↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing image quantization models like VQGAN struggle with large codebooks, leading to low utilization rates and performance limitations. This is because the optimization of codebooks is inefficient and usually only a small subset of entries are actually used. This paper addresses this by proposing a novel approach called VQGAN-LC.
VQGAN-LC initializes a large codebook (100,000 entries) using a pretrained model. The key is that instead of directly optimizing each codebook entry, it optimizes a projector network that maps the entire codebook to a latent space. This strategy maintains a high codebook utilization rate (99%) and significantly improves performance on various downstream tasks such as image reconstruction, classification, and generation across different generative models. The results demonstrate that scaling up the codebook size significantly improves model performance while incurring almost no additional computational cost. This is a significant advancement in image quantization, enhancing the representational capacity of VQGAN and its applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation and quantization because it presents a novel method to significantly improve the performance and scalability of VQGAN. The proposed approach, achieving a 99% utilization rate with a 100,000-entry codebook, opens new avenues for research in high-resolution image generation and other downstream applications. Its impact lies in enhancing the representational capacity of existing models, leading to improved image synthesis and downstream task performance.
Visual Insights#
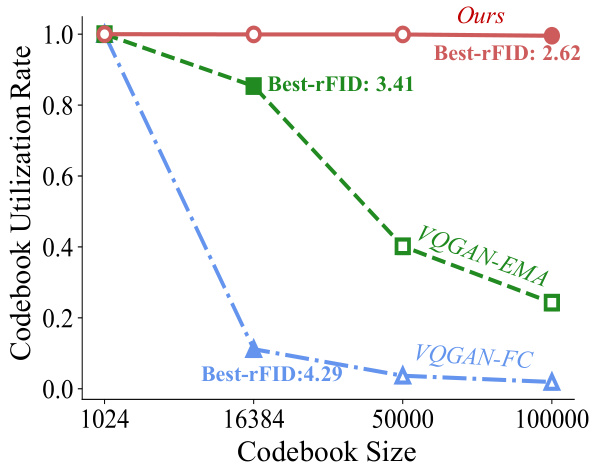
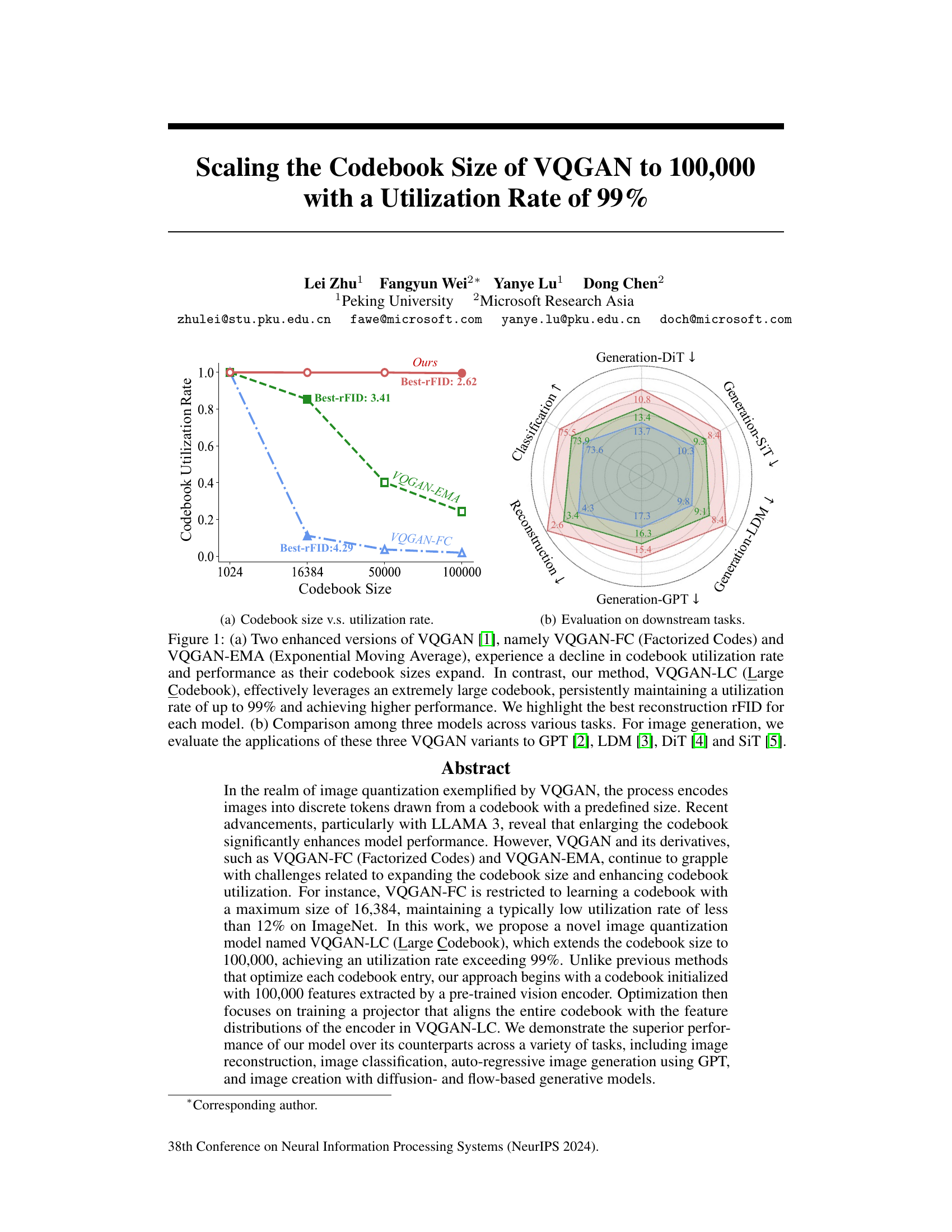
This figure compares three VQGAN models (VQGAN-FC, VQGAN-EMA, and the proposed VQGAN-LC) in terms of codebook utilization rate and performance across different codebook sizes. The left panel (a) shows that VQGAN-FC and VQGAN-EMA suffer from decreasing utilization and performance as codebook size increases. In contrast, VQGAN-LC maintains high utilization (near 99%) even with a much larger codebook. The right panel (b) shows a comparison of the three models on downstream tasks like image generation using different models (GPT, LDM, DiT, SiT).

