↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) often struggle with long-context awareness, overlooking crucial information and hindering performance. This is partly due to the inherent limitations of positional embeddings like Rotary Position Embeddings (RoPE). Existing solutions either lack efficiency or suffer from limitations in their ability to dynamically adjust attention according to the changing context during generation.
To address this, the researchers propose MoICE (Mixture of In-Context Experts), a novel plug-in that enhances LLMs by dynamically selecting and combining multiple RoPE angles within each attention head. MoICE uses a router to select the most relevant RoPE angles for each token, enabling flexible processing of information across different contextual positions. The router-only training strategy ensures efficient fine-tuning without catastrophic forgetting. Experiments demonstrate MoICE’s superior performance across various tasks on long context understanding and generation, while maintaining excellent inference efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient method to improve LLMs’ long context awareness, a critical challenge in the field. The router-only training strategy is particularly significant, offering a practical solution to the catastrophic forgetting problem often encountered when fine-tuning large models. The findings open avenues for developing more efficient and effective LLMs capable of handling longer contexts.
Visual Insights#

This figure compares three different methods for enhancing LLMs’ context awareness: Attention Buckets, Ms-PoE, and MoICE. Attention Buckets uses multiple RoPE angles in parallel, increasing computational cost. Ms-PoE uses a unique angle per head, requiring an extra forward pass. MoICE integrates a router into each attention head to dynamically select the most suitable RoPE angles for each token, offering improved efficiency and performance.

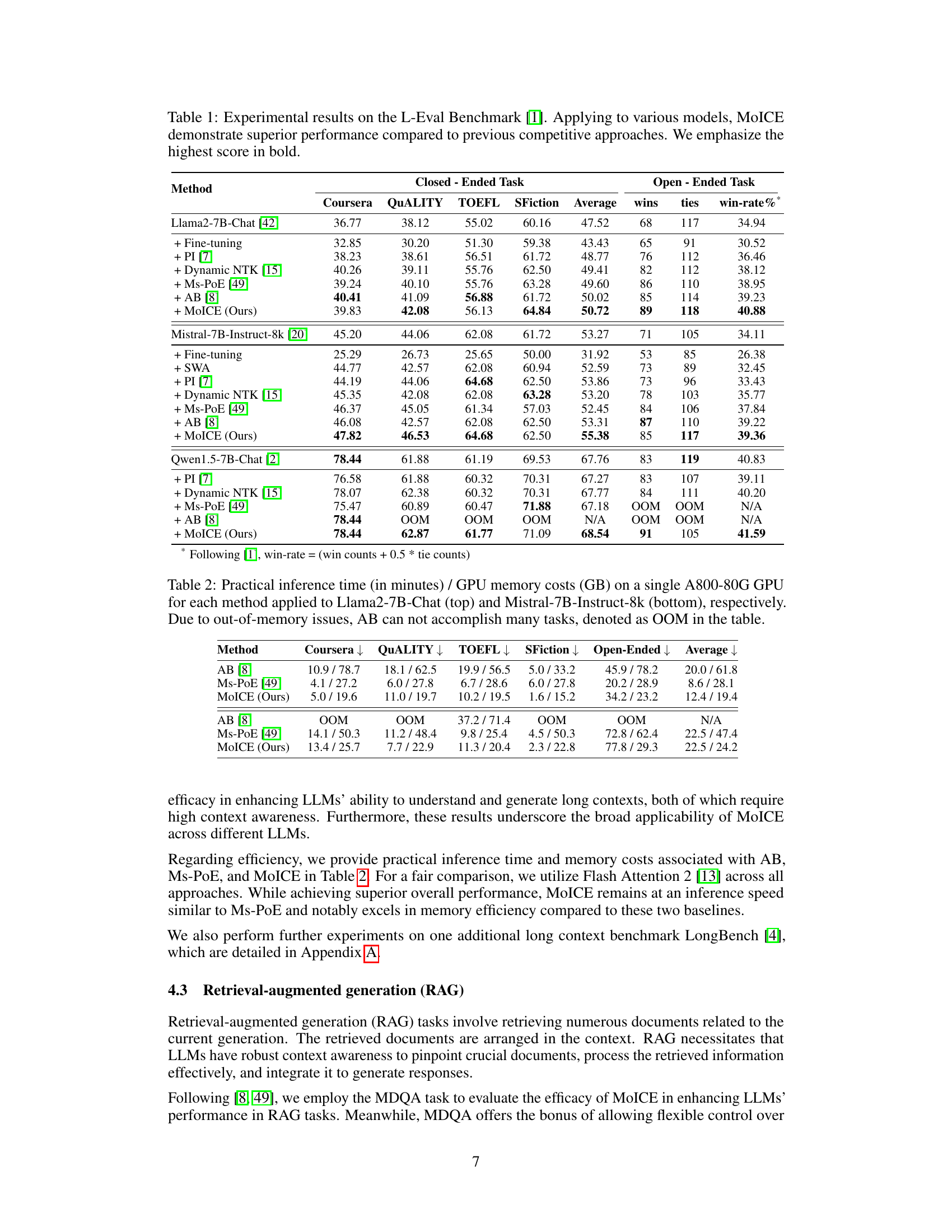
This table presents the results of experiments conducted on the L-Eval benchmark, comparing the performance of MOICE against several baselines across various tasks. The tasks are categorized into closed-ended (requiring factual answers) and open-ended (requiring more creative or complex generation). Three different large language models (LLMs) were used: Llama2-7B-Chat, Mistral-7B-Instruct-8k, and Qwen1.5-7B-Chat. The table shows that MOICE consistently outperforms the baselines across all three LLMs and both task types, demonstrating its effectiveness in enhancing long-context understanding and generation.
