↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Model-based Reinforcement Learning (MBRL) excels in sample efficiency but suffers from high computational costs. Existing MBRL methods often use Recurrent Neural Networks (RNNs) or Transformers for world models, hindering parallelization and slowing training. Transformers’ quadratic complexity with sequence length further limits their efficiency. The paper addresses these limitations.
The paper introduces the Parallelized Model-based Reinforcement Learning (PaMoRL) framework. PaMoRL uses two novel techniques: Parallel World Model (PWM) and Parallelized Eligibility Trace Estimation (PETE) to parallelize both model learning and policy learning. Empirical results across Atari 100k and DeepMind Control Suite benchmarks demonstrate significant speed improvements without sacrificing sample efficiency. PaMoRL maintains MBRL-level sample efficiency, outperforming other MBRL and model-free methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning as it presents PaMoRL, a novel framework that significantly improves the training speed of model-based reinforcement learning methods without compromising sample efficiency. This addresses a major bottleneck in MBRL, opening avenues for applying these sample-efficient methods to more complex tasks and larger datasets. The introduction of parallelization techniques provides valuable insights for optimizing hardware efficiency in sequential data processing.
Visual Insights#

This figure compares the performance of PaMoRL with other state-of-the-art reinforcement learning methods on the Atari 100k benchmark and DeepMind Control Suite. The comparison is based on average normalized scores achieved against the average human scores, and training speed (FPS) on different GPU hardware. The results indicate that PaMoRL achieves comparable or better performance than other methods while also demonstrating significant gains in training efficiency.

