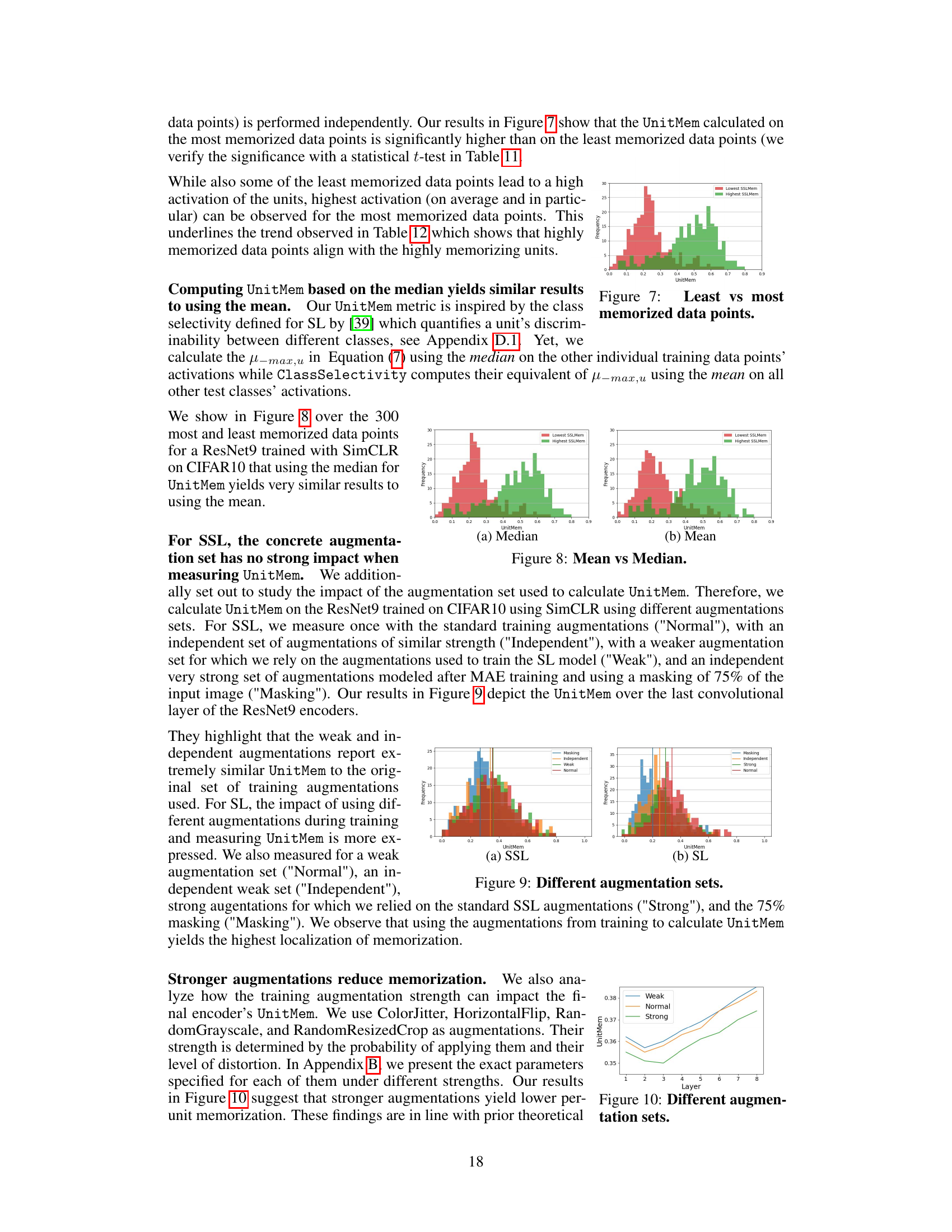
↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Self-supervised learning (SSL) models, despite their large training datasets, exhibit memorization of individual data points. However, the location of this memorization within the model architecture remains poorly understood, hindering efforts to improve model efficiency and generalization. This research directly addresses this gap by introducing novel techniques to precisely pinpoint memorization within SSL encoders, both at the layer and individual unit level.
The researchers developed and employed two new metrics: LayerMem, for layer-level analysis; and UnitMem, for unit-level analysis. Applying these metrics to various encoder architectures trained on different datasets revealed several key findings: Memorization is distributed throughout the entire encoder, not concentrated in the final layers; a substantial fraction of units exhibit high memorization; and atypical data points lead to much higher memorization than standard data points. These discoveries are not only significant in terms of understanding SSL model behavior but also provide practical benefits. The localized insights enable improved fine-tuning strategies, where focusing on the most memorizing layers yields superior downstream performance, and informed pruning methods to further enhance efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in self-supervised learning (SSL) and computer vision. It introduces novel methods for precisely locating memorization within SSL encoders, revealing its distribution across layers and units. This understanding can significantly improve model fine-tuning and pruning strategies, leading to more efficient and effective models. The findings challenge existing assumptions about memorization, opening new avenues for investigating the interplay between memorization and model generalization in SSL. The paper’s methodology is broadly applicable to other deep learning architectures, promising further advances in the field.
Visual Insights#
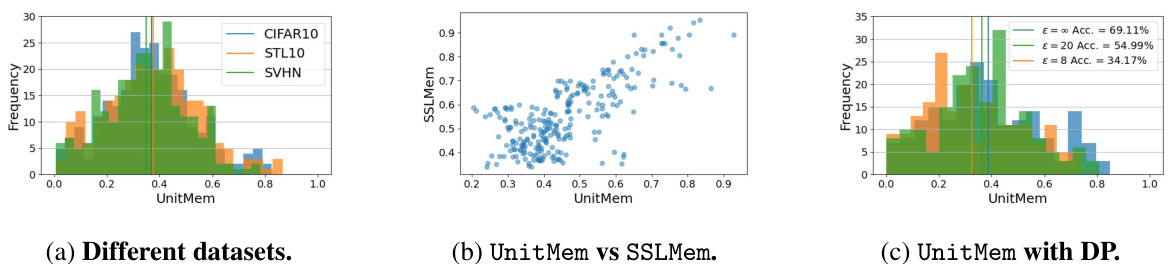
This figure provides insights into the UnitMem metric proposed in the paper. Panel (a) shows UnitMem distributions for three different datasets (SVHN, CIFAR10, and STL10), highlighting variations in memorization across datasets. Panel (b) shows a scatter plot comparing SSLMem and UnitMem scores on CIFAR10, demonstrating a positive correlation: higher SSLMem (overall memorization) corresponds to higher UnitMem (unit-level memorization). Panel (c) illustrates the impact of differential privacy (DP) on UnitMem, showing that stronger DP (lower epsilon values) leads to reduced UnitMem, indicating effective privacy-preserving mechanisms.
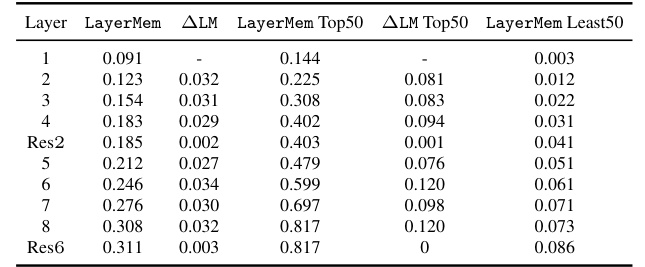
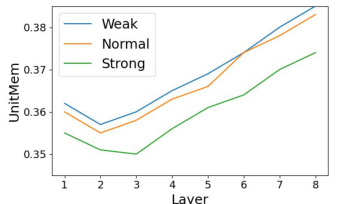
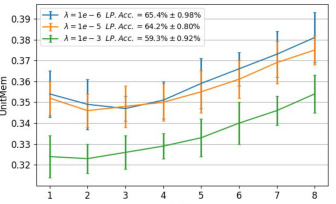
This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows how memorization (as measured by LayerMem) changes across different layers of the network. The table also presents a breakdown of the LayerMem scores for the top 50 and bottom 50 memorized data points, showing how memorization varies for these outlier samples compared to the average data point. The ∆LayerMem shows the increase in memorization of a layer compared to the previous one. It demonstrates that memorization increases with depth but not monotonically.
In-depth insights#
SSL Memorization#
Self-Supervised Learning (SSL) has revolutionized training large vision encoders using unlabeled data. However, a crucial aspect that has emerged is the phenomenon of SSL memorization, where the model retains specific details of the training data, despite the massive size of the datasets. This memorization is not necessarily detrimental, impacting downstream task performance, and its location within the encoder network is poorly understood. This paper addresses this knowledge gap by proposing methods to localize this memorization, providing insights into its per-layer and per-unit distribution. Surprisingly, the study reveals that highly memorizing units are not concentrated in the final layers, but rather distributed across the encoder, highlighting a different memorization pattern than observed in supervised learning. This suggests SSL’s instance discrimination objective contributes to this unique memorization behavior, potentially influencing model generalization. Furthermore, the findings showcase the effect of atypical data points on memorization, which is significantly higher compared to standard data points, suggesting memorization is not uniform. These localization insights are practically valuable, offering potential for improving encoder fine-tuning and pruning strategies.
LayerMem Metric#
The LayerMem metric, as described in the provided context, is a novel approach to quantify memorization within self-supervised learning (SSL) vision encoders on a per-layer basis. Unlike previous methods which focus on overall model memorization or require labels, LayerMem offers a fine-grained analysis that is both label-free and computationally efficient. The metric leverages a layer-wise comparison of representation similarity, identifying layers with unexpectedly high sensitivity to training data points as indicative of memorization. This granular analysis allows for a detailed investigation of how memorization progresses through the network, providing insights into the specific layers where it is most pronounced. The normalization of the SSLMem metric to the range [0,1], where 1 signifies maximum memorization, enhances interpretability. A further innovation is the calculation of ΔLayerMem, which isolates the increase in memorization at each layer relative to the preceding layer. This helps remove the compounding effect of memorization across layers, offering a clearer picture of each layer’s contribution to overall memorization. The LayerMem metric, therefore, represents a substantial advance in the localization of memorization within SSL vision encoders. By providing a label-free, per-layer, and efficient method, it facilitates deeper investigation of this critical aspect of SSL model behavior.
UnitMem Metric#
The proposed UnitMem metric offers a novel approach to fine-grained localization of memorization within self-supervised learning (SSL) models. Unlike previous methods that focused on per-layer analysis or required downstream tasks, UnitMem directly assesses the sensitivity of individual units (neurons or channels) to specific training data points. This unit-level granularity provides insights into the distribution of memorization across the entire network. A key advantage is its independence from downstream tasks and label information, enabling its application to various SSL frameworks. By quantifying the memorization of individual data points through units’ activation patterns, UnitMem helps to identify highly memorizing units, potentially improving model understanding, fine-tuning strategies, and pruning methods. The metric’s ability to highlight memorization differences between SSL and supervised learning models is also noteworthy, contributing to a deeper comprehension of learning paradigms. Further research could explore UnitMem’s effectiveness across diverse architectures and datasets, expanding its utility in improving SSL model robustness and interpretability.
Vision Transformer#
Vision Transformers (ViTs) represent a significant advancement in computer vision, adapting the Transformer architecture initially designed for natural language processing. ViTs leverage the power of self-attention mechanisms to capture long-range dependencies and relationships between image patches, effectively replacing traditional convolutional layers. This approach offers several advantages: handling variable-sized inputs gracefully, exhibiting superior performance on large-scale datasets, and achieving state-of-the-art results on various image classification benchmarks. However, ViTs typically require significantly more computational resources than CNNs due to the quadratic complexity of self-attention. Furthermore, the reliance on large training datasets and extensive pre-training is a key limitation, hindering their applicability in resource-constrained environments. Despite these challenges, ongoing research focuses on improving efficiency through architectural innovations and exploring the synergy between ViTs and CNNs, aiming to combine the strengths of both architectures to achieve optimal performance and scalability.
Future Work#
The “Future Work” section of a research paper on localizing memorization in self-supervised learning (SSL) vision encoders could explore several promising avenues. Improving the metrics (LayerMem and UnitMem) to handle various SSL frameworks and datasets more robustly would enhance their applicability. Investigating the relationship between memorization localization and downstream task performance more deeply, perhaps by correlating specific memorization patterns with task success or failure, is crucial. Developing novel training strategies that leverage the findings, such as fine-tuning only the most memorizing layers or pruning based on the localized memorization maps, could yield significant efficiency gains. Exploring the memorization differences between SSL and supervised learning (SL) models more comprehensively to gain a deeper theoretical understanding of memorization in both settings is vital. Further research could investigate the connections between specific types of data points (e.g., outliers) and their memorization patterns, which would aid in improving robustness and generalizability. Finally, analyzing memorization in other modalities beyond vision, such as natural language processing, would broaden the scope of the research significantly.
More visual insights#
More on figures

