↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual imitation learning (CIL) faces challenges in data efficiency, adaptation to non-stationary environments, and privacy. Existing adapter-based methods struggle with knowledge sharing across tasks. Catastrophic forgetting and the need for comprehensive demonstrations hinder real-world applications.
IsCiL addresses these issues by using a prototype-based skill retrieval system. It incrementally learns reusable skills, mapping demonstrations into state embeddings. A skill retriever retrieves relevant skills based on input states, and these skills are learned on corresponding adapters. IsCiL’s experimental results on complex tasks demonstrate strong performance in both task adaptation and sample efficiency, showcasing its practicality and potential for various applications, even extending to task unlearning.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in continual imitation learning, offering a novel approach to efficient continual task adaptation. It directly addresses the challenges of data inefficiency, non-stationarity, and privacy concerns, paving the way for more robust and adaptable AI agents, particularly in home robotics. The sample efficiency improvements and introduction of task unlearning are significant contributions with implications for various applications. The framework’s focus on incremental learning and skill retrieval opens new avenues for research on parameter-efficient continual learning and generalization in dynamic environments.
Visual Insights#
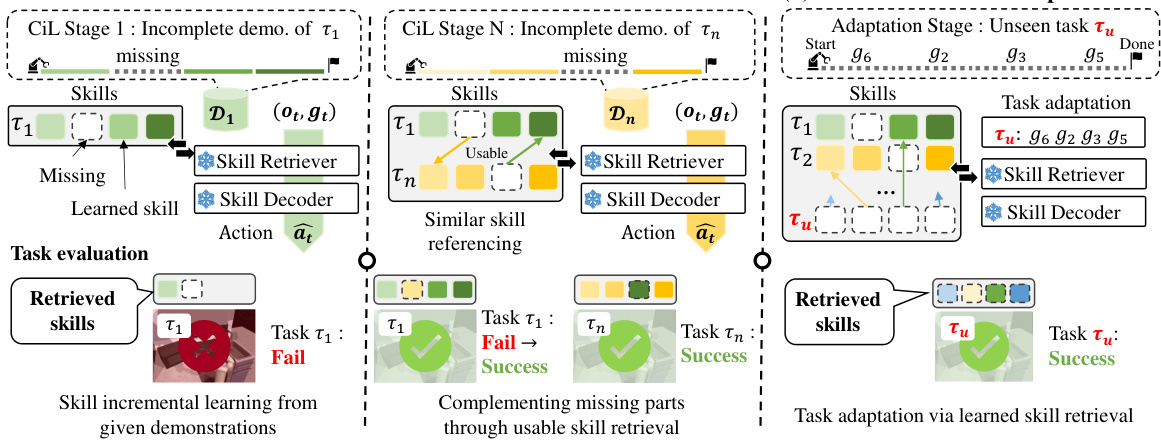
This figure illustrates the IsCiL framework’s two main components: prototype-based skill incremental learning and task-wise selective adaptation. The left panel shows how IsCiL incrementally learns skills from incomplete demonstrations across multiple stages, even recovering from initial failures by retrieving relevant skills from other tasks later. The right panel demonstrates how IsCiL efficiently adapts to a completely new unseen task (τu) by selectively retrieving and utilizing previously learned skills.
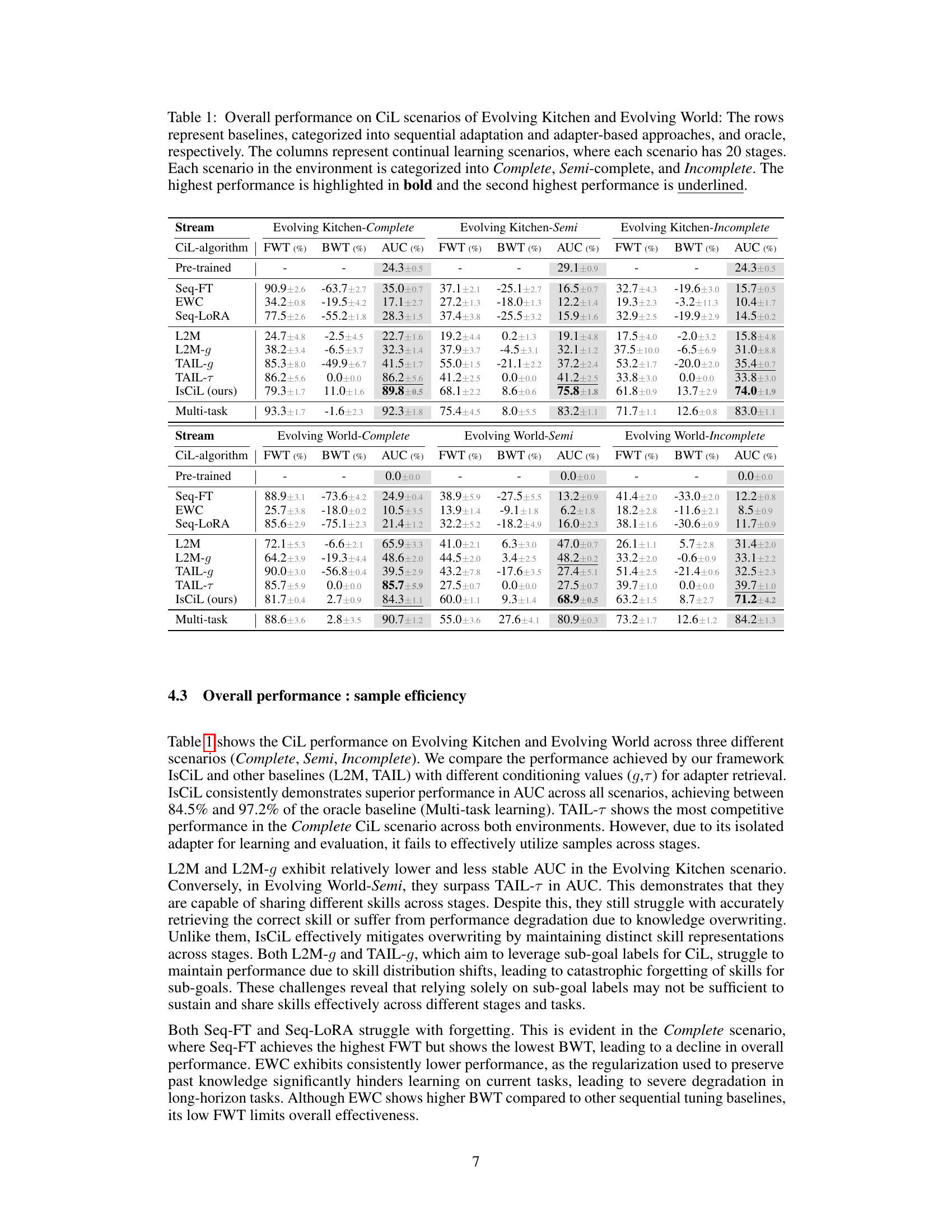
This table presents a quantitative comparison of different continual imitation learning (CIL) methods on two complex tasks: Evolving Kitchen and Evolving World. The results are broken down by three scenarios (Complete, Semi-complete, and Incomplete) that vary the amount and completeness of the training data. The table shows the Forward Transfer (FWT), Backward Transfer (BWT), and Area Under Curve (AUC) for each method across all scenarios, providing a comprehensive view of their performance in terms of adapting to new tasks and retaining previously learned knowledge.