In-depth insights#
MoICE Architecture#
The MoICE architecture centers around integrating a router into each attention head of a transformer-based large language model (LLM). This router, a multi-layer perceptron (MLP), dynamically selects a subset of RoPE angles, treated as “in-context experts,” for each token. Crucially, this selection is not static but rather dynamic, adapting to the specific contextual needs of each token and head. The router outputs a probability distribution over available RoPE angles, and the top K angles with the highest probabilities are selected. The attention mechanism then uses a weighted combination of attention scores calculated using these selected RoPE angles. This dynamic selection process mitigates the limitations of prior approaches that use static RoPE angle assignments, allowing MoICE to effectively attend to relevant information across diverse and changing contextual positions, significantly improving long-context awareness while maintaining computational efficiency.
Router-Only Training#
The ‘Router-Only Training’ strategy in the MoICE framework represents a significant efficiency improvement over standard fine-tuning methods. By freezing the LLM parameters and exclusively training the lightweight routers, it avoids catastrophic forgetting and reduces computational cost considerably. This approach is particularly crucial when dealing with large LLMs, where updating all parameters is computationally expensive and time-consuming. The strategy’s effectiveness highlights the modular design of MoICE, where the router acts as a plug-in component, allowing selective training without impacting the main model’s performance. This modularity is key to MoICE’s efficiency and allows for rapid adaptation to new tasks or datasets with minimal computational overhead. Furthermore, the router-only training effectively addresses the challenge of dynamic context shifts during generation, as the router learns to select relevant contextual positions on a token-by-token basis, offering a significant enhancement to the overall performance and inference efficiency.
Long Context Tasks#
The heading ‘Long Context Tasks’ suggests an examination of how large language models (LLMs) handle inputs exceeding their typical contextual window. This likely involved evaluating performance on tasks requiring the processing of extensive text, such as long document summarization, question answering over extended passages, and multi-turn dialogue. The experiments would gauge the models’ ability to maintain coherence, recall relevant information from earlier parts of the input, and avoid errors caused by context limitations, including the ’lost-in-the-middle’ phenomenon. Successful handling of these long context tasks indicates the LLM’s improved capacity for information integration and sustained attention, signifying advancements beyond the constraints of shorter-context processing. Metrics employed likely included accuracy, coherence scores, and possibly efficiency measures, as successful long-context performance needs to be computationally feasible. The results in this section would reveal the effectiveness of the proposed methods in enhancing LLMs’ long-context capabilities, potentially including comparative analysis with baseline methods that do not address context window limitations.
Efficiency Analysis#
An efficiency analysis of a large language model (LLM) enhancement technique would ideally explore multiple facets. Computational cost, measured by time and memory usage during both training and inference, is crucial. This should compare the enhanced model’s performance against baselines, noting the trade-off between improved accuracy and resource consumption. Inference speed is particularly important for real-world applications, and the analysis should assess if the gains in accuracy justify any increase in latency. A key aspect is the scalability of the method. Does the efficiency advantage hold as model size and context length increase? Furthermore, the analysis should consider the hardware requirements; determining if specialized hardware is needed or if the method is compatible with commonly available resources. Finally, a thorough analysis should decompose the computational overhead, identifying the most resource-intensive components of the enhancement and exploring potential optimizations.