This figure compares the memorization patterns of SSL and SL models at the unit level. For each of eight convolutional layers in a ResNet9 model, it plots ClassMem (a measure of a unit’s sensitivity to classes) against UnitMem (a measure of a unit’s sensitivity to individual data points). The top row shows SSL results, while the bottom row shows SL results. The red line represents the case where ClassMem and UnitMem are equal. The plot reveals that SSL models significantly favor memorizing individual data points over classes, especially in deeper layers. Conversely, SL models tend to exhibit more class memorization, particularly in the later layers.
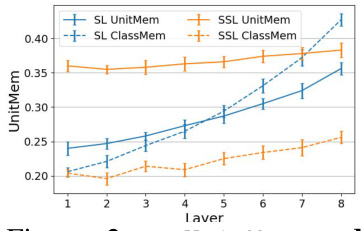
This figure compares the memorization patterns of SSL and SL models at the unit level. It shows that in SSL models, significantly more units memorize individual data points than classes, while the opposite is true for SL models. The comparison is done across eight convolutional layers of a ResNet9 model, trained on the CIFAR100 dataset. The ClassMem metric measures memorization at the class level, while UnitMem measures it at the individual data point level.
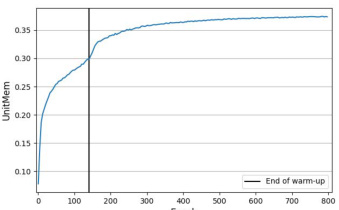
The figure shows the average UnitMem over training epochs for the 8th layer of a ResNet9 trained with SimCLR on CIFAR10. The x-axis represents the training epoch, and the y-axis represents the average UnitMem score. A vertical line indicates the end of the warm-up phase. The graph shows a clear increase in UnitMem during training, with the rate of increase slowing down after the warm-up phase.
This figure compares the memorization patterns of units in SSL and SL models trained on CIFAR100. It shows the ClassMem (class memorization) versus UnitMem (data point memorization) for each convolutional layer (1-8) of a ResNet9 model. The top row represents SSL, and the bottom row represents SL. Each point represents a unit in the network. The red diagonal line indicates where ClassMem equals UnitMem. The figure visually demonstrates that SSL encoders predominantly memorize individual data points rather than classes, while SL encoders show a greater emphasis on class memorization, particularly in the deeper layers.
This figure visualizes the UnitMem metric’s behavior across various settings. (a) shows UnitMem across different datasets, highlighting its sensitivity to dataset complexity. (b) demonstrates a strong correlation between SSLMem (overall memorization) and UnitMem, indicating that highly memorized data points also exhibit high UnitMem in individual units. (c) explores the effect of differential privacy (DP) on UnitMem during training, revealing that stronger DP reduces memorization but doesn’t completely eliminate it.
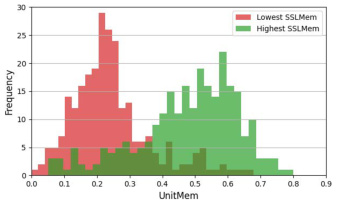
This figure presents an analysis of the UnitMem metric. Panel (a) shows how UnitMem varies across different datasets (SVHN, CIFAR10, STL10), highlighting its sensitivity to data complexity. Panel (b) demonstrates the correlation between SSLMem (overall memorization) and UnitMem (unit-level memorization) on the CIFAR10 dataset. Panel (c) illustrates the effect of differential privacy (DP) on UnitMem, revealing how different privacy levels influence unit-level memorization in both CIFAR10 and ViT-Base models.
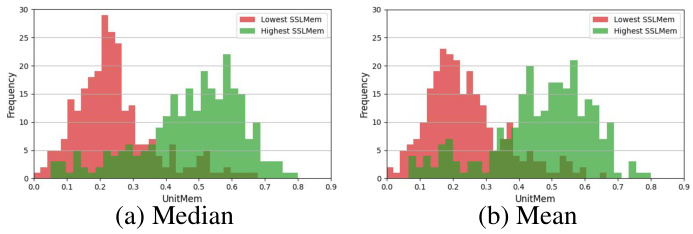
This figure presents an analysis of the UnitMem metric, which localizes memorization in individual units of self-supervised learning (SSL) encoders. Panel (a) shows UnitMem distributions across different datasets, demonstrating that the complexity of the dataset affects the number of highly memorizing units. Panel (b) compares SSLMem (a measure of overall memorization) and UnitMem, revealing a strong correlation; highly memorized data points tend to exhibit higher UnitMem scores. Panel (c) investigates the impact of differential privacy (DP) on UnitMem, illustrating that stronger DP reduces UnitMem but does not completely eliminate it.

