↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current BCI research primarily focuses on reconstructing static images from brain activity, neglecting the rich dynamic information inherent in our visual experience. This limitation hinders our understanding of the brain’s visual processing system and restricts the capabilities of BCIs.
This paper tackles this limitation head-on by introducing EEG2Video, a novel framework that successfully reconstructs dynamic videos from high-temporal resolution EEG signals. The core of this method is a large dataset (SEED-DV), a novel Seq2Seq architecture, and a dynamic-aware noise-adding method for enhanced video generation. The findings show impressive results in semantic classification and video reconstruction tasks, paving the way for more advanced BCIs that can interpret dynamic visual information.
Key Takeaways#
Why does it matter?#
This paper is crucial because it pioneers the decoding of dynamic visual perception from EEG, a significant advancement in brain-computer interface (BCI) research. It introduces a large-scale dataset and novel methods for video reconstruction, directly addressing the limitations of previous research focused on static stimuli. This work opens new avenues for understanding brain processing of dynamic information and for developing more sophisticated BCIs.
Visual Insights#
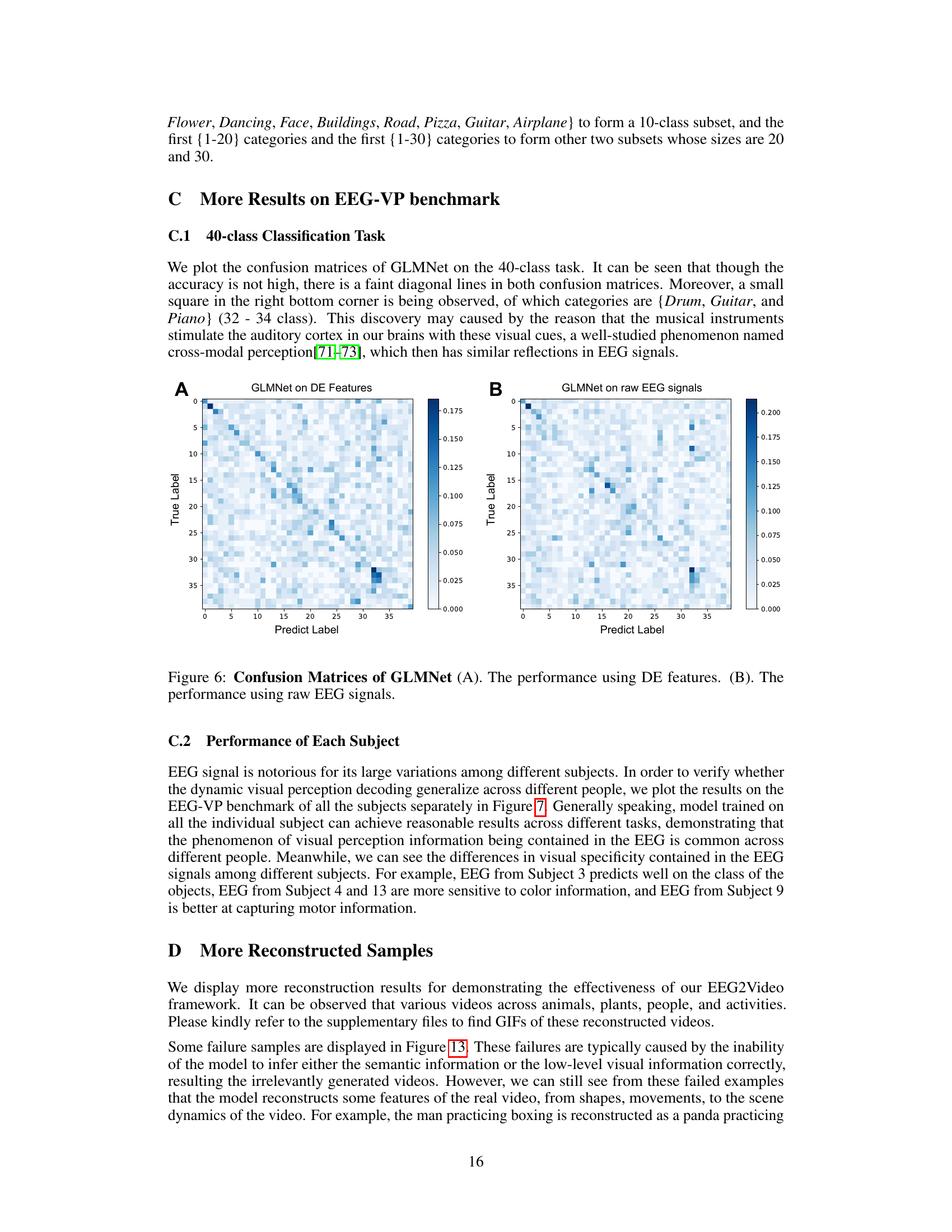
This figure shows the meta-information of the video clips used in the experiment, the experimental setup, and the protocol. Panel A displays visualizations of the average meta-information (color, optical flow score, object number, human face presence, human presence, musical instrument presence, etc.) for each of the 40 video concepts. Panel B illustrates the experimental environment, showing the participant wearing an EEG cap, an eye tracker, and the equipment used for data acquisition. Panel C depicts the structure of a single data collection session. This session consists of seven video blocks, each lasting approximately 8 minutes and 40 seconds, separated by rest periods of at least 30 seconds each. Panel D details the structure of a video block. Each block begins with a 3-second hint indicating the video category, followed by five 2-second video clips belonging to that category.
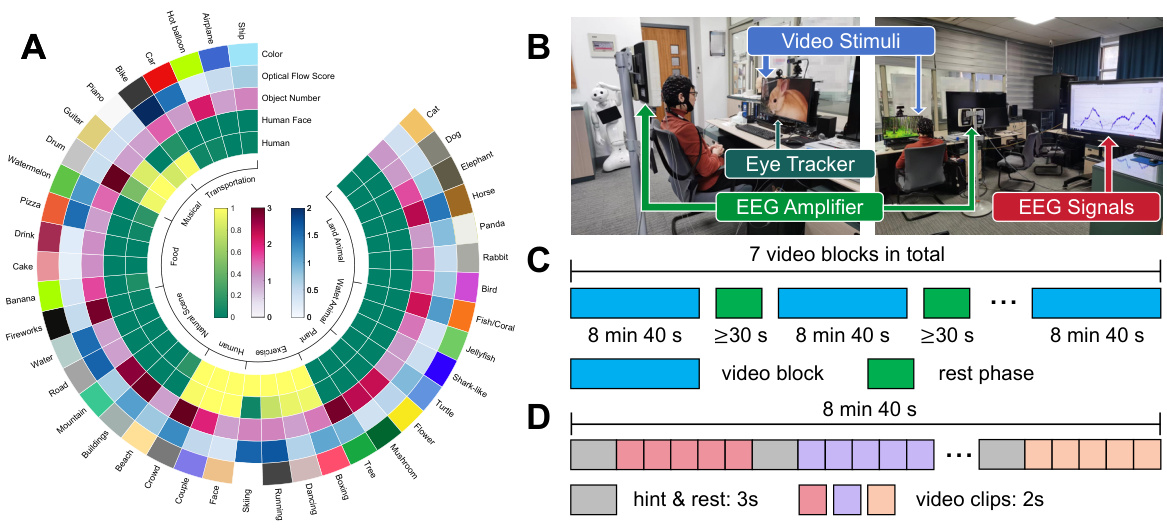
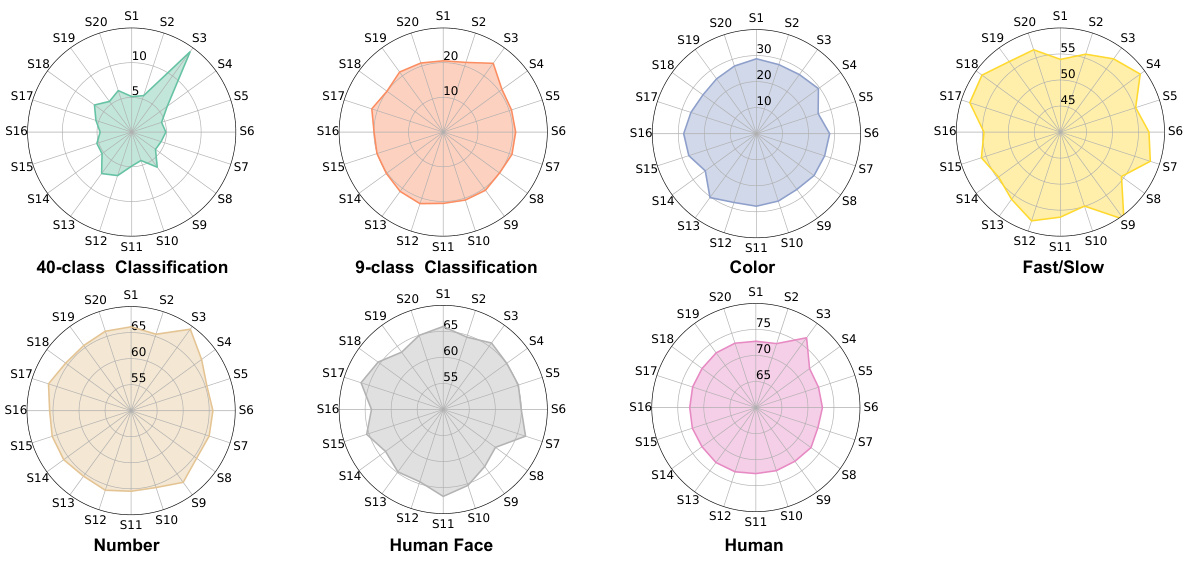
This table presents the classification accuracy of different EEG classifiers on seven visual perception tasks using raw EEG signals, PSD features, and DE features. The tasks assess the ability to decode various aspects of visual information from EEG data, including the fine-grained concept of video clips, coarser concepts, main object color, dynamic characteristics (Fast/Slow), number of main objects, presence of humans, and presence of human faces. Chance level accuracies are included for each task, and statistically significant results above chance are marked with an asterisk.
In-depth insights#
Dynamic Vision EEG#
The concept of “Dynamic Vision EEG” represents a significant advancement in the field of brain-computer interfaces (BCIs). It explores the decoding of dynamic visual information directly from EEG signals, moving beyond the limitations of previous studies that primarily focused on static images. This involves tackling the challenges of high temporal resolution required to capture rapid changes in brain activity associated with dynamic visual perception. The research likely entails developing advanced signal processing techniques to extract relevant features from EEG data, and innovative machine learning models to effectively map these features onto dynamic visual representations. Success in this area could lead to significant breakthroughs in BCIs, creating new possibilities for applications in virtual reality, assistive technologies for visually impaired individuals, and a deeper understanding of the neural mechanisms underlying visual processing. Large datasets of EEG recordings synchronized with dynamic visual stimuli are essential for training and validating such advanced models. The limitations of spatial resolution in EEG compared to other neuroimaging techniques will likely be a challenge that needs to be addressed. Ultimately, “Dynamic Vision EEG” research is paving the way for more natural and intuitive BCIs that can accurately reflect the complexity of human visual experiences.