In-depth insights#
IsCiL Framework#
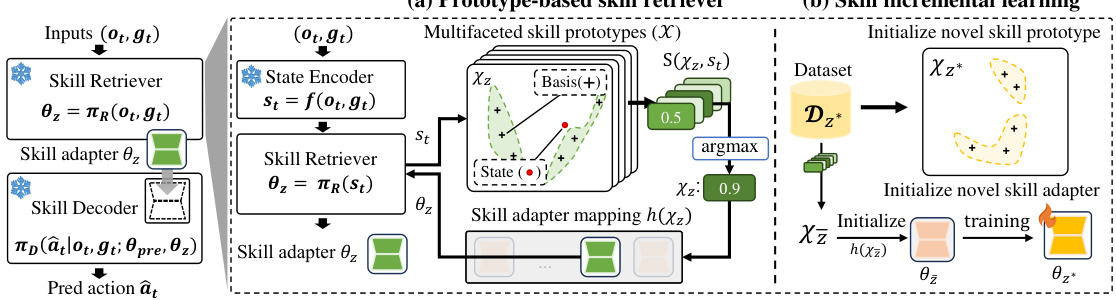
The IsCiL framework introduces a novel approach to continual imitation learning (CIL) by incrementally learning shareable skills from diverse demonstrations. This contrasts with existing adapter-based methods which often limit knowledge sharing across tasks. IsCiL’s core innovation lies in its prototype-based skill retrieval mechanism. Demonstrations are mapped into a state embedding space where skills, represented by prototypes, are retrieved based on input states. These retrieved skills then inform a skill decoder, enabling effective, sample-efficient task adaptation, especially in non-stationary environments. The framework also demonstrates a simple, effective extension to handle task unlearning, a significant advantage for privacy-sensitive applications. Parameter-efficient adapters ensure that learning new skills doesn’t lead to catastrophic forgetting of prior knowledge. Through a two-level architecture (skill retriever and skill decoder) IsCiL elegantly balances skill sharing with task-specific adaptation, thereby addressing several key challenges inherent in CIL.
Skill Prototype#
The concept of “Skill Prototype” in the context of continual imitation learning is crucial for efficient task adaptation. It represents a compact, generalized representation of a skill, learned from various demonstrations. Instead of storing entire demonstrations, skill prototypes act as memory placeholders, each encapsulating the core essence of a specific skill enabling retrieval based on the current state. This approach offers significant advantages. It enhances sample efficiency by reducing the need for extensive demonstrations for each new task. Furthermore, using a prototype-based approach improves the scalability and adaptability of the model in dynamic environments, by facilitating rapid adaptation using previously learned skills. The system’s efficiency is further enhanced through the employment of parameter-efficient adapters, individually associated with each prototype. This selective adaptation strategy effectively addresses the problem of catastrophic forgetting commonly encountered in continual learning scenarios. Overall, skill prototypes constitute a core component enabling efficient skill learning, retrieval, and adaptation in continual imitation learning.
Sample Efficiency#
Sample efficiency, a crucial aspect of continual imitation learning (CIL), is thoroughly investigated in this research. The core idea revolves around minimizing the amount of data required to effectively adapt to new tasks. The study demonstrates that IsCiL, the proposed framework, significantly enhances sample efficiency compared to existing methods. This improvement stems from IsCiL’s capacity to incrementally learn and retrieve shareable skills across various tasks and stages. The use of prototype-based memory for skill retrieval allows IsCiL to effectively leverage past experiences, even when dealing with incomplete or non-stationary data streams. This ability to efficiently utilize available knowledge contributes to reduced data requirements and faster task adaptation, making IsCiL a promising approach for real-world CIL applications. The experimental results, presented across diverse and challenging environments, clearly support this claim of improved sample efficiency, highlighting the practicality and effectiveness of the IsCiL methodology.
Task Adaptation#
The research paper section on “Task Adaptation” likely details the model’s ability to handle novel tasks not seen during training. A key aspect would be the sample efficiency of this adaptation; how much new data is needed for successful performance. The method’s robustness across varied tasks and environments is crucial, demonstrating generalizability. The paper probably presents results quantifying adaptation speed, success rates, and potentially comparing the model’s performance against established baselines. A discussion of catastrophic forgetting, where learning new tasks hinders the performance on previously learned ones, and how the model addresses it would be vital. The explanation of the underlying mechanisms for the adaptation, perhaps using specialized adapters or incremental learning techniques, is key to understand the model’s efficiency and performance.
Future of IsCiL#
The future of IsCiL hinges on addressing its current limitations and exploring new avenues for improvement. Data efficiency remains a key challenge; future work could investigate techniques to further reduce the reliance on extensive demonstrations, perhaps through more effective skill representation or transfer learning from other domains. Non-stationarity is another area ripe for exploration. Improving the skill retriever’s robustness to unexpected shifts in task distributions and environmental changes would significantly enhance IsCiL’s adaptability. Privacy concerns can be mitigated by incorporating more sophisticated unlearning mechanisms that minimize the risk of unintended knowledge leakage or bias. Furthermore, scalability is crucial for real-world deployment; IsCiL’s architecture should be optimized to handle increasingly large numbers of skills and tasks more efficiently. Finally, generalization to new and unseen tasks needs further investigation. Exploring methods for effective knowledge transfer and leveraging pre-trained models to improve sample efficiency would be vital steps towards building a truly robust and versatile lifelong learning agent.
