↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Accurate motion forecasting is crucial for autonomous driving, but existing methods struggle with representing the dynamic evolution of agent states. These often utilize a one-query-one-trajectory approach, which may yield suboptimal results. This paper introduces the problem of the limitation of existing approaches.
The proposed DeMo framework addresses these challenges by decoupling multi-modal trajectory queries into two types: mode queries (capturing directional intentions) and state queries (tracking dynamic states). It leverages combined attention and Mamba techniques for efficient information aggregation and state sequence modeling, resulting in state-of-the-art performance on standard benchmarks. This significantly improves the accuracy and detailed representation of future trajectories for autonomous driving.
Key Takeaways#
Why does it matter?#
This paper is important because it presents DeMo, a novel framework for motion forecasting that significantly improves accuracy. It addresses limitations of existing methods by decoupling multi-modal trajectory queries into directional intentions and dynamic states, paving the way for safer and more efficient autonomous driving systems. The proposed combined attention and Mamba techniques offer new avenues for research in trajectory prediction and time-series modeling.
Visual Insights#
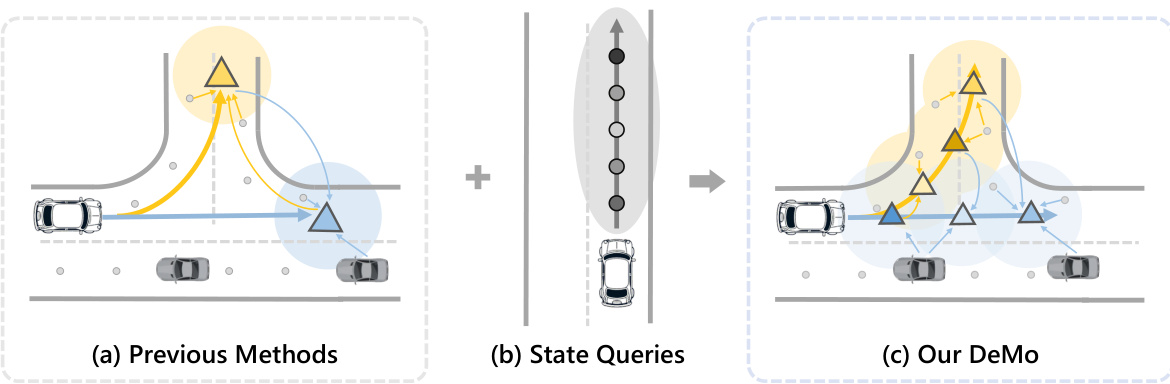
This figure illustrates the core idea of the DeMo framework. Panel (a) shows the traditional one-query-one-trajectory approach where a single query attempts to predict all future possibilities of motion. Panel (b) introduces the concept of state queries, which track the agent’s dynamic states over time separately. Finally, panel (c) combines both mode queries (directional intentions) and state queries, providing a more detailed and accurate representation of future trajectories. This decoupling is the key innovation of the DeMo approach.
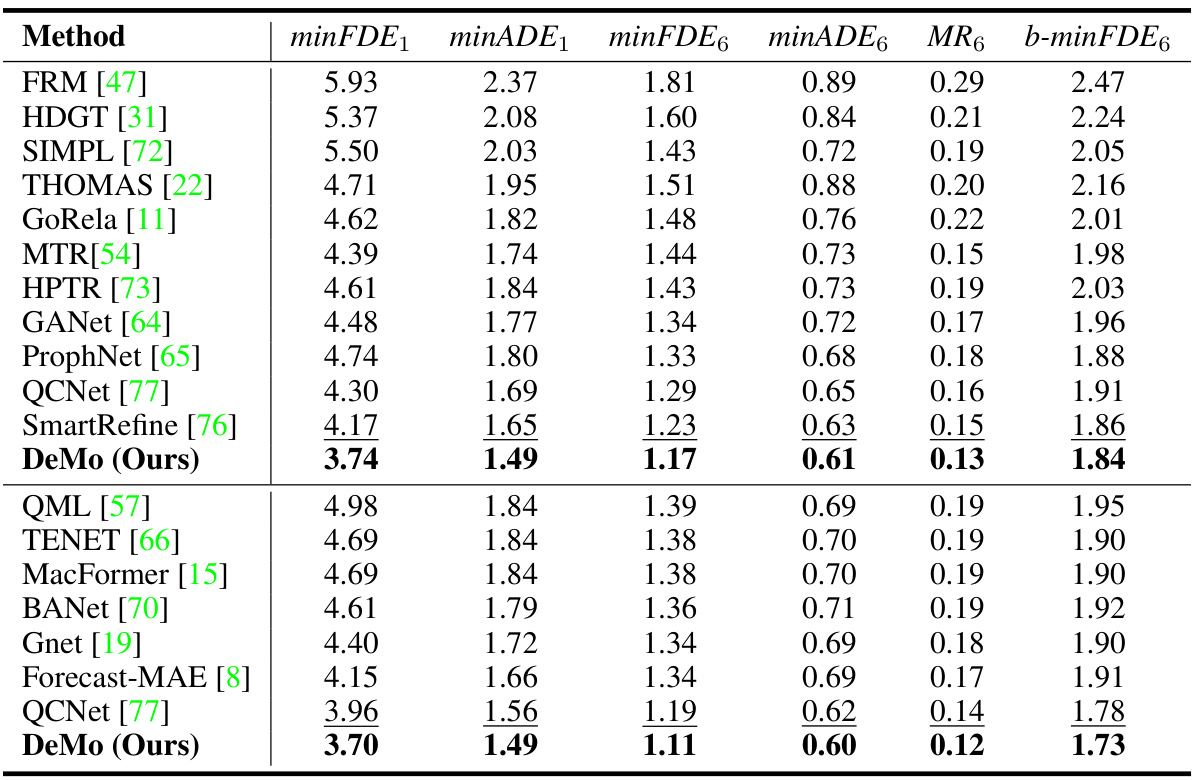
This table compares the performance of DeMo against other state-of-the-art methods on the Argoverse 2 single-agent motion forecasting benchmark. The metrics used include minimum Average Displacement Error (minADE), minimum Final Displacement Error (minFDE), Miss Rate (MR), and the best minimum Final Displacement Error (b-minFDE), each calculated for prediction horizons of 1 and 6 seconds. The table is divided into two sections: the upper section shows results for single models, while the lower section demonstrates the performance gains achievable through model ensembling.
In-depth insights#
Motion Forecasting#
Motion forecasting, crucial for autonomous driving, predicts future movements of traffic agents, enabling safer and more efficient navigation. The challenges involve handling dynamic environments, unpredictable agent behavior, and the need to integrate road map information. Early approaches often relied on simple representations and lacked detailed modeling of future trajectories, leading to suboptimal predictions. Advances leverage vectorized scene representations and complex neural network architectures, such as transformers, to capture intricate relationships between agents and their surroundings. Multi-modal forecasting, addressing the inherent uncertainty of future trajectories, is a prominent area of research, with approaches including goal-oriented models and probabilistic methods. The field is continuously evolving, with improvements focused on handling long-term predictions, improving accuracy, and efficiently processing large-scale datasets. DeMo, presented in the paper, exemplifies recent progress by decoupling motion forecasting into directional intentions and dynamic states, allowing for more accurate and detailed predictions.