Future of MoICE#
The future of MoICE hinges on several key aspects. Extending its applicability to a broader range of LLMs and architectures beyond those initially tested is crucial. This involves rigorous evaluation across diverse model sizes and designs, potentially necessitating architectural modifications to seamlessly integrate with differing attention mechanisms. Improving the efficiency of the router through optimizations like quantization or pruning would enhance practicality for deployment in resource-constrained settings. Another avenue for development lies in exploring more sophisticated routing strategies that move beyond simple MLPs, perhaps incorporating attention mechanisms or graph neural networks for more nuanced context selection. Investigating the interplay of MoICE with other context extension techniques offers the potential for synergistic improvements. The ability to incorporate and leverage external knowledge sources to enhance context awareness also presents a promising area for future research. Finally, thorough investigation into the theoretical underpinnings of MoICE is necessary, deepening our understanding of its effectiveness and addressing any potential limitations. These advancements would solidify MoICE’s position as a robust and versatile tool for enhancing long-context awareness in LLMs.
More visual insights#
More on figures
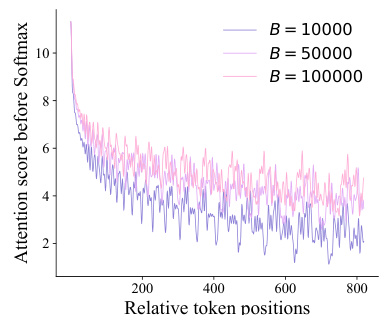
This figure shows how different base values (Bj) in the Rotary Position Embedding (RoPE) affect the attention scores between a token and its neighbors at varying distances. Each line represents a different Bj value, illustrating how the maximum attention score changes with the distance from the token. The varying upper bounds highlight the uneven awareness of LLMs towards different contextual positions, a core problem addressed in the paper.
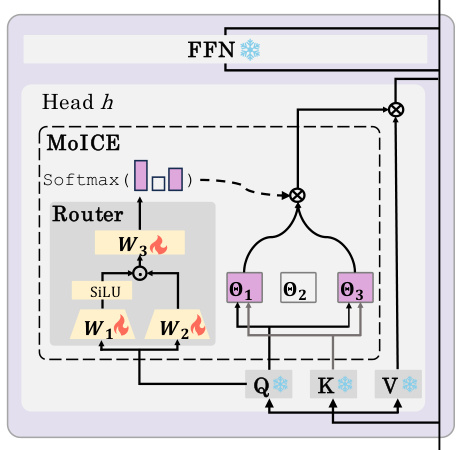
This figure shows the architecture of Mixture of In-Context Experts (MoICE), a novel plug-in for LLMs. It consists of a router integrated into each attention head which selects the most suitable RoPE angles for computing the attention scores. The router’s parameters are the only trainable parameters and the weights are updated through a lightweight router-only training optimization strategy. The figure simplifies the illustration to a single head, showing how the router dynamically selects among a set of available RoPE angles.

This figure illustrates the architecture of the Mixture of In-Context Experts (MoICE) method. It shows how a MoICE router, a multi-layer perceptron (MLP), is integrated into each attention head of a large language model (LLM). The router dynamically selects K RoPE angles (in-context experts) out of a set of N candidate RoPE angles based on the input query. Only the router parameters are updated during training; the LLM parameters remain fixed. The figure highlights the dynamic selection of RoPE angles per token, allowing flexible attention to various contextual positions.

The figure shows the architecture of Mixture of In-Context Experts (MoICE). MoICE is a plug-in module for LLMs that enhances context awareness. The core component is a router integrated into each attention head. The router dynamically selects K RoPE angles (in-context experts) from a set of N candidates, based on the query vector. These selected angles are used to compute attention scores, which are then aggregated to create the final attention pattern. Only the router’s parameters are trained; the LLM’s parameters are frozen. The figure simplifies the illustration to a single attention head with N=3 and K=2 to improve understanding.

This figure illustrates the architecture of the Mixture of In-Context Experts (MoICE) method. It shows how MoICE is integrated into a single attention head within a larger language model (LLM). The key components are a router (an MLP) that selects a subset of RoPE angles (in-context experts) and the mechanism for aggregating the attention scores computed with those selected angles. The figure highlights that only the router’s parameters are updated during training, while the LLM parameters remain frozen. The simplified example uses 3 RoPE angles (N=3) and selects 2 of them (K=2) for each token.
