↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating realistic 3D animal models from text descriptions is a challenge because existing methods often struggle with anatomical accuracy and diversity. Previous approaches relied heavily on either text or image input alone, limiting creativity and control. They also often produced inconsistent or unrealistic results. This resulted in limitations in the visual quality and diversity of generated models.
This paper introduces YOUDREAM, which addresses these issues by incorporating a multi-agent LLM (Large Language Model) to generate 3D poses from text descriptions. The method uses these poses to guide a text-to-image diffusion model for generating multiple consistent 2D views. These views are then used to reconstruct the 3D animal model, resulting in significantly improved anatomical accuracy and the ability to create novel, imaginary animals. This fully automated pipeline offers a user-friendly way to generate high-quality 3D animal assets, even for unreal creatures.
Key Takeaways#
Why does it matter?#
This paper is important because it presents YOUDREAM, a novel method for generating high-quality, anatomically consistent 3D animal models using a text-to-image diffusion model. This significantly advances text-to-3D generation, particularly for complex and creative animal designs, overcoming limitations of existing methods in terms of anatomical accuracy and diversity. Researchers in computer graphics, AI art, and 3D modeling will find this approach valuable for creating realistic and imaginative animal assets for a broad range of applications.
Visual Insights#

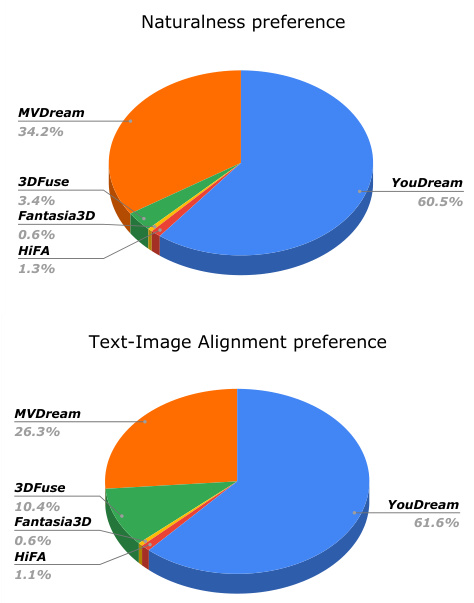
This figure showcases the results of three different text-to-3D generation methods (HiFA, MVDream, and the authors’ YOUDREAM) on generating imaginary creatures. The prompts used for generation are provided below each row of images. The results demonstrate that YOUDREAM can generate more anatomically consistent and high-quality results, as compared to the existing baselines. The 3D poses used as input for YOUDREAM are detailed in Section F.
This table lists the licenses associated with the various open-source code repositories mentioned in the paper. These are primarily the codebases for various baselines used for comparison against the authors’ method. The licenses are critical for understanding usage rights and permissions when using any of the referenced code in future projects.
In-depth insights#
3D Animal Genesis#
Generating three-dimensional animal models is a complex undertaking, requiring a sophisticated approach to realistically capture their diverse anatomies and poses. A key challenge lies in balancing artistic control with the fidelity of the generated model. Methods employing text-to-image diffusion models offer a promising pathway, but often struggle with anatomical consistency and the generation of truly novel, imaginary creatures. Incorporating 3D pose priors significantly improves results, providing structural guidance and enabling more consistent multi-view rendering. However, creating these priors manually is time-consuming. Thus, leveraging large language models (LLMs) to automatically generate or adapt poses from a library of existing models is crucial to make this process feasible. Furthermore, integrating these various components — LLMs, diffusion models, and 3D pose representation — into a unified, automated pipeline remains a significant technological hurdle, presenting opportunities for future innovation. Finally, careful consideration of ethical implications and the responsible use of AI-generated content is vital.
Pose ControlNet#