EEG2Video Method#
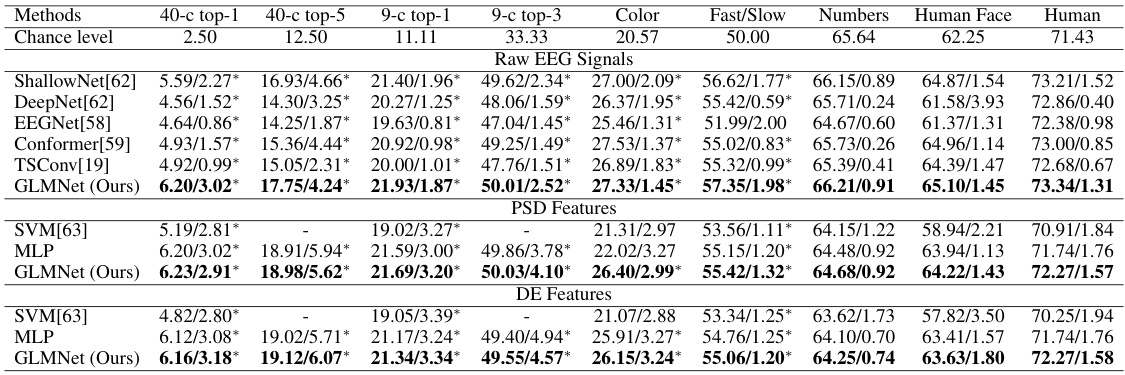
The EEG2Video method represents a novel approach to decoding dynamic visual perception from EEG signals. It leverages a Seq2Seq architecture, specifically employing Transformers, to effectively capture the continuous, high-temporal-resolution brain activity associated with visual processing. This design is crucial for representing the dynamic nature of visual information, unlike previous studies focusing on static stimuli. Furthermore, the method incorporates a dynamic-aware noise-adding (DANA) process which intelligently adjusts noise injection during the diffusion process based on the decoded dynamic information from the EEG. This innovative approach aims to more accurately reflect and recreate the rapid changes inherent in visual perception. Finally, the use of a fine-tuned inflated diffusion model enhances the quality of generated videos, by better capturing semantic and dynamic features. Overall, EEG2Video demonstrates a significant advancement in translating EEG data into dynamic visual reconstruction.
SEED-DV Dataset#
The SEED-DV dataset represents a significant contribution to the field of EEG-based video decoding. Its size (1400 dynamic video clips from 20 subjects across 40 concepts) addresses a critical gap in existing datasets, which largely focus on static images. The inclusion of diverse video content allows for a more comprehensive investigation of dynamic visual perception, moving beyond the limitations of previous studies. Careful annotation of meta-information, such as color, optical flow, and presence of humans/faces, makes the dataset highly valuable for exploring the boundaries of what can be decoded from EEG signals. This multi-faceted approach provides opportunities to assess various aspects of visual processing reflected in EEG, facilitating the development and evaluation of advanced decoding models and further advancing the understanding of brain-vision relationships.
Brain Area Analysis#
A brain area analysis section in a research paper investigating brain activity related to visual perception would ideally delve into the specific brain regions activated during different visual tasks, such as object recognition or motion processing. Electroencephalography (EEG) studies often focus on identifying electrodes showing significant activity changes during these tasks, correlating them to known anatomical locations. This analysis might reveal that occipital regions are primarily involved in object processing, while temporal regions are more engaged in motion perception. The study may use various methods, including topographical maps to visualize the distribution of activity across the scalp, or more advanced techniques like source localization to estimate the underlying neuronal activity. Statistical significance testing is crucial to determine which brain regions display activity reliably associated with the performed tasks. Finally, the analysis might discuss any unexpected activations or the limitations of EEG in precisely localizing brain activity, and relate findings to existing neuroscience literature.
Future of EEG-Video#
The future of EEG-video research is bright, promising significant advancements in brain-computer interfaces (BCIs) and our understanding of visual perception. High-resolution EEG and sophisticated signal processing techniques are crucial for accurately decoding complex dynamic visual information from brain activity. Larger, more diverse datasets are needed to improve model generalizability and address current limitations in accurately reconstructing videos from EEG, especially concerning complex scenes and fine-grained details. Improved deep learning models, particularly those leveraging advanced architectures like Transformers and diffusion models, will further enhance the quality and fidelity of video reconstruction. Future research might explore multimodal integration with other neuroimaging techniques (fMRI, MEG) to improve decoding accuracy and resolution. Ethical considerations regarding data privacy and potential misuse must also be carefully addressed to ensure responsible development and deployment of EEG-video technology.
More visual insights#
More on figures

