↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open-vocabulary 3D object detection (OV-3Det) faces a major hurdle: the scarcity of labeled 3D data. Existing methods often rely on paired RGB-D data or incorporate limited 3D annotations, hindering progress. This problem is particularly acute for open-vocabulary scenarios, where the object categories are not limited to a predefined set. This research tackles this challenge head-on.
The ImOV3D framework ingeniously uses only 2D images for training. It cleverly converts 2D images into pseudo 3D point clouds and then renders them back into images, creating a pseudo-multimodal representation. This representation helps bridge the training modality gap and allows the model to effectively integrate 2D semantic information into the 3D detection task. Extensive experiments show that ImOV3D significantly outperforms existing methods, especially in scenarios with limited or no real 3D data. This opens up new possibilities for OV-3Det research.
Key Takeaways#
Why does it matter?#
This paper is highly important because it significantly advances open-vocabulary 3D object detection (OV-3Det), a crucial area in 3D computer vision. It addresses the critical bottleneck of limited 3D data by cleverly leveraging abundant 2D image datasets. This opens exciting new avenues for research in OV-3Det, enabling progress even with scarce 3D annotation resources. The proposed method’s superior performance and data efficiency make it a significant contribution to the field and has great potential to impact various downstream applications like robotics and autonomous driving.
Visual Insights#
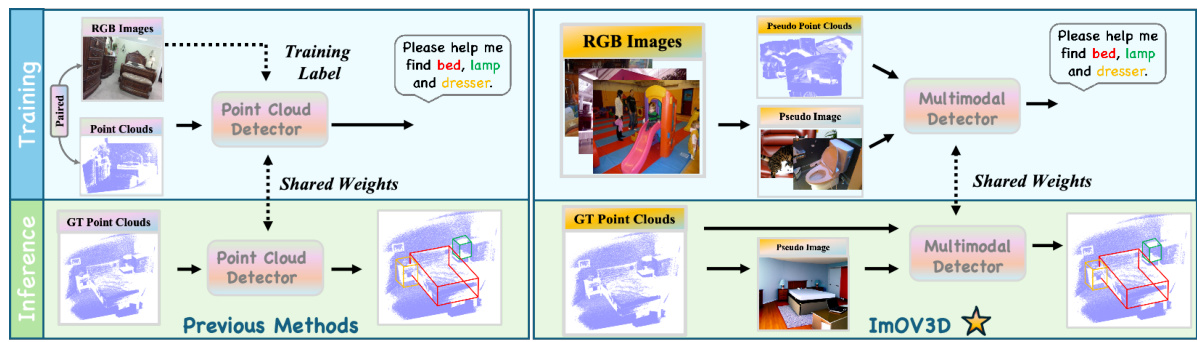
This figure compares traditional open-vocabulary 3D object detection methods with the proposed ImOV3D method. Traditional methods rely on paired RGB-D data for training and use single-modality point clouds during inference. In contrast, ImOV3D uses a large number of 2D images to generate pseudo point clouds during training. These pseudo point clouds are then rendered into images to help bridge the gap between 2D image data and 3D point cloud data. During inference, even with only point clouds as input, ImOV3D utilizes pseudo-multimodal representations to enhance detection performance.

This table presents the results of the pretraining stage experiments conducted on the SUNRGBD and ScanNet datasets. It compares the performance of ImOV3D against other existing methods (OV-VoteNet, OV-3DETR, OV-3DET) using only point cloud input during pretraining. The table highlights ImOV3D’s significant performance improvement (mAP@0.25) over the other methods. The training strategy (one-stage or two-stage) is also listed for comparison.
In-depth insights#
2D-3D Modality Gap#
The core challenge in open-vocabulary 3D object detection from 2D images lies in bridging the 2D-3D modality gap. 2D images, abundant and richly annotated, offer a wealth of information for training, yet they differ fundamentally from the 3D point cloud data used in inference. ImOV3D directly addresses this gap by constructing a pseudo-multimodal representation, unifying the training images and testing point clouds. This is achieved through flexible modality conversion: 2D images are lifted into 3D space via monocular depth estimation, and 3D point clouds are projected into 2D views through rendering. This clever approach leverages the strengths of both modalities, integrating 2D semantic information with 3D depth and structural details to create a common training space that significantly improves 3D object detection performance, even without ground truth 3D data. The effectiveness of this pseudo-multimodal approach highlights the importance of considering data representation when addressing cross-modal learning challenges.
Pseudo-Multimodal#
The concept of “Pseudo-Multimodal” in the context of a research paper likely refers to a method that simulates the benefits of multimodal data (e.g., combining images and point clouds) using only a single modality. This is crucial when dealing with scarce annotated 3D data, a common challenge in 3D object detection. The approach cleverly bridges the modality gap by constructing pseudo point clouds from 2D images using techniques like monocular depth estimation and pseudo images from 3D point clouds through rendering. This pseudo-multimodal representation allows the model to leverage the wealth of readily available 2D image data and its rich annotations during training. This strategy enhances the performance of the 3D object detector by effectively transferring semantic and geometric information from the 2D domain to the 3D domain. The effectiveness hinges on the quality of the pseudo data generation process; the closer the pseudo-data resembles real multimodal data, the better the transfer learning will be. Therefore, careful design and refinement of the modality conversion steps are critical for success. The advantages include circumventing the need for expensive and time-consuming 3D data annotation, making open-vocabulary 3D object detection more practical.
ImOV3D Framework#
The ImOV3D framework represents a significant advancement in open-vocabulary 3D object detection (OV-3Det). Its core innovation lies in cleverly circumventing the limitations of scarce 3D annotated data by leveraging abundant 2D image datasets. ImOV3D cleverly bridges the modality gap between 2D images (used for training) and 3D point clouds (used for inference) through a pseudo-multimodal representation. This involves converting 2D images into pseudo 3D point clouds via depth estimation and rendering 3D point clouds back into pseudo 2D images. This ingenious approach allows the model to learn rich semantic information from 2D images and effectively transfer it to the 3D domain, resulting in superior performance even without ground truth 3D training data. The framework’s flexible modality conversion, combined with advanced techniques like GPT-4 integration for size refinement, significantly improves the quality of the pseudo 3D data and enhances the overall accuracy of 3D object detection. ImOV3D demonstrates state-of-the-art results on benchmark datasets, showcasing its potential to revolutionize OV-3Det and open up new possibilities for applications requiring robust 3D understanding in data-scarce environments.
Open-Vocabulary 3D#
Open-vocabulary 3D object detection signifies a significant advancement in 3D computer vision. The core challenge lies in the scarcity of labeled 3D data, which limits the ability of models to generalize to unseen objects. Existing approaches leverage the abundance of 2D image data and annotations to overcome this data limitation. A key strategy involves transferring knowledge from well-performing 2D open-vocabulary detectors to the 3D domain. This often involves generating pseudo-3D annotations from 2D information, thereby creating training data for 3D models. The modality gap between 2D images and 3D point clouds remains a significant hurdle. Successful methods often employ techniques such as depth estimation and rendering to bridge this gap, creating a unified multimodal representation for training. The performance of these methods often relies heavily on the quality of pseudo-3D data and the effectiveness of the modality conversion techniques. Future work likely focuses on further improving the quality and realism of pseudo data and exploring more sophisticated techniques for transferring knowledge between modalities, particularly for handling diverse, complex 3D scenes.
