↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Diffusion models generate data by reversing a noise-adding process. However, current methods suffer from slow sampling, especially parallel methods which struggle in regions far from the training data distribution. This results in poor sample quality and reduced efficiency.
The proposed Contrastive Diffusion Loss (CDL) addresses this by improving the denoiser’s performance in out-of-distribution regions. CDL leverages the inherent connection between optimal denoisers and noise classifiers in diffusion models, providing additional training signal and significantly improving the performance of both sequential and parallel samplers. Experiments confirm that CDL enhances both the speed and quality of sample generation.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a previously unknown connection between diffusion models and noise classification, leading to a novel training method that significantly improves both the speed and quality of sample generation. It addresses a critical limitation in parallel sampling methods and opens up new avenues for optimizing diffusion models’ performance.
Visual Insights#
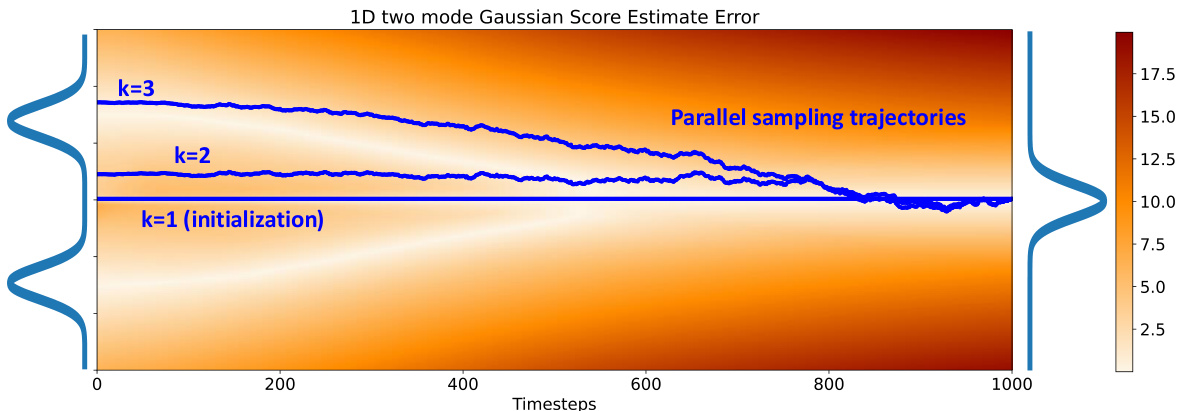
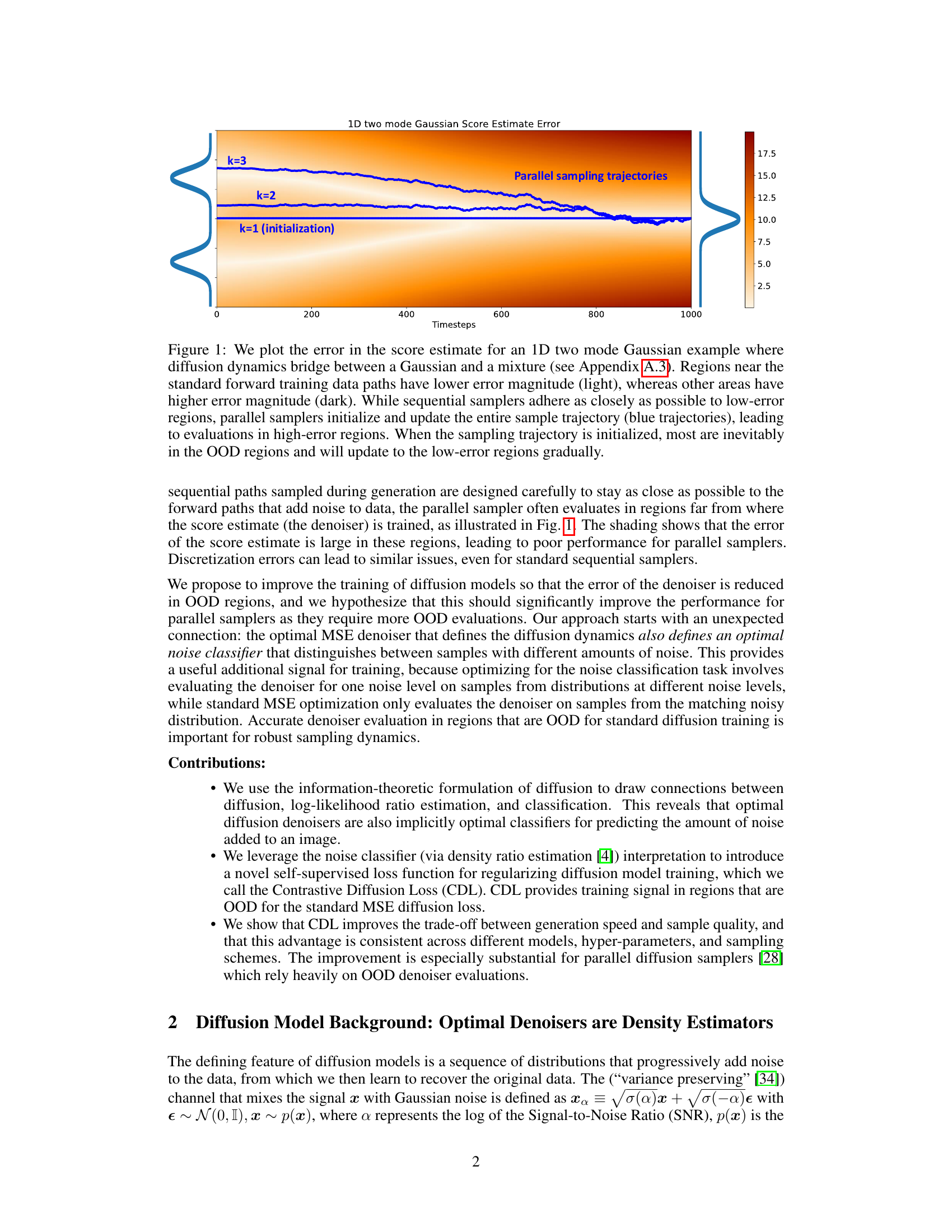
This figure shows the error in score estimation during the sampling process in a 1D two-mode Gaussian model. The heatmap represents the error magnitude across different regions of the sample space, with lighter colors indicating lower error and darker colors indicating higher error. Sequential sampling methods