↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) training is computationally expensive due to the quadratic cost of self-attention and the use of fixed-length token sequences created by randomly concatenating documents and chunking them (concat-and-chunk). This method suffers from cross-document attention, inefficient computational cost, and potentially distorted sequence length distribution. The concat-and-chunk approach leads to underutilization of shorter documents and unnecessary computation.
Dataset Decomposition (DD) is proposed to tackle these issues. DD decomposes the training dataset into buckets of sequences with the same length, all extracted from individual documents. The authors use variable sequence lengths and batch sizes during training, sampling simultaneously from all buckets with a curriculum. Experiments show significant improvements in training speed (up to 6x faster) and data efficiency (over 4x) with enhanced performance on standard language modeling benchmarks and long-context tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) because it presents a novel training technique that significantly speeds up the training process without sacrificing accuracy. This is achieved by addressing the limitations of existing approaches, such as concat-and-chunk, and the quadratic cost of attention. The proposed method not only improves efficiency but also enhances model performance, making it a valuable contribution to the field.
Visual Insights#
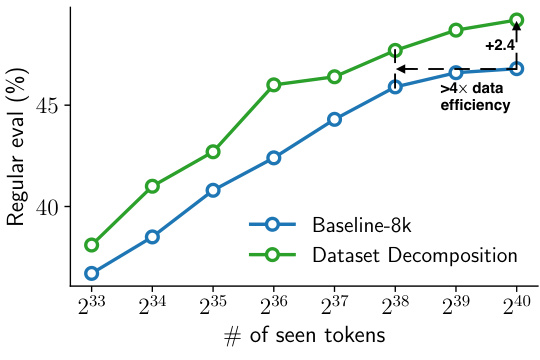
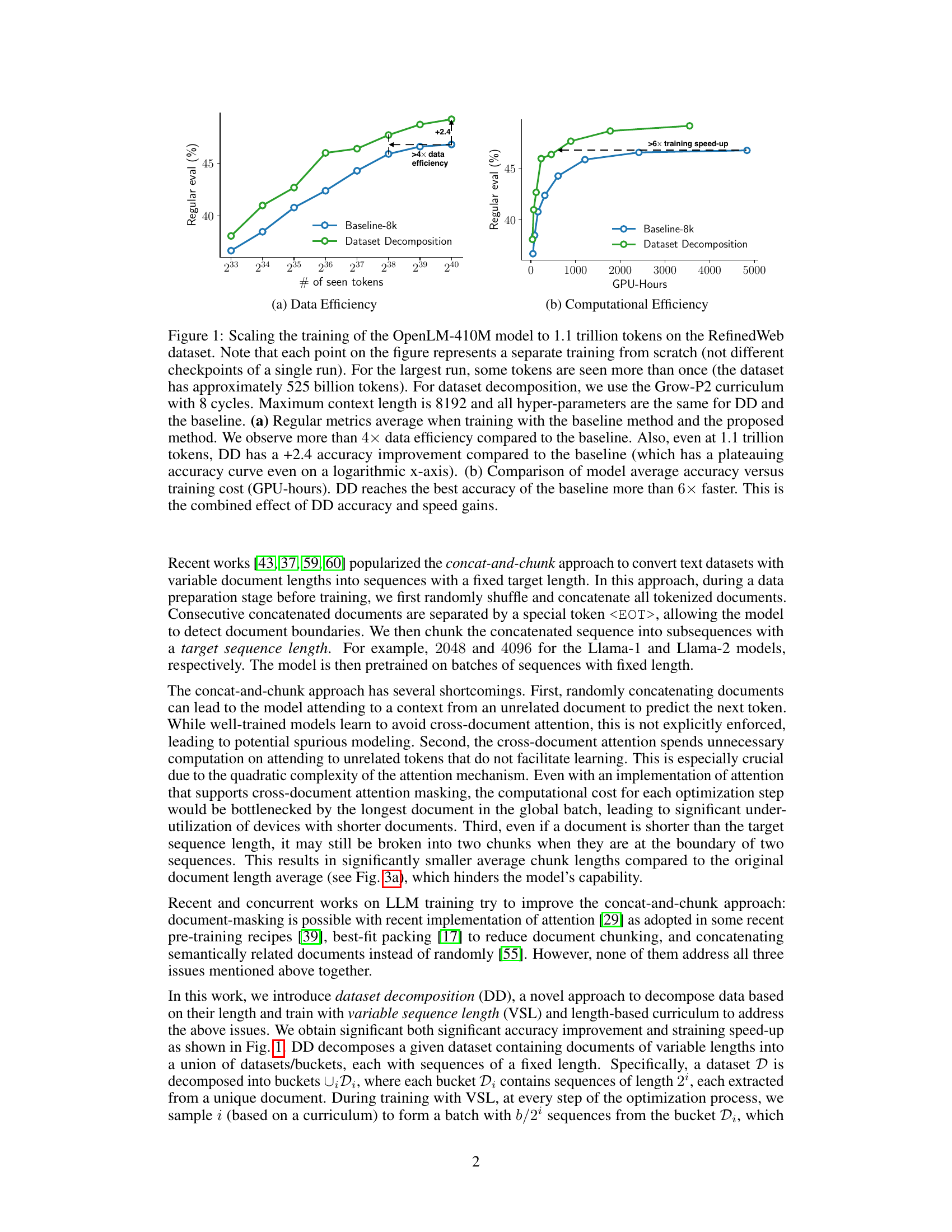
This figure shows the results of scaling the training of the OpenLM-410M language model up to 1.1 trillion tokens using the RefinedWeb dataset. It compares the performance of the baseline concat-and-chunk approach against the proposed dataset decomposition method. Two subfigures are presented: (a) demonstrates the data efficiency of each approach by plotting regular evaluation metrics against the number of seen tokens. Dataset decomposition shows significantly better data efficiency, achieving a 4x improvement, and maintaining a +2.4 accuracy boost over the baseline even with far more training data. (b) shows the computational efficiency by comparing model accuracy against training cost in GPU hours. Dataset Decomposition reaches the same accuracy as the baseline model over 6 times faster.