Future of OV-3Det#
The future of open-vocabulary 3D object detection (OV-3Det) is promising, but challenging. Addressing the data scarcity remains a critical hurdle; current methods rely heavily on 2D data augmentation or limited 3D datasets, which hinders generalization to truly open-vocabulary scenarios. Future advancements will likely explore more sophisticated multimodal fusion techniques, moving beyond simple concatenation to robust and nuanced integration of 2D and 3D information. This will demand more advanced architectures capable of handling large-scale 2D data for training and effectively leveraging the unique geometric and structural characteristics of 3D point clouds. Improved depth estimation and more accurate 3D label generation from 2D data are crucial. Furthermore, research into efficient training strategies for large-scale datasets is essential for widespread adoption. Finally, tackling the inherent modality gap between 2D and 3D data remains key, requiring innovative approaches for effective knowledge transfer. The overall focus should be on creating robust, generalizable models capable of handling diverse and unbounded object categories in real-world 3D environments.
More visual insights#
More on figures
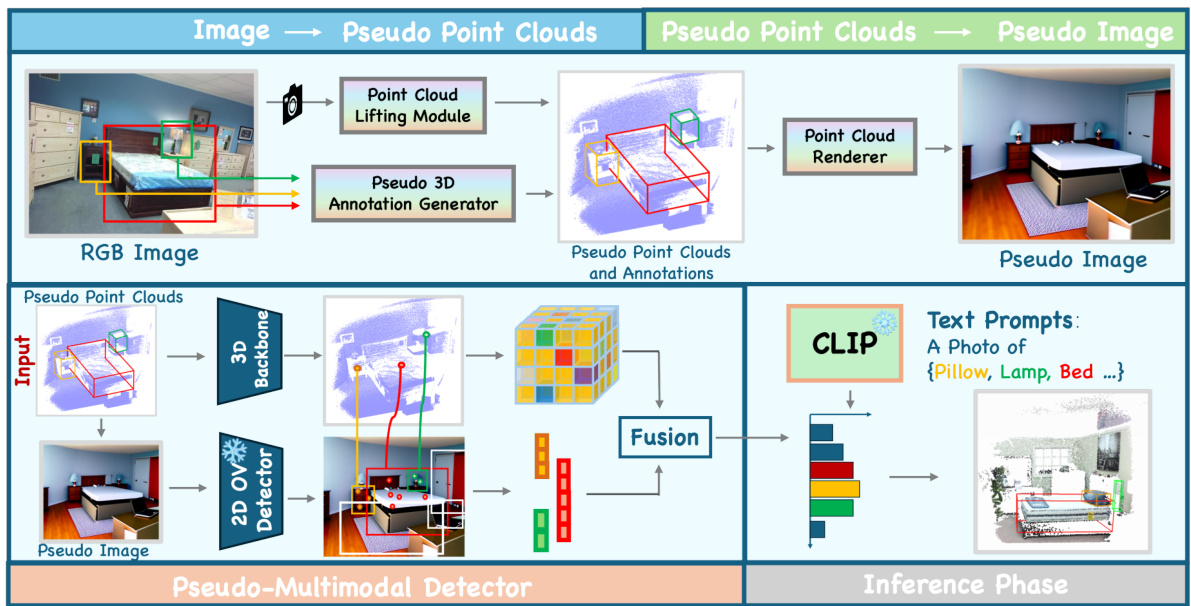
This figure illustrates the overall architecture of the ImOV3D model. It starts with 2D images as input, which are used in two parallel paths. The first path uses a Point Cloud Lifting Module and a Pseudo 3D Annotation Generator to create pseudo 3D point clouds and annotations. The second path uses a Point Cloud Renderer to generate pseudo images from these pseudo point clouds. Both pseudo 3D data and pseudo images are then fed into a Pseudo-Multimodal Detector, which uses a 3D backbone and a 2D open vocabulary detector, along with CLIP for text prompts. The inference phase uses point clouds as input and a pseudo-multimodal representation to generate detections.
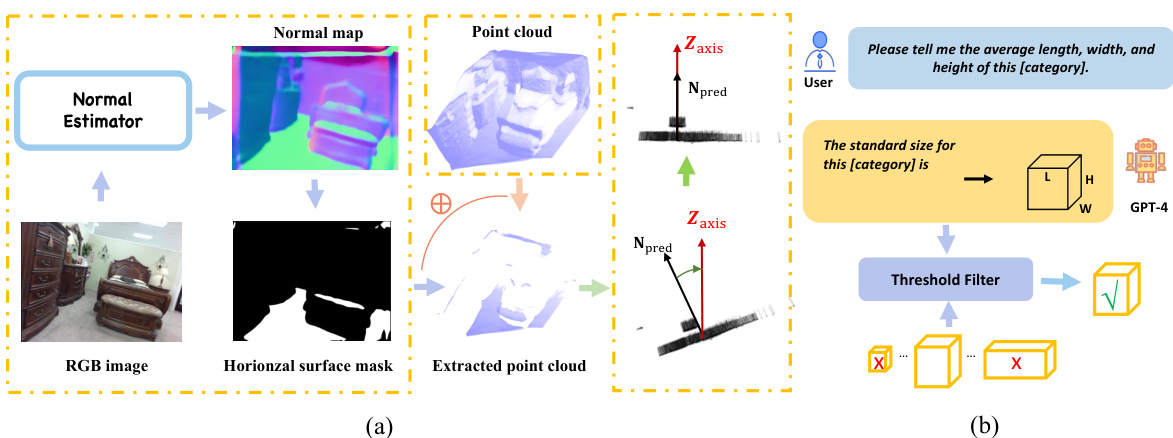
This figure illustrates the 3D data revision module, which consists of two parts: rotation correction and 3D box filtering. The rotation correction part uses a normal estimator to generate a normal map from an RGB image to identify horizontal point clouds, aligns the normal vector with the Z-axis to calculate the rotation matrix R. The 3D box filtering part uses GPT-4 to determine the average size of each object category and filters out boxes that do not meet the threshold criteria.