tend to stay in low-error areas, while parallel methods often start in high-error regions (OOD), gradually moving towards the low-error areas. This difference is a key factor in the performance gap between sequential and parallel samplers.
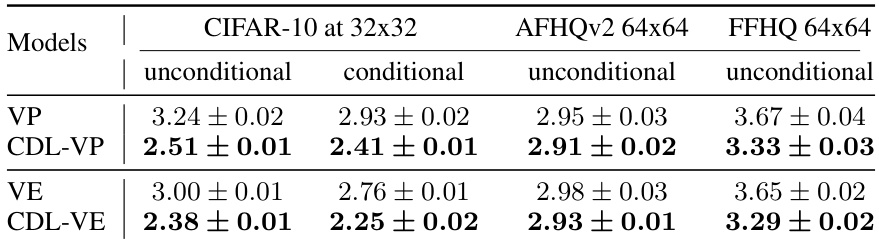
This table shows the FID scores (Frechet Inception Distance) for different models trained on various real-world image datasets, using the parallel DDPM sampler. Lower FID scores indicate better image generation quality. The results are averaged over three runs with different random seeds to account for variability.
In-depth insights#
Contrastive Diffusion#
Contrastive diffusion methods represent a novel approach to training diffusion models, improving their robustness and efficiency. By contrasting samples with varying noise levels, these methods enhance the model’s ability to accurately estimate the score function, even in regions far from the training distribution. This leads to superior sampling performance in sequential and parallel settings. The core idea is that optimal denoisers implicitly act as noise classifiers, an insight leveraged to develop novel loss functions. Contrastive training regularizes the model, effectively reducing errors in out-of-distribution regions crucial for parallel sampling. However, the added computational cost of contrastive loss is a notable limitation. Despite this, the benefits of improved sample quality and faster convergence during training suggest contrastive diffusion as a promising direction for advancing diffusion model technology.