This figure visualizes the UnitMem metric’s behavior across various scenarios. (a) shows how UnitMem varies across different datasets (SVHN, CIFAR10, STL10). (b) demonstrates the strong correlation between UnitMem and SSLMem, implying that data points with high memorization scores tend to have high UnitMem scores in the final convolutional layer. (c) illustrates how different levels of differential privacy (DP) during training affect the UnitMem scores on CIFAR10 and ViT-Base, indicating that stronger DP reduces memorization.
This figure shows three subfigures that provide insights into the UnitMem metric. Subfigure (a) displays UnitMem scores for the last convolutional layer of a ResNet9 encoder trained with SimCLR on three different datasets (SVHN, CIFAR10, and STL10), demonstrating that the complexity of the dataset influences the number of units with high memorization. Subfigure (b) shows the relationship between SSLMem and UnitMem on the CIFAR10 dataset, highlighting that data points with high general memorization (as measured by SSLMem) tend to have higher UnitMem scores. Subfigure (c) demonstrates the effect of differential privacy (DP) on UnitMem, illustrating that stronger privacy protection reduces UnitMem but does not eliminate it completely.
This figure visualizes the insights of the UnitMem metric proposed in the paper. Panel (a) shows the distribution of UnitMem scores across three different datasets (SVHN, CIFAR10, and STL10) for the last convolutional layer of a ResNet9 encoder. Panel (b) compares the relationship between SSLMem (a global memorization metric) and UnitMem for CIFAR10 data points. It shows a positive correlation, indicating that data points with higher general memorization also tend to have higher UnitMem values (more memorization in individual units). Panel (c) demonstrates the effect of differential privacy (DP) on the UnitMem scores, showing how different levels of DP during training impact the degree of memorization in individual units.

This figure visualizes the results of UnitMem experiments. The first subplot (a) shows the distribution of UnitMem scores across three different datasets (SVHN, CIFAR10, STL10) for the last convolutional layer of a ResNet9 model trained with SimCLR. The second subplot (b) compares SSLMem and UnitMem scores for data points in the CIFAR10 dataset, demonstrating a positive correlation between the two metrics: points with high SSLMem (general memorization) tend to have high UnitMem (unit-level memorization). The third subplot (c) illustrates the effect of differential privacy (DP) on UnitMem scores using CIFAR10 and ViT-Base, showcasing a reduction in UnitMem with increasing privacy levels.

