↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating realistic novel views from just one image is a tough task in computer vision. Current methods often struggle with inaccurate depth estimations and lose important details when warping the image. This leads to blurry or unrealistic results in the new views.
The researchers introduced GenWarp, a new method that cleverly combines a generative model (like Stable Diffusion) with a special attention mechanism. This attention mechanism helps the model decide which parts of the image to warp and which parts to generate, avoiding the problems of previous approaches. Their experiments showed GenWarp produced much better results, especially when dealing with images outside of the usual training data.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to novel view synthesis, a challenging problem in computer vision. The GenWarp framework offers significant improvements over existing methods, particularly in handling noisy depth maps and preserving semantic details. This opens up new avenues for research in image generation and 3D scene understanding, and its high-quality results have potential applications in various fields.
Visual Insights#

This figure demonstrates the model’s ability to generate novel views from a single input image. The top row shows examples of in-domain images (images similar to those the model was trained on), where the model generates consistent and plausible views when moving left or right. The bottom row displays the model’s performance on out-of-domain images (images different from the training data). It successfully generates plausible views for these images as well, demonstrating the model’s generalization capabilities.
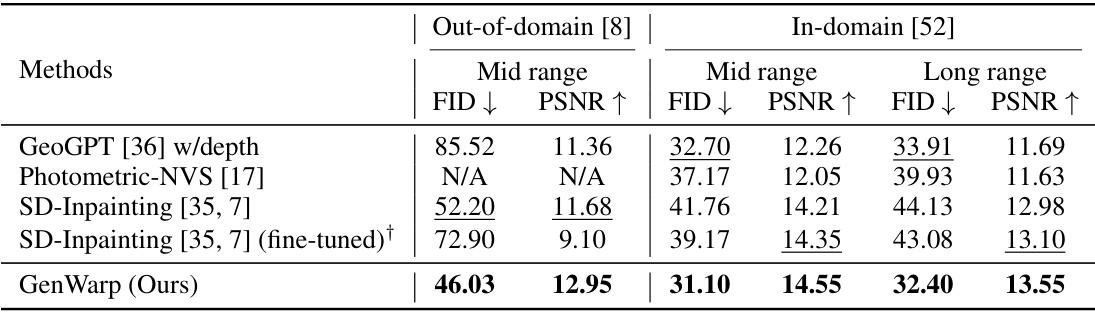
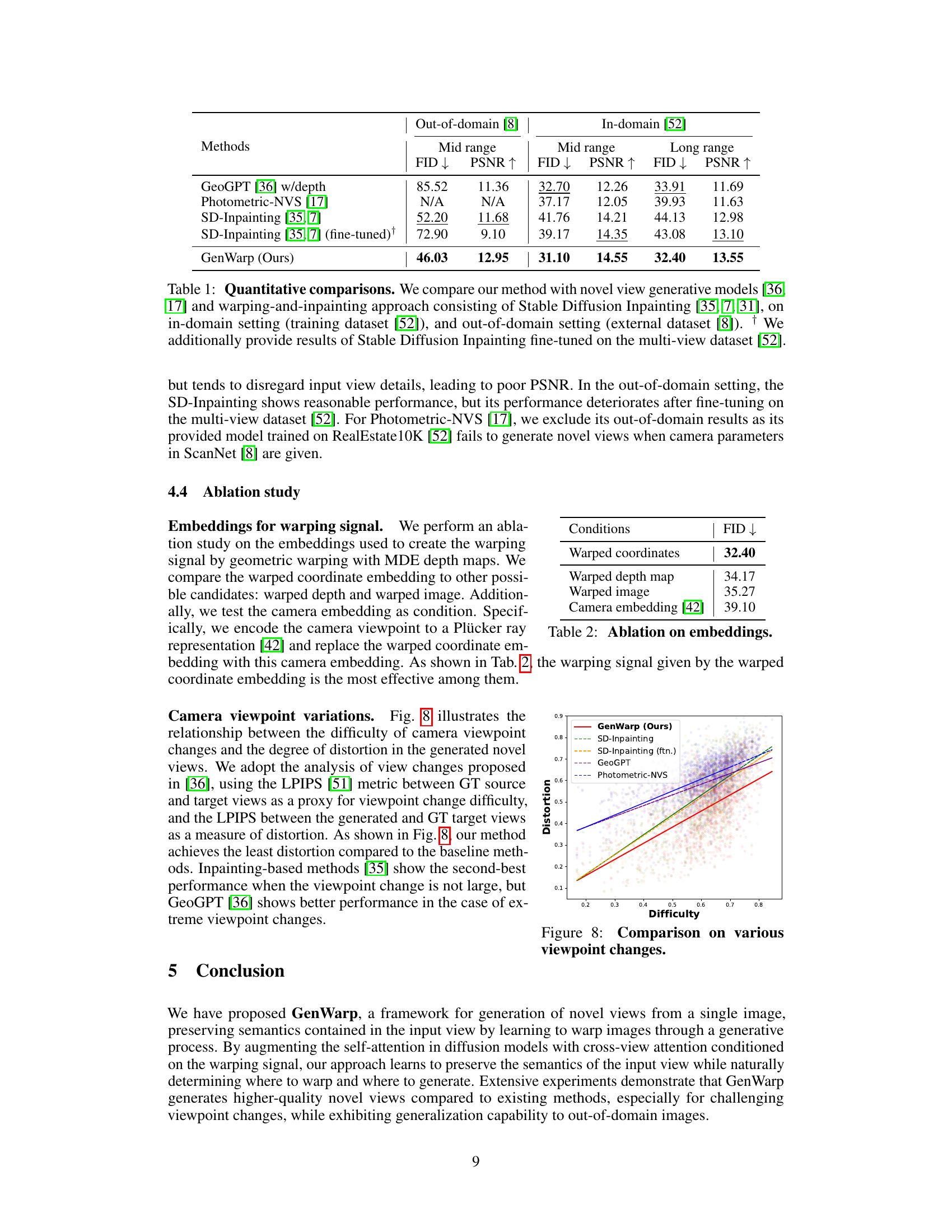
This table presents a quantitative comparison of the proposed GenWarp model against several baseline methods for novel view synthesis. The comparison is conducted on both in-domain (RealEstate10K) and out-of-domain (ScanNet) datasets. Metrics used include FID (Fréchet Inception Distance) and PSNR (Peak Signal-to-Noise Ratio) for both mid-range and long-range viewpoint changes. The results demonstrate the superiority of GenWarp in terms of FID and PSNR, especially in the out-of-domain setting. A fine-tuned version of one of the baseline methods (SD-Inpainting) is also included for a more comprehensive comparison.
In-depth insights#
GenWarp Overview#
GenWarp, as the name suggests, is a generative warping framework designed for high-quality novel view synthesis from a single image. Its core innovation lies in semantic-preserving generative warping, moving beyond the limitations of traditional warping-and-inpainting methods. Unlike methods that warp an input image and then inpaint missing regions, GenWarp trains a diffusion model to intelligently decide where to warp and where to generate. This is accomplished through an innovative two-stream architecture and the augmentation of self-attention with cross-view attention. The model cleverly uses depth maps, but not in the traditional warping sense, allowing it to handle noisy depth estimations more robustly. Augmenting self-attention allows the diffusion model to incorporate both warping information and generate novel content seamlessly. The result is superior performance in generating plausible novel views, especially for challenging scenarios involving significant viewpoint changes or out-of-domain images.
Semantic Preservation#
