↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Online Class Incremental Learning (OCIL) faces the challenge of catastrophic forgetting, where previously learned knowledge is lost when learning new classes from streaming data. Existing solutions like replay-based methods are resource-intensive, requiring extra memory to store past data. Exemplar-free methods, while resource-friendly, often lack accuracy.
F-OAL tackles this problem by employing a forward-only approach using a pre-trained frozen encoder and an Analytic Classifier updated via recursive least squares. This eliminates the need for backpropagation, thus reducing memory and computational costs while maintaining high accuracy. This exemplar-free approach and recursive least squares update are key to the efficiency and accuracy gains. The results showcase F-OAL’s robustness and effectiveness in various OCIL scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents F-OAL, a novel approach to online class incremental learning that is both accurate and resource-efficient. This addresses a critical challenge in machine learning and opens up new avenues of research for handling streaming data.
Visual Insights#

This figure shows the architecture of the proposed F-OAL method. It consists of a frozen pre-trained encoder (using Vision Transformers - ViT blocks) that extracts features. These features are fused, expanded into a higher dimension, and used to update a linear classifier. The key is that the encoder is frozen and the classifier is updated using recursive least squares, making the process forward-only and memory efficient. The R matrix stores historical information for updating the classifier.

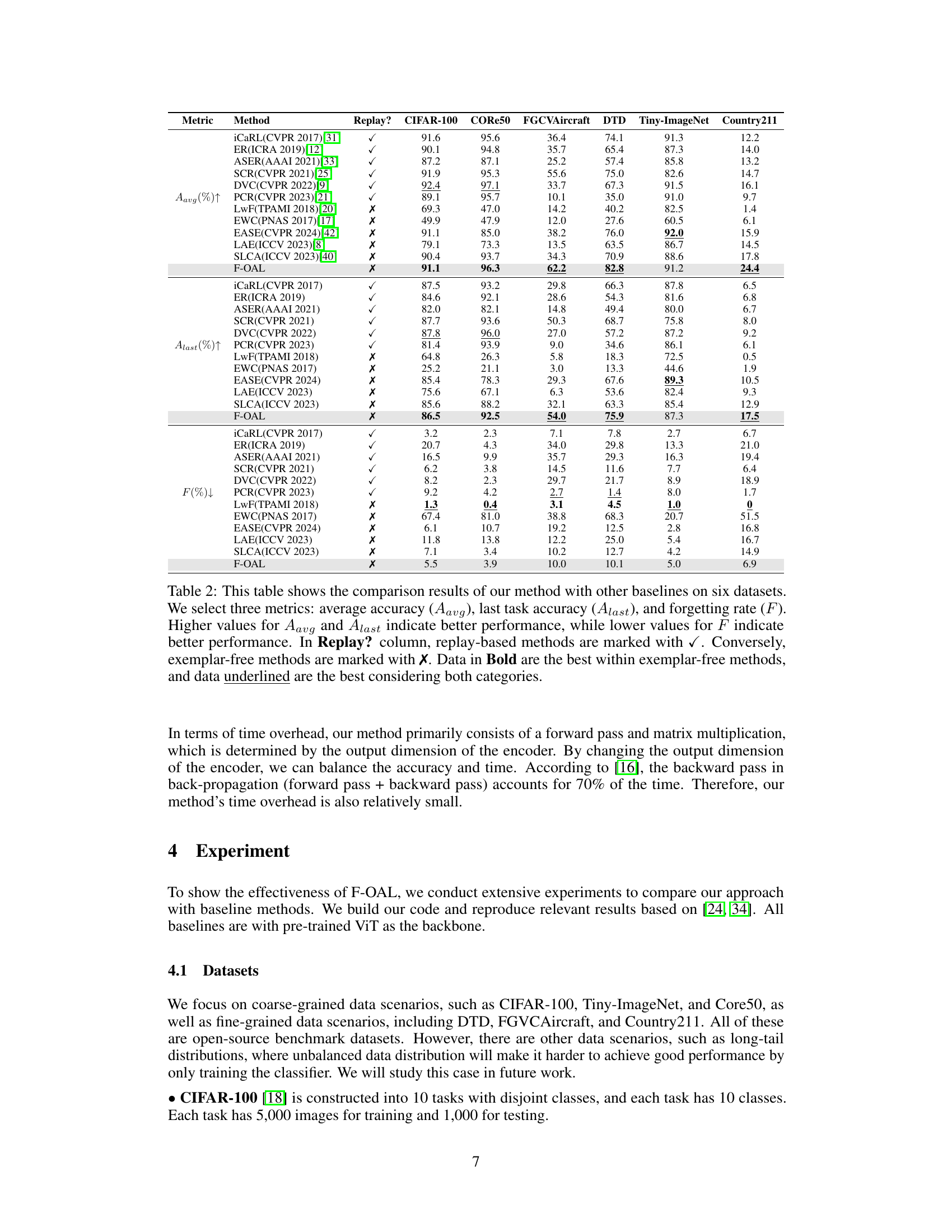
This table compares the performance of the proposed F-OAL method against several baseline methods across six different datasets. The comparison uses three metrics: average accuracy across all tasks, accuracy on the last task, and forgetting rate. The table also indicates whether each method uses an exemplar replay strategy.
