↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-image diffusion models struggle with generating images that accurately reflect complex compositional prompts involving multiple objects and relationships. This is because existing models often prioritize either realism or compositionality but struggle to achieve a good balance between them. The lack of strong spatial awareness further exacerbates this issue, leading to inaccurate object placement and relationships in the generated images.
The paper introduces RealCompo, a novel training-free framework that effectively addresses this challenge. RealCompo leverages large language models (LLMs) to generate scene layouts from text prompts and uses a dynamic balancer to combine the strengths of text-to-image and spatial-aware models during the denoising process. This method automatically adjusts the balance between realism and compositionality, producing images that are both visually appealing and compositionally accurate. The authors demonstrate that RealCompo outperforms state-of-the-art models on multiple-object compositional generation tasks and is easily adaptable to other spatial-aware conditions and stylized image generation.
Key Takeaways#
Why does it matter?#
This paper is important because it presents RealCompo, a novel training-free framework that significantly improves text-to-image generation. It directly addresses the challenge of balancing realism and compositionality, a crucial issue in current image generation models. The framework’s flexibility and generalizability open exciting new avenues of research and offer valuable tools for researchers working on compositional image generation.
Visual Insights#

This figure demonstrates the trade-off between realism and compositionality in text-to-image generation. Subfigure (a) and (c) show that incorporating more layout information into the generation process leads to a decline in the realism and aesthetic quality of the generated images. Subfigure (b) shows that even if layout is only incorporated in the early stages of the generation process, the generated images still suffer from a lack of realism when solely controlled by text in the later stages. This illustrates the limitations of current text-to-image models in handling compositional generation and motivates the proposed RealCompo framework.
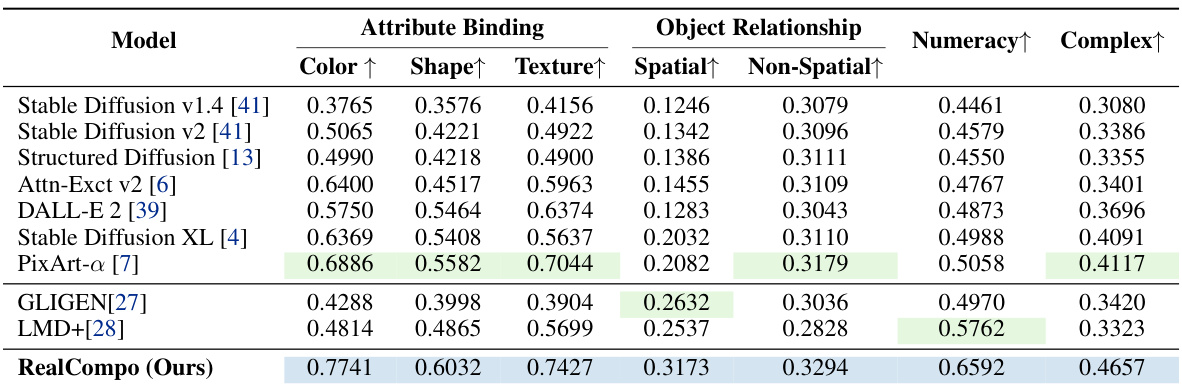
This table presents a quantitative comparison of different text-to-image models on the T2I-CompBench benchmark. The benchmark assesses the models’ ability to generate images that accurately reflect attributes (color, shape, texture), object relationships (spatial and non-spatial), numeracy (correct number of objects), and complex compositions. RealCompo achieves the highest scores across all four categories, indicating superior performance in compositional generation.
In-depth insights#
Compo. Challenges#
Compositional generation in text-to-image models presents significant challenges. Balancing realism and compositionality is a core issue; methods prioritizing accurate spatial arrangements often sacrifice photorealism, while highly realistic models struggle with complex scene layouts and object relationships. Controllability remains a major hurdle, as precisely guiding the model to generate specific object positions, interactions, and attributes within a complex scene requires sophisticated control mechanisms. The inherent ambiguity in natural language prompts adds to the difficulty; disentangling the nuanced details of a prompt to generate the intended composition accurately is not trivial. Furthermore, evaluating the success of compositional generation is subjective; establishing robust quantitative metrics for compositionality is essential for effective model development and comparison. Finally, scaling up to increasingly complex scenes and diverse object types presents a computational challenge, requiring the efficient management of spatial information and attention mechanisms. Addressing these challenges requires advancing both the underlying model architectures and training methodologies.
RealCompo Framework#
The RealCompo framework represents a novel, training-free approach to enhance text-to-image diffusion models. Its core innovation lies in dynamically balancing the strengths of fidelity-focused (text-to-image) models and compositionality-focused (spatial-aware) models. This balance is achieved without additional training, leveraging a novel balancer mechanism that adjusts the influence of each model’s predicted noise based on cross-attention maps. This adaptive weighting allows RealCompo to improve both realism and compositionality in generated images. The framework’s flexibility is a key strength, enabling seamless integration with various spatial-aware models (layout, keypoints, segmentation maps) and even stylized diffusion models, demonstrating a powerful and generalizable method. The use of LLMs for layout generation further streamlines the process, providing a natural and efficient way to incorporate spatial constraints from textual descriptions. In essence, RealCompo offers a significant advancement in controllable image generation by intelligently combining the strengths of existing models, rather than relying on extensive retraining for each new combination.