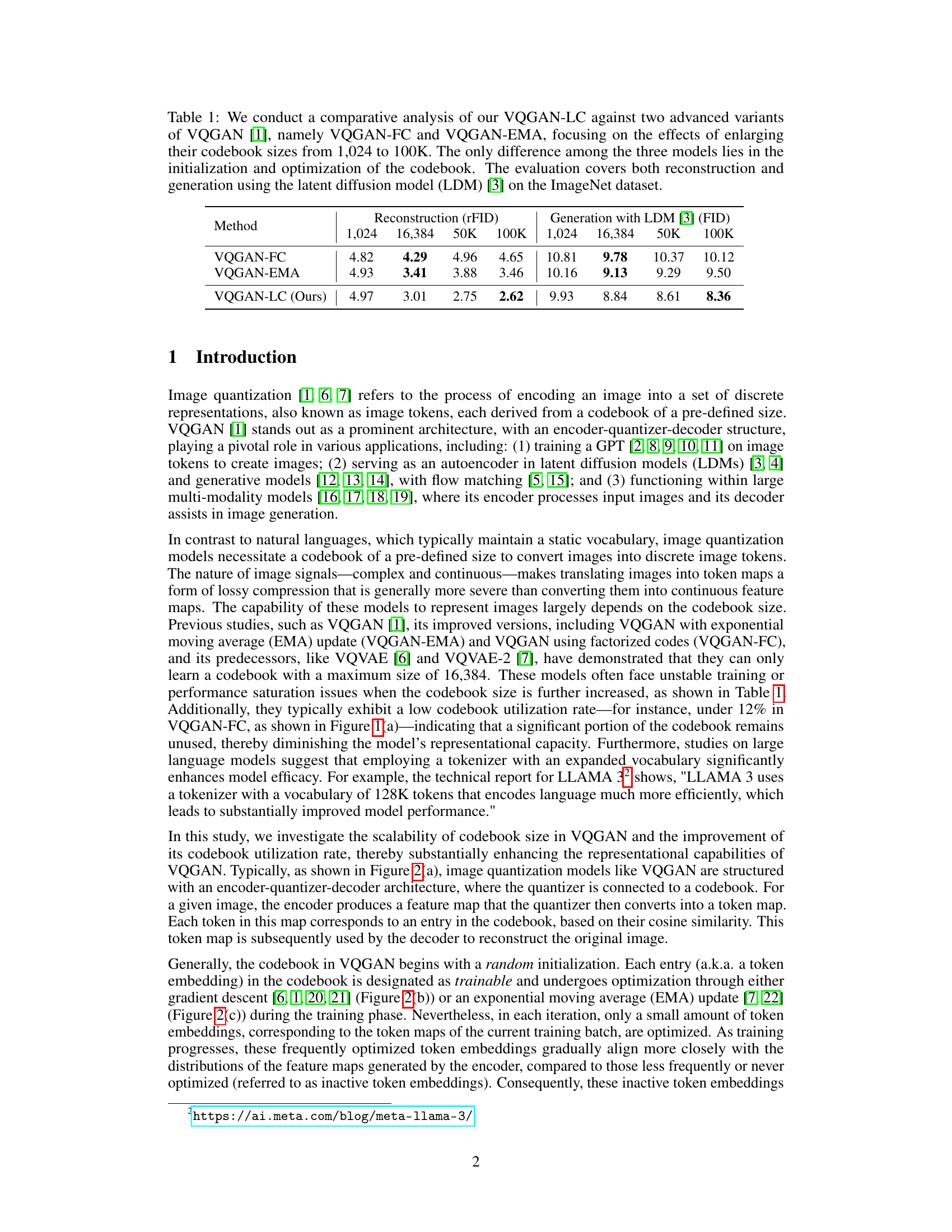
This table compares the performance of three different models (VQGAN-FC, VQGAN-EMA, and VQGAN-LC) on image reconstruction and generation tasks using the ImageNet dataset. The models differ in their codebook initialization and optimization strategies. The table shows the rFID score for reconstruction and FID score for LDM generation, for each model, and for different codebook sizes (1024, 16384, 50K, 100K).
In-depth insights#
Large VQGAN Codebooks#
The concept of “Large VQGAN Codebooks” introduces a significant advancement in vector quantized generative adversarial networks (VQGANs). Traditional VQGANs suffered from limited codebook sizes, restricting their ability to represent diverse image features and leading to low codebook utilization. Enlarging the codebook dramatically improves the model’s capacity to capture intricate details and nuances in images, overcoming the limitations of smaller codebooks. However, simply increasing the codebook size presents challenges. Existing methods often struggle with codebook optimization and maintaining high utilization rates as codebook size grows. The key innovation lies in addressing these challenges through novel codebook initialization and optimization techniques. By using pre-trained vision encoders and focusing on projector optimization rather than direct codebook entry optimization, a high utilization rate is achieved, even with extremely large codebooks. This approach enables VQGANs to achieve superior performance in various downstream tasks, including image reconstruction, classification, and generation, demonstrating the effectiveness of this novel scaling strategy.
Projector Optimization#
Projector optimization, in the context of the described VQGAN-LC model, represents a crucial innovation. Instead of directly training individual codebook entries, which leads to underutilization, the method trains a projector network. This projector maps a pre-initialized, large codebook (100,000 entries) into the latent space of the VQGAN encoder. The optimization focuses on this projector, not the codebook itself. This strategy ensures that almost all codebook entries remain active during training, achieving high utilization rates (exceeding 99%). The effectiveness of this approach is demonstrated by significantly improved performance across various downstream tasks compared to prior methods. The pre-trained vision encoder provides a robust initialization, allowing the projector to effectively align the codebook with the feature space, enabling the model to learn a more complete and efficient representation of the image data. While this optimization approach greatly benefits from the initialization, it is still crucial for maximizing performance, especially when handling very large codebooks. This elegant solution bypasses the inherent limitations of traditional VQGAN training methods in utilizing very large codebooks, enabling it to scale to significantly larger codebooks with remarkably high utilization rates.
