↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Machine learning’s conventional wisdom assumes that larger, more expressive models consistently improve performance. However, this paper demonstrates that this isn’t true in real-world scenarios involving strategic interactions, such as multi-agent reinforcement learning, strategic classification and strategic regression. The presence of strategic agents can introduce unexpected complexities, potentially leading to non-monotonic relationships between model expressivity and equilibrium performance. This challenges the common assumptions of game-theoretic machine learning algorithms and necessitates a more nuanced understanding of model selection in the presence of strategic decision-making.
To address the challenges posed by strategic interactions, the authors propose a novel paradigm for model selection in games. Instead of treating the model class as fixed, they suggest viewing the choice of model class as a strategic action. This perspective leads to new algorithms for model selection in games, aiming for optimal outcomes in strategic settings, even when larger models might appear initially preferable. The research offers illustrative examples and experimental results to support these findings, suggesting that thoughtful model selection can significantly impact the success of AI in real-world strategic interactions.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional wisdom in machine learning that larger models always perform better. It highlights the non-monotonic relationship between model complexity and performance in strategic environments, opening avenues for more robust model selection methods and improving outcomes in various applications involving strategic interactions.
Visual Insights#
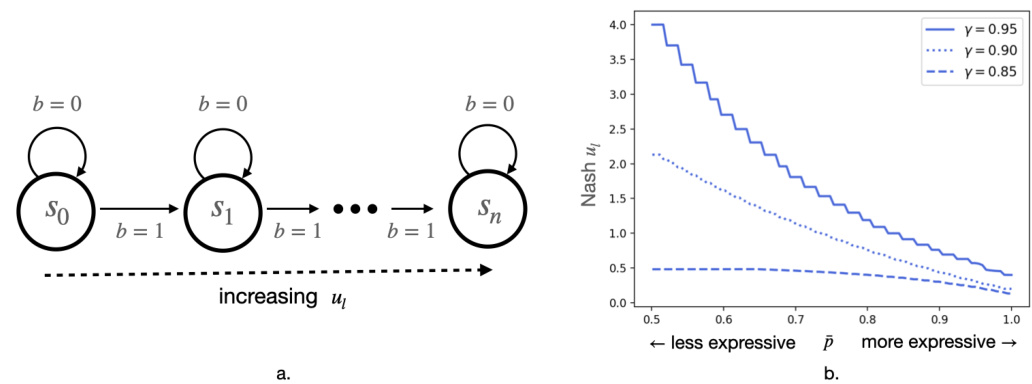
Figure 1(a) shows a two-player Markov game where the learner can increase its payoff by limiting the expressiveness of its policy. Figure 1(b) displays the learner’s payoff at Nash equilibrium in a 50-state version of the game, demonstrating that restricting the policy class leads to higher payoffs for different discount factors.

This algorithm uses stochastic gradient descent to find the Nash Equilibrium in a strongly monotone game. It iteratively updates the players’ actions using a projected gradient step with a decreasing step size. The algorithm returns the average of the iterates over the second half of the iterations. This averaging helps to reduce the noise and improve the accuracy of the estimate of the Nash equilibrium.
Full paper#



