A Pose ControlNet, within the context of a research paper on 3D animal generation, likely refers to a neural network component designed for precise control over the generated animal’s pose. This network takes a 2D pose as input, possibly derived from a 3D pose projection, and conditions a text-to-image diffusion model. The core function is to ensure anatomical and geometrical consistency across different views of the 3D model, preventing common issues like the ‘Janus-head’ problem (where inconsistencies arise between views). The design likely leverages existing ControlNet architectures, adapting them for the complexities of representing animal poses. Training likely involves a dataset of images paired with 2D pose annotations to learn the mapping between pose and image features. This specialized ControlNet would be a key innovation, enhancing control and realism in generated 3D animal models compared to prior methods that rely solely on text or image inputs.
Multi-agent LLM#
The utilization of a multi-agent large language model (LLM) framework represents a novel approach to tackling the complex task of 3D animal pose generation. Instead of relying on a single LLM to directly generate poses from textual descriptions, which often results in inconsistencies and inaccuracies, this method leverages three specialized agents: a Finder, an Observer, and a Modifier. This division of labor allows for a more refined and controlled process. The Finder initially selects a base pose from a pre-defined library, which is then refined by the Observer, which analyzes the input text and proposed pose, providing instructions to the Modifier. The Modifier then adapts the base pose based on those instructions, leading to a final pose that is both consistent with anatomical knowledge and accurate to the user’s intent. This multi-agent strategy enhances the system’s capacity to handle novel and complex animal descriptions, improving the overall accuracy and diversity of generated poses. The reliance on a pre-existing library of poses is also a strength, reducing computational overhead compared to training a new model from scratch. This structured methodology enhances control and flexibility, providing a powerful tool for creative applications.
Method Limitations#
A thoughtful analysis of the limitations section in a research paper focusing on 3D animal generation using diffusion models would highlight several key areas. Data limitations are crucial; the reliance on existing 2D pose datasets might restrict the diversity and realism of generated animals, especially for less-common species. Pose generation limitations stem from the use of LLMs for adapting poses from a limited library; this approach could struggle with generating highly unusual or creative animal poses. ControlNet limitations relate to the diversity and training data, possibly impacting the generation of highly detailed or out-of-domain animals. Computational constraints concerning the high resource requirements for NeRF training would be another important limitation, making the method less accessible to many researchers. Geometric inconsistencies and potential issues arising from multi-view consistency across differing poses need thorough discussion. Finally, it’s crucial to address the subjectivity in evaluation, highlighting the limitations of user studies and the need for more objective metrics for assessing quality and realism.
Future Directions#
Future research directions for anatomically consistent 3D animal generation could explore several promising avenues. Improving the diversity and realism of generated animals is crucial, potentially by expanding the training dataset with more diverse species and poses, or incorporating other modalities such as videos or point clouds. Enhancing the controllability of the system is another key area, allowing users more fine-grained control over the animal’s anatomy, pose, and style through intuitive interfaces. Addressing the limitations of the current multi-agent LLM approach by exploring alternative methods for 3D pose generation that require less human intervention, including more sophisticated neural networks or data-driven techniques, is also important. Finally, exploring the use of advanced rendering techniques for producing higher-quality and more photorealistic 3D assets would enhance the visual appeal and overall impact of the generated animal models.
More visual insights#
More on figures