This figure presents a statistical overview of the meta-information associated with the video clips in the dataset. It includes the proportion of videos featuring humans or human faces, the distribution of the number of objects in a scene, the distribution of the main color of the objects, and a histogram of the optical flow score (OFS), which indicates the level of dynamic movement in the videos. These statistics provide insights into the dataset’s diversity and visual characteristics, which are relevant for understanding the complexity of visual information that the EEG signals need to encode.
This figure illustrates the EEG2Video framework proposed in the paper. It shows the architecture of the GLMNet encoder which combines global and local embeddings from EEG signals. The main framework comprises a Seq2Seq model for predicting latent variables and semantic guidance, a video diffusion model for video generation using the predicted information, and a dynamic-aware noise-adding process incorporating dynamic information. Finally, a fine-tuned inflated diffusion UNet is used for video generation, guided by video-text pairs.
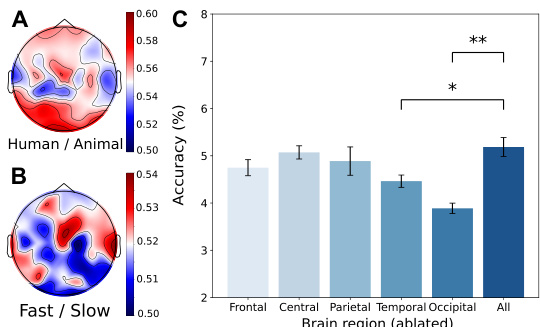
This figure presents a spatial analysis of brain activity related to visual perception tasks. Subfigure (A) shows a topographic map of the EEG electrodes’ accuracy in classifying Human/Animal videos, revealing that the occipital lobe shows high accuracy, supporting the visual cortex’s role in object recognition. Subfigure (B) displays a similar map for Fast/Slow video classification, indicating a strong contribution from the temporal lobe, aligned with its role in processing movement. Subfigure (C) demonstrates the impact of removing electrodes from various brain regions on classification accuracy. Removing occipital electrodes significantly reduces Human/Animal classification accuracy, highlighting the critical role of the visual cortex. Conversely, temporal lobe removal primarily affects Fast/Slow accuracy, supporting the temporal lobe’s role in dynamic visual perception.