This figure demonstrates several key aspects of the UnitMem metric. Panel (a) shows the distribution of UnitMem scores across different datasets, highlighting variations in memorization levels. Panel (b) examines the relationship between SSLMem (overall memorization) and UnitMem, demonstrating a positive correlation: images with high overall memorization tend to have high UnitMem scores in specific units. Finally, panel (c) illustrates the effect of differential privacy (DP) during training on UnitMem, showing how varying privacy levels impact the memorization of individual data points.
More on tables

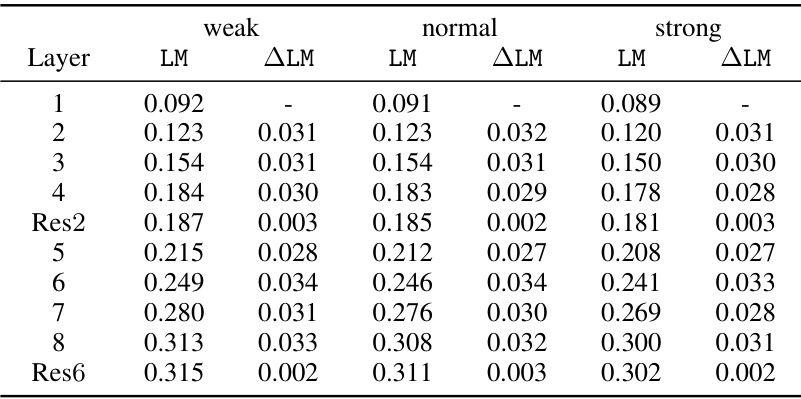
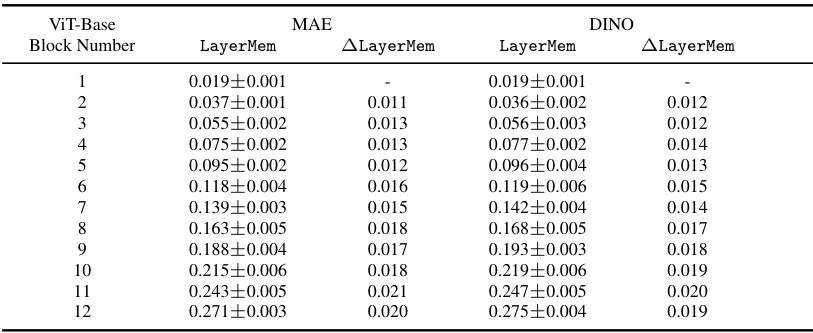
This table shows the results of applying the LayerMem and ALayerMem metrics to a Vision Transformer (ViT) model. It demonstrates that memorization in ViTs is concentrated in the deeper blocks of the network and that, within those blocks, the fully connected layers memorize more than the attention layers. This finding contrasts with previous research focused on language transformers. The table is broken down to show results for both attention and fully-connected layers within each block, highlighting the difference in memorization.

This table presents the consistency of memorization across different layers of a ResNet9 model trained on the CIFAR10 dataset. It shows the pairwise overlap (percentage) between the top 100 most memorized samples in different layer pairs. It also provides the Kendall’s Tau correlation coefficient (τ) and p-value, indicating the statistical significance of the similarity in ranking between these samples across the layer pairs. The results reveal a strong correlation between adjacent layers, particularly in the deeper layers of the network, but little correlation between layers that are further apart.
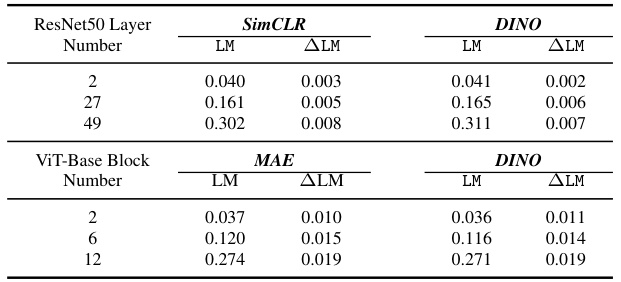
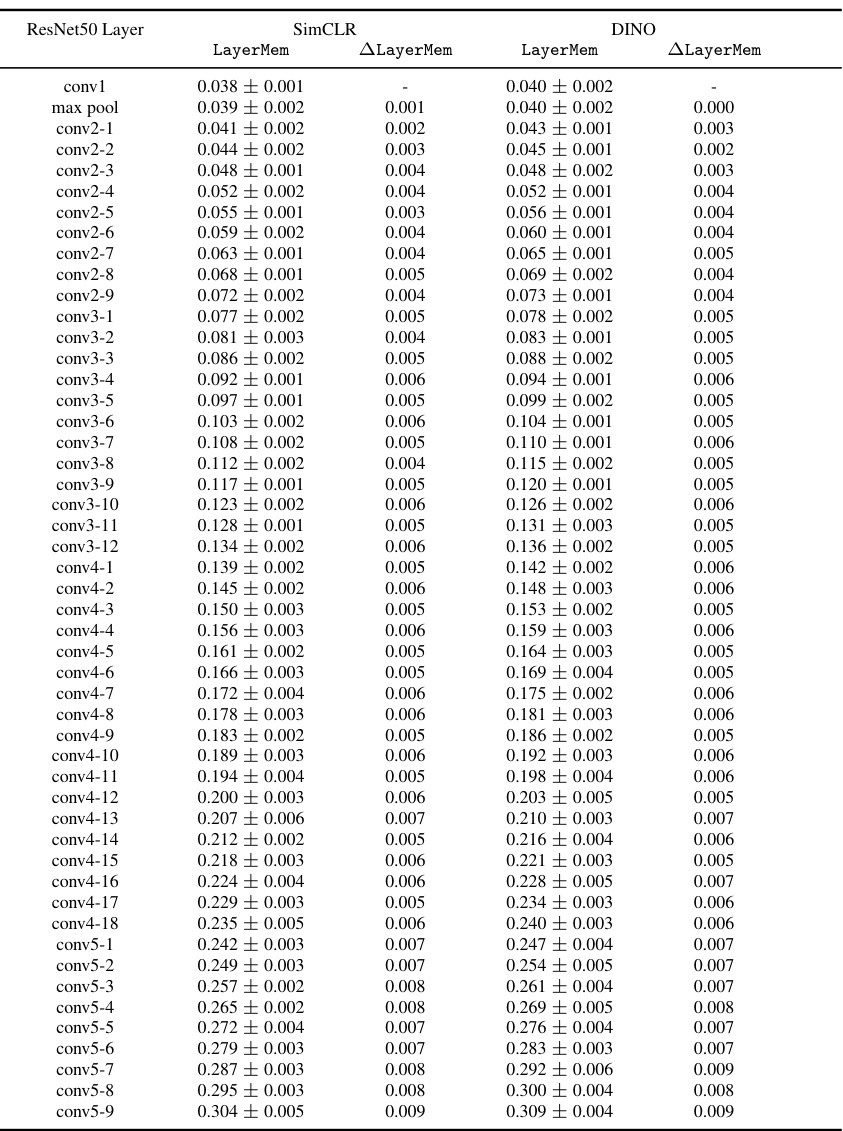
This table compares the LayerMem (LM) and the increase in memorization between subsequent layers (ΔLM) for ResNet50 and ViT-Base encoders trained with different self-supervised learning (SSL) frameworks (SimCLR, DINO, MAE). It demonstrates that the memorization patterns are largely consistent across different SSL frameworks for the same architecture. This supports the finding that the location of memorization is relatively consistent despite the SSL framework used.