Codebook Utilization#
Codebook utilization, a critical factor in vector quantized image generation (VQGAN) models, refers to the efficiency with which the learned codebook entries are used to represent image features. Low utilization indicates wasted capacity, as many codebook entries remain unused, hindering the model’s ability to capture diverse image information. Previous methods, like VQGAN-FC and VQGAN-EMA, suffer from declining utilization rates as codebook size increases, limiting their scalability. The key contribution of VQGAN-LC is its novel approach to significantly improve codebook utilization. This is achieved by initializing the codebook with features from a pretrained vision encoder and then optimizing a projector to align the codebook with image feature distributions, rather than optimizing individual codebook entries. This strategy results in a high utilization rate (exceeding 99%), allowing VQGAN-LC to leverage a much larger codebook (100,000 entries) successfully, leading to improved performance across several downstream tasks, demonstrating the importance of efficient codebook usage for effective image representation and generation.
Downstream Tasks#
The concept of “Downstream Tasks” in a research paper typically refers to the application of a model’s learned representations or predictions to other, related problems. A strong downstream task analysis demonstrates the generalizability and practical value of the model. In the context of a generative model, such as one focused on image quantization, downstream tasks might include image reconstruction, classification, and generation tasks using different generative model architectures (like GPT, LDM, DiT, and SiT). By evaluating performance across various downstream tasks, researchers assess the model’s versatility and robustness. Strong performance across diverse tasks validates the model’s learned representations as meaningful and useful features, not just specific to the primary task for which it was trained. Conversely, poor performance on downstream tasks suggests potential limitations of the model or its training methodology, indicating a lack of generalizable feature extraction. The selection of downstream tasks is critical; they should be relevant to the primary focus of the research and chosen to comprehensively evaluate the model’s capabilities. The results of downstream tasks reveal whether the model’s learned representations capture genuinely useful information or merely reflect artifacts of the training process. Therefore, a thorough evaluation of downstream tasks is essential for a robust and comprehensive assessment of a model’s capabilities.
Ablation Studies#
Ablation studies systematically remove or alter components of a model to assess their individual contributions. In this context, it is crucial to isolate the impact of codebook size and initialization on the overall performance of the image quantization model. The study should evaluate the effect of different codebook sizes, investigating how model performance changes with increasing or decreasing codebook capacity. Furthermore, it is vital to compare various codebook initialization strategies, analyzing the effectiveness of different methods—random initialization, K-means clustering, or initializing with features from a pre-trained model. The goal is to identify the optimal codebook size that balances performance and efficiency while understanding the contribution of each initialization method to the model’s success. The results of the ablation study should clearly highlight the importance of a well-initialized and appropriately sized codebook, demonstrating the value of the proposed method while comparing to alternatives. Any unexpected trends or interactions between codebook size and initialization method would be interesting insights.
More visual insights#
More on figures
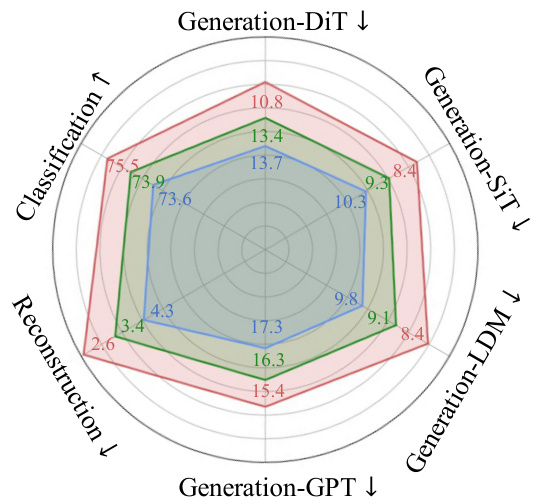
This figure compares three different versions of VQGAN (VQGAN-FC, VQGAN-EMA, and VQGAN-LC) in terms of their codebook utilization rate and performance on various downstream tasks. Panel (a) shows how codebook utilization decreases as the size increases for VQGAN-FC and VQGAN-EMA, whereas VQGAN-LC maintains a high utilization rate. Panel (b) presents a radar chart that compares the performance of the three VQGAN methods on image reconstruction and generation using different generative models (GPT, LDM, DiT, and SiT).