DeMo Framework#
The DeMo framework introduces a novel approach to motion forecasting by decoupling the prediction task into two distinct components: directional intentions and dynamic states. This decoupling allows for a more detailed and comprehensive representation of future trajectories, addressing limitations of previous one-query-one-trajectory methods. Separate modules process mode queries (directional intentions) and state queries (dynamic states), leveraging attention and Mamba mechanisms for efficient global information aggregation and temporal modeling. The framework then integrates these components using a hybrid coupling module to obtain a unified trajectory prediction. This approach enables the model to effectively capture both the multi-modality of future trajectories and their dynamic evolution, leading to state-of-the-art performance on benchmark datasets like Argoverse 2 and nuScenes. The modular design makes it flexible, and the use of Mamba provides efficiency benefits. However, further exploration is needed regarding its scalability for very long trajectories and deployment considerations.
Query Decoupling#
The core idea of “Query Decoupling” is to break down complex motion forecasting queries into smaller, more manageable sub-queries. Instead of directly predicting full trajectories, the method separates the prediction task into two distinct parts: directional intentions (mode queries) and dynamic states (state queries). This decomposition allows the model to focus on each aspect individually, capturing the agent’s intended direction and its dynamic evolution over time separately. By subsequently integrating these decoupled representations, the model gains a more comprehensive and nuanced understanding of the overall future trajectory, leading to improved accuracy and robustness, especially in handling multi-modal scenarios. This approach is particularly beneficial for addressing the limitations of one-query-one-trajectory methods, which often struggle with the detailed representation of future trajectories and capturing intricate spatiotemporal dynamics.
Mamba & Attention#
The integration of Mamba and Attention mechanisms offers a powerful approach to motion forecasting. Mamba, a state space model, excels at capturing long-range temporal dependencies in sequential data like agent trajectories, while Attention mechanisms excel at contextual information aggregation, weighing the importance of various surrounding elements (other agents, map features). Their combination allows the model to effectively leverage both dynamic state evolution and global scene context for improved prediction accuracy. Mamba’s efficiency in handling long sequences complements Attention’s ability to capture complex interactions, resulting in a robust and efficient forecasting framework.
