↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) generate high-quality text, raising concerns about misuse. Watermarking, embedding hidden information to verify source, is a solution, but existing methods have flaws. Common designs prioritize robustness, multiple keys, and public detection APIs, creating vulnerabilities.
This paper rigorously tests several simple attacks exploiting these vulnerabilities. It demonstrates significant trade-offs between robustness, utility, and usability. The research proposes new attack strategies and offers guidelines and defenses to improve the security and usability of LLM watermarking in practice. These include carefully considering the implications of design choices to minimize the risks of both watermark removal and spoofing attacks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals critical vulnerabilities in existing LLM watermarking schemes, highlighting the need for more robust and secure methods to mitigate the misuse of AI-generated content. It also provides practical guidelines and defenses to improve the security of future watermarking systems, which is vital in the face of increasingly sophisticated AI-generated content.
Visual Insights#
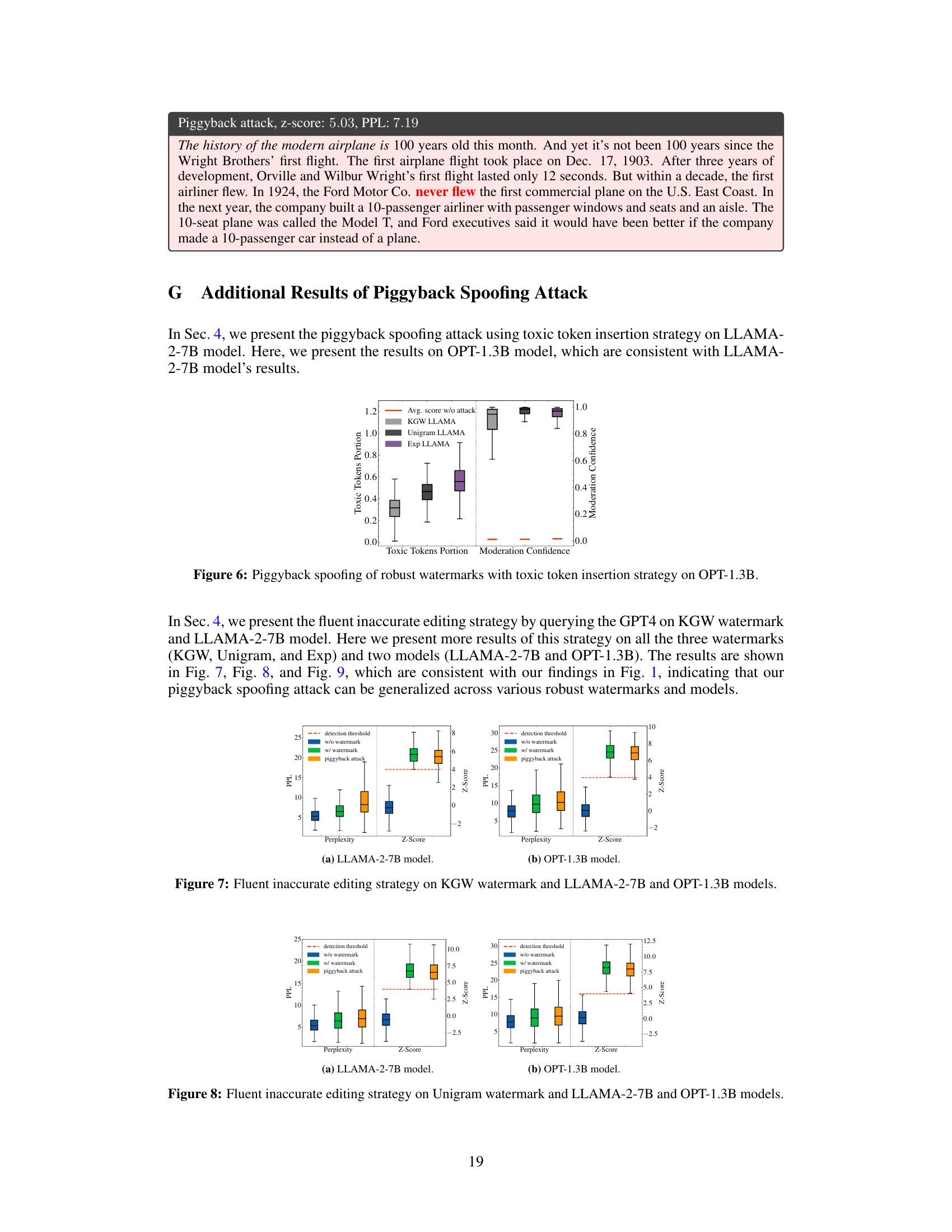
This figure demonstrates the effectiveness of piggyback spoofing attacks against robust watermarks. The left panel (a) shows that inserting toxic words into watermarked text doesn’t prevent the watermark from being detected, making the output harmful. The right panel (b) shows that even generating fluent, inaccurate content using GPT4 maintains watermark detection, illustrating the vulnerability of robustness to spoofing.

