↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing knowledge graph embedding (KGE) methods often struggle with limited knowledge, hindering optimal performance. KG-FIT tackles this by incorporating rich contextual information from large language models (LLMs). This approach helps overcome the limitations of solely relying on graph structure for KGE.
KG-FIT employs a two-stage process. First, it constructs a semantically coherent entity hierarchy using LLMs and agglomerative clustering. Second, it fine-tunes the KG embeddings using this hierarchy, textual information from LLMs, and link prediction. The results demonstrate that KG-FIT significantly improves link prediction accuracy on multiple benchmark datasets. The method’s scalability and compatibility with any LLM make it an important advancement in KGE.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on knowledge graph embedding (KGE) and its applications. It introduces a novel framework that significantly improves the performance of KGEs by integrating open-world knowledge from large language models (LLMs). This work addresses a major limitation of existing KGE methods, which often neglect the wealth of information outside the knowledge graph itself. The improved KGE performance has significant implications across various downstream applications, including question answering, recommendation systems, and drug discovery. Furthermore, the proposed method’s flexibility and efficiency make it highly relevant to current research trends and open up new avenues for further investigation in the field.
Visual Insights#
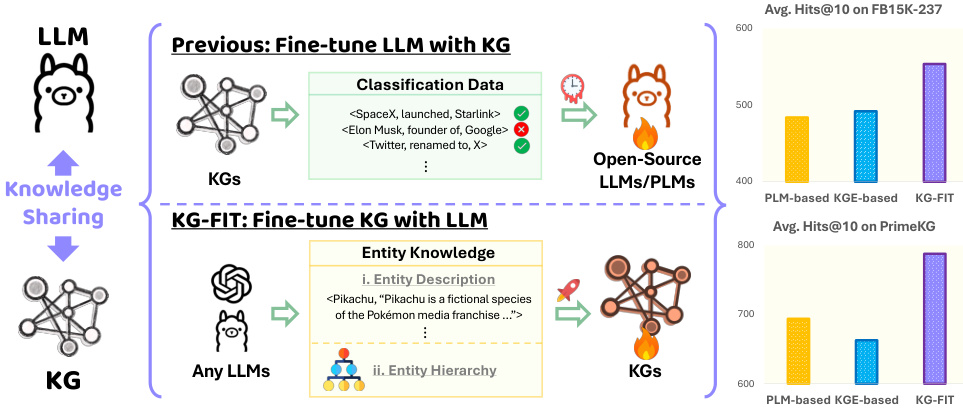
This figure compares two different approaches for integrating knowledge graphs (KGs) with large language models (LLMs): (1) Fine-tuning an LLM with KG data, typically using classification data based on KG facts; and (2) Fine-tuning a KG with LLM-derived knowledge. The chart visually demonstrates the superior performance of the second approach (KG-FIT) on the FB15K-237 and PrimeKG benchmark datasets, measured by average Hits@10 in link prediction tasks. The figure highlights the effectiveness of leveraging LLMs to enrich KG embeddings and improve downstream task performance.
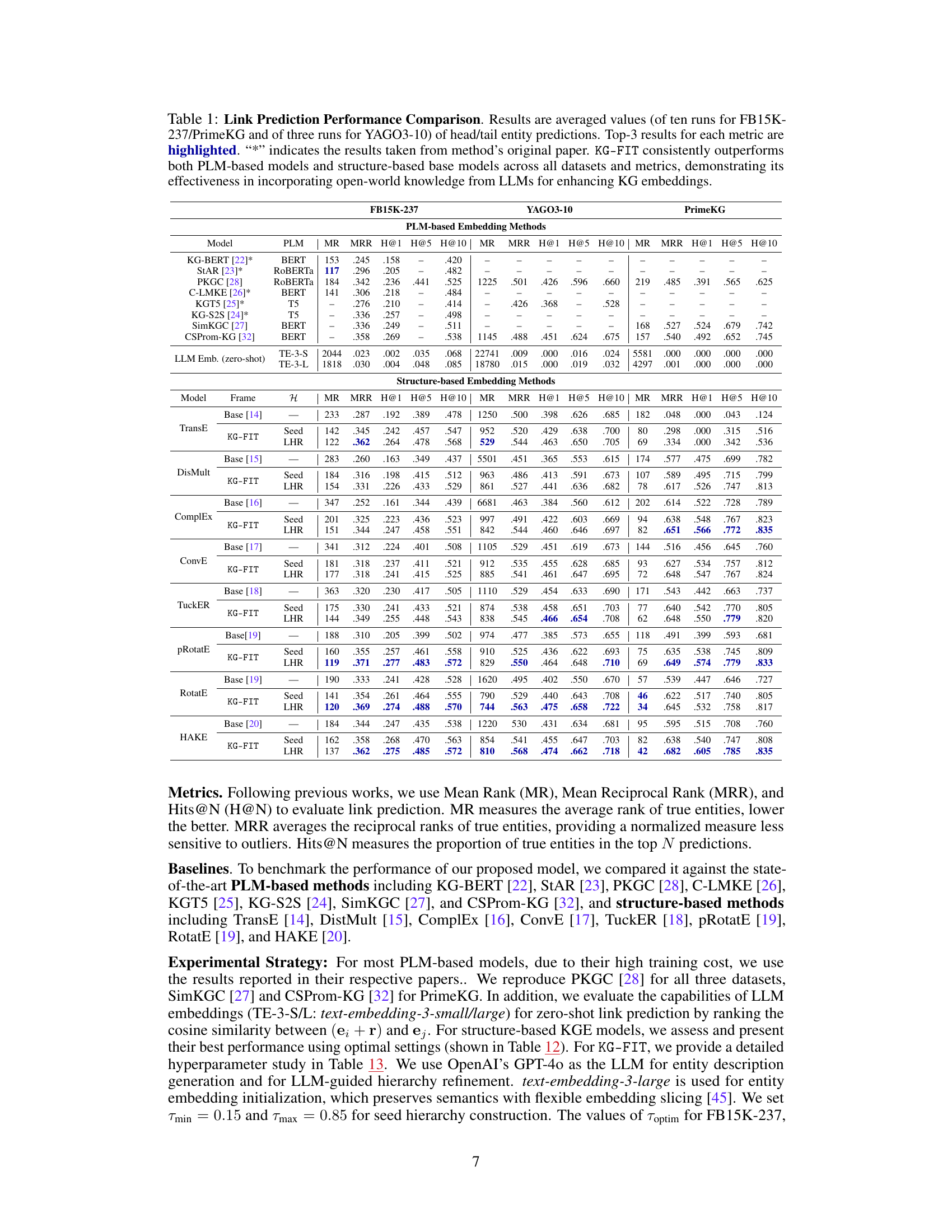
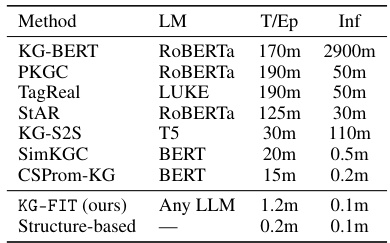
This table presents a comparison of link prediction performance across various KG embedding methods. It includes PLM-based methods (KG-BERT, StAR, PKGC, etc.) and structure-based methods (TransE, DistMult, ComplEx, etc.). The table shows the Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N) metrics for each model on FB15K-237, YAGO3-10, and PrimeKG datasets. The results highlight KG-FIT’s superior performance across all metrics and datasets, showcasing its ability to leverage open-world knowledge from LLMs to improve KG embeddings.
In-depth insights#
KG Embeddings#
