↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Multi-modal in-context learning (MM-ICL) shows great promise but lacks a comprehensive understanding of its effectiveness. Existing research focuses primarily on optimization techniques, neglecting the underlying factors affecting its performance. This paper addresses this gap by systematically investigating MM-ICL’s three core steps: demonstration retrieval, ordering, and prompt construction. The researchers conducted extensive experiments on six vision large language models and twenty strategies across four tasks.
The study reveals three key factors: a multi-modal retriever significantly improves performance over single-modal ones; intra-demonstration ordering, especially modality sequence, is more important than inter-demonstration ordering; and using introductory instructions in prompts greatly enhances task comprehension and performance. These findings provide valuable guidance for researchers to optimize MM-ICL strategies and improve the capabilities of vision-language models. The research contributes a foundational guide for future research in optimizing MM-ICL, offering insights into demonstration retrieval, ordering, and prompt construction.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-modal learning as it systematically investigates factors affecting the performance of multi-modal in-context learning (MM-ICL). It identifies key performance determinants, including the importance of multi-modal retrievers, intra-demonstration ordering, and introductory instructions in prompts. This work is highly relevant to current research trends in large language models and opens new avenues for optimizing MM-ICL strategies, ultimately enhancing the capabilities of VLLMs.
Visual Insights#