This table presents the results of an experiment where the authors fine-tuned different layers of a ResNet9 encoder (trained with SimCLR on CIFAR10) on the STL10 dataset. The goal was to determine if fine-tuning the layers identified as most memorizing by their proposed metrics would improve performance compared to fine-tuning only the last layers, a common practice. The table shows that fine-tuning the layers with the highest memorization scores generally leads to higher accuracy on the STL10 dataset.
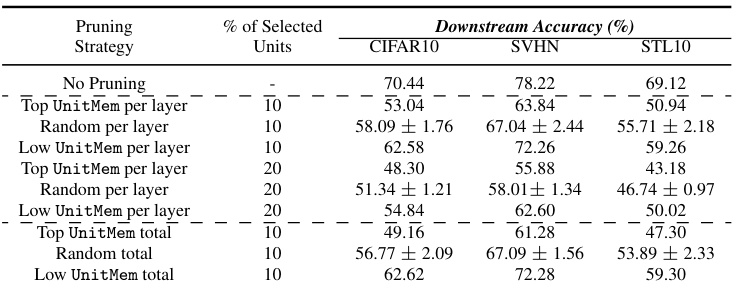
This table presents the results of an experiment where the authors pruned units in a ResNet9 model trained on CIFAR10, based on their memorization scores (UnitMem). Three pruning strategies are compared: removing the top (most memorized) units, the bottom (least memorized) units, and randomly selected units. The table shows the downstream accuracy (on CIFAR10, SVHN, and STL10) after pruning 10% and 20% of the units using each strategy. The results demonstrate the impact of memorization on model performance.
This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows memorization scores (LayerMem) and the increase in memorization between successive layers (ALayerMem) for all layers, as well as a breakdown for the top 50 and bottom 50 most memorized data points. The results demonstrate that memorization increases with depth, although not monotonically.
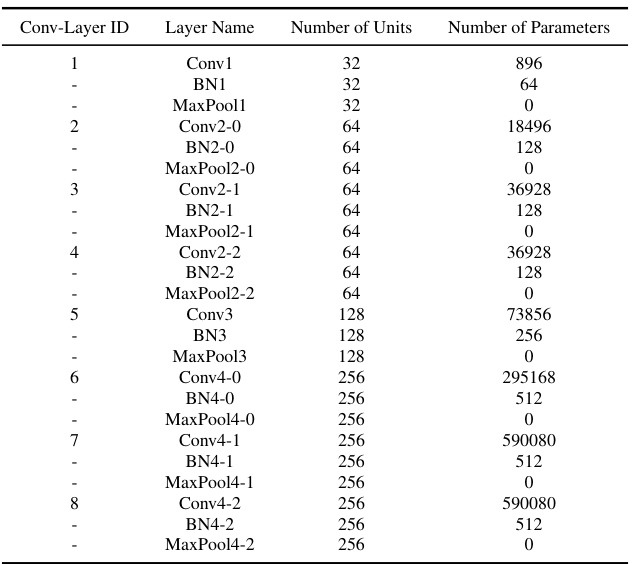
This table details the architecture of the ResNet9 model used in the experiments. It provides a breakdown of each layer, including the convolutional layers (Conv), batch normalization layers (BN), and max pooling layers (MaxPool). For each layer, it lists the number of units (activation maps, which correspond to the number of filters) and the total number of parameters in that layer.
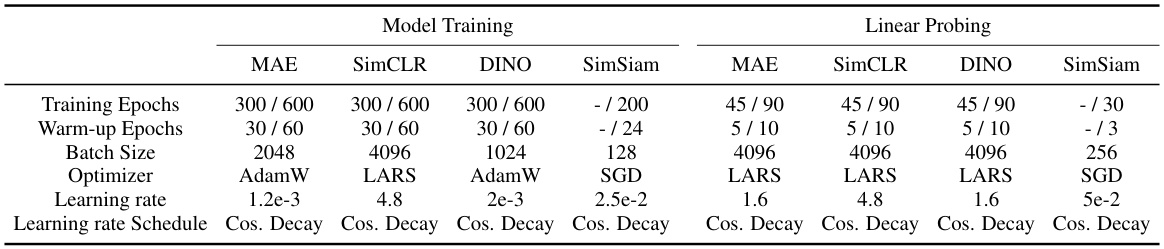
This table presents the training and linear probing setup used for the experiments in the paper. It includes the number of training epochs, warm-up epochs, batch size, optimizer, learning rate, and learning rate schedule for four different self-supervised learning (SSL) frameworks: MAE, SimCLR, DINO, and SimSiam. The table shows hyperparameters used for both training and linear probing phases on various datasets. Note that the specific hyperparameters used vary slightly based on dataset size.
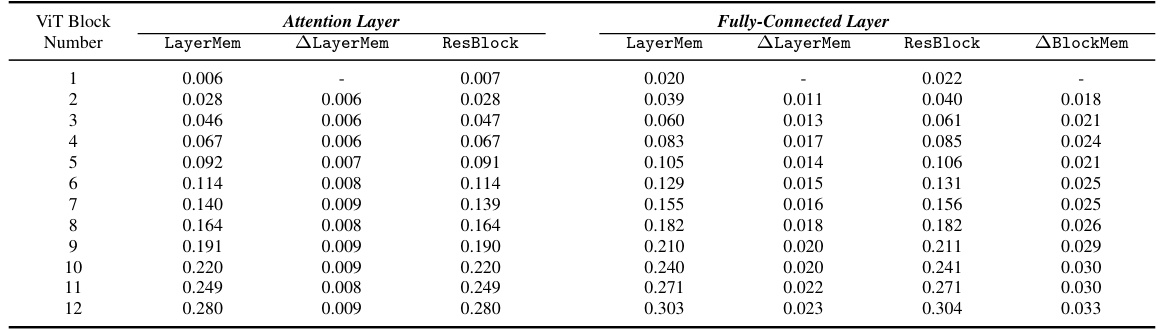
This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows the memorization scores for each layer, broken down into overall memorization, memorization of the top 50 most memorized data points, and memorization of the least 50 memorized data points. The ALM column shows the increase in memorization for each layer compared to the previous layer.
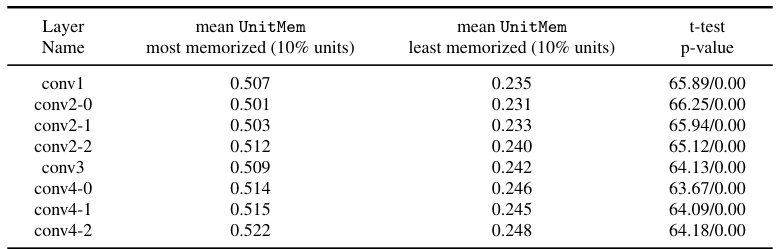
This table compares the per-layer mean UnitMem scores for the top 50 most memorized data points and the top 50 least memorized data points, identified using the SSLMem metric. A statistical t-test is performed to determine if there is a significant difference between the two groups’ memorization levels. The p-values strongly indicate a significant difference, demonstrating that highly memorized data points exhibit considerably higher UnitMem values than those that are less memorized.