OOD Denoising#
The concept of “OOD Denoising” in diffusion models addresses the challenge of effective denoising in regions outside the model’s training distribution. Poor denoising performance in these Out-of-Distribution (OOD) regions significantly impacts sample quality, especially in parallel sampling methods where the entire trajectory may frequently traverse such areas. The core problem is the inadequate estimation of the denoiser in OOD areas, which leads to compounding errors during the denoising process. Addressing this requires strategies that improve OOD denoiser estimation. This might involve techniques that explicitly model or learn the behavior of the denoiser in OOD regions, or using alternative training objectives that encourage robust generalization beyond the training data. Contrastive learning methods, for example, show promise by providing a self-supervised signal for improving OOD generalization by encouraging the model to differentiate between samples at various noise levels, implicitly improving the denoiser’s performance far from the training manifold. Ultimately, effective OOD denoising is critical for high-quality and efficient sample generation from diffusion models.
Parallel Sampling#
The section on ‘Parallel Sampling’ presents a crucial advancement in diffusion models by addressing the computational bottleneck of sequential sampling. Parallel sampling drastically reduces the wall-clock time required for generating samples by simultaneously updating all steps in the reverse diffusion process. This is achieved through the method of Picard iteration, a fixed-point iterative approach that updates the entire trajectory at once. However, parallel sampling introduces a new challenge: the denoiser’s performance in regions outside of the training distribution (OOD). Unlike sequential sampling, which carefully navigates low-error regions, parallel methods may initialize and update in high-error OOD regions, degrading sample quality. This highlights a critical weakness of solely relying on MSE loss in training diffusion models, as the resulting denoisers might lack robustness in OOD regions. This necessitates a novel training objective such as the Contrastive Diffusion Loss (CDL), that enhances OOD performance and improves the efficiency and sample quality of parallel samplers.
CDL Advantages#
Contrastive Diffusion Loss (CDL) offers several key advantages in training diffusion models. Improved sample quality is achieved because CDL reduces denoiser errors in out-of-distribution (OOD) regions, crucial for parallel samplers that extensively traverse these areas. This leads to faster convergence in parallel sampling, as demonstrated by reduced Picard iterations and faster wall-clock times. Furthermore, CDL enhances the trade-off between sample quality and generation speed in sequential sampling settings. By providing a more robust denoiser, CDL mitigates discretization errors common in sequential methods and allows for fewer sampling steps without compromising quality. Enhanced density estimation is another benefit, resulting in more accurate modeling of the data distribution, particularly in complex, low-dimensional manifolds. Overall, CDL acts as a powerful regularizer, improving diffusion model performance and efficiency across diverse sampling schemes and datasets, making it a valuable tool for advancing diffusion model research.
Future Works#
Future work could explore several promising avenues. Extending the Contrastive Diffusion Loss (CDL) to other generative models beyond diffusion models would be valuable, assessing its impact on diverse architectures and tasks. Investigating the theoretical underpinnings of CDL’s effectiveness, particularly its connection to density estimation and out-of-distribution generalization, is crucial. Empirical studies should focus on scaling CDL to larger datasets and higher resolutions, examining its performance and computational cost in those scenarios. Further research could delve into the interaction between CDL and different sampling techniques, seeking to optimize the synergy between training objectives and inference methods for improved efficiency and quality. Finally, a thorough investigation of CDL’s robustness to hyperparameter choices is needed, developing strategies for optimal selection and preventing overfitting.
More visual insights#
More on figures
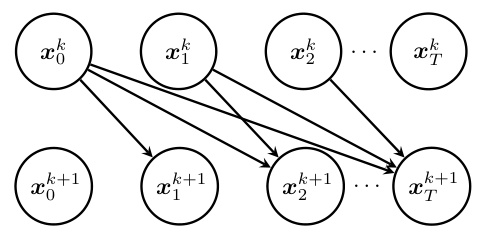
This figure illustrates the computation graph of Picard iteration for parallel sampling. In parallel sampling, the entire reverse process path is randomly initialized, and then all steps in the path are updated in parallel. This is done using Picard iteration, a method for solving ordinary differential equations (ODEs) through fixed-point iteration. The figure shows how each step xk+1 in the path depends on the previous step xk and the drift function s(x, t). The parallel nature of the update is evident in the figure, with each node representing a point in the path at a specific timestep and the arrows showing the dependencies between steps.