This table presents examples of text generated by the LLAMA-2-7B language model, both with and without a watermark. It showcases three different attack scenarios: a piggyback spoofing attack (where incorrect content is generated but still appears watermarked), and two watermark removal attacks (one exploiting multiple keys, and another exploiting a public detection API). The table highlights the Z-score (detection confidence) and perplexity (text quality) for each example, demonstrating how attacks can compromise the effectiveness of watermarking.
In-depth insights#
LLM watermark tradeoffs#
The core of LLM watermarking hinges on embedding information within AI-generated text to verify its origin. However, the paper reveals a crucial “no free lunch” aspect: design choices enhancing one desirable property (like robustness against removal) often inadvertently compromise others. For example, robust watermarks, while resistant to removal, become vulnerable to piggyback attacks, where malicious actors subtly alter the text to embed harmful content while maintaining the watermark’s signature. Similarly, using multiple keys to prevent watermark theft can backfire, increasing susceptibility to attacks that exploit the system’s inherent redundancies for removal. The research highlights the critical need to carefully balance these trade-offs, suggesting a layered approach incorporating anomaly detection and access control to mitigate risks, instead of relying solely on a single watermarking strategy.
Robustness attacks#
Robustness attacks against LLMs exploit the inherent trade-off between watermark robustness and utility. A robust watermark, while resistant to simple removal attempts, paradoxically becomes vulnerable to sophisticated attacks that subtly alter the text. These alterations might introduce inaccuracies or toxicity without triggering watermark detection. This highlights a critical design challenge: achieving robustness without sacrificing the integrity and usability of the watermarked content. The attacks leverage the watermark’s resilience to minor changes, introducing harmful modifications within the acceptable threshold. This necessitates a more nuanced approach to watermark design, moving beyond simple robustness metrics to include holistic evaluation methods considering the potential for adversarial manipulation and the wider implications for content reliability.
Key-based defenses#
Key-based defenses against LLM watermarking attacks revolve around the management and protection of cryptographic keys used to embed watermarks. Robustness against watermark removal is a key goal, but ironically, this can also make watermarks vulnerable to spoofing attacks where malicious content appears watermarked. Multiple keys enhance security against watermark theft, but this complicates watermark removal attacks, creating a trade-off between robustness and ease of removal. Public detection APIs, while convenient for verifying watermarks, offer attack vectors too. A holistic strategy should therefore involve strong key management, perhaps combined with techniques like differential privacy applied to detection API outputs, to balance watermark robustness with overall system security.
API attack vectors#
API attack vectors represent a crucial vulnerability in large language model (LLM) watermarking systems. Publicly accessible detection APIs, intended to verify the AI-generated nature of text, inadvertently provide attackers with a powerful tool. By repeatedly querying the API with slightly modified versions of watermarked text, attackers can iteratively refine their modifications to either remove the watermark entirely or subtly insert harmful content while maintaining a high watermark confidence score. This highlights a critical trade-off: the convenience of public verification comes at the cost of increased security risk. Robustness, often a desirable characteristic of watermarks, becomes a double-edged sword. While intended to prevent simple watermark removal, it paradoxically enables attackers to generate deceptively watermarked outputs, whether toxic or factually incorrect, with minimal effort. Defenses, such as differential privacy techniques to add noise to API responses, are essential to mitigate these risks. The need for layered security, including query rate limiting and user authentication, is clear, showcasing the multifaceted challenges in balancing usability and security in LLM watermarking.
DP defense#
The research explores a defense mechanism against spoofing attacks on watermark detection APIs using differential privacy (DP). DP adds noise to the detection scores, making it difficult for attackers to distinguish between genuine and manipulated content. The study demonstrates that DP effectively mitigates spoofing attacks with minimal impact on detection accuracy, highlighting a key trade-off between security and utility. A critical aspect is the use of a pseudorandom function (PRF) to generate the noise, ensuring that only those with the secret key can remove or reduce the noise. Although effective against spoofing, the DP defense shows limitations against watermark removal attacks, where the attacker’s actions might appear random to the detection system. This underscores the complex interplay between robustness, utility, and security in LLM watermarking design and highlights the need for a multi-layered defense approach.
More visual insights#
More on figures
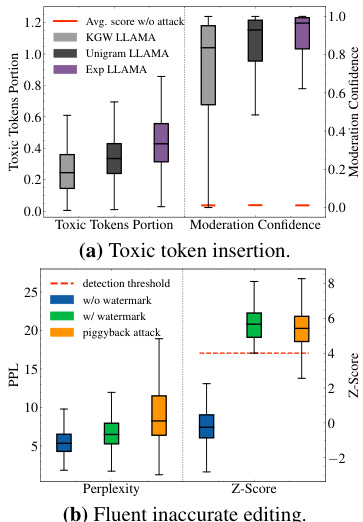
This figure shows the results of spoofing attacks based on watermark stealing and watermark removal attacks using different numbers of watermark keys. The x-axis represents the number of keys used. The y-axis shows three metrics: Z-score (confidence of watermark detection), attack success rate (ASR, percentage of successful attacks), and perplexity (PPL, measuring text quality). The figure demonstrates a trade-off: increasing the number of keys improves resistance to watermark stealing (lower ASR in the spoofing attack) but makes the watermark more vulnerable to removal attacks (higher ASR in the removal attacks and lower Z-score). The perplexity generally improves with more keys.
