↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Vision Transformers (ViTs) excel in capturing global context but suffer from quadratic complexity. State Space Models (SSMs) offer linear complexity but struggle with long-range dependencies, often requiring redundant multi-scan strategies. This necessitates a trade-off between efficiency and performance. Current approaches, like multi-scan ViTs, alleviate this but at the cost of increased redundancy and computation.
To address this, the paper introduces MSVMamba. This model uses a multi-scale 2D scanning technique across original and downsampled feature maps. This approach effectively learns long-range dependencies while reducing computational costs. Furthermore, MSVMamba integrates a Convolutional Feed-Forward Network (ConvFFN) to enhance channel mixing. The results demonstrate MSVMamba’s competitiveness, achieving high accuracy across ImageNet, COCO, and ADE20K benchmarks, showing its practical value and superior efficiency compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly improves the efficiency and performance of state space models (SSMs) in computer vision tasks. By addressing the limitations of existing SSMs, this work opens new avenues for developing efficient and high-performing vision models, potentially leading to advancements in various applications such as image classification, object detection, and semantic segmentation.
Visual Insights#

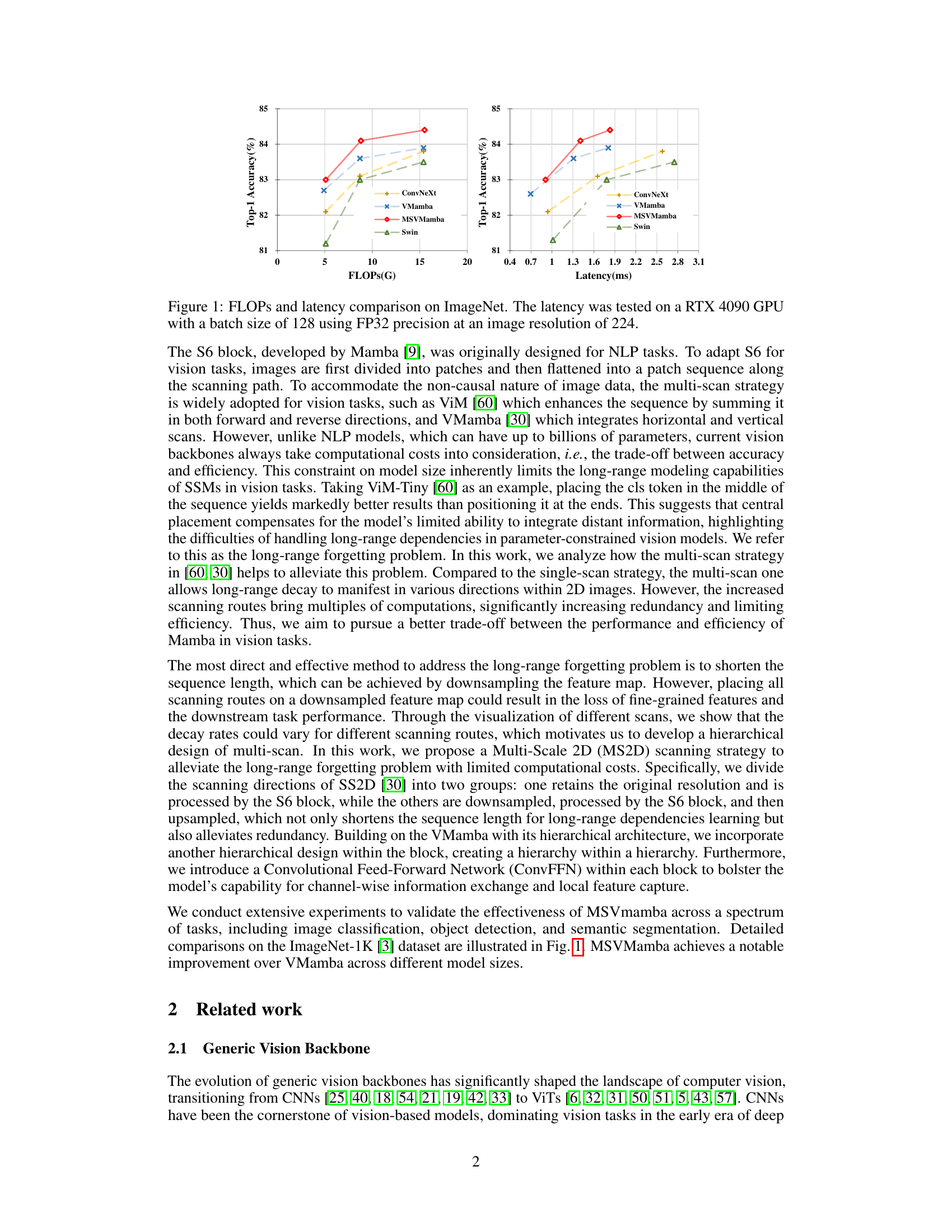
This figure compares the performance of different vision models (ConvNeXt, VMamba, MSVMamba, and Swin) on the ImageNet dataset in terms of FLOPs (floating point operations) and latency. It shows the trade-off between computational cost and accuracy. MSVMamba demonstrates a better balance of accuracy and efficiency compared to other models.