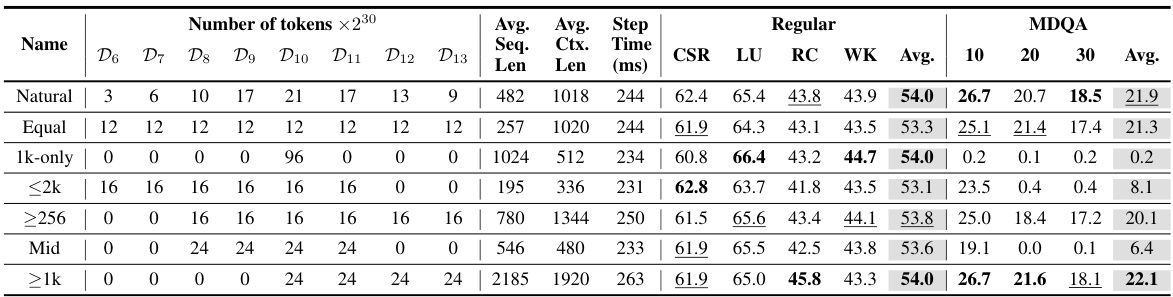
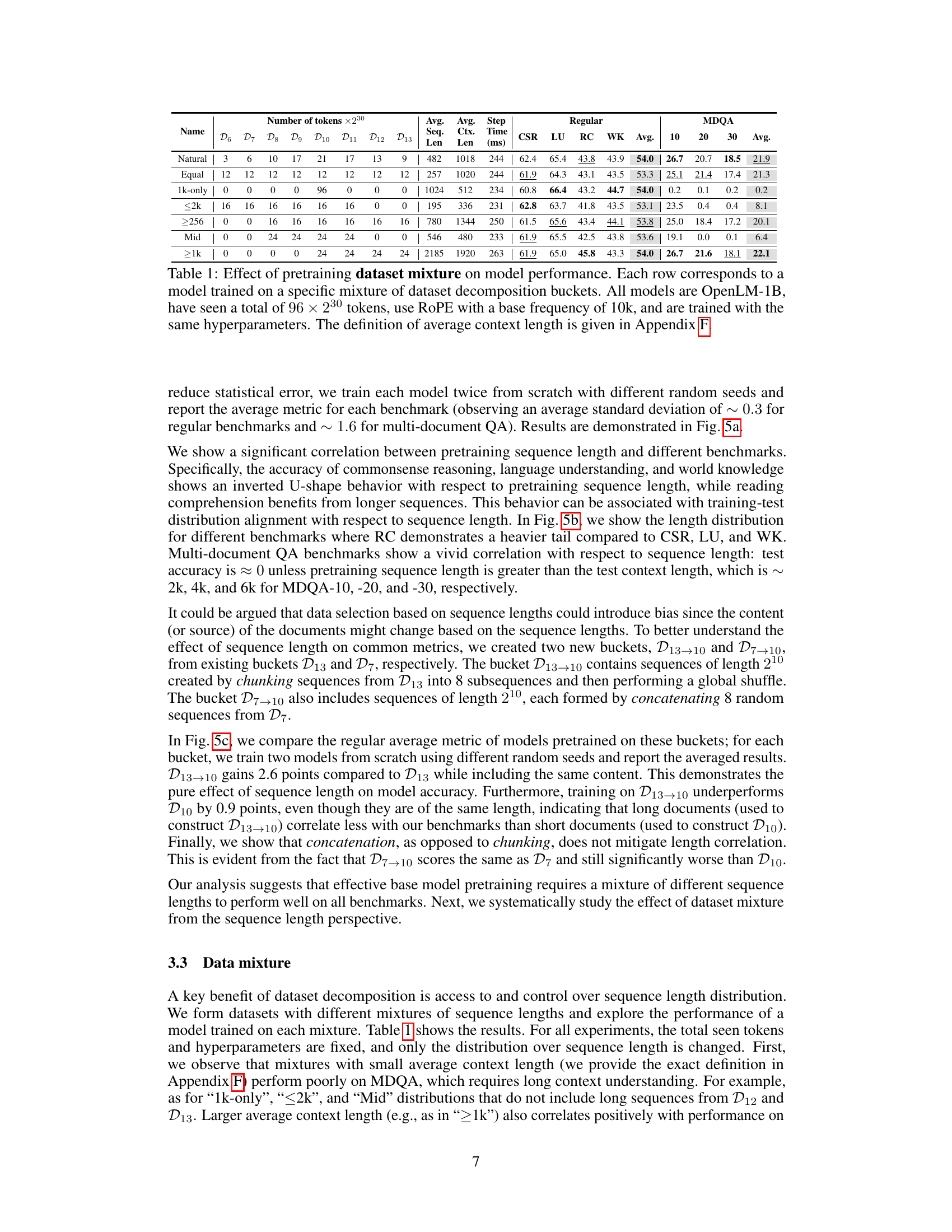
This table shows the impact of different mixtures of dataset decomposition buckets on the performance of the OpenLM-1B model. Each row represents a model trained on a specific mixture, with a total of 96 × 220 tokens. The model uses Rotary Positional Embedding (RoPE) with a base frequency of 10,000 and consistent hyperparameters across all rows. The average sequence and context lengths are reported, along with performance metrics on common benchmarks (CSR, LU, RC, WK, Avg.) and long-context tasks (MDQA 10, 20, 30, Avg.).
In-depth insights#
LLM Dataset Fix#
LLM Dataset Fix addresses the inherent challenges of training large language models (LLMs) on datasets with variable-length sequences. The conventional approach of concatenating and chunking documents into fixed-length sequences leads to inefficiencies due to wasted computation on cross-document attention and the underutilization of shorter documents. Dataset Decomposition, a novel technique proposed, tackles these problems by reorganizing the dataset into buckets of sequences with the same length, drawn from unique documents. This allows for variable sequence length training with a length-based curriculum, resulting in significant computational savings. The core innovation lies in avoiding cross-document attention and tailoring the computational cost to the actual sequence length rather than an arbitrary fixed maximum. By sampling from different buckets during training, a curriculum is established that moves from short to longer sequences. This not only makes training more efficient but also improves the model’s performance on language modeling and long-context benchmarks. The effectiveness is demonstrated via extensive empirical analysis showing significant gains in data and computational efficiency, ultimately accelerating training time while improving model accuracy.
Variable Seq. Len.#
The concept of ‘Variable Seq. Len.’ (Variable Sequence Length) in the context of large language model (LLM) training signifies a paradigm shift from the traditional fixed-length sequence approach. Instead of forcing documents into pre-defined lengths, variable sequence length training directly utilizes sequences of varying lengths extracted from documents, accurately reflecting the natural distribution of text lengths. This is crucial as fixed-length methods often result in inefficient use of computational resources and suboptimal model performance. By adapting the sequence lengths to the actual document content, variable length training potentially leads to faster convergence, improved data efficiency, and enhanced performance on long-context tasks. The core challenge remains in managing computational costs associated with attention mechanisms, which scale quadratically with sequence length; however, techniques like curriculum learning and careful sampling strategies can mitigate this, resulting in significant overall training gains. Dataset decomposition, a method suggested in the paper, strategically breaks down the dataset into buckets of sequences with similar lengths, further refining the training process and enabling efficient batching. This approach directly addresses many of the shortcomings of traditional fixed-length methods while capitalizing on the advantages of training with natural sequence lengths, offering a powerful new strategy for LLM training.
Curriculum Training#
Curriculum learning in the context of large language model (LLM) training involves a carefully designed strategy of presenting training data in a specific order, starting with simpler, easier-to-learn examples and gradually increasing the complexity. This approach, inspired by how humans learn, aims to improve model performance and accelerate training. In the paper, a length-based curriculum is proposed, where sequences of shorter lengths are presented earlier in training, followed by progressively longer sequences. This is implemented by sampling from different ‘buckets’ of sequences, each containing fixed-length sequences extracted from a single document. The curriculum is not static but evolves dynamically based on the current model capabilities, leading to improved training stability and efficiency. The use of variable sequence length training enhances performance gains by adapting the computational cost to the actual sequence length, rather than being fixed to a maximum. The curriculum’s effectiveness is demonstrated by significant improvements in standard language evaluations and long-context benchmarks, showcasing its potential to optimize LLM training across diverse aspects of performance.