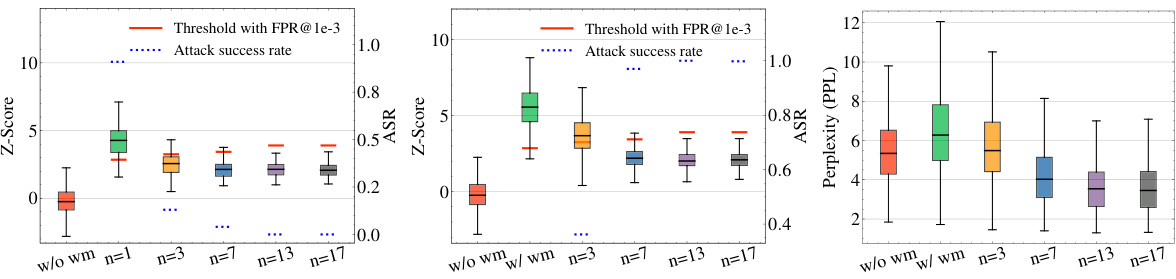
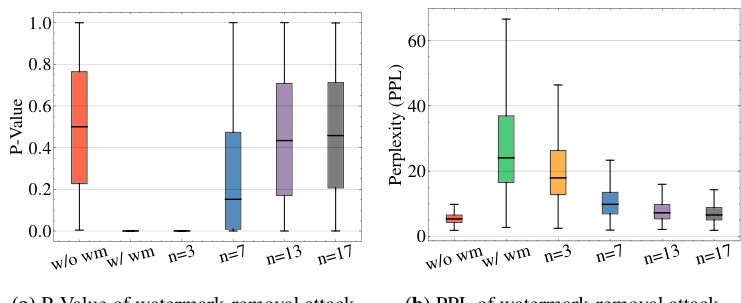
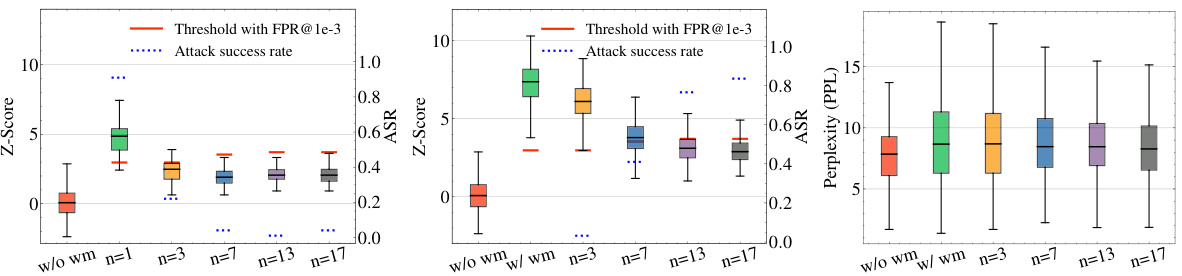
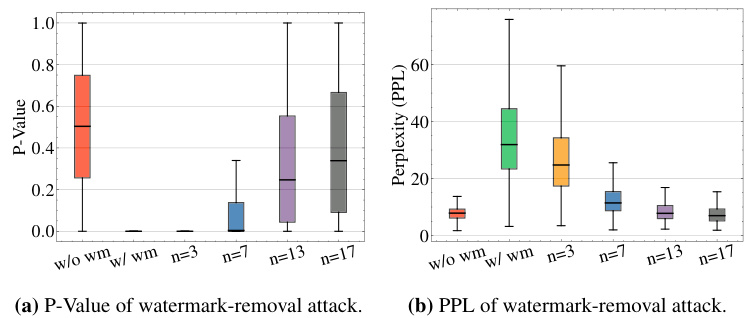
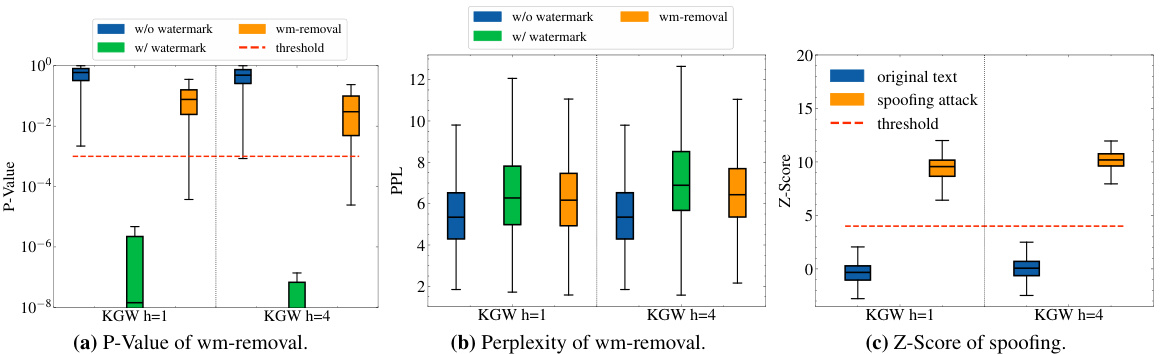
This figure shows the results of watermark removal and spoofing attacks that exploit watermark detection APIs. Three watermarking schemes (KGW, Unigram, Exp) are tested, with results presented as boxplots showing Z-scores and perplexity. (a) shows the Z-scores/P-values for watermark removal; successful attacks lower the score. (b) presents the perplexity of the modified text, indicating the quality of the text after watermark removal. (c) depicts the Z-scores/P-values for spoofing attacks; successful attacks increase the score. The results demonstrate that the attacks are effective in manipulating the watermark detection scores while maintaining reasonable text quality.
