↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open-world semi-supervised learning (OwSSL) faces challenges as unlabeled data might contain samples from unseen classes, leading to misclassification. Existing methods often struggle with confirmation bias (models favoring known classes) and clustering misalignment (inconsistent clustering criteria). These issues hinder accurate classification of both known and unknown classes.
OwMatch tackles these problems using conditional self-labeling (incorporating labeled data to guide self-labeling) and open-world hierarchical thresholding (adapting thresholds based on class confidence). This approach leads to unbiased self-label assignments, improved clustering, and a balanced learning process. Experiments on various datasets (CIFAR-10, CIFAR-100, ImageNet-100) demonstrate significant performance improvements, surpassing previous state-of-the-art models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in semi-supervised learning and open-world settings. It offers a novel framework, OwMatch, that significantly improves accuracy by addressing the challenges of confirmation bias and clustering misalignment. Its theoretical analysis and empirical results provide strong support for its effectiveness, opening avenues for future work on more robust and unbiased self-labeling techniques for open-world scenarios. This work also contributes to a better understanding of self-labeling methods and their limitations, improving the reliability of self-supervised learning models.
Visual Insights#

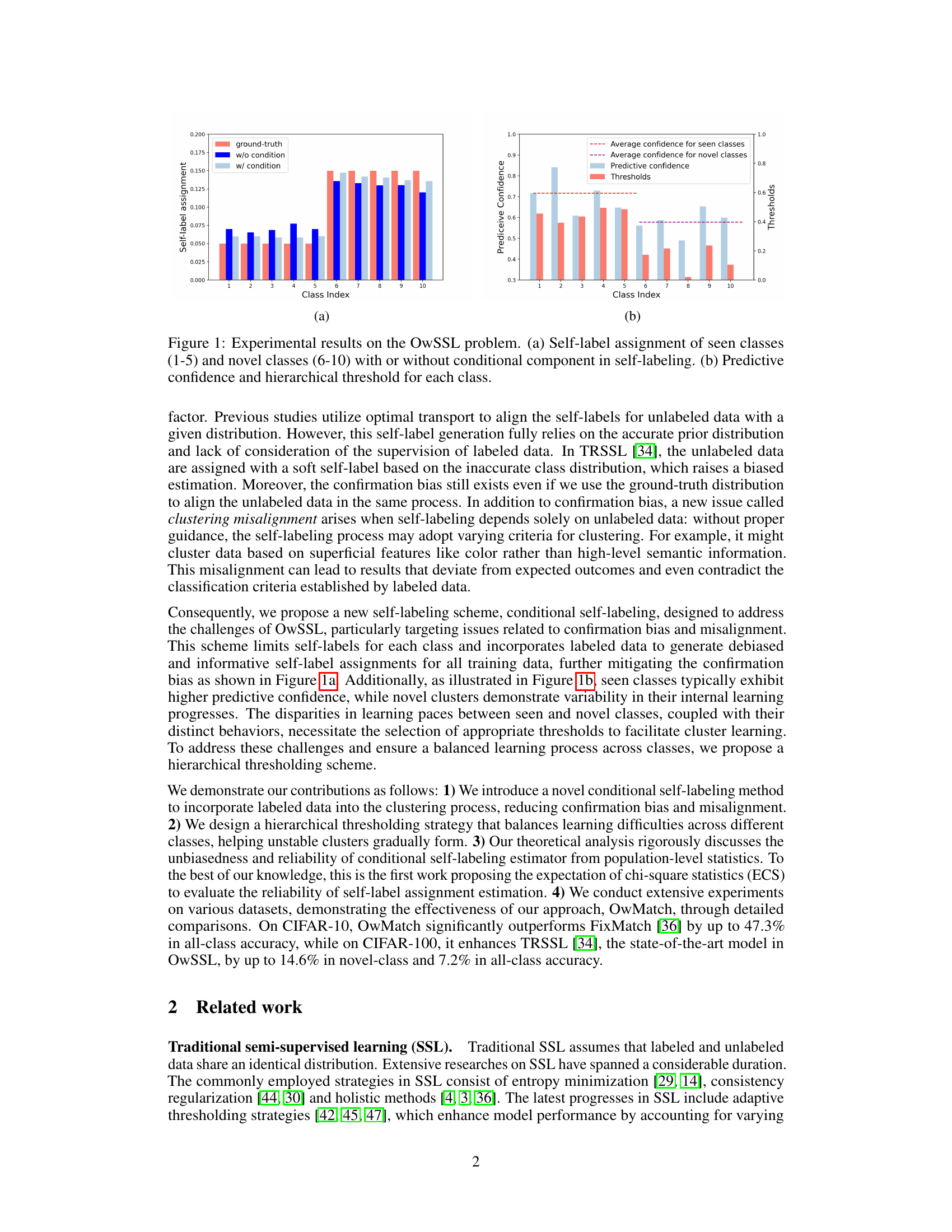
This figure presents experimental results related to open-world semi-supervised learning. Subfigure (a) compares self-label assignments for seen and unseen classes with and without the proposed conditional self-labeling method. It shows the conditional method produces self-label assignments closer to ground truth. Subfigure (b) displays the predictive confidence and the hierarchical thresholds applied to different classes during the learning process, illustrating the difference in learning progress between known and unknown classes.