In-depth insights#
OCIL’s Forgetting#
OCIL, or Online Class Incremental Learning, faces a significant challenge: catastrophic forgetting. As new classes are introduced sequentially and past data is unavailable, the model struggles to retain previously acquired knowledge. This forgetting stems from two key issues: 1) the complete network update via loss functions, hindering nuanced feature capture and leading to a diminished overall representation, and 2) the prevalent recency bias of backpropagation algorithms, making the model overly sensitive to the most recently encountered data. Existing solutions like replay-based methods mitigate forgetting by storing old data for review, but this is memory-intensive. Exemplar-free methods, while resource-efficient, often suffer from accuracy loss due to the limitations inherent in their approach. Addressing OCIL’s forgetting is critical for developing practical online learning systems capable of adapting to ever-changing data streams.
F-OAL Algorithm#
The F-OAL algorithm presents a novel approach to online class incremental learning (OCIL) by employing a forward-only, exemplar-free strategy. Its core innovation lies in eschewing backpropagation, instead utilizing recursive least squares to update a linear classifier. This design choice significantly reduces both the memory footprint and computational cost compared to traditional replay-based methods. By integrating a pre-trained, frozen encoder with feature fusion, F-OAL aims to mitigate catastrophic forgetting by providing robust feature representations. The algorithm’s forward-only nature makes it particularly well-suited for streaming data scenarios where previous data is inaccessible. While promising, a limitation is the reliance on a pre-trained encoder, which might hinder its applicability when suitable pre-trained models are unavailable. Further research could focus on improving the algorithm’s robustness to noisy data and exploring alternative methods for feature representation that are less dependent on external resources.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a detailed comparison of the proposed F-OAL method against existing state-of-the-art online class incremental learning (OCIL) techniques. This would involve multiple datasets, each offering unique challenges (e.g., image complexity, class distribution). Key metrics such as average accuracy, last task accuracy, and forgetting rate should be meticulously reported, ideally with error bars for statistical robustness. The choice of benchmark datasets is critical; a diverse selection showcasing variations in image types, class similarity, and data size would strengthen the evaluation. Visualizations, perhaps bar charts or tables, would effectively convey the performance differences across various methods. Importantly, a discussion of the results is crucial, explaining any unexpected performance patterns and relating them to the inherent properties of each dataset and algorithm. The analysis should carefully highlight the strengths and weaknesses of F-OAL compared to existing methods. Statistical significance testing should be considered and explicitly mentioned, enhancing the reliability of the conclusions.
Resource Efficiency#
The concept of resource efficiency in machine learning, particularly within the context of online class incremental learning (OCIL), is paramount. Memory footprint is a major concern as traditional methods often store past data, leading to scalability issues. The paper champions exemplar-free approaches, avoiding the memory overhead associated with storing past examples. Further efficiency gains arise from the algorithm’s forward-only nature, eliminating the computational cost of backpropagation. This approach drastically reduces training time, thus making the model more resource efficient. Pre-trained encoders are another key aspect of resource efficiency, offering a shortcut to training by leveraging pre-existing knowledge, reducing the overall computational burden. The paper explicitly highlights the low resource demands, enabling practical applications in resource-constrained environments. In essence, the algorithm is designed to excel in scenarios where resources are limited, making it a more sustainable and potentially impactful contribution to the field.