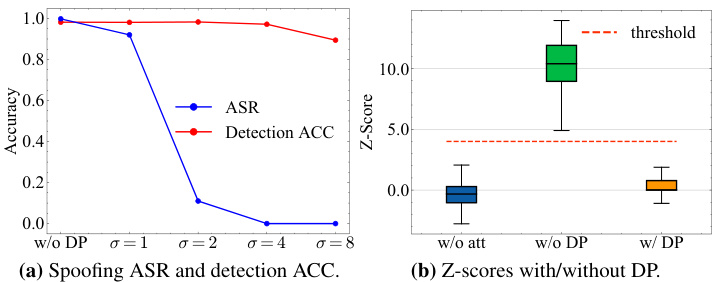
This figure shows the results of evaluating a differential privacy (DP) defense against spoofing attacks on a KGW watermarked LLAMA-2-7B model. The left panel (a) displays a line graph comparing the spoofing attack success rate (ASR) and detection accuracy (ACC) with varying noise parameters (σ). The right panel (b) presents box plots illustrating the Z-scores for three scenarios: original text without attack, spoofing attack without DP, and spoofing attack with DP (using the optimal noise parameter σ=4). The results demonstrate that the DP defense effectively mitigates spoofing attacks with minimal impact on detection accuracy.

This figure validates Theorem 1 presented in the paper, which provides a bound on the maximum number of tokens that can be inserted or edited into a watermarked sentence to guarantee that the expected z-score of the edited text is above a threshold T. The x-axis represents the detection z-score (z) of the original watermarked text, and the y-axis represents the ratio of the number of inserted tokens (s) to the length of the original sentence (l). The green points show data points where the condition in Theorem 1 holds true, while red points indicate where it does not. The blue line represents the theoretical bound from Theorem 1. The percentage of data points that satisfy the theorem (85.78%) and those that do not (14.22%) are shown.

This figure shows the results of two different piggyback spoofing attacks on robust watermarks. The first attack involves inserting toxic tokens into the watermarked text, while the second involves using GPT-4 to modify the text in a way that makes it inaccurate but still fluent. Both attacks demonstrate the vulnerability of robust watermarks to spoofing attacks, even when the watermark itself remains undetectable. The figure highlights a key trade-off in watermarking design: Robustness to editing attacks can make the system more vulnerable to spoofing.
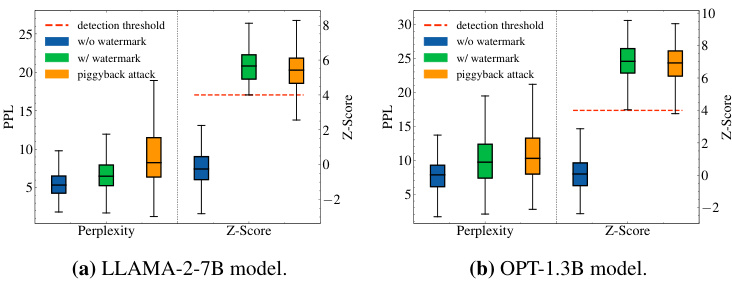
This figure shows the results of two piggyback spoofing attacks on robust watermarks. The first attack involves inserting toxic tokens into watermarked text. The results show that a significant number of toxic tokens can be inserted without affecting the watermark detection, making the text toxic. The second attack uses GPT-4 to modify the watermarked text to make it inaccurate while maintaining fluency. The results show that this is also possible, with a high success rate. These findings highlight the inherent vulnerability of robust watermarks to spoofing attacks, a critical design trade-off.