This figure illustrates the three core steps involved in creating prompts for multi-modal in-context learning (MM-ICL): demonstration retrieval, demonstration ordering, and prompt construction. The process starts with a multimodal validation set, from which relevant demonstrations are retrieved. These demonstrations are then ordered, and finally, a prompt is constructed which includes the ordered demonstrations along with instructions. Each step is visually represented as a box, showing data flow from one step to the next.
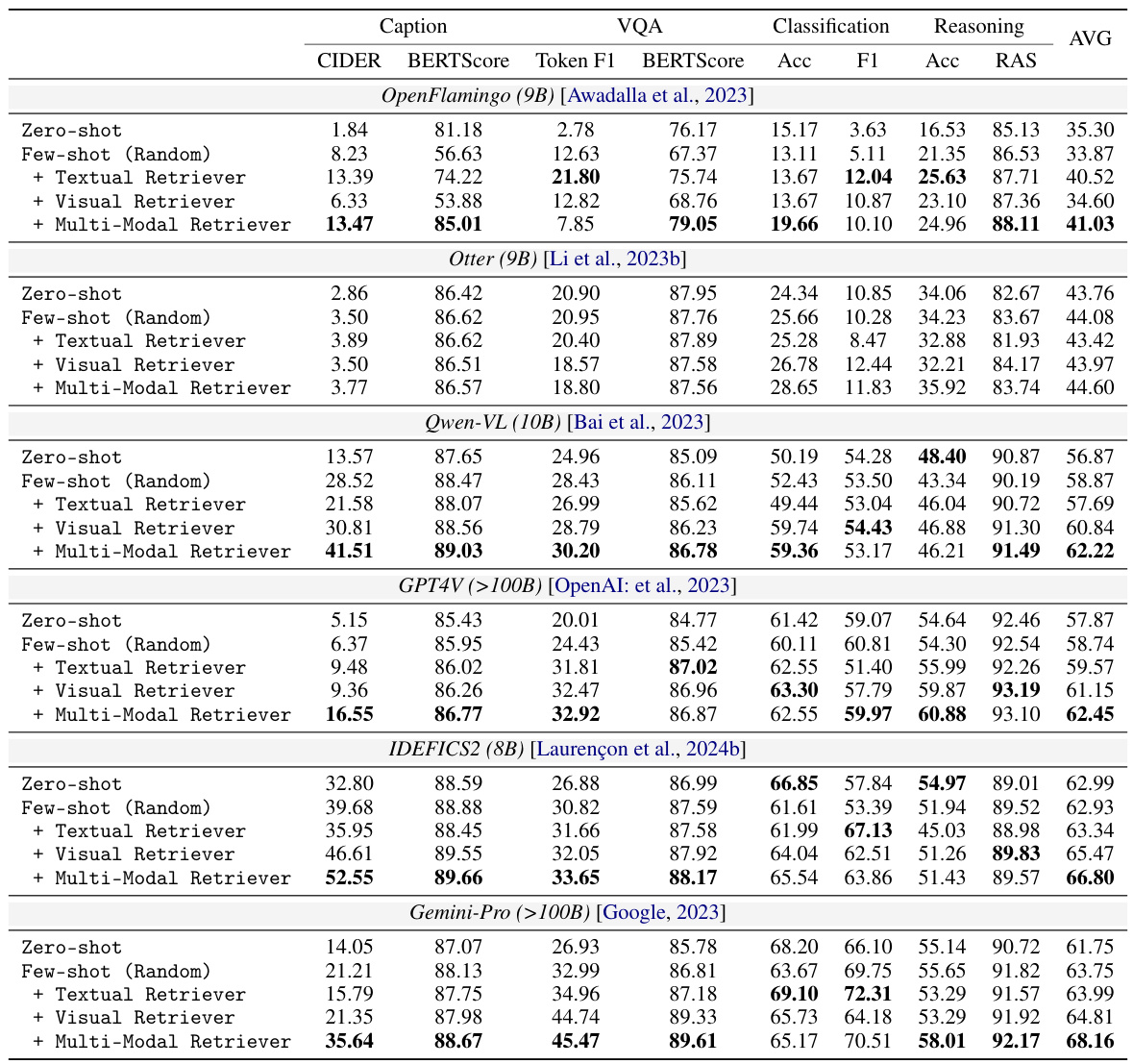
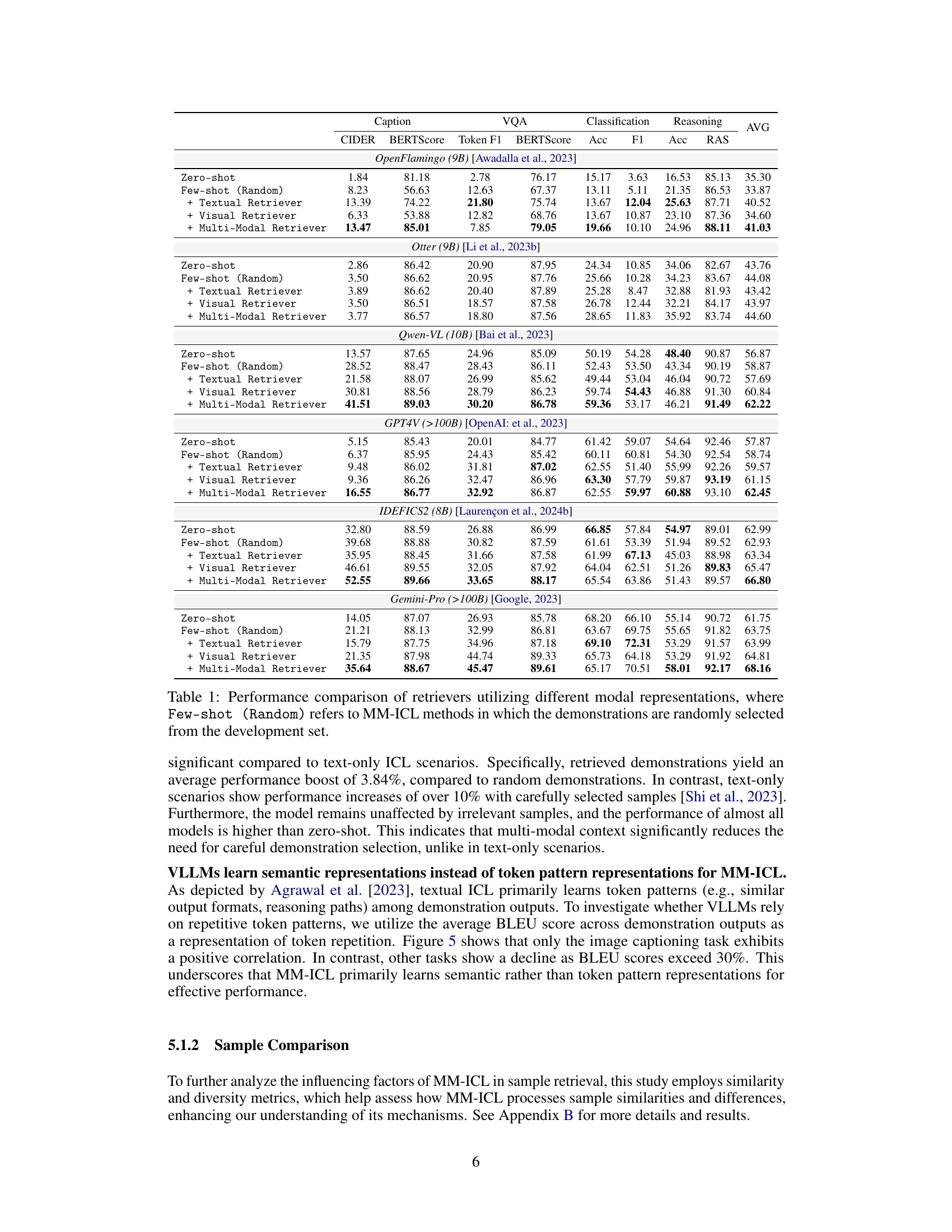
This table compares the performance of different retrieval methods for Multi-Modal In-Context Learning (MM-ICL) across four different tasks (image caption, visual question answering, classification, and reasoning). It shows the performance of zero-shot, few-shot (random), and few-shot methods using textual, visual, and multi-modal retrievers. The table highlights the superior performance of multi-modal retrieval, particularly its resilience to the need for careful demonstration selection, and the limited impact of increasing model size on performance.
In-depth insights#
MM-ICL Factors#
The effectiveness of Multi-Modal In-Context Learning (MM-ICL) hinges on several key factors. Multi-modal retrieval significantly boosts performance, highlighting the need for aligned text and visual representations. Intra-demonstration ordering, specifically the arrangement of modalities within individual examples (e.g., image before text), greatly impacts MM-ICL, unlike inter-demonstration ordering. Prompt construction is also crucial, with introductory instructions proving more beneficial than summative or intra-demonstration instructions by setting appropriate context. The optimal number of demonstrations is task-dependent; while more examples may help with simpler tasks, an excessive number can overload the model on complex tasks. Furthermore, the choice of similarity metrics in retrieval (cosine similarity proving superior to L2) and the consideration of token distance between modalities also influence outcomes.
Retrieval Strategies#
Effective retrieval strategies are crucial for successful multi-modal in-context learning (MM-ICL). Multi-modal retrieval methods, which consider both textual and visual information, consistently outperform single-modal approaches. This highlights the importance of aligning modalities effectively within the retrieval process. The quality of retrieved demonstrations significantly impacts performance, underscoring the need for careful selection strategies. Intra-demonstration ordering, specifically the arrangement of textual and visual components within a single demonstration, holds greater importance than inter-demonstration ordering. Effective strategies incorporate semantic similarity measures, prioritizing contextual relevance, over other metrics like simple token distance. Further research should focus on improving multi-modal alignment techniques and developing more sophisticated methods to evaluate the quality and diversity of retrieved demonstrations. The exploration of advanced sample selection methods, especially those that balance diversity and relevance, remains a promising avenue for future research in MM-ICL.