Knowledge graph embedding (KGE) techniques are crucial for effective knowledge graph (KG) reasoning. KGEs aim to represent entities and relationships in a KG as low-dimensional vectors, capturing semantic information and structural patterns. Various KGE methods exist, each with its own strengths and weaknesses. Early approaches focused on translating embeddings to model relationships (TransE), while later methods leveraged bilinear models (DistMult) and complex numbers (ComplEx) to capture richer interactions. More recent work explores convolutional networks and other neural architectures for improved expressiveness and scalability. A key challenge in KGE is effectively integrating symbolic and statistical information to handle the complexity and heterogeneity of real-world KGs. The incorporation of external knowledge sources, such as large language models, and techniques like hierarchical clustering are promising directions for enhancing the expressiveness and informativeness of KG embeddings. The selection of appropriate scoring functions and the management of computational complexity are crucial considerations in KGE model development and application.
LLM-KG Fusion#
LLM-KG fusion represents a significant advancement in knowledge representation and reasoning. By integrating the strengths of Large Language Models (LLMs) and Knowledge Graphs (KGs), this approach aims to overcome the limitations of each individual technology. LLMs excel at capturing rich semantic information from textual data, while KGs provide structured, symbolic knowledge representation. Fusion strategies must carefully address the inherent differences in data representation and reasoning paradigms. A successful fusion would leverage LLMs’ ability to understand and generate natural language, while harnessing KGs’ capabilities for efficient reasoning and knowledge retrieval. This could involve using LLMs to enrich KGs with missing information, enhance entity representations, or improve question answering capabilities. Challenges include efficiently managing the computational cost of integrating two complex models, and ensuring the resulting system is robust, accurate, and avoids biases present in either the LLM or KG data. Successful LLM-KG fusion will likely lead to improved performance in various downstream tasks such as question answering, recommendation systems, and drug discovery. Further research should explore novel fusion architectures, focus on addressing scalability issues, and investigate methods for mitigating potential biases.
Hierarchical KG#
A Hierarchical KG enhances knowledge graph (KG) representation by organizing entities and relationships into a hierarchy, mirroring real-world taxonomies. This structure improves several aspects of KG analysis. Improved reasoning: Hierarchical relationships facilitate more efficient and accurate inference by reducing the search space and enabling focused traversal. Enhanced expressiveness: Hierarchies capture semantic nuances and inherent relationships among entities more effectively than flat KGs, leading to richer and more meaningful representations. Scalability: Hierarchical organization can significantly improve the scalability of KG processing, enabling efficient management and analysis of large-scale