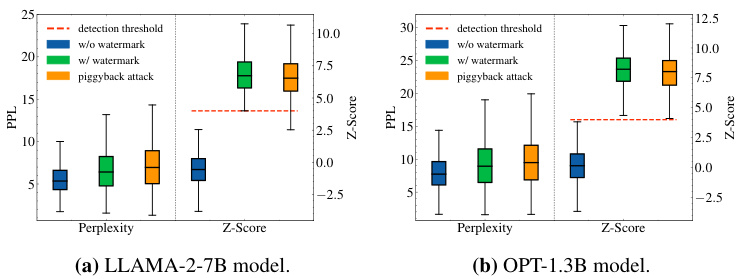
This figure demonstrates the effectiveness of piggyback spoofing attacks against robust watermarks. Subfigure (a) shows that a substantial number of toxic tokens can be inserted into watermarked text without affecting the watermark detection, leading to potentially harmful or inaccurate content. Subfigure (b) illustrates how fluent but inaccurate text can be generated by editing a watermarked sentence, again without impacting the watermark detection. This highlights the vulnerability of robust watermarks to manipulation.
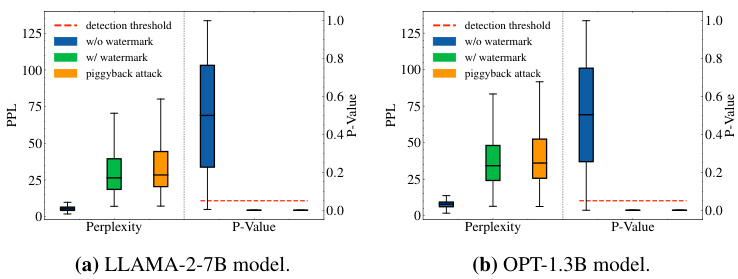
This figure shows the results of two different piggyback spoofing attacks against robust watermarks. The first attack involves inserting toxic tokens into the watermarked text. The results show that a significant number of toxic tokens can be inserted without affecting the watermark detection. The second attack uses GPT-4 to modify the watermarked text to make it inaccurate while maintaining fluency. This also successfully bypasses watermark detection. The figure highlights the tradeoff between robustness and vulnerability to spoofing attacks inherent in robust watermarking schemes.
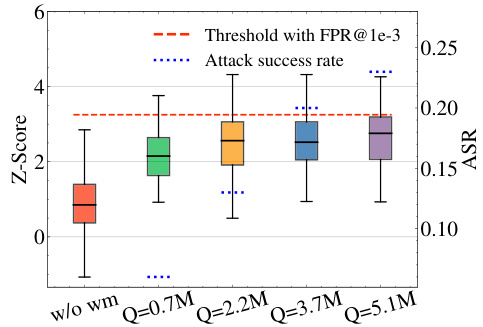
This figure shows the results of a watermark stealing attack on the KGW watermark using the LLAMA-2-7B language model with three keys. The x-axis represents the number of tokens (in millions) obtained by the attacker, and the y-axis shows both the Z-score (a measure of watermark confidence) and the attack success rate (ASR). The red dashed line indicates the detection threshold with a false positive rate (FPR) of 1e-3. As the number of tokens obtained by the attacker increases, the attack success rate also increases, eventually exceeding the detection threshold. This demonstrates the vulnerability of the system to watermark stealing attacks even with multiple keys, if the attacker can obtain a sufficient number of watermarked tokens.
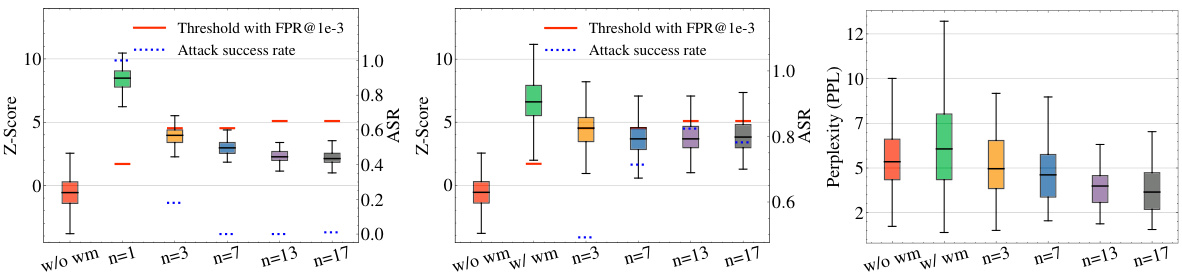
This figure shows the results of spoofing attacks based on watermark stealing and watermark removal attacks using the KGW watermark on the LLAMA-2-7B language model. The x-axis represents the number of watermark keys (n) used, ranging from 1 to 17. The y-axis displays three key metrics: Z-score (reflecting watermark detection confidence), attack success rate (ASR), and perplexity (PPL, indicating text quality). The plots demonstrate a trade-off: increasing the number of keys improves resistance to watermark stealing (lower ASR in the spoofing attack) but simultaneously increases vulnerability to watermark removal attacks (higher ASR in the watermark removal attack and slightly higher PPL).