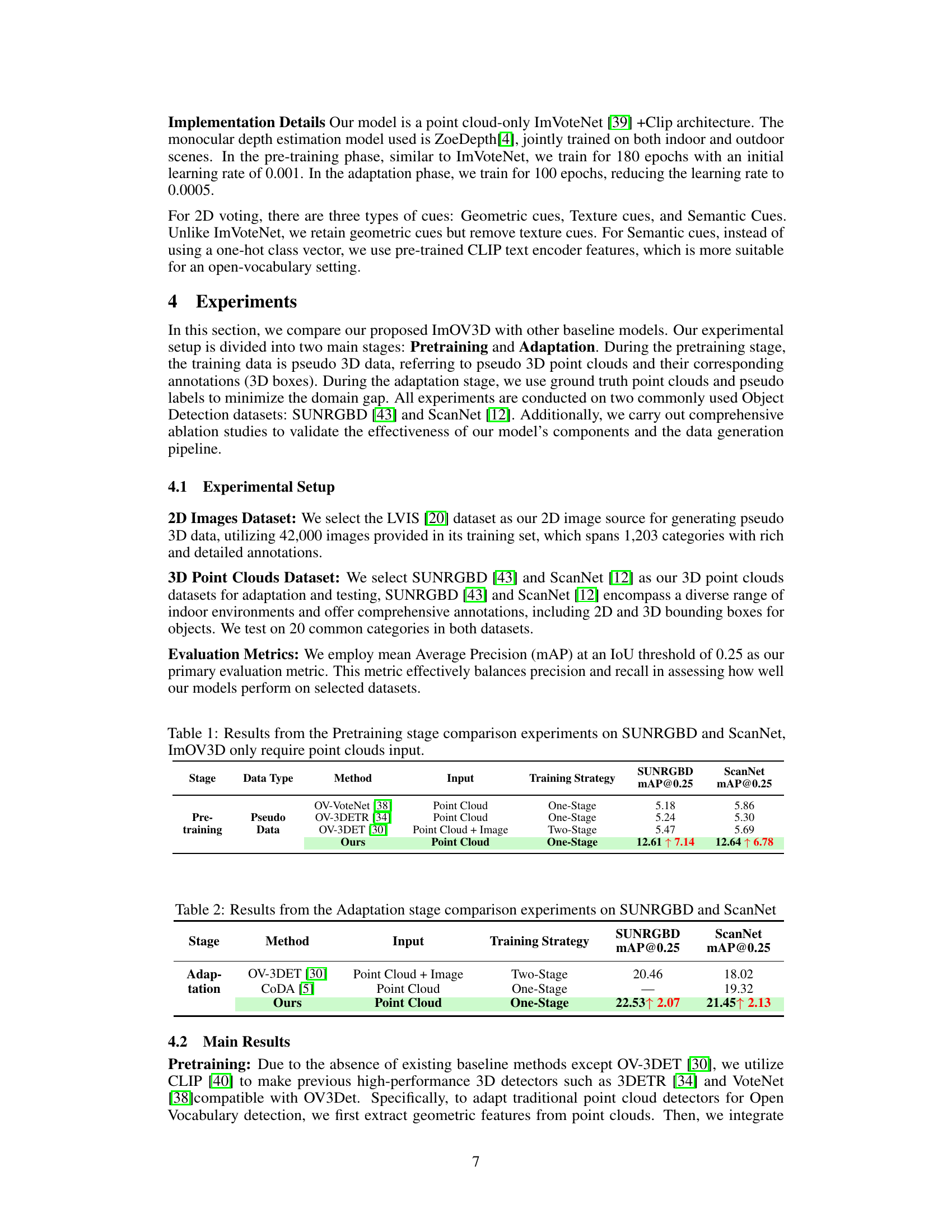
This figure shows qualitative results of the proposed method. It presents three types of images for two different scenes: 2D RGB images, depth maps obtained from point clouds, and pseudo images generated from point clouds. The pseudo images are processed by a 2D open vocabulary detector to generate bounding boxes around the detected objects. This visualization helps demonstrate how the method leverages 2D information (images) to improve 3D object detection in the case of limited 3D data.
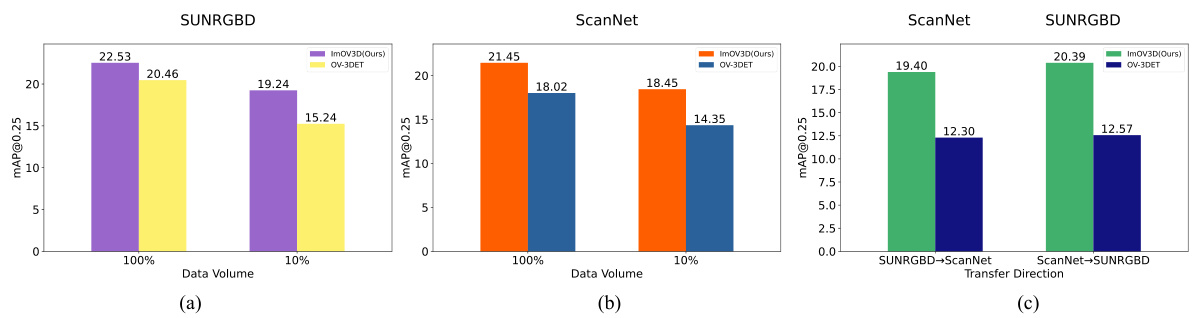
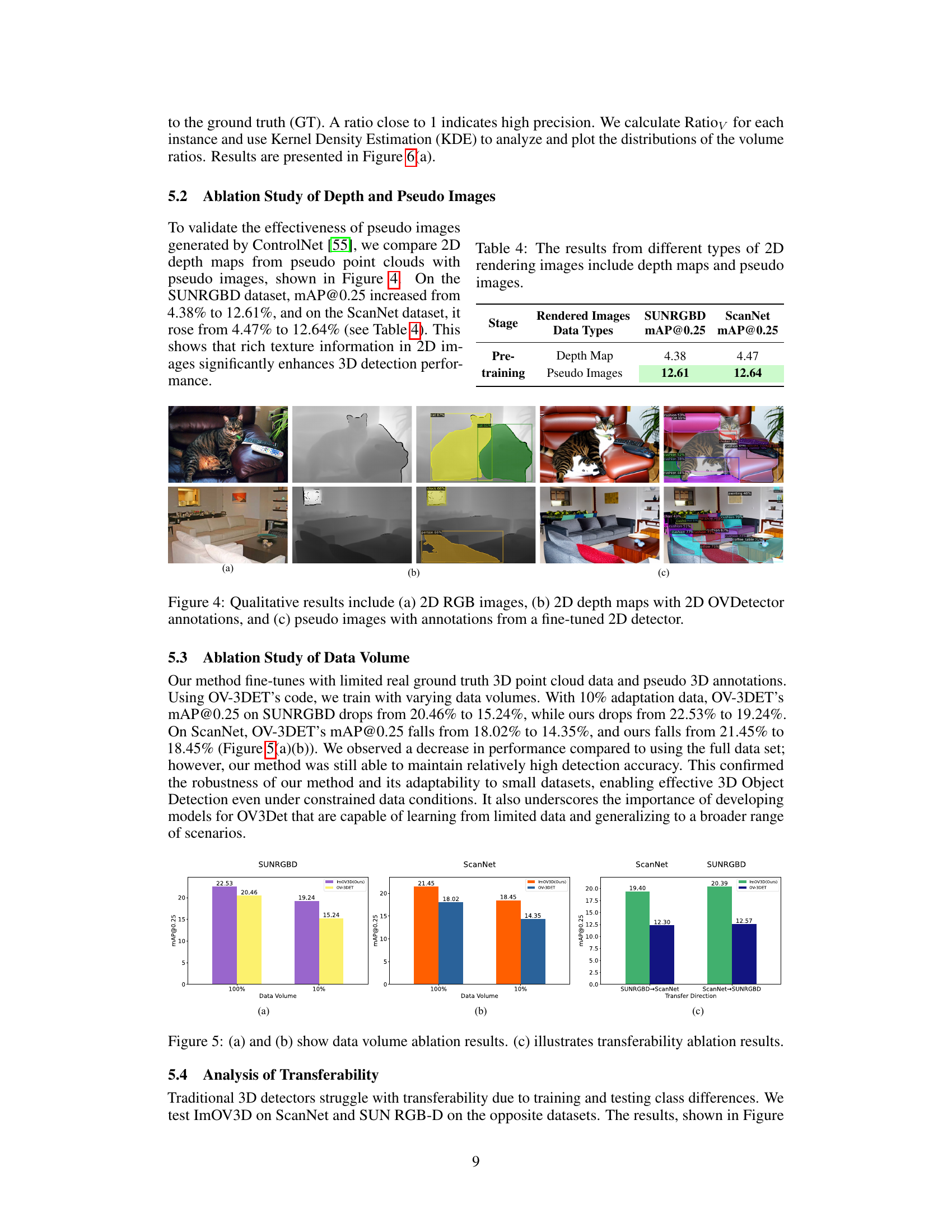
This figure shows the ablation study on the data volume and transferability of the proposed ImOV3D model. Subfigures (a) and (b) demonstrate the impact of reducing the amount of real 3D training data (from 100% to 10%) on the model’s performance (measured by mAP@0.25) on SUNRGBD and ScanNet datasets, respectively. Subfigure (c) shows the transferability of the model, testing its performance when training on one dataset and testing on the other. The results highlight the robustness of ImOV3D even with limited 3D data and its strong transferability across datasets.
