↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning (CL) aims to enable models to learn new tasks without forgetting previous ones. Vision-language models (VLMs), like CLIP, offer strong generalizability but often require finetuning for downstream tasks, and existing deterministic finetuning methods may fail in CL scenarios due to overlooking possible interactions across modalities and unsafe for high-risk applications. This often leads to catastrophic forgetting, a significant challenge in continual learning.
CLAP4CLIP tackles this by employing a probabilistic framework over visual-guided text features, providing more calibrated CL finetuning. Unlike data-hungry anti-forgetting techniques, it leverages CLIP’s pre-trained knowledge for weight initialization and distribution regularization, mitigating forgetting. Experiments show that CLAP4CLIP outperforms deterministic finetuning in in-domain performance, output calibration, and generalization to unseen tasks. Furthermore, its uncertainty estimation abilities enable novel data detection and exemplar selection in CL, expanding its practical use.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in continual learning and vision-language modeling. It introduces a novel probabilistic finetuning method that significantly improves performance and addresses the limitations of deterministic approaches. The findings are relevant to various applications, including high-risk scenarios requiring reliable uncertainty estimation, and open new avenues for research in model calibration and generalization. The proposed method enhances prompt-based finetuning and offers out-of-the-box applications like data detection and exemplar selection.
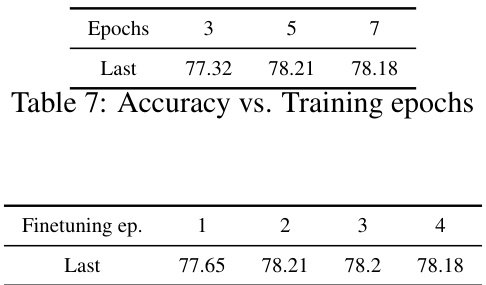
Visual Insights#