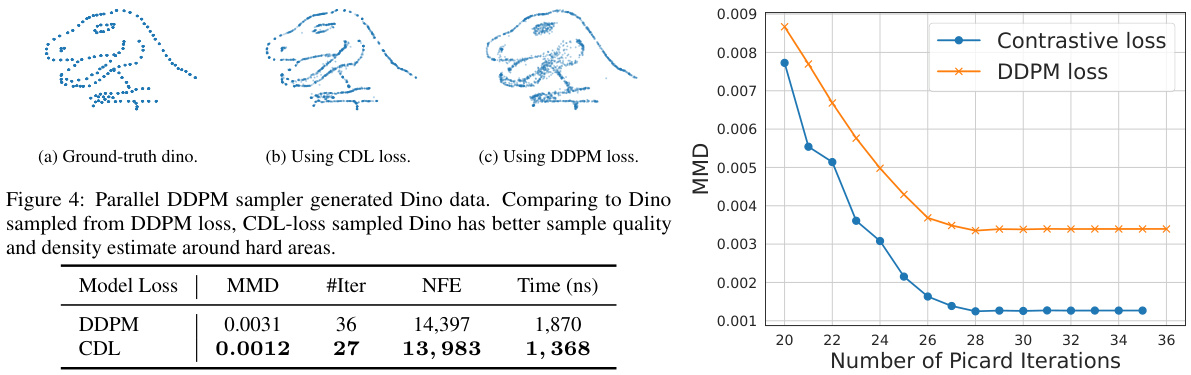
This figure compares the results of using the Contrastive Diffusion Loss (CDL) versus the standard DDPM loss in a parallel DDPM sampler to generate Dino data (a 2D synthetic dataset). The leftmost panel (a) shows the ground truth Dino data. The middle panel (b) displays Dino samples generated using the CDL, showing a higher quality, denser representation, especially in the more complex areas. The rightmost panel (c) shows samples generated with DDPM loss. The table below shows quantitative results that support the visual comparison, highlighting the CDL’s improved MMD score (a measure of the similarity of generated samples to the ground truth), fewer Picard iterations to convergence, and reduced time and sampling cost.
This figure compares the error in score estimation between sequential and parallel sampling methods in a 1D two-mode Gaussian mixture. The shading represents the error magnitude, showing that sequential samplers