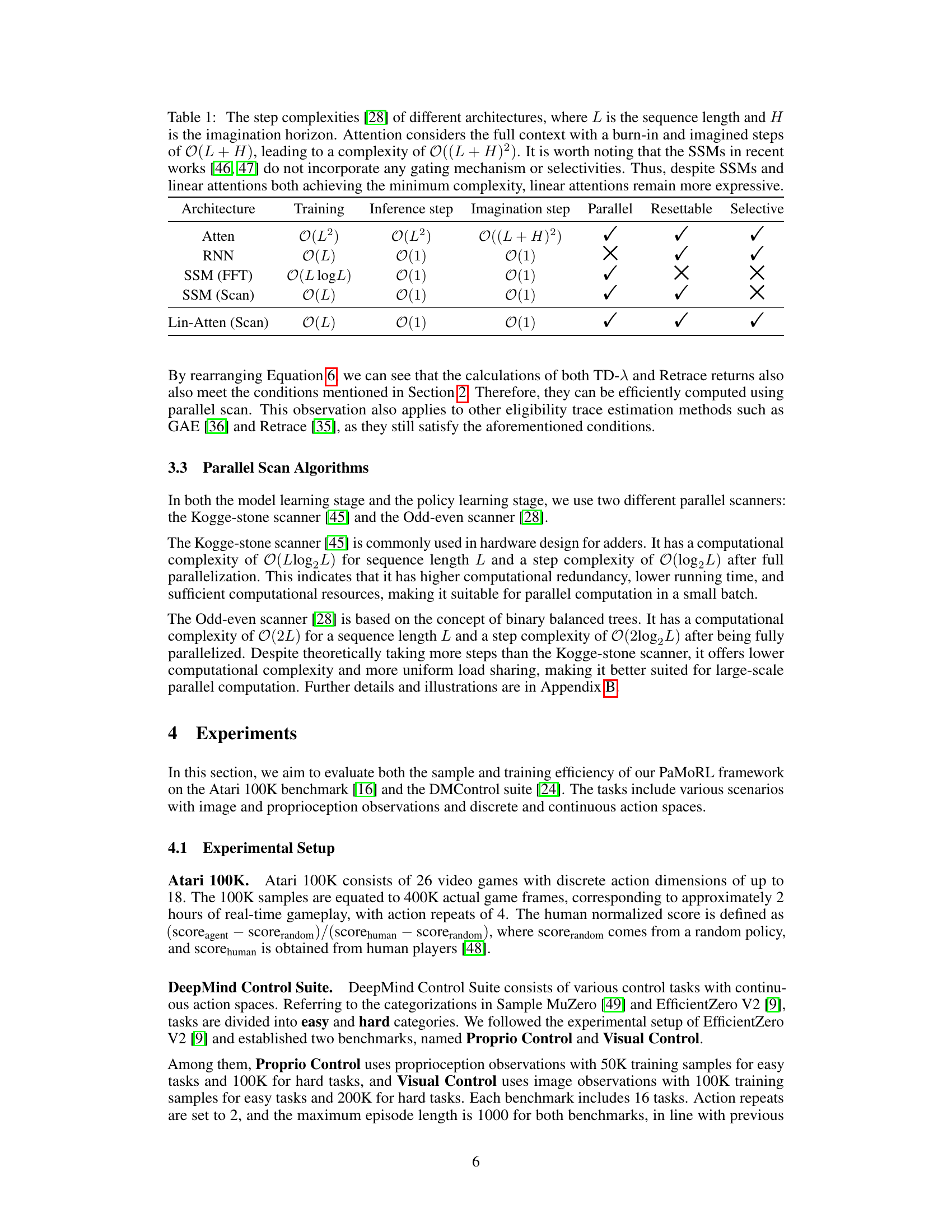
This table compares the computational complexities of different sequence model architectures (Atten, RNN, SSM, Lin-Atten) during training, inference, and imagination steps. It also indicates whether each architecture supports parallel processing, allows for resettable states, and offers selective attention mechanisms. The analysis highlights the efficiency and expressiveness of linear attention with parallel scanning.
In-depth insights#
PaMoRL Framework#
The PaMoRL framework, a novel approach to model-based reinforcement learning (MBRL), tackles the computational challenges associated with achieving high sample efficiency. Its core innovation lies in parallelizing both model learning and policy learning across the sequence length, thereby significantly accelerating training without compromising inference efficiency. This parallelization is achieved through two key techniques: the Parallel World Model (PWM), which leverages parallel scan algorithms to enable efficient parallel training of sequential data, and the Parallelized Eligibility Trace Estimation (PETE), which similarly accelerates policy learning by parallelizing eligibility trace computations. PaMoRL demonstrates superior training speed compared to existing MBRL and model-free methods while maintaining competitive sample efficiency, even surpassing planning-based methods on some tasks. The framework’s flexibility is highlighted by its successful application across tasks with various action spaces and observation types, using a single set of hyperparameters. Hardware efficiency is a central advantage, making PaMoRL a practical and impactful advancement in MBRL.
Parallel Scan Methods#
The effectiveness of parallelization in model-based reinforcement learning hinges on efficiently handling sequential data. Parallel scan algorithms offer a powerful approach to accelerate computations over sequences, addressing the inherent sequential nature of many MBRL components. The paper explores this by examining how parallel scans can be effectively applied to both model learning (e.g., processing sequential model outputs) and policy learning stages (e.g., computing eligibility traces). The choice of parallel scan algorithm (e.g., Kogge-Stone vs. Odd-Even) impacts both computational complexity and memory usage, making the selection crucial for optimizing hardware efficiency. Hardware efficiency is a major concern as the paper suggests the use of parallel scans to alleviate this concern. The experiments highlight the significant speed improvements gained by leveraging parallel scan methods in MBRL and showcase how this leads to faster training without impacting inference efficiency, ultimately improving sample efficiency.
Atari & DMControl#
The Atari and DeepMind Control Suite (DMControl) benchmark results highlight the effectiveness of the PaMoRL framework. In Atari, PaMoRL demonstrates strong performance, surpassing other methods in terms of mean and median human-normalized scores, and achieving superhuman performance on a significant number of games. This success is particularly notable given its hardware efficiency, a key focus of the paper. The DMControl results further validate PaMoRL’s capabilities, exhibiting superior performance in both proprioceptive and visual control tasks, even against methods using larger networks or look-ahead search. The consistent success across diverse environments underscores the robustness and adaptability of the proposed parallel world modeling and eligibility trace estimation techniques within PaMoRL. These results strongly support the paper’s central claim of significantly improving both sample and hardware efficiency in model-based reinforcement learning.
Ablation Study PWM#
The ablation study on the Parallel World Model (PWM) is crucial for understanding its individual components’ contributions to the overall performance. By systematically removing or altering parts of the PWM, researchers can isolate the impact of each module (token mixing, RMSNorm, data-dependent decay rate). The results likely reveal whether each module is essential, beneficial, or detrimental. For example, removing the token mixing module might lead to a performance drop on tasks needing contextual information, but little impact on tasks with simple reward predictions. Similarly, RMSNorm’s impact on training stability is important. Its removal might lead to unstable or divergent training in certain scenarios. The ablation study provides valuable insights into the architecture’s design choices and supports the effectiveness of the PWM’s specific design to improve both sample and training efficiency in model-based reinforcement learning.
Future Work & Limits#
The section on “Future Work & Limits” would ideally delve into several key areas. First, extending the PaMoRL framework to encompass more complex model architectures beyond linear attention, potentially integrating transformers or more advanced RNNs, would be crucial. This could unlock better performance on tasks demanding long-range dependencies. Second, a detailed analysis of the scalability of PaMoRL to larger and more complex environments is essential. Investigating its performance and computational efficiency on high-dimensional state and action spaces is critical for demonstrating real-world applicability. Third, exploring the integration of planning-based methods into PaMoRL would be highly valuable. Combining the parallelization capabilities of PaMoRL with the planning horizon of look-ahead search algorithms could significantly improve sample efficiency and performance, especially in challenging tasks. Finally, a thorough exploration of potential failure modes and robustness to noisy or incomplete data should be conducted, along with strategies to enhance stability. Addressing these aspects would strengthen the paper’s overall contribution and highlight future research directions.
More visual insights#
More on figures
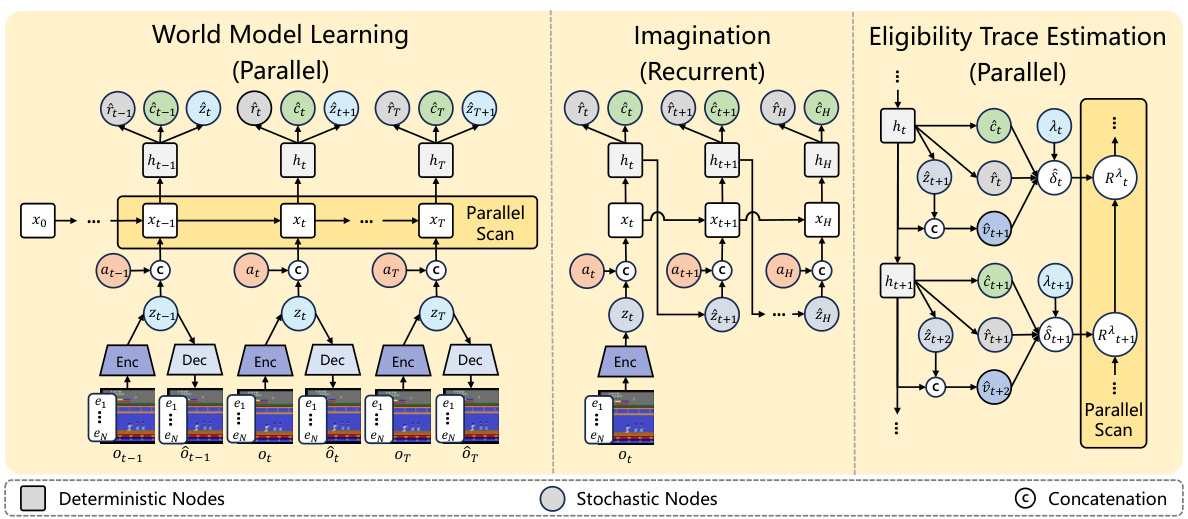
This figure presents a high-level overview of the Parallelized Model-based Reinforcement Learning (PaMoRL) framework proposed in the paper. It shows the three main stages of the model: the parallel world model learning, the recurrent imagination process, and the parallel eligibility trace estimation. The figure illustrates how each stage processes sequential data using either parallel or recurrent methods. The diagram visually depicts the flow of information between the different components and highlights which processes can take advantage of parallel scanning techniques to improve efficiency.