This figure showcases several examples of videos reconstructed by the EEG2Video model. It demonstrates the model’s ability to reconstruct videos with both low and high dynamic content, featuring a range of subjects (animals, people), settings (beaches, mountains, indoor/outdoor), and actions (skiing, dancing, playing guitar). Each row displays a ground truth video (GT) and a corresponding video reconstructed using the proposed model (Ours). The goal is to visually illustrate the quality of video reconstruction achieved by the model across diverse video content.

The figure shows the confusion matrices for the 40-class classification task using the GLMNet model. Subfigure (A) displays the results using Differential Entropy (DE) features, while subfigure (B) shows the results using raw EEG signals. The matrices visualize the performance of the model by showing the counts of correctly and incorrectly classified instances for each class. The color intensity represents the proportion of predictions for a given true class that ended up in each predicted class. Darker colors indicate higher counts, and brighter colors indicate lower counts. This allows for a visual analysis of the model’s strengths and weaknesses in classifying different classes within the 40-concept video dataset. The diagonal line indicates correctly classified samples.
This figure provides a detailed overview of the experimental setup and data collection process. It showcases the meta-information visualization for the 40 video concepts (A), the data acquisition setup (B), the structure of a complete recording session with video blocks and rest periods (C), and the within-block structure which starts with a 3-second hint followed by five 2-second video clips from the same category (D). This comprehensive visualization aids in understanding the study design and how data were collected.