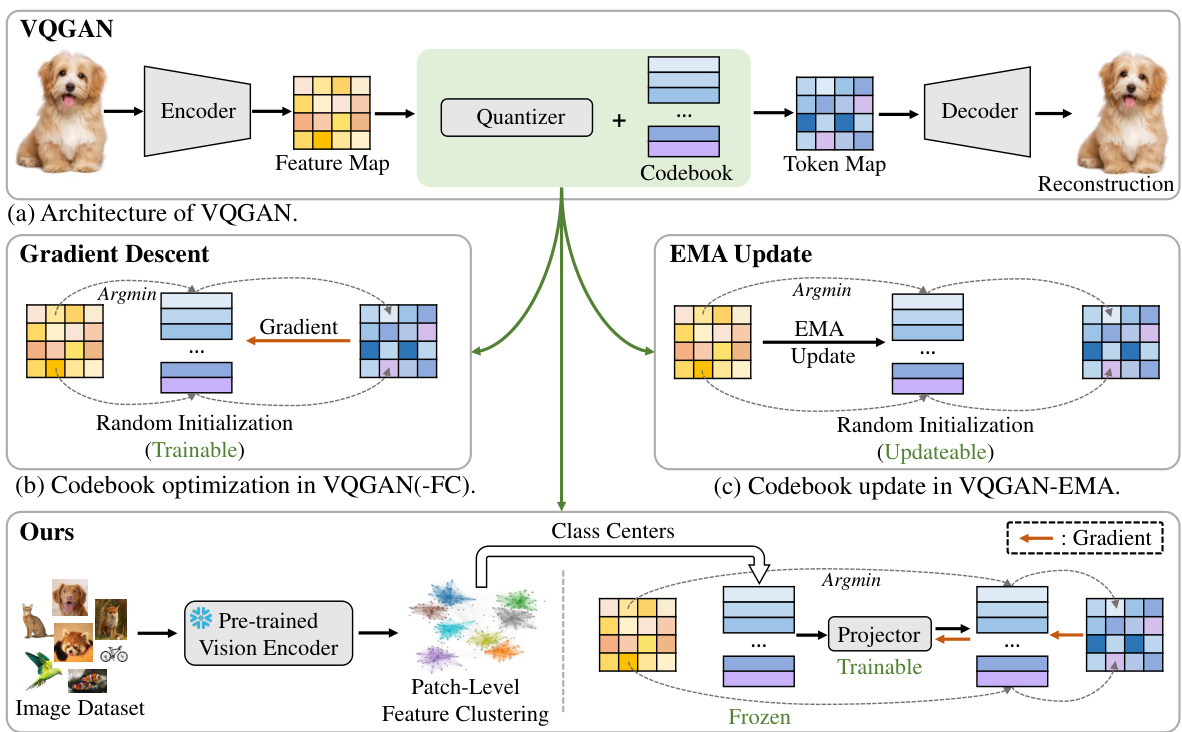
This figure illustrates the architectures of VQGAN, VQGAN-FC, VQGAN-EMA, and the proposed VQGAN-LC. It shows how each model handles codebook optimization, highlighting the differences in their initialization and training methods. (a) depicts the basic VQGAN structure. (b) and (c) show how VQGAN-FC and VQGAN-EMA update the codebook, respectively. (d) details the novel approach used in VQGAN-LC, which initializes the codebook with pre-trained features and then trains a projector to align the codebook with the encoder’s output.
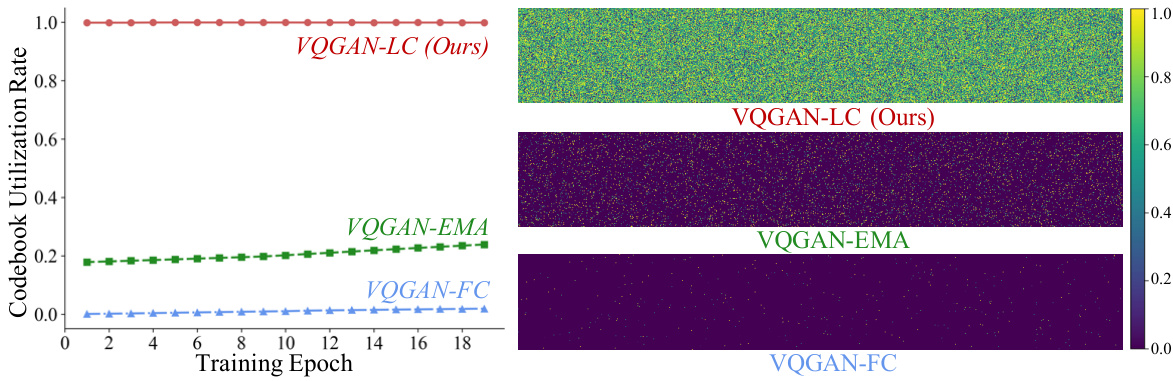
This figure shows the codebook utilization rate over training epochs for three different VQGAN variants: VQGAN-LC, VQGAN-EMA, and VQGAN-FC. The left panel plots the utilization rate over time, demonstrating that VQGAN-LC maintains a near-perfect utilization rate (close to 100%) throughout training, unlike the other two methods, which show a significant decrease in utilization rate as training progresses. The right panel is a heatmap visualizing the average utilization frequency of each codebook entry across all training epochs, providing a visual representation of the codebook usage patterns. VQGAN-LC’s heatmap shows a much more uniform distribution of color, indicating that a large fraction of its codebook is used consistently, while the other models show a higher concentration of dark pixels, suggesting many entries remain largely unused.
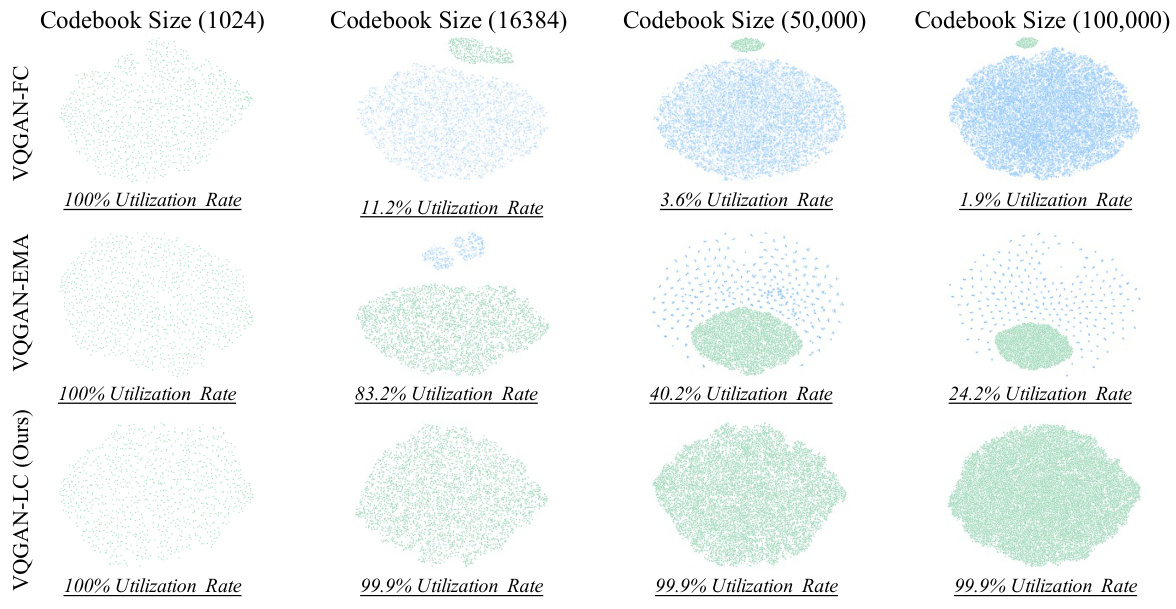
This figure visualizes the distribution of active (green) and inactive (blue) codebook entries for three different models: VQGAN-FC, VQGAN-EMA, and the proposed VQGAN-LC. The visualization uses t-SNE to reduce the dimensionality of the codebook entries for easier plotting. It shows how the proportion of inactive codebook entries increases as the codebook size grows for VQGAN-FC and VQGAN-EMA, while VQGAN-LC maintains a high utilization rate even with a large codebook size. The varying shades of blue and green represent the frequency of usage for each code. Darker shades indicate higher usage frequencies.