This table shows the alignment between highly memorized data points and highly memorizing units in the last layer of a ResNet9 encoder trained with SimCLR on CIFAR10. It lists the frequency of data points that caused the maximum activation (µmax) for a given unit, and the number of units that each data point activated maximally. The table demonstrates a strong correlation between the data points deemed most memorized by the SSLMem metric and the units exhibiting the highest memorization according to the UnitMem metric. This further strengthens the connection between high-level memorization and the presence of highly memorizing units.

This table shows the results of an experiment designed to verify the accuracy of the UnitMem metric. A SimSiam-based ResNet18 model, pre-trained on CIFAR10, had its units fine-tuned using a single data point. The experiment focused on two units: one with the highest UnitMem score and another with the lowest. The results demonstrate that the UnitMem metric accurately reflects memorization, as only the targeted units showed increased memorization scores after fine-tuning.

This table presents the results of the LayerMem metric applied to a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. The LayerMem score is presented for all layers of the encoder. The table shows the LayerMem scores, the increase in memorization from the previous layer (ALM), and the scores calculated for only the top 50 and least 50 memorized data points (ALM Top50 and LayerMem Least50 respectively). This shows how memorization changes through the layers of the network.

This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows the memorization scores across all 8 layers (including residual connections and max pool layers) for 100 randomly chosen training data points, the top 50 memorized data points, and the least 50 memorized data points. The ALM column shows the increase in memorization for each layer compared to the previous layer.

This table presents the LayerMem scores for each layer of a ResNet18 model trained on CIFAR10 using the SimCLR framework. LayerMem quantifies the level of memorization in each layer of the model. The results are presented as mean ± standard deviation across multiple trials, offering a layer-by-layer view of memorization within the ResNet18 architecture under SimCLR training.

This table presents the LayerMem scores for each layer of a ResNet34 model trained on CIFAR10 using the SimCLR framework. LayerMem is a metric used to quantify the level of memorization in each layer of the model. The values in the table represent the average LayerMem score and the standard deviation over multiple trials, offering insights into how memorization varies across different layers of the ResNet34 architecture.

This table presents the LayerMem scores for each layer of a ResNet50 model trained on CIFAR10 using the SimCLR framework. LayerMem quantifies the level of memorization in each layer of the encoder. The results show how memorization changes across different layers of the network.

This table presents a detailed breakdown of memorization scores across different layers of a ResNet9 encoder trained with SimCLR on the CIFAR10 dataset. It shows the LayerMem (overall memorization), ALayerMem (increase in memorization compared to the previous layer), and memorization scores for the top 50 and bottom 50 most memorized data points for each layer. This allows for a fine-grained analysis of memorization patterns within the model.
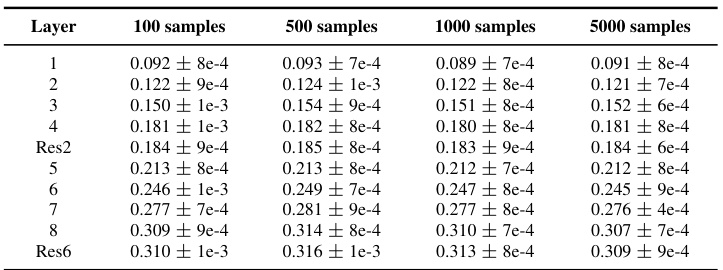
This table shows the results of an ablation study to test the sensitivity of the LayerMem metric to the number of samples used in its calculation. The experiment uses a ResNet9 model pre-trained on CIFAR10 with SimCLR. LayerMem scores are calculated for batches of 100, 500, 1000, and 5000 samples, with three independent seeds used for each batch size. The results demonstrate that LayerMem is not significantly affected by the size or composition of the batch, indicating its robustness and reliability.