Future Works#
The paper’s success in decoupling motion forecasting into directional intentions and dynamic states opens several exciting avenues for future work. Improving the model’s efficiency is crucial; the current architecture’s complexity could hinder real-time deployment. Exploring techniques like sparse state representations or more efficient attention mechanisms could significantly reduce computational costs. Addressing the limitations of the decoupled query paradigm is important; while effective, this approach could lead to increased model size and complexity with longer prediction horizons. Investigating alternative query designs or integrating multi-modal trajectory representations directly could mitigate this. Finally, extending the framework to handle more complex scenarios such as interactions with pedestrians, cyclists, and unpredictable events would significantly broaden its applicability. Thorough investigation into these areas will enhance both the accuracy and efficiency of the model, paving the way for safer and more reliable autonomous driving systems.
More visual insights#
More on figures
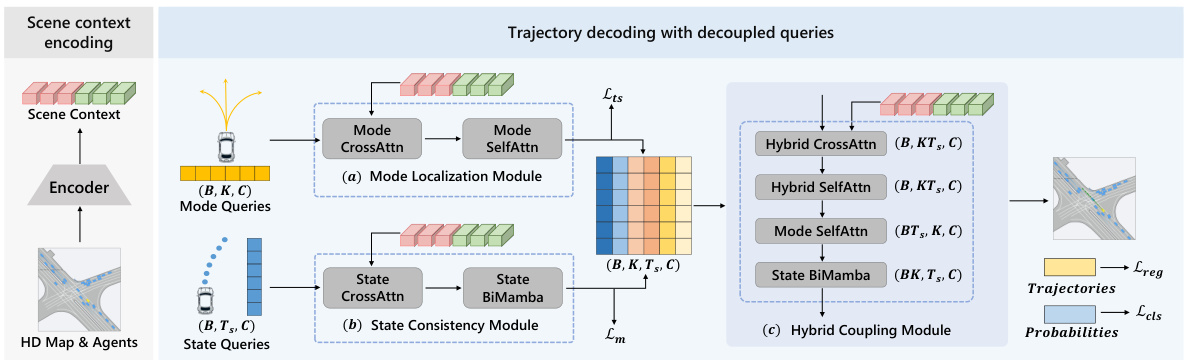
This figure provides a detailed overview of the DeMo framework. It shows how HD maps and agents are initially processed by an encoder to extract scene context. The decoding process is then broken down into three modules: the Mode Localization Module processes mode queries (directional intentions), the State Consistency Module processes state queries (dynamic states), and the Hybrid Coupling Module combines the outputs of the previous two modules to generate the final trajectory predictions. The illustration uses a single-agent scenario for clarity, showing the flow of data and the feature dimensions at each step.
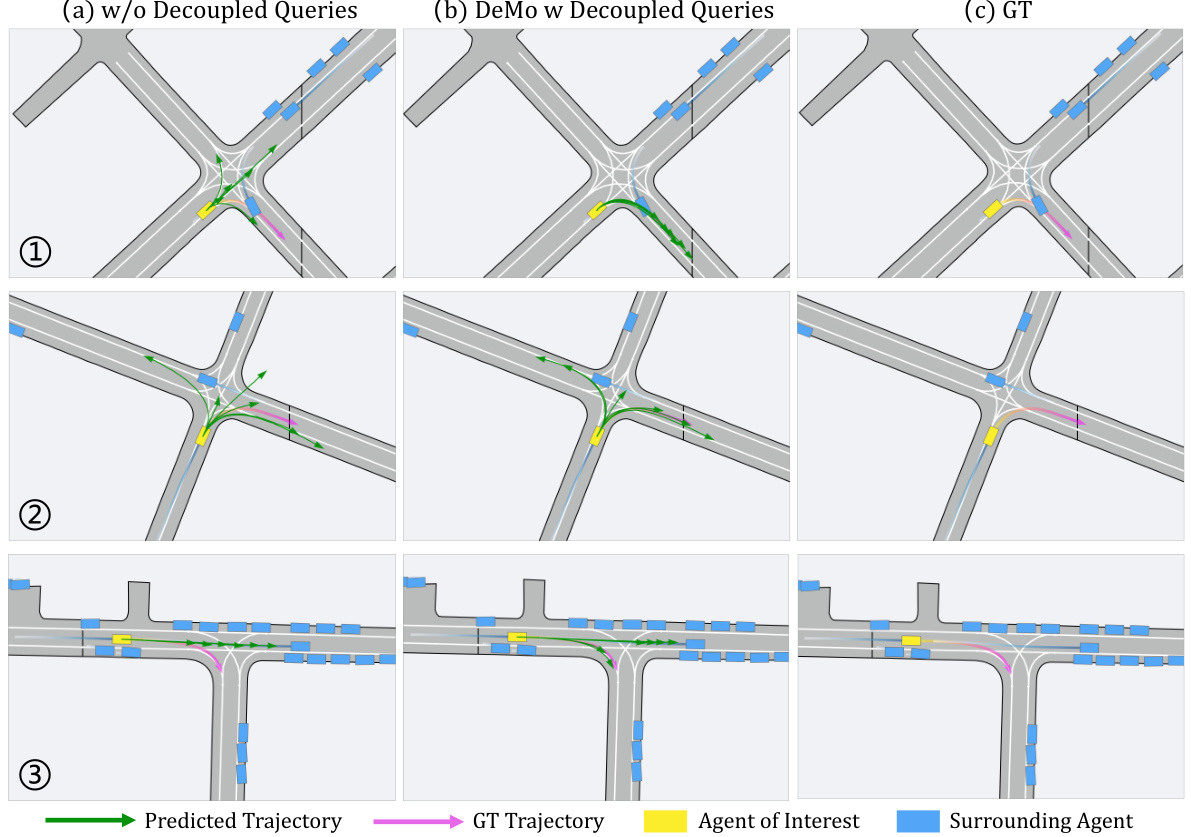
This figure provides a qualitative comparison of the baseline model and the proposed DeMo model for single-agent motion forecasting on the Argoverse 2 validation set. It showcases three different scenarios where the models’ predictions are compared with the ground truth. The baseline model lacks the decoupled query paradigm of DeMo. The results show that DeMo, with its decoupled queries, yields more accurate and realistic trajectory predictions compared to the baseline model.

