentially valuable area of investigation. The effectiveness of different diffusion model architectures and training strategies for multilingual text generation, along with quantitative and qualitative evaluations across various languages, would form the core of the results section. Finally, considerations for handling different writing systems, including those with complex character structures or right-to-left writing directions, would likely also play a significant role in the discussion.
Dataset & Ablation#
A robust evaluation of any image generation model hinges on a well-constructed dataset and a thorough ablation study. Dataset creation requires careful consideration of factors such as image diversity, text quality, language representation, and annotation consistency. A diverse dataset ensures the model generalizes well to unseen data, while careful annotation is crucial to avoid introducing biases. For ablation studies, a systematic approach is vital. This involves isolating individual components of the model, such as the control input mechanism, the two-stage generation process, or the Fourier analysis techniques, and then evaluating the model’s performance after removing or modifying each component. This allows for a precise understanding of each component’s contribution to the overall performance. Careful analysis of results from ablation studies can then provide crucial insights into the model’s strengths and weaknesses, allowing for targeted improvements. By presenting comprehensive results from well-designed experiments using a high-quality dataset, the paper strengthens its claims and improves the overall understanding of the factors affecting performance in the image generation process.
Future Directions#
Future research directions in visual text generation should prioritize improving the handling of complex and detailed text, addressing limitations of current latent diffusion models. This includes exploring alternative architectures beyond the current U-Net-based framework to better manage fine-grained details and reduce artifacts. More sophisticated control mechanisms are needed, moving beyond simple glyph images to incorporate richer linguistic information and higher-level semantic understanding. This might involve integrating robust language models for better context awareness and more effective control of text style and layout. Advanced data augmentation techniques could further improve model robustness, particularly for low-resource languages. Furthermore, the research community should pay close attention to ethical considerations related to text generation, particularly concerning potential misuse for generating misinformation and deepfakes. Finally, research into unified frameworks for text generation and editing promises to accelerate progress and create more versatile tools.
More visual insights#
More on figures

This figure visualizes how control information affects image generation at different stages of the denoising process. Panel (a) shows that detailed textural information requires control information at later stages for high-quality results. Panel (b) demonstrates that early-stage control, even with limited input, impacts the overall coherence of the image, ensuring a consistent background and matching text regions.
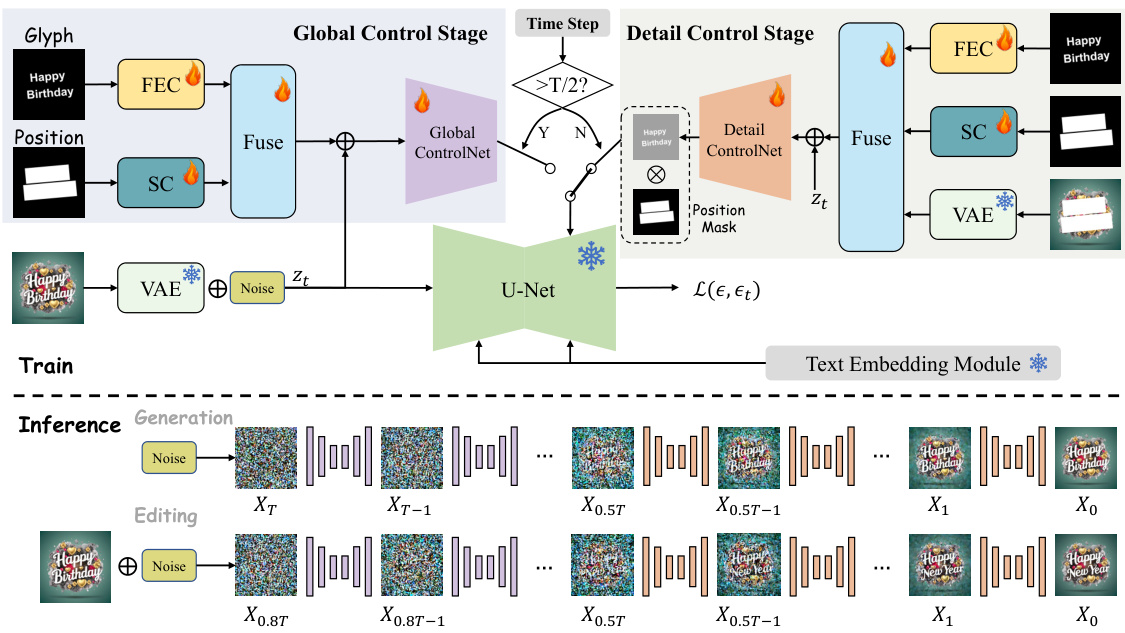
This figure illustrates the architecture of TextGen, a two-stage framework for visual text generation and editing. The global control stage focuses on overall structure and style, while the detail stage refines details and allows for editing. Both stages utilize Fourier Enhancement Convolution (FEC) and Spatial Convolution (SC) blocks to process control information. A novel inference paradigm unifies generation and editing tasks.
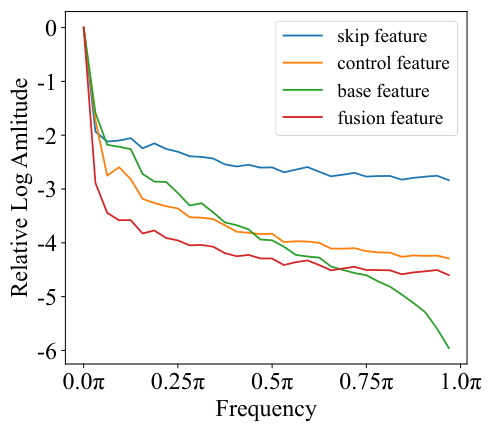
This figure visualizes the frequency components of different feature types within the U-Net decoder of a diffusion model used for text image generation. It shows the relative log amplitude across various frequencies (from 0 to π) for four feature types: skip features, control features, base features, and the fusion of these features. The plot helps illustrate how these features differ in their frequency distribution, which is relevant to understanding their respective roles in the image generation process, particularly concerning the balance between high and low-frequency information in controlling texture details.

