↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-agent systems often involve diverse agents with unpredictable behaviors, posing significant challenges for reinforcement learning (RL). Existing methods struggle to effectively handle such heterogeneity and partial observability in decision-making. This paper tackles this issue by introducing an Episodic Future Thinking (EFT) mechanism for RL agents. The EFT mechanism enables agents to predict the future actions of others by inferring their characteristics (defined as different reward preferences) and simulating future scenarios. This foresight improves the agent’s ability to make optimal, adaptive decisions.
The proposed method consists of two main modules: a multi-character policy that models diverse agent behaviors and a character inference module that infers the characteristics of other agents from their observed actions. Extensive experiments in autonomous driving and other multi-agent scenarios demonstrate that the EFT mechanism, especially when combined with accurate character inference, leads to higher rewards than existing methods. The benefits are consistent even with high character diversity, showcasing the method’s robustness and practical applicability.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel Episodic Future Thinking (EFT) mechanism for multi-agent reinforcement learning, addressing the challenge of decision-making in complex, heterogeneous environments. The EFT mechanism, combined with accurate character inference, significantly improves the performance of RL agents. This opens new avenues for research in MARL, particularly in scenarios with diverse agent behaviors and partial observability. The method’s robustness across various levels of character diversity makes it highly applicable to real-world multi-agent systems.
Visual Insights#

This figure illustrates the architecture of an agent with a multi-character policy. The agent interacts with the environment by receiving observations (Ot,i) and taking actions (at,i). The multi-character policy π(ot,i; C) uses both the observation and the agent’s character (C) to decide the action to take. The agent infers the characters of other agents (Cj) using maximum likelihood estimation (MLE) based on collected observation-action trajectories from those agents. The figure highlights the use of a multi-character policy which can handle characters (C1, C2, C3…) and how character inference is used to predict other agents’ behavior.

This table presents the accuracy of character inference at different levels of noise in the collected trajectory data. The accuracy (ACC) is shown as a percentage, along with the standard deviation to quantify the uncertainty. Signal-to-noise ratio (SNR) in dB and a qualitative assessment of quality are also provided for each noise level.
In-depth insights#
EFT Mechanism#
The Episodic Future Thinking (EFT) mechanism, a core contribution of this research paper, presents a novel approach to enhance multi-agent reinforcement learning. It is inspired by cognitive processes in animals, specifically the ability to simulate future scenarios. The EFT mechanism consists of two main modules: a multi-character policy that models diverse agent behaviors and a character inference module that infers the characteristics of other agents. By combining these modules, the agent can predict other agents’ actions, simulate potential future states, and select optimal actions proactively. This proactive decision-making capability significantly improves the agent’s performance, especially in complex, multi-agent environments with diverse agent characteristics. The effectiveness of the EFT mechanism is robust even with varying levels of character diversity, as demonstrated through extensive experimental validation. Accurate character inference is crucial for EFT’s success, as demonstrated by the comparative analysis with a false consensus model. This system represents a significant advancement in MARL, enabling agents to make more sophisticated and socially aware decisions.
Character Inference#
The heading ‘Character Inference’ suggests a crucial section focusing on how the AI agents in a multi-agent system deduce the characteristics or behavioral patterns of other agents. This is a key component for enabling effective collaboration or competition in such systems. The process likely involves observing the actions and states of other agents, and then using a model to infer their underlying motivations and decision-making processes. Accurate character inference is critical because it allows an agent to anticipate the actions of others, plan accordingly, and improve its overall performance. The methods used for character inference might involve machine learning techniques, such as clustering or classification, trained on data from agent interactions. This section would likely describe the model, its training, evaluation metrics, and results, demonstrating its effectiveness. The accuracy and robustness of this process is essential, as inaccurate inference could lead to suboptimal decisions by the AI agent. Therefore, the discussion under this heading might include analysis of inference accuracy under different conditions, exploring the impact of factors such as noise in observations or diversity among agents. The authors likely highlight limitations and areas for future work, particularly around the challenges of inferring complex and dynamic character traits in realistic multi-agent scenarios.
Action Prediction#
Action prediction, in the context of multi-agent systems and reinforcement learning, is a crucial capability for building truly intelligent agents. Accurate prediction of other agents’ actions allows an agent to proactively plan its own actions, leading to improved decision-making in complex environments. The accuracy of the prediction heavily relies on the quality of the agent’s model of other agents, often referred to as a ’theory of mind’ or character inference. The model needs to accurately capture the diversity of agent behaviors and their decision-making processes, which is frequently modeled by incorporating character variables to represent the diverse behavioral preferences. Therefore, robust character inference techniques are essential for effective action prediction. Furthermore, the effectiveness of action prediction often hinges on the ability to simulate the potential future consequences of actions by both itself and other agents, hence future scenario simulation is a key component. Considering uncertainties and partial observability makes action prediction more challenging and necessitates the use of advanced techniques like Monte Carlo methods or deep learning approaches for enhanced accuracy.
Multi-agent RL#
Multi-agent reinforcement learning (MARL) tackles the complexities of training multiple agents to interact within a shared environment. Challenges in MARL arise from the non-stationarity of the environment, as each agent’s actions affect the other agents and change the overall reward structure. Partial observability, where agents only have access to incomplete information, further complicates the learning process. Credit assignment becomes difficult as determining which agent’s actions contributed most to a collective outcome becomes ambiguous. Many approaches address these issues, including techniques like centralized training with decentralized execution (CTDE) to leverage centralized learning benefits while preserving decentralized operation, and methods that explicitly model agent interactions, such as those using communication or theory of mind. Addressing heterogeneity, where agents possess distinct characteristics or preferences, is a growing area of research. Ultimately, the goal of MARL is to create agents capable of effective collaboration and competition in dynamic, complex, and unpredictable multi-agent scenarios.
Future Directions#
Future research could explore several avenues. Extending the EFT mechanism to handle more complex scenarios with larger numbers of agents and diverse interaction patterns is crucial. Investigating different character inference techniques beyond IRC, such as those leveraging deep learning models, could improve accuracy and efficiency. Moreover, incorporation of counterfactual thinking into the EFT framework would add another layer of sophistication, enabling agents to learn from past mistakes and avoid similar situations in the future. Incorporating more nuanced reward functions reflecting real-world complexities and incorporating communication into the decision-making process would improve applicability. Finally, thorough empirical evaluation across various multi-agent environments is needed to fully understand the generalizability and robustness of this framework.
More visual insights#
More on figures