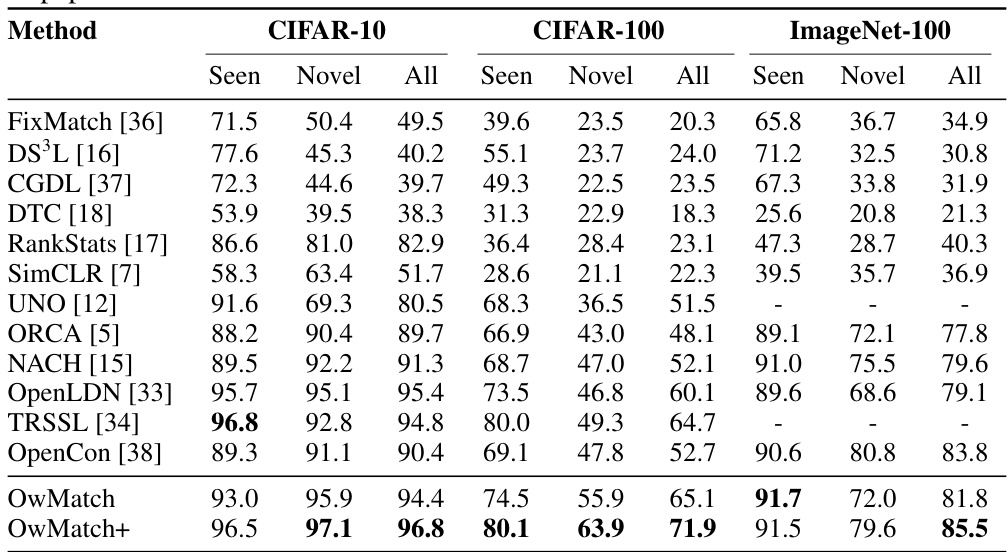
This table presents a comparison of the OwMatch model’s performance against other state-of-the-art models for open-world semi-supervised learning (OwSSL) on three benchmark datasets: CIFAR-10, CIFAR-100, and ImageNet-100. The table includes both seen and novel class accuracies for each method, giving a comprehensive overview of the performance on both known and unknown classes. It also compares OwMatch with traditional SSL, OSSL, and NCD approaches, highlighting its improved performance.
In-depth insights#
OwSSL Framework#
An OwSSL (Open-World Semi-Supervised Learning) framework tackles the challenges of traditional SSL by addressing the presence of unseen classes in unlabeled data. A key innovation is the integration of conditional self-labeling, which refines self-label assignments by incorporating labeled data to reduce confirmation bias. This is coupled with open-world hierarchical thresholding which dynamically adjusts prediction confidence thresholds to handle the varied learning paces between known and unknown classes. The framework’s theoretical grounding demonstrates the unbiased nature of the self-labeling estimator. Empirical results highlight significant performance gains over existing methods across multiple datasets, showing improvements for both known and novel classes. The framework’s design directly addresses the core issues inherent in OwSSL, making it a noteworthy advancement in the field.
Conditional Self-Labeling#
Conditional self-labeling, a crucial aspect of the OwMatch framework, significantly enhances the robustness of open-world semi-supervised learning. Instead of relying solely on unlabeled data for self-label assignment, OwMatch incorporates labeled data, mitigating the confirmation bias inherent in unsupervised methods. This conditional approach ensures the self-labels are more informed and aligned with the actual class distributions. By combining conditional self-labeling with open-world hierarchical thresholding, OwMatch effectively balances the learning process across seen and unseen classes, addressing challenges of inconsistent learning paces. The theoretical analysis further supports the method’s effectiveness, demonstrating that the conditional self-labeling estimator is unbiased, and the expectation of chi-square statistics (ECS) metric evaluates its reliability. This sophisticated approach leads to substantial performance improvements in various experiments, demonstrating a considerable advancement in handling open-world scenarios within semi-supervised learning.
Hierarchical Thresholding#
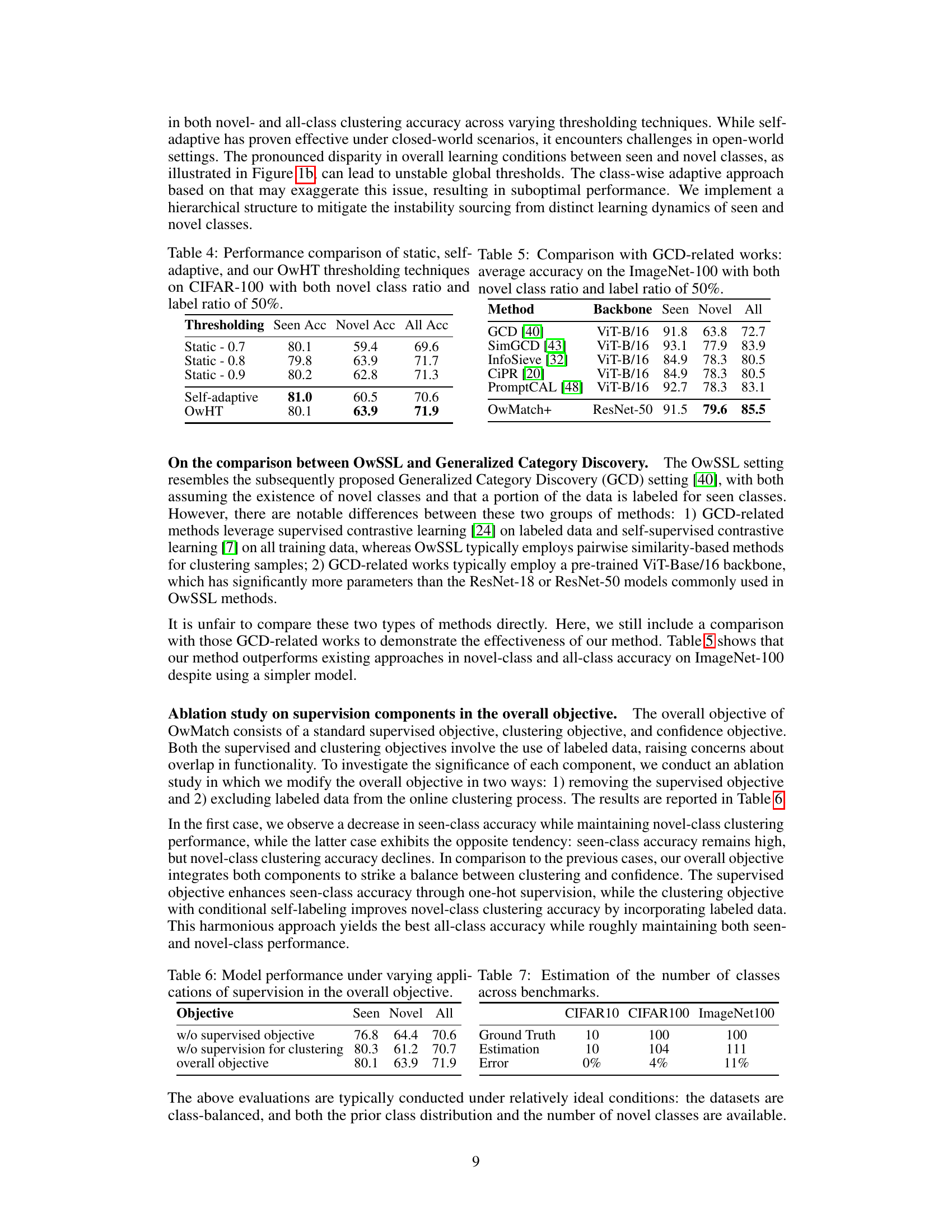
Hierarchical thresholding, as presented in the context of open-world semi-supervised learning (OwSSL), is a crucial technique to address the challenge of imbalanced learning progress between seen and novel classes. The core idea is to dynamically adjust thresholds for assigning pseudo-labels based on the confidence of model predictions, rather than using a global or class-agnostic threshold. This addresses the issue where novel classes often exhibit lower confidence and slower learning rates, leading to unreliable pseudo-labeling. By creating a hierarchy, often a two-level system dividing seen and novel classes, the approach tailors the thresholding strategy to the specific characteristics of each group. This allows for more effective pseudo-label assignment for novel classes, improving their learning and reducing confirmation bias. The effectiveness of this approach is particularly beneficial in open-world settings where unseen data continuously presents classification challenges. The implementation details often involve predictive confidence estimates for individual classes and hierarchical thresholds that account for confidence variability. This method results in a more balanced learning process across all classes and improved overall model performance.