More visual insights#
More on figures
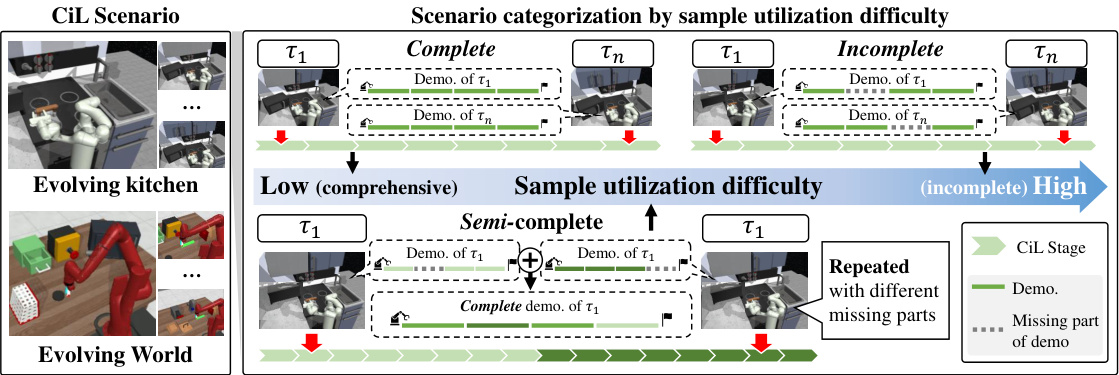
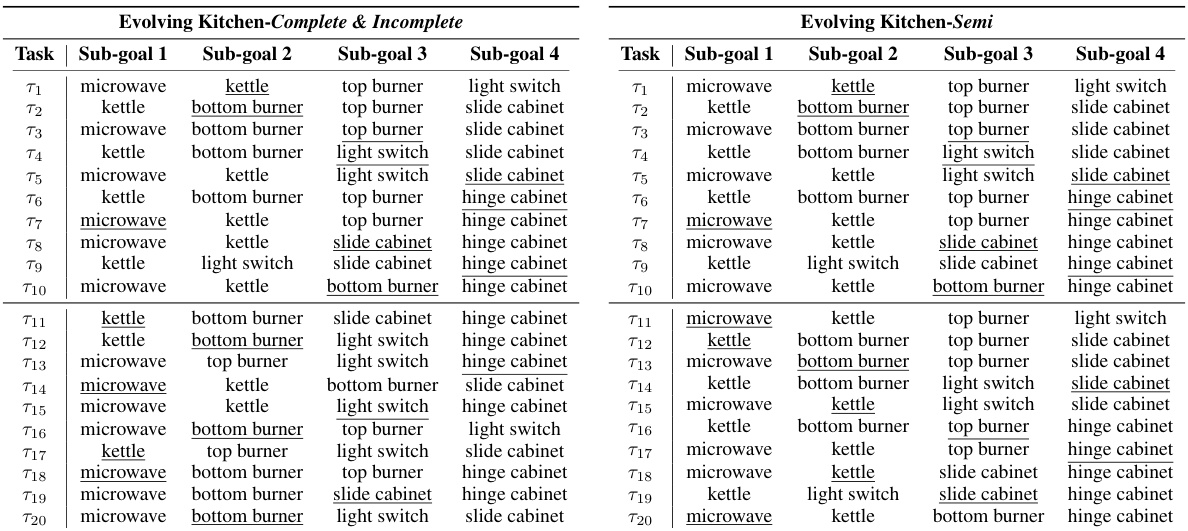
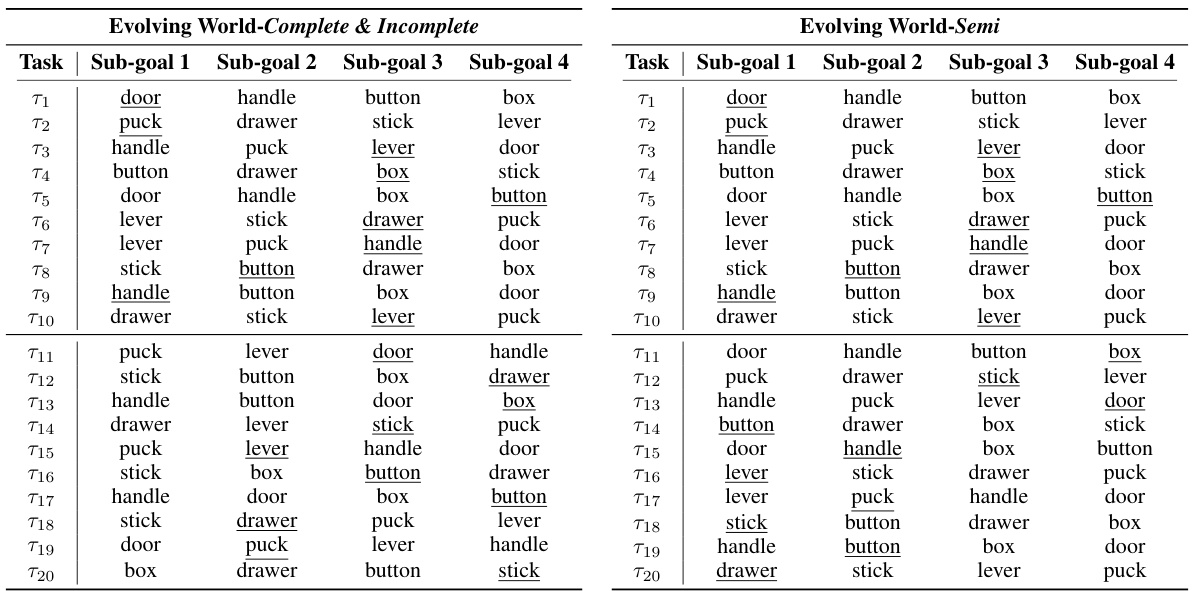
This figure illustrates three different scenarios for continual imitation learning (CiL): Complete, Semi-complete, and Incomplete. These scenarios differ in the completeness of the demonstrations provided for each task, ranging from complete demonstrations in the ‘Complete’ scenario to partially complete demonstrations in the ‘Semi-complete’ and ‘Incomplete’ scenarios. The ‘Incomplete’ scenario presents the most challenging condition, where significant parts of the demonstration are missing for many of the tasks. This difference in demonstration completeness is used to measure the impact of incomplete information on the algorithm’s sample efficiency and task adaptation performance.