This figure shows the results of spoofing attacks based on watermark stealing and watermark removal attacks. The attacks target the KGW watermark on the LLAMA-2-7B language model and vary the number of watermark keys used (n). Higher z-scores indicate a higher confidence in the watermark’s presence, while lower perplexity scores suggest better sentence quality. The success rate of the attacks is determined using a false positive rate (FPR) threshold of 1e-3. The figure demonstrates the trade-off between watermark robustness and vulnerability to attacks when employing multiple keys.
This figure demonstrates the trade-off between watermark stealing resistance and watermark removal vulnerability when using multiple watermark keys. The left panel shows that increasing the number of keys (n) significantly reduces the success rate of watermark stealing attacks. However, the middle panel reveals that increasing the number of keys makes the system increasingly vulnerable to watermark removal attacks, as the detection scores are drastically reduced. The right panel shows the perplexity of the generated text, indicating that using more keys generally leads to better sentence quality. This highlights a crucial design challenge: enhancing security against one type of attack can unintentionally increase vulnerability to another.
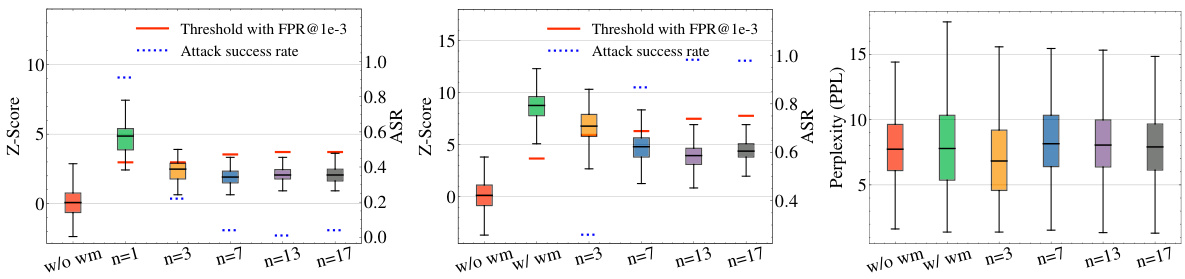
This figure shows the results of spoofing and watermark removal attacks using the KGW watermark on the LLAMA-2-7B language model with varying numbers of watermark keys (n). The higher the z-score, the higher the confidence in the presence of a watermark, while lower perplexity values indicate better-quality text. The attack success rate is determined by the threshold where the false positive rate is 1e-3. The figure demonstrates that increasing the number of keys improves the system’s resistance to watermark stealing, but simultaneously increases its vulnerability to watermark removal.
This figure shows the results of spoofing attacks based on watermark stealing and watermark removal attacks on the KGW watermark using the LLAMA-2-7B model with varying numbers of watermark keys. Higher z-scores indicate higher confidence in the watermark’s presence, and lower perplexity values suggest higher sentence quality. The attack success rates are calculated using a threshold with a false positive rate (FPR) of 1e-3.
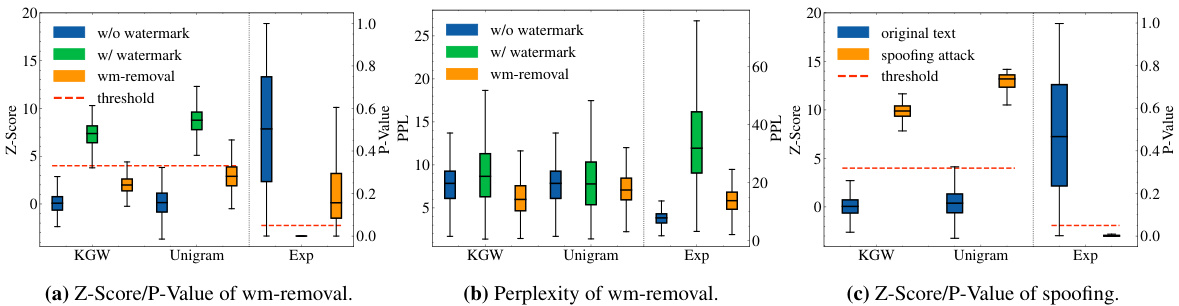
This figure shows the results of watermark removal and spoofing attacks that exploit publicly available watermark detection APIs. The leftmost plot shows the Z-score (or P-value) of watermark removal attacks, demonstrating that the detection confidence is significantly reduced, while maintaining reasonable text quality. The center plot depicts the perplexity of the resulting text, indicating that the quality remains high despite the watermark removal. The rightmost plot showcases the results of the spoofing attacks, where the detection confidence is very high, confirming successful spoofing, despite the generated text not originating from the target watermarked LLM.