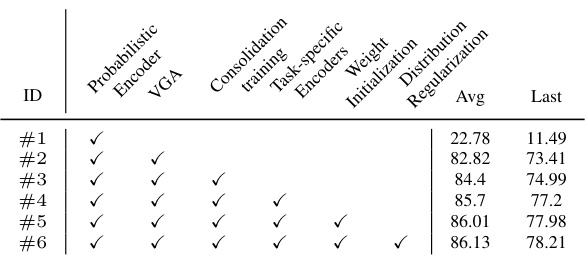
This figure illustrates four different design choices for probabilistic finetuning of pre-trained CLIP for continual learning. Each design is evaluated based on four criteria: in-domain performance, prompt-type agnosticism, cross-modal cues utilization, and distinct task representation. The authors’ proposed method (Choice #3) aims to balance in-domain performance with the utilization of visual and textual information and distinct task representations by using visual-guided text features and lightweight task-specific adapter modules.
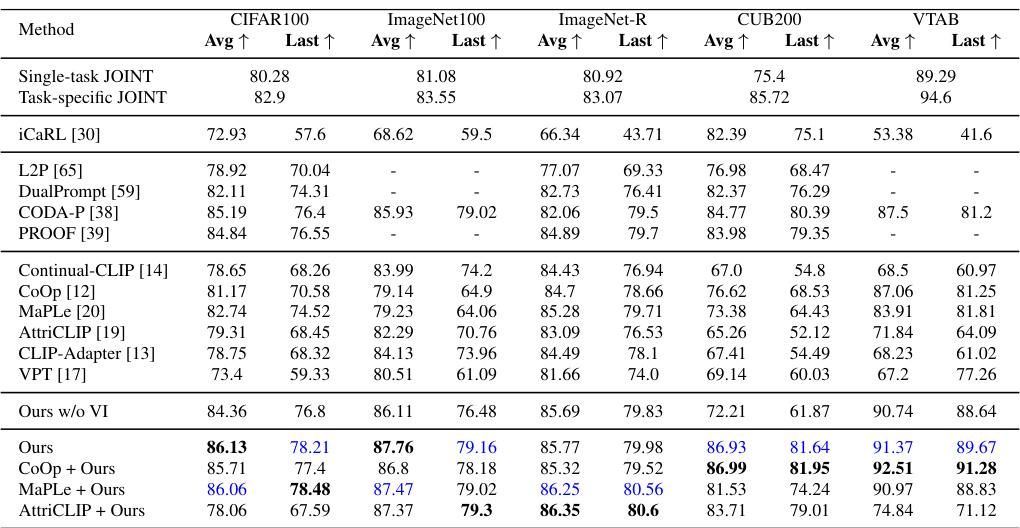
This table presents a comparison of the proposed CLAP4CLIP method against various baselines and state-of-the-art continual learning approaches on five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The table shows the average and last-step accuracy across three runs for each method. The best and second-best performing methods are highlighted in bold and blue, respectively. It also references Appendix Table 12 for a statistical analysis of the results demonstrating the significance of the differences between the compared methods.
In-depth insights#
Probabilistic Finetuning#
Probabilistic finetuning, as a technique, offers a significant advancement over traditional deterministic methods by explicitly modeling uncertainty in the model’s predictions. This is particularly crucial in continual learning, where models encounter shifts in data distributions and must adapt without catastrophic forgetting. By incorporating probabilistic elements, the approach provides more calibrated uncertainty estimates, improving reliability, especially in high-stakes applications. A key advantage is the ability to leverage pre-trained knowledge, avoiding the need for extensive retraining on all previous data. The probabilistic framework enables the model to better generalize to new tasks, mitigating overfitting issues often encountered in deterministic finetuning. Another key benefit is improved robustness: the model can identify uncertain predictions, facilitating novel data detection and enabling more reliable decision-making. Although this approach might introduce added computational overhead compared to deterministic methods, the benefits of increased reliability, robustness, and generalization outweigh these costs in many real-world applications.
CLIP Continual Learning#
CLIP, with its impressive zero-shot capabilities, presents a compelling foundation for continual learning (CL). However, the inherent challenge lies in effectively adapting CLIP to new tasks without catastrophic forgetting of previously learned knowledge. Probabilistic methods offer a promising approach, enabling better uncertainty estimation and more robust generalization. A key focus in CLIP CL research is efficient finetuning, often using lightweight adapter modules to modify the pre-trained weights rather than full retraining. This is essential for resource-constrained CL scenarios. Moreover, the interplay between different prompt engineering techniques and CL strategies remains an active area of investigation; integrating prompt engineering within probabilistic CL frameworks could be particularly beneficial. Finally, addressing catastrophic forgetting remains crucial, demanding more research into effective regularization and memory management strategies to maintain performance across numerous tasks.
Visual-Guided Attention#