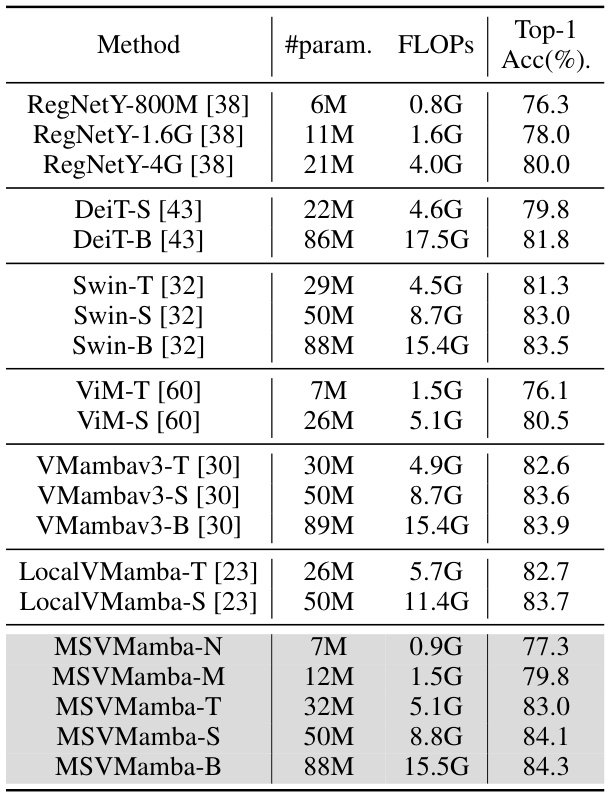
This table compares the top-1 accuracy of various vision models (including RegNetY, DeiT, Swin Transformer, ViM, VMambav3, LocalVMamba, and MSVMamba) on the ImageNet-1K dataset. The models are categorized by their parameter count and FLOPS to show the trade-off between model size, computational cost, and accuracy. MSVMamba models are shown for comparison against established and related methods.
In-depth insights#
Multi-Scale SSMs#
Multi-scale state space models (SSMs) represent a powerful paradigm shift in processing sequential data, offering a compelling alternative to traditional recurrent neural networks and transformers. The core idea revolves around representing the data as a sequence of states evolving over time, governed by a linear dynamical system. The multi-scale aspect introduces significant advantages, allowing the SSM to capture both fine-grained details (at smaller scales) and broader contextual information (at larger scales). This is achieved through techniques such as applying the SSM to feature maps at multiple resolutions or through hierarchical state space structures. This approach addresses the limitations of single-scale SSMs, enhancing their performance in complex tasks involving long-range dependencies and diverse levels of detail, such as those found in computer vision and natural language processing. A key benefit is the ability to leverage long-range dependencies efficiently, a significant challenge for many sequential models. By incorporating information from multiple scales, the SSM avoids the limitations of local receptive fields found in some approaches. Further, multi-scale SSMs offer a pathway to improving computational efficiency by operating on lower resolution data for coarser scale processing while maintaining detailed information at finer scales. This is crucial for deploying complex models on resource-constrained devices. The development of effective multi-scale SSM architectures requires careful consideration of data representation, scanning strategies, and the interplay between different scales. However, the potential of this approach remains vast.
MS2D Scanning#
The proposed Multi-Scale 2D (MS2D) scanning strategy offers a significant improvement over existing multi-scan approaches by addressing the computational redundancy and long-range dependency limitations of State Space Models (SSMs) in vision tasks. Instead of applying multiple scans to the full-resolution feature map, which is computationally expensive, MS2D cleverly divides the scanning directions into two groups. One group processes the original resolution map, focusing on fine-grained features. The other processes a downsampled map, reducing the computational cost while still capturing long-range dependencies. This hierarchical approach provides a superior balance between accuracy and efficiency, as demonstrated by the experimental results. The key insight of MS2D lies in its ability to maintain high accuracy with drastically reduced computational load. This is achieved by strategically combining high-resolution scans that preserve crucial details with lower-resolution scans for capturing the broad context. This allows MS2D to effectively resolve the long-range forgetting problem inherent in SSMs while avoiding the inefficiencies of redundant computation found in existing multi-scan methods.
