↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating diverse and realistic 3D indoor scenes is challenging due to complex object interactions, limited data, and the need to meet spatial constraints. Existing methods often struggle with these limitations, either by using autoregressive approaches (sequentially placing objects) or by simultaneously predicting all attributes without spatial considerations.
DeBaRA tackles these issues by focusing on precise and controllable object placement. It uses a score-based model that prioritizes 3D spatial awareness. This allows DeBaRA to generate diverse and realistic layouts, perform scene synthesis, completion and re-arrangement tasks efficiently. The novel Self Score Evaluation (SSE) further enhances the model by selecting optimal conditioning inputs from external sources, improving overall performance and controllability.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DeBaRA, a novel approach to 3D room arrangement generation that significantly improves upon existing methods. Its focus on spatial reasoning and disentanglement of spatial and semantic attributes leads to more realistic and controllable outputs. The introduction of Self Score Evaluation (SSE) further enhances the model’s capabilities and opens up new avenues for integrating LLMs in scene generation. These advances are highly relevant to the growing fields of AR/VR, game development, and interior design, providing researchers with a powerful new tool and stimulating further research in 3D scene understanding and generation.
Visual Insights#
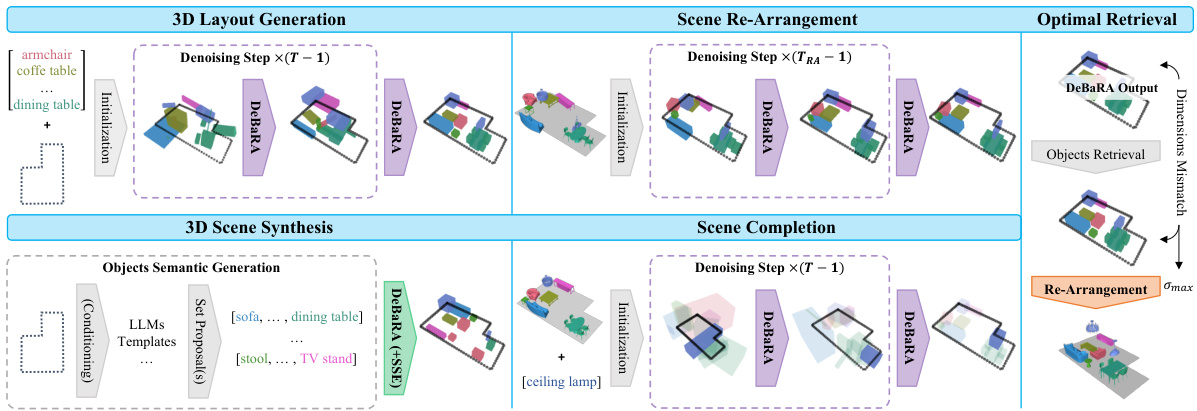
This figure illustrates the various applications of the DeBaRA model. It shows how a single trained DeBaRA model can be used for 3D layout generation, scene re-arrangement, optimal retrieval, and scene completion. The diagram highlights the input and output for each task, including the use of external Language Models (LLMs) and a novel Self Score Evaluation (SSE) procedure for 3D scene synthesis.

