↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multi-scene absolute pose regression methods struggle with underutilized transformer encoders due to the collapsed self-attention map, leading to low representation capacity. This is caused by distorted query-key embedding spaces where queries and keys are mapped into completely different spaces. This paper analyzes this issue and highlights the significant performance limitations resulting from this problem.
To address this issue, the authors propose an auxiliary loss to align query and key spaces, promoting interaction between them. They also replace the undertrained learnable positional encoding with a fixed sinusoidal positional encoding. These methods effectively resolve the self-attention collapse problem, significantly improving both accuracy and efficiency of camera pose estimation on various datasets, outperforming current state-of-the-art models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on camera pose estimation and transformer-based models. It addresses a critical limitation in existing methods, potentially improving accuracy and efficiency across various applications like augmented reality and autonomous driving. The findings also open avenues for further research into self-attention mechanisms and their optimization within transformer architectures. By providing effective solutions to activate self-attention, this research contributes to the advancement of efficient and accurate multi-scene absolute pose regression.
Visual Insights#
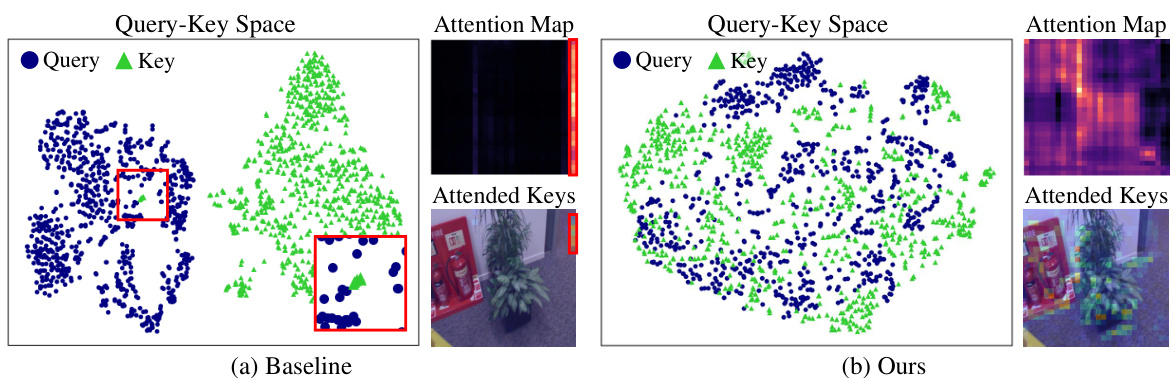
This figure visualizes the impact of the proposed method on query-key space and attention maps. The left panel (a) shows the baseline model, where query and key regions are distinctly separated, leading to a collapsed attention map. This is indicated by the visualization of the attended keys, which only represent a small region of the image. Conversely, the right panel (b) illustrates the improved model with the proposed method, where query and key regions are better aligned, creating a richer attention map that incorporates more global relationships, as evidenced by the attended keys covering a broader area of the image. The figure highlights the effectiveness of the proposed method in activating self-attention.

This table shows the results of an ablation study on the encoder self-attention modules of the MSTransformer model. The study compares the model’s performance with and without the encoder self-attention modules. The average median position and orientation errors are reported for both outdoor and indoor datasets. The results indicate that removing the encoder self-attention modules does not significantly improve or even degrades the performance.
In-depth insights#
Self-Attention Issues#
Self-attention mechanisms, while powerful, suffer from critical issues, especially in complex tasks like multi-scene absolute pose regression. One key problem is the distortion of the query-key embedding space. This leads to a collapse of the self-attention map, where queries become insensitive to most keys, effectively limiting the model’s capacity to learn meaningful relationships between image features. This collapse is exacerbated by undertrained positional embeddings, hindering the model’s ability to leverage positional information within images. Another significant problem is the tendency of the model to avoid exploring self-relationships, especially early in training. Consequently, the model fails to leverage the full potential of self-attention, leading to suboptimal performance. Addressing these issues requires novel approaches to activate self-attention, such as auxiliary losses that align query and key spaces and utilizing robust fixed positional encodings instead of the unreliable learnable ones.
Query-Key Alignment#
The concept of ‘Query-Key Alignment’ in the context of self-attention mechanisms within transformer models addresses a critical limitation: the distortion of embedding spaces. When queries and keys are mapped to significantly different regions, the self-attention mechanism fails to capture meaningful relationships, as only a few keys effectively interact with many queries. This ‘query-key space distortion’ leads to a collapsed self-attention map, hindering the model’s representational capacity. Query-Key Alignment aims to correct this by introducing methods such as auxiliary loss functions. These losses penalize the separation between query and key spaces, forcing the model to learn mappings that encourage a denser and more uniform distribution of queries and keys in the embedding space, thereby activating self-attention and promoting the identification of useful global relations within the data.