Dynamic Balancer#
The core of RealCompo is its Dynamic Balancer, a novel mechanism designed to dynamically adjust the influence of the text-to-image (T2I) and spatial-aware models during the denoising process. This isn’t a simple weighting; it involves a sophisticated analysis of cross-attention maps from both models. By examining how each model attends to visual and textual elements, the balancer determines which model’s predictions should carry more weight at each step, thus achieving a dynamic equilibrium between realism (from the T2I model) and compositionality (from the spatial-aware model). The training-free and adaptive nature of the balancer is a significant advantage, making RealCompo easily extendable to diverse model combinations without requiring retraining. The dynamic adjustment based on cross-attention allows the balancer to adapt to various spatial-aware inputs (layout, keypoints, segmentation maps). Crucially, the balancer’s use of cross-attention maps allows for a nuanced understanding of how different models impact image generation and provides a more controlled approach to balancing different generative directions than simply switching between models at predetermined stages. This innovative method represents a significant advancement in controllable image generation, effectively addressing the trade-off between high-fidelity realism and accurate compositional adherence to text prompts.
Generalization & Style#
The study’s exploration of “Generalization & Style” within the context of text-to-image generation is crucial. It delves into the model’s ability to handle diverse prompts and stylistic variations, moving beyond simple, straightforward scenarios. RealCompo demonstrates impressive generalization by seamlessly integrating with various spatial-aware models, extending its applicability to layouts, keypoints, and segmentation maps. This adaptability showcases its robustness and flexibility, unlike methods requiring additional training for each new model or condition. The framework’s ability to leverage stylized diffusion models is a particularly interesting aspect. By switching the primary text-to-image model, RealCompo can adapt to different stylistic preferences, demonstrating not only compositional skill but also stylistic control. This opens up exciting possibilities for creative control and diverse image generation. However, a deeper analysis of the trade-offs between style preservation and compositional accuracy when using stylized models would strengthen this section. The effects of varying stylistic choices on the model’s overall performance, including potential biases or limitations, deserve further investigation. Quantitative metrics evaluating style consistency and fidelity would provide valuable insights into the model’s capabilities.
Future Works#
The ‘Future Works’ section of a research paper on RealCompo, a framework balancing realism and compositionality in text-to-image generation, would naturally focus on expanding its capabilities and addressing limitations. Improving computational efficiency is paramount, as RealCompo’s dual-model approach currently increases processing time. Exploring more efficient model combinations or alternative algorithmic strategies could significantly improve scalability. Extending RealCompo’s functionality beyond images is another crucial area. Applying the framework to text-to-video generation or 3D modeling would unlock significant new applications. Investigating the potential of fixed coefficient strategies instead of dynamic balancing, and exploring how this could further enhance efficiency and maintain quality, is a promising direction. Finally, the impact of different spatial-aware models must be carefully explored. While RealCompo shows flexibility, a deeper understanding of how specific models influence the final output could lead to better control and more predictable results. Addressing these points in ‘Future Works’ would solidify RealCompo’s position as a leading framework for advanced image synthesis.
More visual insights#
More on figures
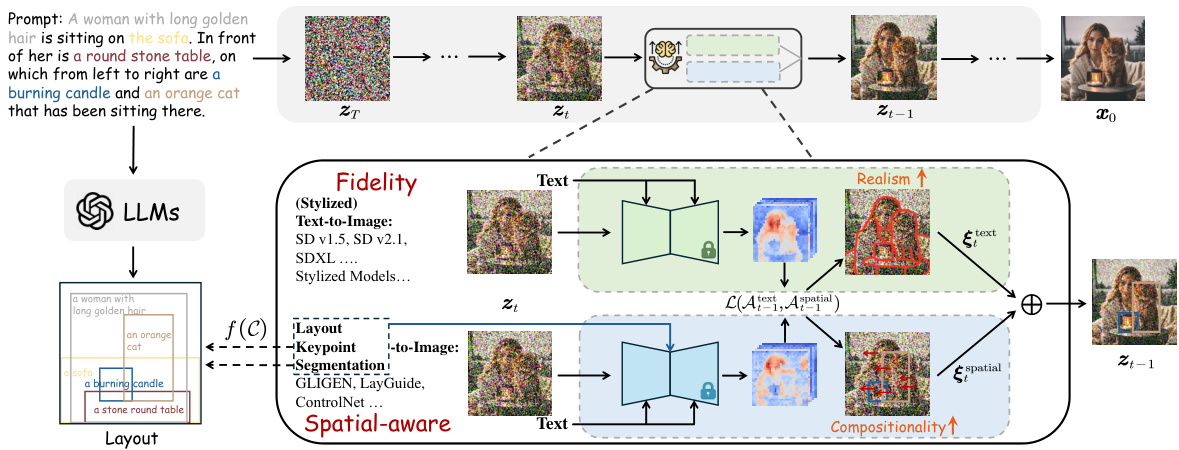
This figure illustrates the RealCompo framework, a text-to-image generation method. It starts with a text prompt that’s processed by LLMs (Large Language Models) to generate a scene layout. The core of the framework is a dynamic balancer that combines two types of diffusion models: a fidelity-focused model (like Stable Diffusion) prioritizing realism and a spatial-aware model (like GLIGEN) focusing on composition. The balancer adjusts the influence of each model during the denoising process using cross-attention maps, achieving a balance between realism and compositionality. The resulting image benefits from both models’ strengths: realistic details from the fidelity branch and accurate object placement from the spatial branch.