OwMatch Analysis#
OwMatch analysis would delve into a multifaceted evaluation of the proposed framework. It would likely begin with a theoretical analysis, rigorously justifying the framework’s design choices and demonstrating its unbiasedness and reliability. Empirical results across various datasets and scenarios would then be presented, showcasing OwMatch’s performance relative to existing methods. This would involve a detailed breakdown of the results, possibly including separate analyses for seen and unseen classes. The analysis would also address the impact of key components such as conditional self-labeling and open-world hierarchical thresholding, highlighting their individual and combined contributions to the overall performance. Furthermore, a comparison of different thresholding strategies and sensitivity analyses regarding factors like data imbalance and the number of novel classes would further establish the framework’s robustness and limitations. Finally, the analysis may include a discussion of the broader implications of OwMatch for open-world semi-supervised learning and potential future research directions.
Future of OwMatch#
The future of OwMatch hinges on addressing its current limitations and exploring new avenues for improvement. Extending OwMatch to handle highly imbalanced datasets and diverse data distributions is crucial for real-world applicability. This could involve incorporating advanced techniques for handling class imbalance and developing more robust methods for estimating class distributions in the absence of prior knowledge. Improving the efficiency and scalability of OwMatch is another key area for development. The current approach relies on computationally expensive steps like the Sinkhorn-Knopp algorithm; exploring more efficient alternatives would significantly enhance its practicality. Integrating OwMatch with other open-world learning paradigms, such as continual learning and few-shot learning, is a promising direction. This would lead to a more adaptive and robust framework capable of handling novel classes and evolving data distributions in dynamic environments. Finally, thorough theoretical analysis of OwMatch’s generalization capabilities is needed to further solidify its foundations and guide future research. This includes understanding how well the model handles unseen classes and its susceptibility to confirmation bias. Future work might focus on refining the theoretical framework, improving the self-labeling strategy, and developing more powerful methods for clustering novel classes.
More visual insights#
More on figures

This figure illustrates the hierarchical thresholding scheme used in the OwMatch framework. It shows how the predictive confidence is used to generate thresholds for seen and novel classes. Seen classes generally have higher predictive confidence and thus have a higher threshold, while novel classes exhibit more variability in their confidence levels and therefore have a hierarchical thresholding strategy applied to them.