Positional Encoding#
Positional encoding is crucial for transformer-based models, particularly in tasks like absolute pose regression where the order of input features matters. Standard learnable positional embeddings, however, suffer from undertraining, hindering the model’s ability to capture spatial relationships. This paper highlights this problem, showing how undertrained positional embeddings lead to a distortion of the query-key embedding space in the self-attention mechanism. This distortion causes the self-attention map to collapse, reducing the model’s capacity to learn global contextual information. As a solution, the authors advocate for employing fixed sinusoidal positional encodings. This approach ensures that positional information is appropriately integrated into the input features from the start of training, promoting better interaction between queries and keys in the self-attention mechanism and preventing the problematic collapse. The effectiveness of this solution is demonstrated through the improved performance and analysis of self-attention maps. The choice of fixed positional encoding suggests a trade-off: while learnable embeddings might offer more flexibility, their tendency to undertrain in this specific context limits their efficacy. The use of fixed sinusoidal encoding provides a stable and effective alternative, showcasing the importance of careful consideration when choosing positional encoding strategies for transformer architectures.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In a pose regression model, this might involve disabling specific modules (e.g., self-attention layers, positional encodings) or removing data augmentation techniques. The goal is to isolate the impact of each component, providing strong evidence that observed improvements are directly attributable to the specific feature being tested rather than arising from other changes or interactions. By showing that removing the component significantly degrades performance, the researchers can make a compelling case for its importance. Conversely, if removing a part has minimal effect, it suggests that the component may be redundant or less crucial. These experiments are crucial for understanding the model’s architecture and building a robust and efficient system because they reveal which components are essential and which might be simplified or removed. A well-designed ablation study enhances confidence in the results and provides valuable insights into model behavior.
Future Directions#