graphs. However, creating and maintaining a hierarchical KG poses challenges. Construction: Building accurate hierarchies may require substantial domain expertise or sophisticated algorithms. Maintenance: Updating and evolving the hierarchy to incorporate new information or changes in existing relationships requires careful consideration and potentially significant computational effort. Ultimately, the benefits of a hierarchical KG depend on the specific application and the costs associated with its creation and maintenance.
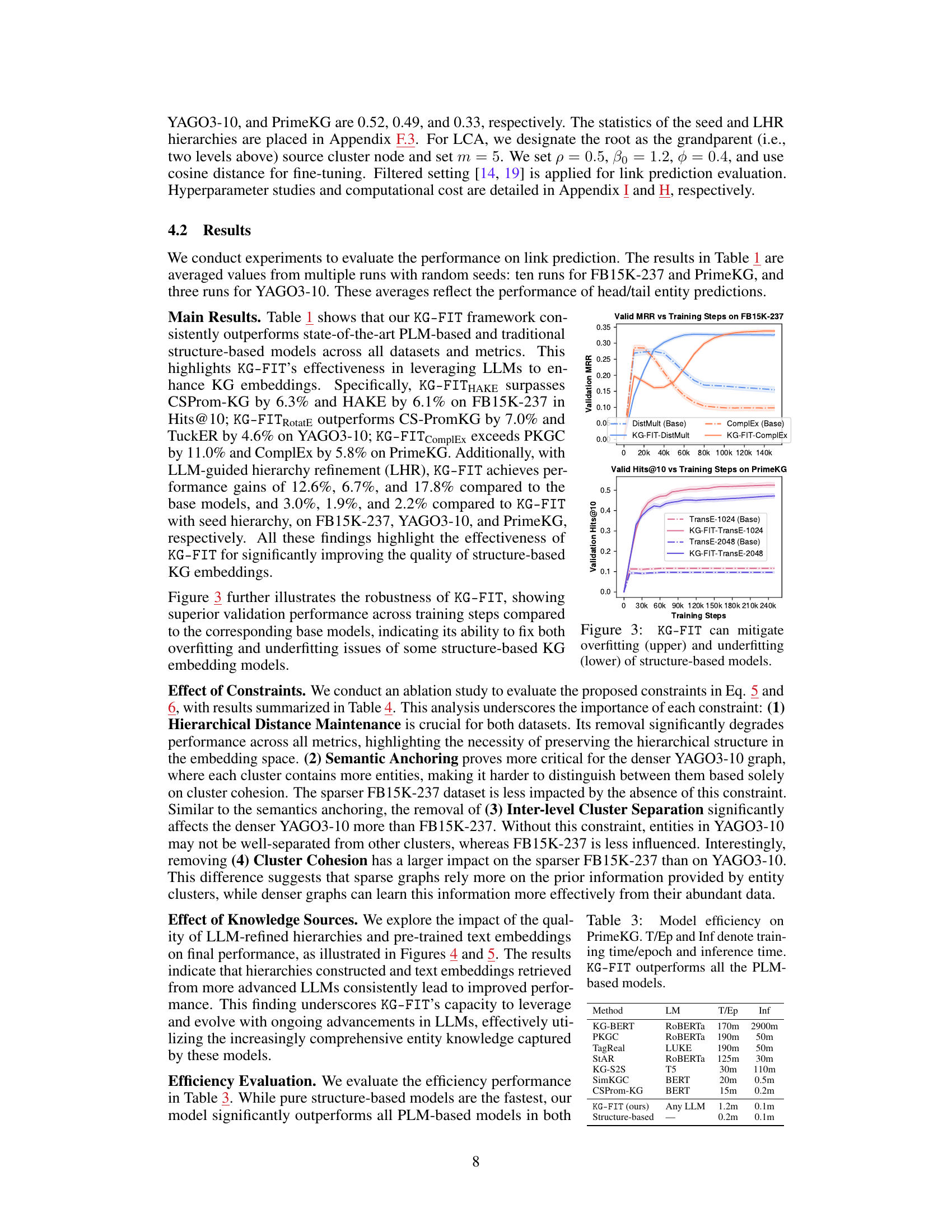
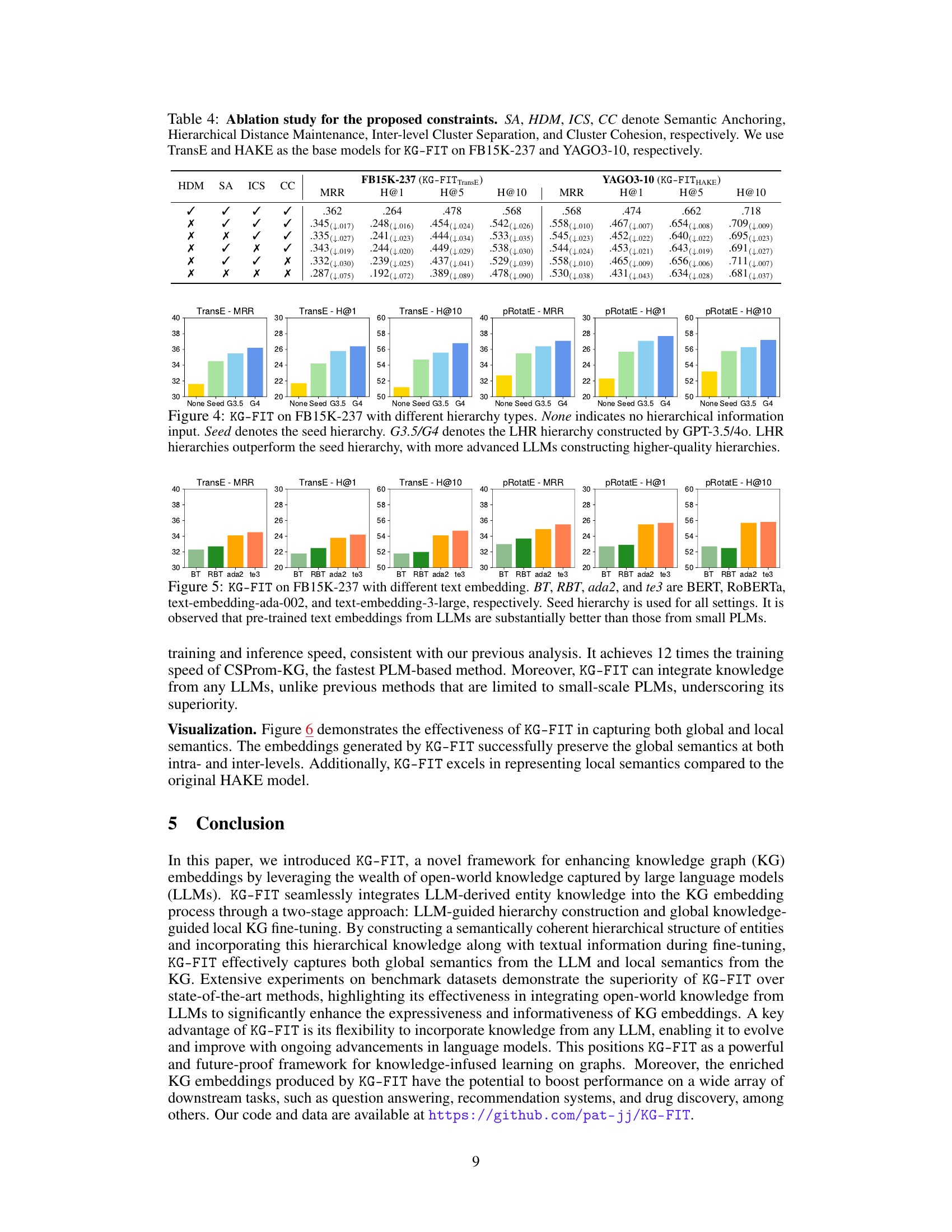
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In this context, it would likely involve removing constraints (e.g., hierarchical, semantic anchoring, inter-level separation, cluster cohesion) to determine their impact on link prediction performance. The results would reveal the relative importance of each constraint, highlighting which ones significantly contribute to the model’s accuracy and which ones are less critical or even detrimental. A well-executed ablation study would demonstrate the robustness of the proposed methodology, showing that the model’s success relies on the integrated interaction of its components, not a single dominant factor. Interpreting the results will require careful consideration of whether constraint removal leads to performance degradation or improvements. For example, removing the semantic anchoring constraint might help mitigate overfitting in some scenarios. It will also indicate if the model is more sensitive to the removal of specific components on particular datasets, suggesting that optimal model design may vary depending on dataset characteristics. Overall, the ablation study serves as crucial validation of the KG-FIT model architecture and its individual components.
Future Works#
The paper’s ‘Future Works’ section would ideally explore several avenues. Extending KG-FIT to handle various KG structures and sizes is crucial, going beyond the current benchmark datasets. Addressing the limitations of relying solely on agglomerative clustering for the hierarchical structure, perhaps by incorporating more sophisticated methods, would improve accuracy and robustness. Investigating different LLM prompting strategies to refine the hierarchical structure would yield insights into efficiency and semantic coherence. Finally, a thorough investigation into the impact of different LLMs on KG-FIT’s performance is needed to ensure generalizability and to explore the potential benefits of utilizing more advanced models. Exploring how to adapt KG-FIT for different downstream tasks, such as question answering or recommendation systems, while demonstrating its effectiveness, is paramount. Addressing the inherent biases within LLMs and their propagation into KG embeddings, along with exploring techniques for bias mitigation, should also be a priority. Ultimately, a focus on scalability and efficiency of KG-FIT in handling very large-scale KGs is essential for widespread applicability.
More visual insights#
More on figures