This figure shows a qualitative comparison of trajectory prediction results between the baseline model (without decoupled queries) and DeMo (with decoupled queries) on the Argoverse 2 dataset. It provides a visual representation of the improved accuracy achieved by DeMo. Each row presents a different scenario, with ground truth trajectories shown in (c), the baseline model’s predictions in (a), and DeMo’s predictions in (b).

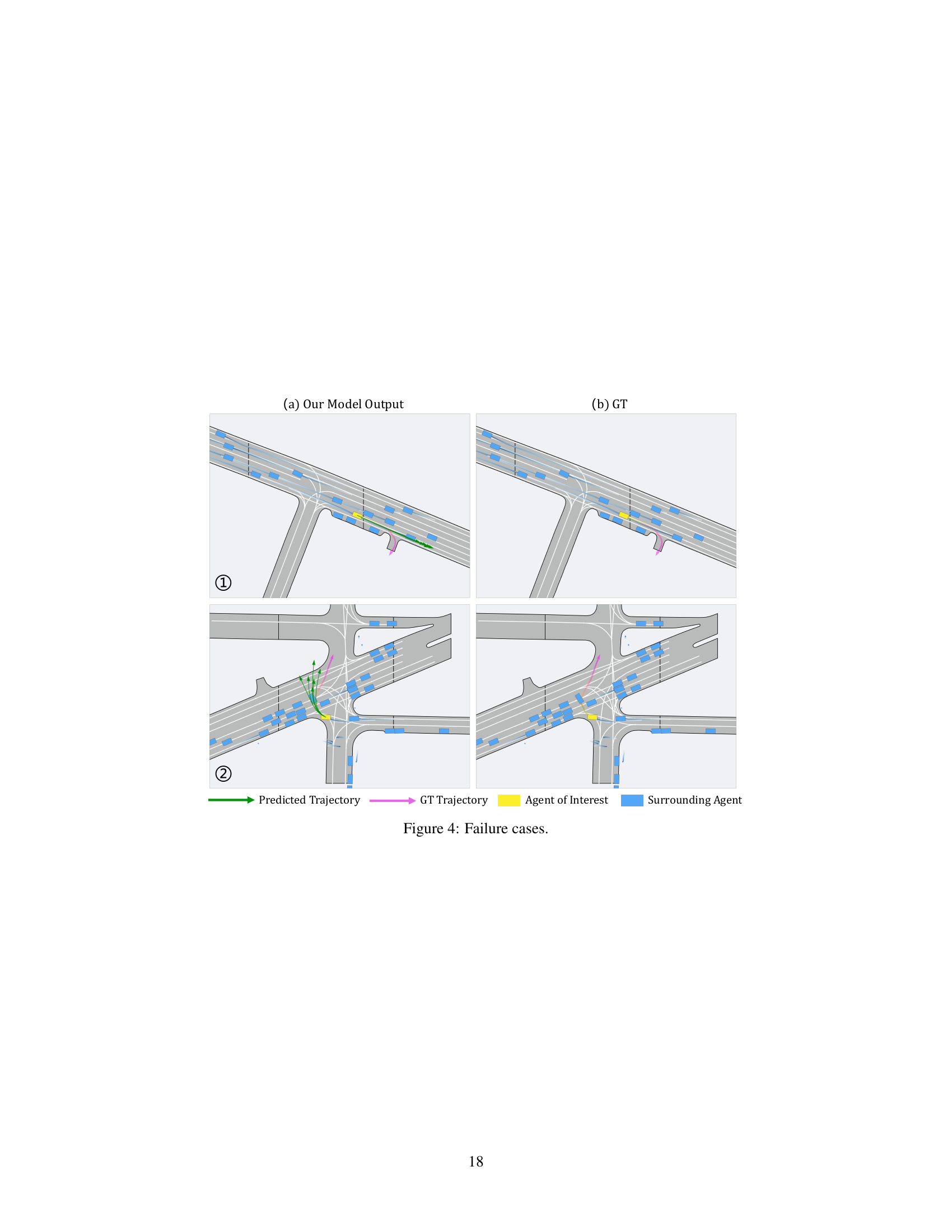
This figure compares the qualitative results of the baseline model and DeMo on the Argoverse 2 single-agent validation set. It shows six examples of trajectories. For each example, there are three panels: (a) shows the predictions from the baseline model that uses a single query to predict trajectories; (b) shows the predictions from DeMo that uses decoupled mode queries and state queries; (c) shows the ground truth trajectories. The figure visually demonstrates that DeMo is superior in prediction accuracy, particularly when the agents’ movements are complex or involve changes in direction.