ConvFFN Impact#
The integration of the Convolutional Feed-Forward Network (ConvFFN) within the Multi-Scale Vision Mamba (MSVMamba) architecture demonstrates a notable impact on performance. ConvFFN acts as a channel mixer, effectively addressing the inherent limitation of State Space Models (SSMs) in vision tasks, which often struggle with channel mixing. By incorporating ConvFFN, MSVMamba significantly improves its ability to exchange information across channels. This leads to a substantial enhancement in feature representation and a boost in overall model accuracy. The experimental results highlight that the ConvFFN contributes significantly to performance gains across various datasets and tasks. Although the specific improvement varies with the model size and the task, the consistent positive impact across all test settings strongly suggests the importance of ConvFFN as a key component of the MSVMamba architecture. Therefore, incorporating ConvFFN is vital to the model’s success and demonstrates its effectiveness in improving the performance of SSMs in computer vision applications.
Efficiency Gains#
Analyzing efficiency gains in the context of a research paper requires a multifaceted approach. Computational complexity is a primary concern; algorithms with lower complexity (e.g., linear vs. quadratic) directly translate to faster processing. Parameter reduction is another key aspect; smaller models require less memory and computation, leading to quicker training and inference. Hardware acceleration plays a crucial role; designs optimized for specific hardware architectures (like GPUs) significantly boost performance. Algorithmic optimizations, such as improved scanning strategies or novel network architectures, can lead to substantial speedups without sacrificing accuracy. Finally, a thorough evaluation needs to consider real-world scenarios, benchmarking against state-of-the-art methods to demonstrate tangible performance advantages.
Future of SSMs#
The future of State Space Models (SSMs) in computer vision is exceptionally promising. Their linear complexity offers a significant advantage over Vision Transformers (ViTs) for handling high-resolution images and long sequences, crucial for real-world applications. Further research should focus on addressing the limitations of long-range dependency modeling, potentially through more sophisticated scanning strategies or architectural improvements. Combining SSMs’ strengths with the localized feature extraction capabilities of CNNs is another key area for exploration. Ultimately, the effectiveness of SSMs will hinge on their ability to improve efficiency while maintaining accuracy and generalizability, especially for large-scale datasets and complex tasks. Hardware-aware designs will also be crucial for widespread adoption, enabling faster training and inference.
More visual insights#
More on figures

This figure visualizes the decay rate of influence along horizontal and vertical scanning routes in the VMamba model. The decay rate represents how quickly the influence of a token diminishes as the distance from the central token increases. The horizontal and vertical scan plots show this decay along each scan direction. The decay ratio plot shows the ratio between the decay rates of the horizontal and vertical scans, and the binary decay ratio plot displays a binarized version of this ratio. These plots illustrate the long-range forgetting problem faced by the VMamba model and motivate the use of the multi-scan strategy to alleviate this issue.
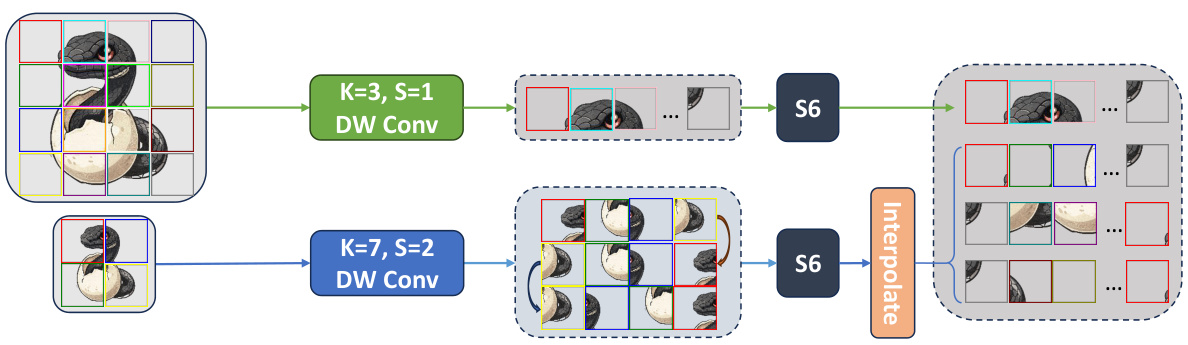
This figure illustrates the multi-scale 2D selective scan. The input image is processed via two depthwise convolutions (DW Conv) with different kernel sizes (K) and strides (S). The first DW Conv (K=3, S=1) maintains the original resolution, while the second (K=7, S=2) downsamples the input. Each resulting feature map is then processed by an S6 block. The outputs of these S6 blocks are subsequently interpolated to enhance the feature representation.