stay close to low-error regions, while parallel samplers often venture into high-error OOD regions due to their initializations across the whole trajectory. This highlights the challenge that parallel sampling faces in regions where the denoiser is less accurate.
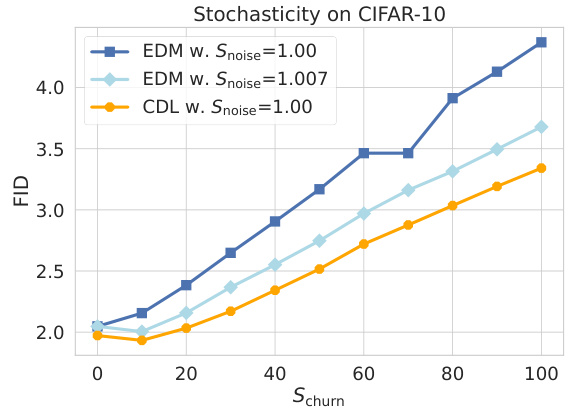
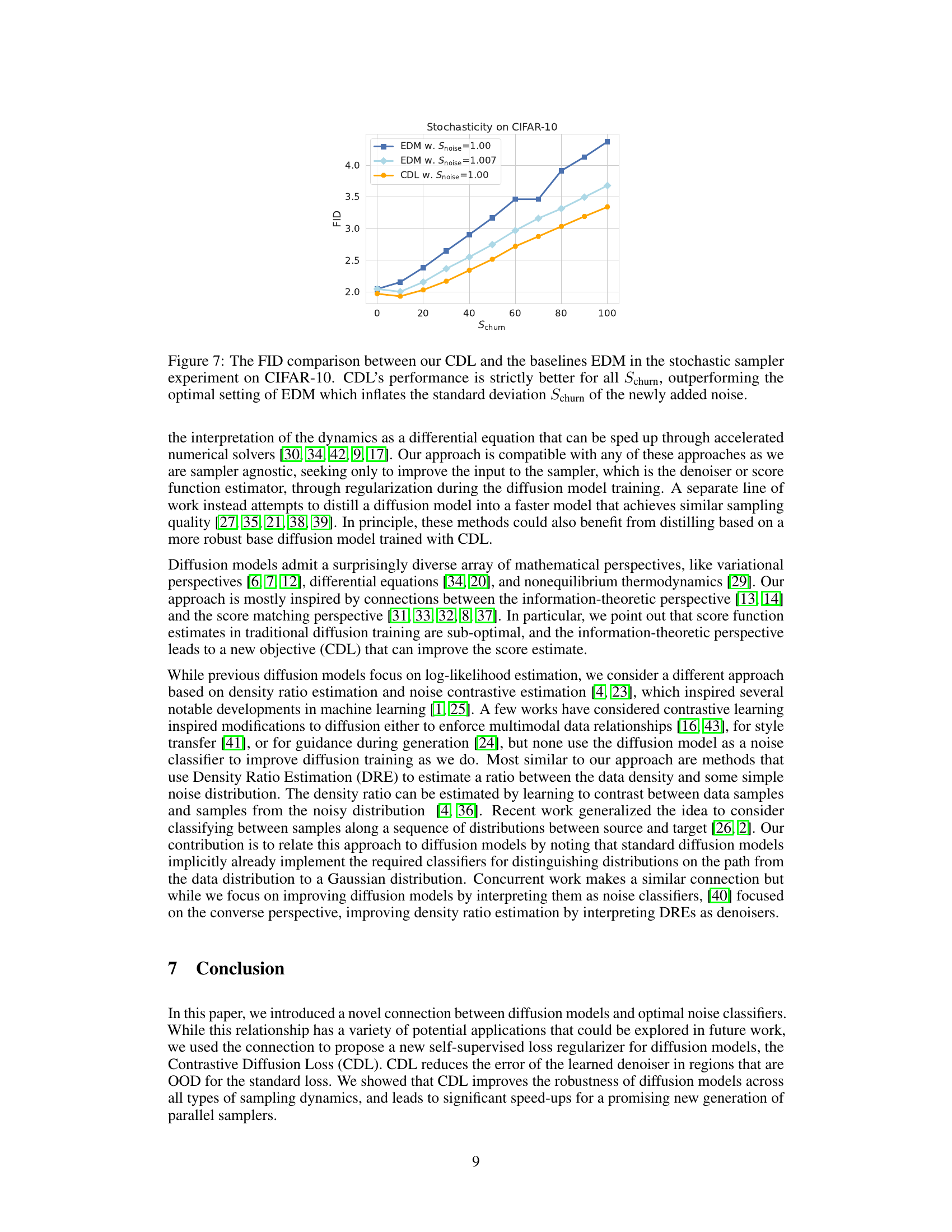
This figure compares the Frechet Inception Distance (FID) scores of three different models on the CIFAR-10 dataset. The models are EDM with Snoise = 1.00, EDM with Snoise = 1.007, and CDL with Snoise = 1.00. The x-axis represents the Schurn parameter, which controls the amount of stochasticity in the sampling process. The y-axis represents the FID score, which measures the quality of the generated samples. The figure shows that CDL consistently outperforms EDM across all values of Schurn, even when EDM uses the optimal setting (Snoise = 1.007). This demonstrates that CDL is more robust to variations in sampling strategy than EDM.