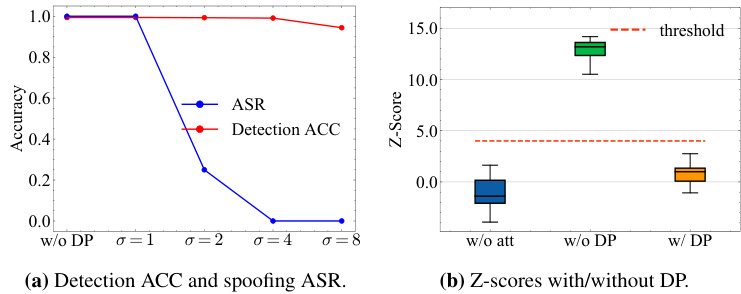
This figure shows the results of evaluating the effectiveness of a differential privacy (DP) defense against spoofing attacks on a KGW watermark using the LLAMA-2-7B language model. Part (a) presents a comparison of the spoofing attack success rate (ASR) and detection accuracy (ACC) with and without the DP defense, illustrating how different noise parameters (σ) affect performance. Part (b) visually represents the Z-scores (a measure of watermark detection confidence) for original text, spoofing attacks without DP, and spoofing attacks with the DP defense (using the optimal noise parameter, σ=4, determined in part (a)). The figure demonstrates the trade-off between the DP defense’s ability to mitigate spoofing attacks and its impact on detection accuracy.

This figure shows the results of an experiment evaluating the effectiveness of a differential privacy (DP) defense against spoofing attacks on a KGW watermark using the LLAMA-2-7B language model. The left subplot (a) displays the spoofing attack success rate (ASR) and detection accuracy with different noise parameters (σ), demonstrating how adding noise impacts the ability of attackers to successfully spoof the watermark. The right subplot (b) compares the watermark detection Z-scores (a measure of confidence) with and without the DP defense, illustrating the effectiveness of the defense in mitigating the spoofing attacks. The optimal noise parameter (σ = 4) was chosen based on the balance between minimizing the attack success rate and maintaining a reasonable detection accuracy.
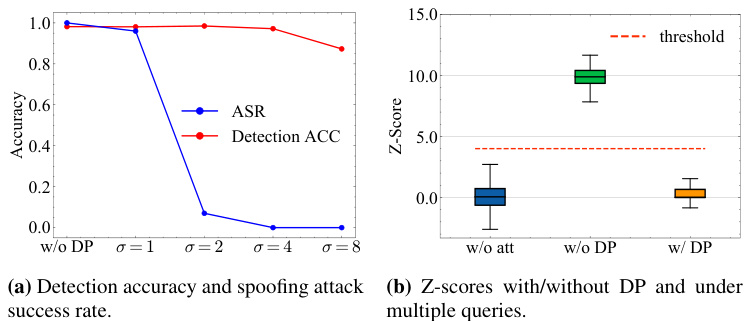
This figure shows the results of evaluating a defense mechanism using differential privacy (DP) against spoofing attacks on a KGW watermark using the LLAMA-2-7B language model. Panel (a) presents a comparison of spoofing attack success rates (ASR) and detection accuracy (ACC) with and without the DP defense, across various noise levels (σ). Panel (b) illustrates the Z-scores (watermark confidence) for original text, spoofing attacks without DP, and spoofing attacks with DP (using the optimal noise level, σ = 4). The results demonstrate the trade-off between detection accuracy and the effectiveness of the DP defense in mitigating spoofing attacks.
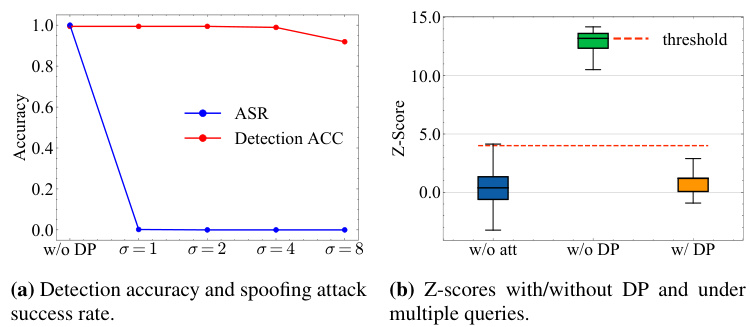
This figure shows the results of evaluating a differential privacy (DP) defense against spoofing attacks on a KGW watermark using the LLAMA-2-7B language model. Panel (a) compares the spoofing attack success rate (ASR) and detection accuracy with and without the DP defense, showing varying levels of Gaussian noise (σ). Panel (b) presents box plots visualizing the Z-scores (watermark confidence) for original text, attacks without DP, and attacks with the optimal DP noise level (σ=4). The DP defense significantly reduces the ASR while maintaining reasonable detection accuracy.