Prompt Engineering#
Prompt engineering plays a crucial role in maximizing the effectiveness of multi-modal in-context learning (MM-ICL). Careful crafting of prompts, including the selection and ordering of demonstrations, significantly influences model performance. The inclusion of introductory instructions to clearly define the task before presenting examples is shown to be particularly beneficial, improving task comprehension. Furthermore, the study highlights the importance of considering the inherent properties of different modalities (e.g., text, image) when structuring prompts. Strategies for both intra- and inter-demonstration ordering significantly impact model behavior, underscoring the need for a thoughtful approach to sequence design. Ultimately, the effectiveness of prompt engineering underscores the intricate interplay between human guidance (prompt design) and model capabilities in driving successful MM-ICL.
MM-ICL Limits#
Multi-modal In-Context Learning (MM-ICL) presents exciting possibilities but faces inherent limitations. Data Dependency is a major constraint; MM-ICL’s effectiveness hinges on the quality and relevance of demonstration examples, making curated datasets essential. The need for high-quality, diverse data is resource-intensive and may not generalize well across tasks or domains. Model Capacity also plays a critical role; current large language models may struggle to effectively handle complex multi-modal interactions, especially with increasing numbers of demonstrations, leading to cognitive overload. Additionally, alignment between modalities (text, image, etc.) is crucial for effective learning. Misalignment or inconsistent information across modalities can hinder performance, highlighting the importance of carefully designed and curated multimodal data. Generalization remains a significant challenge; MM-ICL’s capacity to adapt to unseen tasks or domains outside the training distribution remains limited. Addressing these limitations will require advances in both model architectures and data curation techniques, and further research into techniques to improve data efficiency and generalization.
Future of MM-ICL#
The future of Multimodal In-Context Learning (MM-ICL) is bright, but success hinges on addressing key challenges. Improving multimodal alignment is paramount; current methods struggle to effectively integrate diverse modalities like text and images, limiting performance. Enhanced demonstration retrieval techniques are crucial—methods that go beyond simple similarity metrics and incorporate richer semantic understanding are needed. We also need to develop better demonstration ordering strategies that account for both intra- and inter-demonstration relationships. Finally, research should explore more sophisticated prompt engineering, including the optimal design of introductory and task-specific instructions. Addressing these challenges will unlock MM-ICL’s full potential for a wide range of applications.
More visual insights#
More on figures