This figure shows the codebook utilization rate over training epochs for three different VQGAN variants: VQGAN-LC, VQGAN-EMA, and VQGAN-FC. The left panel displays the overall utilization rate for each epoch, highlighting how VQGAN-LC maintains a near-perfect utilization rate (close to 99%), whereas VQGAN-EMA and VQGAN-FC show significantly lower and decreasing utilization rates as the training progresses. The right panel provides a detailed visualization of the average utilization frequency of each codebook entry across all epochs, showing the distribution of usage for each entry, with VQGAN-LC demonstrating significantly more uniform utilization.

This figure visualizes the active (green) and inactive (blue) codebook entries for three different models: VQGAN-FC, VQGAN-EMA, and the proposed VQGAN-LC. It uses t-SNE to reduce the dimensionality of the codebook for visualization. The visualization shows how the number of inactive codes increases with codebook size in VQGAN-FC and VQGAN-EMA, while VQGAN-LC maintains a high utilization rate, even with a significantly larger codebook.

This figure visualizes the active and inactive codebook entries for three different models: VQGAN-FC, VQGAN-EMA, and the proposed VQGAN-LC. It uses t-SNE to reduce the dimensionality of the codebook embeddings and project them into a 2D space for visualization. Active codes (frequently used during training) are shown in green, while inactive codes (rarely or never used) are shown in blue. The visualization helps demonstrate how the codebook utilization rate differs across the models and shows that VQGAN-LC uses nearly all of its codebook entries, while VQGAN-FC and VQGAN-EMA have many unused entries, particularly as the codebook size increases.

This figure shows sample images generated by the VQGAN-LC model using the Latent Diffusion Model (LDM) for three different categories from the ImageNet dataset. The model uses a codebook of size 100,000 and a classifier-free guidance scaling factor of 1.4. Each category is represented by a 4x4 grid of generated images demonstrating the diversity achievable by the model within a given category.

This figure shows the qualitative results of class-conditional image generation using the proposed VQGAN-LC model with the DiT architecture on the ImageNet dataset. The model used 256 tokens (arranged in a 16x16 grid) to generate images. The figure showcases several example image categories, each with several generated images, providing a visual demonstration of the model’s capabilities. Classifier-free guidance with a scale of 8.0 was used during generation. The category name and corresponding ID are provided for each example category.

This figure visualizes the distribution of active (green) and inactive (blue) codebook entries for three different VQGAN models using t-SNE. It demonstrates how the proportion of inactive codes increases with larger codebook sizes in VQGAN-FC and VQGAN-EMA, while VQGAN-LC maintains a high utilization rate even with a large codebook.

This figure compares three versions of VQGAN (VQGAN-FC, VQGAN-EMA, and the proposed VQGAN-LC) in terms of codebook utilization and performance across various image generation tasks. Panel (a) shows the relationship between codebook size and utilization rate, demonstrating that VQGAN-LC achieves a significantly higher utilization rate (up to 99%) than the other methods, even with a much larger codebook. Panel (b) shows the performance of these models on various downstream tasks, suggesting that VQGAN-LC achieves superior performance.

This figure visualizes the active (green) and inactive (blue) codebook entries for three different VQGAN models (VQGAN-FC, VQGAN-EMA, and VQGAN-LC) using t-SNE for dimensionality reduction. The visualization shows how the number of inactive codes increases as the codebook size grows in VQGAN-FC and VQGAN-EMA, highlighting the improved codebook utilization of VQGAN-LC.
More on tables

This table presents a comparison of various image quantization models on the ImageNet-1K dataset, focusing on their reconstruction performance. It shows the reconstruction error (rFID), perceptual similarity (LPIPS), peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM) for different models with varying codebook sizes and numbers of tokens used to represent each image. The table highlights the improved performance of VQGAN-LC (the proposed model) in terms of lower reconstruction error and higher perceptual similarity, especially with larger codebooks.