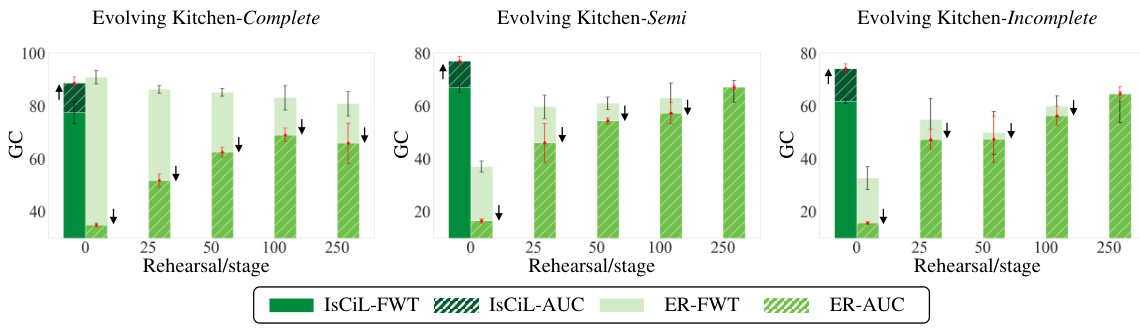
This figure compares the performance of IsCiL and an experience replay (ER) baseline across three different scenarios in the Evolving Kitchen environment. The x-axis shows the number of rehearsals per stage, while the y-axis shows the goal-conditioned success rate (GC). The results indicate that IsCiL consistently outperforms ER across all scenarios and rehearsal amounts, showcasing its sample efficiency. In the Complete scenario, IsCiL maintains high performance even without rehearsals, while ER shows a decline in performance as the number of rehearsals increases. In the Semi and Incomplete scenarios, the advantage of IsCiL is even more pronounced.
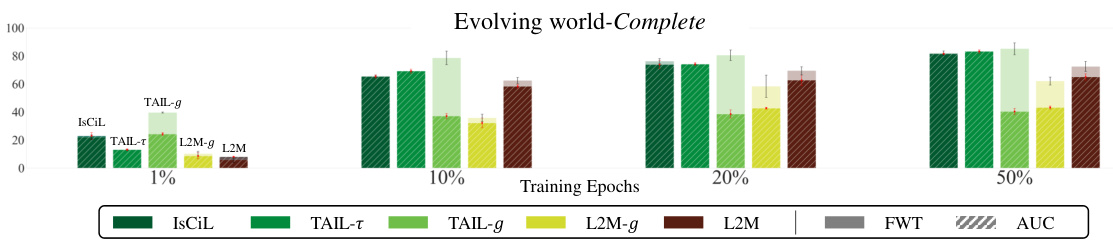
This figure compares the performance of IsCiL and several baselines across different training resource levels (1%, 10%, 20%, 50%). The performance metrics used are Forward Transfer (FWT) and Area Under the Curve (AUC), both measuring goal-conditioned success rates (GC). The results show the computational efficiency of IsCiL, maintaining robust performance even with limited training data.
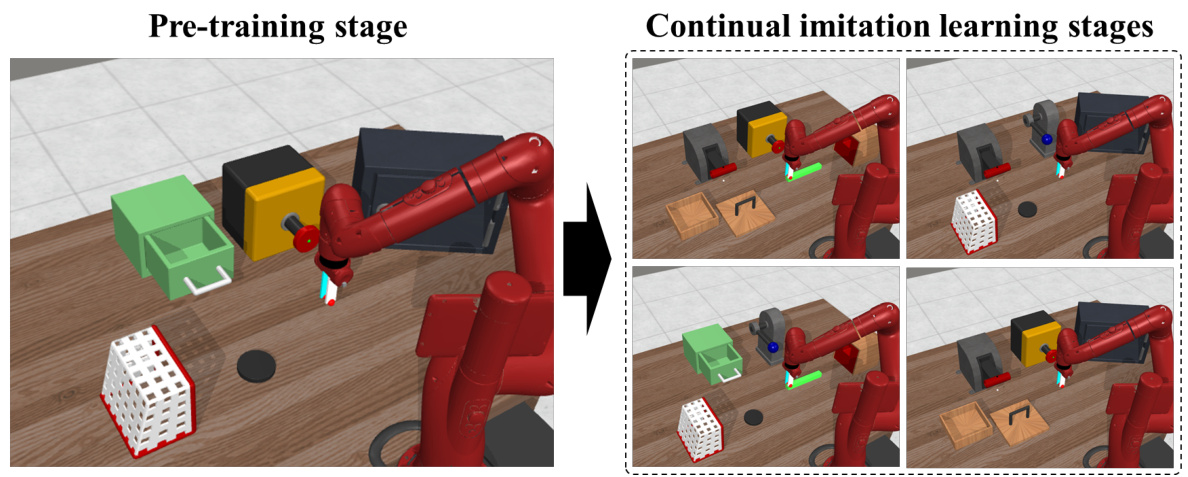
This figure shows a multi-stage Meta-World environment used in the continual imitation learning experiments. The left side depicts the pre-training stage, where the robot arm interacts with a simplified set of objects. The right side shows the continual imitation learning stages, where the environment complexity increases with the addition of new objects and tasks. This illustrates the non-stationary nature of the continual learning problem addressed in the paper.