This table compares the downstream generalization performance of SSL and SL encoders on CIFAR100, CIFAR10, STL10, and SVHN datasets. The SSL encoder was pretrained on CIFAR100 using SimCLR, while the SL encoder was trained until convergence on CIFAR100 with cross-entropy loss and then the last layer was removed. The results show that SSL encoders perform better on the STL10 and SVHN datasets, whereas SL encoders perform better on the CIFAR100 and CIFAR10 datasets, indicating that memorization plays a role in determining downstream performance.
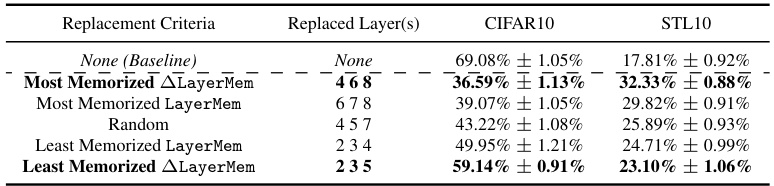
This table presents the results of an experiment where layers from a ResNet9 model trained on CIFAR10 were replaced with corresponding layers from a model trained on STL10. The replacement strategies varied: replacing the layers with the highest memorization scores (according to LayerMem and ALayerMem metrics), replacing layers randomly, and replacing the least memorizing layers. The table shows the resulting linear probing accuracy on CIFAR10 and STL10 test sets for each replacement strategy. The results highlight that replacing the most memorizing layers leads to the most significant decrease in accuracy on CIFAR10 but increase on STL10, indicating a relationship between memorization and downstream performance.
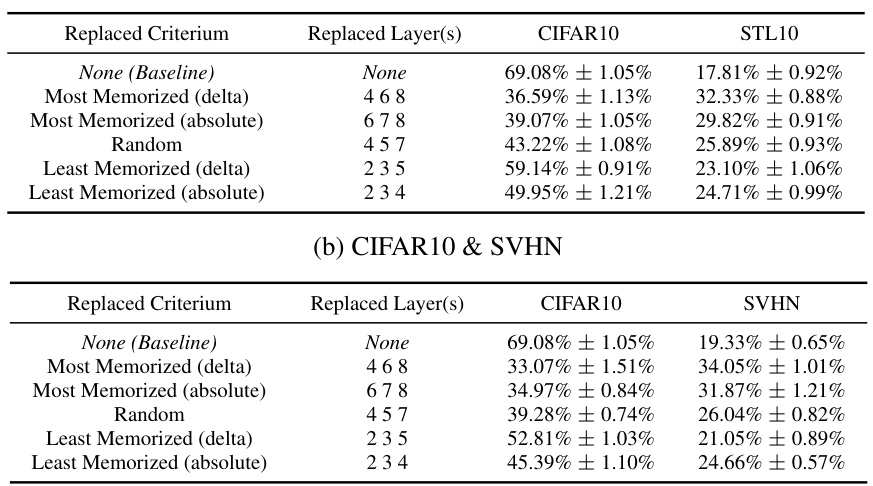
This table presents an ablation study on the impact of replacing different layers of a ResNet9 model trained on CIFAR10 with corresponding layers from a ResNet9 model trained on STL10. Three sets of layers are replaced: those with the highest memorization scores according to LayerMem (absolute and delta), those with the lowest memorization scores (absolute and delta), and random layers. The resulting linear probing accuracies on CIFAR10 and STL10 are reported to demonstrate the effect of localized memorization on downstream performance. The full results for replacing 1,2 and 3 layers are in the appendix.
This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows the memorization scores for each layer (LayerMem), the increase in memorization from the previous layer (ALM), and the scores broken down for the top 50 and bottom 50 memorized data points. This illustrates how memorization changes across the different layers of the network. The ‘ResN’ column indicates residual connections within the ResNet architecture.

This table presents the results of an experiment where layers from a ResNet9 model trained on CIFAR10 were replaced with corresponding layers from a ResNet9 model trained on STL10. The goal was to assess the impact of memorization by comparing linear probing accuracy on CIFAR10 and STL10 after replacing layers identified as most/least memorized (using LayerMem and ALayerMem) or randomly selected layers. The results show that replacing the most memorized layers leads to the largest performance drop on CIFAR10 and the highest gain on STL10.

This table presents the results of the LayerMem metric applied to a ResNet9-based SSL encoder trained on CIFAR10 using SimCLR. It shows the memorization scores (LayerMem, ALM, LayerMem Top50, ALM Top50, LayerMem Least50) for each layer of the network. The results are reported for 100 randomly selected training data points, the top 50 most memorized data points, and the least 50 memorized data points. The ALM represents the increase in memorization of a given layer compared to the previous layer.
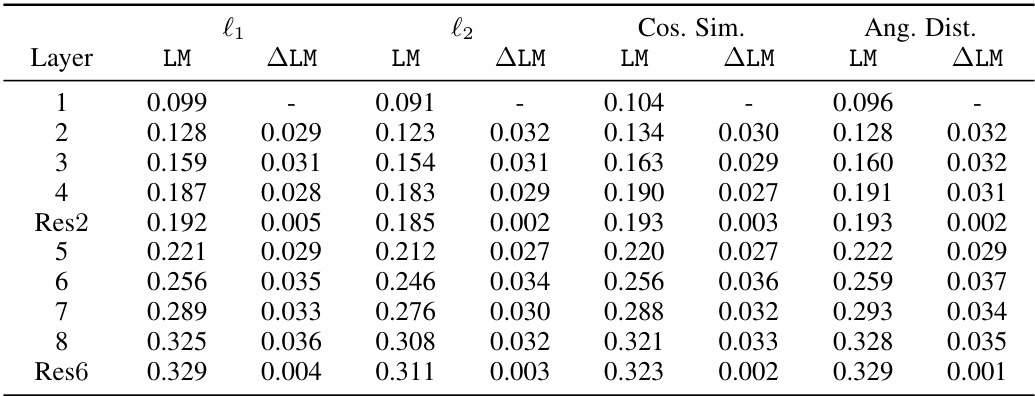
This table presents the results of the LayerMem metric applied to a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows the LayerMem scores (memorization scores), the increase in memorization from the previous layer (ALM), the LayerMem scores for only the top 50 memorized data points and their increase in memorization (ALM Top50), and the LayerMem scores for only the least 50 memorized data points. The results demonstrate how memorization increases with layer depth in SSL.
This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows the memorization scores (LayerMem) for each layer of the network, along with the change in memorization between consecutive layers (ALM). It also provides scores for the top 50 and bottom 50 most memorized data points, highlighting how memorization varies across different subsets of data and layers.