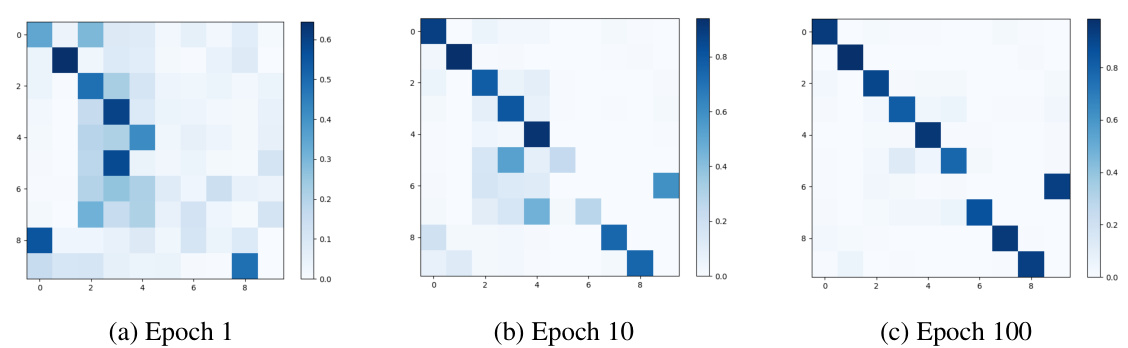
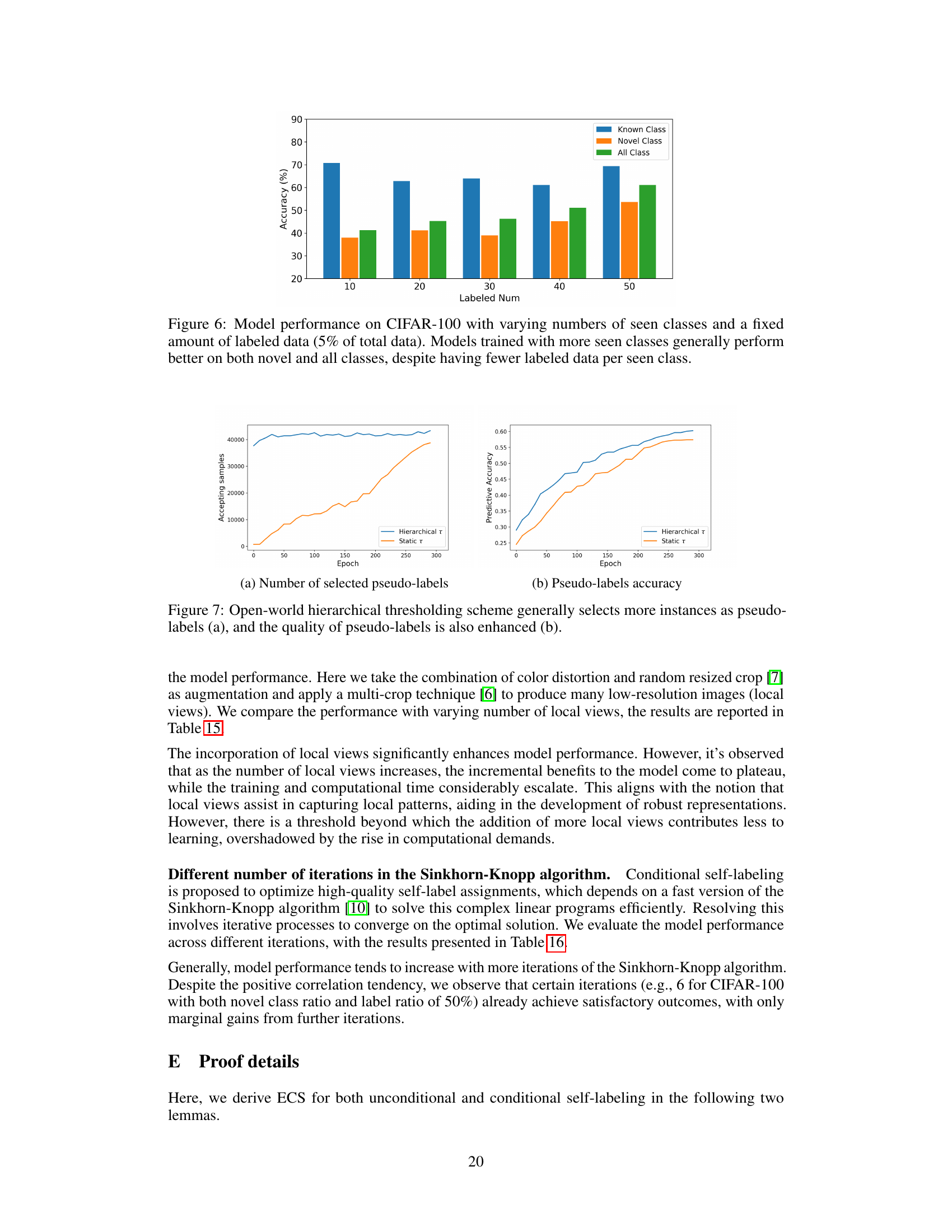
This figure shows confusion matrices for CIFAR-10 at different training epochs (1, 10, and 100). It visualizes how the model’s ability to distinguish between seen and novel classes improves during training. The diagonal elements represent accurate classification of seen classes. The off-diagonal elements, particularly the dark blue blocks, illustrate the model’s progress in correctly clustering novel classes with their ground truth labels. The matrices show a clear trend towards improved classification and clustering accuracy as training progresses.
