↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) rapidly become outdated due to the constant influx of new information. Existing solutions like online finetuning are computationally expensive and prone to catastrophic forgetting, while retrieval-augmented methods suffer from limitations in knowledge selection. These challenges necessitate efficient online adaptation techniques to keep LLMs up-to-date.
This paper proposes MAC, a novel framework that addresses these challenges. MAC employs amortization-based meta-learning to compress new documents into compact modulations stored in a memory bank. Instead of directly updating the LLM, MAC leverages an aggregation network to select and combine relevant modulations based on the input question, thereby enabling efficient adaptation without gradient updates. The experiments demonstrate that MAC outperforms state-of-the-art methods in online adaptation speed, memory efficiency, and knowledge retention.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel and efficient online adaptation framework for large language models (LLMs). This addresses a critical challenge in the field of LLMs: keeping them up-to-date with rapidly changing information. The proposed method, MAC, provides substantial improvements over existing techniques in terms of speed, memory efficiency, and knowledge retention, opening new avenues for research into efficient and effective online learning for LLMs.
Visual Insights#

The figure illustrates the Memory of Amortized Contexts (MAC) framework. The left side shows the training phase, where context documents are processed by an amortization network to produce compact PEFT modulations. These modulations are then aggregated by an aggregation network, conditioned on the question, to create a single target modulation. This modulation is applied to a frozen language model (@base) to generate an answer. The right side shows the online adaptation phase: the amortized contexts are stored in a memory bank (M), and during inference, the memory bank is used in conjunction with the question to adapt the frozen LM to new information without needing further gradient updates.
This table compares the performance of MAC against various online finetuning baselines on three question answering datasets: StreamingQA, SQUAD-Seq, and ArchivalQA-Seq. It shows the exact match (EM) and F1 scores achieved by each method after adapting the language model to a stream of documents. The results highlight MAC’s superior performance and efficiency compared to the baselines, with CaMeLS showing memory limitations on larger models.
In-depth insights#
Amortized Context#
The concept of “Amortized Context” in the context of language model adaptation centers on efficiently encoding and storing contextual information. Instead of computationally expensive fine-tuning for each new context, amortization techniques compress the relevant information from new documents into compact representations or “modulations.” These modulations are stored in a memory bank and retrieved/aggregated based on the current query, enabling efficient adaptation without gradient updates. This avoids catastrophic forgetting by not modifying the main language model’s parameters, while still allowing the model to leverage new knowledge effectively. The memory efficiency is further improved by using random sub-sampling of documents during training and hierarchical aggregation techniques during inference, enabling the handling of a very large corpus of contexts. The approach demonstrates strong knowledge retention and improved performance in various aspects, suggesting a promising direction in online learning for language models.
Online Adaptation#
Online adaptation of large language models (LLMs) is crucial for maintaining relevance in rapidly evolving environments. The paper explores this by proposing Memory of Amortized Contexts (MAC), a novel framework that allows efficient adaptation without retraining. Instead of expensive fine-tuning, MAC leverages parameter-efficient fine-tuning and amortization-based meta-learning. New information is compressed into compact modulations stored in a memory bank. A crucial aspect is the aggregation network which intelligently selects and combines relevant modulations, conditioned on the current query. This strategy addresses limitations of prior approaches like retrieval-augmented generation (RAG) and online finetuning, overcoming issues such as high computational costs and catastrophic forgetting. The efficiency of MAC is further enhanced by incorporating backpropagation dropout and hierarchical modulation aggregation, mitigating memory constraints during training and inference. Experimental results across various datasets and LLMs demonstrate the superior performance, efficiency, and knowledge retention of MAC compared to existing online adaptation methods.
Efficient Training#
Efficient training of large language models (LLMs) is crucial for practical applications. The paper explores this challenge by introducing two key memory-efficient techniques. Backpropagation dropout allows training with significantly larger memory sizes by computing gradients on a random subset of documents, improving scalability. This approach mitigates the memory constraints associated with handling extensive data during model adaptation. Second, hierarchical modulation aggregation addresses the memory burden of large memory banks during inference by using a divide-and-conquer approach, reducing the computational cost of aggregating information. By breaking down the aggregation process into smaller, manageable sub-groups, MAC (Memory of Amortized Contexts) reduces the overall memory requirements and computational time, enhancing efficiency without sacrificing performance. These optimizations are particularly relevant for LLMs due to their massive parameter space and computational intensity, enabling effective online adaptation with improved speed and memory efficiency.