Semantic preservation in novel view synthesis aims to retain the meaning and context of the original image when generating new viewpoints. Methods achieving this often struggle with the inherent challenges of geometric warping, which can distort or lose details, especially in areas with occlusion or noisy depth maps. Successful semantic preservation requires careful consideration of how to combine geometric warping with generative models. Strategies may involve conditioning the generative model on the original image features to ensure consistency and leveraging attention mechanisms to selectively warp regions with high confidence while generating new content for occluded or ambiguous areas. Ultimately, semantic preservation hinges on the ability to guide the generation process to maintain the original intent, rather than simply inpainting arbitrary content into the warped image. The evaluation of semantic preservation typically involves both qualitative visual assessment and quantitative metrics that measure the similarity between the generated novel view and the original image’s semantic content.
Warping & Inpainting#
The core concept of ‘Warping & Inpainting’ in novel view synthesis involves geometrically transforming a single input image to simulate different viewpoints, followed by filling in any resulting holes or inconsistencies. Warping leverages depth information, often estimated using monocular depth estimation methods, to project pixels from the source image to their corresponding locations in the target view. However, this process often suffers from depth estimation errors, leading to artifacts in the warped image. To rectify these issues, inpainting uses a generative model, such as a large-scale text-to-image diffusion model, to seamlessly fill in the missing or distorted regions. The generative model’s ability to understand context and synthesize realistic details is crucial for producing high-quality results. The challenge lies in the interplay between the warping and inpainting stages. Noisy or inaccurate depth maps can significantly hinder the warping process and make inpainting much more difficult. A key area of improvement focuses on designing effective methods for robust depth estimation, refining the geometric warping algorithm, and ensuring smooth transitions between warped and generated regions to avoid noticeable artifacts.
Cross-View Attention#
Cross-view attention, in the context of novel view synthesis, is a crucial mechanism for generating realistic and consistent images from unseen viewpoints. It elegantly addresses the challenge of limited data by leveraging existing information from the source image. Instead of relying solely on depth maps, which can be noisy and inaccurate, cross-view attention learns implicit correspondences between features of the source and target views. This allows the model to ‘warp’ features implicitly, mitigating the artifacts often introduced by explicit warping techniques. By integrating this mechanism with self-attention, the model intelligently determines where to generate novel content and where to warp features from the source image, resulting in high-quality, semantically coherent novel views. This hybrid approach combines the strengths of geometric warping and generative image synthesis and represents a significant advancement in handling both in-domain and out-of-domain images.
Future of GenWarp#
The future of GenWarp hinges on several key areas. Improving depth estimation is crucial; more accurate depth maps will directly translate to higher-fidelity warped images, reducing artifacts and enhancing realism. Incorporating more sophisticated attention mechanisms could further improve semantic preservation, allowing GenWarp to handle more complex scenes and challenging viewpoints with greater accuracy. Exploring alternative generative models beyond diffusion models might unlock new capabilities, potentially leading to faster generation speeds or improved control over the generated images. Extending the framework to handle video data is a natural next step, opening exciting possibilities for novel view synthesis in dynamic scenes. Finally, addressing the limitations of dealing with out-of-domain images and noisy depth maps remains a focus. Progress in these areas will significantly expand GenWarp’s capabilities and applications in areas such as virtual reality, augmented reality, and 3D modeling.
More visual insights#
More on figures

