↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are increasingly used in decision support systems, raising concerns about their behavior aligning with human norms and ethical expectations. This paper addresses this critical gap by investigating whether LLMs’ decision-making processes exhibit biases similar to those observed in humans. Existing research on LLM rationality and social behavior is limited and lacks a comprehensive framework to assess internal decision-making tendencies.
The paper proposes a novel framework grounded in behavioral economics theories to evaluate LLM decision-making behaviors across three dimensions: risk preference, probability weighting, and loss aversion. It uses a multiple-choice-list experiment to evaluate three commercial LLMs (ChatGPT-4.0-Turbo, Claude-3-Opus, and Gemini-1.0-pro) in context-free settings and with embedded socio-demographic features. The results show that LLMs generally exhibit patterns similar to humans but with significant variations and biases influenced by demographic factors. This work underscores the need for careful consideration of ethical implications and potential biases when deploying LLMs in decision-making scenarios.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with LLMs in decision-making contexts. It provides a much-needed framework for evaluating LLM decision-making behaviors, highlighting potential biases and ethical concerns. This opens avenues for developing standards and guidelines to ensure responsible LLM deployment and promotes fairer, more ethical AI.
Visual Insights#

This figure visually represents the three key parameters of the TCN model used in the paper to evaluate LLMs’ decision-making behavior under uncertainty. The parameters are: σ (Risk Preference), α (Probability Weighting), and λ (Loss Aversion). Each parameter is shown on a separate gradient bar, illustrating how different values of each parameter correspond to different decision-making tendencies (risk-averse, risk-neutral, risk-seeking; underweighting, no distortion, overweighting; more sensitive to loss, neutral, more sensitive to gain).
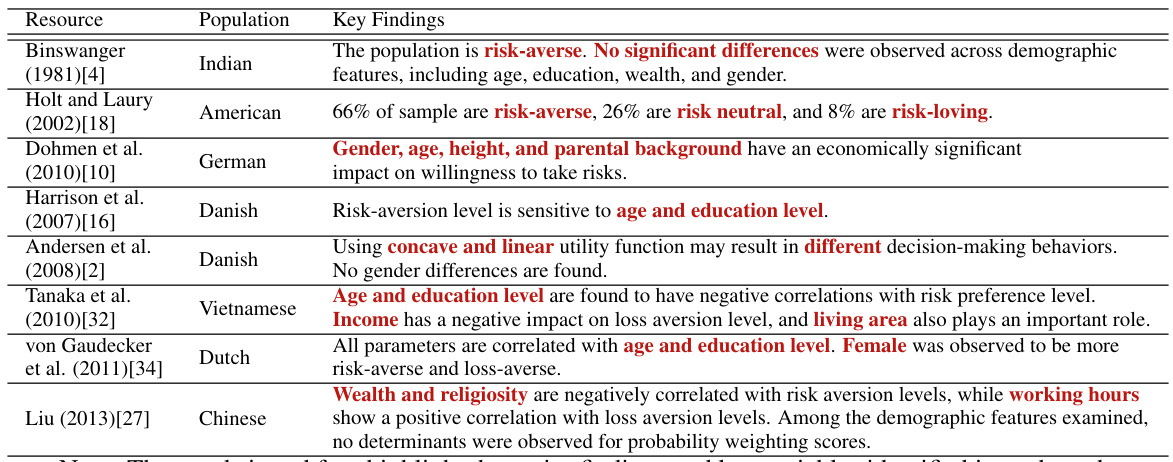
This table summarizes the key findings of several studies that have investigated decision-making behavior in humans, focusing on risk preference, probability weighting, and loss aversion. The studies analyzed diverse populations and used various methodologies. The findings highlight the influence of demographic and socioeconomic factors on risk attitudes and the complexities of human decision-making under uncertainty.
In-depth insights#
LLM Decision Making#
The study of LLM decision-making is a nascent but crucial area of research. Current work highlights that LLMs, while exhibiting seemingly rational behavior in certain tasks, deviate significantly from human decision-making processes under uncertainty. LLMs demonstrate tendencies towards risk aversion and loss aversion, mirroring some human traits, but also display significant variations in probability weighting and sensitivity to contextual factors, such as demographic information. This suggests that LLMs’ internal decision mechanisms are complex and not fully understood. The presence of biases and inconsistencies across different LLMs and across various demographic contexts raises important ethical considerations for deployment in real-world decision support systems. Future research should focus on developing more robust and standardized evaluation frameworks, investigating the root causes of these biases, and establishing guidelines for ensuring fairness and ethical considerations in LLM-driven decision-making. Transparency and explainability of LLM decision processes remain critical challenges that need to be addressed to fully realize the potential of LLMs in decision support.
Behavioral Framework#