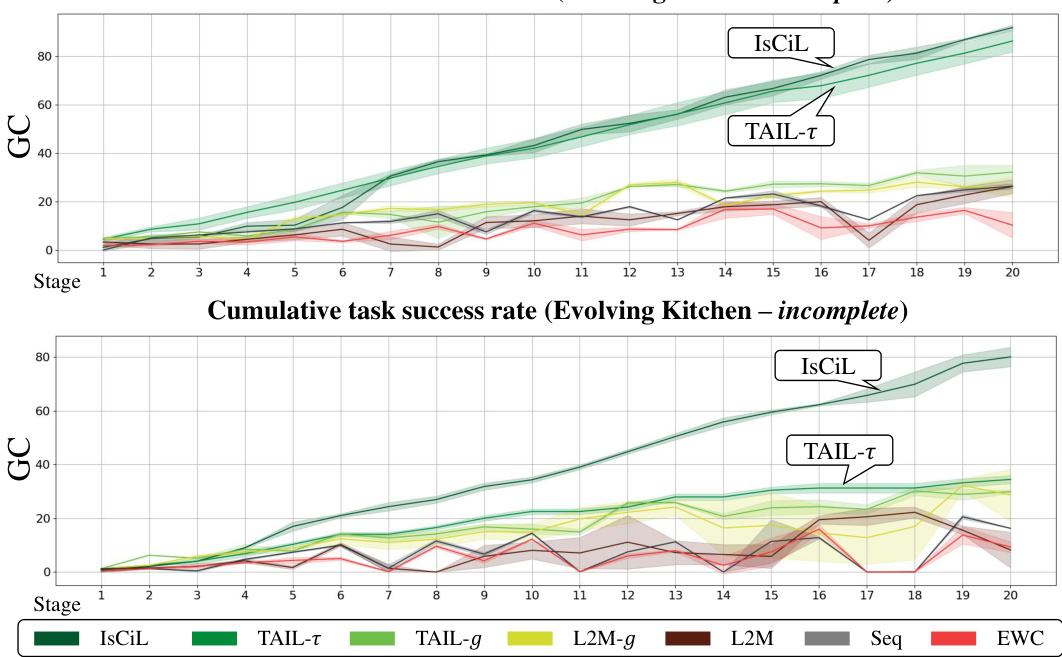
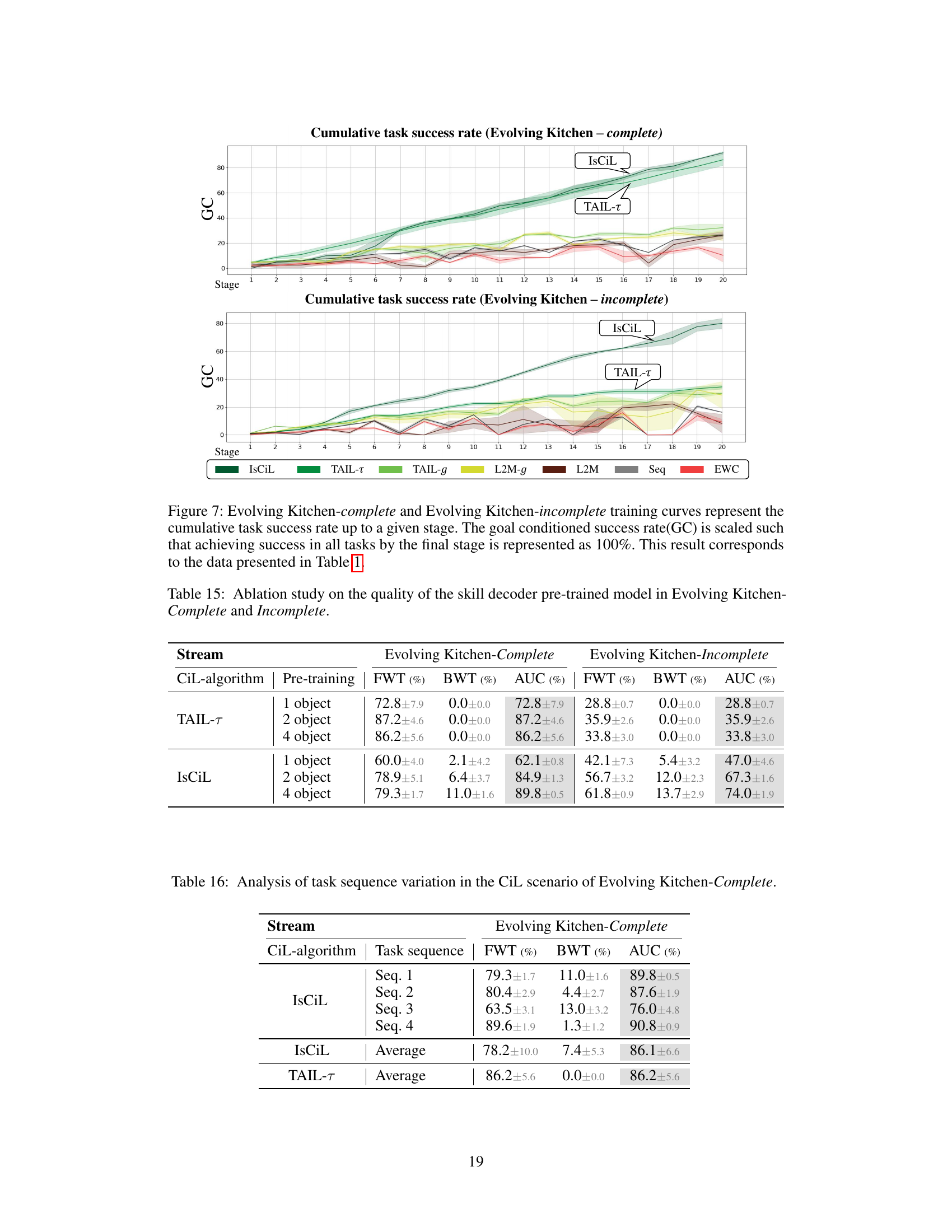
This figure shows the training curves for the ‘Evolving Kitchen-complete’ and ‘Evolving Kitchen-incomplete’ scenarios. The y-axis represents the cumulative task success rate (GC), scaled to 100% for complete success in all tasks at the final stage. The x-axis shows the training stage. The curves illustrate how the task success rates change over the training stages for various continual learning methods (IsCiL, TAIL-τ, TAIL-g, L2M-g, L2M, Seq, EWC), allowing for comparison of their performance.
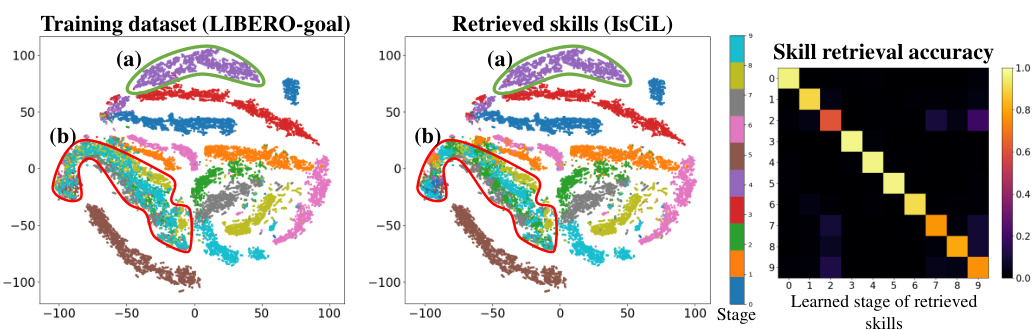
This figure visualizes the performance of the Skill Retriever component of the IsCiL framework. The left panel shows a t-SNE visualization of the state space for each stage of the LIBERO-goal dataset, highlighting the distribution of skills over time. The middle panel displays the skills retrieved by the Skill Retriever, demonstrating its ability to identify relevant skills across stages. Finally, the right panel shows a heatmap illustrating the accuracy of skill retrieval for different stages, revealing that the retriever successfully identifies and shares skills across various stages and tasks in the complex LIBERO environment.