Computational Gains#
The research paper highlights significant computational gains achieved through dataset decomposition and variable sequence length training. Dataset decomposition breaks down the dataset into smaller, manageable chunks, each with sequences of the same length from a single document, thereby avoiding the computational overhead of attending to irrelevant tokens across different documents. This method reduces the quadratic cost associated with attention mechanisms, leading to considerable savings. The use of variable sequence length and batch sizes further optimizes computational efficiency by dynamically adjusting to document lengths, avoiding unnecessary attention calculations. The effectiveness is demonstrated by training a larger model with the same computational budget as a smaller baseline model, achieving up to 6x speedup in training. This technique offers a significant improvement in data efficiency, allowing for more efficient use of training resources and improved model performance. Curriculum learning incorporating variable sequence lengths is shown to enhance training stability and generalization, leading to improved model performance and accelerated training times.
Future of LLMs#
The future of LLMs hinges on addressing current limitations and exploring novel avenues. Efficiency gains are crucial, moving beyond computationally expensive training methods. This likely involves innovative architectures, optimized training techniques like dataset decomposition, and potentially hardware advancements. Enhanced capabilities are paramount; future LLMs will likely exhibit improved reasoning, common sense understanding, and reduced biases. Safety and ethics will continue to be central, necessitating robust safeguards against misuse and harmful outputs. The development of more explainable and interpretable models will foster trust and responsible deployment. Finally, seamless integration with diverse modalities (images, audio, video) is key, creating truly multimodal LLMs with broader applications and improved human-computer interaction. Achieving this future requires collaborative research efforts across multiple disciplines.
More visual insights#
More on figures
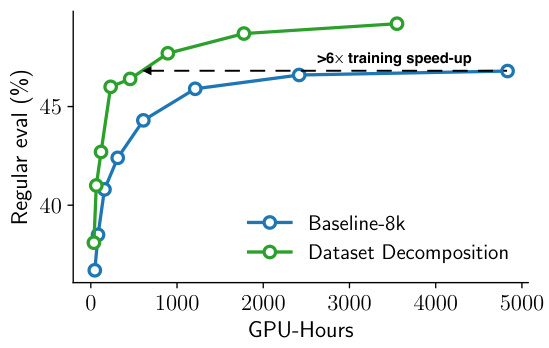
This figure shows the results of scaling the training of the OpenLM-410M language model on the RefinedWeb dataset up to 1.1 trillion tokens using two different methods: the baseline concat-and-chunk method and the proposed dataset decomposition (DD) method. Subfigure (a) demonstrates the superior data efficiency of DD, achieving a more than 4x improvement and a +2.4 accuracy increase compared to the baseline at 1.1 trillion tokens. Subfigure (b) showcases the significant computational efficiency gains offered by DD, reaching the same accuracy as the baseline more than 6 times faster, highlighting the combined benefits of data and computational speedup.
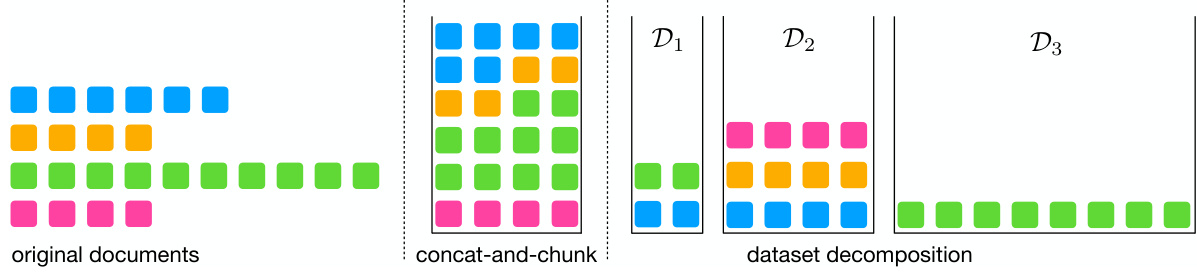
This figure illustrates the difference between the concat-and-chunk method and the proposed dataset decomposition method. The concat-and-chunk method concatenates documents of varying lengths and then chunks them into fixed-length sequences. This can lead to sequences that span multiple documents, resulting in cross-document attention. The dataset decomposition method, on the other hand, decomposes the dataset into buckets of sequences with the same length, each extracted from a single document. This eliminates cross-document attention and allows for more efficient training.

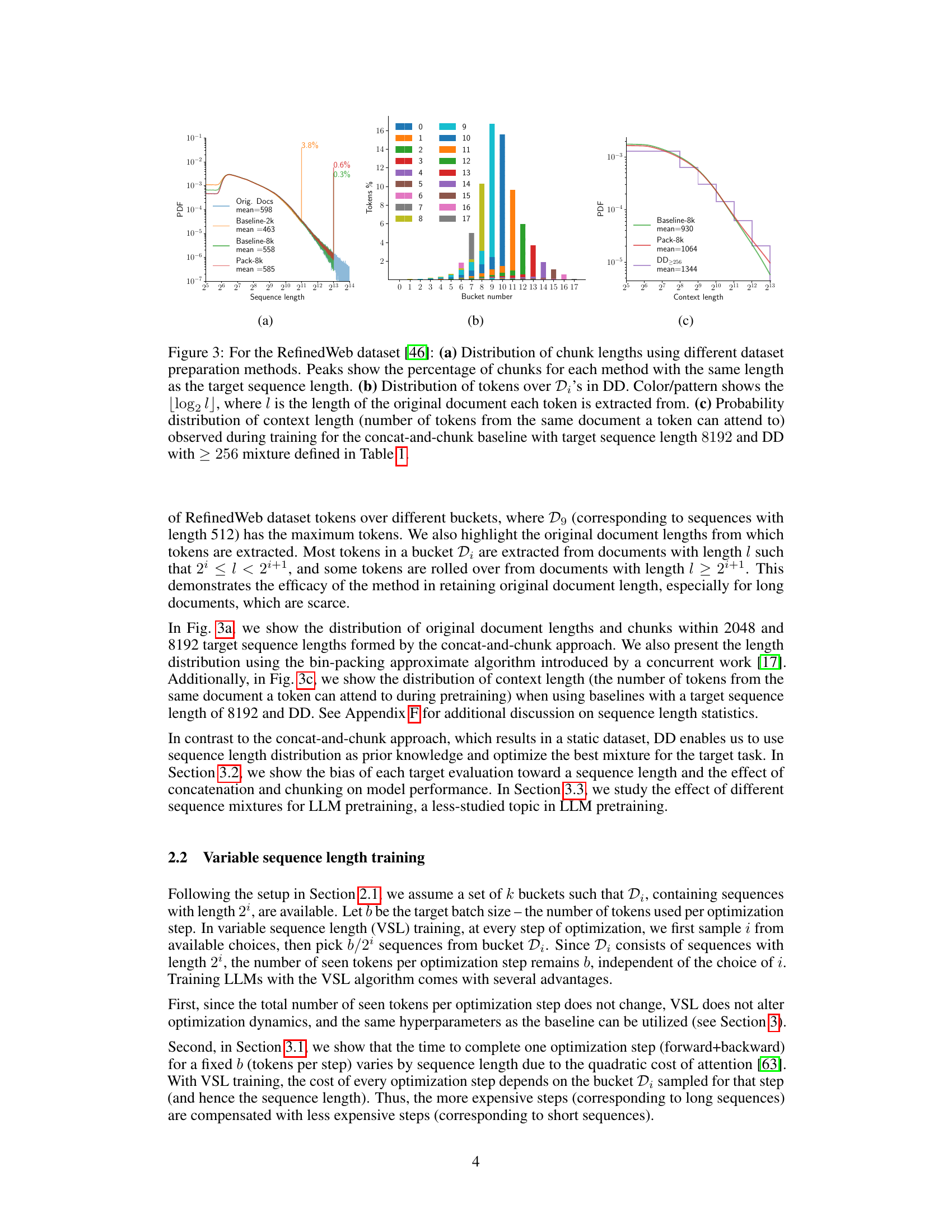
This figure compares the distribution of chunk lengths for different dataset preparation methods (concat-and-chunk with different target sequence lengths, best-fit packing, and dataset decomposition). It shows that dataset decomposition preserves the original document length better, leading to a more natural distribution of context lengths during training. Subplot (a) shows the chunk length distributions. Subplot (b) illustrates the distribution of tokens across different buckets in dataset decomposition, highlighting the alignment with the original document lengths. Subplot (c) contrasts the context length distribution (how far the model attends within a single document during training) across the methods.