This figure shows example images generated by extending the RealCompo framework to handle keypoint and segmentation maps as spatial-aware conditions in addition to layout. The top row shows a prompt about a girl dancing, along with the keypoint map input, the ControlNet output, and the RealCompo output. The bottom row shows the same for another prompt involving a group of four friends. The middle row shows an example relating to a prompt involving astronauts on the moon. The improved realism and compositionality of RealCompo are highlighted by comparing its output with the results from SDXL and ControlNet.
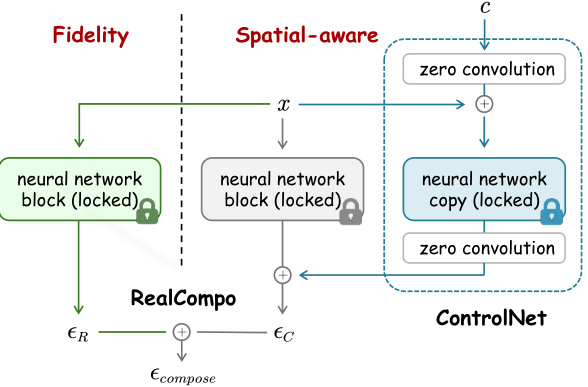
This figure illustrates the architecture of RealCompo, which uses ControlNet to incorporate spatial-aware conditions into a text-to-image diffusion model. ControlNet is shown as a separate block within the overall architecture, receiving spatial-aware information (such as layout, keypoints, or segmentation maps) as input. The output of ControlNet is combined with the output of the fidelity-aware (T2I) branch using a novel balancer in RealCompo to produce the final balanced noise used to generate the image. The figure shows how the fidelity and spatial-aware branches of RealCompo are combined using ControlNet, highlighting the key components and their interactions within the overall framework.