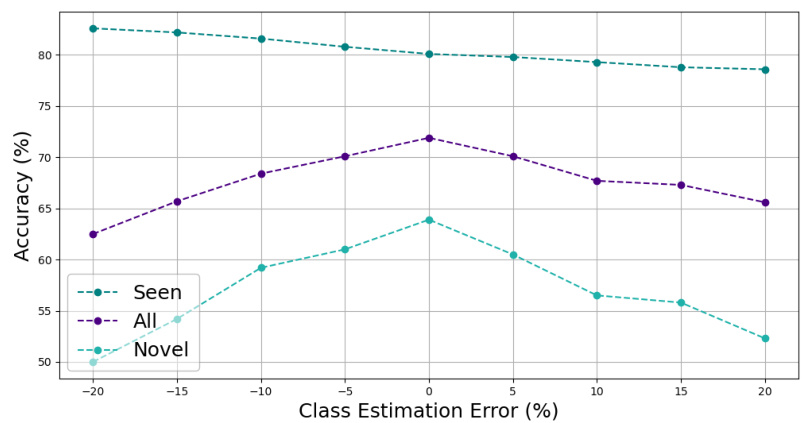
This figure shows how the accuracy of the OwMatch model changes with different levels of class estimation error on the CIFAR-100 dataset. The accuracy is shown for three categories: seen classes (already known to the model), novel classes (unknown to the model), and all classes (both seen and novel). It demonstrates the robustness of OwMatch’s performance even when the model’s initial estimate of the number of classes is imperfect. The graph shows that the overall accuracy (Seen + Novel) remains relatively stable, even with a significant estimation error, highlighting the model’s resilience to errors in the initial class number estimation.

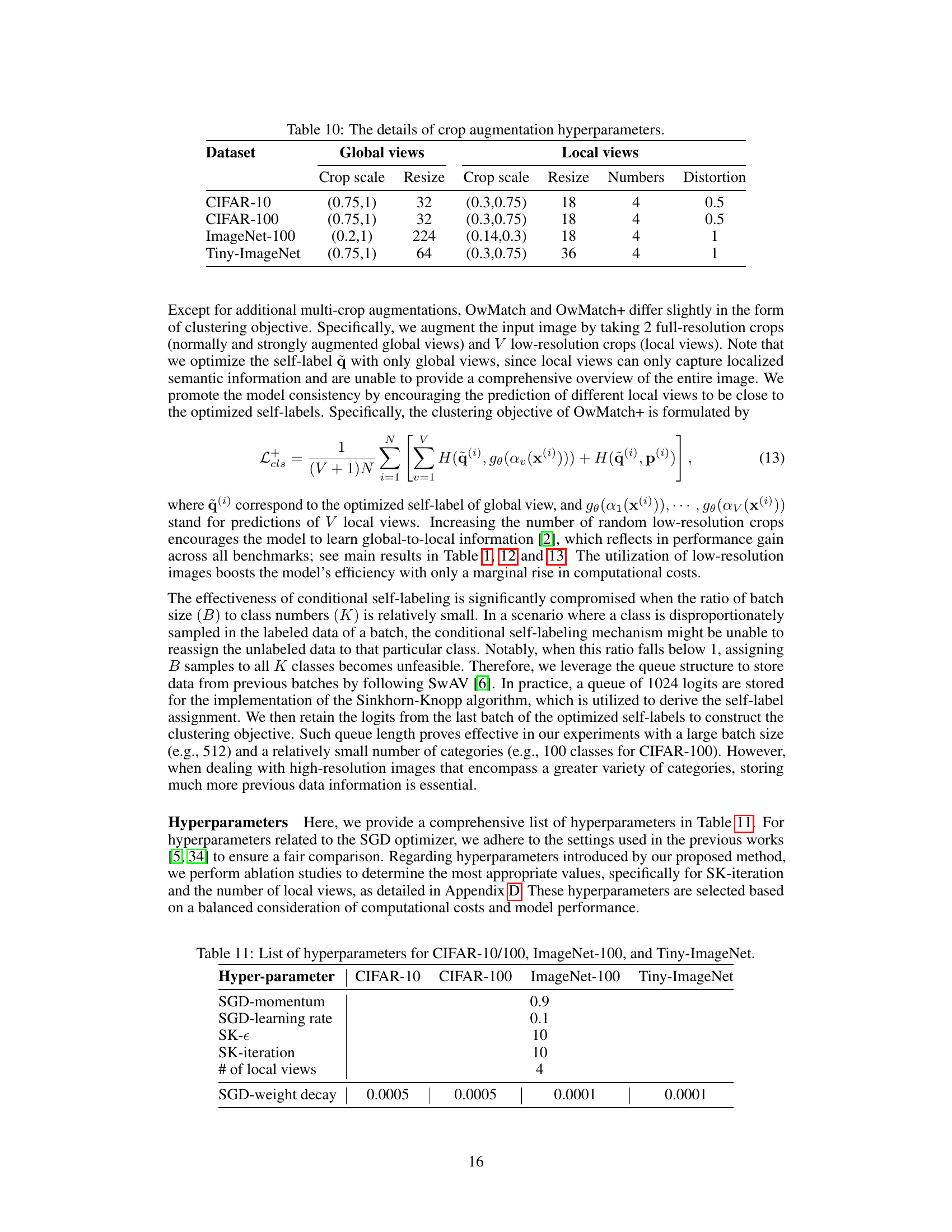
This figure shows the impact of the number of seen classes on the model’s performance when the total amount of labeled data is fixed at 5% of the total dataset. The results indicate that models trained with more seen classes achieve higher accuracy on both known and novel classes, even though there are fewer labeled samples per class. This suggests that a wider range of seen classes, even with fewer labeled examples, can be more beneficial for open-world semi-supervised learning.