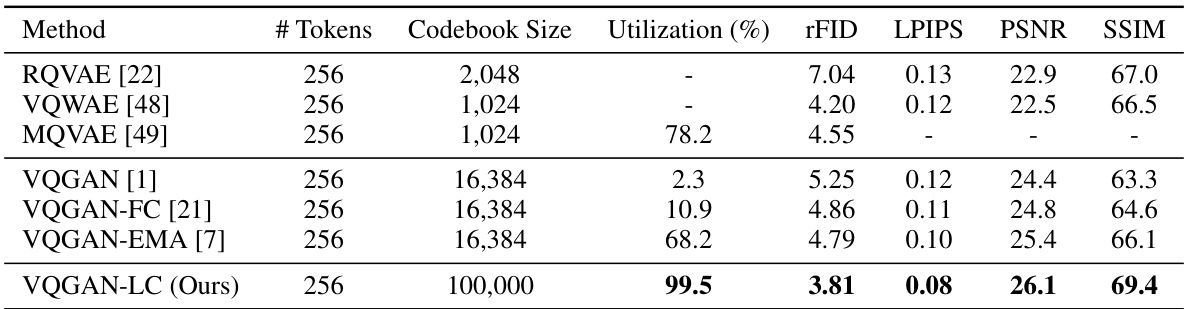
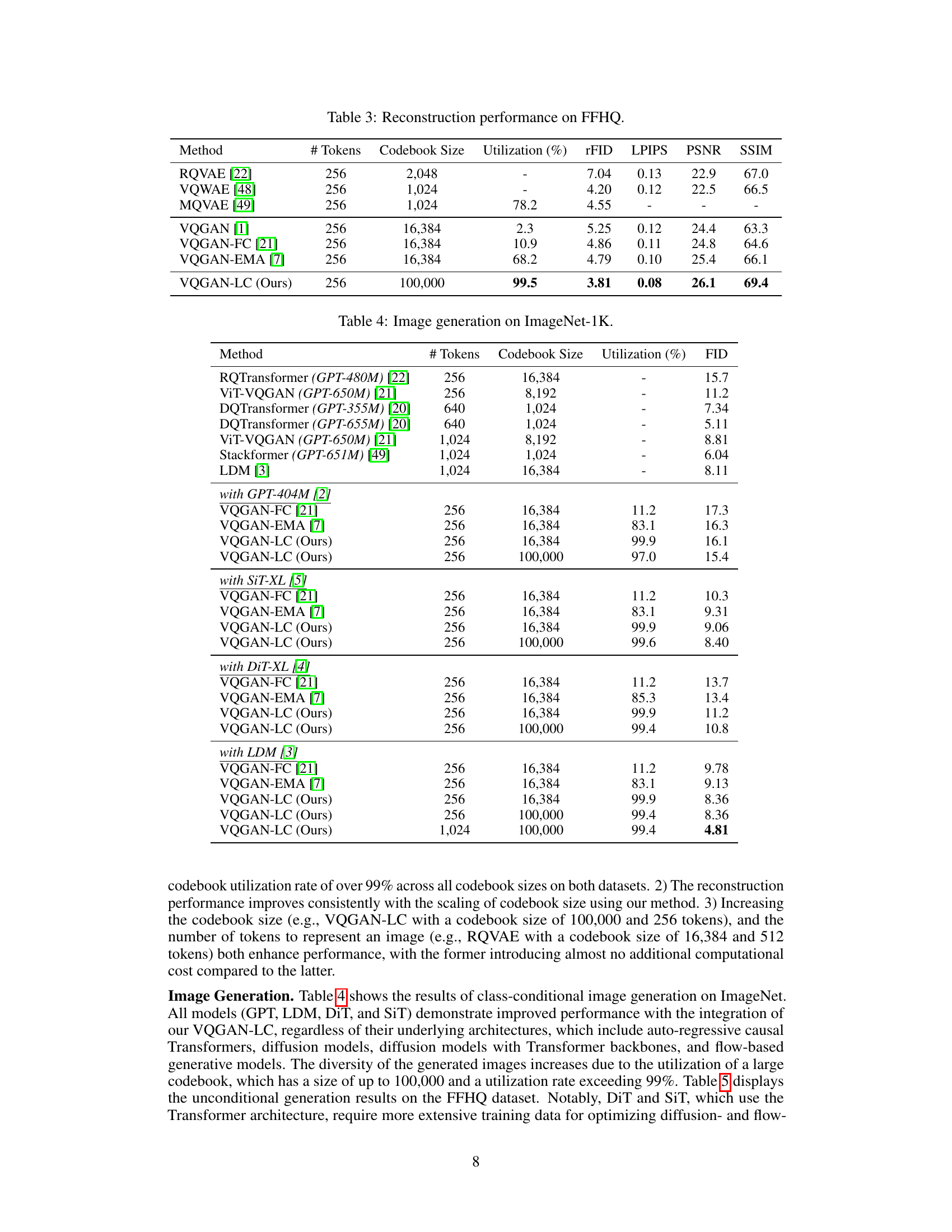
This table presents the reconstruction performance results on the FFHQ dataset. It compares several methods (RQVAE, VQWAE, MQVAE, VQGAN, VQGAN-FC, VQGAN-EMA, and VQGAN-LC) across different metrics: # Tokens (number of tokens used to represent an image), Codebook Size, Utilization (percentage of codebook entries utilized), rFID (reconstruction quality), LPIPS (perceptual similarity), PSNR (peak signal-to-noise ratio), and SSIM (structural similarity index). The table highlights the performance improvement achieved by VQGAN-LC, demonstrating its ability to efficiently utilize a large codebook.