More on tables
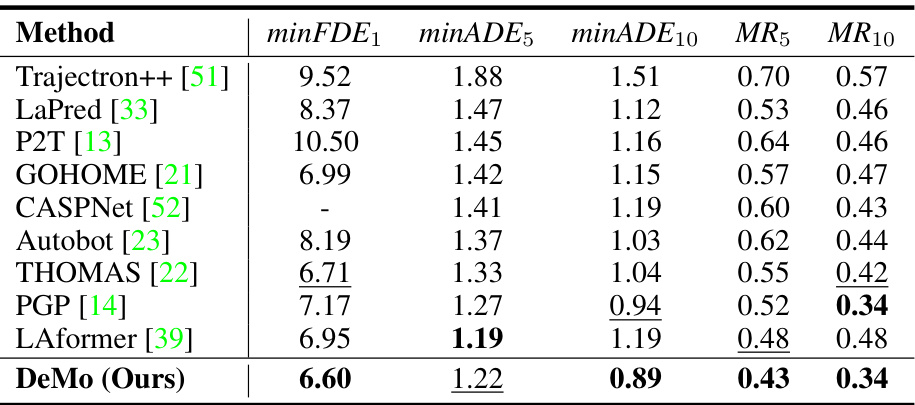
This table compares the performance of DeMo against other state-of-the-art methods on the nuScenes benchmark dataset for motion forecasting. The metrics used are standard in the field, including various versions of Average Displacement Error (ADE) and Final Displacement Error (FDE), along with Miss Rate (MR). Lower values indicate better performance. The table highlights DeMo’s competitive performance, showing superior results in several metrics compared to other approaches.

This table compares the performance of DeMo against other state-of-the-art methods on the Argoverse 2 multi-agent dataset. The metrics used are avgMinFDE₁, avgMinADE₁, avgMinFDE₆, avgMinADE₆, and actorMR₆, which assess the average minimum final displacement error, average minimum average displacement error, at horizons of 1 and 6 seconds, respectively, and the actor miss rate at 6 seconds. Lower values indicate better performance.

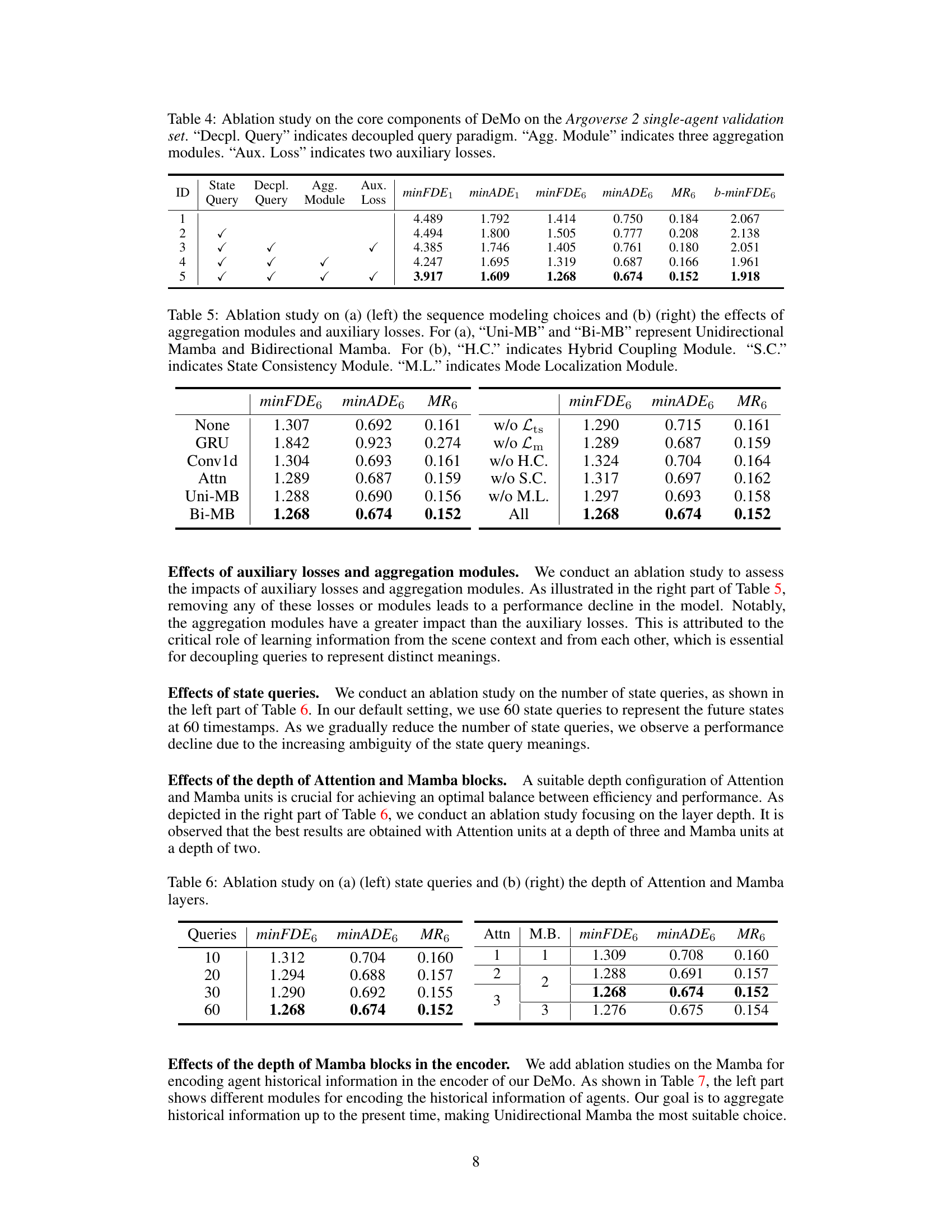
This table presents the results of an ablation study performed on the DeMo model using the Argoverse 2 single-agent validation set. It systematically evaluates the impact of different model components on the performance metrics: minFDE₁, minADE₁, minFDE₆, minADE₆, MR₆, and b-minFDE₆. Each row represents a different model