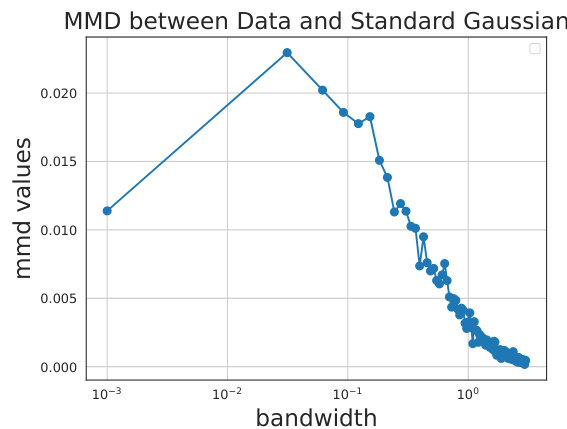
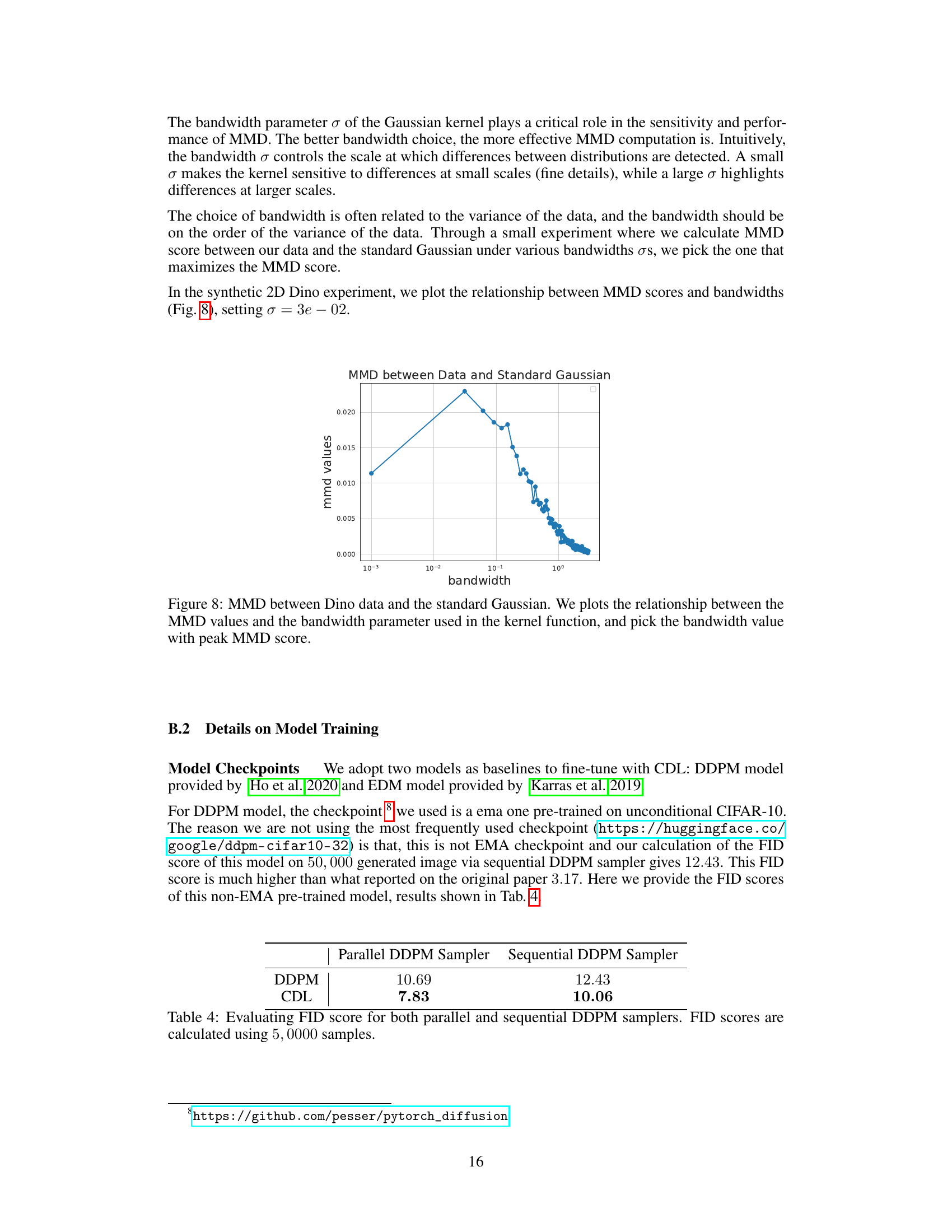
This figure shows the relationship between the Maximum Mean Discrepancy (MMD) values and the bandwidth parameter of the Gaussian kernel used to compute the MMD. The MMD is a statistical test used to determine if two distributions are different. In this case, the two distributions are the Dino dataset and a standard Gaussian. The plot shows that the MMD score is maximized at a specific bandwidth, indicating that this is the optimal bandwidth for distinguishing between these two distributions.

This figure displays sample images generated from a Conditional CIFAR-10 dataset using a parallel DDPM sampler. The model used was fine-tuned with the Contrastive Diffusion Loss (CDL). The images showcase the quality of samples produced by the model after training with CDL, highlighting the effectiveness of the proposed method in generating high-quality samples in a parallel setting.