This figure demonstrates the limitations of the warping-and-inpainting approach for novel view synthesis. The top row shows an example where noisy depth estimation leads to distortions in the warped image, which the inpainting model struggles to correct. The bottom row shows an example of severe occlusion where the warped image loses significant semantic details, resulting in an incomplete and inaccurate novel view. GenWarp addresses these limitations by utilizing a generative warping approach, instead of relying on explicit warping followed by inpainting.

This figure illustrates the GenWarp framework’s architecture. The left side shows the process of generating a novel view image from a single input view, using MDE (Monocular Depth Estimation) to create warped coordinates and a semantic preserver network to extract semantic features. A pretrained T2I (text-to-image) diffusion model then combines these to generate the novel view. The right side details how cross-view attention and self-attention are combined to improve the model’s ability to determine what to warp and what to generate.
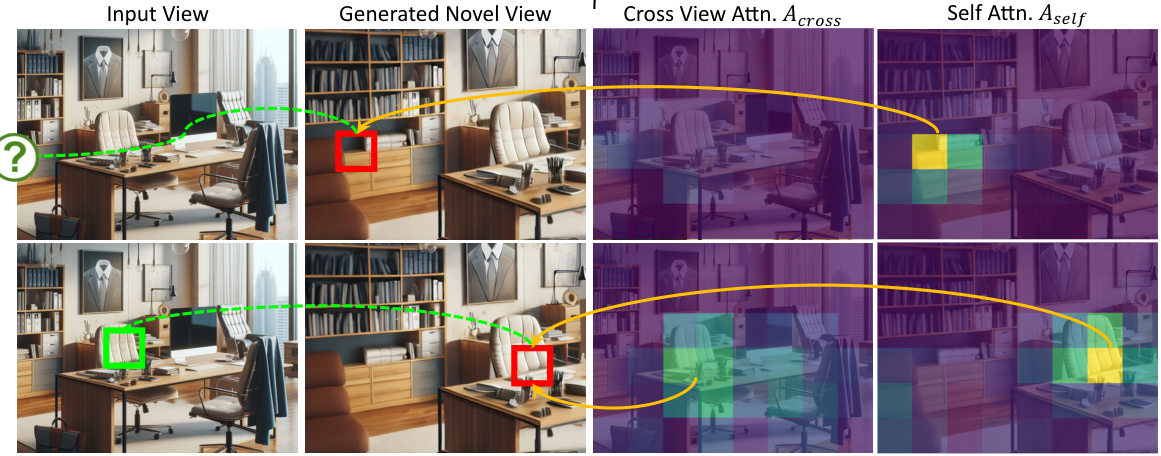
This figure visualizes the augmented self-attention map used in the GenWarp model. It shows how the model combines self-attention (focusing on areas needing generation) and cross-view attention (focusing on areas that can be reliably warped from the input image) to determine which parts of a novel view to generate and which to warp from the input image. The top row shows a situation where the self-attention focuses on an occluded area, while the bottom row shows a situation where it focuses on an area that is poorly warped due to noise in the depth map. The cross-view attention helps the model maintain consistency and coherence between the input and generated views.