Retrieval Augmentation#
Retrieval augmentation techniques significantly enhance language models by integrating external knowledge sources. This addresses the limitations of relying solely on pre-trained parameters, which often become outdated or incomplete. By retrieving and incorporating relevant information from external databases, retrieval augmentation improves the model’s accuracy, reduces hallucinations, and allows for handling of queries requiring up-to-date or specialized knowledge. However, challenges include computational cost and the quality of retrieved information. The efficiency of the retrieval process is crucial, as inefficient retrieval can negate performance gains. Furthermore, the reliability of external knowledge sources is paramount; inaccurate or biased information can lead to incorrect or misleading outputs. Effective retrieval methods involve techniques that go beyond simple keyword matching, such as semantic search, which considers contextual meaning to improve relevance. Advanced approaches leverage sophisticated embedding models and efficient indexing structures to optimize retrieval speed and accuracy. The integration of retrieved information into the language model’s architecture is also key. Various methods exist, from simple concatenation to more complex mechanisms involving attention or fusion mechanisms. A successful integration method ensures seamless blending of external information with the model’s internal representation, ultimately enhancing its reasoning and generation capabilities.
Future Directions#
Future research could explore several promising avenues. Extending MAC to encompass diverse NLP tasks beyond question answering is crucial to demonstrate its broader applicability. Investigating more sophisticated memory management techniques to address the scaling challenges associated with growing memory banks is vital. This might involve exploring neural compression methods or more efficient data structures. Further research should also focus on combining MAC with other advanced techniques, such as advanced retrieval augmentation and larger language models, to achieve even greater performance gains. A comprehensive analysis of MAC’s robustness under various conditions, including noisy data and adversarial attacks, is needed to establish its reliability in real-world scenarios. Finally, a thorough investigation into MAC’s potential societal impact and mitigation strategies for potential risks is paramount, ensuring responsible application of this powerful technique.
More visual insights#
More on figures
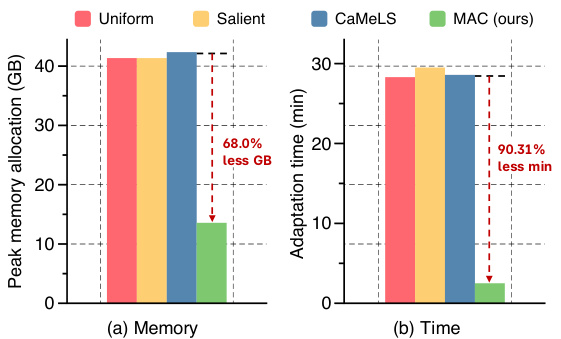
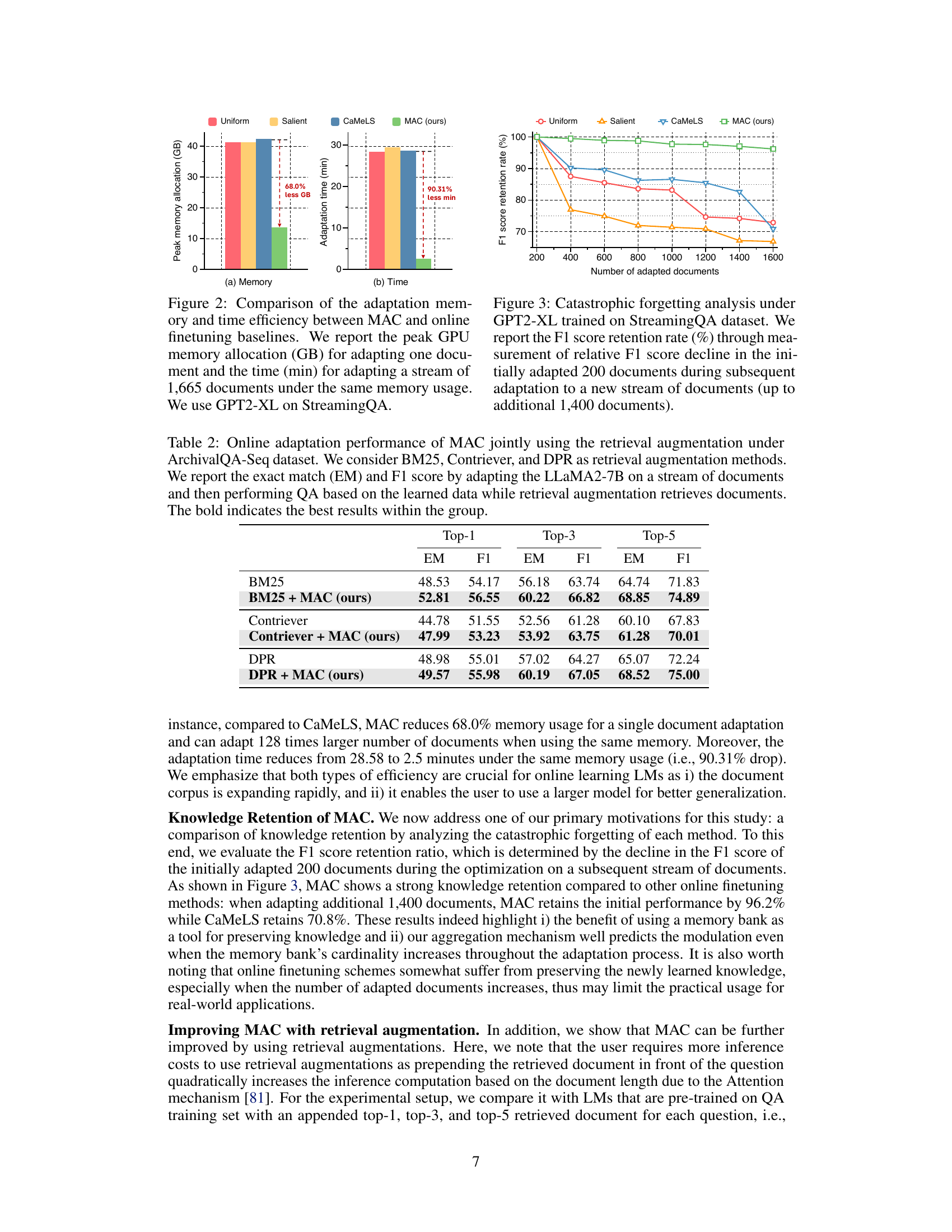
This figure compares the memory usage and time efficiency of MAC against three online finetuning baselines (Uniform, Salient Spans, and CaMeLS) for adapting a language model to a stream of documents. The left bar chart shows the peak GPU memory allocation in gigabytes (GB) required to adapt a single document. The right bar chart displays the time in minutes (min) needed to adapt a stream of 1,665 documents. The experiment used the GPT2-XL model on the StreamingQA dataset. MAC demonstrates significantly lower memory usage and adaptation time compared to the baselines.