This figure illustrates the three key steps involved in the demonstration retrieval process for multi-modal in-context learning (MM-ICL). These steps are: 1. Sample Representation: Each input sample and the query are mapped into a shared representation space using various encoder architectures (textual, visual, or multi-modal). 2. Sample Comparison: The quality of each sample representation is evaluated relative to the query using metrics like cosine similarity, L2 distance, and semantic coverage. 3. Sample Selection: A selection criterion is applied to choose the most advantageous samples for inclusion in the demonstration set. This selection is guided by factors such as domain information, image style, and modality distance. The figure visually depicts the flow of these processes using different components and arrows.

This figure illustrates the demonstration ordering process in multi-modal in-context learning (MM-ICL). It shows two key aspects: intra-demonstration ordering (the sequence within a demonstration, particularly the order of modalities like text and image), and inter-demonstration ordering (the sequence in which demonstrations are arranged within the dataset).

This figure shows the impact of token pattern representation on the performance of different tasks using the Gemini-Pro model. The x-axis represents the BLEU score (measuring token repetition in demonstration outputs), and the y-axis represents the model performance in terms of accuracy and other metrics like CIDER, RAS, and BERTScore. Different colored lines represent different tasks: VQA, Classification, Caption, and Reasoning. The figure shows the performance of each task under various levels of token pattern repetition.