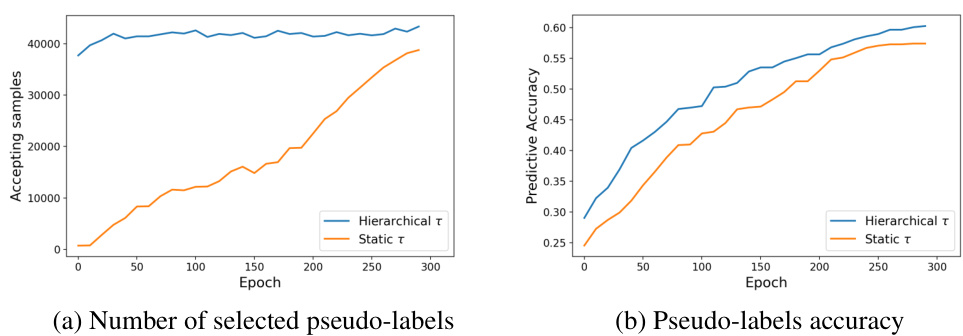
This figure shows experimental results on the open-world semi-supervised learning (OwSSL) problem. Panel (a) compares the self-label assignment for seen and novel classes with and without the conditional component in the self-labeling method. It demonstrates that the conditional approach leads to a better assignment of self-labels, especially for novel classes. Panel (b) illustrates the predictive confidence and hierarchical thresholds assigned to each class. This shows that seen classes typically have higher confidence and different thresholding strategies are used for seen and novel classes.
More on tables

This table presents a comparison of OwMatch’s performance against other state-of-the-art methods in open-world semi-supervised learning (OwSSL) across three different datasets: CIFAR-10, CIFAR-100, and ImageNet-100. The comparison includes both seen classes (classes with labeled data) and novel classes (unseen classes). The table shows the average accuracy for each method across seen, novel, and all classes. It also includes a comparison to traditional semi-supervised learning, open-set semi-supervised learning, and novel class discovery methods for a comprehensive evaluation.
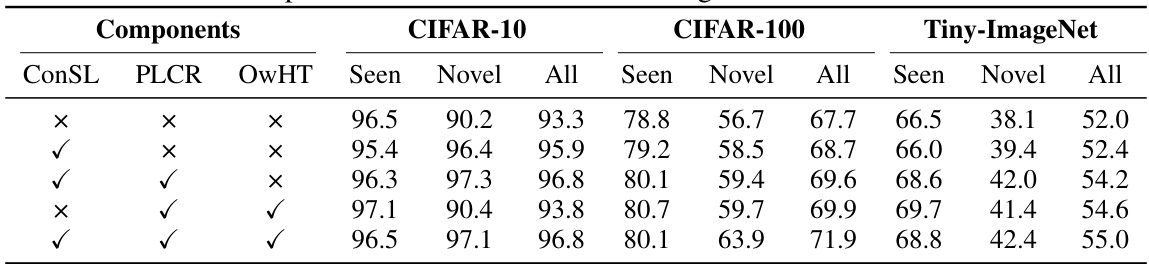
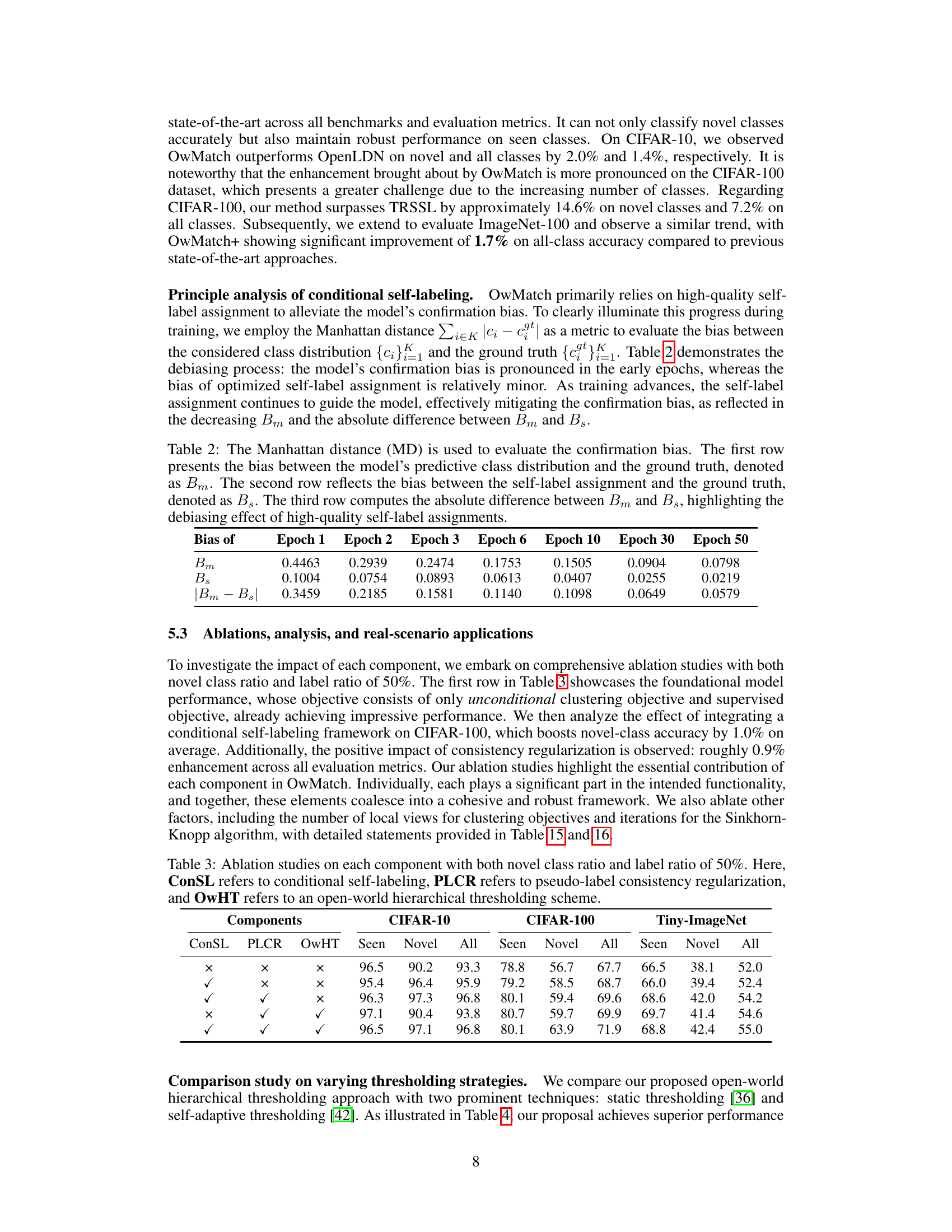
This table presents the ablation study results on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. It shows the impact of different components of the OwMatch model on the accuracy of seen classes, novel classes, and all classes. The components evaluated are conditional self-labeling (ConSL), pseudo-label consistency regularization (PLCR), and open-world hierarchical thresholding (OwHT). Each row represents a different combination of these components, allowing for an assessment of their individual and combined effects on model performance.