A behavioral framework for evaluating LLMs’ decision-making processes under uncertainty is crucial. It should ground the evaluation in established behavioral economics theories, such as prospect theory, to analyze risk preferences, probability weighting, and loss aversion. The framework must move beyond simply comparing LLM outputs to human averages and instead should focus on underlying decision-making mechanisms. This includes exploring how these mechanisms respond to variations in contextual information, including socio-demographic features. A robust framework would quantify the degree to which LLMs exhibit biases and deviations from human norms, and critically examine how these behaviors affect fairness and ethical implications in decision support systems. Furthermore, such a framework could provide a basis for developing standards and guidelines for the ethical development and deployment of LLMs to ensure responsible use in real-world applications. It is vital that the framework enable reproducible and verifiable evaluations, with clear methodological descriptions and accessible data.
LLM Bias & Ethics#
LLMs, while powerful, inherit biases present in their training data, leading to ethical concerns. Bias can manifest in various ways, such as gender, racial, or socioeconomic biases, impacting the fairness and equity of LLM outputs. This necessitates careful consideration of ethical implications when deploying LLMs, especially in decision-making contexts. Mitigation strategies are crucial, including bias detection and mitigation techniques during training, as well as ongoing monitoring and evaluation to identify and address emerging biases. Transparency and accountability are also vital, enabling users to understand the potential limitations and biases of the systems they employ. Ultimately, responsible LLM development and deployment require a proactive approach to ethical considerations, fostering fairness, and minimizing harm.
Demographic Effects#
Analyzing the influence of demographics on Large Language Model (LLM) decision-making reveals significant disparities across various groups. The study reveals that embedding socio-demographic features, such as age, gender, sexual orientation, and disability, into LLM decision processes leads to noticeable shifts in risk preference, probability weighting, and loss aversion. For instance, some LLMs demonstrate increased risk aversion when presented with attributes of individuals from minority groups, suggesting potential biases in the models. These findings highlight the critical need for researchers and developers to consider the ethical implications and potential biases of LLMs in diverse contexts. Fairness and equity are paramount concerns that require careful attention during model development and deployment. Further research is needed to mitigate these biases and ensure that LLMs operate ethically and equitably across all populations.
Future Research#
Future research directions stemming from this paper could explore more sophisticated models of human decision-making under uncertainty, moving beyond the simplified TCN model. This includes investigating the influence of cognitive biases, emotional factors, and social context on LLM choices. A crucial area is developing robust methods for detecting and mitigating biases within LLMs, particularly those stemming from demographic features. Further research should assess the generalizability of findings across different LLM architectures and datasets. Finally, a deeper exploration into the ethical implications of deploying LLMs in high-stakes decision-making scenarios is needed, focusing on fairness, accountability, and transparency.
More visual insights#
More on figures
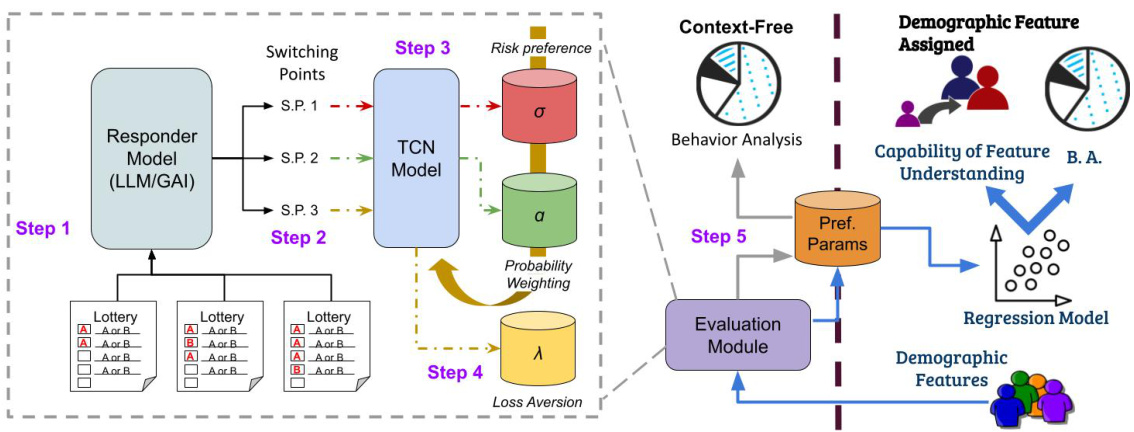
This figure illustrates the framework used to evaluate LLMs’ decision-making behavior. It shows a step-by-step process, starting with experimentation using multiple-choice lottery games to elicit preferences from the LLMs. These preferences are then analyzed using the TCN model to estimate risk preference, probability weighting, and loss aversion. The framework also incorporates the embedding of socio-demographic features to explore how these factors influence LLM decision-making. The process culminates in a behavior analysis and assessment of the LLM’s capability to understand and respond to those features.