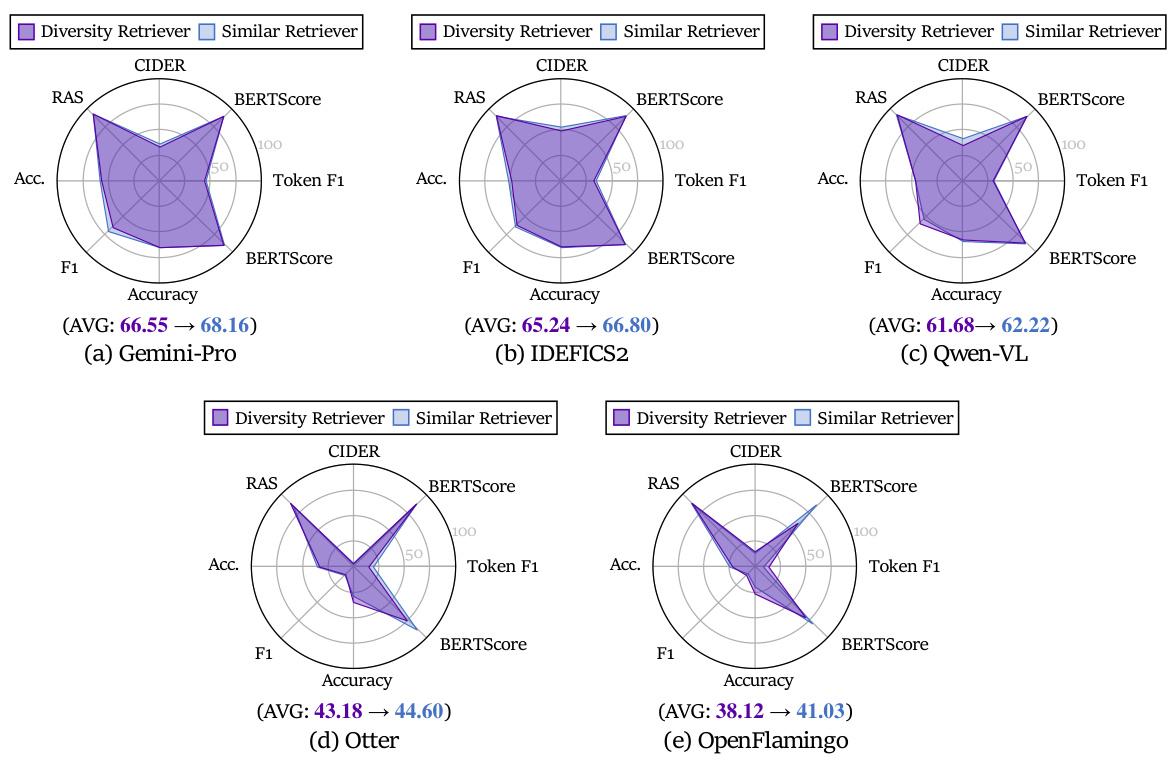
This figure shows the impact of different sample comparison methods on the performance of MM-ICL using the Gemini-Pro model. Specifically, it compares two different similarity metrics (cosine similarity and L2 similarity) and two different diversity approaches (diversity retriever and similar retriever) across various downstream tasks (Image Caption, Visual Question Answering, Classification, and Reasoning). The results highlight the importance of cosine similarity over L2 similarity for MM-ICL, and show minimal effect of diversity on performance.

This figure presents a comprehensive analysis of how sample selection strategies affect the performance of Multi-modal In-context Learning (MM-ICL) using the Gemini-Pro model. It systematically explores three key factors influencing sample selection: in-domain vs. out-of-domain samples, visual style consistency, and the token distance between modalities. The results highlight the importance of selecting in-domain samples for optimal performance, the nuanced role of visual style consistency depending on the task, and the non-monotonic relationship between token distance and performance. The figure provides a detailed breakdown of these effects across multiple tasks and metrics, offering valuable insights for optimizing MM-ICL strategies.
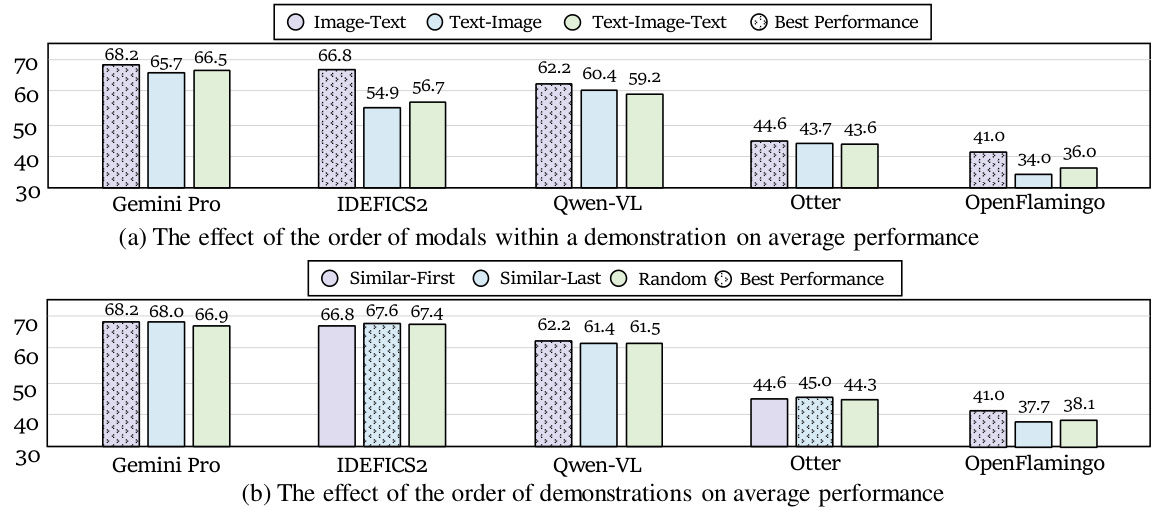
This figure illustrates the demonstration ordering process in multi-modal in-context learning (MM-ICL). It shows two key aspects: intra-demonstration ordering (the sequence within a single demonstration, such as the order of text and image) and inter-demonstration ordering (the sequence of multiple demonstrations). The intra-demonstration ordering is represented by a permutation of the modalities within a single sample, while the inter-demonstration ordering is represented by a permutation of the selected demonstrations.