More on tables
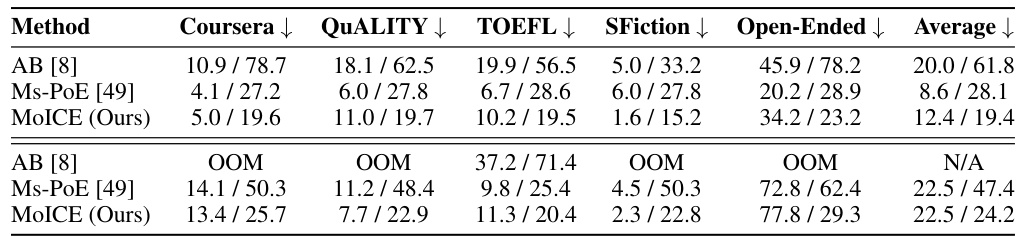
This table presents a comparison of the practical inference time and GPU memory consumption for different methods used to enhance LLMs’ context awareness. The methods compared are Attention Buckets (AB), Multi-Scale Positional Embedding (Ms-PoE), and Mixture of In-Context Experts (MoICE). The table shows the resource usage for each method on two different LLMs (Llama2-7B-Chat and Mistral-7B-Instruct-8k) for various tasks (Coursera, QUALITY, TOEFL, SFiction, Open-Ended). Note that the Attention Buckets (AB) method resulted in out-of-memory (OOM) errors for several tasks due to high resource demands.
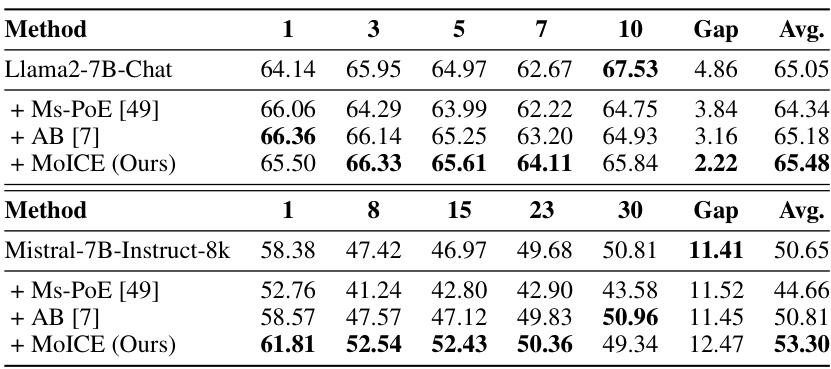
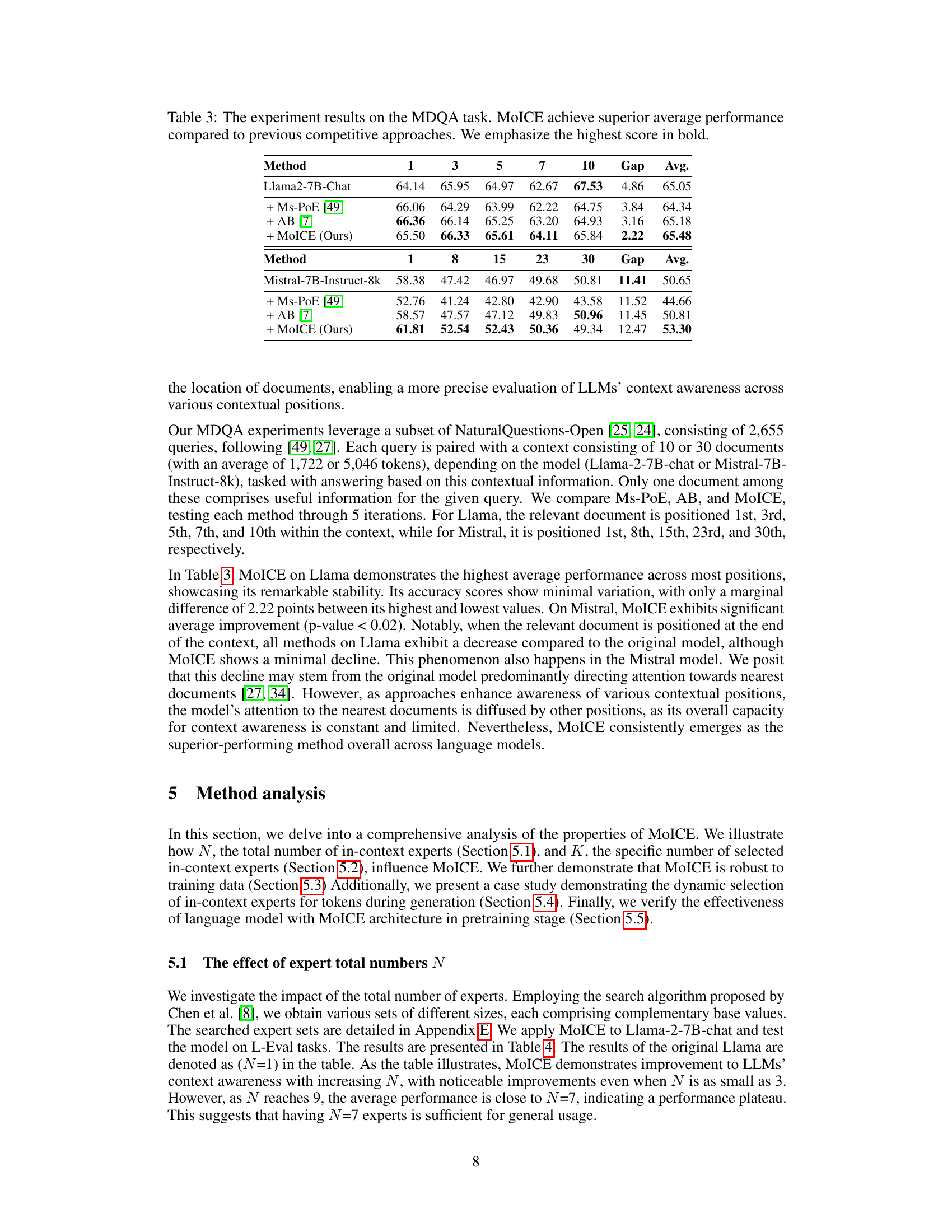
This table presents the results of experiments conducted on the MDQA task, a benchmark for evaluating the effectiveness of different methods in enhancing LLMs’ context awareness within the context of retrieval-augmented generation (RAG). The table compares the performance of MoICE