This figure shows the comparison of the three LLMs’ decision-making behavior under uncertainty in a context-free setting. It presents the mean and standard deviation of three key parameters derived from the Tanaka, Camerer, and Nguyen model (TCN): risk preference (σ), probability weighting (α), and loss aversion (λ). The figure helps visualize the differences in risk attitude, how probabilities are perceived, and the sensitivity to gains versus losses between ChatGPT, Claude, and Gemini.

This figure compares the average values of the three decision-making behavior parameters (risk preference (σ), probability weighting (α), and loss aversion (λ)) across three LLMs (ChatGPT, Claude, and Gemini) under three different experimental contexts: context-free, random demographic feature assignment, and real-world demographic distribution. The error bars represent the standard deviations. The figure shows how the LLMs’ behavior varies depending on whether they are given any demographic information and the type of demographic distribution used.

This figure displays the average values of the three key decision-making parameters (risk preference (σ), probability weighting (α), and loss aversion (λ)) for three different LLMs (ChatGPT, Claude, and Gemini). The results are shown for three experimental contexts: context-free (no demographic information), random demographic assignments, and real-world demographic distributions. The figure highlights how the decision-making parameters of each LLM vary across the different contexts, showing the impact of adding demographic information on model behavior. The use of mean +/- standard deviation indicates variability in results across multiple trials.

This figure compares the results of three different experimental settings (context-free, random demographic assignment, and real-world demographic distribution) across three LLMs (ChatGPT, Claude, and Gemini). Each bar represents the mean value of three parameters (Risk Preference (σ), Probability Weighting (α), and Loss Aversion (λ)) with error bars showing standard deviations, providing a visual representation of how the LLMs’ decision-making behaviors vary across these experimental contexts. The figure shows the extent to which the LLMs’ behavior is affected by the presence and type of demographic information provided.

This figure displays the influence of advanced demographic features (sexual orientation, disability, ethnicity, religion, and political affiliation) on the decision-making parameters (risk preference, probability weighting, and loss aversion) of three LLMs: ChatGPT-4.0-Turbo, Claude-3-Opus, and Gemini-1.0-pro. Each bar represents the average parameter value for a specific demographic group, with error bars indicating statistical significance. The asterisks denote the significance level ( * for p < 0.05, ** for p < 0.01, and *** for p < 0.001). The figure highlights the varying degrees to which different LLMs exhibit sensitivity to specific demographic characteristics and the distinct patterns of behaviour observed across different models.
More on tables

This table lists the ten socio-demographic groups used in the study to investigate how embedding demographic features influences LLM decision-making. These groups are categorized into foundational features (sex, education level, marital status, living area, age) and advanced features (sexual orientation, disability, race, religion, political affiliation). The combination of these features creates diverse personas for testing.

This table summarizes the main findings from the LLMs’ responses regarding the impact of foundational demographic features (age, gender, education level, marital status, and living area) on three key decision-making parameters: risk preference, probability weighting, and loss aversion. It highlights key observations about how these features influence the LLMs’ behavior in context-free and embedded settings.

This table summarizes the main findings from the LLMs’ responses when embedding advanced demographic features. It shows how different LLMs exhibit varying sensitivities to different demographic groups across three key parameters: risk preference (σ), probability weighting (α), and loss aversion (λ). For instance, Claude shows a notable sensitivity to sexual orientation, while ChatGPT demonstrates sensitivity to disability in terms of probability weighting. The table also highlights differences in how LLMs respond to ethnicity, religious background, and political affiliation.

This table presents a summary of the key parameters (risk preference (σ), probability weighting (α), and loss aversion (λ)) obtained from the context-free experiments for three LLMs (ChatGPT-4.0-Turbo, Claude-3-Opus, Gemini-1.0-pro) and a human sample. It shows the mean, standard deviation, minimum, and maximum values for each parameter across the different models and the human baseline. This allows for a direct comparison of the decision-making characteristics between LLMs and humans in a context-free setting, highlighting differences and similarities in risk preferences, probability weighting, and loss aversion.