This figure shows the architecture of two blocks used in the TextGen model: the Spatial Convolution Block (SC) and the Frequency Enhancement Convolution Block (FEC). The SC block uses standard convolutions to process spatial information. The FEC block uses two branches, one for spatial information processing via convolutions and another for frequency information processing using a Fast Fourier Transform (FFT), convolutions in the frequency domain, and an Inverse Fast Fourier Transform (IFFT). Both blocks have a global perception layer using a large kernel convolution to capture global image context.

This figure showcases a qualitative comparison of English text generation performance between different methods: ControlNet, GlyphControl, TextDiffuser, TextDiffuser2, AnyText, a baseline model, ground truth, and the proposed TextGen model. Each method is shown generating images for several different prompts demonstrating differences in text quality, style, and artistic rendering. TextGen is highlighted as producing significantly more realistic and artistically pleasing results compared to other approaches.

This figure compares the visual text generation results in Chinese from ControlNet, AnyText, ground truth and the proposed TextGen method. The examples show that TextGen produces more realistic and accurate results than the other methods, especially in terms of text clarity and overall image quality.

This figure shows examples of the text editing capabilities of the TextGen model. It showcases how the model can successfully replace text in images while maintaining background consistency and overall image quality. Different variations of text are edited in several examples, highlighting the model’s flexibility and precision in altering text content within various visual contexts.

This figure shows examples of captions generated by BLIP-2 and Qwen-VL for the same images. BLIP-2 captions are often repetitive and nonsensical, while Qwen-VL captions are more accurate and descriptive, highlighting the improvement in caption quality achieved by using Qwen-VL to refine BLIP-2’s initial output. This showcases the need for caption refinement in datasets used for visual text generation.

This figure shows some example images from the TG-2M dataset, highlighting the diversity of image styles and text content present in the dataset. The images illustrate different fonts, languages (English and Chinese), background styles and text arrangements, demonstrating the complexity handled by the model.

This figure illustrates the typical process of generating text images using a ControlNet. A glyph image (text image with standard font) is used as control information, which is added to the skip features of the U-Net decoder. The process is the same for control information at all stages, which is a limitation addressed by the paper’s proposed method.
More on tables
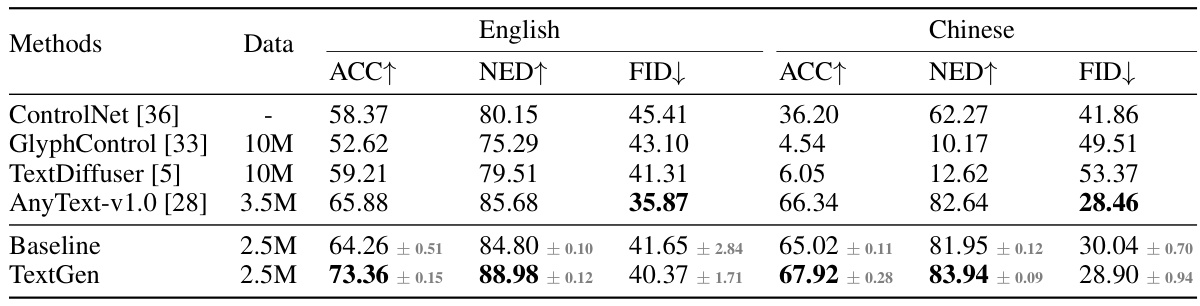
This table compares the performance of the proposed TextGen model against several state-of-the-art visual text generation methods. The metrics used for comparison are sentence accuracy (ACC), normalized edit distance (NED), and Fréchet Inception Distance (FID). The table highlights that TextGen achieves superior performance on both English and Chinese text generation, despite using a smaller training dataset (2.5M images) compared to some of the other models (10M images).
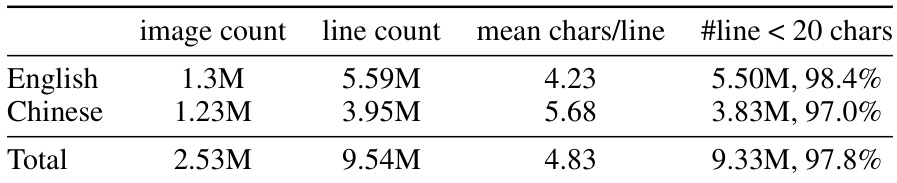
This table presents a statistical summary of the TG-2M dataset, a multilingual dataset created for training visual text generation models. It breaks down the dataset’s composition by language (English and Chinese), providing the image count, line count, average number of characters per line, and the percentage of lines containing fewer than 20 characters. The total dataset size is also shown.
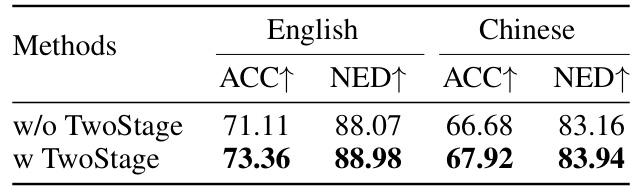
This table compares the performance of the proposed TextGen model with and without the two-stage generation framework. The comparison is done using the metrics ACC (sentence accuracy) and NED (normalized edit distance) on both English and Chinese datasets. The results show a slight improvement in performance when using the two-stage framework.
Full paper#