This figure presents a detailed overview of the KG-FIT framework, a novel method for enhancing knowledge graph (KG) embeddings by incorporating open-world knowledge from large language models (LLMs). It illustrates the four main steps involved: entity embedding initialization, seed hierarchy construction, LLM-guided hierarchy refinement, and global knowledge-guided local KG fine-tuning. Each step shows the input, process, and output, clarifying how KG-FIT leverages LLMs to build a semantically coherent entity hierarchy and integrate it into the KG embedding process. The figure highlights the iterative nature of the framework, particularly in the hierarchy construction and refinement stages, and emphasizes how this iterative approach ensures the accuracy and effectiveness of the final KG embeddings.

This figure compares two different approaches to integrating knowledge graphs (KGs) with large language models (LLMs). The left side shows the traditional approach of first fine-tuning an LLM with KG data (using classification data), and then applying the fine-tuned LLM to KG tasks like link prediction. The right side depicts KG-FIT’s novel approach, which fine-tunes the KG embeddings using information from an LLM to improve their expressiveness and informativeness. The bar charts illustrate the comparative performance (average Hits@10 on FB15K-237 and PrimeKG datasets) of the PLM-based approach, the KGE-based approach, and the KG-FIT approach, highlighting the improved performance achieved by KG-FIT.

This figure provides a visual overview of the KG-FIT framework, highlighting the input and output of each step in the process. It begins with entity embedding initialization using LLMs, followed by seed hierarchy construction via agglomerative clustering. The hierarchy is then refined using LLM guidance, leading to a final fine-tuning step that integrates this refined hierarchical structure with the knowledge graph for enhanced KG embeddings.