This figure presents the ablation study results for the Parallel World Model (PWM). It shows the impact of removing different components of the PWM architecture on the performance of the model in several Atari games. Specifically, it compares the performance of the PWM with: 1) no RMSNorm; 2) no Token Mixing; and 3) SSM with scan (equivalent to removing the data-dependent decay rate). The results are compared against the baseline performance of vanilla DreamerV3. The x-axis represents the number of training steps (in thousands), while the y-axis represents the score achieved in each game.

This figure presents a comparison of PaMoRL’s performance against other state-of-the-art methods on the Atari 100K benchmark. The left panel shows aggregated metrics (mean, median, interquartile mean, and optimality gap) with 95% confidence intervals, illustrating PaMoRL’s superior performance. The right panel provides probabilities of improvement, indicating the likelihood of PaMoRL surpassing each competitor.
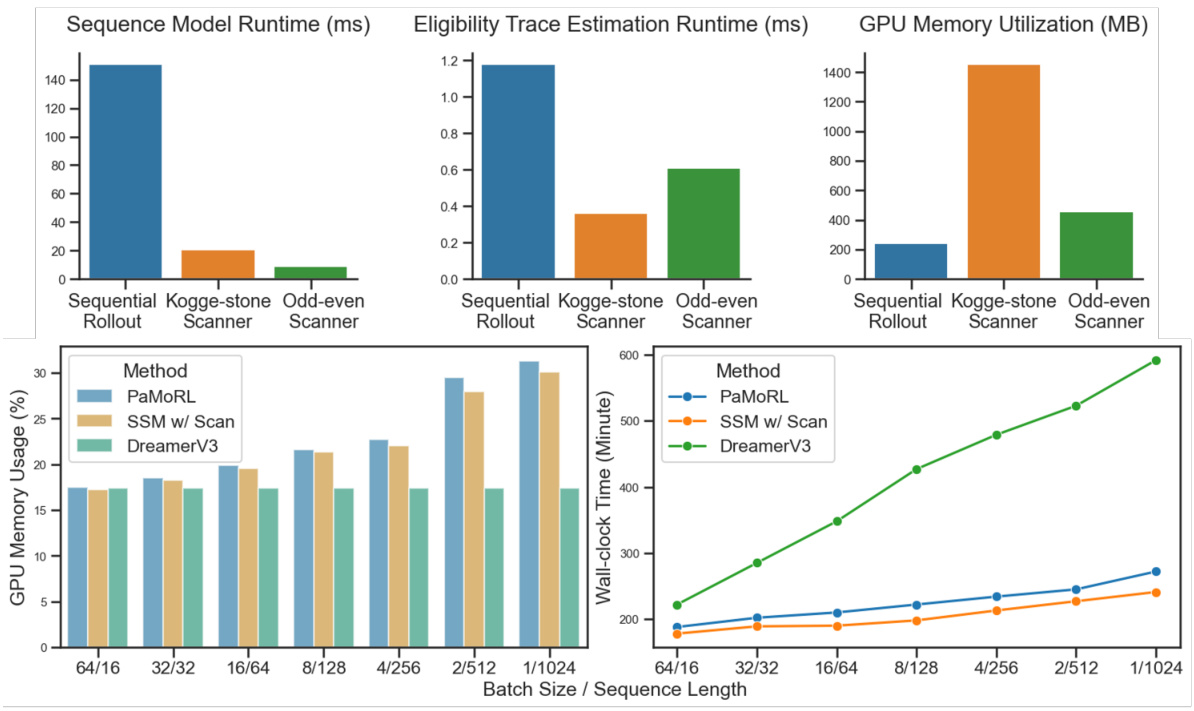
This figure compares the performance of different parallel scanning algorithms (Kogge-Stone and Odd-Even) against a sequential rollout approach for sequence modeling and eligibility trace estimation in the PaMoRL model. The upper part shows the runtime and GPU memory usage for each method and scanning approach, highlighting the efficiency gains achieved with parallelization. The lower part demonstrates how the wall-clock training time and GPU memory usage change as the batch size and sequence length are varied, further illustrating the scalability benefits of PaMoRL.