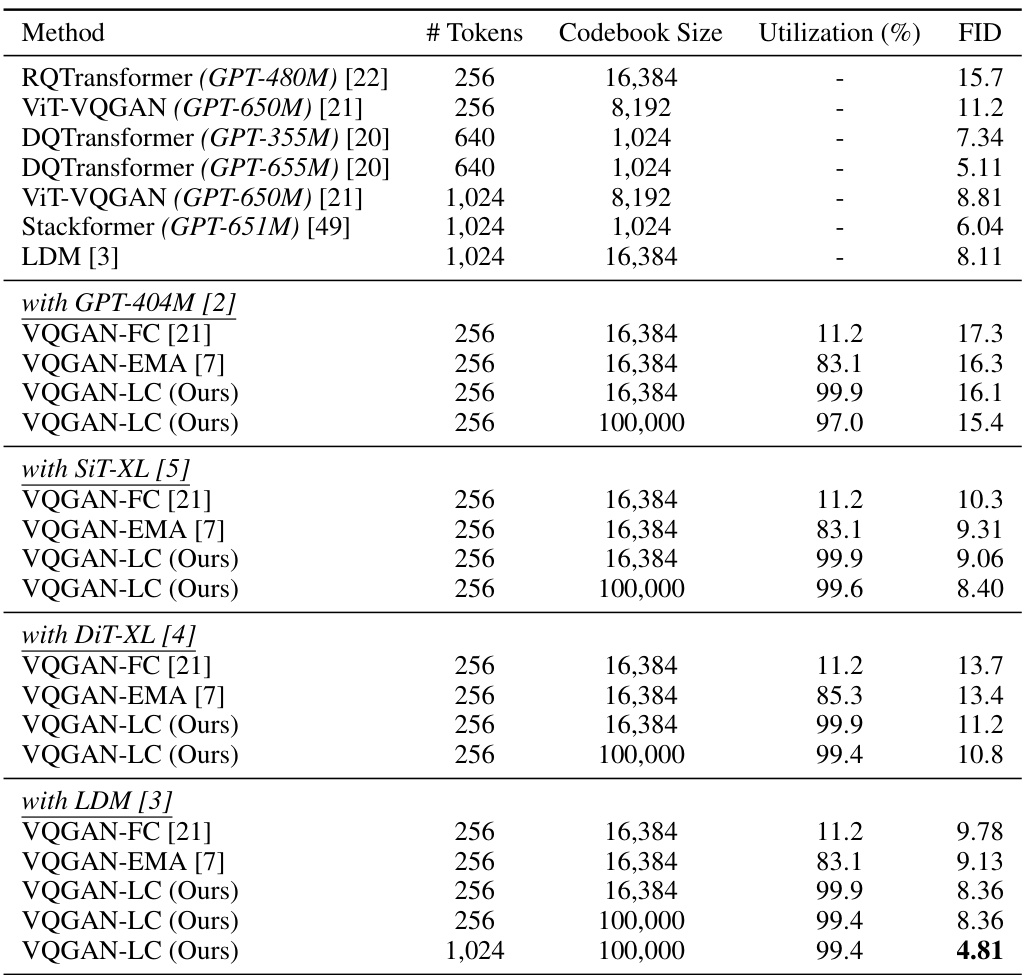
This table presents the FID scores achieved by various image generation models when integrated with different image quantization models on the ImageNet-1K dataset. It compares the FID scores of several methods, including different variants of VQGAN (VQGAN-FC, VQGAN-EMA, and VQGAN-LC), with different image generation models (GPT, SiT-XL, DiT-XL, and LDM). The table highlights the impact of using VQGAN-LC with a large codebook size (100,000) on the FID scores, demonstrating improved performance across various generation models. The number of tokens (# Tokens) and codebook size used by each method is also provided, along with the codebook utilization rate for the VQGAN variants.
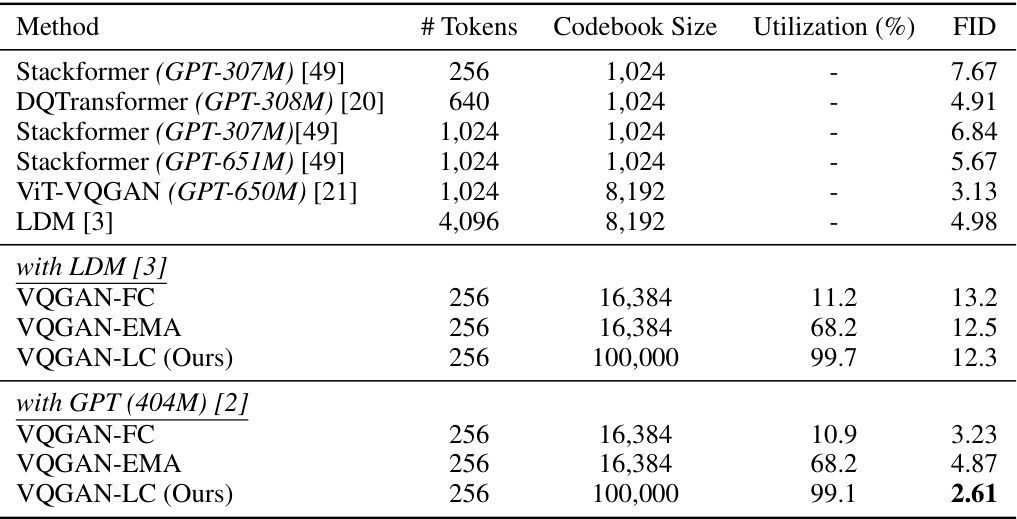
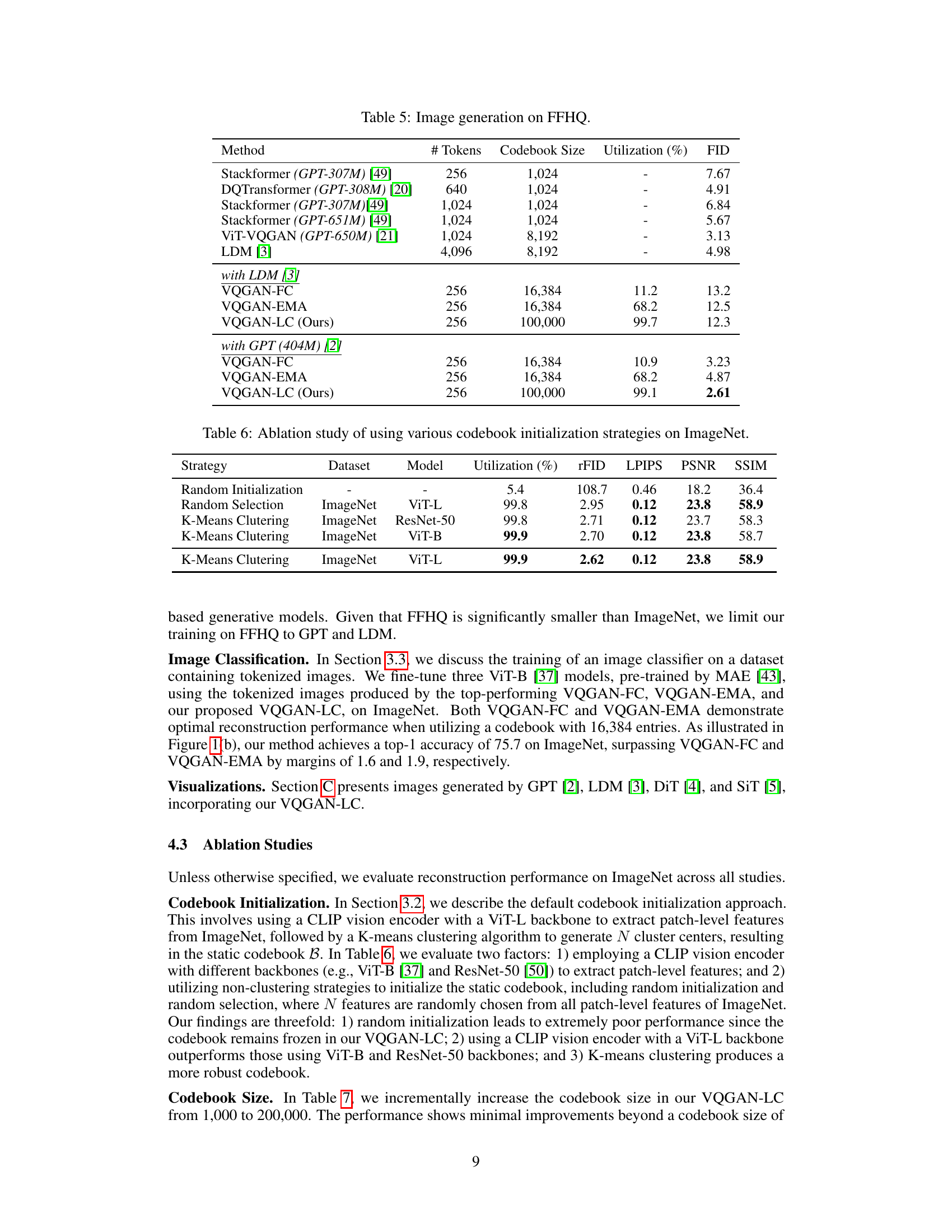
This table presents the FID scores for unconditional image generation on the FFHQ dataset using different image quantization models integrated with various generative models like GPT, LDM. It shows the performance of VQGAN-FC, VQGAN-EMA and VQGAN-LC (the proposed method) with different codebook sizes and utilization rates. The FID scores indicate the quality of generated images, with lower scores indicating better quality.

This table presents the ablation study results on ImageNet, comparing different codebook initialization strategies (Random Initialization, Random Selection, K-Means Clustering) using various vision models (ViT-L, ResNet-50, ViT-B). It shows the utilization rate, rFID, LPIPS, PSNR, and SSIM metrics for each strategy. The goal is to determine the best codebook initialization method for optimal performance.
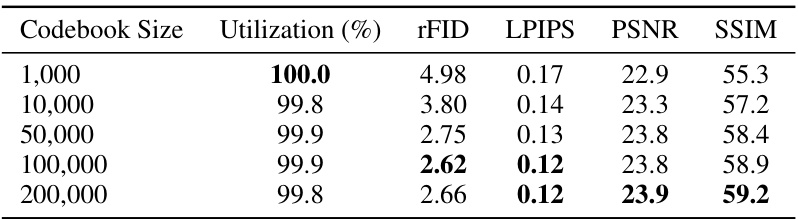
This table presents the ablation study results on the ImageNet dataset by varying the codebook size from 1,000 to 200,000. The results show minimal improvements beyond a codebook size of 100,000. Key metrics such as rFID, LPIPS, PSNR, and SSIM are reported for each codebook size to evaluate reconstruction quality. The utilization rate remains consistently high, exceeding 99% across all sizes.