This table presents a comparison of the risk preference (σ), probability weighting (α), and loss aversion (λ) parameters across three LLMs (ChatGPT-4-Turbo, Claude-3-Opus, Gemini-1.0-pro) under different experimental conditions. The first column shows results from context-free experiments, the second column from experiments with randomly assigned demographic features, and the third column with features distributed according to real-world demographics. This allows for an assessment of how the LLMs’ risk-related decision-making behaviors vary in different contexts and with the introduction of demographic factors.

This table presents the results of risk preference (σ), probability weighting (α), and loss aversion (λ) parameters for three LLMs (ChatGPT-4-Turbo, Claude-3-Opus, Gemini-1.0-pro) under three different experimental conditions: context-free, random demographic feature assignment, and real-world demographic distribution. The table allows for a comparison of the LLMs’ decision-making behaviors across various demographic contexts. The statistical significance of the differences is implied by the values presented.

This table presents the mean and standard deviation of the three decision-making parameters (risk preference (σ), probability weighting (α), and loss aversion (λ)) for three different LLMs (ChatGPT, Claude, and Gemini) under three experimental conditions: context-free, random demographic feature assignment, and real-world demographic distribution. It shows how the embedding of demographic features influences the LLMs’ decision-making behaviors compared to a context-free setting.
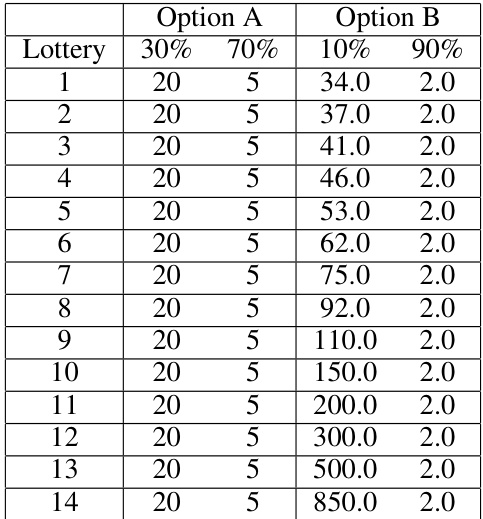
This table presents the first series of multiple choice questions used in the study to evaluate the risk preferences of LLMs. Each row represents a lottery with two options (A and B). Option A offers a 30% chance of winning a certain amount, and a 70% chance of winning a smaller amount. Option B offers a 10% chance of winning a larger amount and a 90% chance of winning a very small amount. The table shows the payoff amounts for each option in each lottery.
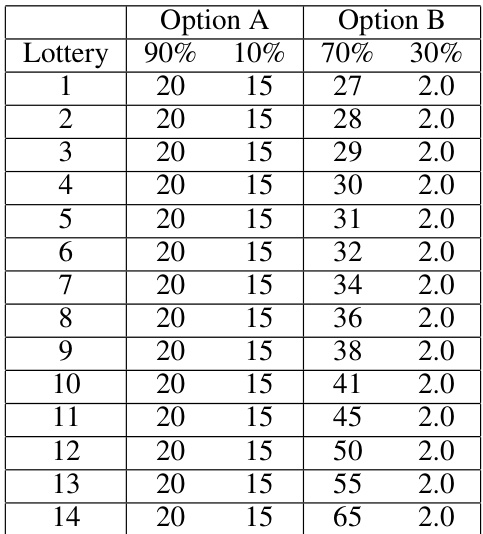
This table presents the second series of multiple-choice lottery experiments used in the study. Each row represents a lottery choice with two options (A and B). Option A offers a 90% chance of winning a smaller amount and a 10% chance of winning nothing. Option B provides a 70% chance of winning a slightly larger amount and a 30% chance of winning nothing. The varying payout amounts across the rows are designed to elicit participants’ risk preferences and probability weighting tendencies.

This table presents the seventh series of multiple-choice lists used in the study to evaluate loss aversion in LLMs. Each row represents a lottery with two options, A and B, each having a 50% chance of occurring. Option A offers a smaller win and a larger potential loss than option B, while option B offers a larger win and a smaller potential loss. The goal is to assess how LLMs choose between different options considering both the gains and losses involved.