The concept of ‘Visual-Guided Attention’ in the context of a vision-language model for continual learning suggests a mechanism where the visual input directly influences the attention mechanism applied to textual information. This is crucial because it allows the model to focus on the most relevant textual features based on the associated visual context. For instance, if the image depicts a dog, the model should pay more attention to words and phrases related to dogs in the textual description, rather than unrelated elements. This cross-modal interaction is vital for robust continual learning, as it enables the model to avoid catastrophic forgetting by relating new information to existing knowledge effectively through the shared visual context. The use of visual attention guidance might involve a weighted attention mechanism based on the similarity or relevance of visual features to text embedding which then modulates the attention weights for each word. This intelligent approach could thus improve both accuracy and generalization performance, making the model more adaptable to ever-changing visual language tasks. The integration of a visual-guided attention mechanism is a key innovation, significantly enhancing the model’s ability to learn new tasks effectively and retaining information about past learned tasks
CLAP4CLIP Methodology#
The CLAP4CLIP methodology centers on probabilistic finetuning of pre-trained CLIP for continual learning. Instead of deterministic approaches, it models the distributions of visual-guided text features per task, leading to more calibrated uncertainty estimates crucial for high-risk applications. This probabilistic approach leverages CLIP’s pre-trained knowledge for weight initialization and distribution regularization, mitigating catastrophic forgetting without relying on extensive data. The method incorporates lightweight task-specific adapter modules to enhance task distinctiveness while maintaining cross-modal cue alignment. It’s compatible with existing prompting methods and shows improvements in in-domain performance, output calibration, and generalization to unseen tasks. Visual-guided attention is a key component, ensuring alignment between visual and textual cues. The framework’s modularity allows for adaptation to different prompt types. The approach also explores functional regularization using pre-trained knowledge to alleviate forgetting and address the stability gap often encountered in continual learning.
Future Research#
The paper’s “Future Research” section suggests several promising avenues. Parameter efficiency is crucial for scaling to large continual learning tasks, necessitating the exploration of more efficient adapter architectures. Improving regularization techniques to better combat catastrophic forgetting is another key area. The use of more informed priors for Bayesian inference could enhance model accuracy and calibration, although careful consideration of computational costs is necessary. Finally, exploring the use of LLM-generated prompts offers an interesting alternative to hand-crafted prompts, potentially improving generalizability and reducing the need for manual labeling. This research direction would also require investigating the transferability of LLM-generated knowledge to unseen datasets and classes.
More visual insights#
More on figures
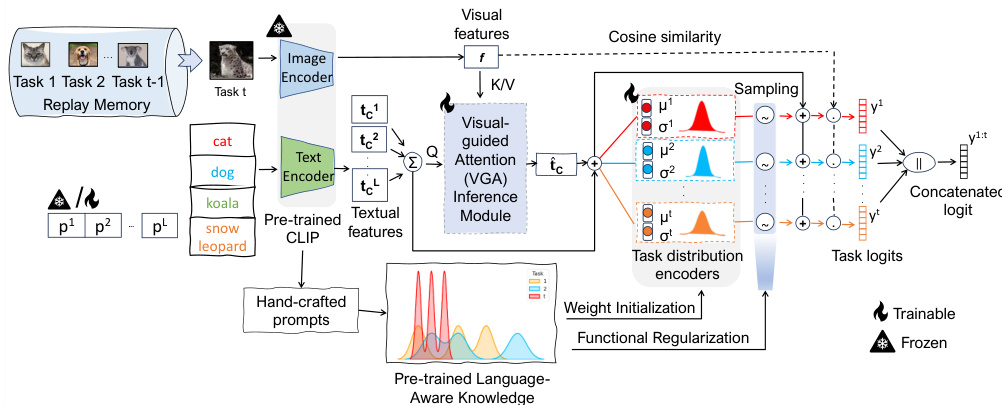
This figure provides a detailed overview of the CLAP4CLIP architecture. It shows how the visual and text features are processed through a visual-guided attention (VGA) module to generate task-specific visual-guided text features. These features are then passed through task-specific distribution encoders which learn separate distributions for each task. Samples are drawn from these distributions and combined with the original features to create task logits, which are ultimately concatenated to make the final prediction. The figure also highlights the weight initialization and functional regularization techniques used, as well as the use of pre-trained language-aware knowledge.