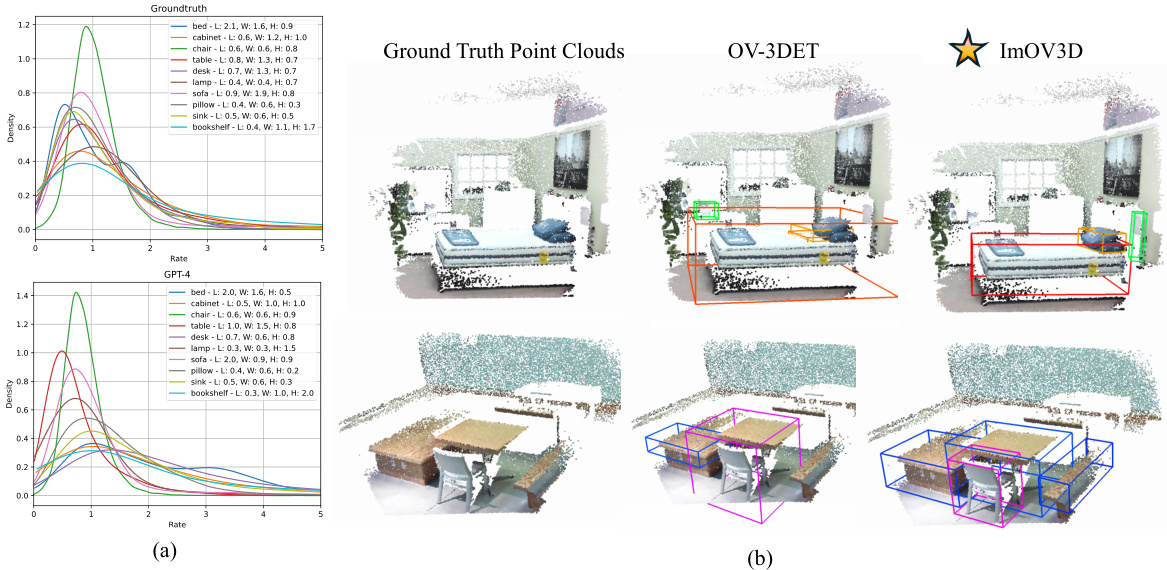
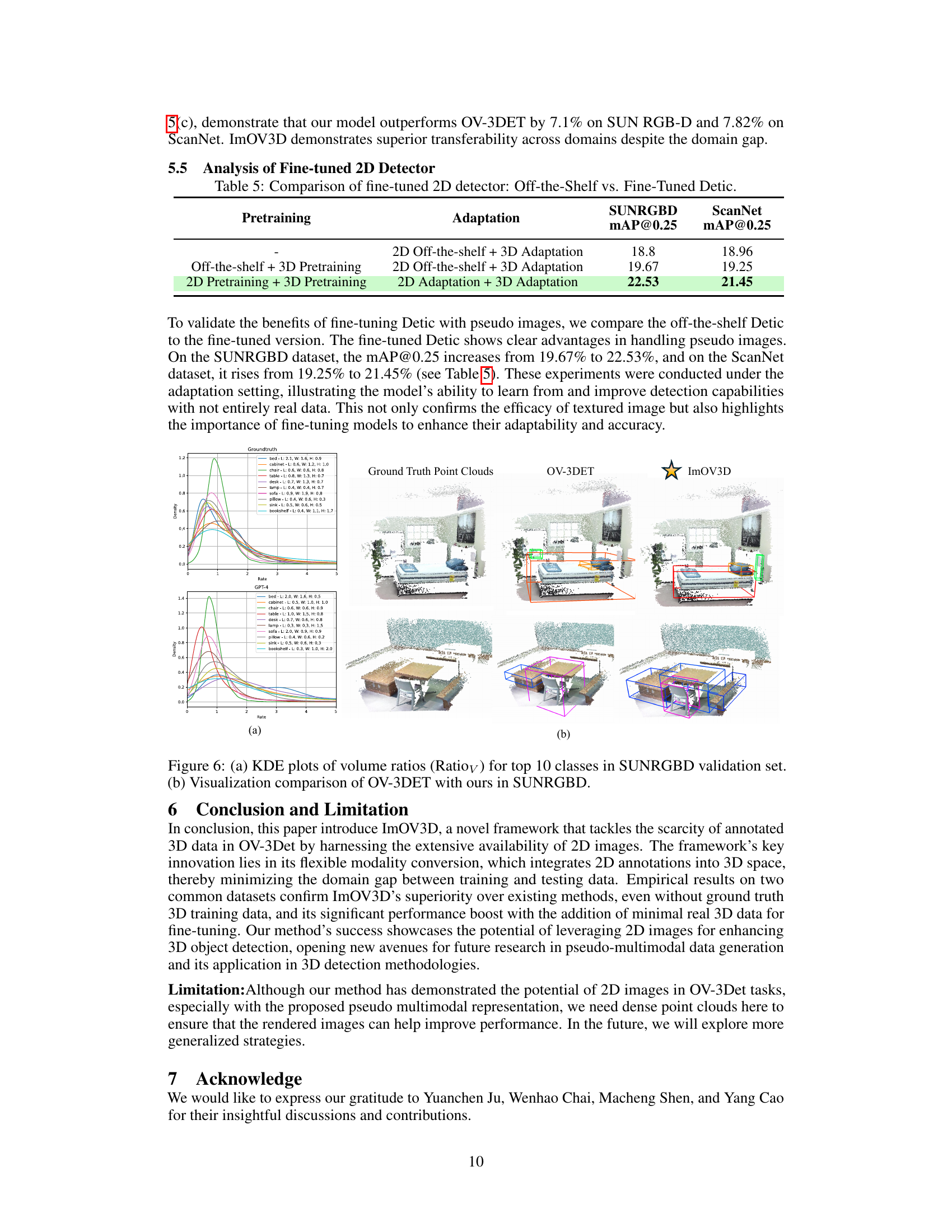
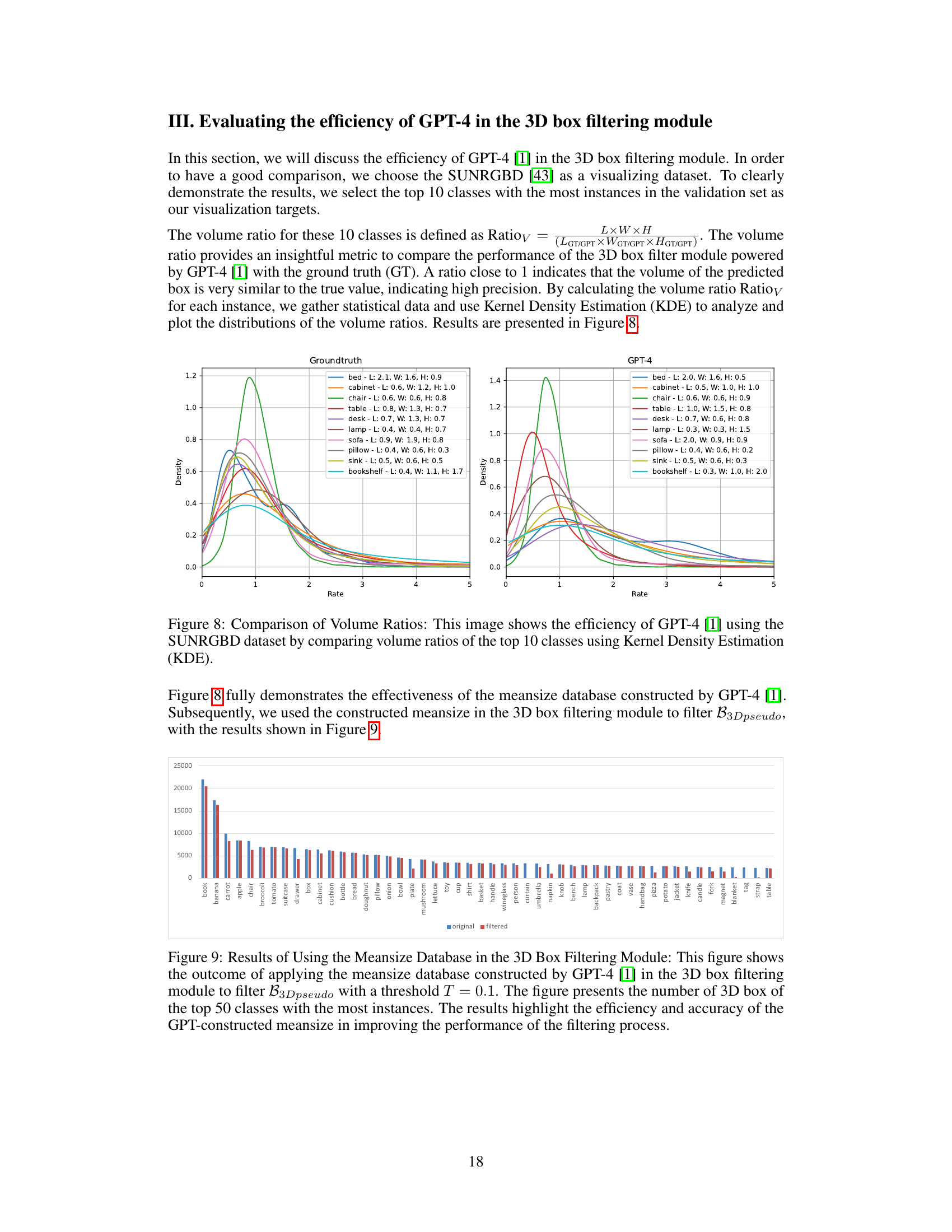
Figure 6(a) shows kernel density estimation (KDE) plots illustrating the distribution of volume ratios for the top 10 classes in the SUNRGBD validation set. The volume ratio quantifies the precision of 3D bounding box size predictions by comparing predicted volumes to ground truth volumes. Figure 6(b) provides a visual comparison of the object detection results of OV-3DET and ImOV3D on the SUNRGBD dataset. It highlights the improved accuracy of ImOV3D’s 3D bounding box predictions.

This figure shows the results of the partial-view removal process. (A) displays the depth images generated using a monocular depth estimation model. (B) presents the rendered point cloud images obtained after removing overlapping points visible from multiple viewpoints. This step enhances the robustness of the model by simulating occlusions, improving performance across various scenarios. (C) shows the ground truth 2D images corresponding to the point cloud data, enriching the 3D data by providing additional texture information.