This figure compares the image generation results of RealCompo with three other models (Stable Diffusion v1.5, GLIGEN, and LMD+) across four different image prompts. Each prompt depicts a scene with multiple objects and complex spatial relationships. The colored text highlights where RealCompo’s output surpasses the other models in terms of realism and accurate representation of the scene, demonstrating its strength in handling compositional generation.

The figure shows the results of a user study comparing the realism, compositionality, and overall quality of images generated by three different methods: a T2I model, a spatial-aware model, and RealCompo. RealCompo shows significant improvement over the other two methods across all three aspects, highlighting its success in balancing both realism and composition.
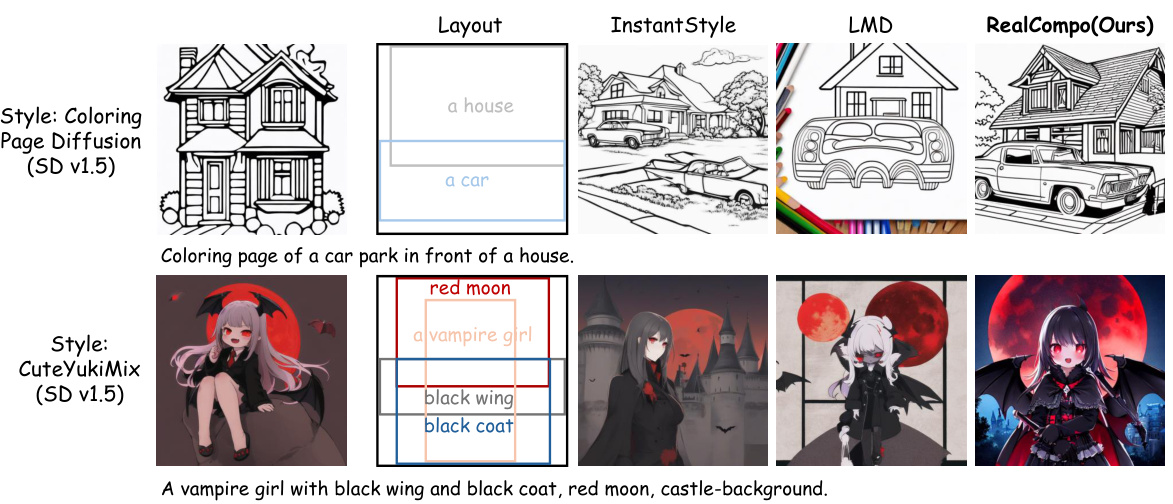
This figure demonstrates the flexibility of RealCompo in handling stylized compositional generation. Two examples are shown. The top row uses the
Coloring Page Diffusionstyle, and shows the results of four different methods: a simple layout, results from theInstantStylemodel, results from theLMDmodel, and results from the RealCompo model. The bottom row uses theCuteYukiMixstyle, and shows the same comparison between the four methods. RealCompo successfully integrates the style with compositionality in both examples.

This figure presents an ablation study and qualitative comparison to demonstrate the importance of the dynamic balancer in RealCompo and its generalization ability across different models. It shows that the dynamic balancer significantly improves compositional generation, and that RealCompo consistently performs well with various combinations of T2I and L2I models, exhibiting high fidelity and alignment with text prompts.

This figure demonstrates the limitations of existing text-to-image models and layout-to-image models. Subfigure (a) and (c) show how incorporating layout information progressively degrades the realism and aesthetic quality of generated images. Subfigure (b) shows that even limiting layout input to only the early denoising stages fails to prevent realism degradation when using only text-based control for the later stages, motivating the development of RealCompo which balances both realism and compositionality.

This figure demonstrates the impact of layout density (controlled by parameter β) and layout injection time (controlled by parameter t₀) on the realism of images generated using the InstanceDiffusion model. As β and t₀ increase, the realism of the generated images decreases, showing a decline in image quality and the appearance of unrealistic details. This highlights the trade-off between realism and compositionality during the image generation process. The images show a scene with a robin, dog, cat and a waterfall. The layout describes the location of each animal, and the increase in β and t₀ causes the animals to be placed less naturally and realistically within the scene.