This figure compares two approaches to integrating knowledge graphs (KGs) with large language models (LLMs). The left side shows the traditional approach of fine-tuning an LLM with KG data (classification data). The right side presents the KG-FIT approach, which fine-tunes a KG with LLM-derived knowledge (entity descriptions and entity hierarchy). The bar chart visually represents the average Hits@10 score on FB15K-237 and PrimeKG datasets, demonstrating that KG-FIT significantly outperforms the traditional approach in link prediction.
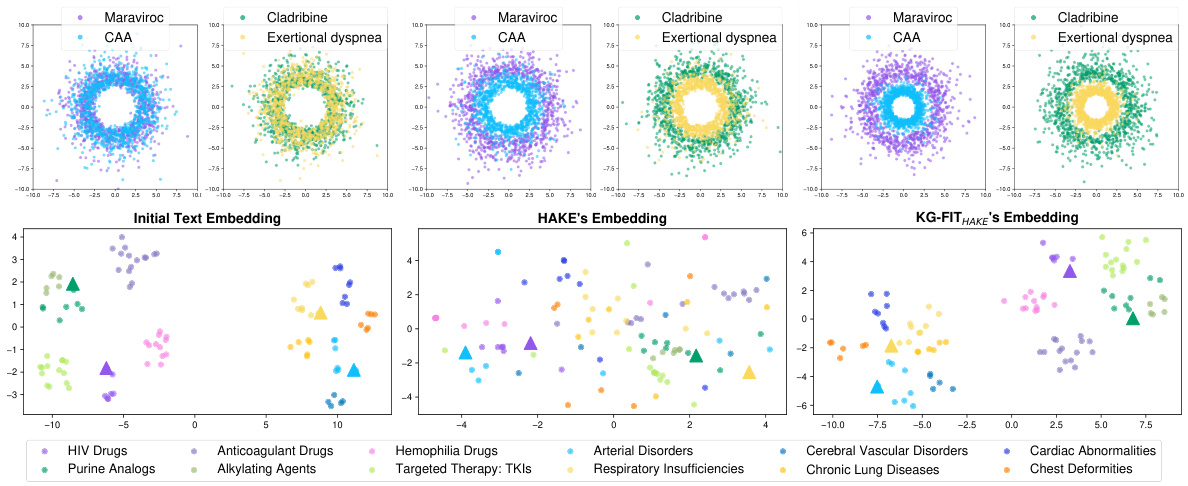
This figure visualizes the entity embeddings generated by three different methods: initial text embedding, HAKE embedding, and KG-FIT with HAKE embedding. It shows both local and global comparisons, highlighting how KG-FIT enhances the representation by combining both global semantics from LLMs and local semantics from the KG. The upper section uses polar plots to compare embeddings of specific entities related in parent-child triples in PrimeKG, visualizing local semantic relations. The lower section presents t-SNE plots for global comparison. KG-FIT demonstrates better capturing of hierarchical local semantics within the KG, without losing global semantic understanding from pretrained text embeddings.