This figure shows various examples of video reconstruction results from EEG signals using the proposed EEG2Video method. The top row of each section displays the ground truth video frames, while the bottom row shows the corresponding frames reconstructed by the model. The examples include videos with both low and high dynamic content, demonstrating the model’s ability to handle diverse visual information.

This figure shows several examples of videos reconstructed by the EEG2Video model. Each row shows a ground truth video (GT) and the video reconstructed by the model (Ours). The examples demonstrate the model’s ability to reconstruct both low-dynamic videos (showing static or slow-moving scenes) and high-dynamic videos (showing fast-paced action or movement). The videos cover various categories, including animals, scenes, people, and activities.

This figure shows several examples of videos reconstructed by the EEG2Video model. The figure demonstrates the model’s ability to reconstruct videos with varying degrees of dynamic content. The top row shows the ground truth video frames and the bottom row presents the corresponding frames reconstructed by the EEG2Video model. The examples include static scenes (mountain, beach, face) and highly dynamic scenes (skiing, fireworks, dancing). The diversity of the examples illustrates the model’s capacity to handle various types of visual information.

This figure showcases the video reconstruction results of the proposed EEG2Video model. It presents several video clips, both with low and high dynamic content, that were successfully reconstructed using EEG signals. Each example consists of two rows: the top row displays the ground truth (GT) video frames, while the bottom row shows the frames generated by the EEG2Video model. This illustrates the model’s ability to accurately reconstruct a variety of video content, capturing both subtle and rapid changes in visual information.

This figure shows various video reconstruction results from the EEG2Video model. It demonstrates the model’s ability to reconstruct videos across different categories, including animals, plants, people, and activities. Each row displays a sequence of frames from both the ground truth video and the video reconstructed by the model. The figure illustrates both successes and limitations of the reconstruction approach.

This figure showcases examples where the EEG2Video model’s reconstruction of video clips was unsuccessful. It highlights instances where the model struggled to accurately capture either the semantic content or low-level visual details of the original videos. Despite some failures, certain features like shapes, movements, and scene dynamics were partially reconstructed in some cases. This demonstrates that while the model can generate video from EEG data, achieving perfect reconstruction is still a challenge.
Full paper#