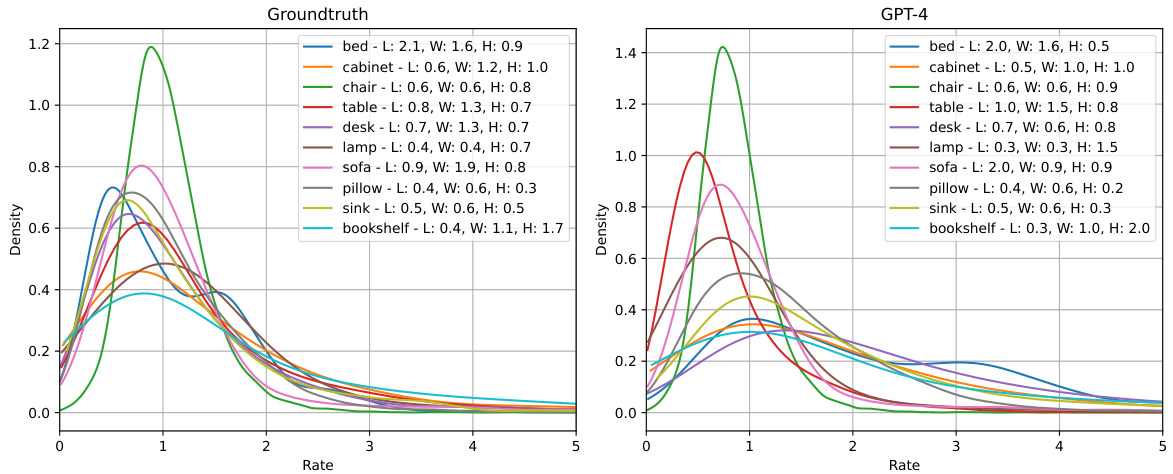
Figure 6(a) shows the Kernel Density Estimation (KDE) plots of volume ratios for the top 10 classes in the SUNRGBD validation set. The volume ratio, Ratioy, indicates how well the predicted 3D bounding box volume matches the ground truth volume. A value close to 1 suggests high accuracy. Figure 6(b) provides a visual comparison of the 3D object detection results between OV-3DET and the proposed ImOV3D method on the SUNRGBD dataset. This visual comparison highlights the improved detection performance achieved by ImOV3D.
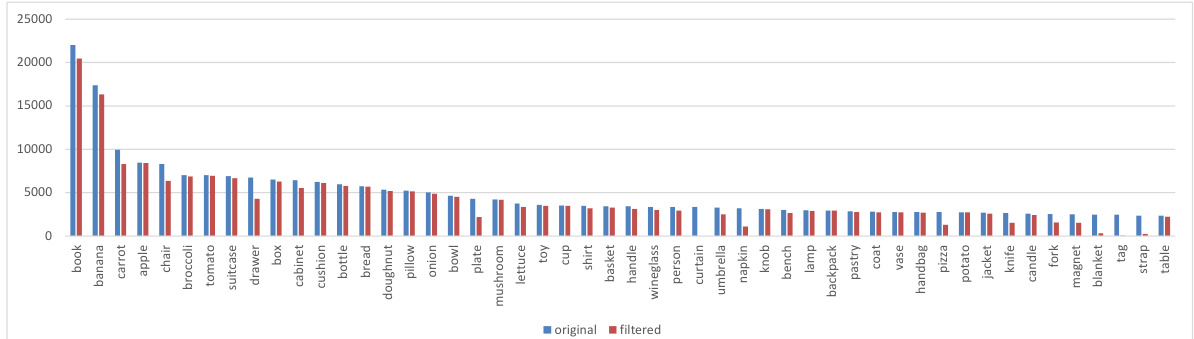
This figure displays the results of using a mean size database (generated by GPT-4) within a 3D box filtering module. It shows the number of 3D boxes (before and after filtering) for the top 50 most frequent object classes in a dataset. The comparison highlights the effectiveness of using the GPT-4 generated mean sizes in improving the accuracy of the 3D bounding box filtering process.