This figure illustrates the Episodic Future Thinking (EFT) mechanism within a Partially Observable Markov Decision Process (POMDP) framework. The EFT mechanism consists of two key modules: future thinking and action selection. The future thinking module predicts future actions of other agents and simulates subsequent observations. This simulation uses predicted actions of others and considers the agent’s own action to be ’no action’ to isolate its impact on the environment. The action selection module then uses the simulated future observation to select an optimal current action. Solid lines and filled circles represent the real-world events and states; dashed lines and grayed circles represent simulated events based on the agent’s predictions and internal model.

This figure demonstrates the performance of the character inference module of the proposed EFT mechanism. Figure 3A shows how the L1-norm between the estimated character and true character decreases as the number of iterations increases, illustrating the convergence of the character inference. Figure 3B shows the trade-off between the length of observation-action trajectory and the number of iterations required for convergence. The results suggest that longer trajectories lead to faster convergence.

This figure shows the reward difference between the proposed method, the FCE-EFT method, and the baseline method (without EFT) across different levels of character diversity (number of character groups). The proposed method, which incorporates accurate character inference, consistently outperforms the other two methods, demonstrating the benefit of accurate character prediction for decision-making in multi-agent environments. In contrast, the FCE-EFT method, which assumes a false consensus effect (all agents have the same character), performs worse than the baseline due to inaccurate character assumptions.
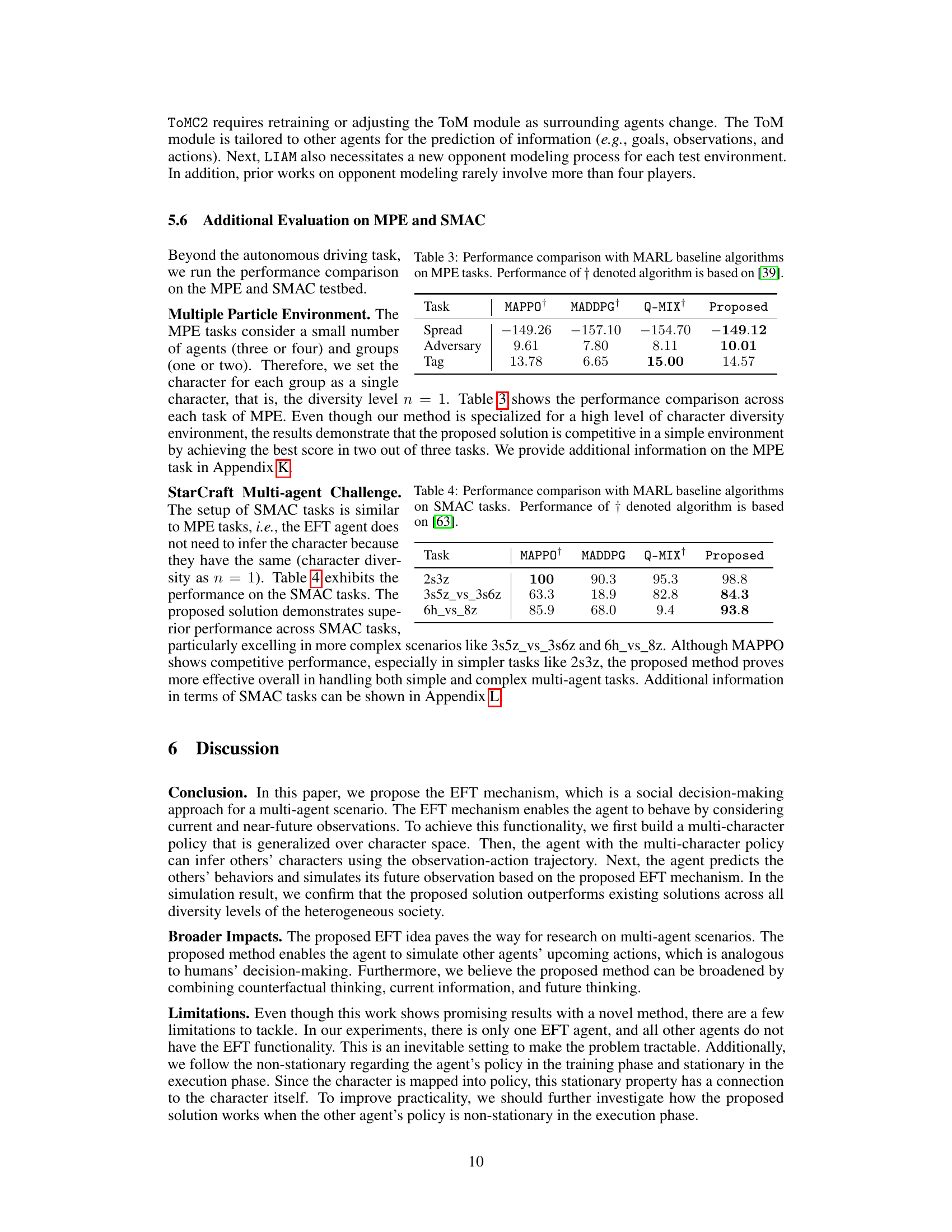
The figure shows the relationship between the accuracy of character inference and the average reward achieved by the proposed EFT mechanism across different levels of character diversity (n=1 to n=5). As character inference accuracy increases, the average reward also increases, demonstrating the effectiveness of accurate character inference in improving decision-making in multi-agent settings. The shaded area represents the confidence interval.