This figure shows the results of scaling the training of the OpenLM-410M language model up to 1.1 trillion tokens using the RefinedWeb dataset. It compares the performance of the proposed Dataset Decomposition (DD) method against a baseline concat-and-chunk approach. Subfigure (a) demonstrates the significant improvement in data efficiency (more than 4x) and accuracy (+2.4) achieved by DD compared to the baseline. Subfigure (b) highlights the substantial speedup in training time (over 6x faster) using DD, while reaching the same accuracy as the baseline. The improvements are attributed to the combined effects of increased accuracy and faster training speed provided by DD.
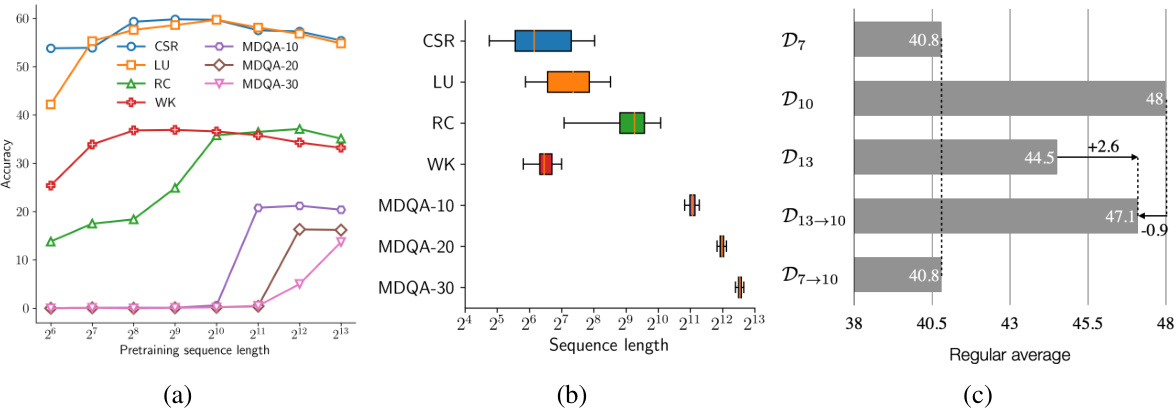
This figure analyzes the impact of pretraining sequence length on model performance. Panel (a) shows how accuracy on various benchmarks (Commonsense Reasoning, Language Understanding, Reading Comprehension, World Knowledge, and Multi-Document Question Answering) changes as the pretraining sequence length increases. Panel (b) illustrates the distribution of document lengths for those same benchmarks. Finally, panel (c) demonstrates the effects of modifying pretraining data by either chunking long sequences into smaller ones (D13→10) or concatenating short ones into longer ones (D7→10) on model performance, highlighting that maintaining the original document length distribution is crucial for optimal results.
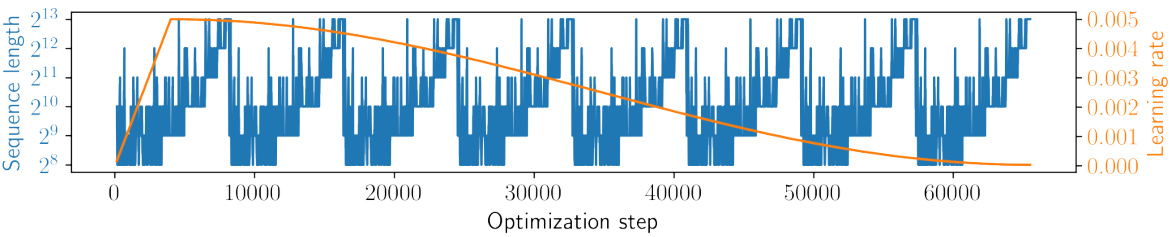
This figure visualizes the curriculum used in the dataset decomposition method. The x-axis represents the optimization steps during training. The blue bars show the length of the sequence sampled at each step (determined randomly, but biased by the curriculum), ranging from 256 to 8192 tokens. The orange line represents the learning rate schedule which follows a cosine curve with a warm-up period. The Grow-P2 curriculum with 8 cycles ensures a gradual increase in the proportion of longer sequences over the course of training.
This figure shows the results of scaling the training of the OpenLM-410M language model using two different methods: the baseline concat-and-chunk approach and the proposed dataset decomposition (DD) method. The training was performed on the RefinedWeb dataset with a total of approximately 1.1 trillion tokens. The figure highlights the superior data and computational efficiency of DD. Subfigure (a) demonstrates that DD achieves over 4x data efficiency and a 2.4 point accuracy improvement over the baseline. Subfigure (b) shows that DD achieves more than 6x faster training speed compared to the baseline.