The MS3 block is a core component of the proposed MSVMamba model. It integrates a Multi-Scale Vision Space State (MSVSS) block and a Convolutional Feed-Forward Network (ConvFFN) block to enhance feature extraction and information flow. The MSVSS block utilizes a multi-scale 2D scanning technique to capture both fine-grained and coarse-grained features from multi-scale feature maps. The ConvFFN block then facilitates information exchange across different channels, improving the model’s capacity to capture richer feature representations. This hierarchical design improves accuracy and efficiency compared to previous approaches like VMamba.

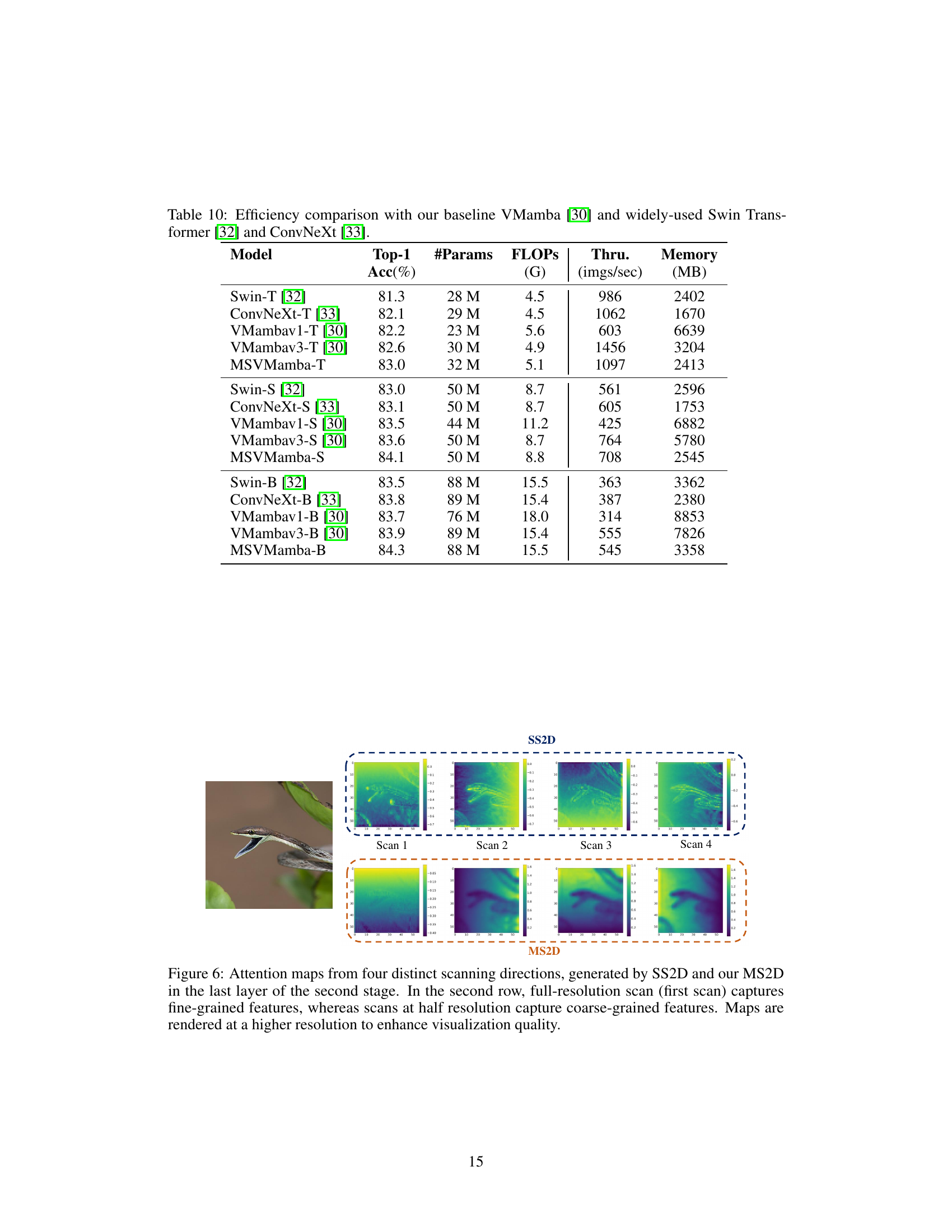
The figure shows attention maps for SS2D and MS2D scanning strategies used in the VMamba model. It visualizes how different scanning routes capture features at different scales. The left side (a) shows the SS2D strategy, where all four scans operate on the full-resolution feature map, resulting in detailed features. The right side (b) illustrates MS2D, which uses downsampled feature maps for three scans, resulting in attention that captures broader structural features while still preserving fine-grained detail from the full resolution scan.