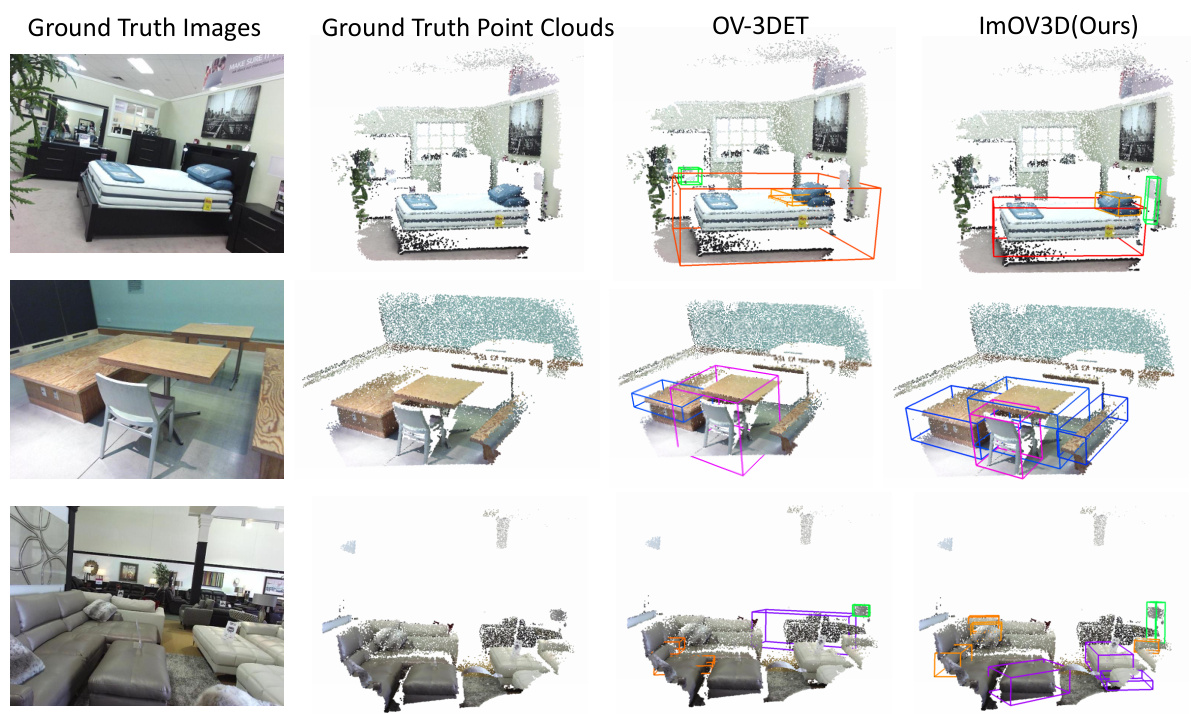
This figure compares the results of object detection between ImOV3D and OV-3DET on the SUNRGBD dataset. It shows four columns for each scene: ground truth images, ground truth point clouds, OV-3DET detections, and ImOV3D detections. The visualization highlights the differences in the quality and accuracy of object detection between the two methods during the pre-training phase, where only pseudo-3D data is used to train ImOV3D.
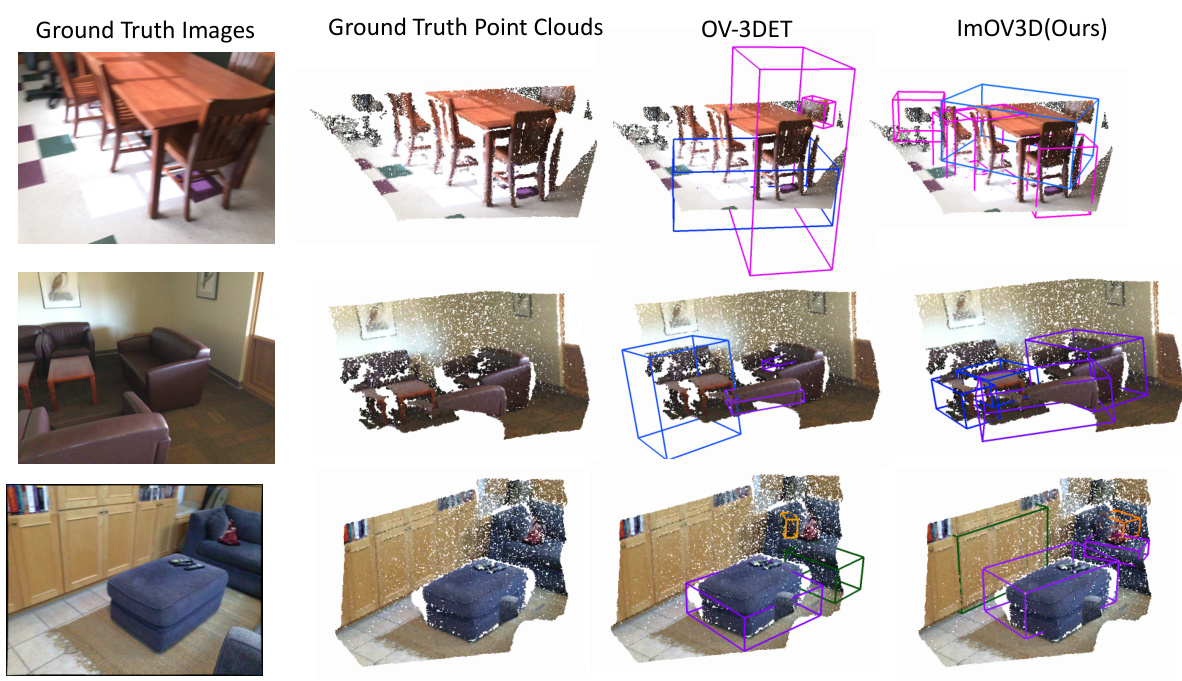
This figure compares the performance of ImOV3D and OV-3DET during the pretraining stage on the SUNRGBD dataset. It shows ground truth images and point clouds alongside the 3D bounding boxes generated by each method. This allows for a visual comparison of the accuracy of object detection.
More on tables

This table presents the results of the adaptation stage experiments conducted on two benchmark datasets: SUNRGBD and ScanNet. The adaptation stage uses real 3D point cloud data to improve performance, focusing on the comparison of ImOV3D’s performance against existing methods such as OV-3DET and CODA. The table compares models’ performance using the mean Average Precision (mAP) at an IoU threshold of 0.25, highlighting the improvement achieved by ImOV3D in both datasets.