This table presents a quantitative comparison of different methods for generating 3D room layouts, including the proposed DeBaRA model. The comparison is based on four key metrics: Fréchet Inception Distance (FID), Kernel Inception Distance (KID), Scene Classification Accuracy (SCA), and Out of Bounds Area (OBA). Lower FID and KID scores indicate better realism, higher SCA suggests better alignment with the scene class, and lower OBA shows better adherence to the room boundaries. The table includes results for living rooms and dining rooms, comparing DeBaRA against ATISS, DiffuScene, and LayoutGPT (a training-free approach).
In-depth insights#
DeBaRA: Denoising Approach#
DeBaRA, a denoising-based approach for 3D room arrangement generation, offers a novel solution to the complexities of creating realistic and diverse indoor scenes. Its core innovation lies in disentangling the spatial reasoning from other attributes, focusing on the precise prediction of object positions, sizes, and orientations within a bounded environment. This targeted approach leads to a more data-efficient and robust model, unlike methods that attempt to predict all attributes simultaneously. The use of a conditional score-based model ensures controllability and flexibility, allowing for various downstream applications, such as scene completion and re-arrangement. The introduction of a Self Score Evaluation procedure is another key strength, enabling effective selection of semantically coherent inputs, ideally from external sources like large language models, significantly improving output quality. The lightweight architecture allows for fast generation and efficient resource utilization. Overall, DeBaRA represents a significant advance in 3D scene generation by leveraging the power of denoising while maintaining focus on the crucial spatial aspects of the problem.
3D Spatial Awareness#
3D spatial awareness in the context of 3D room arrangement generation is crucial for creating realistic and usable scenes. It involves understanding and modeling the spatial relationships between objects, including their positions, orientations, and sizes within a bounded environment. A model with strong 3D spatial awareness will avoid physically impossible layouts (e.g., objects overlapping or floating), and will instead create arrangements that are both visually appealing and functionally correct. This necessitates moving beyond simply predicting object attributes independently; it requires explicitly encoding spatial context. Achieving this may involve using geometric representations like bounding boxes and incorporating mechanisms to ensure spatial consistency and avoid collisions. Sophisticated deep learning architectures, such as transformers, might be employed to capture the complex, long-range dependencies between objects. Further, it suggests the need for appropriate loss functions that directly penalize spatial violations, incentivizing the generation of physically plausible scenes. Ultimately, effective 3D spatial awareness is not just about accurate placement, but also about generating diverse and creative layouts while adhering to spatial constraints.
Self Score Evaluation#
The proposed ‘Self Score Evaluation’ method is a novel approach to enhance the efficiency and quality of 3D scene synthesis. Instead of relying solely on external sources like LLMs for conditioning information, SSE leverages the pretrained diffusion model’s knowledge to select optimal conditioning inputs. This process involves evaluating multiple candidate object semantic sets by comparing the corresponding 3D spatial layout’s density to those generated unconditionally. By choosing candidates aligned with the model’s learned distribution, SSE avoids generating unrealistic or implausible layouts, thereby significantly improving the model’s ability to generate high-quality and diverse 3D scene arrangements. The key advantage lies in its ability to disentangle the conditioning from external sources, leading to better alignment with the model’s internal representations and avoiding the suboptimal scenarios often caused by misaligned conditioning signals. This approach not only enhances synthesis capabilities but also makes the process more efficient and robust by focusing the model’s efforts on the most promising candidates.
Diverse Layout Generation#