This figure compares two different approaches to integrating knowledge graphs (KGs) with large language models (LLMs). The left side (‘Fine-tune LLM with KG’) shows a traditional approach where the LLM is first fine-tuned with KG data (e.g., classification data), and then used for KG-related tasks. The right side (‘Fine-tune KG with LLM’) depicts the KG-FIT approach, where the LLM provides knowledge to refine the KG embeddings, resulting in improved performance. The bar charts illustrate the difference in average Hits@10 performance on FB15K-237 and PrimeKG datasets, demonstrating the superiority of KG-FIT.

This figure illustrates the KG-FIT framework’s four steps. It starts by initializing entity embeddings using LLMs (Step 1), then constructs a seed hierarchy via agglomerative clustering (Step 2). This hierarchy is refined using LLM suggestions (Step 3) before a final fine-tuning step integrates the refined hierarchy and textual information with KG triples to enhance the KG embeddings (Step 4).

This figure provides a visual overview of the KG-FIT framework, illustrating its four main steps: (1) Entity Embedding Initialization, which combines LLM-generated descriptions with existing embeddings; (2) Seed Hierarchy Construction, which uses agglomerative clustering to create an initial hierarchy; (3) LLM-Guided Hierarchy Refinement, which refines the hierarchy using LLM suggestions; and (4) Global Knowledge-Guided Local KG Fine-Tuning, which integrates hierarchical and textual information to fine-tune KG embeddings.
This figure compares two different approaches for integrating knowledge graphs (KGs) with large language models (LLMs). The left side shows the traditional approach of fine-tuning an LLM with KG data, typically using classification tasks on KG triples. The right side depicts the KG-FIT approach, which fine-tunes KG embeddings using knowledge from the LLM. The bar charts visually represent the average Hits@10 scores on FB15K-237 and PrimeKG datasets, illustrating the performance difference between the two approaches. The KG-FIT approach shows significantly better performance in link prediction compared to the traditional method. This highlights KG-FIT’s ability to leverage the knowledge within an LLM and to better integrate this with KG data.
More on tables