configuration, indicating whether specific components (State Query, Decoupled Query, Aggregation Module, Auxiliary Loss) are included or excluded. The results show how each component contributes to the overall performance of the DeMo model.
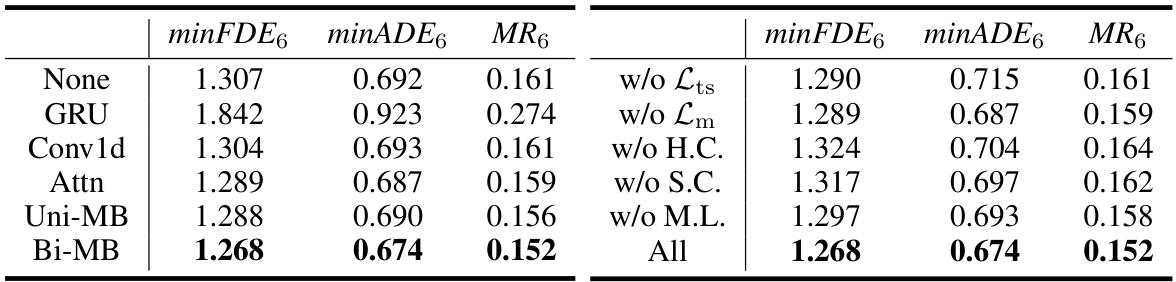
This table presents the ablation study results on different components of the DeMo model. The left part shows the impact of different sequence modeling methods (GRU, Conv1d, Attention, Unidirectional Mamba, and Bidirectional Mamba) on the model’s performance. The right part shows the influence of removing each of the three aggregation modules (Hybrid Coupling Module, State Consistency Module, and Mode Localization Module) and the two auxiliary loss functions (Lts and Lm) individually on the model’s performance. Bi-directional Mamba shows the best performance in both parts.

This ablation study investigates the impact of the number of state queries and the depth of the attention and Mamba modules on the model’s performance. The left side shows how the performance metrics change as the number of state queries (10, 20, 30, 60) varies. The right side shows the effect of varying the number of layers in the attention and Mamba modules on model performance. The best performance is achieved with 60 state queries, 3 attention layers and 2 Mamba layers.