Future Extensions#
Future research directions could explore improving F-OAL’s robustness to noisy or incomplete data streams, a common challenge in online learning. Investigating alternative encoder architectures beyond Vision Transformers, such as CNNs or hybrid models, could broaden applicability and potentially improve efficiency. The impact of different regularization techniques on the stability and performance of the linear classifier warrants further investigation. Addressing class imbalance in the online setting is another important area. Finally, a systematic exploration of transfer learning strategies to leverage knowledge from related tasks could significantly enhance F-OAL’s performance in low-data scenarios.
More visual insights#
More on figures

The figure is a bar chart showing the peak GPU memory usage (in GB) for various online class incremental learning (OCIL) methods on the CIFAR-100 dataset. The chart compares F-OAL against several baseline methods, highlighting the significantly lower memory footprint of F-OAL due to its exemplar-free and gradient-free nature. Replay-based methods (those with 5000 buffer size) are shown for comparison, illustrating their substantially higher memory consumption.

This figure visualizes the weights of a linear classifier trained using the proposed F-OAL method on the DTD dataset. It compares the L2 norm of weights for the current task being learned against the L2 norm of weights for previously learned tasks (completed tasks). The goal is to show that F-OAL mitigates the ‘recency bias’ problem; a common issue in incremental learning where the model overemphasizes recently seen data and forgets previously learned information. The graph shows that in F-OAL, the weights of the current task are not significantly larger than those of previous tasks, indicating successful mitigation of recency bias.
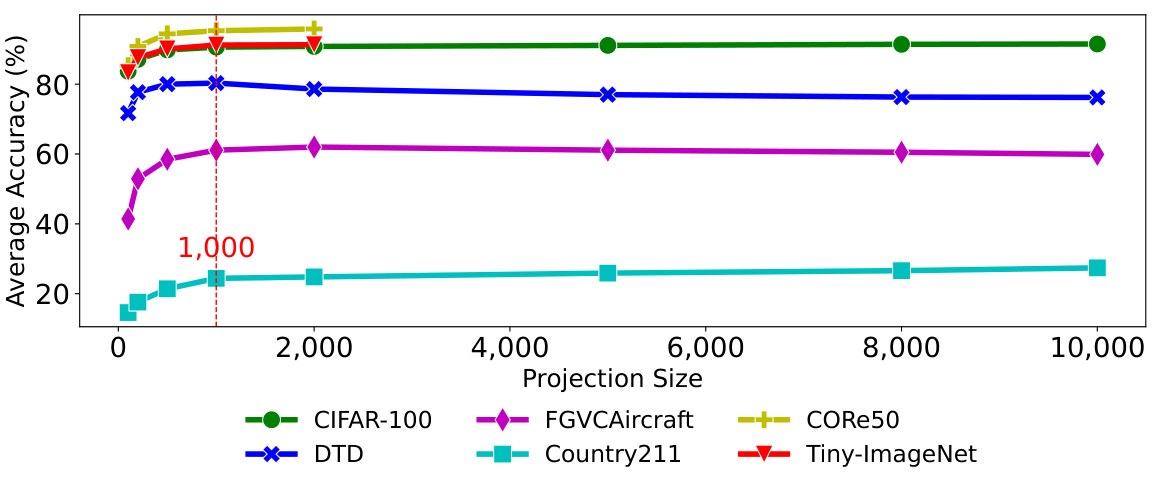
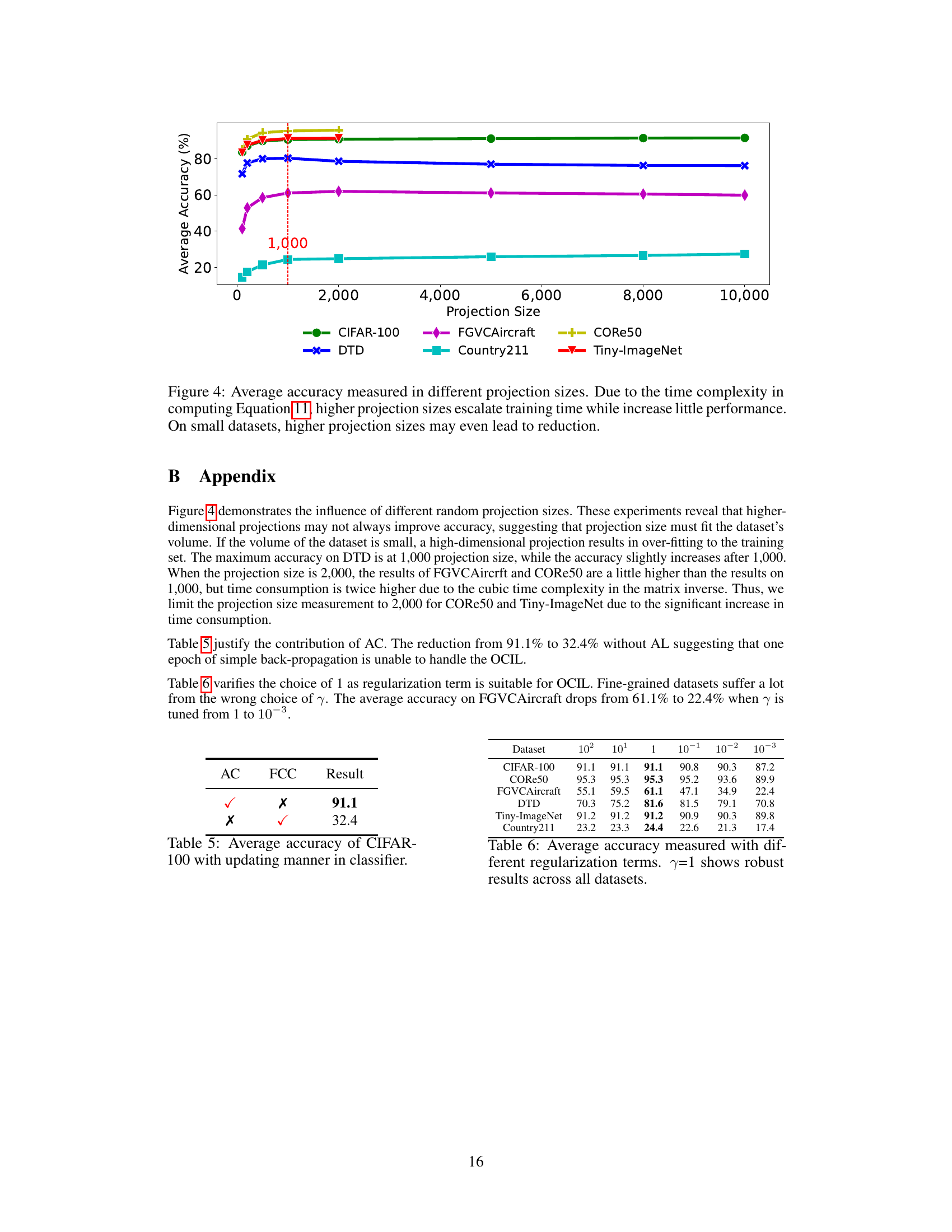
This figure shows the impact of different projection sizes on the average accuracy of the model across six different datasets. Higher projection sizes increase training time significantly due to the computational cost of the recursive update formula, but do not proportionally improve accuracy. In fact, for smaller datasets, increasing the projection size can even slightly reduce accuracy.