This table presents the results of link prediction experiments on three benchmark datasets: FB15K-237, YAGO3-10, and PrimeKG. It compares KG-FIT’s performance against various state-of-the-art baselines, including both PLM-based (language model based) and structure-based (graph structure based) knowledge graph embedding methods. The results are averaged across multiple runs and presented using three evaluation metrics: Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (where N=1, 5, 10). The table highlights KG-FIT’s superior performance across all datasets and metrics, demonstrating the effectiveness of integrating open-world knowledge from Large Language Models (LLMs) to improve knowledge graph embedding.
This table presents a comparison of link prediction performance across various models on three benchmark datasets: FB15k-237, YAGO3-10, and PrimeKG. The models are categorized into PLM-based (pre-trained language model-based) and structure-based methods. For each dataset and method, the table reports the Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N) metrics (where N is 1, 5, and 10) for head and tail entity prediction. KG-FIT consistently achieves top performance across all metrics and datasets, highlighting its ability to leverage open-world knowledge from LLMs (Large Language Models) to improve KG (Knowledge Graph) embeddings.
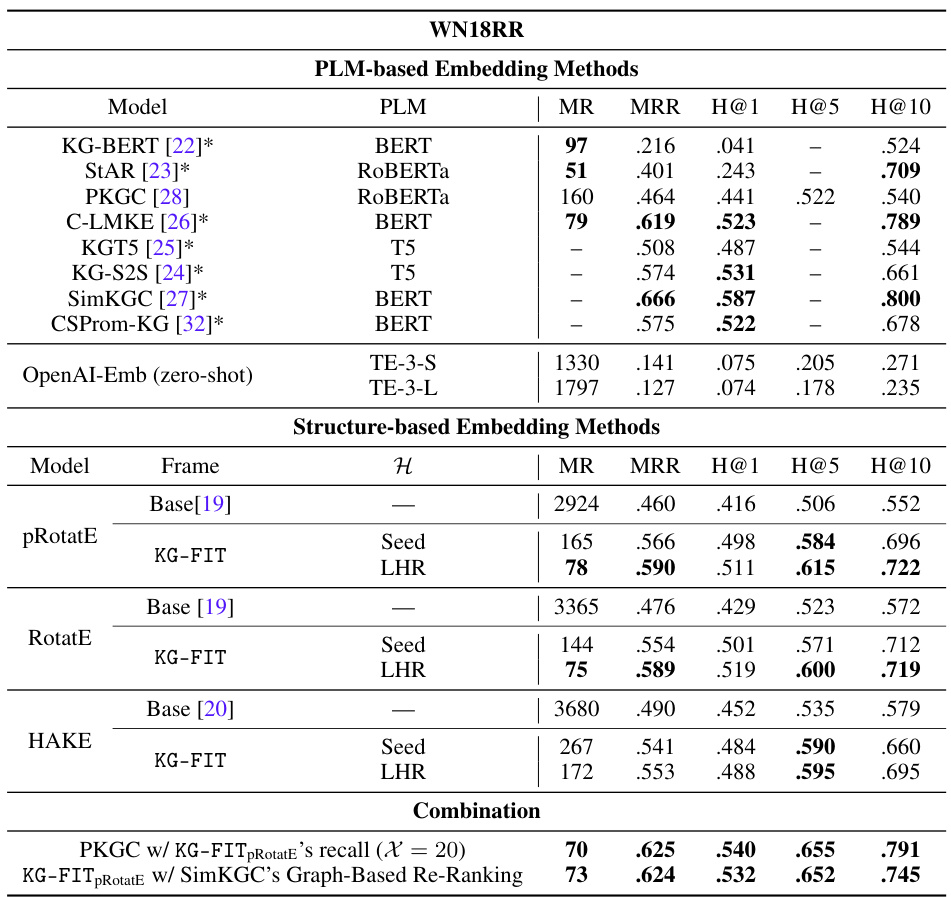
This table presents a comparison of link prediction performance among various knowledge graph embedding (KGE) methods. It compares KG-FIT against state-of-the-art PLM-based and structure-based methods on three benchmark datasets (FB15K-237, YAGO3-10, PrimeKG). The results, averaged over multiple runs, are reported using Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N) metrics for both head and tail entity predictions. The table highlights KG-FIT’s superior performance, demonstrating the effectiveness of integrating open-world knowledge from LLMs to improve KG embeddings.

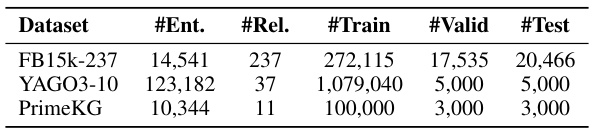
This table presents the statistics of the WN18RR dataset, including the number of entities, relations, and triples in the training, validation, and testing sets. It provides a summary of the dataset’s size and composition, which is important context for understanding the experimental results presented in the paper.

This table presents a comparison of link prediction performance across different knowledge graph embedding (KGE) methods. It compares KG-FIT against state-of-the-art PLM-based (pre-trained language model-based) and structure-based KGE methods on three benchmark datasets: FB15k-237, YAGO3-10, and PrimeKG. The results are averaged over multiple runs and show the performance for both head and tail entity prediction using Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (where N is 1, 5, and 10). KG-FIT consistently achieves better results than the baselines, highlighting its ability to leverage open-world knowledge from LLMs to improve KG embeddings.
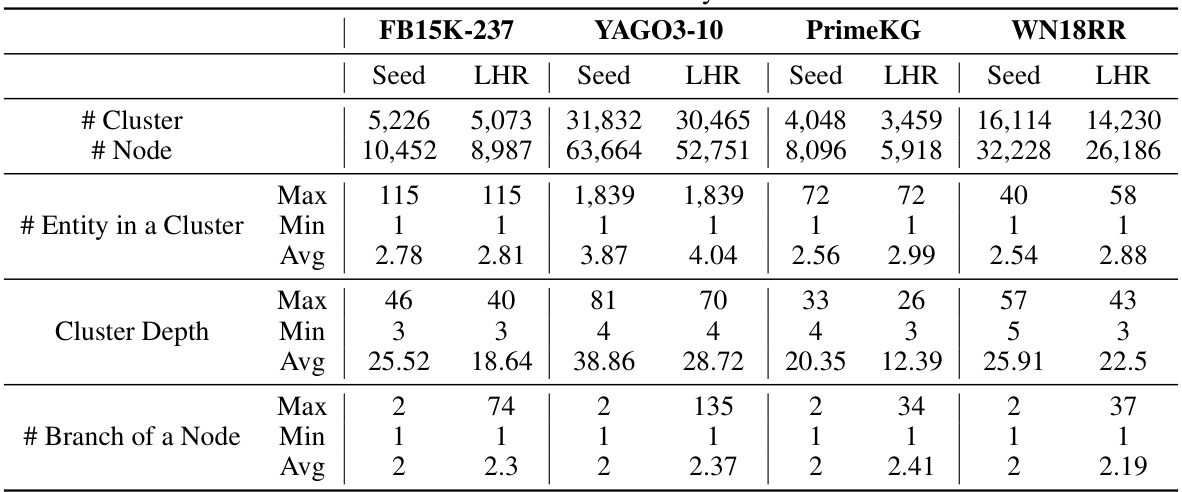
This table presents statistics on the hierarchies created by the KG-FIT model for four different knowledge graph datasets: FB15K-237, YAGO3-10, PrimeKG, and WN18RR. It compares the seed hierarchy (before LLM refinement) with the LLM-guided refined hierarchy (after refinement) to show the changes and improvements after applying the LLM-guided refinement process. The statistics include the number of clusters, the number of nodes, the maximum, minimum, and average number of entities within each cluster, the maximum, minimum, and average depth of the hierarchy, and the maximum, minimum, and average number of branches per node. The data reveals the effect of the LLM refinement process on the structure and organization of the hierarchies, providing insights into its effectiveness in enhancing the quality of the knowledge graph embeddings.