This table shows the computational cost (measured in MACs - multiply-accumulate operations) and model size (in parameters) for the VQGAN-LC model with two different codebook sizes: 16,384 and 100,000. It highlights that increasing the codebook size from 16,384 to 100,000 has a negligible impact on computational cost and model size, demonstrating the efficiency of the proposed method.
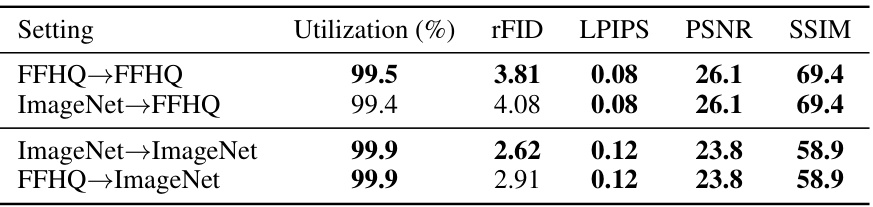
This table presents the reconstruction performance results for the FFHQ dataset, focusing on metrics such as rFID, LPIPS, PSNR, and SSIM. It compares the performance of different models: RQVAE, VQWAE, MQVAE, VQGAN, VQGAN-FC, VQGAN-EMA, and VQGAN-LC (the proposed model). The table shows the number of tokens, codebook size, utilization rate, and the reconstruction performance in terms of these metrics.

This table presents an ablation study on ImageNet, comparing the reconstruction performance (measured by rFID, LPIPS, PSNR, and SSIM) under different codebook initialization strategies. It shows the results when the codebook is static (not updated during training), when a projector is used to map the codebook to a latent space, and when both are implemented. The results highlight the significant improvement in reconstruction quality when a projector is used with a static codebook, indicating the effectiveness of the proposed method.
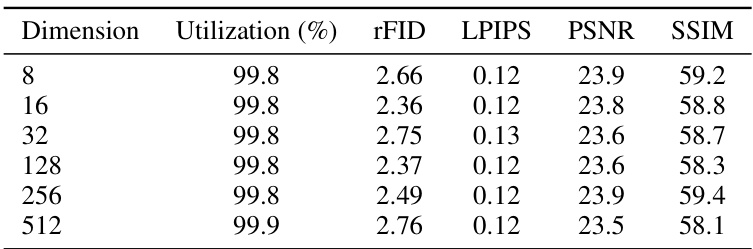
This table presents the results of an ablation study conducted to evaluate the impact of varying the dimension of the projected codebook (D’) in the proposed VQGAN-LC model. The study was performed on the ImageNet dataset. The table shows the codebook utilization rate, reconstruction error (rFID), perceptual loss (LPIPS), peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM) for different values of D’, ranging from 8 to 512. The results indicate that the model’s performance remains relatively stable across a wide range of D’ values, consistently maintaining a high codebook utilization rate.
Full paper#