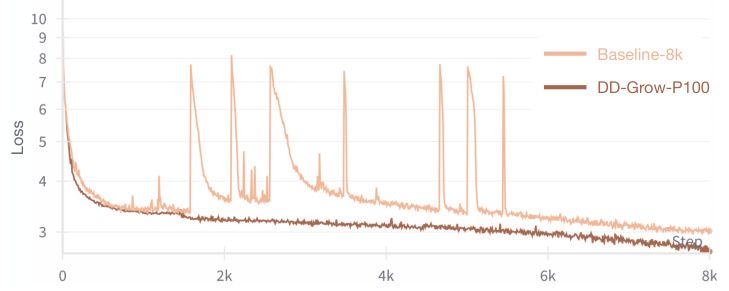
This figure compares the training loss curves for two different training methods: the Baseline-8k method and the Dataset Decomposition (DD) method with the ‘Grow-P100’ curriculum. Both methods used identical hyperparameters, a high learning rate (10^-2), and no gradient clipping. The key observation is that the DD method exhibits greater stability during training, indicating a more robust training process.
More on tables
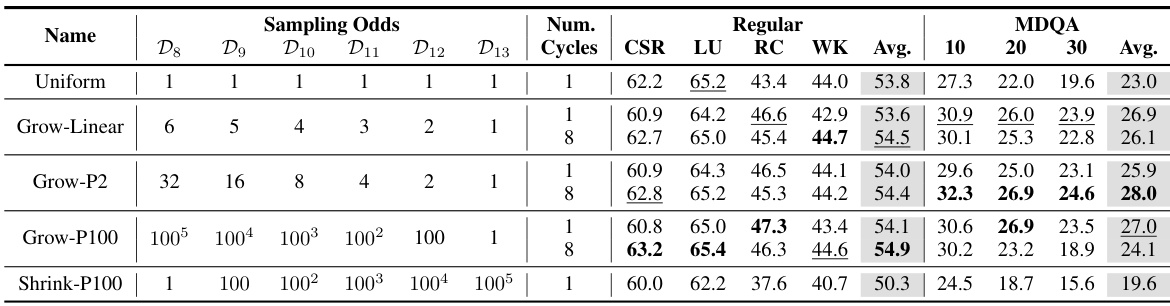
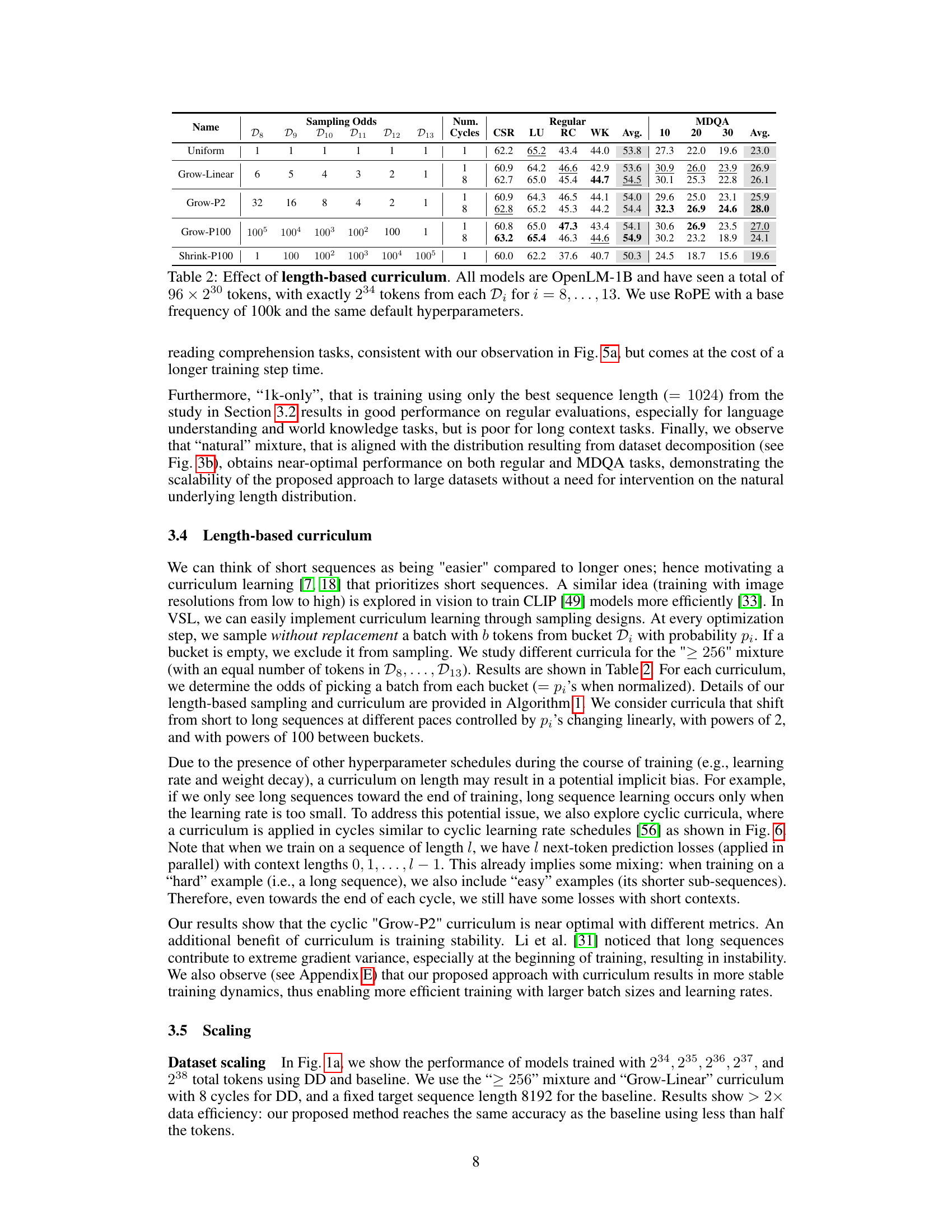
This table presents the results of experiments using different length-based curricula for training the OpenLM-1B model. Each row represents a different curriculum, characterized by the sampling odds assigned to each bucket (D8-D13), representing sequence lengths of 28 to 213 tokens. The ‘Uniform’ row serves as a baseline, while other rows show various strategies to increase the proportion of shorter sequences at the beginning of training and gradually increase the longer ones. The table shows the performance metrics across different evaluation benchmarks (CSR, LU, RC, WK) and multi-document question answering (MDQA) for each curriculum, with both short and long context performance.