Diverse layout generation in 3D room arrangement is a challenging problem due to the complex interplay of object interactions, spatial constraints, and the need for realistic and varied outputs. Score-based generative models show promise due to their ability to model all attributes simultaneously and enable controllability. However, simply using a score-based model to predict all attributes at once may not be optimal because different types of attributes (spatial vs. semantic) have varying degrees of difficulty and data efficiency. A key insight is that focusing on accurate spatial placement, using 3D bounding boxes as a minimal representation, allows the model to learn efficient representations for spatial relationships and leverage the semantic categories as conditioning inputs. This leads to significant improvements in generating diverse, realistic, and valid layouts. A further enhancement is the introduction of a novel Self Score Evaluation (SSE) procedure, which leverages the density estimates of the model to efficiently select appropriate conditioning semantics from external sources like LLMs. This allows for more control and higher-quality output. The model is shown to be flexible in handling various downstream tasks such as scene completion, re-arrangement, and scene synthesis, all enabled by simply adjusting the initial sampling noise levels and/or utilizing inpainting techniques. The flexibility and strong results demonstrate that a focus on 3D spatial awareness in generative models offers a robust and efficient path towards diverse and realistic 3D layout generation.
Future Work Directions#
Future research could explore enhancing DeBaRA’s capabilities by incorporating physics engines for more realistic object interactions and collision handling. Improving the model’s ability to generate diverse styles and aesthetics beyond the current datasets is also crucial. Furthermore, investigating the use of more advanced deep learning architectures or generative models may unlock improved performance and scalability. Integrating DeBaRA with other AI systems, such as natural language processing models or robotic control systems, would open up new applications in areas like virtual and augmented reality design. Addressing the limitations of current 3D object datasets with respect to size and diversity would significantly benefit the model’s training and generalization, as would explorations into more efficient and interpretable loss functions. Finally, research on the ethical implications and responsible use of DeBaRA in various applications is essential to ensure its beneficial and harmless deployment.
More visual insights#
More on figures
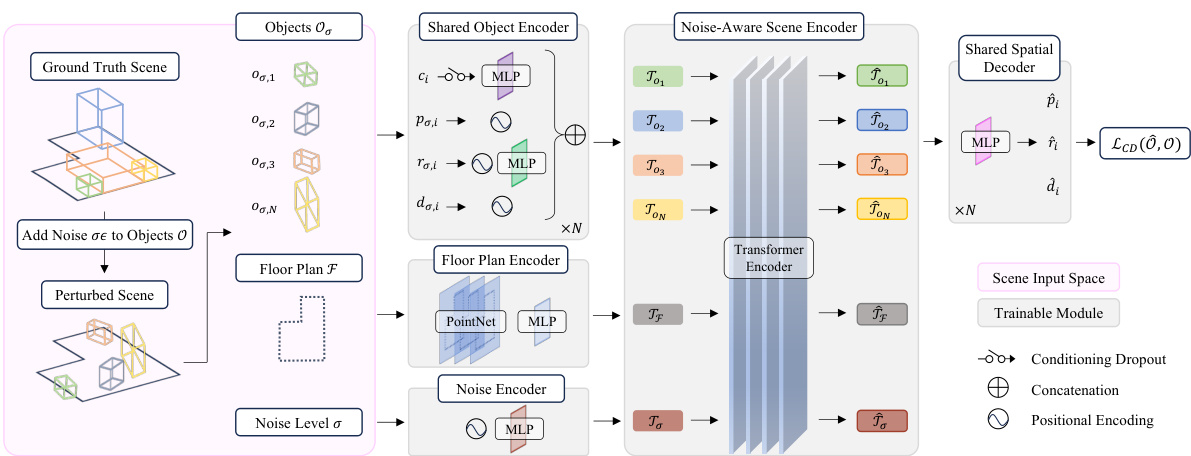
This figure illustrates the DeBaRA architecture and its training process. The model takes as input a floor plan (F), a noise level (σ), and a set of objects (O) with their associated semantic categories (c). Each object’s 3D bounding box parameters (position (p), rotation (r), dimension (d)) are perturbed with Gaussian noise. These inputs are processed through separate encoders, creating a combined representation (T) fed into a transformer encoder. This encoder processes the information and feeds the result to a decoder, ultimately predicting the clean (denoised) object spatial attributes (p, r, d). The model is trained by minimizing a Chamfer distance loss that considers semantic categories, and by using a conditioning dropout strategy on the categories for robust training across different conditions.
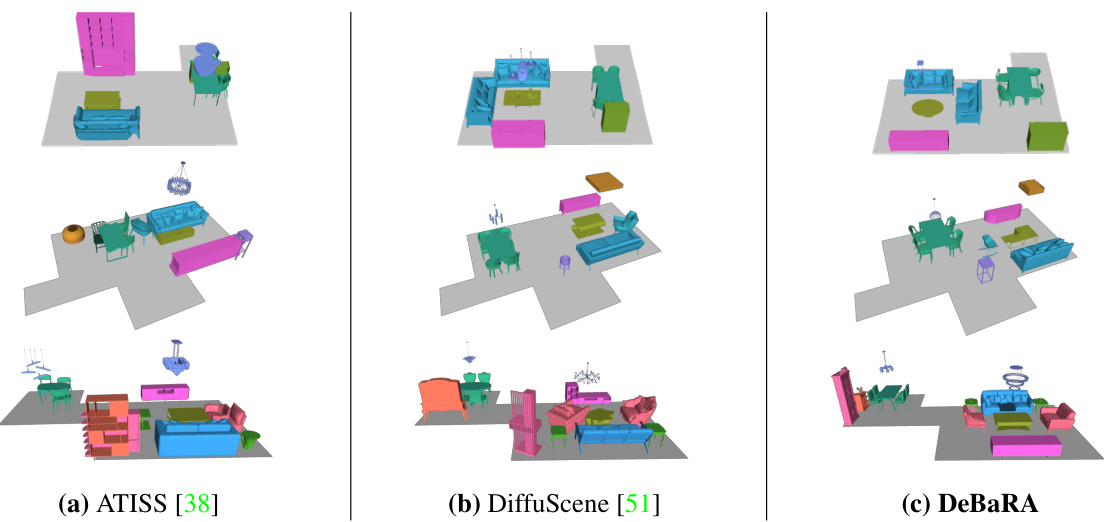
This figure compares the results of three different methods (ATISS, DiffuScene, and DeBaRA) for generating 3D room layouts. Each method was given the same floor plan and set of object categories as input. The results show that DeBaRA generates more realistic and regular arrangements within the bounds of the room compared to the other two methods.
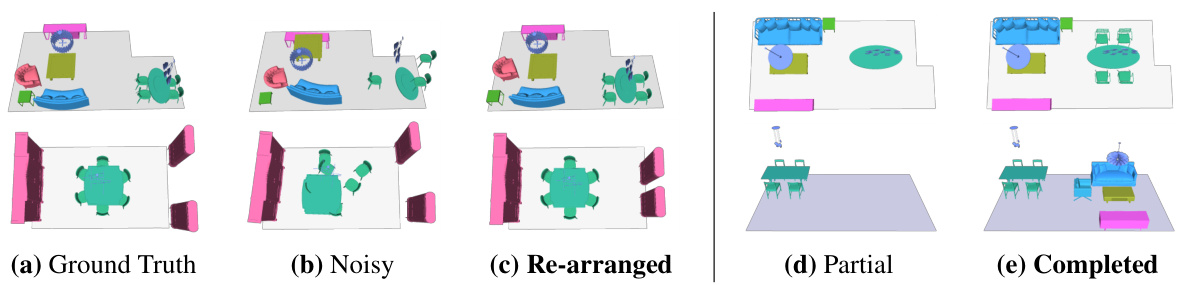
This figure demonstrates DeBaRA’s capability in two scenarios: scene re-arrangement and scene completion. The left side shows how DeBaRA recovers an organized layout from a noisy, disorganized initial state. The right side illustrates DeBaRA’s ability to add missing objects to a partially furnished scene, resulting in a complete and realistic layout while maintaining consistency with the original arrangement.