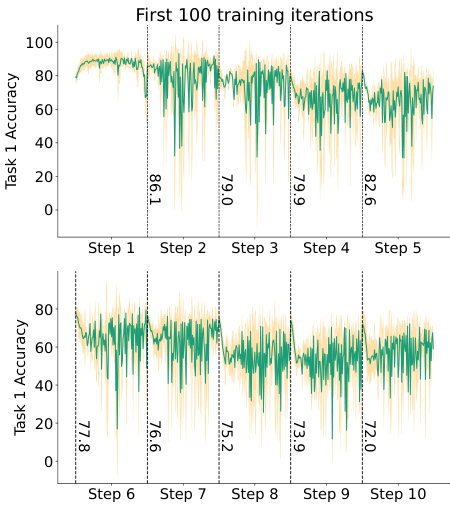
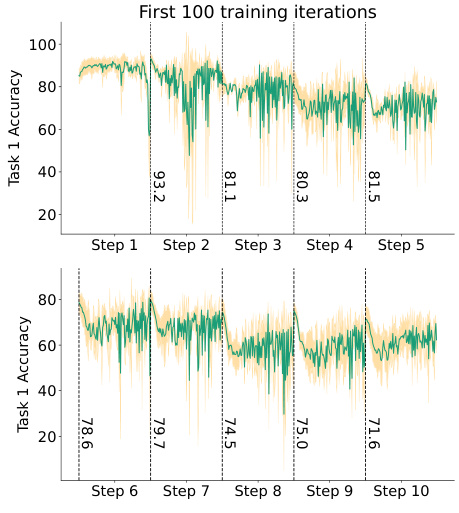
This figure demonstrates the necessity of the visual-guided attention (VGA) module in the CLAP4CLIP model. Subfigure 3a shows that a simple adapter fails to prevent catastrophic forgetting in continual learning (CL), as indicated by high backward transfer (BwT) scores. Subfigure 3b illustrates how the VGA module ensures alignment between learned text features and pre-trained visual features, thereby mitigating catastrophic forgetting. The average angle between image and text feature vectors decreases with incremental training steps, indicating successful cross-modal alignment.
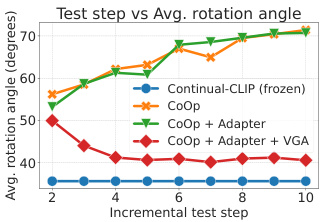
This figure shows the necessity of using a visual-guided attention module in continual learning with CLIP. Subfigure 3a demonstrates that a simple adapter is insufficient to prevent catastrophic forgetting, as indicated by high backward transfer (BwT) scores. Subfigure 3b illustrates how the visual-guided attention (VGA) module helps maintain alignment between learned text features and pre-trained visual features, preventing the text features from drifting apart during incremental training.