This figure shows samples generated from a Conditional CIFAR-10 dataset using the parallel DDPM sampler and a model fine-tuned with the Contrastive Diffusion Loss (CDL). The CDL is a novel self-supervised loss function designed to improve the model’s performance, particularly in regions outside of the standard training distribution (OOD). The use of CDL aims to enhance the quality and speed of the generated samples. The image showcases a grid of diverse images generated by the model, reflecting its ability to create realistic and varied samples from the specified dataset.

This figure shows samples generated from an unconditional AFHQ dataset using a parallel DDPM sampler and the CDL loss. The CDL loss is a contrastive diffusion loss that improves the quality of samples generated by diffusion models, particularly in regions outside of the training distribution. The use of the parallel DDPM sampler makes sample generation faster than with traditional sequential methods.

The figure shows the error in score estimation for a 1D two-mode Gaussian example. It highlights that sequential samplers stay in low-error regions while parallel samplers, due to their initialization across the whole trajectory, inevitably sample from high-error, out-of-distribution regions. This illustrates the core challenge of parallel sampling, motivating the need for improved out-of-distribution performance of diffusion models.

This figure shows samples generated by a parallel DDPM sampler using a model fine-tuned with the Contrastive Diffusion Loss (CDL). The model was trained on the CIFAR-10 dataset, and the images demonstrate the improved sample quality and density estimation achieved using the CDL.

This figure shows samples generated from a Conditional CIFAR-10 dataset using the parallel DDPM sampler. The model was fine-tuned using the Contrastive Diffusion Loss (CDL). The image grid visually demonstrates the quality of generated samples after applying CDL for fine-tuning the EDM checkpoint.

This figure shows samples generated from a diffusion model fine-tuned using the Contrastive Diffusion Loss (CDL). The model was trained on the AFHQ dataset (high-quality animal images), and the samples were generated using the parallel DDPM sampler. The CDL aims to improve the model’s performance in regions far from the training data distribution, which is beneficial for parallel sampling methods.

This figure shows samples generated from a Conditional CIFAR-10 dataset using the parallel DDPM sampler and the CDL-loss fine-tuned EDM checkpoint. It visually demonstrates the quality of images produced by the model trained with the Contrastive Diffusion Loss (CDL). The parallel DDPM sampler is a method for generating samples more efficiently compared to the traditional sequential approach.
More on tables
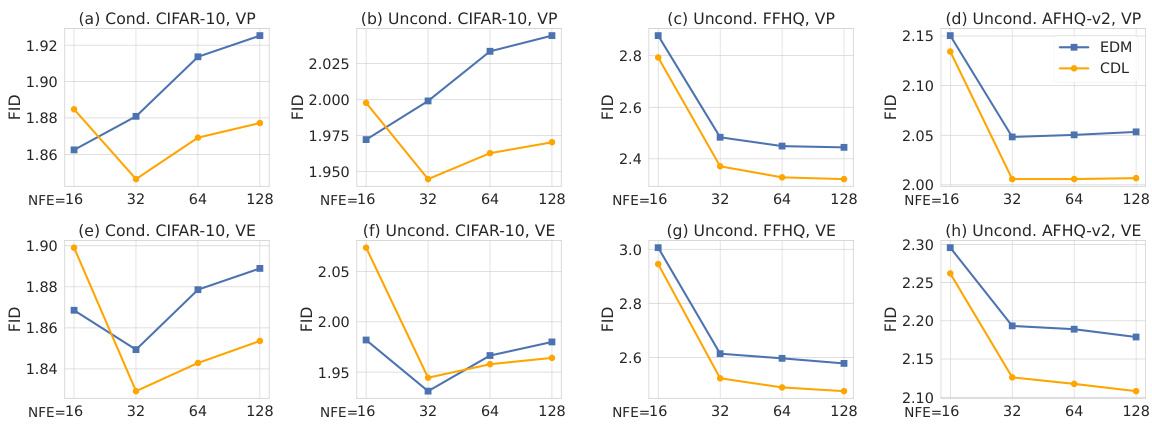
This table presents the FID scores (Frechet Inception Distance, a metric for evaluating the quality of generated images) for sequential deterministic EDM (Energy-based Diffusion Model) samplers. The results are broken down by dataset (CIFAR-10, AFHQv2, FFHQ) and conditioning type (unconditional, conditional). Two models are compared: VP and VE, representing two variations of the EDM architecture, and their CDL-regularized counterparts (CDL-VP, CDL-VE). Lower FID scores indicate better image generation quality. The number of function evaluations (NFEs) required for sampling is also included. The reported FID scores are averages across three runs with different random seeds, along with uncertainty.