This figure displays the impact of three different instruction injection methods on the average performance across five different large language models (LLMs) for four different tasks. The three methods are: Introductory Instruction (placing instruction before demonstrations), Summative Instruction (placing instruction after demonstrations), and Intra-demonstration Instruction (embedding instructions within demonstrations). The results indicate that Introductory Instruction consistently enhances performance, while the other two methods generally reduce performance, suggesting the importance of providing context before examples for better task comprehension.

This figure shows the effect of varying the number of demonstrations on the performance of different large language models across various tasks. It demonstrates how the optimal number of demonstrations may vary across different tasks and models. In some cases, increasing the number of demonstrations leads to improved performance, while in other cases it can lead to a decrease in performance. This highlights that there is no universally optimal number of demonstrations for Multi-Modal In-Context Learning (MM-ICL), and that the optimal number may be dependent on various factors such as task complexity, model architecture, and dataset characteristics.
This figure shows the impact of the number of demonstrations on the average performance across different tasks and models. It reveals that increasing the number of demonstrations does not always lead to performance improvements in MM-ICL, and the optimal number of demonstrations varies across different tasks. For image captioning and VQA tasks, performance increases with the number of demonstrations to a point, but then starts to decline when the number of demonstrations exceeds 3. For more complex reasoning tasks, additional demonstrations do not improve performance.