This table presents the ablation study results on the Rotation Correction Module and the 3D Box Filtering Module. The study was performed on SUNRGBD and ScanNet datasets. The 3D Box Filtering module consists of two components: Train Phase Prior Size Filtering and Inference Phase Semantic Size Filtering. The table shows the mAP@0.25 scores for different combinations of modules (enabled or disabled) during pre-training. It demonstrates the impact of each module on improving the overall performance.

This table presents the performance comparison between using depth maps and pseudo images as input for 2D rendering during the pretraining stage. It shows a significant improvement in mean Average Precision (mAP@0.25) when using pseudo images compared to depth maps on both SUNRGBD and ScanNet datasets. This highlights the value of incorporating rich texture information from pseudo images generated by ControlNet for enhanced 3D object detection performance.

This table presents the comparison results of using off-the-shelf and fine-tuned Detic models during the adaptation stage of the ImOV3D experiments. The results are shown separately for SUNRGBD and ScanNet datasets, evaluating the mAP@0.25 metric for each condition (off-the-shelf with 3D pretraining and adaptation, off-the-shelf with 3D adaptation, and fine-tuned 2D model with 3D adaptation). This comparison highlights the impact of fine-tuning the Detic model with pseudo images generated by the ImOV3D framework before adaptation, demonstrating its effectiveness in improving the overall performance of the 3D object detection task.
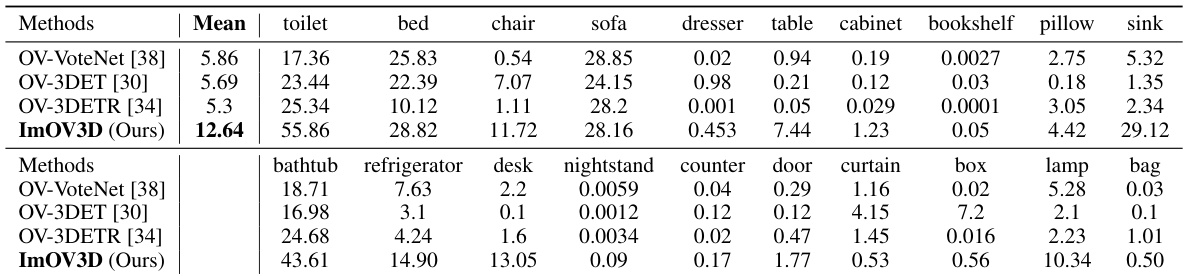
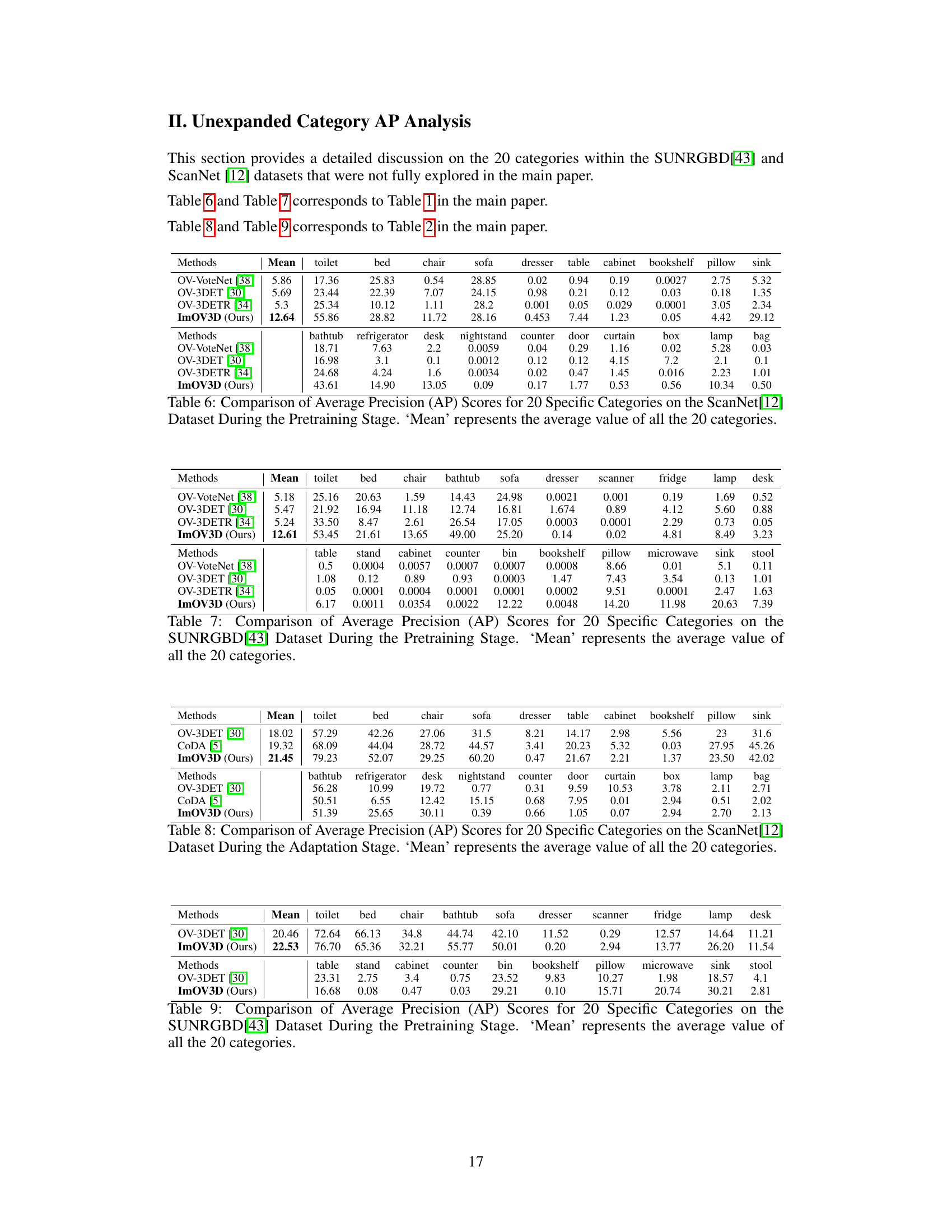
This table presents the results of pretraining stage comparison experiments conducted on two benchmark datasets, SUNRGBD and ScanNet. The comparison focuses on the mean Average Precision (mAP) at an Intersection over Union (IoU) threshold of 0.25. The table highlights that the proposed ImOV3D method, which only requires point cloud input, significantly outperforms existing methods (OV-VoteNet [38], OV-3DETR [34], OV-3DET [30]) in both datasets. This demonstrates the effectiveness of ImOV3D’s training strategy using solely pseudo-multimodal representations derived from 2D images.