This figure compares the 3D animal generation results of three different methods: HiFA, MVDream, and the authors’ proposed method, YOUDREAM. For each of several prompts describing fantastical creatures (e.g., a llama with octopus tentacles), the figure shows the 3D models generated by each method. The results highlight YOUDREAM’s ability to generate higher-quality, more anatomically consistent models, especially when compared to methods relying solely on text-based input. The 3D pose controls used by YOUDREAM are referenced, indicating the method’s ability to achieve fine-grained control over the generated animal’s anatomy.
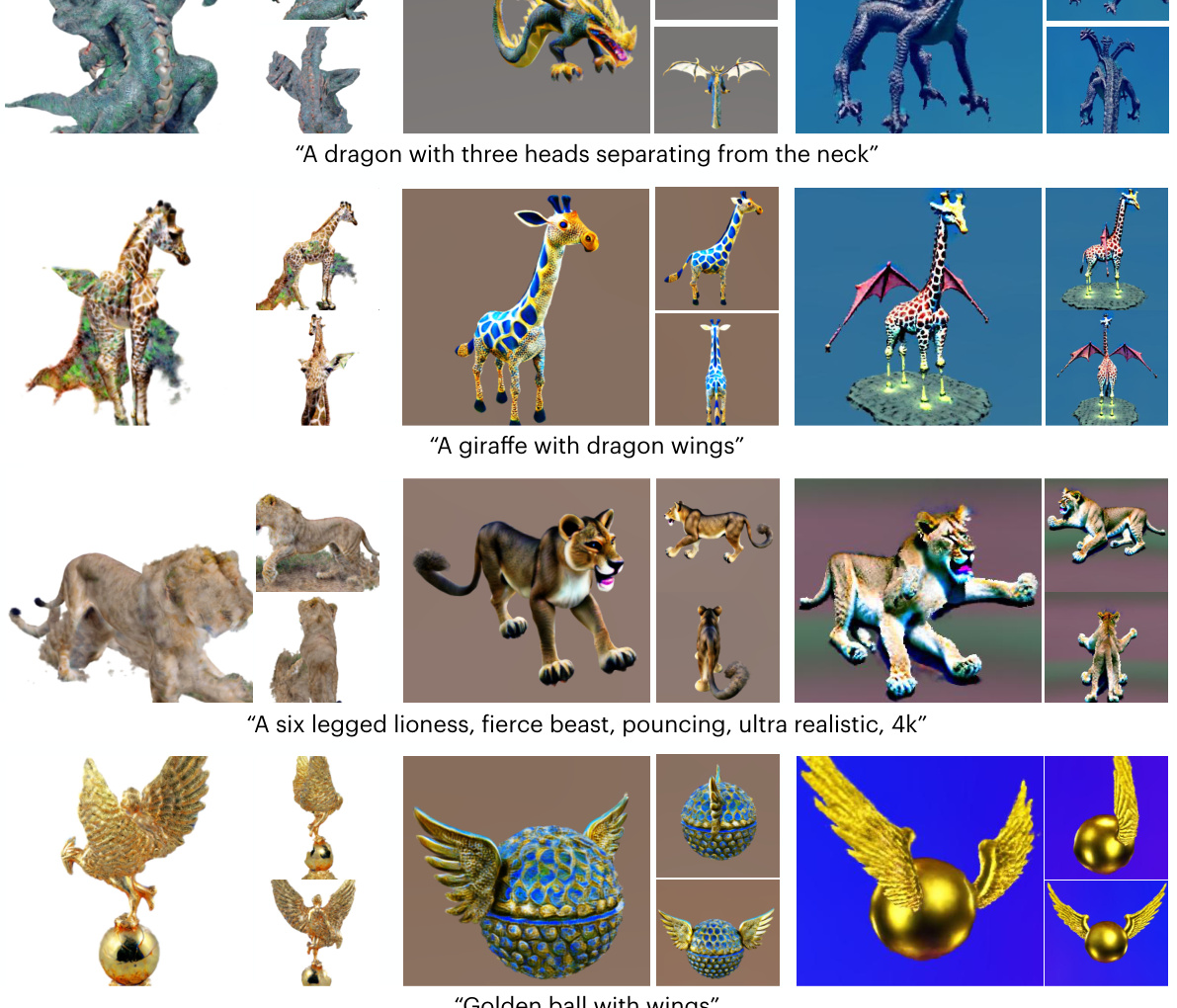
This figure showcases the results of three different text-to-3D animal generation methods: HiFA, MVDream, and the authors’ proposed method, YOUDREAM. Each row shows the same prompt given to all three methods, demonstrating that YOUDREAM, guided by both text and 3D pose, produces more realistic and creative results than the other methods which rely solely on text input. The differences highlight YOUDREAM’s ability to generate even unreal animals with complex anatomies.
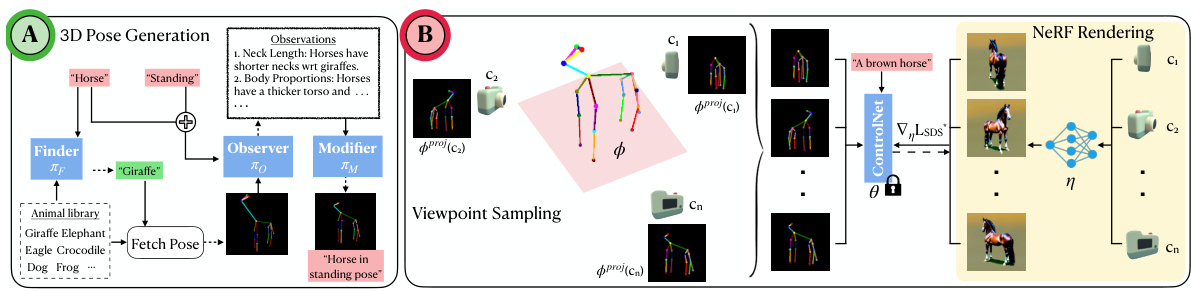