This figure compares attention maps generated by SS2D and MS2D methods in the second stage of the model. The top row shows the attention maps from four different scanning directions using the SS2D method, and the bottom row shows the maps generated using the MS2D method. The MS2D method uses both full-resolution and half-resolution scans, allowing it to capture both fine-grained and coarse-grained features. The figure demonstrates the superior ability of the MS2D method to capture the relevant information.
More on tables

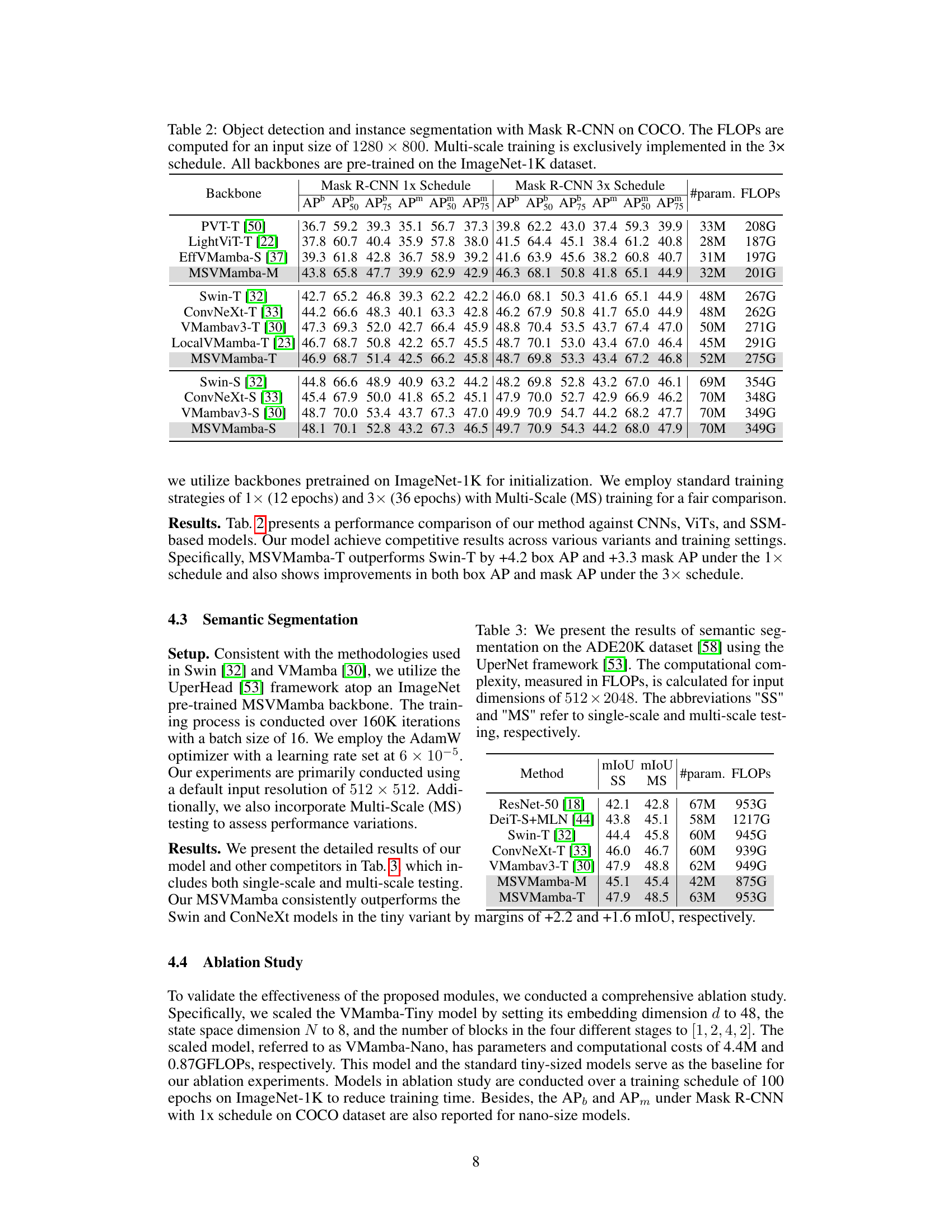
This table presents a comparison of different backbones (PVT-T, LightViT-T, EffVMamba-S, MSVMamba-M, Swin-T, ConvNeXt-T, VMambav3-T, LocalVMamba-T, MSVMamba-T, Swin-S, ConvNeXt-S, VMambav3-S, MSVMamba-S) used in Mask R-CNN for object detection and instance segmentation tasks on the COCO dataset. It shows the performance (AP, AP50, AP75, APs, APM) for both 1x and 3x training schedules. FLOPs and the number of parameters are also listed for each backbone.