More on tables
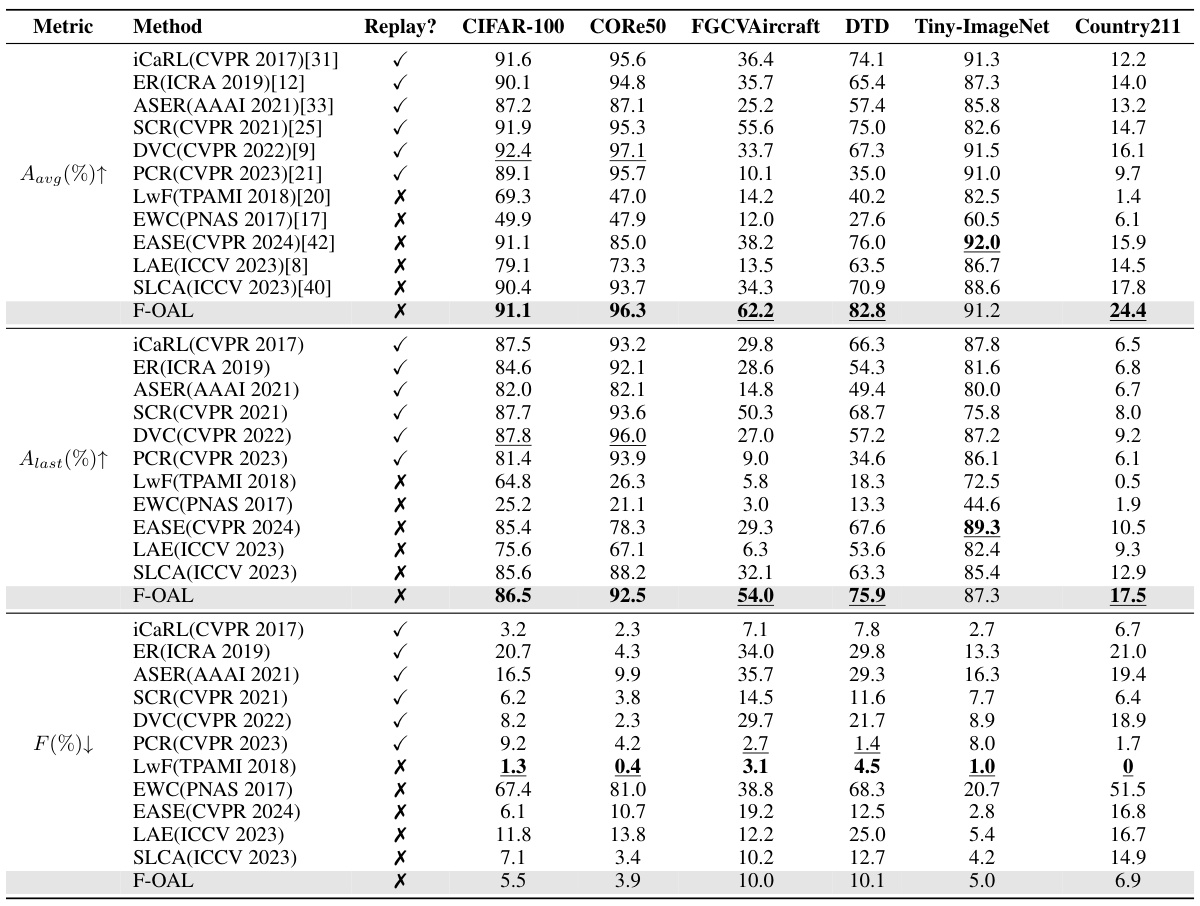
This table compares the performance of the proposed F-OAL method against several baseline methods across six benchmark datasets for online class incremental learning. The table shows the average accuracy, last task accuracy, and forgetting rate for each method. Replay-based and exemplar-free methods are distinguished, and the best results within each category, as well as overall best results, are highlighted.

This table compares the training time of various class incremental learning methods, including the proposed F-OAL, across six benchmark datasets (CIFAR-100, CORe50, FGVCAircraft, DTD, Tiny-ImageNet, and Country211). Training time includes feature extraction. The table highlights the efficiency of F-OAL in terms of training speed by comparing it to other exemplar-free and replay-based methods. Replay-based methods use a memory buffer of 5000 samples, whereas F-OAL is exemplar-free, meaning it does not store previous samples. The fastest training times for each dataset are highlighted in bold.