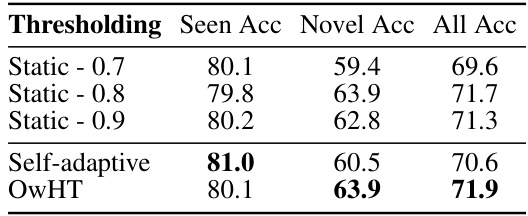
This table compares the performance of three different thresholding techniques: static thresholding (with different threshold values), self-adaptive thresholding, and the proposed open-world hierarchical thresholding (OwHT). The comparison is done on the CIFAR-100 dataset with both a novel class ratio and label ratio of 50%. The results show the accuracy achieved by each thresholding technique on seen classes, novel classes, and all classes combined. OwHT demonstrates a good balance between the accuracy achieved on seen and novel classes.

This table compares the performance of OwMatch+ against several other state-of-the-art methods on the ImageNet-100 dataset. The comparison focuses specifically on the accuracy achieved on seen and novel classes, as well as overall accuracy. A key aspect highlighted is that OwMatch+ uses a ResNet-50 backbone, while the others use the more complex ViT-B/16 backbone.

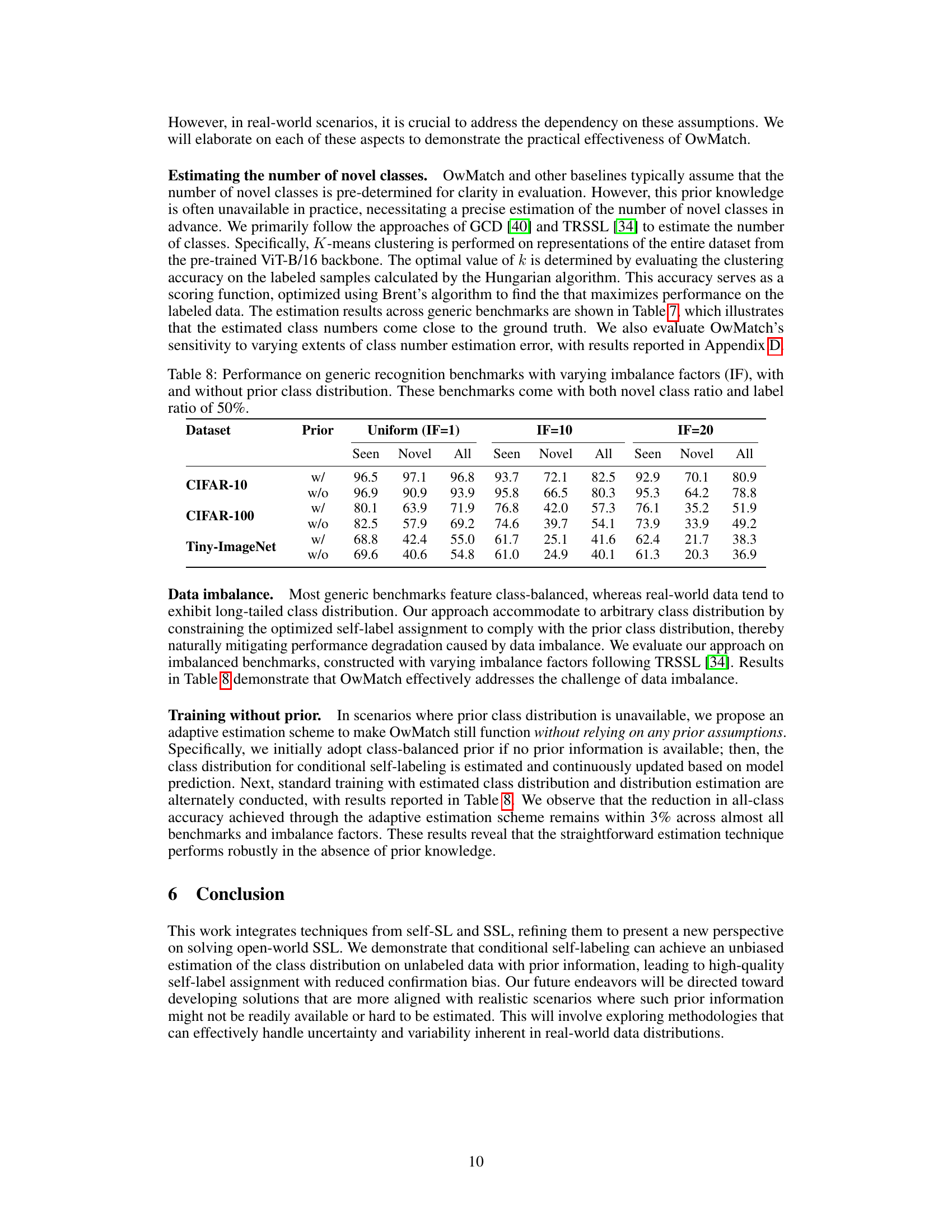
This table presents the ground truth number of classes and the estimated number of classes obtained using the proposed method for CIFAR-10, CIFAR-100, and ImageNet-100 datasets. The estimation is performed using K-means clustering on feature representations of the entire dataset and selecting the optimal number of clusters (k) based on clustering accuracy on the labeled samples (evaluated using the Hungarian algorithm). The error is calculated as the absolute difference between ground truth and estimation, expressed as a percentage.