This figure illustrates the Kogge-stone parallel scan algorithm for a sequence length of 8. The Kogge-stone algorithm is a parallel algorithm for efficiently computing prefix sums. The figure shows the steps involved in the algorithm, starting with the initial input values Q(i,i) and progressing through multiple steps until the final prefix sums are computed. Each step involves parallel computations on pairs of elements, leading to a logarithmic time complexity.

This figure shows the step-by-step operation of the Kogge-stone parallel scanner algorithm for a sequence length of 8. Each step represents a parallel computation phase where intermediate results Q(m,n) are calculated. The Kogge-Stone algorithm efficiently computes parallel prefix sums in logarithmic time, showcasing the effectiveness of parallel processing for sequential tasks.
This figure compares the performance of PaMoRL against other state-of-the-art reinforcement learning methods on the Atari 100k benchmark and the DeepMind Control Suite. It shows training speed (FPS) on different GPU hardware (V100, A100, P100) and average normalized scores. The results highlight PaMoRL’s efficiency and performance compared to model-free and other model-based approaches.

This figure compares the performance of PaMoRL against other state-of-the-art model-based and model-free reinforcement learning methods on the Atari 100k benchmark and DeepMind Control Suite. The x-axis represents training frames per second (FPS) on different GPUs (V100, A100, P100), illustrating hardware efficiency. The y-axis shows the average human-normalized scores, indicating sample efficiency. The figure demonstrates that PaMoRL achieves a high level of sample efficiency while maintaining good hardware efficiency compared to other methods.

This figure compares the performance of PaMoRL against other state-of-the-art model-based and model-free reinforcement learning methods on the Atari 100k benchmark and DeepMind Control Suite. It shows the average human-normalized scores achieved by each method, plotted against their training speed (frames per second) on different GPU hardware (V100, A100, P100). The results demonstrate PaMoRL’s superior performance and efficiency.

The figure shows the effectiveness of batch normalization in the world model by visualizing the model’s predictions on two Atari games, Pong and Breakout, with and without batch normalization. The images compare the model’s reconstruction of game frames with and without using batch normalization, highlighting the improved ability to distinguish fine details (such as the small ball in Breakout) when batch normalization is applied.
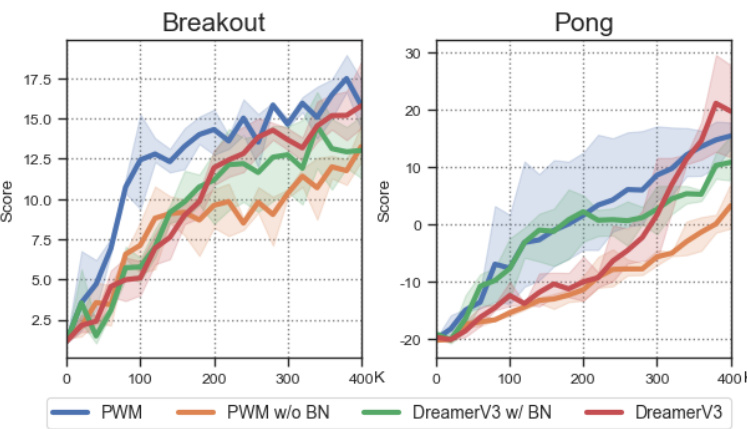
This ablation study investigates the impact of different components within the Parallel World Model (PWM) on the performance of the overall PaMoRL framework. Specifically, it examines the effects of removing the token mixing, RMSNorm, and data-dependent decay rate, comparing these variants to a standard SSM model and the baseline DreamerV3. The results help determine the importance of each module in the PWM and its contribution to training stability and overall performance.

This figure shows the multi-step predictions of the world model in several environments. The model uses the first five observations and actions as context and then predicts the subsequent 56 frames. This demonstrates the model’s ability to generate plausible future scenarios using a relatively small amount of input.

This figure shows the model’s ability to predict future frames in various environments (Atari games and DeepMind Control Suite). It uses 5 observations and actions to predict the next 56 frames using autoregression.
More on tables