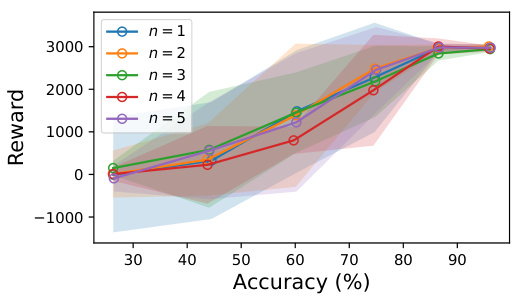
This figure shows the performance of the character inference module when the model is tested on out-of-distribution (OOD) character ranges. Two scenarios are presented: (A) The model is trained on the range [0.0, 0.6] and [0.8, 1.0] and tested on the OOD range {0.65, 0.7, 0.75}; (B) The model is trained on the range [0.2, 0.8] and tested on the OOD range {0.0, 0.1, 0.9, 1.0}. In both cases, the blue circles represent in-distribution samples, while the red circles represent out-of-distribution samples. The gray shaded area indicates the OOD range. The results show that the model can still successfully capture the overall pattern by predicting the extreme values that are close to the true ones, even when tested on OOD ranges.
This figure shows the results of experiments on character inference. Subfigure A shows the convergence of the estimated character to the true character over iterations. Subfigure B shows the trade-off between trajectory length and number of iterations needed for convergence.

Figure I1A shows the contour plots of the log-likelihood function for the combination of character parameters. It shows the convergence of the estimated character to the true one. Figure I1B shows the estimated character value by the agent versus the true character value. It shows the character inference is successful without a large error between the estimated and true value.

The figure shows the reward difference between three different approaches (Proposed, FCE-EFT, w/o EFT) with varying levels of character diversity in a multi-agent system. The proposed approach consistently outperforms the others, highlighting the importance of accurate character inference for effective future thinking in multi-agent decision-making.
More on tables

This table compares the average reward achieved by different multi-agent reinforcement learning algorithms across varying levels of character diversity (number of character groups). The ‘Proposed’ algorithm represents the approach described in the paper, while the others are existing baselines. Higher rewards indicate better performance.