This figure demonstrates the effect of using task-specific adapters in a continual learning setting. The left panel shows the cosine distance between centroids of class-specific latent variables without task-specific adapters. The right panel shows the same but with task-specific adapters. The visualization clearly shows that task-specific adapters improve the separability of class centroids across different tasks, indicating a better ability to distinguish between tasks and reduce catastrophic forgetting.
This figure provides a visual overview of the CLAP4CLIP architecture. It shows how visual and textual features are processed through visual-guided attention (VGA) to create visual-guided text features. These are then passed to task-specific encoders, which model the task distribution and generate task logits. These logits are then combined to form the final prediction, demonstrating the model’s ability to handle multiple tasks in a continual learning setting.

This figure compares the number of parameters (in millions) of different continual learning methods for vision-language models. The methods compared are iCaRL, CLIP-Adapter, Continual-CLIP, L2P, DualPrompt, PROOF, CoOp, AttriCLIP, and the proposed method, CLAP4CLIP (Ours). The figure shows that the proposed method has a relatively low number of parameters compared to some of the other methods, particularly iCaRL.

This figure compares different exemplar selection strategies on CIFAR100. The strategies include entropy, iCaRL, random, energy, and variance. The bar chart shows the average and last accuracy for each strategy, indicating the performance of each method in selecting representative samples for continual learning.

This figure shows the architecture of CLAP4CLIP, a continual learning framework for vision-language models. It uses a visual-guided attention (VGA) module to combine visual and textual information, and then uses task-specific encoders to learn task-specific distributions over visual-guided text features. The output of each task-specific encoder is then combined with the original task features to produce the task logits, which are finally concatenated to produce the final prediction.
The figure illustrates the architecture of CLAP4CLIP, a continual learning framework for vision-language models. It shows how visual and textual information is processed through visual-guided attention (VGA) to generate task-specific features, which are then used for probabilistic finetuning and prediction across multiple tasks. The process combines visual features from an image encoder with text features (prompts) from a text encoder. These features are passed through a visual-guided attention mechanism, which dynamically weights the text features based on their relevance to the visual input. The resulting features are then processed by task-specific adapter modules and used to generate predictions. The task-specific modules, which learn parameters specific to each task, are integrated to generate a final prediction, preventing catastrophic forgetting across tasks.

This figure demonstrates the necessity of the visual-guided attention (VGA) module in the CLAP4CLIP framework. The left sub-figure (3a) shows that a simple adapter module is insufficient to prevent catastrophic forgetting in continual learning scenarios, as evidenced by high backward transfer (BwT) scores. The right sub-figure (3b) illustrates how the VGA module facilitates cross-modal alignment between learned text features and pre-trained visual features. This alignment is crucial for maintaining the generalizability of the model over time, preventing the learned textual features from deviating significantly from the visual features as new tasks are added.

This figure shows the necessity of using the Visual-guided Attention (VGA) module in the CLAP4CLIP model. It demonstrates that a simple adapter is not enough to prevent catastrophic forgetting (Figure 3a), as measured by the backward transfer (BwT) score. The VGA module, however, helps maintain alignment between learned text features and pre-trained visual features (Figure 3b), thereby reducing forgetting. The average angle between the text and visual features illustrates this alignment.

This figure shows the necessity of using the Visual-guided Attention (VGA) module in the CLAP4CLIP framework. Figure 3a demonstrates that a simple adapter alone is insufficient to prevent catastrophic forgetting in continual learning scenarios, as evidenced by the high Backward Transfer (BwT) scores. Conversely, Figure 3b illustrates that the VGA module effectively aligns learned text features with pre-trained visual features, reducing the average angle between them. This alignment is crucial, as otherwise the text features would deviate significantly from the visual features as more incremental training steps occur.