This figure illustrates the automatic pipeline for generating 3D animals using YOUDREAM. It starts with a user providing the name and pose description of the desired animal. A multi-agent large language model (LLM) then generates a 3D pose based on a library of existing animal poses. This 3D pose is used to generate 2D views via viewpoint sampling. These views are then fed into a ControlNet-guided diffusion model, which produces the final 3D animal model using NeRF rendering. The pipeline is fully automated, requiring minimal human intervention.
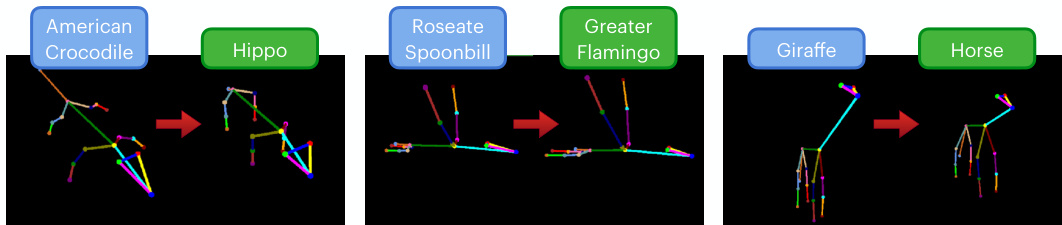
This figure shows examples of how the multi-agent LLM system modifies 3D poses of animals. The system consists of three agents: Finder, Observer, and Modifier. The Finder selects an initial pose from a library based on the requested animal. The Observer analyzes the differences between the initial pose and the desired pose (described in text), suggesting necessary adjustments. Finally, the Modifier applies those adjustments to the initial pose to generate a modified pose representing the desired animal in the specified pose. The figure visually demonstrates this process for three different animals: crocodile, spoonbill, and giraffe. Each example shows the desired animal, the initial pose selected by the Finder, and the final modified pose generated by the system.