This figure shows a qualitative comparison of the proposed GenWarp method against the Stable Diffusion Inpainting method on several in-the-wild images. It demonstrates the ability of GenWarp to generate more realistic and semantically consistent novel views compared to the baseline method, particularly in challenging scenarios with significant viewpoint changes or occlusions.

This figure showcases qualitative results from the GenWarp model and baselines (Stable Diffusion Inpainting [35] and a warping-and-inpainting approach [7]) on a diverse set of real-world images. The results demonstrate the ability of GenWarp to generate high-quality and semantically consistent novel views from a single input image, even when dealing with complex and varied scenes. It particularly highlights the model’s strengths over baseline methods in situations with challenging camera viewpoints or scenes with significant occlusions.

This figure compares the novel view generation results of the proposed GenWarp model with three baseline methods: Stable Diffusion Inpainting, Photometric-NVS, and GeoGPT. The comparison uses images from the RealEstate10K dataset, showcasing the ability of each method to generate novel views with significant viewpoint changes. GenWarp demonstrates superior performance in generating high-quality, consistent views compared to the baselines.

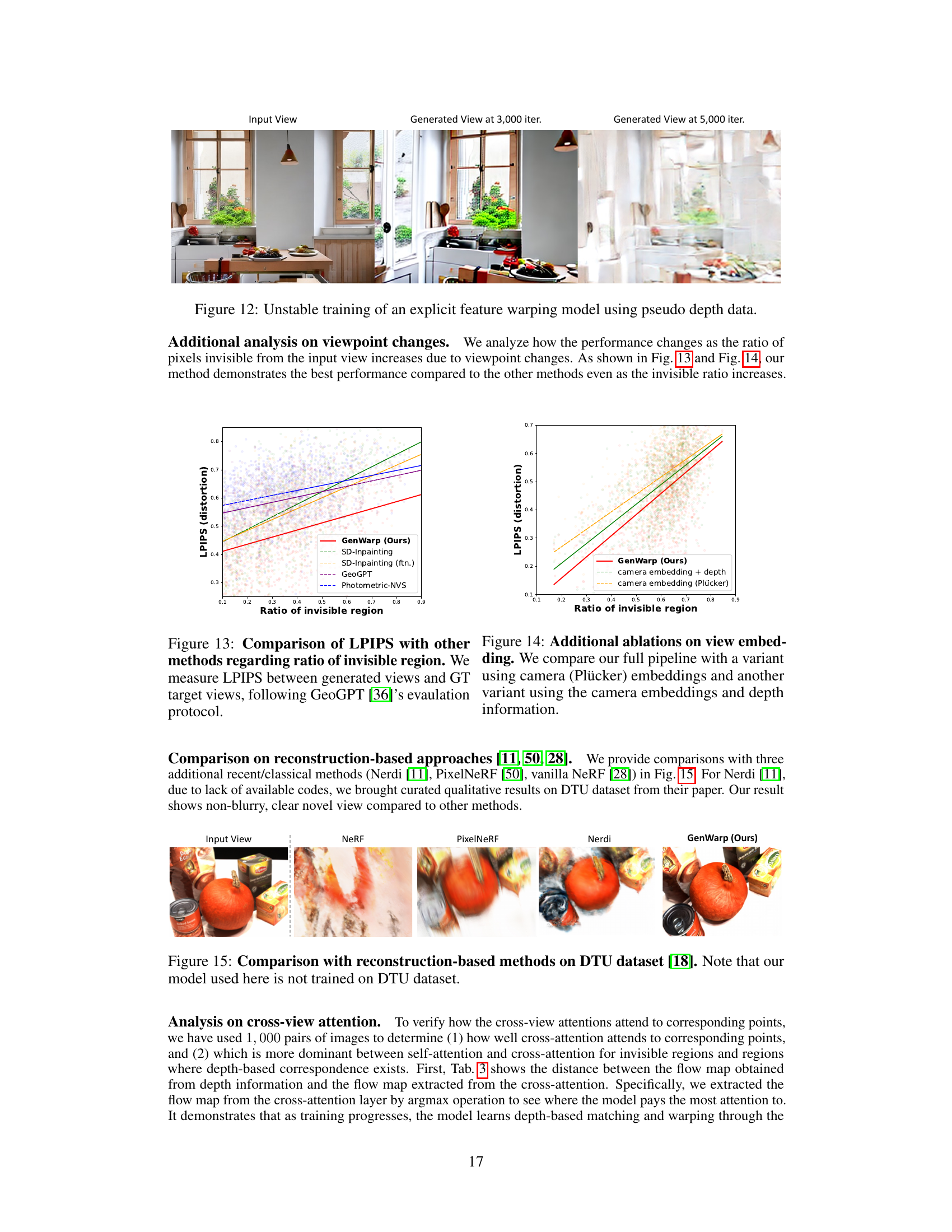
This figure shows the relationship between the difficulty of camera viewpoint changes and the degree of distortion in the generated novel views. The x-axis represents the difficulty of the viewpoint change (measured using LPIPS between the ground truth source and target views). The y-axis represents the distortion of the generated view (measured using LPIPS