More on tables
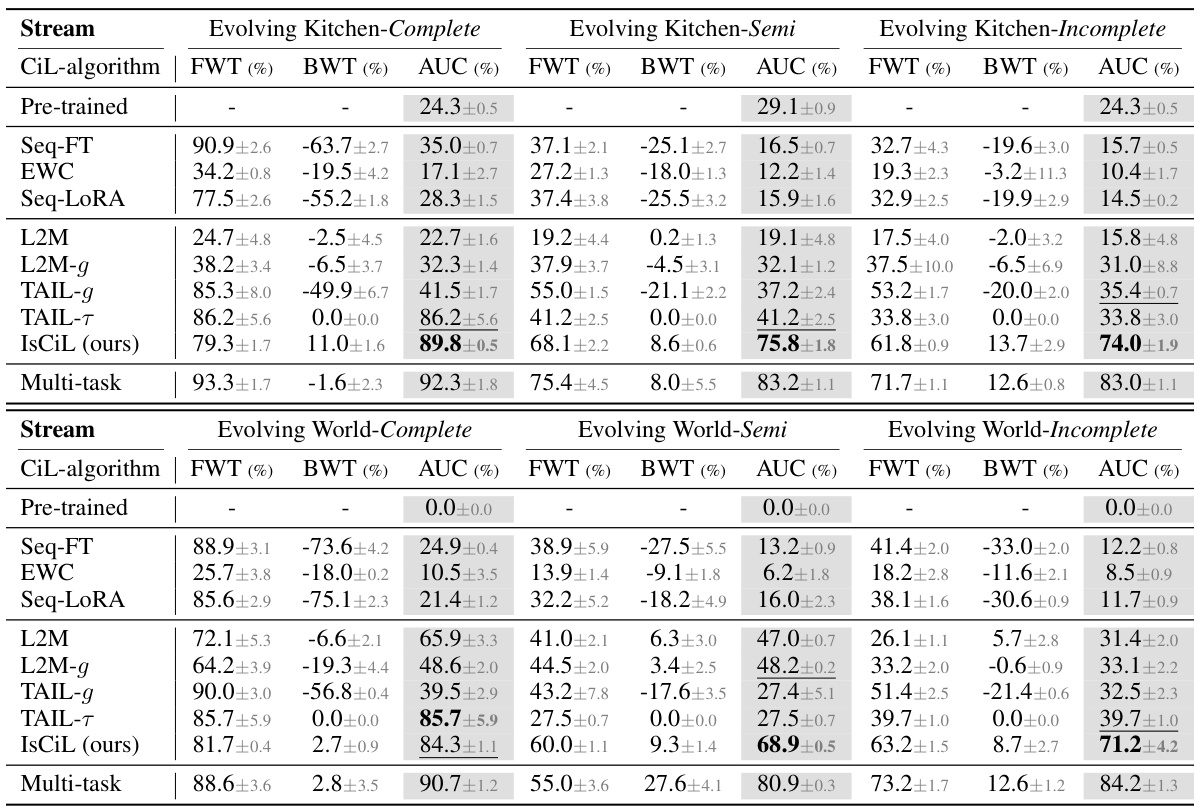
This table presents a comparison of different continual imitation learning (CIL) methods across three scenarios (Complete, Semi-complete, and Incomplete) in two environments (Evolving Kitchen and Evolving World). Each scenario consists of 20 stages with varying levels of data completeness. The table shows the forward transfer (FWT), backward transfer (BWT), and area under the curve (AUC) for each method and scenario. The highest and second highest performing methods are highlighted for easy comparison.
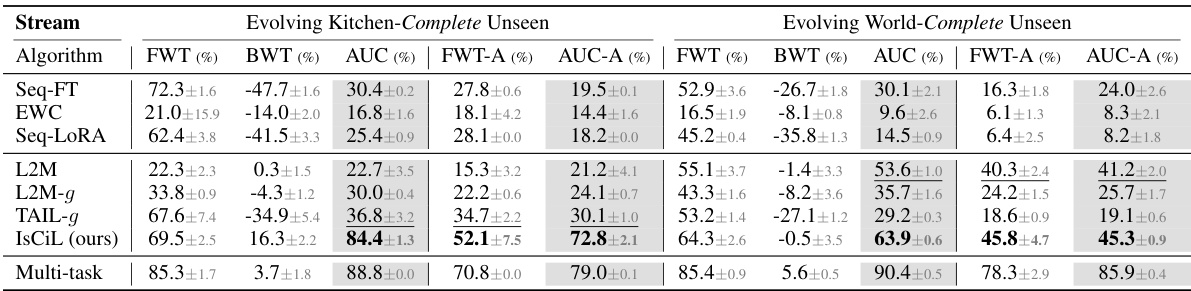
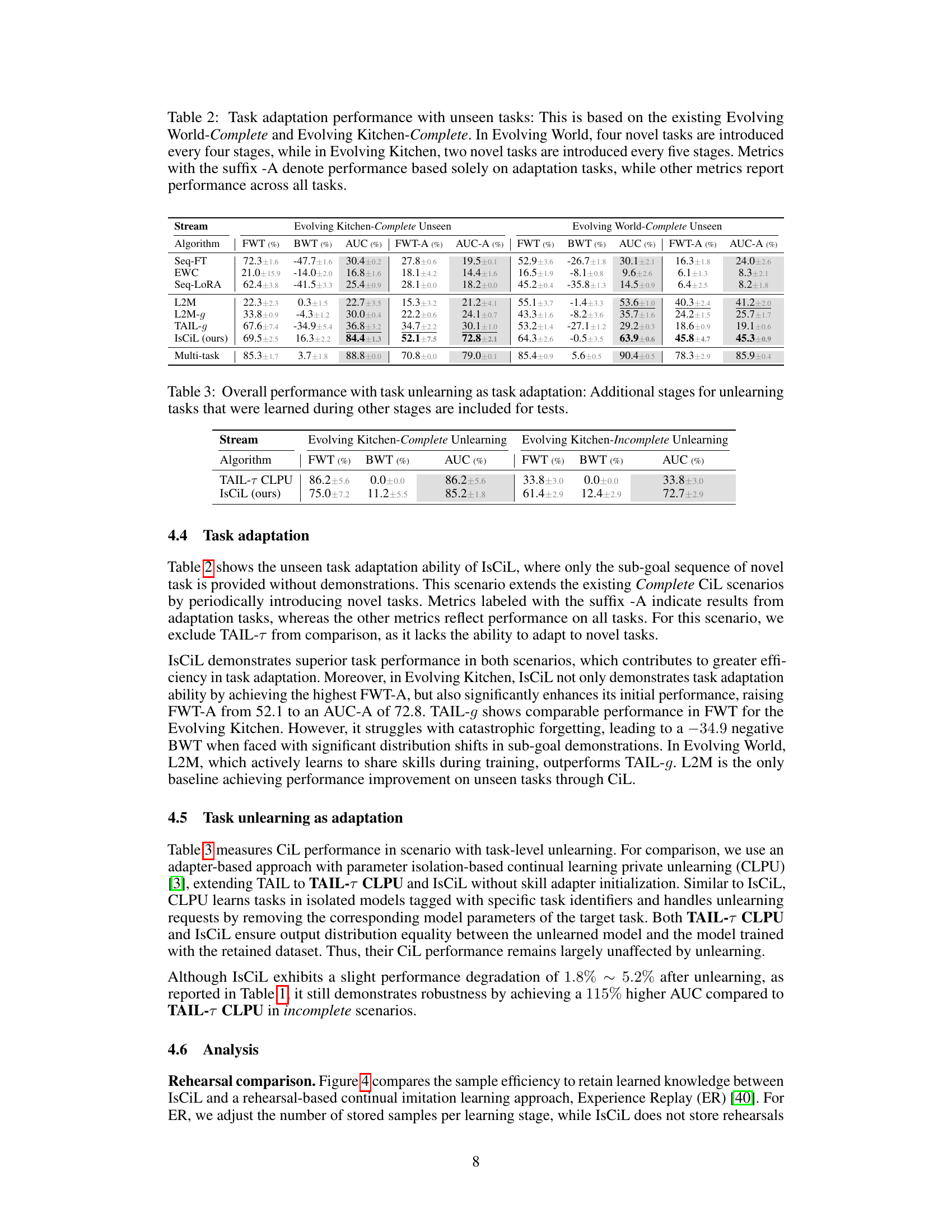
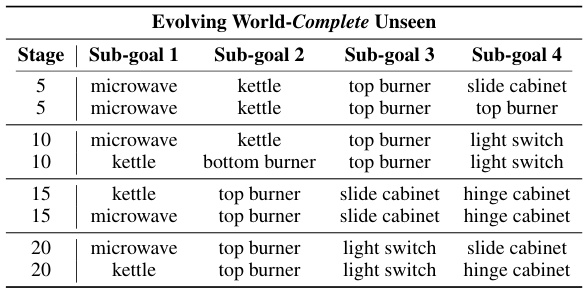
This table presents the results of task adaptation experiments using unseen tasks in two environments: Evolving Kitchen and Evolving World. For each environment, the table shows the performance (FWT, BWT, AUC) of different algorithms, including both on all tasks and only on the unseen adaptation tasks (FWT-A, AUC-A). The suffix ‘-A’ indicates metrics calculated specifically for the unseen tasks, providing a more focused view on adaptation capabilities. The table allows for comparison of different continual learning algorithms in their ability to handle newly introduced tasks and adapt their models.

This table shows the performance of different continual learning algorithms on two scenarios: Evolving Kitchen-Complete Unlearning and Evolving Kitchen-Incomplete Unlearning. The algorithms were evaluated on their ability to adapt to novel tasks and also to effectively unlearn previously learned tasks. The results are presented in terms of Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC), all expressed as percentages. The FWT, BWT, and AUC metrics assess task adaptation, how well the algorithms maintain performance on previous tasks after learning new ones, and overall continual learning performance, respectively.
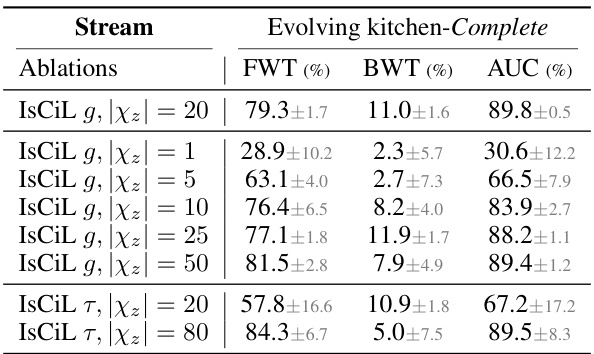
This table presents the results of continual imitation learning (CiL) experiments on two environments: Evolving Kitchen and Evolving World. Multiple baselines are compared, categorized as sequential adaptation, adapter-based methods, and a multi-task oracle (representing ideal performance). The table shows Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC) for three scenarios (Complete, Semi-complete, and Incomplete) each with 20 stages. Higher values for FWT, BWT, and AUC indicate better performance. The scenarios differ in how much of the demonstration data is available for each task. The table helps assess the sample efficiency and task adaptation capabilities of different continual learning approaches.