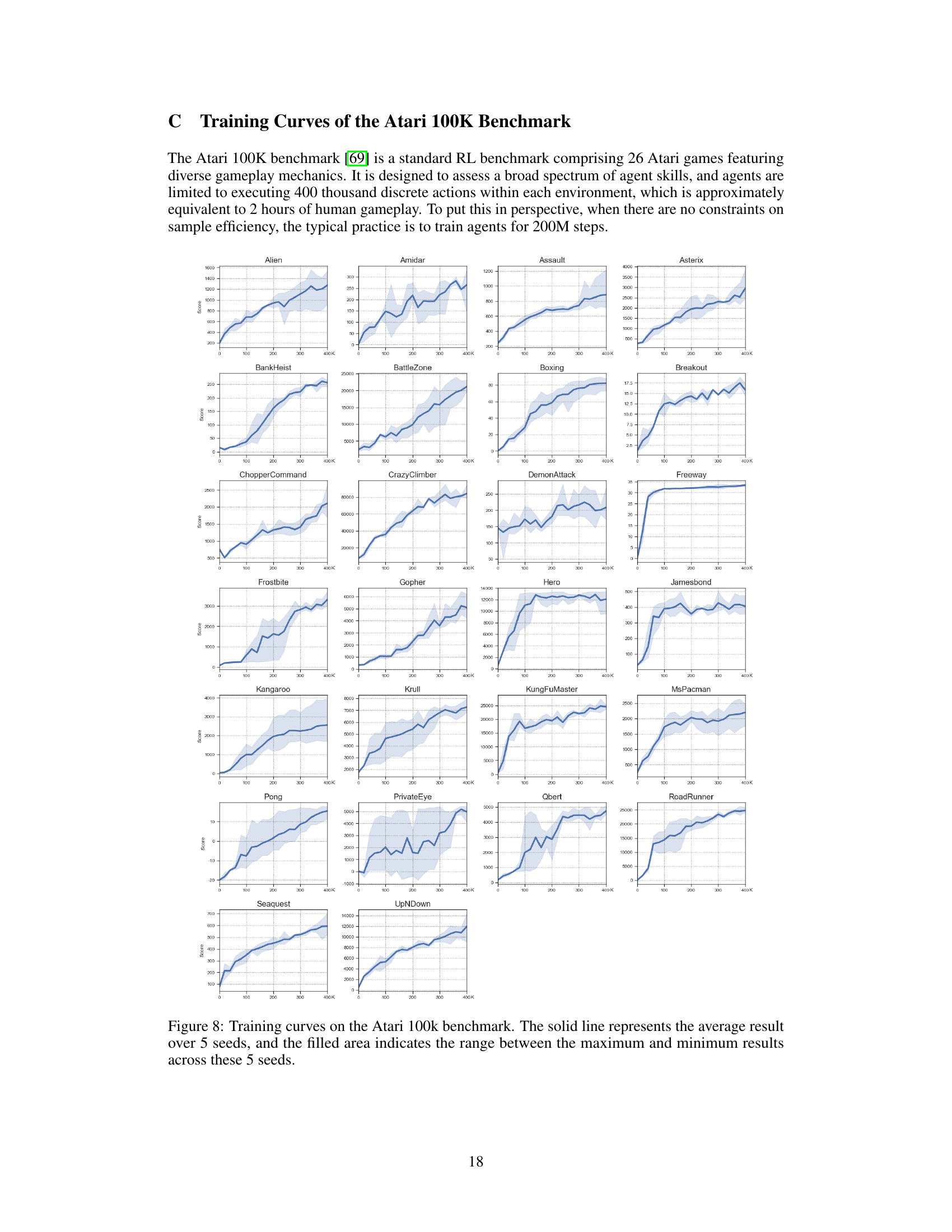
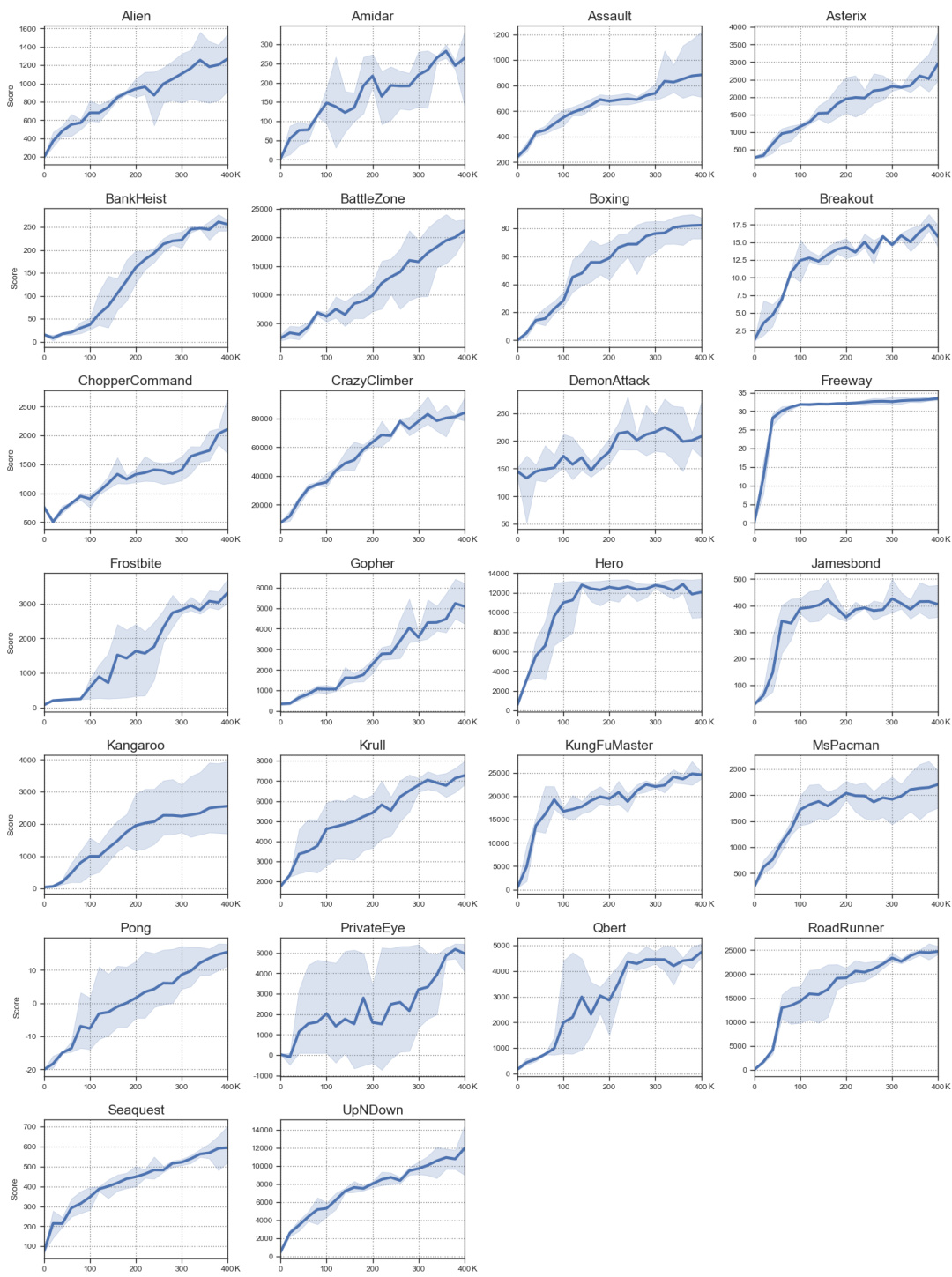
This table presents the results of the Atari 100k benchmark after 2 hours of real-time gameplay. It compares the performance of the proposed PaMoRL method against several other state-of-the-art reinforcement learning algorithms, showing human-normalized scores for each game. The bold and underlined scores highlight the best and second-best performers for each game. Key metrics (number of superhuman games, mean, and median scores) demonstrate PaMoRL’s superiority.