between the generated and ground truth target views). The graph shows that GenWarp outperforms other methods across various levels of viewpoint change difficulty. In other words, GenWarp produces consistently lower distortion even as viewpoint change difficulty increases.
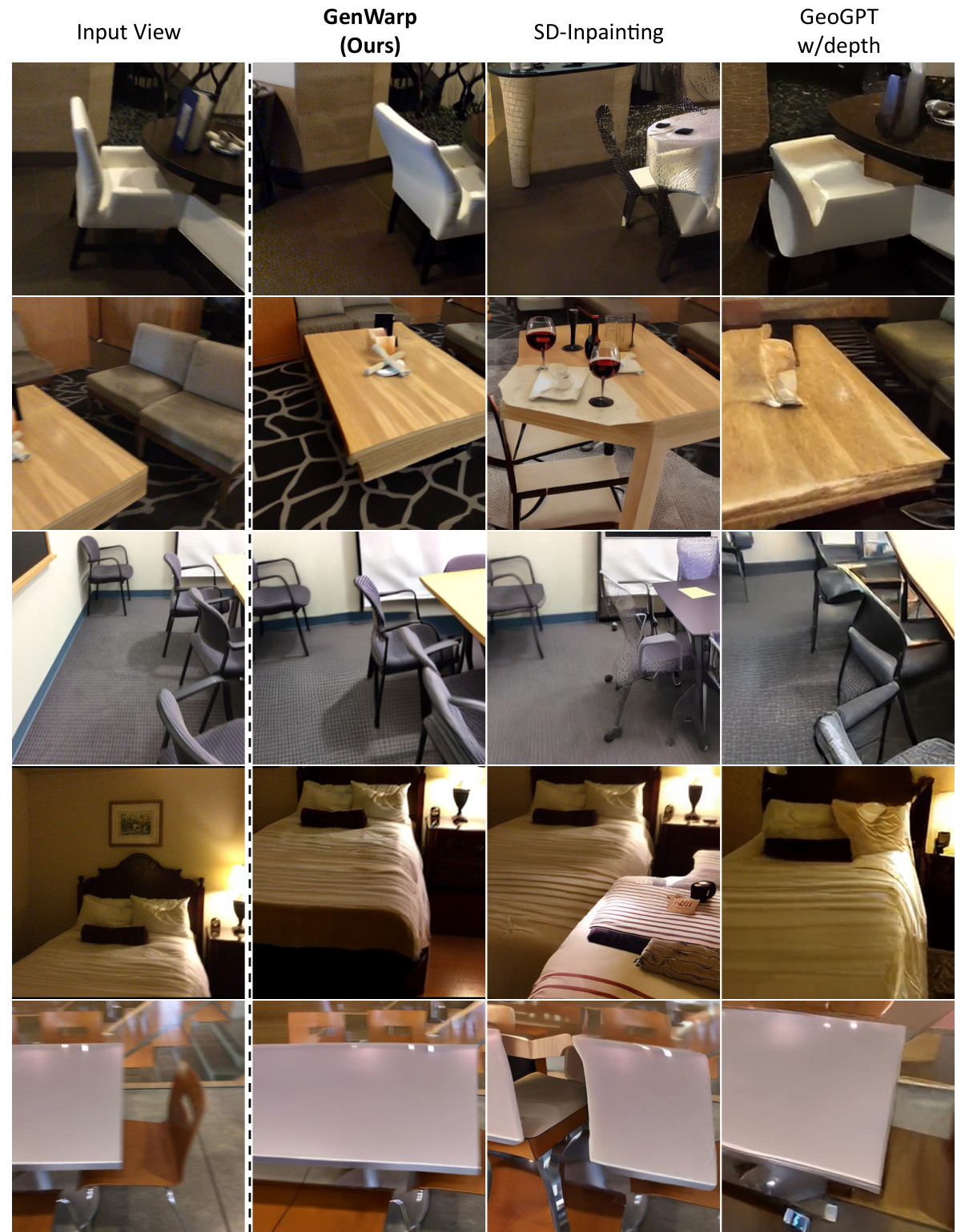
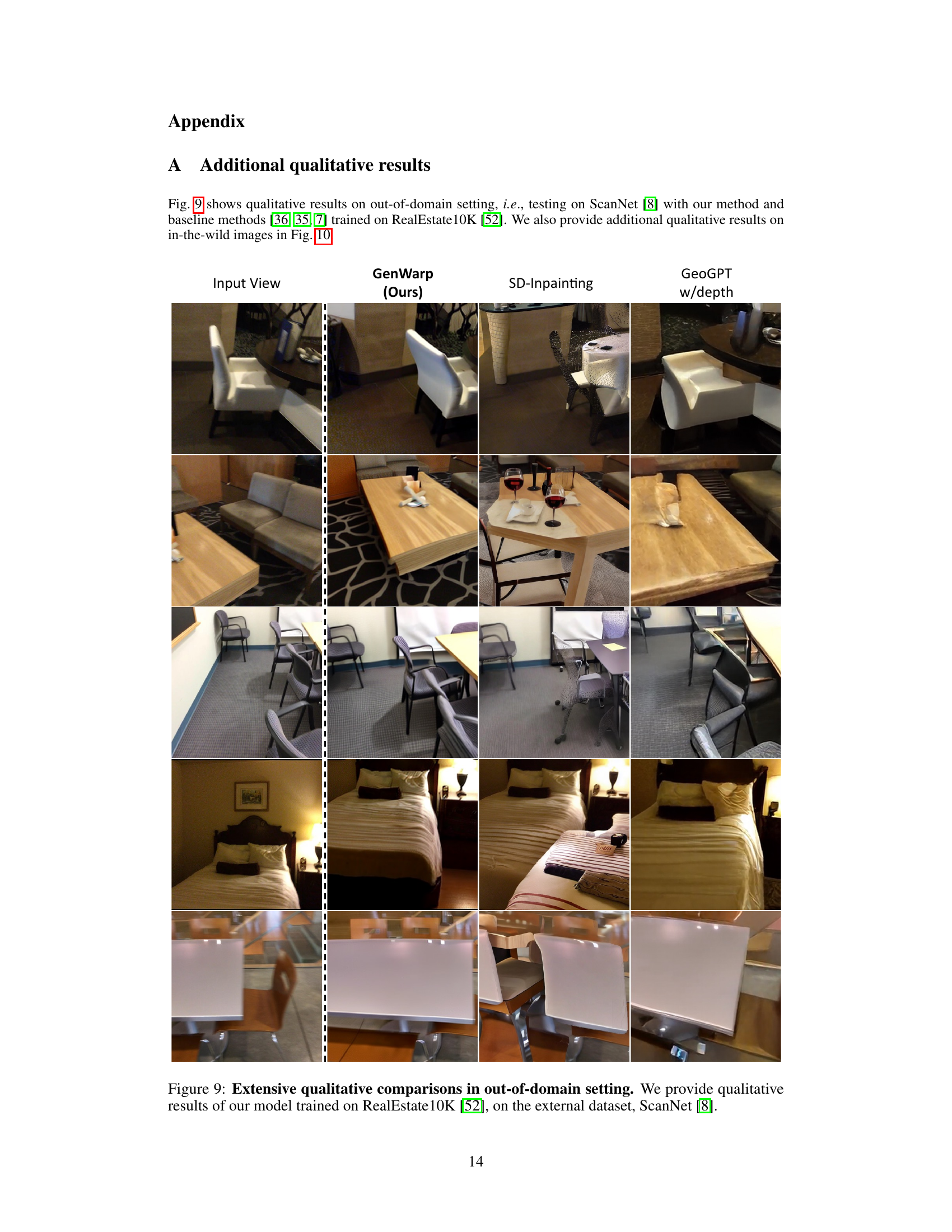
This figure shows a qualitative comparison of novel view generation results on the ScanNet dataset using GenWarp, SD-Inpainting, and GeoGPT. The comparison is done in an out-of-domain setting, where the models were trained on the RealEstate10K dataset, which is different from the test dataset. The figure highlights the visual quality and consistency of novel views generated by each method, showcasing GenWarp’s superior performance in generating plausible and semantically consistent novel views, especially in complex scenes.