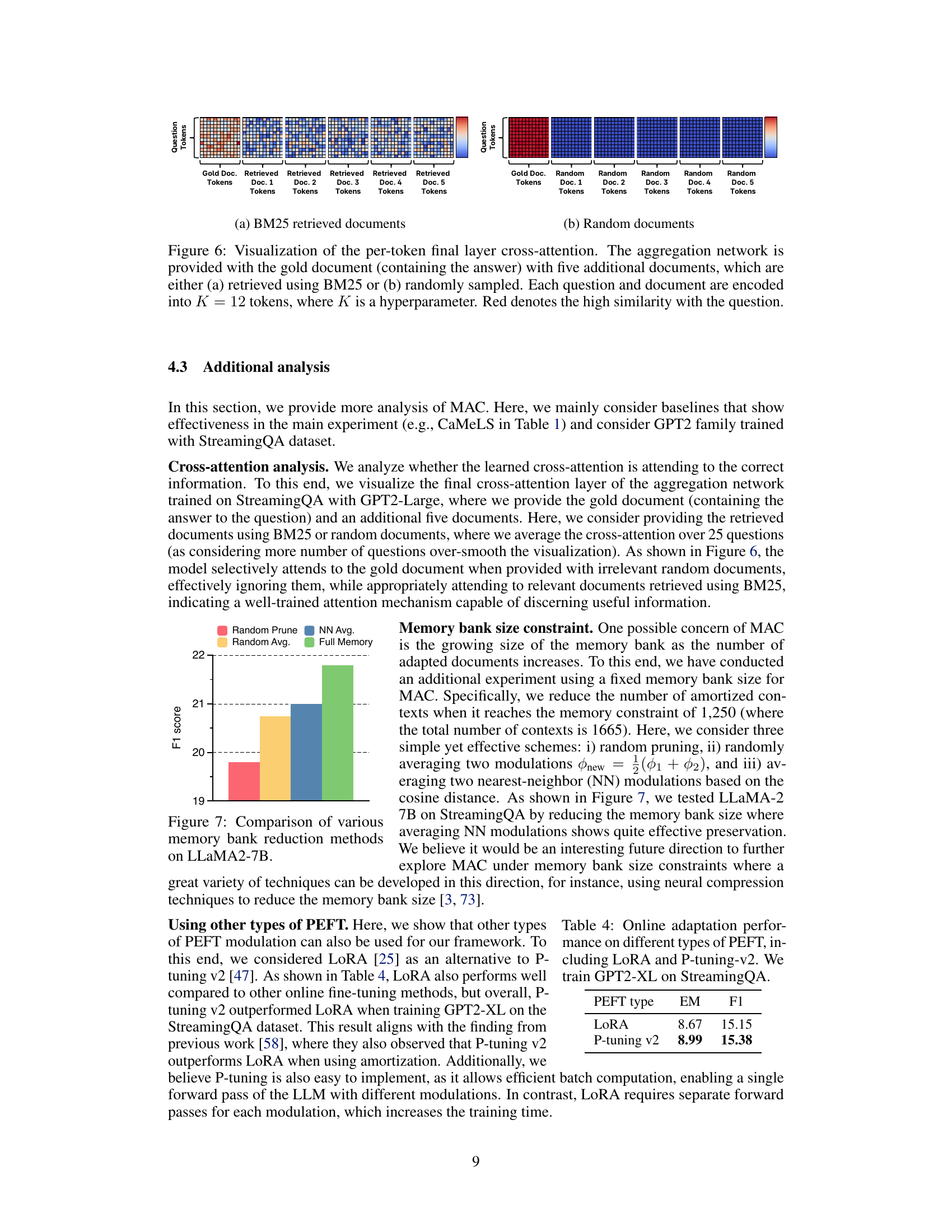
This figure shows the F1 score retention rate over time for four different online adaptation methods. The x-axis represents the number of documents adapted after the initial adaptation of 200 documents. The y-axis represents the F1 score retention rate, calculated as the percentage of the initial F1 score maintained after further adaptation. The figure demonstrates that MAC (Memory of Amortized Contexts) significantly outperforms the baselines (Uniform, Salient Spans, and CaMeLS) in terms of knowledge retention. The other methods show a significant decrease in F1 score as more documents are added, indicating catastrophic forgetting, while MAC maintains a much higher F1 score, demonstrating its effectiveness at preserving previously learned knowledge during online adaptation.

This figure compares the memory usage and time efficiency of MAC against other online finetuning methods for adapting Language Models. The left-hand bar chart shows that MAC requires significantly less peak GPU memory (68% less) to adapt a single document. The right-hand bar chart shows that MAC is also much faster (90.31% less time) to adapt a stream of 1665 documents when using the same memory constraints. The experiment uses the GPT2-XL model on the StreamingQA dataset.