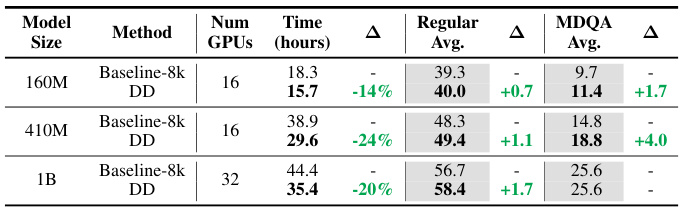
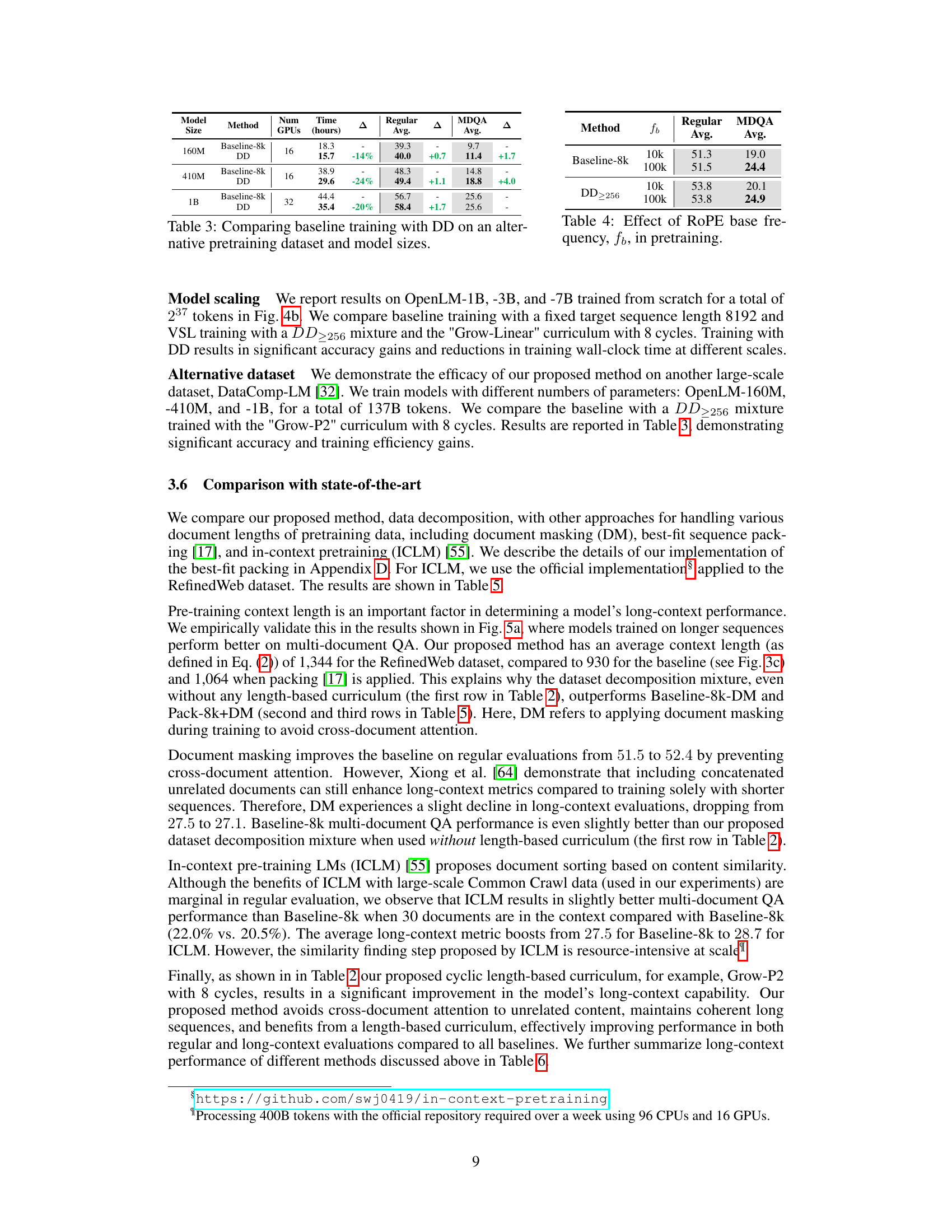
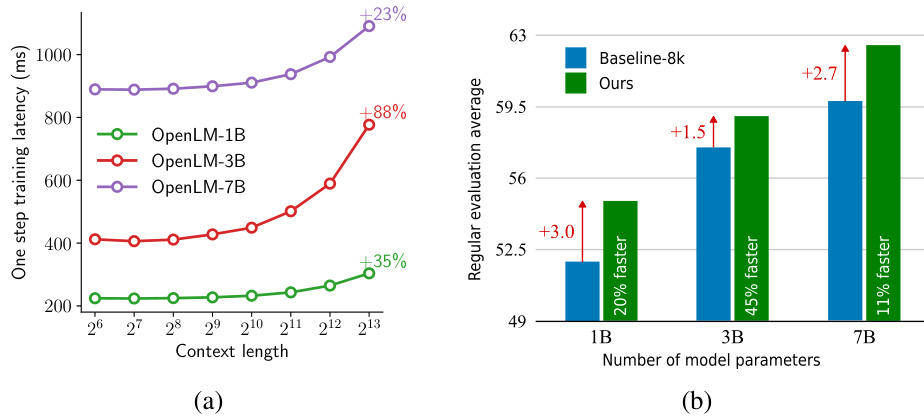
This table compares the performance of baseline training with 8k context length and dataset decomposition (DD) on different model sizes (160M, 410M, and 1B parameters) using an alternative dataset. The number of GPUs used, training time in hours, regular average accuracy, and MDQA average accuracy are reported for each model and method. The Δ column shows the percentage change in training time for DD compared to the baseline. The table highlights the efficiency gains of DD across different model scales.