This table presents FID (Frechet Inception Distance) scores, a metric for evaluating the quality of generated images, for both parallel and sequential DDPM (Denoising Diffusion Probabilistic Models) samplers. Two models are compared: one trained with the standard DDPM loss and another trained with the proposed Contrastive Diffusion Loss (CDL). Lower FID scores indicate better image quality. The table shows that CDL improves the quality of generated images for both parallel and sequential samplers.

This table lists the hyperparameters used for fine-tuning different pre-trained models on various datasets. The hyperparameters shown include the training duration, batch size, learning rate, channel resampling parameters (cres), dropout rate, and data augmentation parameters (augment). Different datasets (CIFAR-10, AFHQ-64, and FFHQ-64) required different hyperparameter settings for optimal performance.
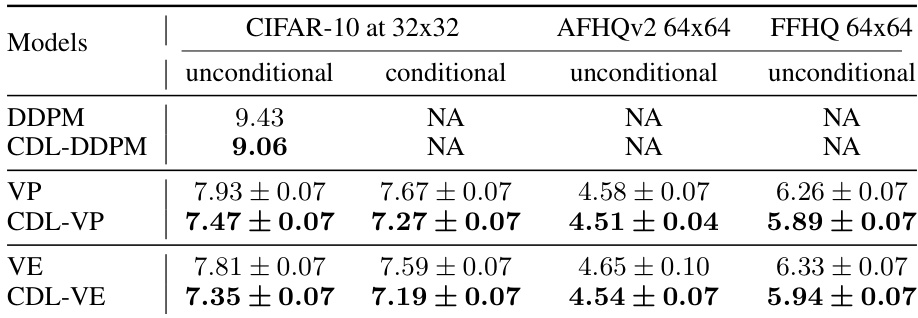
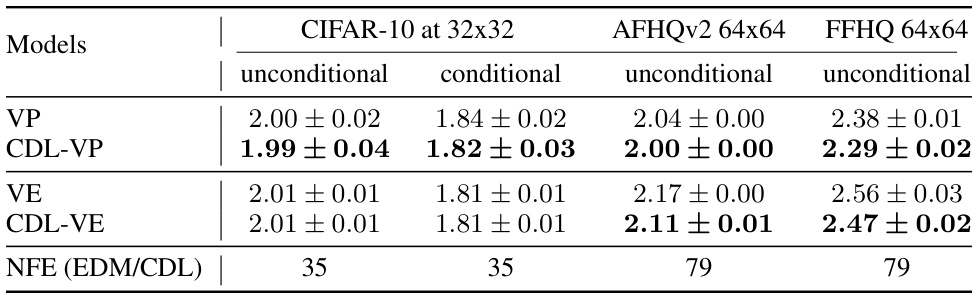
This table presents the Frechet Inception Distance (FID) scores for various models trained on three real-world datasets: CIFAR-10, AFHQv2, and FFHQ. Lower FID scores indicate better image quality. The table compares the performance of standard models (DDPM, VP, VE) against models trained with the Contrastive Diffusion Loss (CDL-DDPM, CDL-VP, CDL-VE). The results show that CDL-trained models generally achieve lower FID scores, suggesting improved image quality. The ‘NA’ values indicate that the corresponding metrics were not applicable for those models and datasets.
This table shows the FID scores achieved by different models on various real-world image datasets, using the parallel DDPM sampler. Lower FID scores indicate better sample quality. The results compare the standard DDPM and CDL-regularized models for both unconditional and conditional generation on CIFAR-10, AFHQv2, and FFHQ datasets. The average FID scores across three random seeds are reported, along with uncertainty estimates.

This table presents the Fréchet Inception Distance (FID) scores for various models trained on different datasets (CIFAR-10, AFHQv2, and FFHQ) using a parallel DDPM sampler. Lower FID scores indicate better sample quality. The results show that models trained using Contrastive Diffusion Loss (CDL) consistently achieve lower FID scores than their baselines, demonstrating improved generation quality. Three random seeds were used for each model, and the average FID with uncertainty is reported.
Full paper#