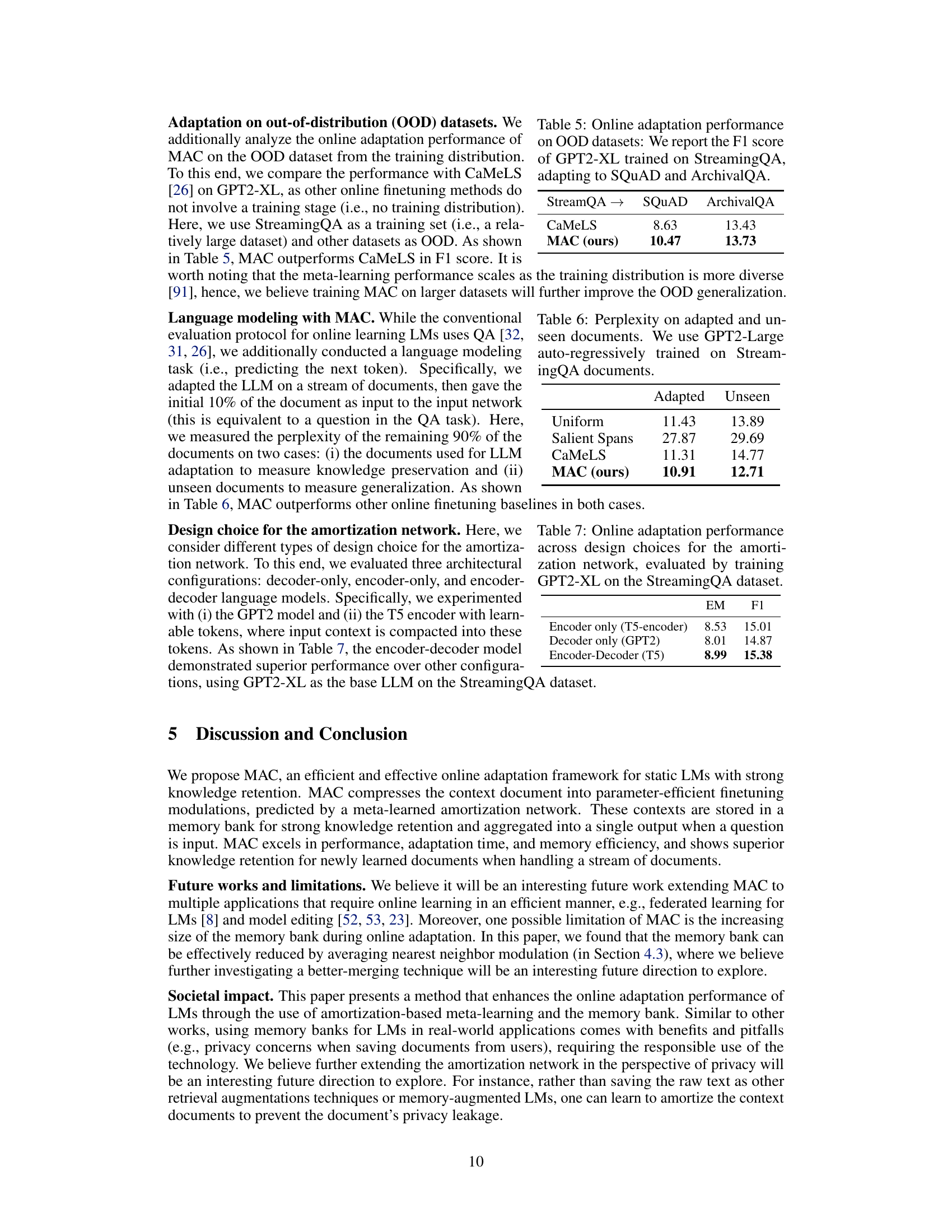
This figure visualizes the attention weights of the aggregation network’s final layer. It demonstrates how the network attends to different tokens in the gold document (containing the correct answer) and five additional documents. The additional documents are either retrieved using BM25 (a well-known information retrieval technique) or randomly selected. The heatmaps show the attention weights, with red indicating high attention (similarity to the question) and blue indicating low attention. This helps illustrate how the network effectively focuses on relevant information when given a question and various documents.