This figure illustrates the three main steps involved in creating prompts for multi-modal in-context learning: demonstration retrieval (selecting relevant demonstrations), demonstration ordering (arranging demonstrations in an effective sequence), and prompt construction (combining demonstrations with instructions into a final prompt). The process starts with a set of multimodal samples, followed by retrieval of relevant demonstrations based on a validation sample. Then, the retrieved demonstrations are ordered, and finally, a prompt is constructed incorporating the ordered demonstrations and instructions.
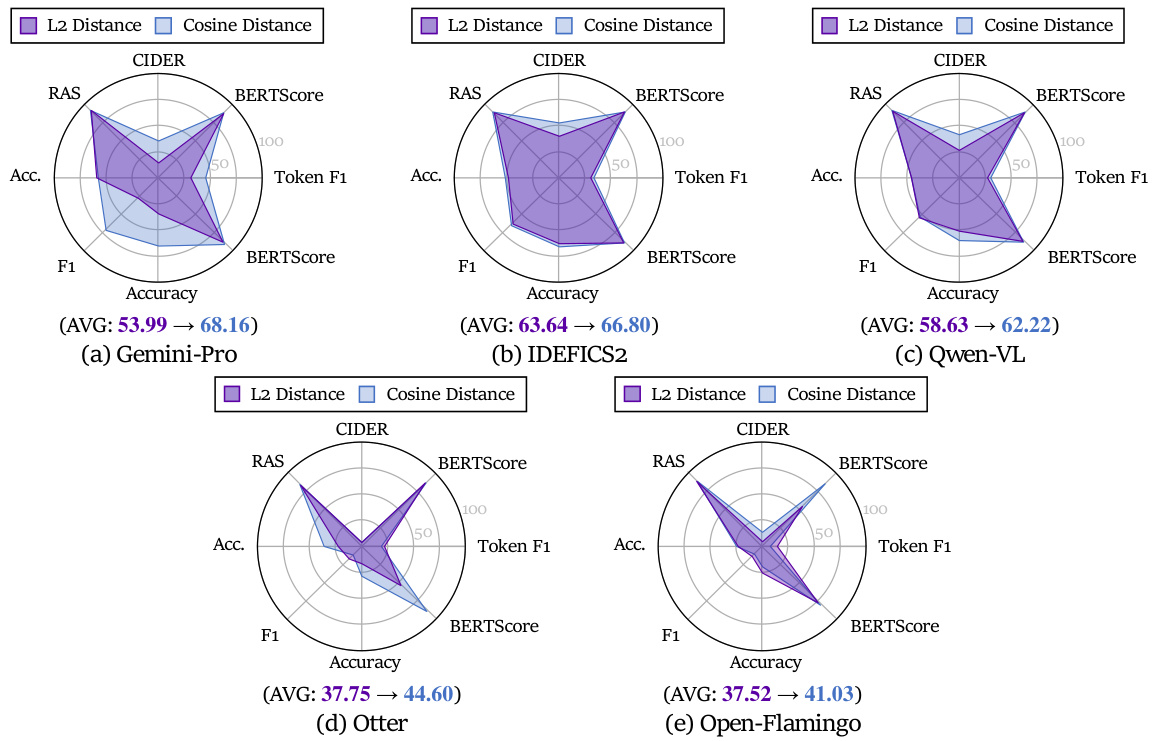
This figure compares the performance of two different sample comparison metrics (cosine similarity and L2 similarity) and two different diversity strategies (diversity retriever and similar retriever) across five different large language models (LLMs). The results indicate that cosine similarity is a better metric for MM-ICL than L2 similarity, and that diversity is not a significant factor in sample comparison for MM-ICL. This suggests that semantic directional consistency is more important than complete semantic alignment for MM-ICL, and that diversity may not be directly correlated with better MM-ICL performance.
This figure details the demonstration retrieval process for Multi-Modal In-Context Learning (MM-ICL). It outlines three key steps: sample representation (using textual, visual, and multi-modal encoders), sample comparison (using cosine distance, L2 distance, and semantic coverage), and sample selection (employing domain selection, image style selection, and modality distance). The diagram illustrates how these steps work together to retrieve the most relevant demonstrations for the MM-ICL task.
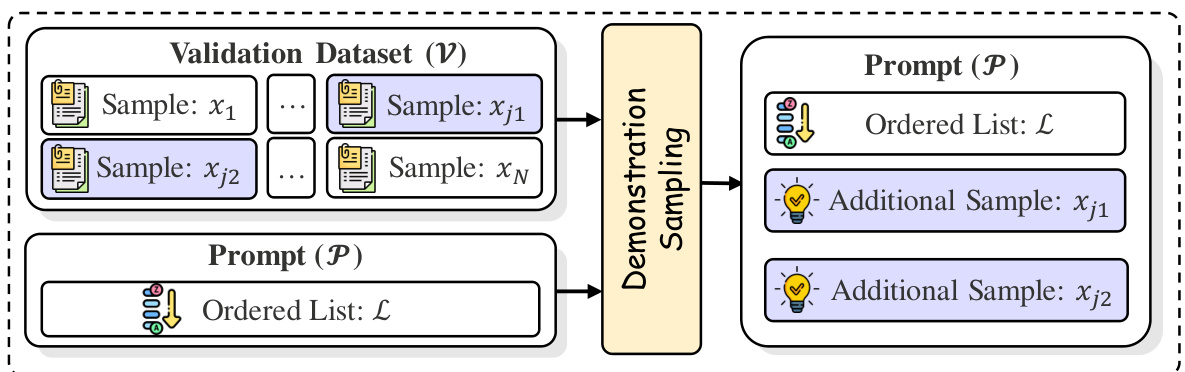
This figure illustrates the demonstration sampling process within the MM-ICL prompt construction. The process starts with a validation dataset (V) containing multiple samples. A subset of these samples forms an ordered list (L). Then, additional samples (Xj1, Xj2) are selected via demonstration sampling. This expanded list is then used to create the final prompt (P). This process is crucial for optimizing the MM-ICL method by carefully selecting relevant examples and additional samples for the prompt.
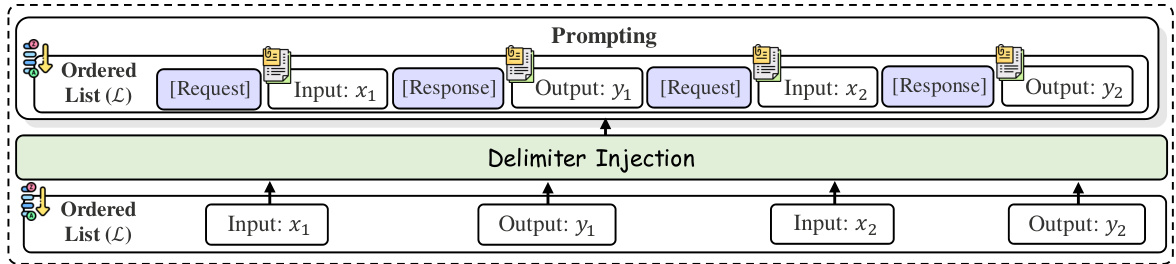
This figure illustrates the three core steps involved in creating prompts for multi-modal in-context learning: demonstration retrieval, demonstration ordering, and prompt construction. Demonstration retrieval selects relevant examples from a dataset. Demonstration ordering arranges those examples in a sequence. Prompt construction combines the ordered demonstrations and instructions to create the final prompt given to a language model. Each step is crucial for effective multi-modal in-context learning.