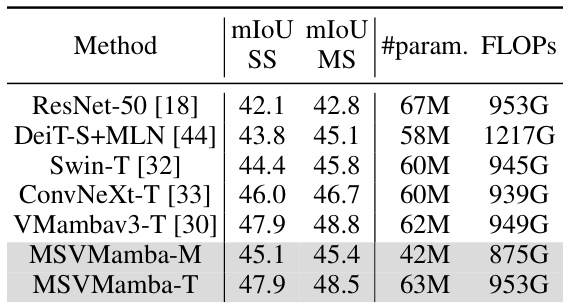
This table compares the performance of various semantic segmentation models on the ADE20K dataset. It shows the mean Intersection over Union (mIoU) scores for both single-scale (SS) and multi-scale (MS) testing. The table also includes the number of parameters and FLOPs (floating point operations) for each model, providing a comprehensive comparison of model efficiency and accuracy.

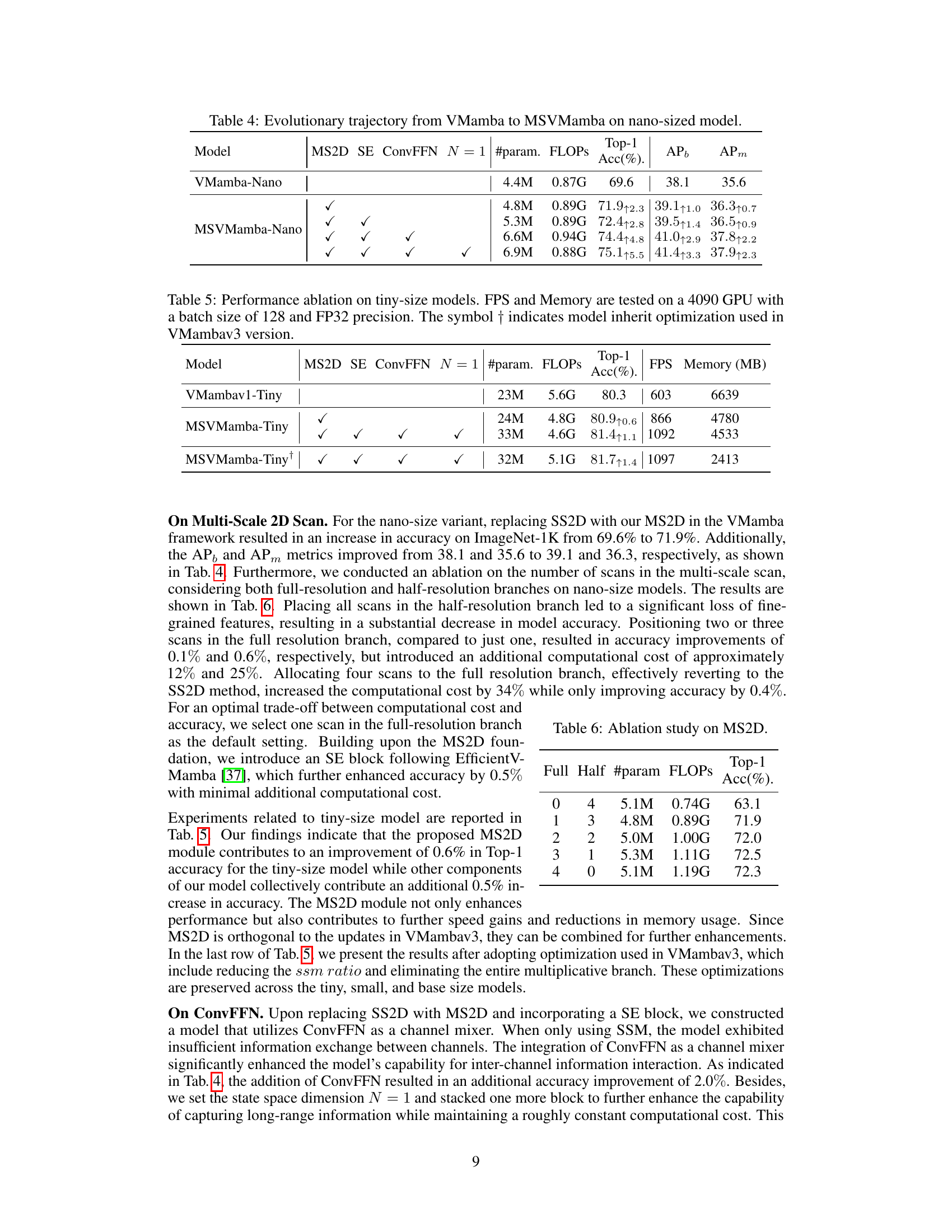
This table shows the impact of progressively adding MS2D, SE, and ConvFFN components to a nano-sized VMamba model. It demonstrates how each addition affects the model’s performance in terms of ImageNet Top-1 accuracy, COCO APb, and APm. The table illustrates the performance gains achieved by incorporating the proposed MSVMamba features.