This table presents a comparison of different continual imitation learning (CIL) methods on two benchmark tasks: Evolving Kitchen and Evolving World. The methods are categorized into sequential adaptation, adapter-based approaches, and a multi-task oracle (representing optimal performance). Results are shown for three scenarios representing varying levels of data completeness (Complete, Semi-complete, Incomplete) across 20 stages of continual learning. The metrics used are Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC), all based on goal-conditioned success rates. Higher values generally indicate better performance.
This table presents the results of continual imitation learning (CiL) experiments conducted on two environments: Evolving Kitchen and Evolving World. It compares various baseline methods (sequential adaptation and adapter-based approaches) against the proposed IsCiL method and an oracle (multi-task learning). The performance is evaluated across three scenarios (Complete, Semi-complete, and Incomplete), each comprising 20 stages. The table reports the Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC) for each method and scenario, highlighting the best and second-best performing methods.
This table presents a comparison of different continual imitation learning (CIL) methods on two complex tasks: Evolving Kitchen and Evolving World. It shows the performance of each method across three different scenarios (Complete, Semi-complete, and Incomplete) that vary in the completeness of the training data. The metrics used for evaluation include Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC). The results show how well each method adapts to new tasks, maintains performance on previously learned tasks, and learns efficiently across different stages and scenarios.
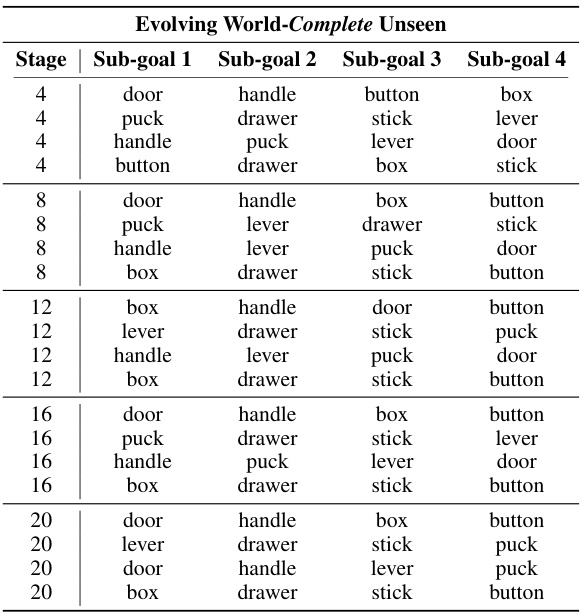
This table presents the results of experiments evaluating the task adaptation performance of different continual learning methods when faced with completely unseen tasks. Two environments are tested: Evolving World and Evolving Kitchen. Novel tasks are introduced periodically, and performance is measured both on these new tasks and on previously learned tasks. The suffix ‘-A’ denotes metrics calculated only from the new adaptation tasks, providing a focused evaluation of the algorithm’s ability to learn new tasks.