This table compares the performance of the proposed EFT mechanism against three other popular multi-agent reinforcement learning (MARL) algorithms on three different MPE tasks: Spread, Adversary, and Tag. The table shows the average reward achieved by each algorithm on each task. The † symbol indicates that the performance numbers for that algorithm are taken from a previous study [39], rather than reproduced by the authors of this paper.

This table compares the performance of the proposed EFT mechanism against several popular Multi-Agent Reinforcement Learning (MARL) algorithms on three StarCraft Multi-Agent Challenge (SMAC) tasks: 2s3z, 3s5z_vs_3s6z, and 6h_vs_8z. The results show the win rate (percentage) achieved by each algorithm on each task. The proposed EFT method consistently outperforms the other MARL baselines, particularly on the more complex tasks.

This table compares the average reward achieved by different multi-agent reinforcement learning algorithms across varying levels of character diversity in a society. The algorithms compared include the proposed EFT mechanism, several popular MARL algorithms (MADDPG, MAPPO, Q-MIX), model-based RL algorithms (Dreamer, MBPO), and agent modeling algorithms (TOMC2, LIAM). The table shows that the proposed EFT mechanism consistently outperforms other algorithms across different levels of character diversity, highlighting its effectiveness in handling heterogeneous multi-agent interactions.

This table compares the average reward of all agents across different levels of character diversity (number of character groups) for various multi-agent reinforcement learning algorithms. The algorithms include the proposed EFT mechanism, several baseline MARL algorithms (MADDPG, MAPPO, QMIX), model-based RL methods (Dreamer, MBPO), and agent-modeling approaches (TOMC2, LIAM). The results demonstrate that the proposed EFT method outperforms the other algorithms across different levels of diversity.
This table presents the average reward values and their corresponding confidence intervals (with one standard deviation) for different multi-agent reinforcement learning algorithms across various levels of character diversity (number of character groups). The algorithms compared include the proposed EFT mechanism, FCE-EFT (False Consensus Effect), MADDPG, MAPPO, QMIX, Dreamer, MBPO, TOMC2, and LIAM. The confidence intervals provide a measure of the uncertainty in the average reward estimates, reflecting the variability in the experimental results.

This table compares the average reward of all agents across different levels of character diversity (number of character groups) for various multi-agent reinforcement learning algorithms. The algorithms are categorized into MARL (Multi-Agent Reinforcement Learning), model-based RL, and agent modeling approaches. The proposed EFT method is compared against these baselines to demonstrate its superior performance across all diversity levels.

This table compares the average reward achieved by different multi-agent reinforcement learning algorithms across various levels of character diversity (number of character groups). The ‘Proposed’ algorithm represents the novel EFT mechanism introduced in the paper. Other algorithms serve as baselines for comparison, illustrating the performance of existing approaches in managing heterogeneous agents. The results show that the proposed algorithm consistently outperforms the baselines, particularly as character diversity increases. This highlights the effectiveness of the EFT mechanism in enhancing collaborative decision-making in complex, diverse environments.

This table compares the performance of the proposed EFT mechanism against several popular multi-agent reinforcement learning (MARL) algorithms on three different Multiple Particle Environment (MPE) tasks: Spread, Adversary, and Tag. The table shows the average reward achieved by each algorithm on each task, along with the standard deviation (represented by ± values). The results highlight the relative performance of the proposed method compared to existing MARL approaches in these specific MPE scenarios.
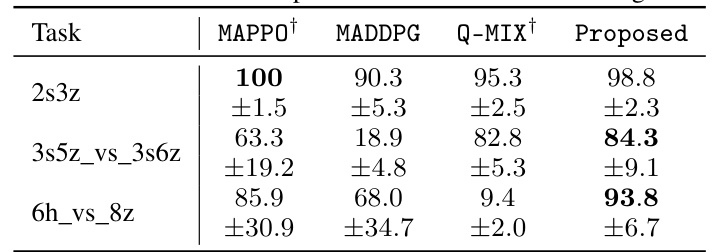
This table compares the performance of the proposed EFT mechanism against several popular Multi-Agent Reinforcement Learning (MARL) algorithms on three different StarCraft Multi-Agent Challenge (SMAC) tasks: 2s3z, 3s5z_vs_3s6z, and 6h_vs_8z. The results show the average reward and standard deviation for each algorithm on each task. The proposed method outperforms the baselines across all tasks, demonstrating its effectiveness in complex scenarios.
Full paper#