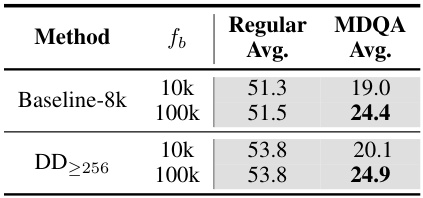
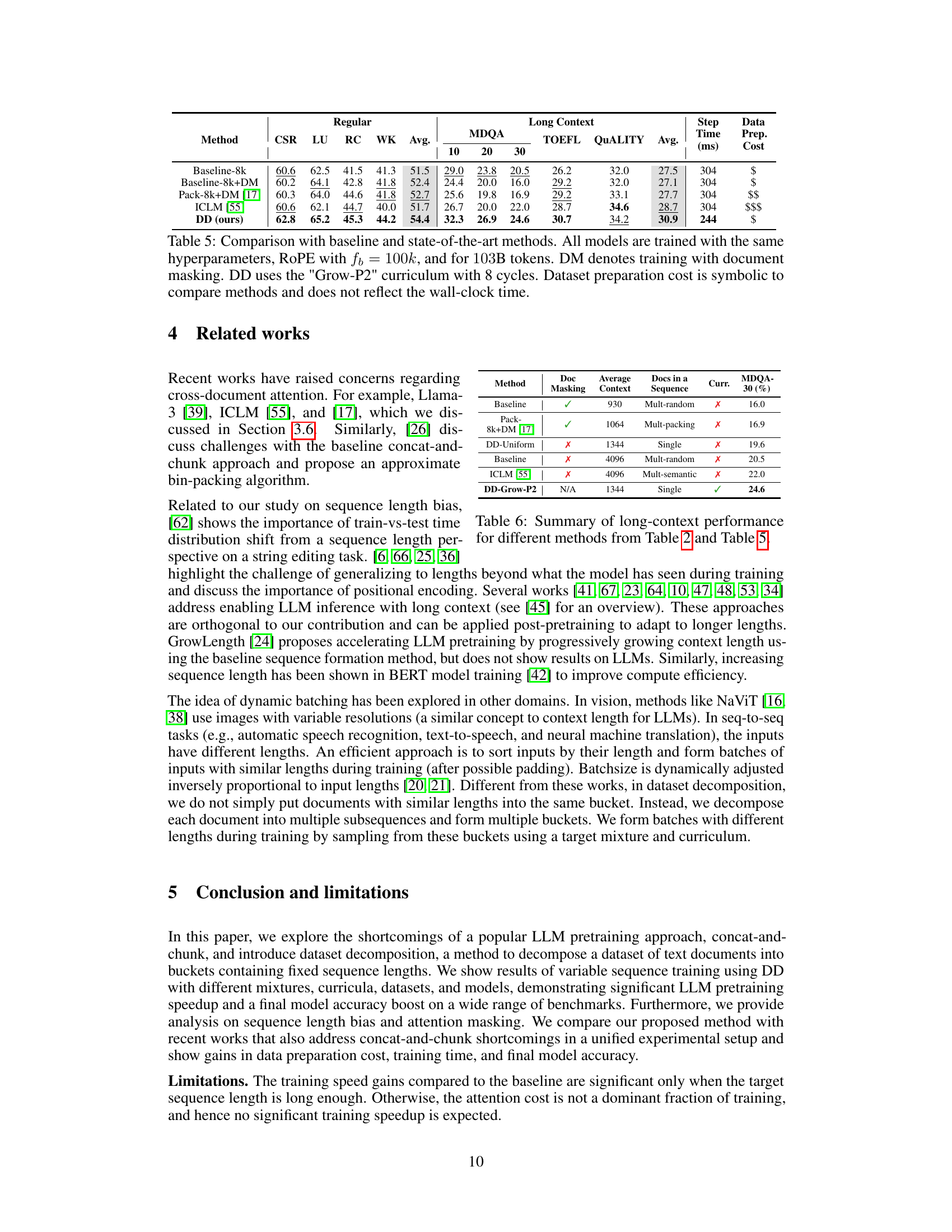
This table presents the results of experiments evaluating the impact of the RoPE (Rotary Positional Embedding) base frequency (fb) on the model’s performance. Two different base frequencies (10k and 100k) were tested for both the baseline method (Baseline-8k) and the proposed dataset decomposition method (DD≥256). The table shows that increasing the base frequency from 10k to 100k leads to a significant improvement in the MDQA (Multi-Document Question Answering) average, indicating that a larger base frequency is beneficial for long-context tasks.
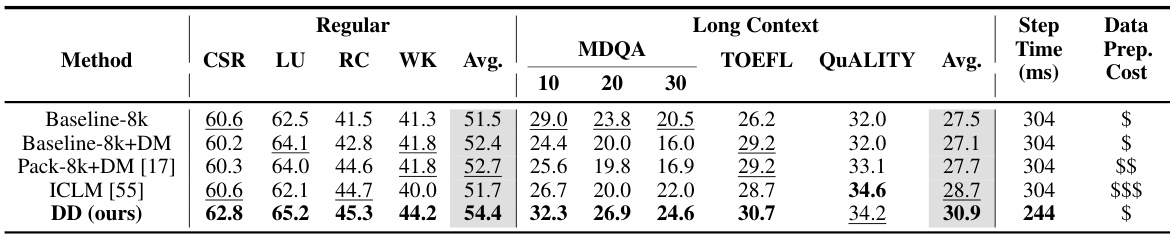
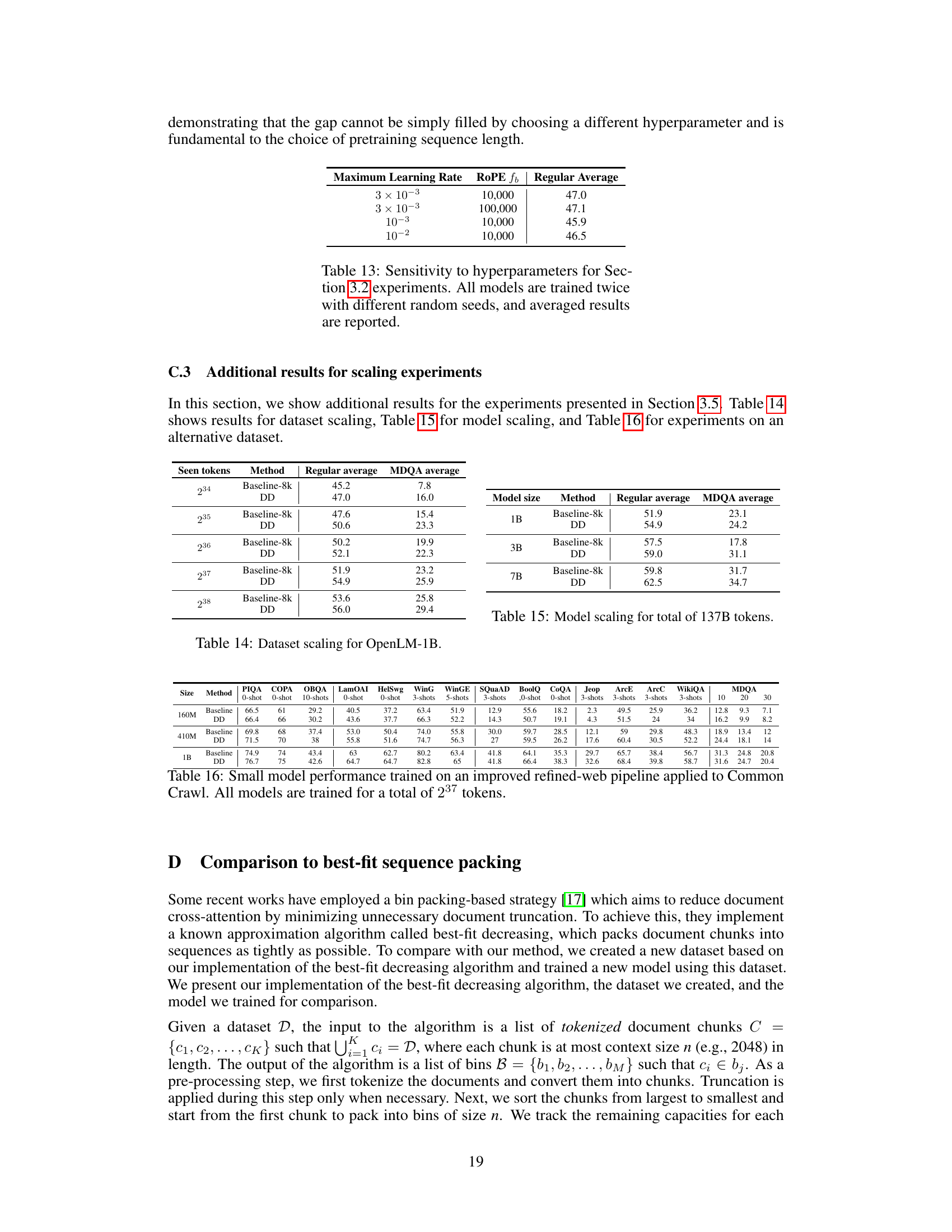
This table compares the performance of the proposed dataset decomposition method (DD) with several baseline and state-of-the-art methods for handling various document lengths in LLM pretraining. The performance metrics include standard language understanding benchmarks (CSR, LU, RC, WK) and long context benchmarks (MDQA, TOEFL, QUALITY). The table shows that DD outperforms the baselines across all metrics, achieving significant improvements in long-context tasks while maintaining comparable or better performance on regular tasks. The data preparation cost is denoted symbolically to indicate the relative effort required for each approach, rather than absolute resource use.