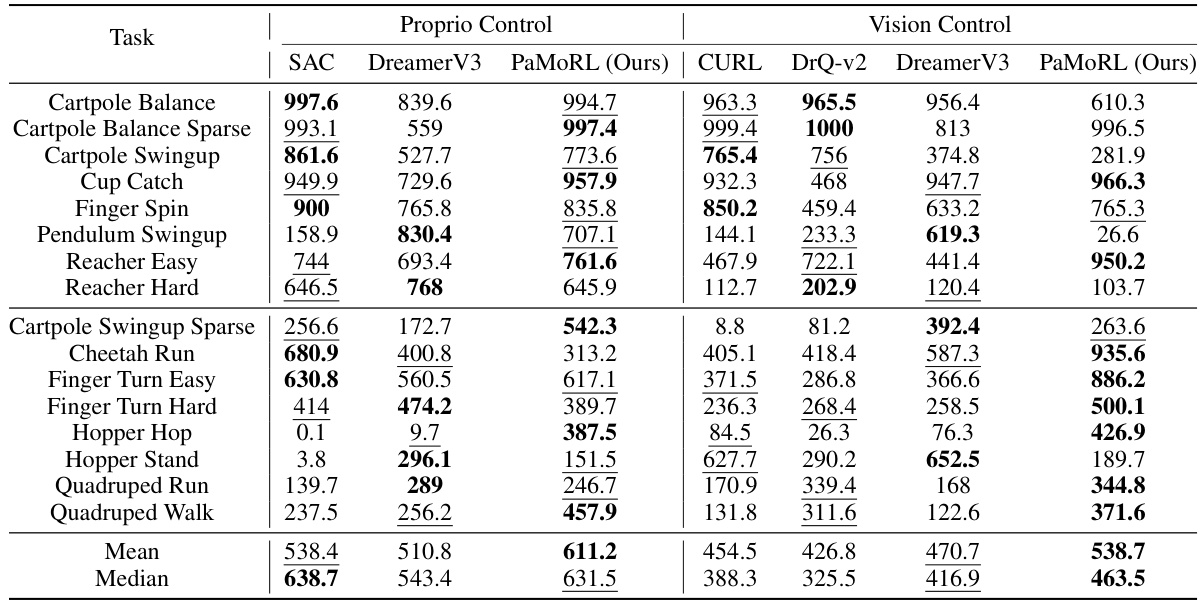
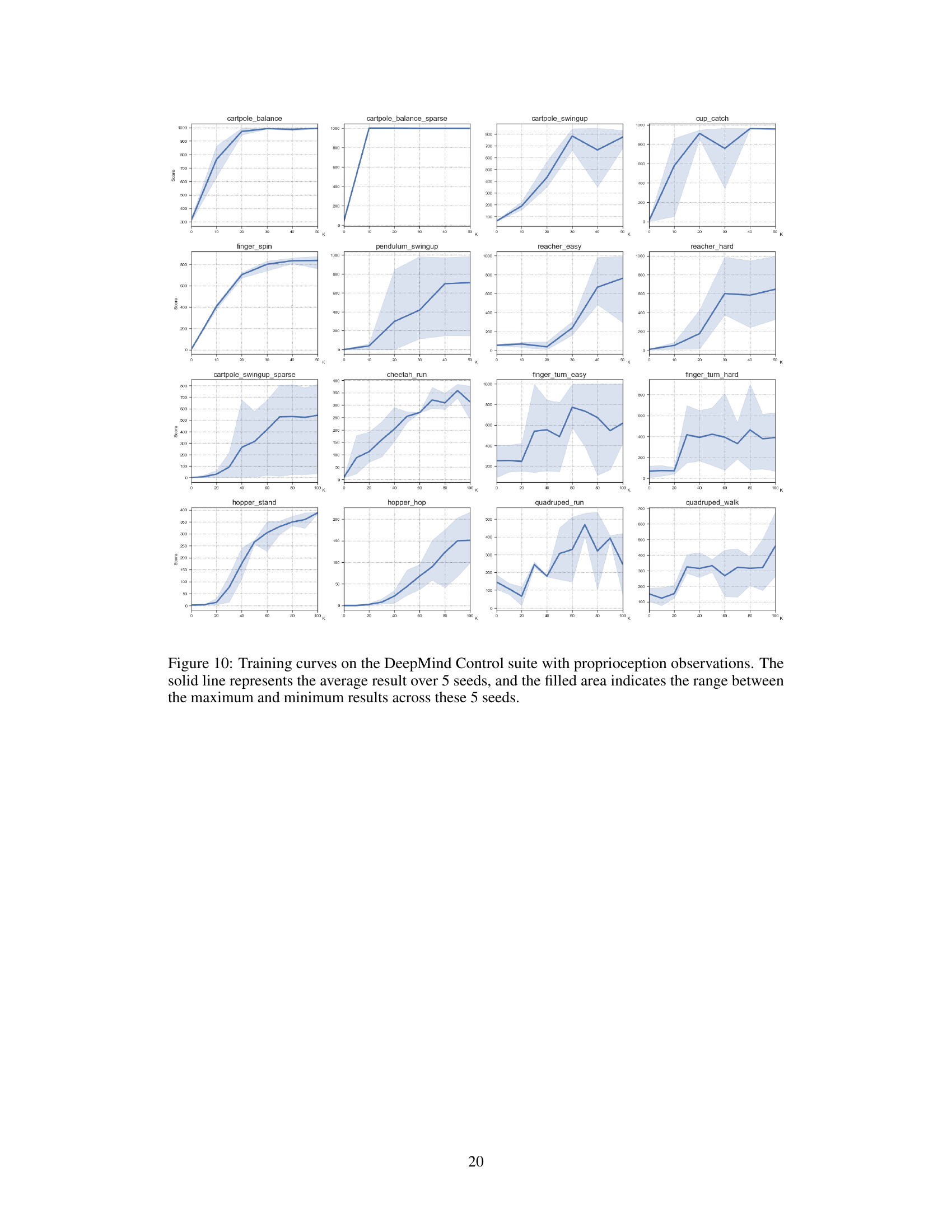
This table presents the experimental results of the PaMoRL framework and several baseline methods on the DeepMind Control Suite benchmark. The benchmark consists of various control tasks with continuous action spaces, using either proprioception or visual observations. The table shows the performance of each method on each task, measured by the mean score. PaMoRL’s performance is highlighted, showing it outperforms baselines in terms of mean and median scores. Bold and