This table presents a comparison of link prediction performance between KG-FIT and various baseline methods (PLM-based and structure-based) across three benchmark datasets: FB15K-237, YAGO3-10, and PrimeKG. The results, averaged over multiple runs, show KG-FIT achieving superior performance in terms of Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N) metrics for all datasets. The table highlights KG-FIT’s improvement over both PLM-based and structure-based methods, demonstrating the effectiveness of integrating open-world knowledge from LLMs.

This table presents a comparison of link prediction performance between KG-FIT and several baseline models (both PLM-based and structure-based) across three benchmark datasets (FB15K-237, YAGO3-10, PrimeKG). The results, averaged over multiple runs, are reported for three key metrics: Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (for N=1, 5, 10). The table highlights KG-FIT’s superior performance, demonstrating the effectiveness of incorporating open-world knowledge from LLMs to improve KG embedding models.

This table presents a comparison of link prediction performance across several state-of-the-art knowledge graph embedding models, including both PLM-based and structure-based methods. The results are averaged over multiple runs for each method and dataset, using metrics such as Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N). The table highlights the superior performance of the proposed KG-FIT model compared to existing methods. KG-FIT consistently outperforms baseline methods in all metrics across three benchmark datasets (FB15k-237, YAGO3-10, PrimeKG).

This table presents a comparison of link prediction performance across several datasets (FB15K-237, YAGO3-10, PrimeKG) using various methods. The methods compared include both PLM-based (e.g., KG-BERT, StAR, PKGC) and structure-based (TransE, DistMult, ComplEx, etc.) knowledge graph embedding techniques. The table shows the Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N) metrics for each method and dataset, highlighting KG-FIT’s superior performance. The results illustrate the improvement achieved by KG-FIT, which integrates knowledge from LLMs to enhance KG embeddings, over both structure-based and existing PLM-based methods.

This table presents a comparison of link prediction performance across different KG embedding methods. It shows the Mean Rank (MR), Mean Reciprocal Rank (MRR), and Hits@N (H@N) metrics for three benchmark datasets (FB15k-237, YAGO3-10, and PrimeKG). The methods are categorized into PLM-based and structure-based methods, with KG-FIT being compared against both. The results show that KG-FIT consistently outperforms all baselines across all metrics and datasets, demonstrating its effectiveness at integrating open-world knowledge from LLMs to improve KG embedding.
This table presents a comparison of link prediction performance across various methods on three benchmark datasets (FB15k-237, YAGO3-10, PrimeKG). It compares KG-FIT against state-of-the-art PLM-based methods (KG-BERT, StAR, PKGC, etc.) and structure-based methods (TransE, DistMult, ComplEx, etc.). The results are averaged across multiple runs, and the top three results for Mean Rank (MR), Mean Reciprocal Rank (MRR), Hits@1, Hits@5, and Hits@10 are highlighted. The table shows KG-FIT consistently outperforms the other methods, demonstrating its effectiveness in integrating open-world knowledge from LLMs into KG embeddings.

This table presents a comparison of link prediction performance between KG-FIT and various baseline methods (PLM-based and structure-based) across three benchmark datasets (FB15K-237, YAGO3-10, and PrimeKG). The results show KG-FIT consistently outperforms all baseline models across multiple metrics (Mean Rank, Mean Reciprocal Rank, Hits@1, Hits@5, Hits@10), highlighting the effectiveness of incorporating open-world knowledge from LLMs to improve KG embeddings.
Full paper#