against several baseline methods (Ms-PoE, AB) across various positions of the relevant document within the context (for Llama2-7B-Chat, positions 1, 3, 5, 7, and 10; for Mistral-7B-Instruct-8k, positions 1, 8, 15, 23, and 30). The ‘Gap’ column represents the difference between the highest and lowest average performance across all positions for each method. The highest average scores are highlighted in bold, showcasing the superior performance of MOICE.
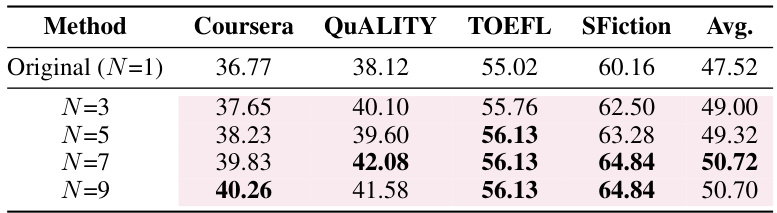
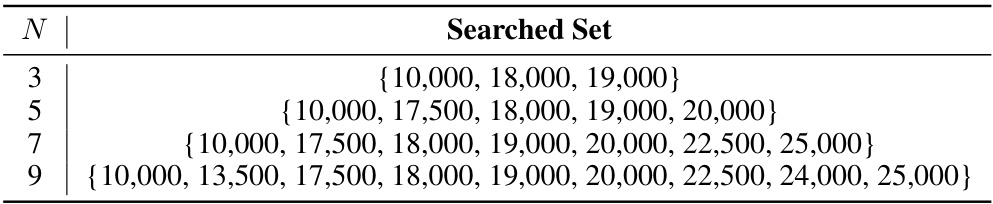
This table presents the performance of the Llama-2-7B-chat language model enhanced with the MoICE method, using different numbers (N) of in-context experts. The results show how increasing the number of experts improves the model’s performance on various aspects, highlighting improvements over the original model without MoICE. The table’s data is organized by different numbers of experts (N), and their effect on performance metrics (Coursera, QUALITY, TOEFL, SFiction, and Avg.) is shown.