underlined numbers highlight the best and second-best performing methods for each task.
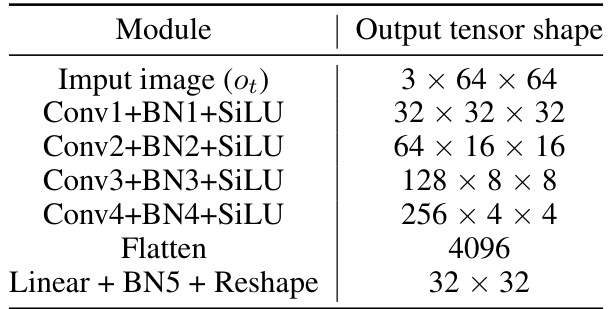
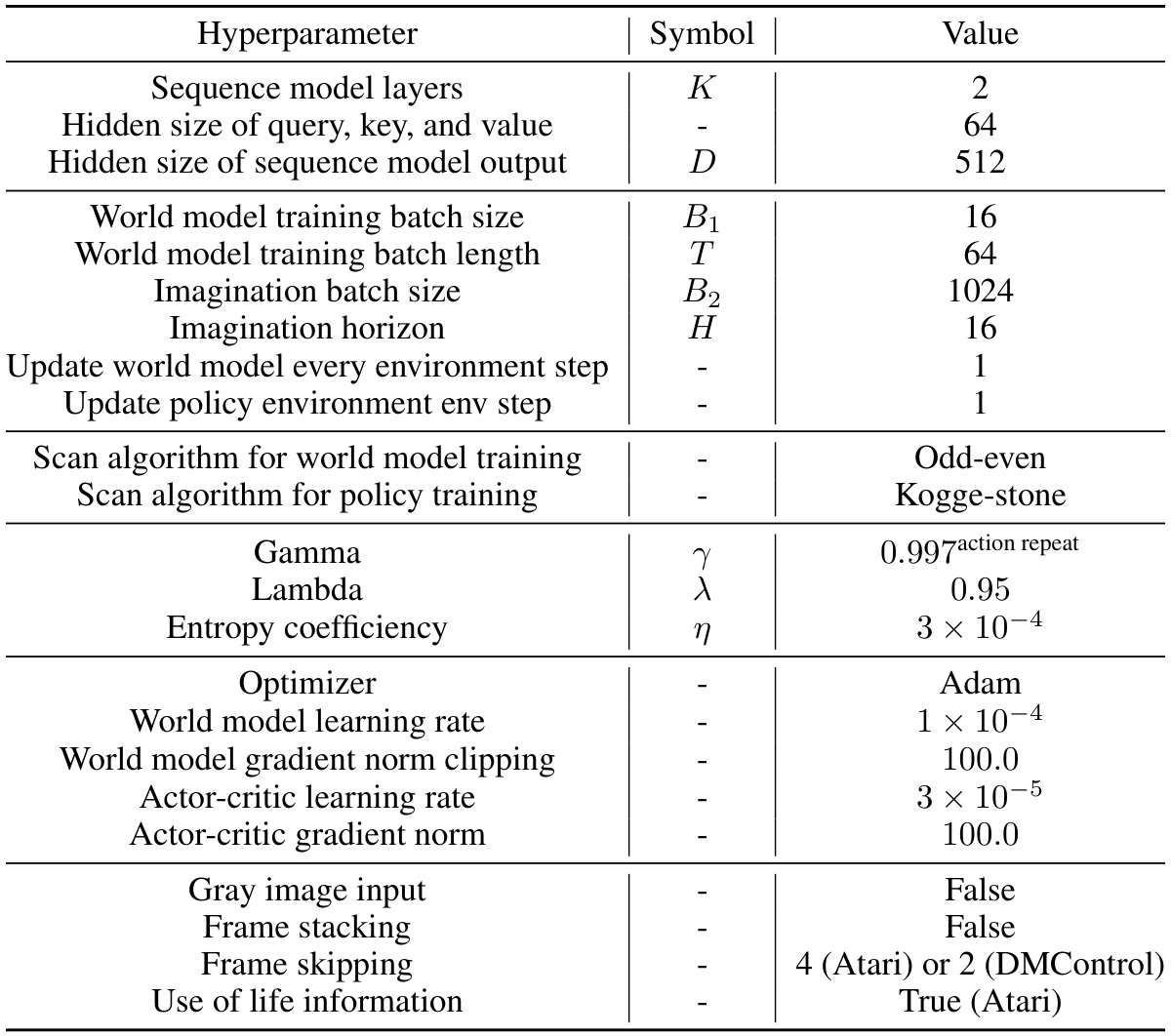
This table details the architecture of the image encoder used in the PaMoRL model. It lists each module in the encoder (convolutional layers, batch normalization, activation functions, and fully connected layers), along with the output tensor shape for each module. This allows readers to understand the progression of data transformations within the encoder as it processes input images.