This figure compares different methods for reducing the size of the memory bank in the MAC model. The methods compared are: Random Prune, Random Average, Nearest Neighbor Average, and using the Full Memory. The y-axis represents the F1 score achieved by each method on the LLaMA-2-7B model, demonstrating that the full memory achieves the highest F1 score, while other methods achieve lower, but still comparable performance.
More on tables

This table presents the results of an experiment evaluating the performance of MAC when combined with different retrieval augmentation methods (BM25, Contriever, and DPR) on the ArchivalQA-Seq dataset. The experiment uses the LLaMA2-7B language model and reports the exact match (EM) and F1 scores for different top-k retrieved documents (top-1, top-3, top-5). The bold values highlight the best performance within each group of methods.
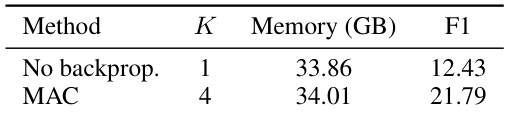
This table demonstrates the impact of the backpropagation dropout technique on the performance of the LLaMA2-7B model when trained on the StreamingQA dataset. It compares two scenarios: one without backpropagation dropout and the other using MAC with a dropout ratio of 0.75. The results reveal the effectiveness of backpropagation dropout in significantly reducing memory usage while maintaining improved F1 scores.
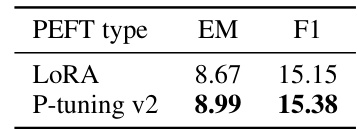
This table compares the performance of online adaptation using two different Parameter-Efficient Fine-Tuning (PEFT) methods: LoRA and P-tuning v2. The experiment uses the GPT2-XL model trained on the StreamingQA dataset. The results are measured using the Exact Match (EM) and F1 scores, which are common metrics for evaluating question answering performance. The table shows that P-tuning v2 achieved slightly better results than LoRA in this specific setting.
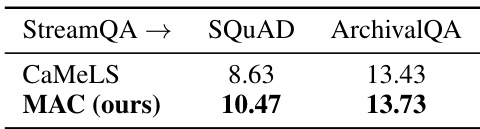
This table presents the results of an experiment evaluating the online adaptation performance of the proposed MAC method on out-of-distribution (OOD) datasets. The experiment used GPT2-XL as the base language model, pre-trained on the StreamingQA dataset. The model was then adapted to two OOD datasets: SQUAD and ArchivalQA. The F1 score, a common metric for evaluating the performance of question answering models, is reported for both CaMeLS (a baseline method) and MAC (the proposed method) on each of the OOD datasets. The results demonstrate the ability of MAC to generalize better to unseen data compared to the baseline.

This table presents the perplexity scores achieved by different online adaptation methods on both adapted and unseen documents. Lower perplexity indicates better performance. The GPT2-Large language model was trained autoregressively on the StreamingQA dataset before online adaptation was performed using the various methods. The ‘Adapted’ column shows results for the documents used during the adaptation process, while ‘Unseen’ shows the results for documents not used in adaptation, indicating generalization ability.
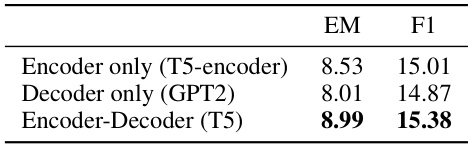
This table compares the performance of three different designs for the amortization network in the MAC model when training on the StreamingQA dataset. The designs are: using only the encoder of the T5 model; using only the decoder of the GPT2 model; and using the encoder and decoder parts of the T5 model. The results are measured by Exact Match (EM) and F1 score, and it shows that the encoder-decoder design (using the T5 model) performs best.