This figure compares the performance of YOUDREAM against three baseline methods (HIFA, Fantasia3D, and 3DFuse) on generating common animals from text descriptions. The results show that YOUDREAM outperforms the baselines in terms of generating high-quality, anatomically consistent 3D animal models. While the baselines show inconsistencies in anatomy and geometry, YOUDREAM generates more realistic and accurate results.
This figure compares the 3D animal generation results of three different methods: HiFA, MVDream, and the authors’ proposed method, YOUDREAM. Each row shows the results for a different animal prompt, demonstrating the ability of YOUDREAM to generate more realistic and imaginative creatures compared to the other two methods. The figure highlights the importance of using 3D pose control for generating high-quality, anatomically consistent animals.

This figure shows an ablation study on the effects of using an initial shape and pose control in the YOUDREAM model. It demonstrates the impact of each component on the quality of the generated 3D animal models. The results indicate that both initial shape and pose control are beneficial, with pose control being particularly important for maintaining 3D consistency across multiple views.

This ablation study demonstrates the impact of different scheduling techniques on the quality of generated images. The results indicate that using only guidance scaling or only control scaling leads to unnatural color artifacts in the generated images. The use of neither scaling technique results in artifacts, such as grass appearing at the feet of the elephant, likely due to the lower diversity of the ControlNet compared to the Stable Diffusion model used.

This figure demonstrates the versatility of the YOUDREAM model by showcasing its ability to generate images of animals with various styles and compositional elements. The top row shows the input prompts. The subsequent rows illustrate variations in the generated images based on different styles and compositions, all while maintaining a good level of detail and realism. This highlights the model’s ability to incorporate diverse artistic directions, not solely relying on a single, literal interpretation of the text prompt.
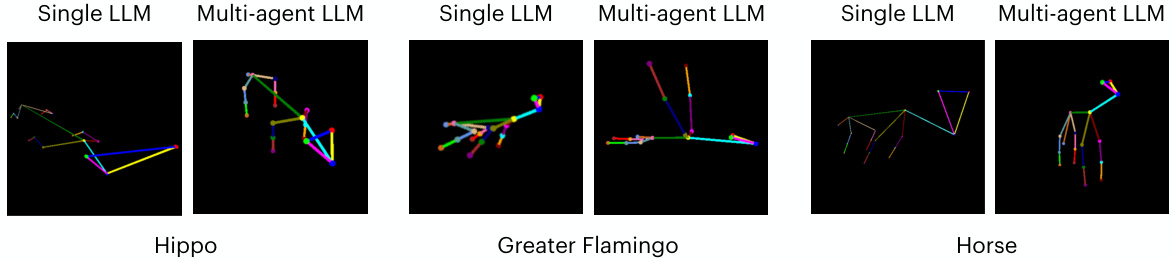
This figure compares the performance of a single Large Language Model (LLM) against a multi-agent LLM system for generating 3D animal poses. The comparison is shown for three different animals: a hippopotamus, a greater flamingo, and a horse. For each animal, the figure displays the 2D projection of the 3D pose generated by both methods. The visual difference highlights the improved pose generation quality achieved through the multi-agent approach.

This figure compares the performance of YOUDREAM’s TetraPose ControlNet against OpenPose ControlNet for generating images of animals. It shows that, unlike YOUDREAM, the OpenPose ControlNet either fails to follow the provided pose control or generates images with unnatural anatomical features. The example images provided are of a gazelle, a horse, and a baboon.
This figure compares the results of three different text-to-3D animal generation methods: HiFA, MVDream, and the authors’ proposed method, YOUDREAM. Each row shows the generated 3D models for a different animal based on a textual description provided as a prompt. The purpose is to demonstrate that YOUDREAM, which incorporates 3D pose controls, can generate more imaginative and anatomically consistent results, especially compared to methods that rely solely on text prompts.

This figure demonstrates the robustness of the YOUDREAM model to different random seeds. Four different images of a tiger are shown, each generated using a different random seed. While the overall pose and general characteristics of the tiger remain consistent, minor variations appear in details like the exact pattern and coloring of its stripes, and the expression on its face. This illustrates that YOUDREAM produces similar but not identical results when provided with different random seeds, thereby showcasing its stability while preserving creative diversity.

This figure compares different scheduling strategies for guidance and control in the training process of the proposed model. The results suggest that using a cosine schedule for both guidance and control leads to oversaturation, while a cosine schedule for guidance and a linear schedule for control results in over-smoothed textures. The best results are obtained using a linear schedule for both.
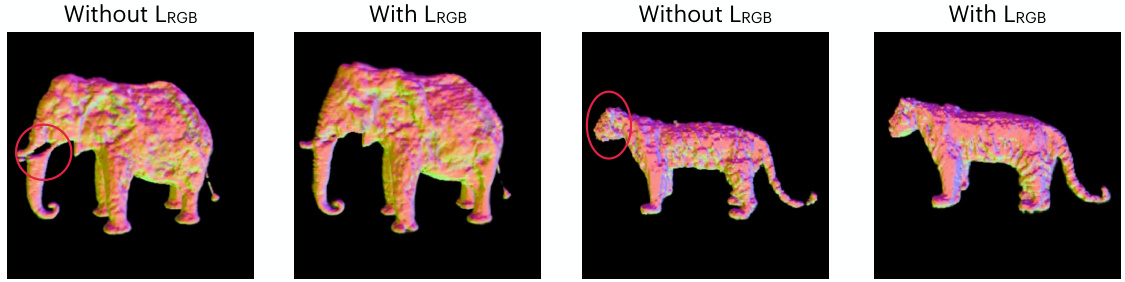
This figure demonstrates the impact of using the LRGB loss function in the YOUDREAM model. The left panels show results without LRGB, exhibiting hollow geometry and flickering artifacts, especially noticeable in the elephant’s trunk and tiger’s chin. The right panels present results with LRGB, showing improved geometry and reduced flickering. The highlighted regions show the areas where the artifacts are most apparent.