This table presents the results of continual imitation learning (CIL) experiments on two environments: Evolving Kitchen and Evolving World. It compares various CIL methods (including the proposed IsCiL method) across three different scenarios (Complete, Semi-complete, and Incomplete) which vary in the completeness of the demonstrations provided for each task. The table shows the performance of each method in terms of Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC). Higher values for all three metrics indicate better performance.

This table presents the results of continual imitation learning (CiL) experiments on two different environments, ‘Evolving Kitchen’ and ‘Evolving World.’ Several baselines are compared against the proposed IsCiL method. The performance is evaluated across three scenarios: Complete, Semi-complete (with some missing demonstrations), and Incomplete (with many missing demonstrations). The metrics used to assess performance are Forward Transfer (FWT), Backward Transfer (BWT), and Area Under Curve (AUC). The table highlights the best and second-best performing methods for each scenario and environment.

This table presents a comparison of different continual imitation learning (CIL) methods on two benchmark environments: Evolving Kitchen and Evolving World. The methods are categorized into sequential adaptation and adapter-based approaches. Three scenarios are evaluated: Complete, Semi-complete, and Incomplete, which vary in the amount of training data available for each task. The results show the forward transfer (FWT), backward transfer (BWT), and area under the curve (AUC) for each method across different scenarios. The table highlights the best-performing method for each scenario and provides a quantitative assessment of the efficiency and robustness of various CIL approaches.
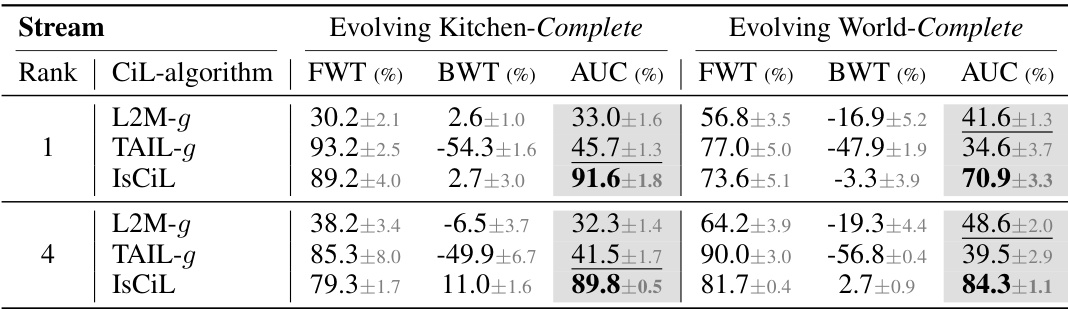
This table presents the results of continual imitation learning (CIL) experiments on two environments: Evolving Kitchen and Evolving World. Different CIL algorithms (baselines and the proposed IsCiL) are evaluated across three scenarios (Complete, Semi-complete, and Incomplete) varying in the completeness of the demonstrations provided for each task. The scenarios differ in how much of the data is available for each task. Performance is measured using Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC), all calculated from goal-conditioned success rates. The table highlights the best and second-best performing algorithms for each scenario.
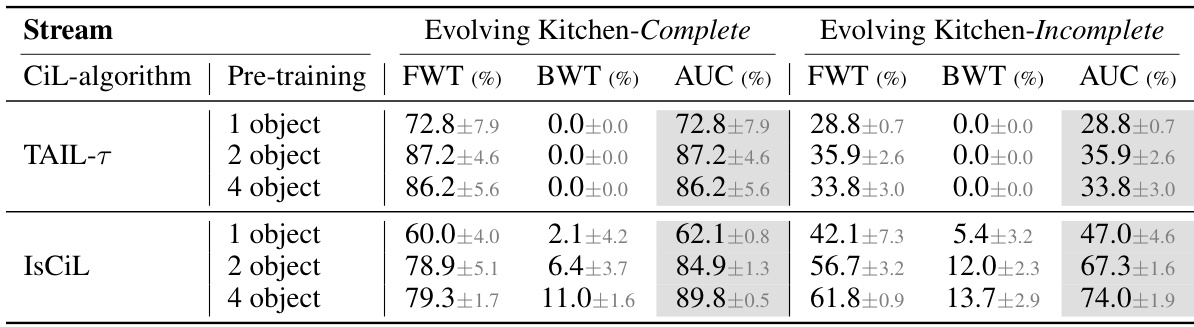
This table presents the overall performance comparison of various continual imitation learning (CIL) methods across different scenarios (Complete, Semi-complete, and Incomplete) in two environments: Evolving Kitchen and Evolving World. The methods are categorized as sequential adaptation, adapter-based approaches, and a multi-task oracle. Each scenario consists of 20 stages, and performance is measured using Forward Transfer (FWT), Backward Transfer (BWT), and Area Under the Curve (AUC) metrics. The table highlights the best and second-best performing methods for each scenario.
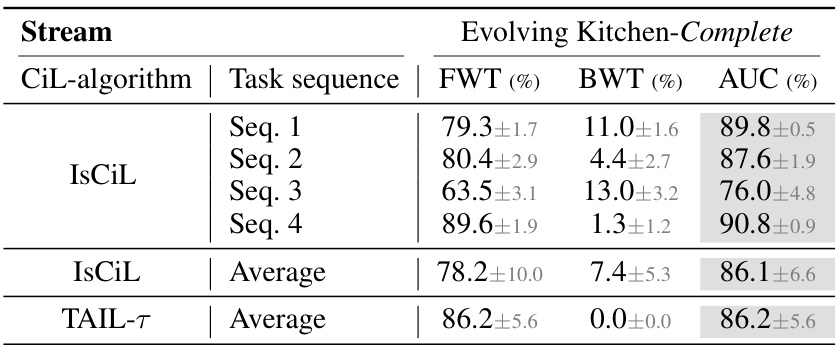
This table presents the results of continual imitation learning (CIL) experiments on two environments: Evolving Kitchen and Evolving World. Different CIL algorithms (baselines and the proposed IsCiL) are evaluated across three scenarios (Complete, Semi-complete, and Incomplete) which vary in the completeness of the provided demonstrations. The table shows the forward transfer (FWT), backward transfer (BWT), and area under the curve (AUC) for each algorithm and scenario, indicating their performance in adapting to new tasks and retaining knowledge of previously learned tasks. Higher values indicate better performance. The best-performing algorithm is highlighted in bold, and the second-best is underlined.
Full paper#