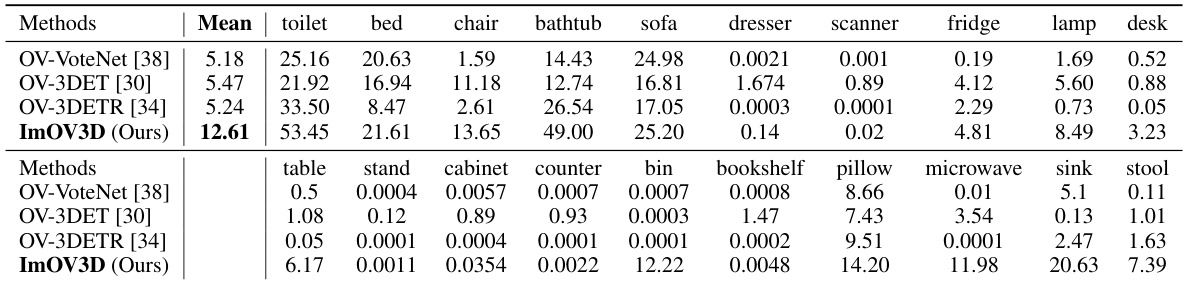
This table presents the results of the pretraining stage of the ImOV3D model, which is trained using only pseudo point clouds generated from 2D images. It compares ImOV3D’s performance on two benchmark datasets, SUNRGBD and ScanNet, against three other methods (OV-VoteNet, OV-3DETR, OV-3DET). The table shows the mean Average Precision (mAP@0.25) achieved by each method, highlighting ImOV3D’s significant improvement over existing methods in this data-scarce setting.

This table presents the results of the adaptation stage of the ImOV3D experiments, comparing its performance against other methods (OV-3DET [30] and CODA [5]) on the SUNRGBD and ScanNet datasets. It shows the mean Average Precision (mAP@0.25) achieved by each method using different input data (Point Cloud + Image or Point Cloud only) and training strategies (Two-Stage or One-Stage). The results demonstrate ImOV3D’s superior performance, even with only point cloud input, in the adaptation stage.

This table presents the results of the adaptation stage experiments performed on the SUNRGBD and ScanNet datasets. It compares the performance of the proposed ImOV3D method against existing methods (OV-3DET [30] and CoDA [5]) when a small amount of real 3D data is used for fine-tuning. The table shows the mean Average Precision (mAP@0.25) achieved by each method on both datasets, indicating their ability to improve detection performance using real-world 3D data.
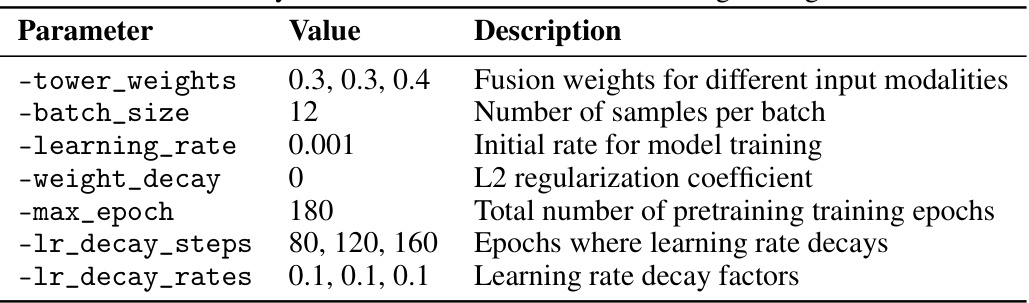
This table presents the hyperparameters used during the pretraining phase of the ImOV3D model. It includes parameters related to the fusion of different input modalities (-tower_weights), batch size (-batch_size), initial and decaying learning rates (-learning_rate, -lr_decay_steps, -lr_decay_rates), L2 regularization (-weight_decay), and the total number of training epochs (-max_epoch). These settings are crucial for the model’s performance during the initial training phase using pseudo-multimodal data.
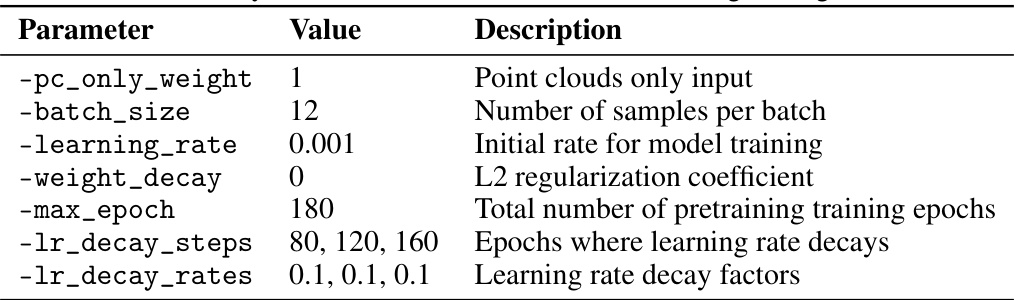
This table lists the hyperparameters used during the pretraining phase for the OV-VoteNet model. It details the settings for various aspects of the training process, such as the type of input data (point clouds only), batch size, learning rate, weight decay (L2 regularization), total number of training epochs, and the epochs at which the learning rate is adjusted (decay steps) along with the decay factors.
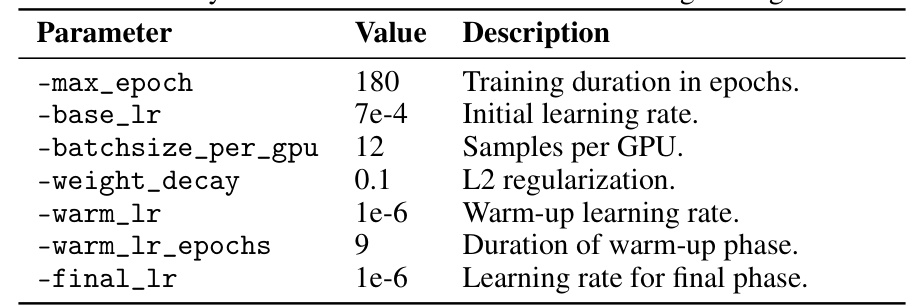
This table lists the hyperparameters used for training the OV-3DETR model during the pretraining phase. It includes the maximum number of epochs, the initial and final learning rates, batch size per GPU, weight decay, warm-up learning rate, and warm-up epoch duration. These parameters are crucial in controlling the training process and achieving optimal model performance.

This table presents the key hyperparameters used during the pretraining phase of the OV-3DET model. It shows the settings for two distinct phases: the local phase and the DTCC phase. The parameters include the maximum number of training epochs, the number of queries, the base learning rate, warm-up epochs for the learning rate, the batch size per GPU, and the final learning rate.
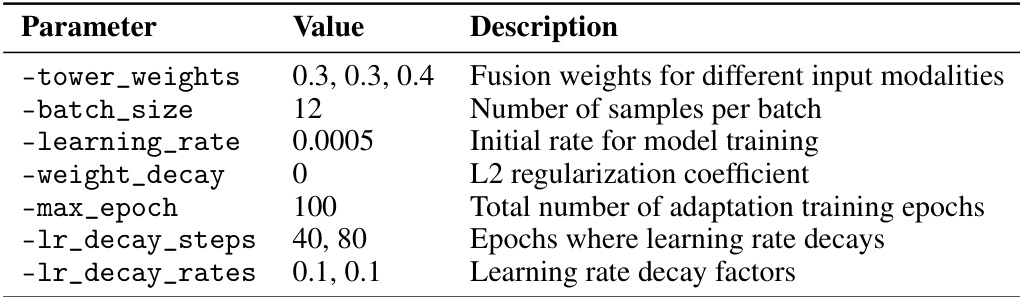
This table presents the key hyperparameters used during the adaptation stage of the ImOV3D model training. It specifies values for parameters controlling the fusion of different input modalities, batch size, initial learning rate, L2 regularization, the total number of training epochs, and the learning rate decay schedule.
Full paper#