This figure demonstrates the necessity of the Visual-guided Attention (VGA) module in preventing catastrophic forgetting during continual learning. Subfigure (a) shows that a simple adapter without VGA is insufficient for maintaining accuracy across tasks (high backward transfer (BwT) scores indicate forgetting), while subfigure (b) illustrates how VGA aligns learned text features with pre-trained visual features, preventing cross-modal feature deviation and catastrophic forgetting.

This figure demonstrates the necessity of the visual-guided attention (VGA) module in the CLAP4CLIP model for continual learning. Subfigure (a) shows that a simple adapter is insufficient to prevent catastrophic forgetting, as indicated by high backward transfer (BwT) scores. Subfigure (b) illustrates how the VGA module helps maintain alignment between learned text features and pretrained visual features, preventing the cross-modal features from deviating, thus avoiding catastrophic forgetting. The average rotation angle between the two feature sets is used to quantify the degree of alignment.
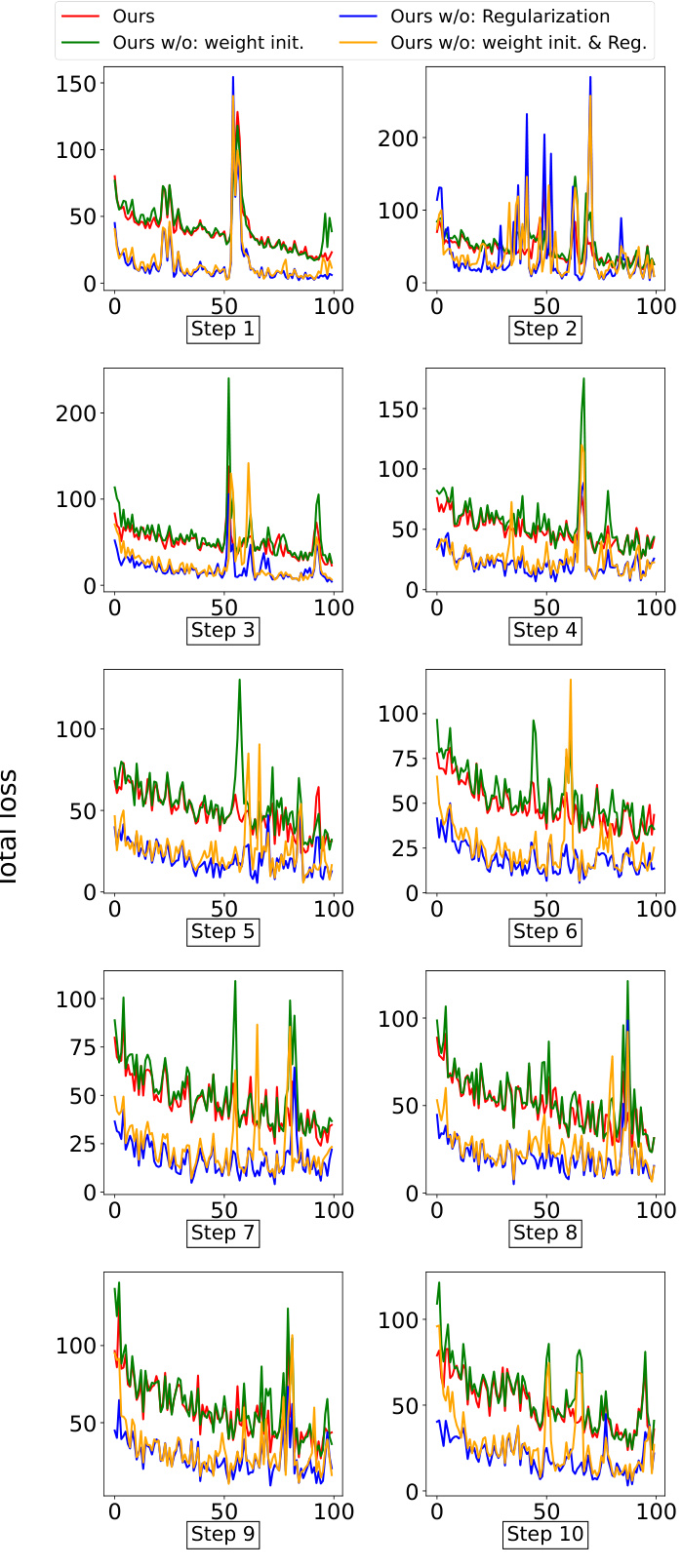
This figure shows the performance of various continual learning methods across different tasks. The x-axis represents the task number, and the y-axis represents the top-1 accuracy. Each line corresponds to a different method, illustrating how the accuracy evolves over the course of continual learning. This provides a visual comparison of the methods’ ability to maintain performance on previous tasks as new tasks are introduced.
This figure shows the performance of different continual learning methods across ten incremental tasks on five different datasets. The x-axis represents the number of classes seen so far, and the y-axis represents the top-1 accuracy. The graph illustrates how the accuracy of each method evolves as it learns new tasks. It highlights the ability of the proposed CLAP4CLIP method to maintain higher accuracy across multiple tasks compared to baseline methods, demonstrating its effectiveness in mitigating catastrophic forgetting.
This figure shows the performance of various continual learning methods across different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB) as the number of classes (tasks) increases. The y-axis represents the top-1 accuracy, and the x-axis represents the number of classes. Each line represents a different continual learning method. The figure demonstrates how the accuracy of each method changes over time as new classes are introduced. It highlights the ability of the proposed CLAP4CLIP method to maintain high accuracy even when dealing with a large number of classes.