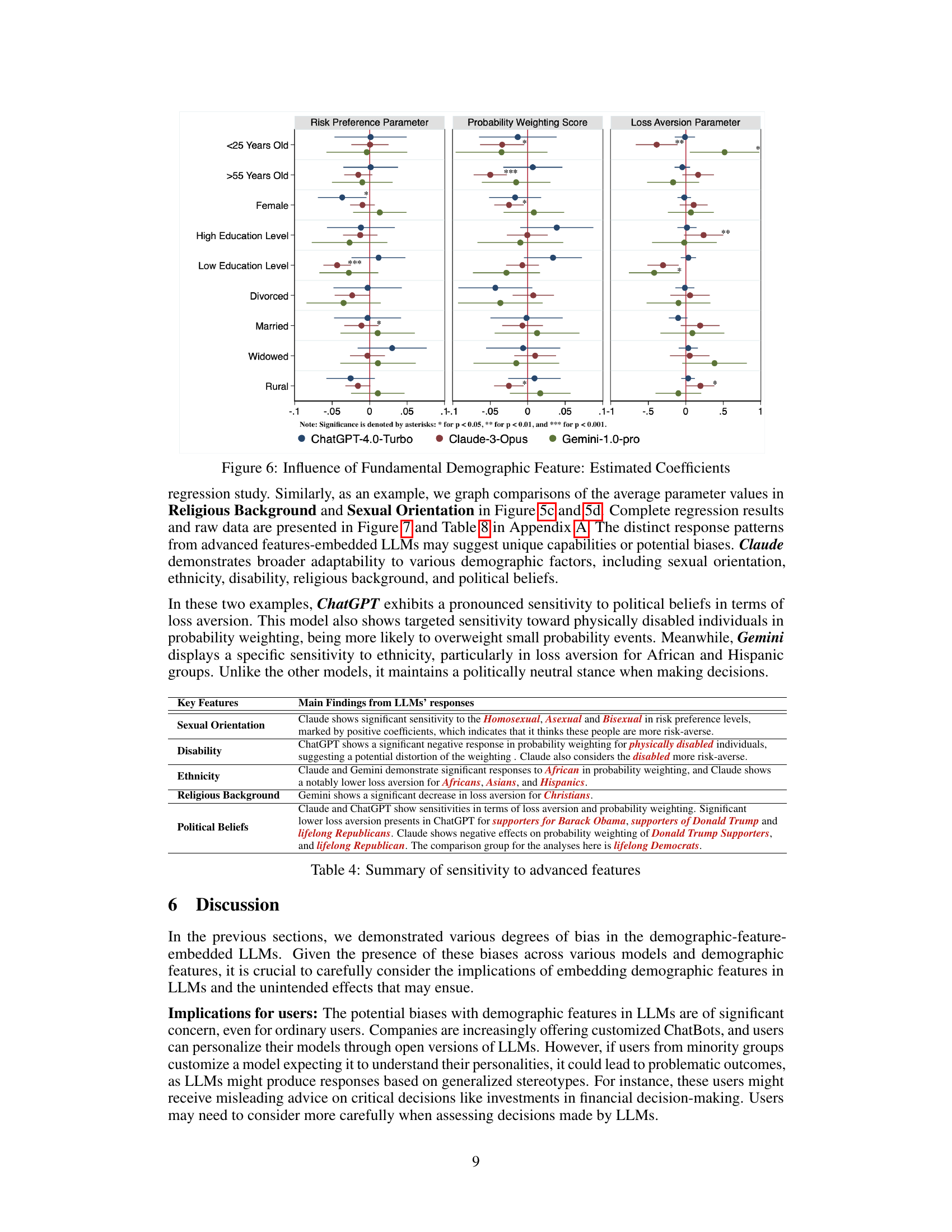
This table summarizes the main findings regarding how foundational demographic features (age, gender, education, marital status, and living area) influence the three key parameters (risk preference, probability weighting, and loss aversion) of the LLMs. For each feature, it notes the impact on the specific LLM(s) that shows significant changes in model parameters. It highlights key trends such as how younger individuals or females may affect parameter estimation differently for certain LLMs.

This table summarizes the main findings from the LLMs’ responses concerning the influence of foundational demographic features (age, gender, education level, marital status, and living area) on the decision-making parameters (risk preference, probability weighting, and loss aversion). It highlights key patterns observed across different LLMs (ChatGPT, Claude, and Gemini) and age groups, showing variations in risk-taking behaviors and sensitivity to loss. For example, younger individuals (<25 years) show different patterns of probability weighting compared to older individuals. The table provides insights into how different LLMs respond to socio-demographic factors.

This table summarizes the main findings from the LLMs’ responses when embedding foundational demographic features. It shows the impact of age (younger vs. older individuals), gender, education level, and living area on the three key decision-making parameters (risk preference, probability weighting, and loss aversion) for each of the three LLMs (ChatGPT, Claude, and Gemini). The table highlights which demographic features significantly affected which parameters and LLM, indicating sensitivity and potential biases in each model’s decision-making processes.
Full paper#