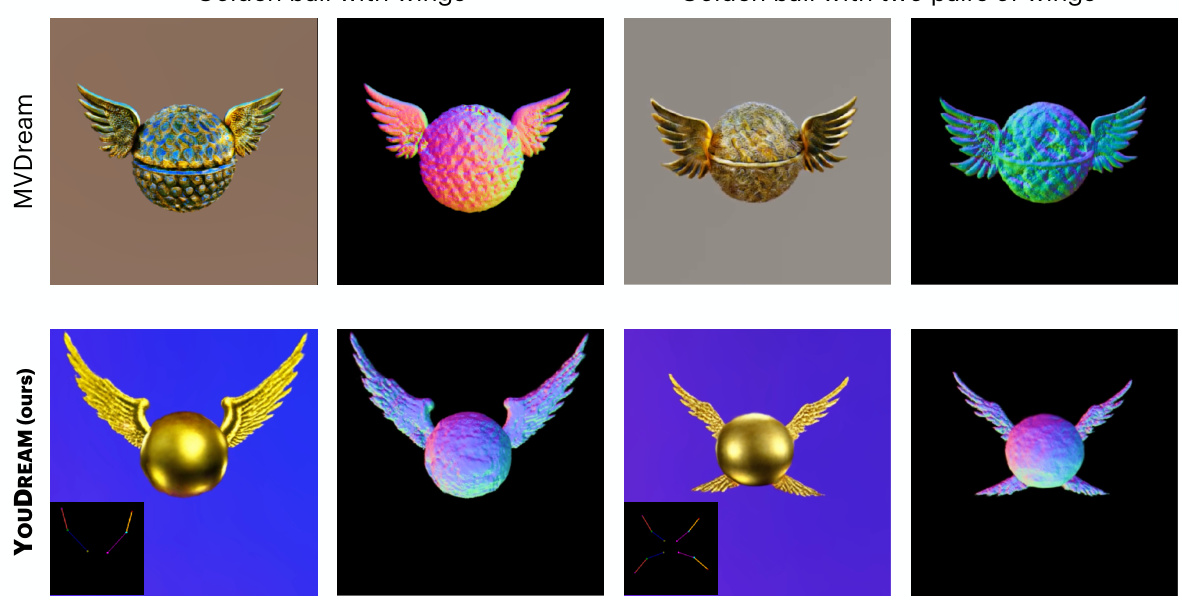
The figure compares the results of the proposed method, YOUDREAM, and the baseline method, MVDream, in generating images of a pangolin and a giraffe. The comparison highlights YOUDREAM’s superior ability to generate more realistic and texturally accurate animal models compared to MVDream.
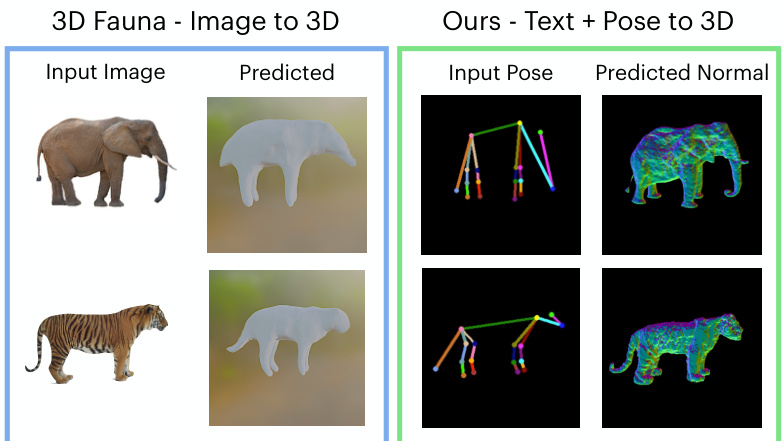
This figure compares the 3D animal generation results of the proposed YOUDREAM method and the baseline method 3DFauna. The top row shows an input image of an elephant and a tiger for the 3DFauna method, and the corresponding generated 3D models. The bottom row shows the input pose (a skeleton) for the YOUDREAM method, and the generated 3D models for the elephant and tiger. The comparison highlights that YOUDREAM produces 3D models with significantly more detailed geometry compared to 3DFauna.