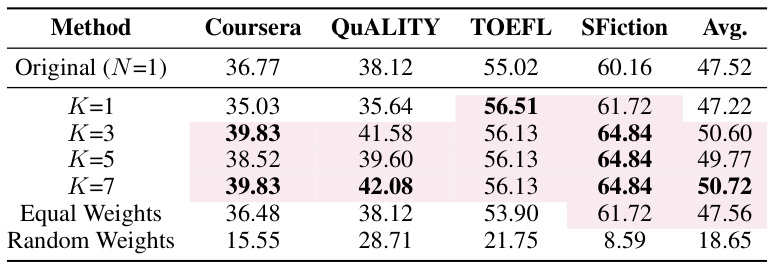
This table presents the performance of Llama-2-7B-chat enhanced with MoICE, varying the number of selected experts (K) while keeping the total number of experts (N) fixed at 7. It shows the average scores across four metrics (Coursera, QUALITY, TOEFL, SFiction) for different values of K (1, 3, 5, 7), as well as for scenarios with equal or random weights assigned to the selected experts. The purpose is to demonstrate the effect of the number of selected experts on the model’s context awareness.
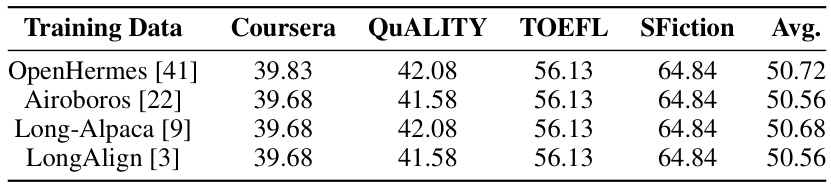
This table presents the results of experiments evaluating the impact of different training datasets on the performance of Llama-2-7B-chat enhanced with the MoICE method. The table shows the average scores achieved on four different tasks (Coursera, QuALITY, TOEFL, and SFiction) for four different training datasets (OpenHermes, Airoboros, Long-Alpaca, and LongAlign). The results demonstrate the robustness of the MoICE method to various training data.
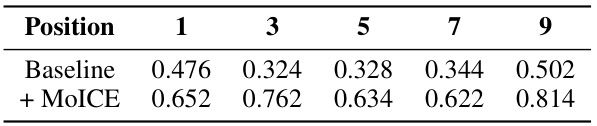
This table presents the results of experiments conducted on the MDQA (Multi-Document Question Answering) task. It compares the performance of MoICE against several baseline methods (Ms-PoE, AB) across different LLMs (Llama-2-7B-Chat and Mistral-7B-Instruct-8k). The results show the average performance across various positions of the relevant document within the context. The ‘Gap’ column represents the difference between the highest and lowest average performance across positions for each model and LLM.

This table presents the results of experiments conducted on the L-Eval benchmark to evaluate the performance of the proposed MoICE method and several competitive baselines. The benchmark consists of tasks categorized into two groups: closed-ended and open-ended. Closed-ended tasks focus on the capacity for understanding and reasoning within long contexts, while open-ended tasks include summarization generation and open-format question-answering. The table compares the performance across multiple open-source LLMs (Llama2-7B-Chat, Mistral-7B-Instruct-8k, and Qwen1.5-7B-Chat), highlighting the superior performance achieved by MOICE in both task categories and across various models.
This table presents the results of experiments conducted on the L-Eval benchmark, comparing the performance of the proposed MoICE method against several baselines and other state-of-the-art methods for enhancing long-context understanding and generation in LLMs. It shows the performance across different tasks (Coursera, QUALITY, TOEFL, SFiction) for both closed-ended and open-ended questions, indicating superior performance of MoICE across multiple models (Llama2-7B-Chat, Mistral-7B-Instruct-8k, Qwen1.5-7B-Chat). The highest scores for each category are highlighted in bold, showcasing the effectiveness of MOICE.

This table presents the results of experiments conducted on the L-Eval benchmark to evaluate the performance of MoICE against several baselines and other state-of-the-art methods for enhancing the context awareness of LLMs. The benchmark consists of closed-ended and open-ended tasks, evaluating long context understanding and generation. Results show MoICE’s superior performance across various LLMs, and the best results are highlighted.

This table presents the ablation study results on the auxiliary loss used in the MoICE model. By removing the auxiliary loss (Laux) from the overall training objective (Eq. 10), the impact on the model’s performance is evaluated on two different LLMs (Llama2-7B-chat and Mistral-7B-Instruct-8k). The results demonstrate that removing the auxiliary loss leads to a significant decrease in performance across various metrics (Coursera, QUALITY, TOEFL, SFiction), highlighting its crucial role in enhancing the performance of the MoICE model.
Full paper#