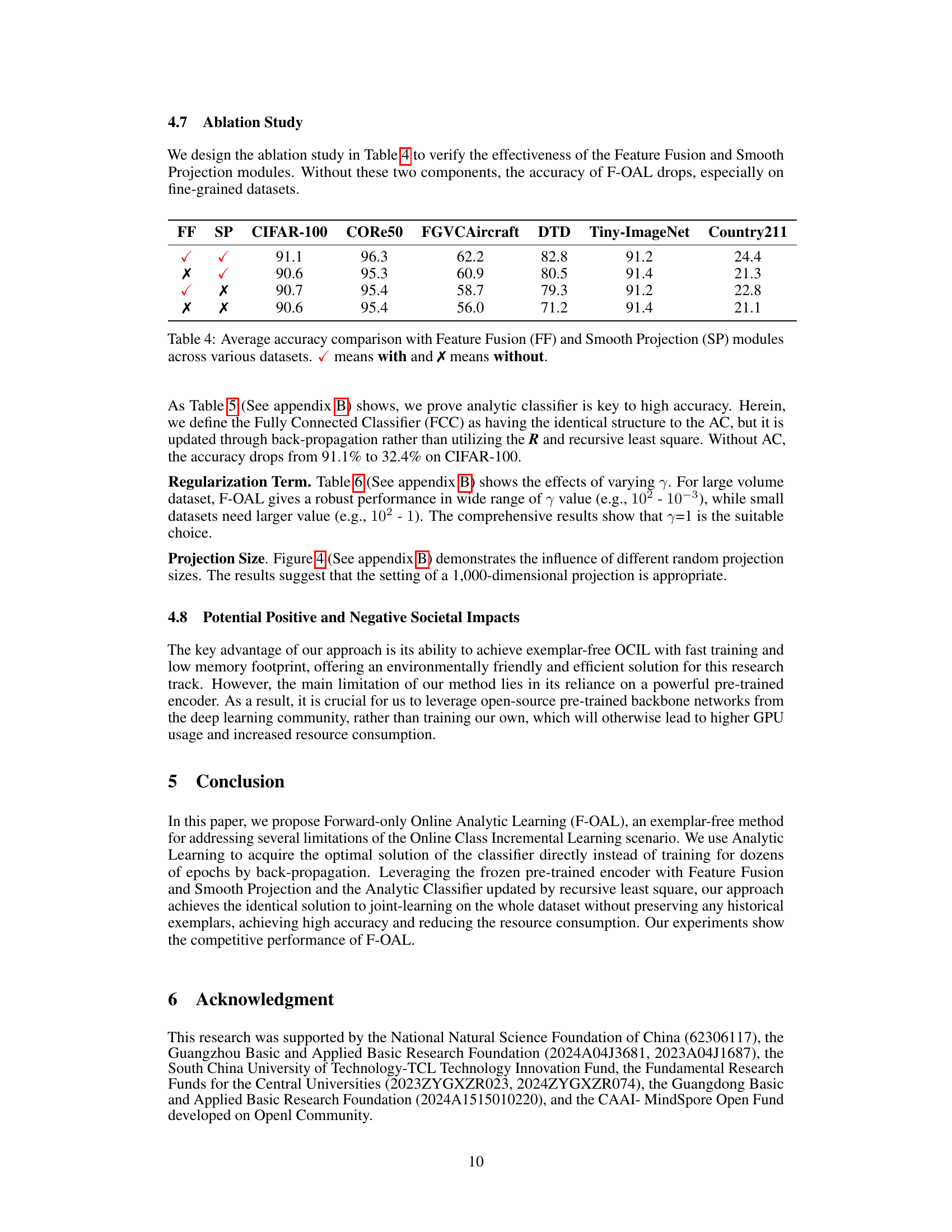
This ablation study table shows the impact of Feature Fusion and Smooth Projection on the F-OAL model’s accuracy across six datasets. It demonstrates that both modules contribute positively to the model’s performance, especially on fine-grained datasets.
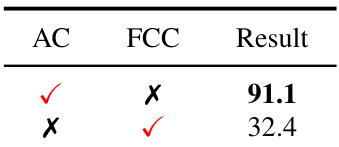
This table compares the average accuracy results on the CIFAR-100 dataset using two different classifier updating methods: Analytic Classifier (AC) and Fully Connected Classifier (FCC). The results demonstrate the superior performance of the AC method compared to the FCC method, highlighting the effectiveness of the proposed analytic classifier approach in achieving higher accuracy.

This table presents the average accuracy results obtained using different regularization terms (γ) across six datasets. The results demonstrate the robustness of the model’s performance when using a regularization term of 1. Variations in accuracy are observed across different datasets and regularization terms, showcasing the impact of this hyperparameter on model performance.
Full paper#