This figure shows qualitative comparisons of novel view synthesis results using GenWarp and baseline methods (Stable Diffusion Inpainting) on various real-world images. Each row represents a different scene, with the input view, warped image, inpainted image using Stable Diffusion, and the result of GenWarp shown side-by-side. The figure demonstrates the ability of GenWarp to generate more realistic and semantically consistent novel views compared to the baseline method.

This figure shows a comparison of forward and inverse warping methods used in the warping-and-inpainting approach with Stable Diffusion inpainting. The figure demonstrates that inverse warping and applying occlusion masks based on depth map filtering are used in the warping-and-inpainting approach. It also shows how these methods create artifacts in the results.

This figure shows the results of training a model that warps features explicitly using pseudo depth maps. The instability of the training process is highlighted by comparing generated views at different iteration numbers (3,000 and 5,000). The instability is likely due to inaccuracies in the pseudo depth maps, demonstrating the challenges of relying on explicit warping without a more robust approach like the GenWarp method proposed in the paper.
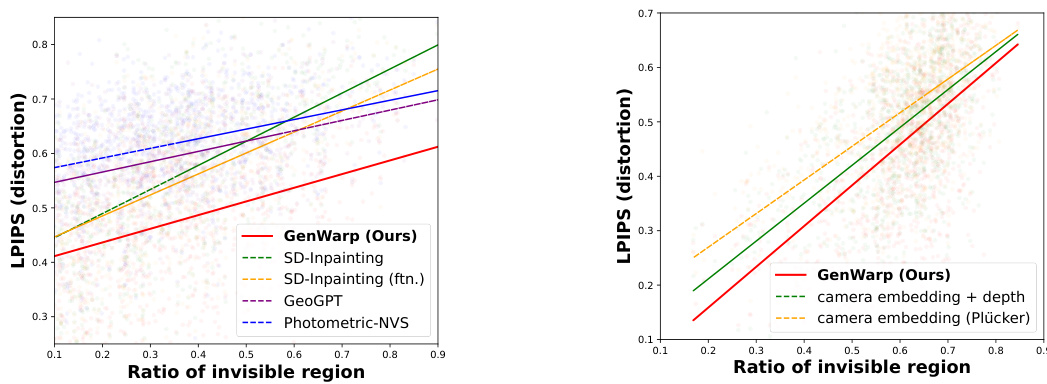
This figure shows a comparison of the Learned Perceptual Image Patch Similarity (LPIPS) scores for different novel view synthesis methods as the ratio of invisible regions increases. The LPIPS score measures the perceptual difference between the generated novel view and the ground truth view. The x-axis represents the ratio of invisible pixels in the novel view, which increases as the viewpoint of the camera changes drastically. The y-axis represents the LPIPS score, indicating how different the generated view is from the ground truth. The lower the score, the better the generation. The figure helps to assess the performance and robustness of various methods under challenging scenarios with significant occlusion.

This figure compares the novel view synthesis results of GenWarp against three other reconstruction-based methods (NeRF, PixelNeRF, and Nerdi) on the DTU dataset. The input view shows a scene with a pumpkin and other objects. GenWarp produces a result that is visually similar to the input image and preserves details and object appearances well. The other methods have significantly more artifacts and distortions. Notably, GenWarp was not trained on the DTU dataset, showcasing its generalization capabilities.

This figure showcases qualitative comparisons between the proposed GenWarp method and baseline methods (Stable Diffusion Inpainting) on real-world images. It visually demonstrates the ability of GenWarp to generate high-quality novel views from a single input image, even in challenging scenarios involving complex scenes and diverse image styles.
More on tables

This table presents the results of an ablation study on the effectiveness of different types of embeddings used to guide the geometric warping process within the GenWarp model. The study compares the use of warped coordinates, warped depth maps, warped images, and camera embeddings (using Plücker coordinates). The FID (Fréchet Inception Distance) score is used to evaluate the quality of the generated novel views, with lower scores indicating better quality. The results demonstrate that using warped coordinates as the embedding condition yields the best performance in terms of FID, indicating superior generation quality compared to other embedding strategies.