This figure illustrates the three main steps involved in creating prompts for multi-modal in-context learning (MM-ICL): demonstration retrieval, demonstration ordering, and prompt construction. Each step is represented visually, showing how the process flows from selecting relevant demonstrations to constructing the final prompt used to evaluate the model. The validation set provides samples for retrieval. A demonstration set is created, ordered, and then used to construct the prompt, which contains instructions and the ordered demonstrations.

The figure illustrates the three main steps involved in creating prompts for multi-modal in-context learning (MM-ICL): demonstration retrieval, demonstration ordering, and prompt construction. Each step is visually represented, showing how demonstrations are selected, ordered, and combined to form a prompt used with a multi-modal large language model. The process helps to understand how each stage influences the effectiveness of the MM-ICL approach.

This figure illustrates the three main steps involved in creating prompts for multi-modal in-context learning. First, relevant demonstrations are retrieved from a demonstration set. Second, these demonstrations are ordered, considering both intra-demonstration (order within a single demonstration) and inter-demonstration (order between demonstrations) sequencing. Finally, a prompt is constructed using the ordered demonstrations, which may also include instructions.

The figure illustrates the three core steps involved in creating prompts for multi-modal in-context learning. First, relevant demonstrations are retrieved. Second, these demonstrations are ordered. Third, a final prompt is constructed, incorporating the ordered demonstrations. This process aims to leverage examples to enable a model to perform a task without explicit parameter tuning.
More on tables

This table compares the performance of different retrieval methods (zero-shot, few-shot random, text-only, image-only, and multi-modal) across various vision-language models (VLLMs) on four tasks: image captioning, VQA, classification, and reasoning. It highlights the significant improvement achieved by using multi-modal retrieval compared to other methods, demonstrating the crucial role of multi-modal alignment in MM-ICL. The table also reveals that increasing model parameters does not necessarily lead to substantial improvements, and that multi-modal context diminishes the need for careful demonstration selection.

This table compares the performance of different retrieval methods (zero-shot, few-shot random, textual, visual, and multi-modal) across four tasks (image caption, VQA, classification, and reasoning) and six VLLMs. It shows that multi-modal retrieval generally outperforms other methods, highlighting the importance of multi-modal alignment in MM-ICL. The gains from carefully selecting demonstrations are less significant in multi-modal settings than in text-only settings.

This table compares the performance of different retrieval methods for multi-modal in-context learning (MM-ICL) across four tasks (image captioning, visual question answering, image classification, and reasoning). It shows the performance boost achieved by using multi-modal retrievers compared to zero-shot, random few-shot, and single-modality retrieval methods. The results highlight the importance of multi-modal alignment for MM-ICL, showing that increasing model parameters doesn’t significantly improve performance.
Full paper#