This figure shows the results of scene re-arrangement and completion experiments. The left side demonstrates DeBaRA’s ability to rearrange a messy scene back to its original state. The right side demonstrates DeBaRA’s ability to complete a partially furnished scene by intelligently adding missing objects. The figure highlights DeBaRA’s capability of handling noisy or incomplete input and producing plausible, visually appealing results.

This figure compares the 3D room layout generation results of DeBaRA against two other state-of-the-art methods, ATISS and DiffuScene. Each method was given the same floor plan and list of objects to include. The results demonstrate that DeBaRA is superior at producing realistic arrangements within the boundaries of the room, with fewer failures to generate a valid layout.

This figure shows five examples of 3D room layouts generated by DeBaRA. Each example uses a different, irregular floor plan (top row) that deviates from the typical rectangular or square shapes found in the dataset. The generated layouts (bottom row) demonstrate that DeBaRA can successfully handle complex floor plans and still produce realistic and plausible arrangements of the objects.

This figure visualizes the iterative denoising process of the DeBaRA model for generating 3D layouts. It shows a sequence of intermediate layouts at different timesteps, starting from an initial, noisy state (timestep 0) and progressing towards a final, refined layout (timestep 50). The visualization highlights how the model gradually refines the positions, rotations, and dimensions of the objects as the denoising process advances. The objects’ coarse attributes are determined in the beginning and then become more accurate and detailed during the later timesteps.

This figure visualizes the variety in placement of objects during scene completion experiments. Ten different scene completions were run, each adding a bookshelf and coffee table to an existing scene. The figure shows the trajectories (paths) of each object during the sampling process as pink and blue lines, with the final positions marked as black dots. This illustrates how DeBaRA generates varied, yet plausible, results while adhering to spatial constraints. The bookshelf is shown to be placed in a variety of locations against walls, demonstrating flexibility, while the coffee table’s final position remains consistent across the trials, highlighting the model’s understanding of spatial relationships.

The figure illustrates the process of Self Score Evaluation (SSE). First, multiple object category candidates are generated using an LLM (Large Language Model) and a template, conditioned on a given floor plan. Then, for each candidate, DeBaRA (the proposed model) generates a 3D layout using iterative conditional sampling and calculates a Chamfer distance loss. Simultaneously, a one-step unconditional denoising step is performed at a noise level σ, also using DeBaRA but without specific categories as input. The Chamfer distance loss is used for both steps to rank the candidates. The candidate with the lowest combined loss across both processes is selected as the optimal conditioning input for 3D scene synthesis. The whole process leverages the knowledge of a pre-trained diffusion model to make better selections of categories that the model already knows how to deal with.