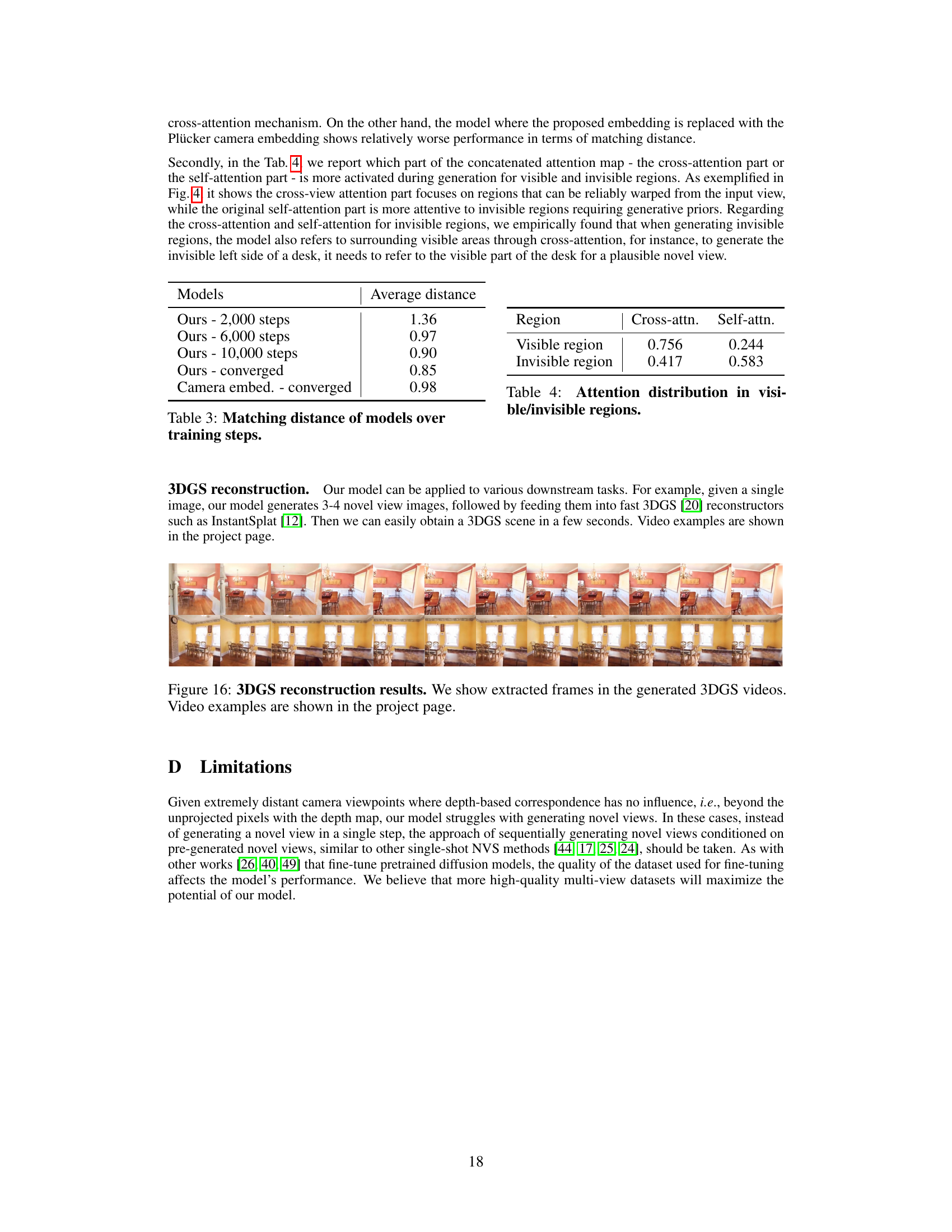
This table presents the average distance between the flow map obtained from depth information and the flow map extracted from the cross-attention layer at different training steps (2000, 6000, 10000) and after the model converged. It also includes a comparison with a model where the warped coordinate embedding is replaced with the Plücker camera embedding.

This table shows the distribution of attention weights between cross-attention and self-attention mechanisms for visible and invisible regions in the generated novel view. It highlights how the model leverages cross-attention more heavily for visible regions (where warping is more reliable) and self-attention for invisible regions (requiring more generative capacity).
Full paper#