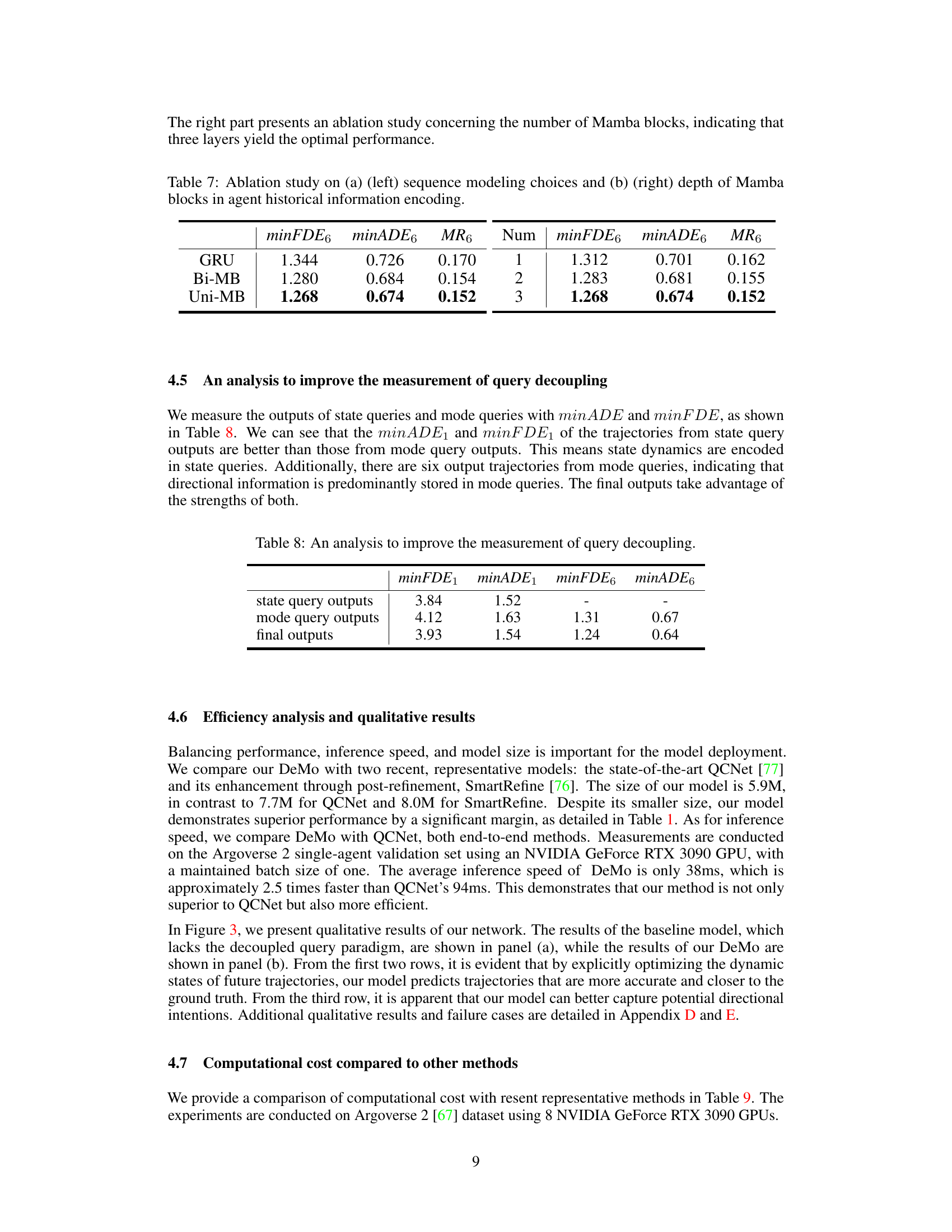
This table presents the ablation study results on the impact of different sequence modeling choices (GRU, Bi-Mamba, Uni-Mamba) and the depth of Mamba blocks in the encoder for agent historical information. The results show the effects on the minFDE6, minADE6, and MR6 metrics. The best performance is achieved with the unidirectional Mamba configuration and a depth of three for the Mamba blocks.

This table presents a comparison of the performance of state query outputs, mode query outputs, and final outputs in terms of minimum final displacement error (minFDE) and minimum average displacement error (minADE) for prediction horizons of 1 and 6 seconds. The results show that state queries better capture state dynamics while mode queries excel at capturing directional intentions. The final outputs combine the strengths of both.

This table compares the performance of DeMo against other state-of-the-art methods on the Argoverse 2 single-agent motion forecasting benchmark. The metrics used are minADE (minimum Average Displacement Error), minFDE (minimum Final Displacement Error), MR (Miss Rate), and b-minFDE (Brier minimum Final Displacement Error), all calculated for prediction horizons of 1 and 6 seconds. The table is divided into two sections: single models and models using ensemble methods. The best performing model for each metric is shown in bold, while the second-best is underlined, offering a clear visual comparison of model performance.