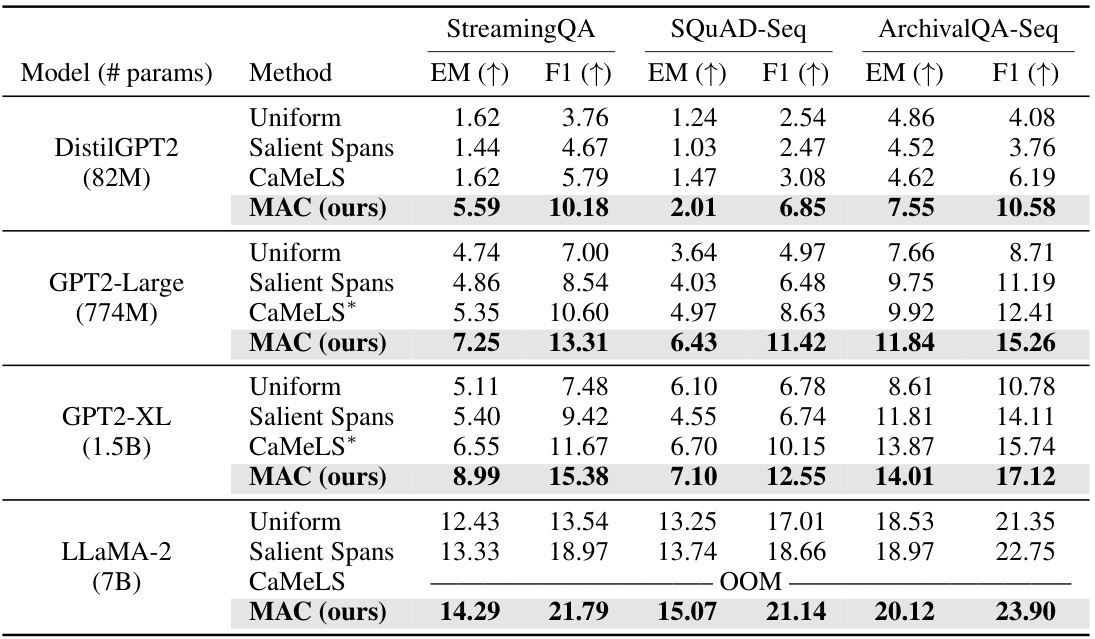
This table compares the performance of MAC against several online finetuning baselines on three question answering datasets (StreamingQA, SQUAD-Seq, and ArchivalQA-Seq). The metrics used are Exact Match (EM) and F1 score, reflecting the accuracy of the language model after adapting to a stream of documents. The table shows that MAC significantly outperforms the baselines across all datasets and model sizes, demonstrating its effectiveness in online adaptation. It also notes limitations faced by some baselines due to memory constraints.

This table compares the performance of MAC against several online finetuning baselines on three different question answering datasets. The metrics used are Exact Match (EM) and F1 score. The baselines include methods using uniform token weighting, salient spans, and CaMeLS. Note that CaMeLS used a smaller language model due to memory constraints on some of the datasets. The table highlights MAC’s superior performance across various datasets and model sizes.
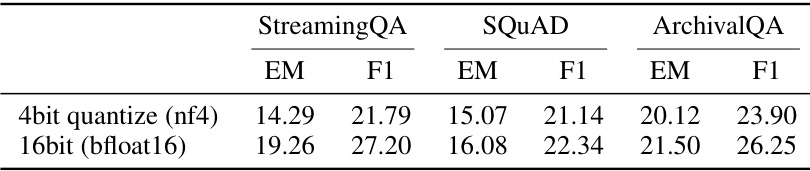
This table compares the online adaptation performance of MAC against several online finetuning baselines across three datasets: StreamingQA, SQUAD-Seq, and ArchivalQA-Seq. The metrics used are Exact Match (EM) and F1 score, reflecting the accuracy of question answering after adapting the language model to a stream of new documents. The table also notes instances where CaMeLS, due to memory limitations, used a smaller language model and cases where the memory constraints prevented results from being obtained.

This table compares the performance of MAC against a memory-augmented language model approach that uses context compression (CCM) and a retriever to select relevant compressed documents. The results, shown as exact match (EM) and F1 scores, demonstrate MAC’s superior performance on the StreamingQA dataset.

This table compares the performance of MAC against several online finetuning baselines on three question answering datasets. The metrics used are Exact Match (EM) and F1 score, measuring the accuracy of the language model after adapting to a stream of documents. The table also notes limitations encountered by some baseline methods due to memory constraints.
Full paper#