This figure compares the results of 3D layout generation using DeBaRA against two other methods: ATISS and DiffuScene. Each column shows example layouts generated by a different method, given the same input (floor plan and object categories). The figure highlights that DeBaRA generates more realistic and consistently regular layouts compared to the baselines and that it is better at keeping objects within the room boundaries.

This figure compares the scene synthesis capabilities of DeBaRA against state-of-the-art methods. Different approaches to providing object semantics are shown: random selection from the training data, generation from an external Large Language Model (LLM), and LLM-generated semantics filtered by the Self Score Evaluation (SSE) procedure. The results demonstrate DeBaRA’s ability to create more natural-looking scenes, particularly when using the SSE procedure for semantic selection.

This figure demonstrates DeBaRA’s ability to perform scene re-arrangement and completion tasks. The left side shows three examples of a messy scene being rearranged to a more plausible layout. The right side shows three examples of an incomplete scene being completed by adding objects to create a more natural-looking layout. In both cases, DeBaRA effectively considers existing object placements while producing valid configurations.

This figure shows the qualitative results of DeBaRA on scene re-arrangement and completion tasks. The left part displays the ground truth, noisy, re-arranged, partial and completed scenes in a re-arrangement task. The right part shows a similar process in a scene completion task. DeBaRA successfully recovers a plausible layout from a messy scene and incorporates initial configurations effectively.

This figure shows radial histograms of object rotation values from the 3D-FRONT dataset and those generated by DeBaRA. It demonstrates that objects in the dataset tend to have rotations aligned with cardinal directions (0°, 90°, 180°, 270°), and that DeBaRA learns and replicates this tendency.
More on tables

This table presents a quantitative comparison of different methods for 3D layout generation, including the proposed DeBaRA model and several baselines (ATISS, DiffuScene, and LayoutGPT). The results are evaluated using FID, KID, SCA, and OBA metrics across two datasets (living rooms and dining rooms) and show that DeBaRA achieves improved performance in generating realistic and valid 3D layouts.

This table presents the results of an ablation study conducted to evaluate the impact of different components of the DeBaRA model on 3D layout generation performance. The study examines two key aspects: (1) the choice of loss function (L) for training the model, and (2) the use of conditioning dropout (Pdrop) during training. The results show that the proposed semantic-aware Chamfer distance significantly improves performance compared to the Mean Squared Error (MSE) loss and a standard Chamfer distance. The use of conditioning dropout also enhances performance.
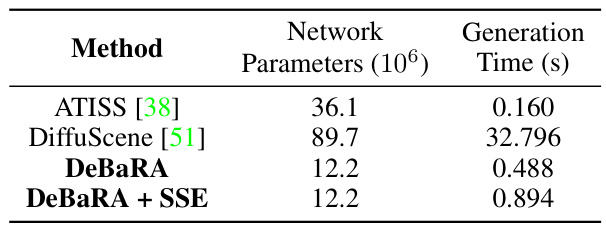
This table presents a comparison of the generation time and number of parameters for different models on the 3D-FRONT living room test subset. The models compared are ATISS, DiffuScene, DeBaRA, and DeBaRA with Self Score Evaluation (SSE). DeBaRA uses 50 sampling steps and 100 trials for the SSE.

This table presents the results of an ablation study comparing different sampling strategies used in DeBaRA for 3D layout generation. It shows the FID, KID, SCA, OBA, and generation time for three different sampling methods (DDPM with 1000 steps, EDM with 25 steps, and EDM with 50 steps) applied to both living rooms and dining rooms datasets. The results demonstrate how the choice of sampling method and number of steps impacts the quality and efficiency of the generated layouts.

This table presents a quantitative comparison of the DiffuScene model’s performance on 3D layout generation with and without floor plan conditioning. The results show a significant improvement in FID, KID, and OBA when floor plan information is included, demonstrating that the model effectively incorporates this additional context to generate more realistic and spatially accurate layouts.

This table presents a quantitative comparison of different methods for generating 3D room layouts. The methods are evaluated using four metrics: Fréchet Inception Distance (FID), Kernel Inception Distance (KID), Scene Classification Accuracy (SCA), and Out of Bounds Area (OBA). Lower values for FID, KID, and OBA are better, indicating more realistic and valid scene layouts. Higher SCA values (closer to 50%) are better, indicating more diverse layouts.
Full paper#



