This table presents the pairwise overlap between the 100 most memorized samples in adjacent layers of a ResNet9 model trained with SimCLR on CIFAR10. It also shows the consistency of the ranking of these samples using Kendall’s Tau correlation test. The results demonstrate high overlap and statistical similarity between adjacent layers, especially in deeper layers, but low similarity between early and late layers.
This table presents the results of the LayerMem metric applied to a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. The table shows the memorization scores (LayerMem) for each layer of the network, and the increase in memorization between consecutive layers (ΔLayerMem). The results for the top 50 and bottom 50 most memorized data points are also shown, to highlight the differences in memorization patterns for atypical versus typical data points. These results illustrate how memorization increases with layer depth in SSL, but not monotonically, and also how this memorization pattern varies depending on whether the data points are typical or atypical.
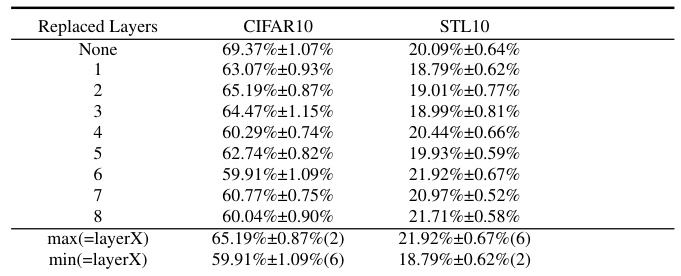
This table presents the results of an ablation study where different layers of a ResNet9 encoder pretrained on CIFAR10 are replaced with corresponding layers from encoders pretrained on STL10. The goal is to assess the impact of memorization on downstream performance by replacing layers identified as having the most, least, or random memorization. The table shows the resulting linear probing accuracy on both CIFAR10 and STL10 datasets, illustrating the effect of replacing specific layers on the performance for each dataset.
This table presents the results of the LayerMem metric applied to a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. The table shows LayerMem scores for different layers, including the increase in memorization between subsequent layers (ALM), and separately for the top 50 and bottom 50 most memorized data points to highlight memorization trends across the network. Residual connections within the ResNet architecture are also noted.
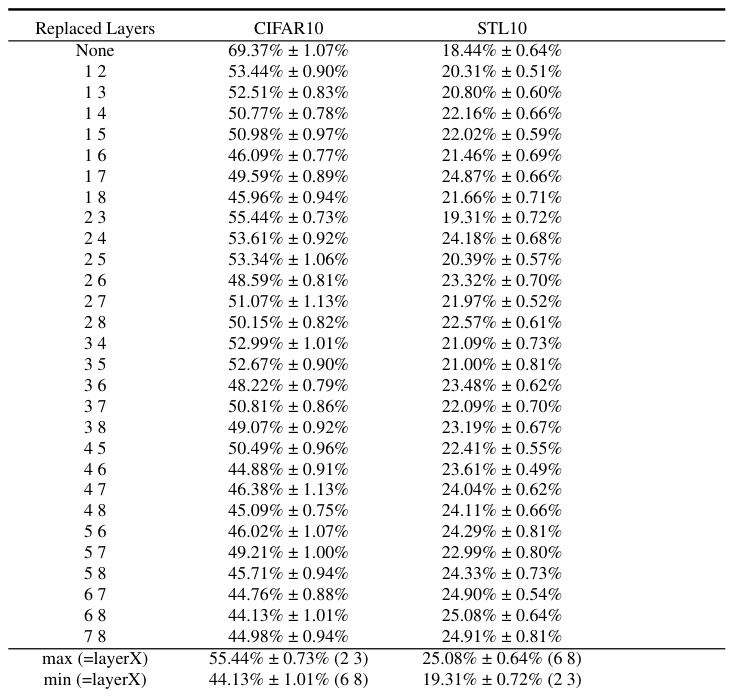
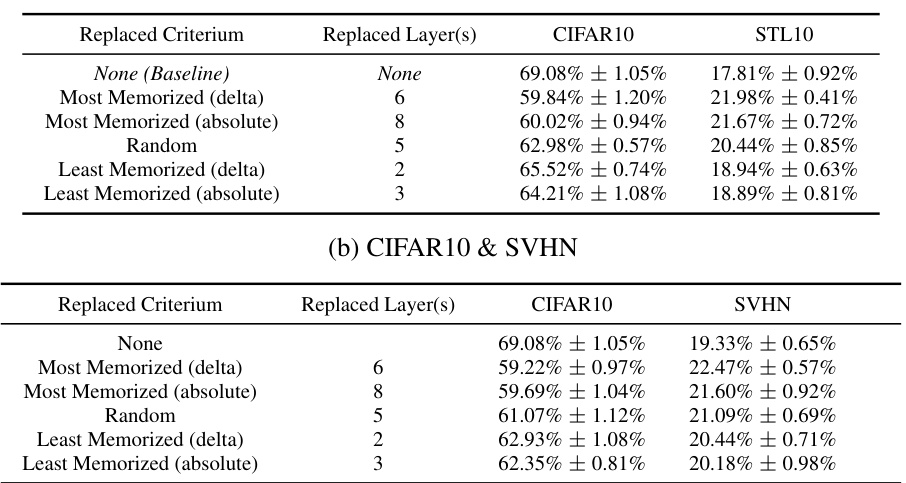
This table presents the results of an experiment where layers from a ResNet9 model trained on CIFAR10 were replaced with corresponding layers from a ResNet9 model trained on STL10. The goal was to assess the impact of replacing layers with varying memorization levels (most, least, random) on downstream task performance, measured by linear probing accuracy on both CIFAR10 and STL10. The table shows that replacing the most memorized layers leads to the greatest performance drop on CIFAR10 and the least memorized layers leads to the best performance on STL10. This suggests that highly memorized layers are crucial for downstream task performance on the original dataset, but those layers could be detrimental to performance when the downstream task involves a new dataset.

This table presents the results of an ablation study where different layers of a ResNet9 model trained on CIFAR10 using SimCLR are replaced with corresponding layers from a model trained on STL10. The experiment aims to verify the accuracy of the LayerMem metric in identifying the most impactful layers in SSL encoders. The table shows that replacing the most memorizing layers according to the ALayerMem metric causes the largest drop in accuracy for CIFAR10. Conversely, replacing the least memorizing layers results in the least performance decrease. The full results of replacing different combinations of layers (one, two, and three) can be found in Appendix C.12.
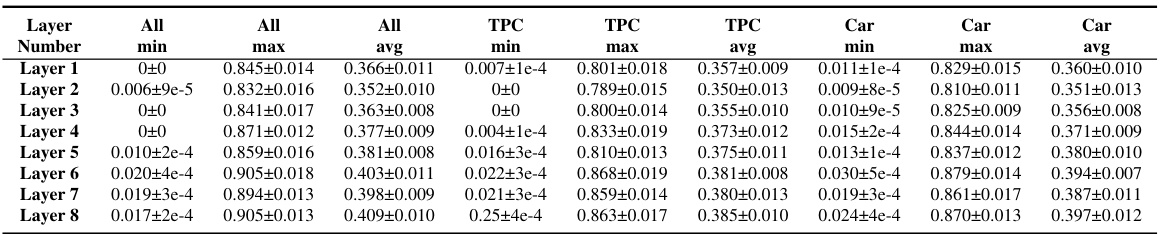
This table presents the LayerMem scores for a ResNet9-based SSL encoder trained with SimCLR on CIFAR10. It shows memorization scores (LayerMem) for each layer of the network, calculated as the average memorization score across 100 randomly selected training data points. The table also includes the change in memorization score between consecutive layers (ALM) and separates the results for the top 50 and bottom 50 most memorized data points to highlight variations in memorization across the network and different types of data points.
Full paper#