This figure presents a high-level overview of the RealCompo framework’s architecture. It starts with a text prompt that’s fed into an LLM to generate a scene layout. Then, the core of the system is the dynamic balancer. This component integrates a fidelity-focused model (like Stable Diffusion) and a spatial-awareness model (like GLIGEN). The balancer continuously adjusts the influence of these two models during the denoising process to balance realism (handled by the fidelity model, which focuses on contours and colors) and compositionality (handled by the spatial model, that focuses on object positions). The output is a generated image.
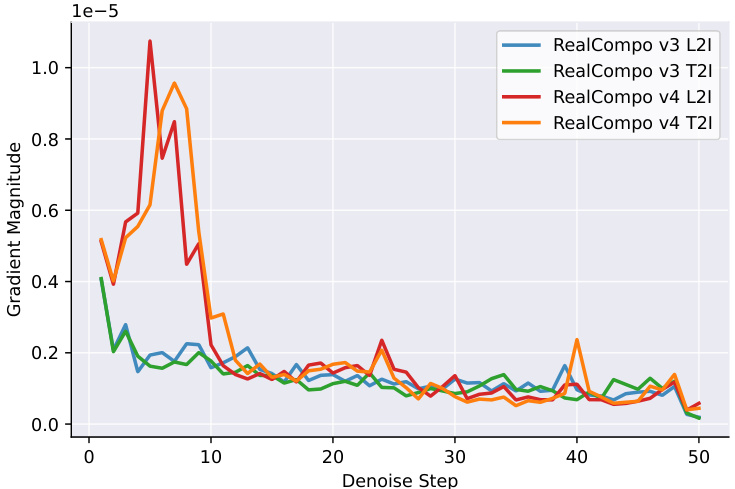
This figure visualizes the gradient magnitude changes during the denoising process for two versions of RealCompo (v3 and v4) using both text-to-image (T2I) and layout-to-image (L2I) models. It shows how the gradient magnitudes fluctuate differently across denoising steps for each model and combination. These variations likely stem from differences in the models’ functionalities and their interplay during the generation process. The fluctuating gradients in the early stages of RealCompo v4 suggest less stable balancing between the model components than v3.

This figure shows a comparison of image generation results using different models: SD1.5, GLIGEN, LMD+, and the proposed RealCompo. Each row shows a different prompt and the corresponding generated images. The layout is provided to the models to guide object arrangement. The figure demonstrates RealCompo’s improved realism and compositionality compared to the other methods.

This figure shows three examples of images generated using RealCompo with different spatial-aware conditions. The first row shows a keypoint-based image generation of Leonardo from Teenage Mutant Ninja Turtles in a cinematic action pose, demonstrating that RealCompo successfully incorporates keypoint information to generate a realistic and dynamic image. The second row shows an image generation of Elsa and Anna from Frozen, again showing that RealCompo successfully incorporates keypoint information to generate a realistic image consistent with the prompt. The third row shows an image generation of two astronauts on the moon, showcasing the ability of RealCompo to handle complex scenes and multiple objects, accurately positioning the objects based on the prompt. Overall, this figure highlights the versatility and effectiveness of RealCompo in generating high-quality, compositionally accurate images across various spatial-aware conditions.

This figure shows three examples of images generated using the keypoint-based RealCompo method. The leftmost column displays the keypoints used as input. The next column presents the images generated by ControlNet, a method that uses keypoints for image generation. The rightmost column shows the images generated by the RealCompo method. The results demonstrate the ability of RealCompo to improve the realism and quality of the images generated using keypoints compared to ControlNet.

This figure showcases three examples of images generated using RealCompo with keypoint-based spatial-aware conditions. The leftmost column shows the keypoint map used as input. The middle column displays images generated using only the ControlNet model with keypoints. The rightmost column presents images generated using the proposed RealCompo framework which combines a fidelity-aware diffusion model (SDXL) and the ControlNet model, aiming to balance realism and compositionality. The examples highlight that RealCompo better leverages the spatial information from the keypoints to generate more realistic and compositionally accurate images, especially for complex scenes involving multiple characters and actions.

This figure shows a comparison of images generated by three different models: SDXL (a fidelity-aware model), ControlNet (a spatial-aware model), and RealCompo (the proposed model). Each row represents a different prompt. For each prompt, the three models produce different images, highlighting their strengths and weaknesses. RealCompo often demonstrates superior results by combining the strengths of the other two models, balancing realism with compositionality.
Full paper#



