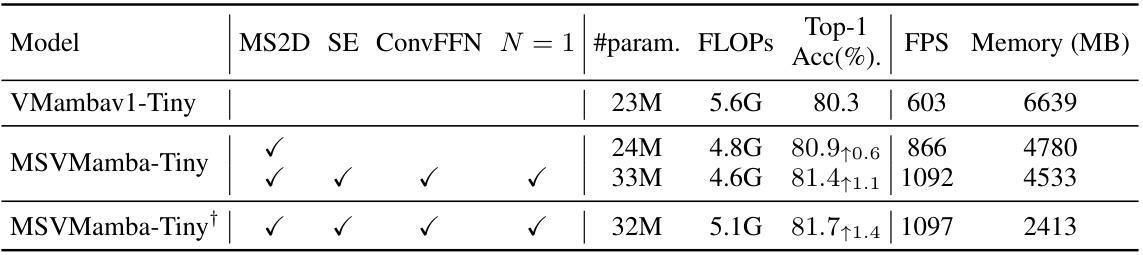
This table presents the ablation study results on tiny-size models. It shows the impact of different components (MS2D, SE, ConvFFN, N=1) on the model’s performance. The metrics reported include Top-1 accuracy, FPS (frames per second), and memory usage. The results are compared against the baseline VMambav1-Tiny model, highlighting the improvements achieved by adding each component. Note that the last row shows results with additional optimizations inherited from VMambav3.
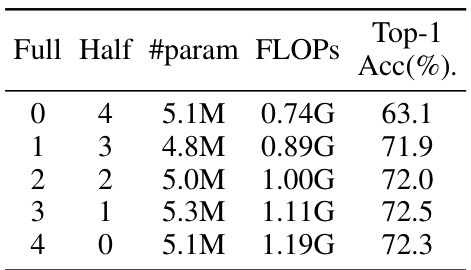
This table presents an ablation study on the effect of different configurations of the Multi-Scale 2D (MS2D) scanning strategy on the model’s performance. It shows the number of scanning routes used at full resolution and half resolution, the number of parameters, FLOPs, and Top-1 accuracy on ImageNet. The results demonstrate that using a combination of full and half resolution scanning routes achieves the best performance.