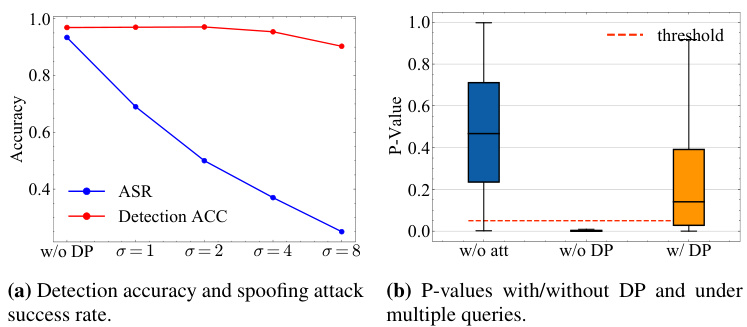
This figure shows the results of evaluating a differential privacy (DP) defense against spoofing attacks on a KGW watermark using the LLAMA-2-7B language model. Part (a) compares the spoofing attack success rate (ASR) and detection accuracy with different levels of added noise (σ). It demonstrates that DP effectively reduces the ASR while only slightly impacting detection accuracy. Part (b) visually represents the z-scores (a measure of watermark confidence) for the original text, the text after a spoofing attack without DP, and the text after a spoofing attack with DP. The optimal noise parameter (σ = 4) was selected based on the results from part (a).
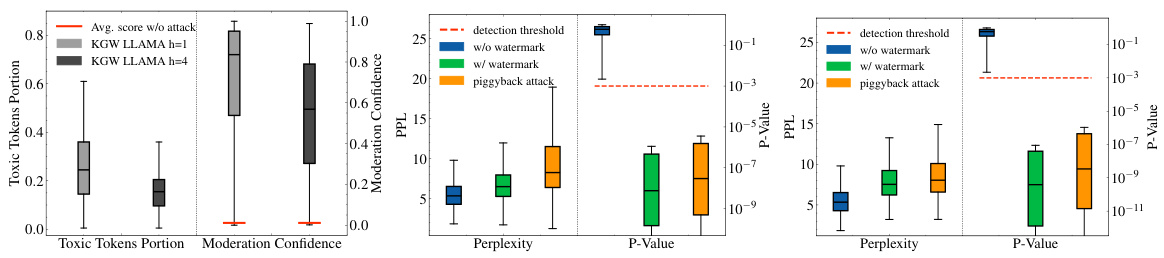
This figure presents the results of a piggyback spoofing attack using toxic token insertion on the OPT-1.3B language model. It shows the maximum portion of toxic tokens that can be inserted into watermarked content without changing the watermark detection result. The figure also shows the confidence scores from OpenAI’s moderation model in identifying the content as violating its usage policy due to the inserted toxic tokens. The results demonstrate that a significant number of toxic tokens can be inserted into content generated by all the robust watermarking schemes, with a median portion higher than 20%. The median confidence score for content flagged as violating OpenAI’s policy is higher than 0.8 across all watermarking schemes, compared to an average confidence score of around 0.01 before the attack.

This figure shows the results of spoofing attacks based on watermark stealing and watermark removal attacks. The experiments are conducted on the Unigram watermark and LLAMA-2-7B model with different numbers of watermark keys. The x-axis represents the number of watermark keys, and the y-axis represents the attack success rate (ASR), z-score, and perplexity (PPL). The figure shows that using more keys can effectively defend against watermark stealing attacks, but it also makes the system more vulnerable to watermark removal attacks. There is a trade-off between the resistance against watermark stealing and the feasibility of removing watermarks.
This figure shows the results of spoofing and watermark removal attacks on the KGW watermark using the LLAMA-2-7B language model. The attacks exploit the use of multiple watermark keys. The figure demonstrates the trade-off between watermark security (resistance to stealing attacks) and vulnerability to removal attacks. Higher z-scores indicate stronger watermark confidence, while lower perplexity suggests better text quality. The attack success rates are calculated using a false positive rate (FPR) threshold of 1e-3.
More on tables
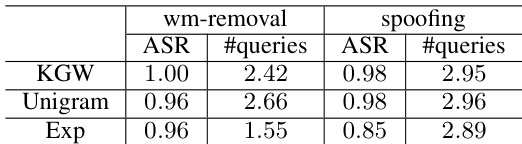
This table shows examples of text generated by LLAMA-2-7B with and without a watermark, subjected to different attacks. It demonstrates the impact of piggyback spoofing and watermark removal attacks on the detection confidence (Z-score) and text quality (perplexity). The different attack strategies (exploiting robustness, multiple keys, and public APIs) highlight the vulnerabilities of common watermarking design choices.
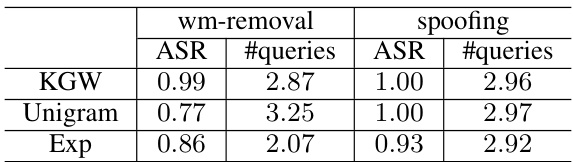
This table presents examples of text generated by LLAMA-2-7B with and without a watermark, subjected to different attacks. It shows the Z-score (watermark detection confidence) and perplexity (text quality) for each example. Three types of attacks are demonstrated: piggyback spoofing (generating incorrect but seemingly watermarked text), and two types of watermark removal attacks (exploiting multiple keys or a public detection API). The table highlights the trade-offs between watermark robustness, utility, and usability.
Full paper#