This figure illustrates the architecture of CLAP4CLIP, a continual learning framework for vision-language models. It shows how the model uses visual-guided attention to align text and visual features, and how task-specific adapters are used to process these features for each task. The model outputs a weighted combination of task logits to produce a final prediction.
This figure shows a detailed overview of the CLAP4CLIP model architecture. The process begins with image and text encoders from pre-trained CLIP. Visual features are used as keys and values, while text features act as queries in a visual-guided attention (VGA) module. The VGA’s output visual-guided text features are then passed to task-specific distribution encoders (each encoder producing a mean and standard deviation) where samples are drawn from these distributions. These samples are combined with original text features, passed through task-specific adapter modules, and finally combined into a final prediction using a concatenation of task logits.

This figure provides a high-level overview of the CLAP4CLIP architecture. It shows how visual and textual information are processed and integrated to perform continual learning. The visual-guided attention (VGA) module combines visual and textual features. Task-specific adapter modules learn task-specific distributions, and the outputs are fused to make the final prediction.

This figure shows the architecture of the CLAP4CLIP model. The visual-guided attention (VGA) module is a key component that combines visual and textual information to generate visual-guided text features. These features are then fed to task-specific distribution encoders, which generate task-specific logits. Finally, all task logits are combined to produce the final prediction.
More on tables
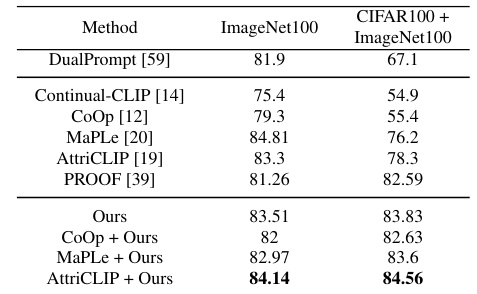
This table compares the performance of different continual learning methods on a challenging cross-dataset continual learning (CDCL) setting. The CDCL setting involves training the model sequentially on CIFAR100 and ImageNet100 datasets and testing the model on both datasets after training. The table shows the average and last-step accuracy for various methods, including the proposed CLAP4CLIP approach and several baselines. The ViT-L/14 backbone is used for all CLIP-based methods to ensure fair comparison. The results highlight the effectiveness of the proposed method in handling cross-dataset continual learning scenarios.
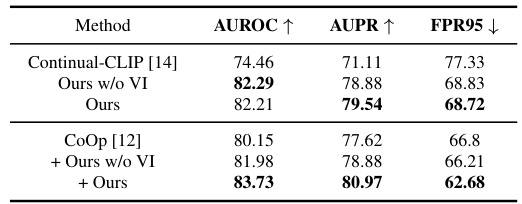
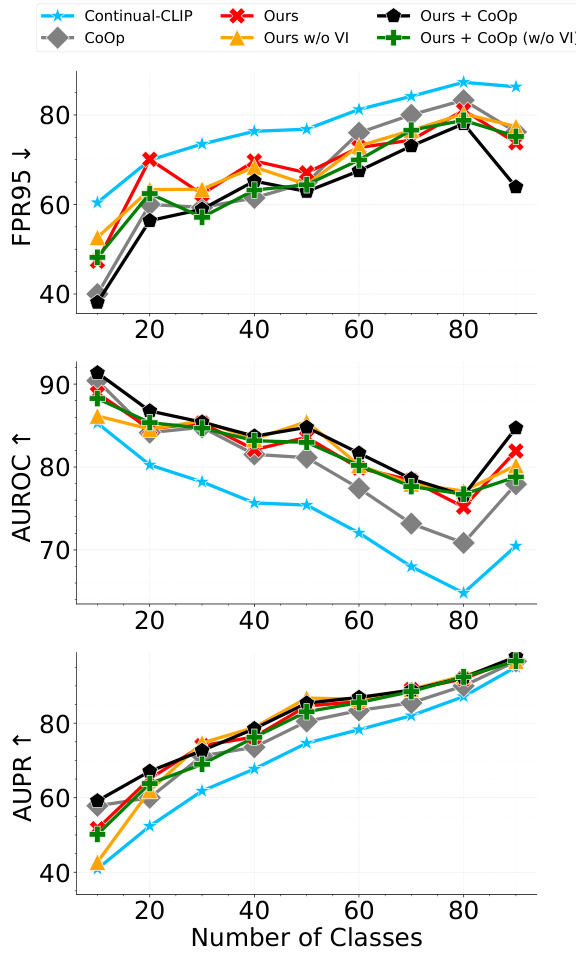
This table presents the results of post-hoc novel data detection (PhNDD) experiments conducted on the CIFAR100 dataset. Three metrics are reported: AUROC (Area Under the Receiver Operating Characteristic curve), AUPR (Area Under the Precision-Recall curve), and FPR95 (False Positive Rate at 95% True Positive Rate). The table compares the performance of several methods, including the baseline Continual-CLIP and variants of the proposed CLAP4CLIP method (with and without variational inference), as well as combinations of CLAP4CLIP with the CoOp method. The best performance for each variant is highlighted in bold, showing that the proposed methods, especially those incorporating variational inference, significantly improve upon the baseline in terms of novel data detection.

This table lists five benchmark datasets used in the paper’s experiments: CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB. For each dataset, it provides the number of training instances, the number of testing instances, the number of classes, the number of tasks, and a link to the dataset.

This table compares the average performance of several continual learning methods across five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The ‘Avg’ column represents the average accuracy across all incremental tasks, while ‘Last’ shows the accuracy on the final task. The table highlights the best-performing method in bold for each dataset and includes a reference to Appendix Table 12 for statistical significance testing.
This table compares the performance of several continual learning methods on five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The table shows the average accuracy across three runs for each method, with the best performance highlighted in bold and the second-best in blue. It also provides references to supplementary materials for statistical significance testing.

This table presents a comparison of different continual learning methods on five benchmark datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). For each dataset, the table shows the average accuracy and the accuracy on the last task across three runs for each method. The best performing method for each dataset is highlighted in bold, and the second best is highlighted in blue. Methods compared include several CLIP-based methods (Continual-CLIP, CoOp, MaPLe, AttriCLIP, CLIP-Adapter, VPT, and the proposed CLAP4CLIP method with various prompting methods), vision-only methods (DualPrompt, L2P, CODA-P, and PROOF), and one baseline continual learning method (iCaRL). The table provides a comprehensive overview of the performance of various continual learning methods on various datasets.
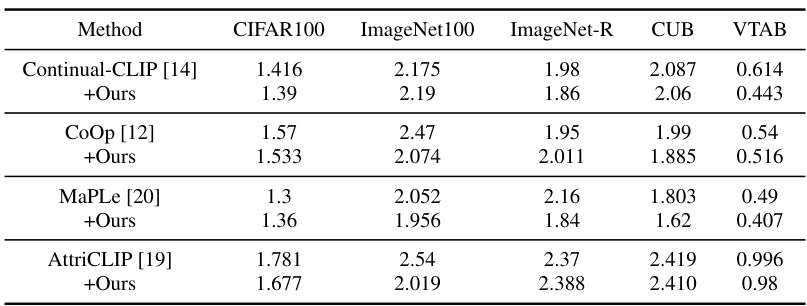
This table presents a comparison of the proposed CLAP4CLIP method against various other continual learning methods across five different datasets: CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB. For each dataset, it shows the average and last-step accuracy achieved by each method, with the best scores highlighted in bold. It also indicates the statistical significance of the results using standard deviations.