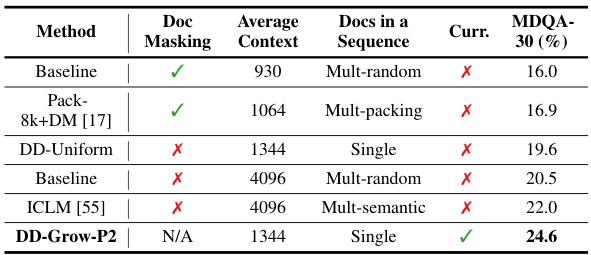
This table summarizes the performance of different methods on long-context tasks, specifically MDQA-30. It compares the baseline approach with document masking, best-fit packing with document masking, dataset decomposition with uniform sampling, baseline with longer context length, ICLM, and dataset decomposition with Grow-P2 curriculum. The table highlights the impact of different strategies (document masking, context length, curriculum) on long-context performance, showing that dataset decomposition with Grow-P2 curriculum significantly improves the results.

This table presents the results of experiments evaluating the effect of different mixtures of dataset decomposition buckets on the performance of an OpenLM-1B model. Each row represents a model trained on a specific combination of buckets, all using the same hyperparameters (except for the mixture of buckets). The table shows the performance across various metrics including regular evaluation average, commonsense reasoning (CSR), language understanding (LU), reading comprehension (RC), world knowledge (WK), and multi-document question answering (MDQA) with varying numbers of documents. The average sequence length and average context length used for each model are also reported. Appendix F provides further detail on the calculation of average context length.

This table presents the results of experiments evaluating the effect of different mixtures of dataset decomposition buckets on the performance of an OpenLM-1B model. The model was trained on 96 x 230 tokens total, using Rotary Positional Embedding (RoPE) with a base frequency of 10,000, and consistent hyperparameters. Each row shows a different mixture, indicating which buckets (with sequences of length 2i) were used in the training. The results are evaluated across various metrics, including several standard language understanding benchmarks and three long-context question answering benchmarks (MDQA-10, MDQA-20, MDQA-30). The table shows the performance impact of varying the distribution of sequence lengths used in training.

This table presents the results of experiments conducted to evaluate the impact of different mixtures of dataset decomposition buckets on the performance of an OpenLM-1B model. The model was trained on a total of 96*230 tokens using Rotary Positional Embeddings (RoPE) with a base frequency of 10k and consistent hyperparameters across all experiments. The table highlights how varying the proportion of sequences from different length buckets (representing different document lengths) affects overall performance metrics including common sense reasoning, language understanding, reading comprehension, and world knowledge, as well as long-context performance measured by the MDQA metric.

This table presents the results of experiments evaluating the impact of different mixtures of dataset decomposition buckets on model performance. Each row represents a model trained on a specific mixture, all using the OpenLM-1B architecture, the same hyperparameters, and a total of 96 x 230 tokens. The RoPE positional embedding method was used with a base frequency of 10,000. The table shows various performance metrics across different benchmarks for each mixture, highlighting the effect of the specific sequence length distribution in the training dataset.

This table presents the results of experiments evaluating the impact of different mixtures of dataset decomposition buckets on the performance of an OpenLM-1B model. Each row represents a model trained on a specific mixture, varying the number of sequences from each bucket. The total number of tokens seen by each model is constant (96 × 230). All models used Rotary Positional Embeddings (RoPE) with a base frequency of 10,000 and shared hyperparameters. The average context length, a key metric defined in Appendix F, is also reported, which influences model performance.
This table presents the results of experiments conducted to evaluate the impact of different mixtures of dataset decomposition buckets on the performance of the OpenLM-1B language model. Each row shows a different mixture, indicating the number of tokens from buckets of various sequence lengths (D6 to D13). The results are presented in terms of average performance metrics across several benchmarks and the average context length, providing insights into the relationship between training dataset composition and model performance. The hyperparameters, total number of tokens, and RoPE settings are kept constant to isolate the effect of dataset composition.

This table demonstrates the robustness of the findings in Section 3.2 to changes in hyperparameters. It shows that the choice of pretraining sequence length is fundamental, as the performance difference between different lengths persists even when hyperparameters like maximum learning rate and RoPE base frequency are adjusted.
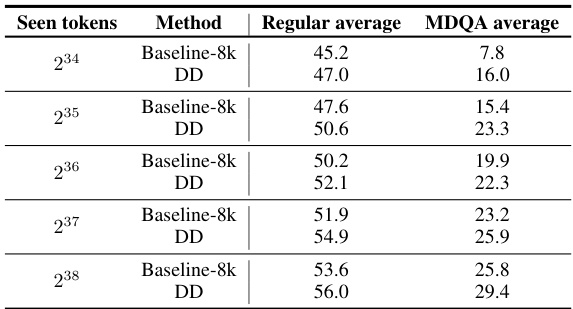
This table presents the results of experiments evaluating the effect of different mixtures of dataset decomposition buckets on the performance of an OpenLM-1B model. Each row represents a model trained on a specific mixture, with the total number of tokens and hyperparameters remaining constant across all experiments. The table shows that different mixtures of sequence lengths impact the performance on various benchmarks.
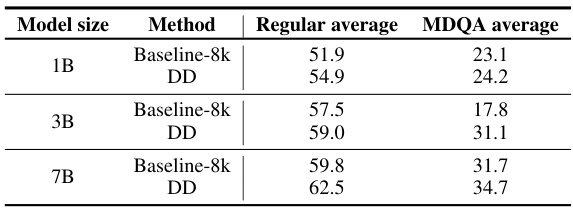
This table compares the performance of baseline training with 8k context length and dataset decomposition (DD) on OpenLM models of different sizes (160M, 410M, and 1B parameters). It shows the regular average accuracy and MDQA average accuracy for each model and method, highlighting the gains achieved by using DD in terms of accuracy and training time reduction. The experiment uses an alternative pretraining dataset.

This table presents the results of experiments evaluating the effect of different mixtures of dataset decomposition buckets on the performance of an OpenLM-1B model. The model was trained on a total of 96 x 230 tokens, using Rotary Positional Embeddings (RoPE) with a base frequency of 10,000, and consistent hyperparameters. Each row represents a different mixture of buckets, demonstrating how varied sequence length distributions influence the model’s performance on various benchmarks.
Full paper#