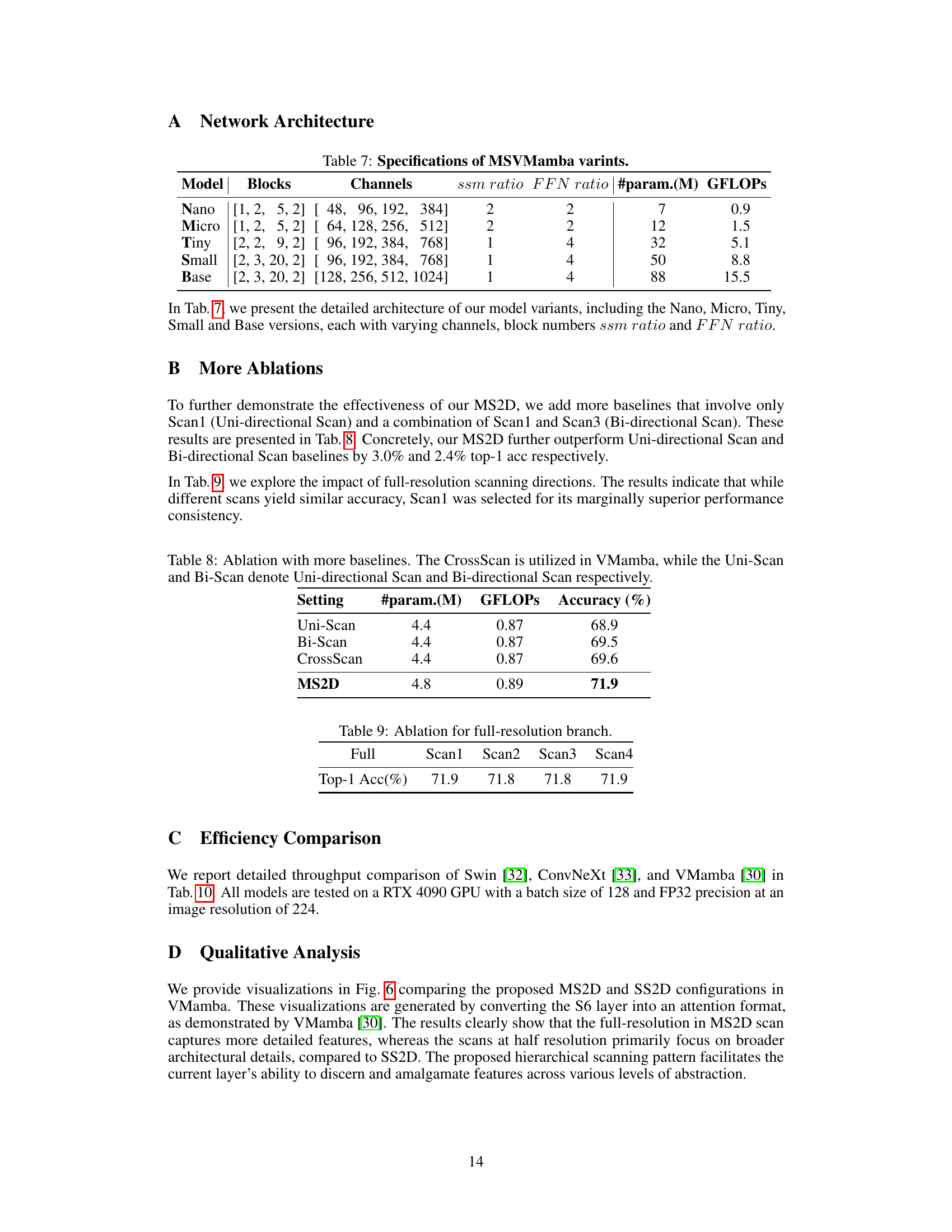
This table presents the detailed architectural specifications for different variants of the MSVMamba model. It shows the number of blocks used in each stage, the number of channels in each block, the SSM ratio, the FFN ratio, the total number of parameters (in millions), and the GFLOPs for each variant (Nano, Micro, Tiny, Small, and Base). These specifications illustrate the scalability of the MSVMamba architecture across various model sizes and computational budgets.
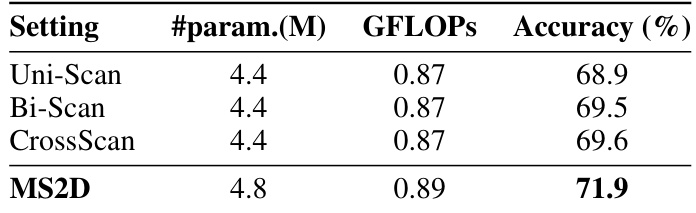
This table presents the ablation study results comparing the performance of different scanning strategies in the context of the MS2D (Multi-Scale 2D) scanning approach. It shows the parameter count, GFLOPs (floating point operations), and accuracy for three baseline scanning strategies (Uni-Scan, Bi-Scan, and CrossScan) and the proposed MS2D method. The results demonstrate the effectiveness of the MS2D approach in improving the accuracy, particularly compared to the simpler uni-directional and bi-directional scanning methods.

This table presents the ablation study results for the full-resolution branch in the MS2D (Multi-Scale 2D) scanning strategy. It shows the Top-1 accuracy achieved when using only one of the four scanning routes (Scan1, Scan2, Scan3, Scan4) compared to using all four routes (‘Full’). The results indicate minimal performance differences among the various routes, with Scan1 chosen as the default due to its superior performance consistency.

This table compares the top-1 accuracy of various vision models on the ImageNet-1K dataset. It shows the model name, the number of parameters (#param.), the number of GFLOPs (floating-point operations), and the achieved top-1 accuracy (%). Models are compared across different scales to showcase performance differences. The table is organized to help readers compare model performance considering the trade-off between model size and accuracy.
Full paper#