This table compares the computational complexities of different neural network architectures (Attention, RNN, SSM, Linear Attention) used in sequential modeling across training, inference, and imagination steps. It highlights the impact of parallelization and other factors on computational efficiency, especially in relation to sequence length (L) and imagination horizon (H). The table also notes the unique properties of the compared architectures, such as their capability for parallel reset and selective computation.

This table compares the computational complexity of different neural network architectures (Attention, RNN, SSM, and Linear Attention) used in the model learning and policy learning stages of Model-based Reinforcement Learning (MBRL). It breaks down the complexity in terms of training, inference, and imagination steps, and indicates whether each architecture allows for parallelization, the ability to reset the state, and the ability to be selective about the input.
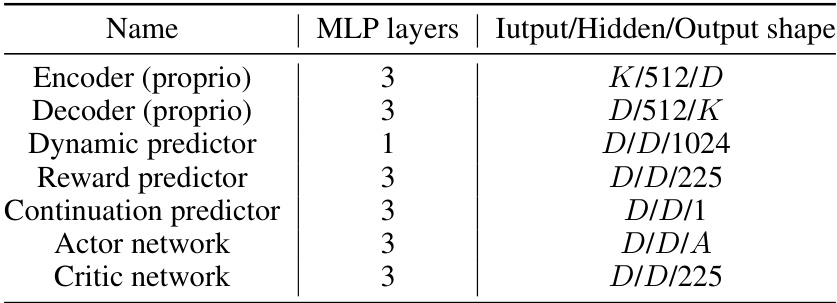
This table compares the computational complexities of different neural network architectures used in model-based reinforcement learning (MBRL) in terms of training, inference, and imagination steps. It highlights the trade-offs between complexity and parallelization capabilities of various architectures, including attention mechanisms, recurrent neural networks (RNNs), and state-space models (SSMs). The table also notes the impact of using parallel scan algorithms on the complexity of some of these architectures. The table specifically analyzes the step complexities of different architectures, taking into account the sequence length (L) and imagination horizon (H), illustrating the suitability of various architectures for different tasks and the impact of parallelization techniques.
This table compares the computational complexities of various neural network architectures (Attention, RNN, SSM, and Linear Attention) used in sequence modeling, across training, inference, and imagination stages. It highlights the impact of parallelization and other factors on computational cost and explores the trade-off between computational complexity and model expressiveness.

This table presents the results of the Atari 100k benchmark experiment. It compares the performance of PaMoRL against several other methods across 26 different Atari games. The scores are human-normalized, and the best and second-best scores are highlighted. The table shows average and median scores and the number of games where each method outperforms humans.

This table presents the average runtime for experiments conducted on different tasks. The tasks include the Atari 100K benchmark, along with easy and hard versions of DeepMind Control Suite tasks using proprioception and vision. The table shows that the Atari 100K benchmark took significantly longer to complete than the DeepMind Control Suite tasks, and that vision-based tasks generally took longer than those using proprioception. The ‘hard’ versions of DeepMind Control Suite tasks also took longer to complete than their ’easy’ counterparts.
Full paper#