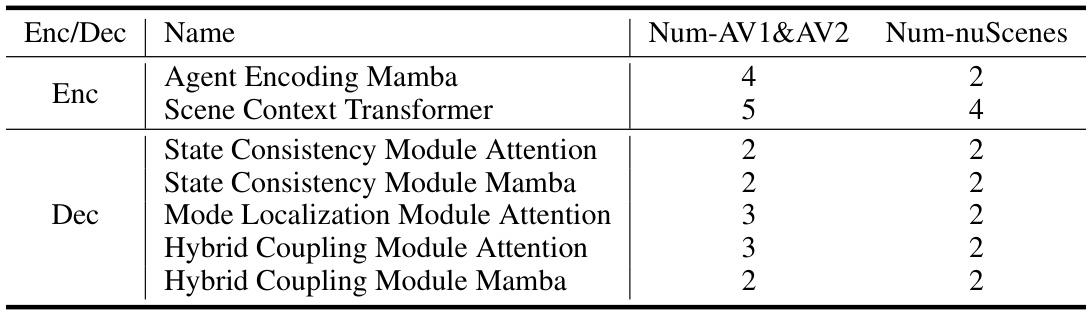
This table shows the number of layers used in each module of the DeMo framework for the Argoverse datasets (AV1&AV2) and the nuScenes dataset. The modules are categorized into encoder (Enc) and decoder (Dec) components, and further divided based on their function (e.g., Agent Encoding, Scene Context, State Consistency, Mode Localization, Hybrid Coupling). The number of layers varies for each module depending on the dataset used.
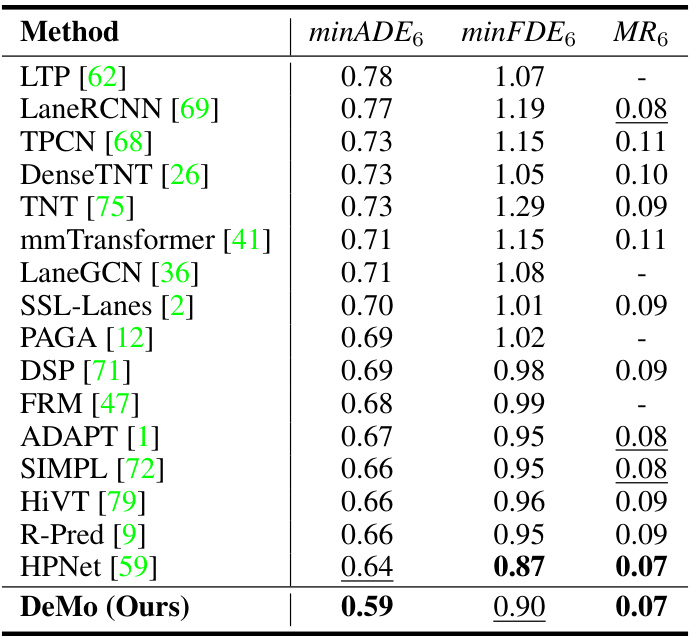
This table presents a comparison of the DeMo model’s performance against other state-of-the-art models on the Argoverse 2 single-agent motion forecasting benchmark. It shows the minimum Average Displacement Error (minADE), minimum Final Displacement Error (minFDE), miss rate (MR), and best minimum Final Displacement Error (b-minFDE) for both single models and models using ensembling. The best performance for each metric is highlighted in bold, and the second best is underlined.

This table compares the performance of DeMo against other state-of-the-art motion forecasting models on the Argoverse 2 single-agent test dataset. The metrics used include minimum Average Displacement Error (minADE), minimum Final Displacement Error (minFDE), miss rate (MR), and the Brier-modified minimum Final Displacement Error (b-minFDE). The table is split into two sections: one showing results for individual models and another showing results from models using ensembling techniques. The best performing model for each metric is highlighted in bold, and the second-best is underlined.
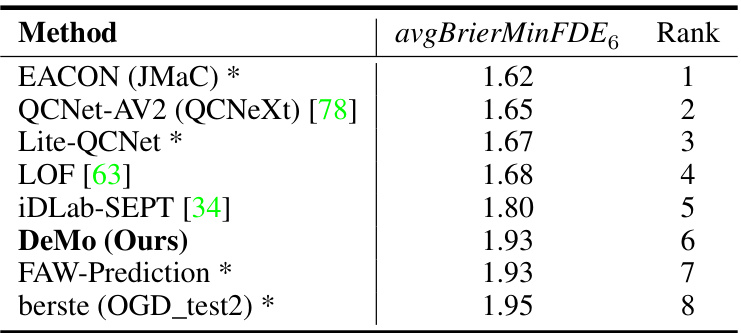
This table compares the performance of different methods on the Argoverse 2 multi-agent dataset. The metric used is avgBrierMinFDE6, representing the average of the lowest Brier minimum final displacement errors across all agents in a scene. The ranking shows the relative performance of each method compared to others.

This table presents the performance comparison of different methods on the Waymo Open Motion Dataset (WOMD). The metrics used are minimum final displacement error (minFDE6) and minimum average displacement error (minADE6). The results show that DeMo outperforms other state-of-the-art methods on this dataset.
Full paper#