This table presents the performance of the OwMatch model on three benchmark datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet) under different levels of data imbalance, indicated by the imbalance factor (IF). It shows the accuracy (Seen, Novel, and All) for each dataset with and without utilizing prior class distribution information. The results highlight the robustness of OwMatch to varying degrees of class imbalance, even when prior knowledge about class distribution is not available.

This table presents a comparison of the OwMatch model’s performance against several existing methods on three different datasets (CIFAR-10, CIFAR-100, and ImageNet-100). The comparison includes traditional semi-supervised learning (SSL) methods, open-set semi-supervised learning (OSSL) methods, and novel class discovery (NCD) methods. The table shows the accuracy achieved by each method on seen classes, novel classes, and all classes, with both novel class ratio and label ratio set at 50%. The results highlight OwMatch’s superior performance compared to existing state-of-the-art models.
This table presents a comparison of the proposed OwMatch model’s performance with existing state-of-the-art methods for open-world semi-supervised learning (OwSSL) on CIFAR-10, CIFAR-100, and ImageNet-100 datasets. The comparison includes traditional SSL, open-set SSL (OSSL), and novel class discovery (NCD) methods, highlighting OwMatch’s superiority. Results are averaged across three runs and show seen, novel, and all-class accuracy.
This table compares the performance of OwMatch against other semi-supervised learning methods on three image classification datasets: CIFAR-10, CIFAR-100, and ImageNet-100. The comparison includes traditional SSL, open-set SSL (OSSL), and novel class discovery (NCD) methods. The results show the average accuracy for both seen and novel classes, with a novel class ratio and label ratio of 50%.

This table presents a comparison of the proposed OwMatch model’s performance against existing state-of-the-art methods on CIFAR-10, CIFAR-100, and ImageNet-100 datasets. It includes results for both seen and novel classes, as well as overall accuracy. The comparison includes various semi-supervised learning techniques and considers both novel class ratio and label ratio at 50%. Baseline performance figures are sourced from the original papers referenced.
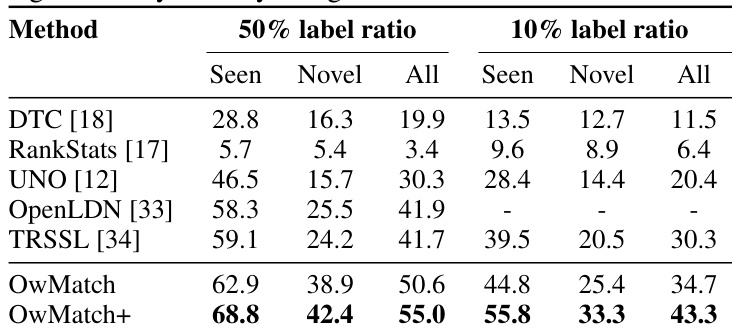
This table presents the average accuracy results on the Tiny-ImageNet dataset. The results are broken down by the label ratio used (10% and 50%) and further categorized into Seen (accuracy on seen classes), Novel (accuracy on novel classes), and All (overall accuracy). Multiple methods are compared, allowing for a direct comparison of performance across different techniques under varying data labeling conditions.

This table presents the results of experiments conducted to evaluate the model’s performance under different novel class ratios. The novel class ratio is varied from 50% to 90%, while maintaining a constant label ratio of 50% within seen classes. The table shows the accuracy for seen classes, novel classes and all classes across three benchmark datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet). It demonstrates how the model’s performance changes as the proportion of novel classes in the dataset increases.
This table presents the average accuracy results on the Tiny-ImageNet dataset using OwMatch and OwMatch+. The results are broken down by seen class accuracy, novel class accuracy, and overall accuracy, with separate columns for experiments using 10% and 50% label ratios. It shows the performance comparison with other methods on this dataset.
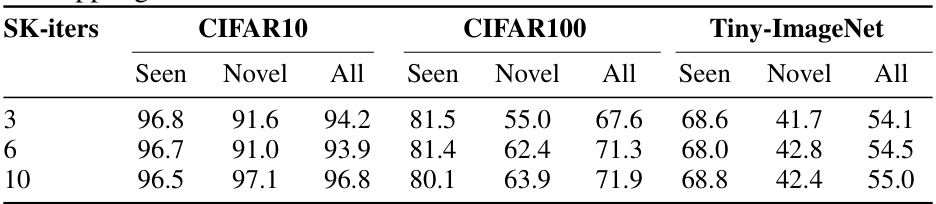
This table presents the results of an ablation study on the number of iterations used in the Sinkhorn-Knopp algorithm, a key component of the OwMatch framework. The table shows the performance (Seen, Novel, and All accuracy) of the model on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets, with varying numbers of iterations (3, 6, and 10). This analysis helps to determine the optimal number of iterations for balancing computational cost and model performance.
Full paper#