This table presents a comparison of the proposed CLAP4CLIP method against various baseline and state-of-the-art continual learning methods across five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). For each dataset and method, it shows the average and last-step accuracy across three runs. Bold text indicates the best performance for each dataset, while blue text indicates the second-best performance. It also references an appendix table for statistical significance testing of the results.

This table compares the average performance of various continual learning methods across five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The ‘Avg’ column shows the average accuracy across all incremental learning steps, while ‘Last’ represents the accuracy achieved on the final step. The table highlights the best-performing method for each dataset in bold and the second-best in blue. For a more detailed statistical analysis, including standard deviation scores, the reader is referred to Appendix Table 12.

This table compares the average performance of several continual learning methods (including baselines and state-of-the-art methods) across five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, VTAB). The results are averaged over three runs for each method, and the best-performing method for each dataset is shown in bold. The table also notes where the performance results for certain methods were sourced from another paper ([39]), and references an appendix table for statistical significance details.

This table presents a comparison of the proposed CLAP4CLIP method against various existing continual learning and vision-language model finetuning methods across five benchmark datasets. The metrics used for comparison are average accuracy and last-step accuracy across ten incremental tasks, providing a comprehensive assessment of performance and forgetting. The table also highlights the statistical significance of the results.

This table presents a comparison of the proposed CLAP4CLIP method against several baseline and state-of-the-art continual learning methods. The average and last-step accuracy are reported across three runs for five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The best-performing method in each category is highlighted in bold, and the second-best is in blue. It shows that CLAP4CLIP consistently outperforms other methods.

This table presents a comparison of various continual learning methods on five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The performance is measured by the average accuracy across all tasks and the accuracy on the last task. It also includes results from several baselines. The best and second-best performing methods are highlighted. A reference to Appendix Table 12 is provided for details on statistical significance testing.

This table compares the average performance of various continual learning methods across five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). For each dataset and method, it shows the average accuracy across three runs and the accuracy on the last incremental task. The best and second-best performances are highlighted. Statistical significance is discussed in the appendix.
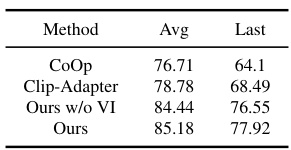
This table presents the results of exemplar selection using entropy on the CIFAR100 dataset. It compares the average and last-task accuracy achieved by several continual learning methods, including CoOp, Clip-Adapter, and the authors’ method (both with and without Variational Inference). The ‘Avg’ column shows the average accuracy across all tasks, while ‘Last’ shows the accuracy on the final task. The goal is to show how well each method selects exemplars which will aid in preventing catastrophic forgetting.
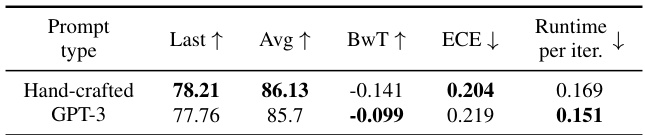
This table compares the performance of various continual learning methods on five different datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). For each dataset and method, average and last-step accuracy are shown. The table also indicates which methods achieved the best and second-best results for each dataset. It refers the reader to Appendix Table 12 for statistical details regarding the significance of the results.

This table compares the performance of different continual learning methods on a challenging cross-dataset continual learning setting (CDCL). The CDCL setting involves training sequentially on two datasets, CIFAR100 and ImageNet100, and evaluating performance on both. The table highlights that the proposed CLAP4CLIP method outperforms several baselines and state-of-the-art continual learning methods, demonstrating its effectiveness in handling the challenges posed by cross-dataset continual learning.

This table compares the average performance of several continual learning methods across five benchmark datasets (CIFAR100, ImageNet100, ImageNet-R, CUB200, and VTAB). The ‘Avg’ column shows the average accuracy across all incremental learning steps, and the ‘Last’ column shows the accuracy at the final step. Bold values represent the best performance for each dataset, and blue values represent the second-best performance. The table highlights the superior performance of the proposed CLAP4CLIP method compared to existing baselines. Appendix Table 12 provides additional statistical details regarding the significance of the results.
Full paper#



