This figure compares YOUDREAM against several other text-to-3D generation methods (Stable Dreamfusion, ProlificDreamer, and LucidDreamer). It demonstrates that YOUDREAM produces superior results in terms of image quality and adherence to the text prompt. The comparison is performed by showing the front and side views of two different animals generated using each method. The two animals are an elephant and a llama with octopus tentacles.

This figure shows the results of generating out-of-distribution (OOD) assets using the proposed automatic pipeline. The pipeline uses a multi-agent large language model (LLM) to generate 3D poses for animals not included in the initial training data. The figure demonstrates how the LLM selects an existing animal pose as a starting point and modifies it to create the desired OOD animal. Specifically, it shows that a roseate spoonbill pose is used as a basis for generating the clownfish pose, and a German shepherd pose is used to generate the four-legged tarantula pose. The resulting 3D models are then generated using these modified poses.

This figure demonstrates the impact of increasing the resolution of the Neural Radiance Field (NeRF) used in the 3D animal generation process. By doubling the dimensions of the NeRF (from 128x128x128 to 256x256x256), a significant improvement in the sharpness and detail of the generated 3D tiger model is observed. This suggests that higher-resolution NeRFs can lead to more realistic and visually appealing 3D animal models, even without adjusting other hyperparameters.
This figure compares the results of generating imaginary creatures using three different methods: HiFA, MVDream, and the authors’ proposed method, YOUDREAM. The input for each method is a text prompt describing an unusual creature (e.g., a llama with an octopus body). The figure shows that YOUDREAM is superior in generating high-quality, anatomically consistent results that are more closely aligned with the user’s creative intent compared to the other methods. The 3D pose controls utilized by YOUDREAM for the creation of these images are further explained in section F of the paper.

This figure demonstrates the ability of the YOUDREAM model to generate imaginary creatures based on artistic text prompts and 3D pose controls. It compares the results of YOUDREAM to those of two other methods, HiFA and MVDream, highlighting YOUDREAM’s superior ability to generate anatomically consistent and visually compelling results, especially for unreal creatures that are difficult to describe solely through text. The 3D pose controls, detailed in section F of the paper, provide a crucial element of artistic control for YOUDREAM.

This figure shows examples of how the multi-agent large language model (LLM) system modifies 3D poses of animals. The system consists of three agents: a Finder, an Observer, and a Modifier. The Finder selects a base animal pose from a library that’s similar to the target animal. The Observer then analyzes the differences between the base pose and the desired animal and pose, generating instructions for the Modifier. Finally, the Modifier adjusts the base pose to match the target animal and pose. The figure showcases this process for several animals, illustrating the system’s ability to generate realistic and diverse poses.

This figure demonstrates the robustness of the YOUDREAM model to different random seeds. Four different images of a tiger are shown, each generated with a different random seed. While the overall pose and structure of the tiger remain consistent, subtle variations in the details, such as the stripes and facial features, are observed. This highlights the ability of YOUDREAM to consistently generate high-quality results even when dealing with stochastic components of the model.
Full paper#



