Future research directions stemming from this work could involve exploring alternative self-attention mechanisms that are more robust to the challenges of high-dimensional data and complex scenes. Investigating the impact of different positional encoding schemes on the performance of the model, especially in dynamic environments, warrants attention. Adapting the proposed method to handle various image modalities beyond RGB images (e.g., depth maps, LiDAR data) could lead to more versatile and accurate pose estimation. Furthermore, refining the loss functions used for query-key space alignment and scene classification remains a promising avenue of investigation. Finally, a thorough analysis of the computational efficiency of the proposed approach relative to existing state-of-the-art methods is needed to understand its practical deployment and scalability.
More visual insights#
More on figures

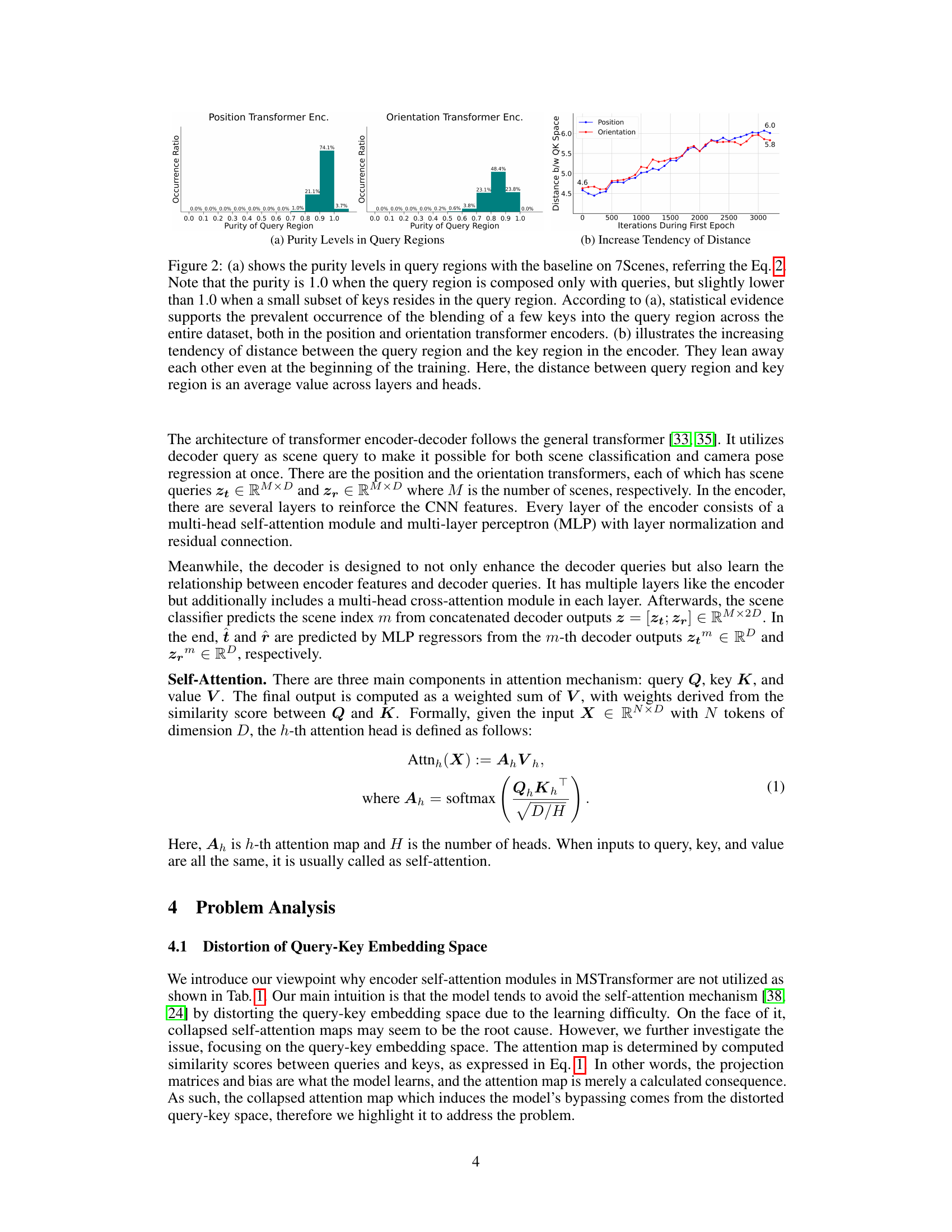
This figure shows the results of a statistical analysis of the query-key space in the transformer encoder of the baseline model. (a) shows the purity levels of the query regions which indicates how many keys are mixed with the queries. The higher the purity is, the more the region is composed of queries. (b) shows the tendency of the distance between query and key regions during the first epoch of training, showing that they are distanced in the embedding space even before training.
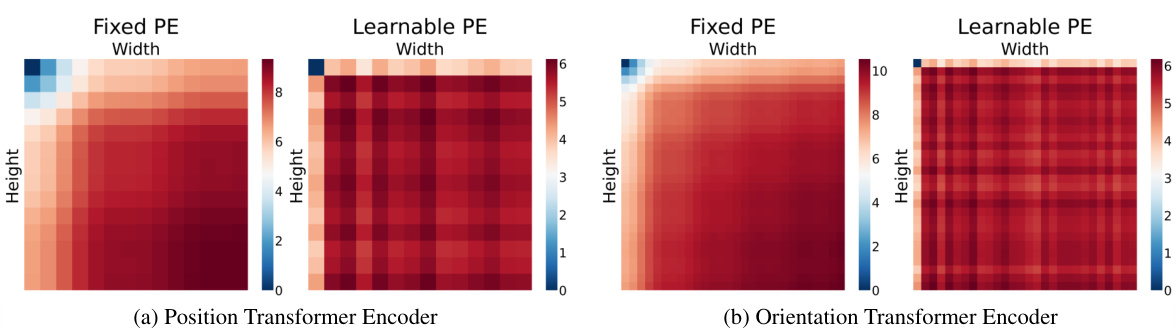
This figure visualizes the distances between tokens using fixed and learnable positional embeddings in a transformer encoder for both position and orientation. The fixed embedding maintains positional order, while the learned embedding exhibits randomness, hindering the model’s ability to learn geometric relationships.

This figure illustrates the training pipeline of the proposed method. It shows how the additional objectives LQKA and LQKA are applied to activate the self-attention modules by aligning query and key regions. Fixed 2D sinusoidal positional encoding is also used to ensure interaction between queries and keys.

The figure shows a comparison of attention entropy for each layer of the position and orientation transformer encoders between the baseline model and the model with the proposed solutions. The attention entropy is a metric reflecting the capacity of the self-attention mechanism. Higher entropy indicates better utilization of the self-attention mechanism, and thus better learning capacity. As shown in the plot, our model shows significantly higher attention entropy across all encoder layers, indicating that our approach effectively improves the capacity of the encoder self-attention and enhances the learning capability of the model.
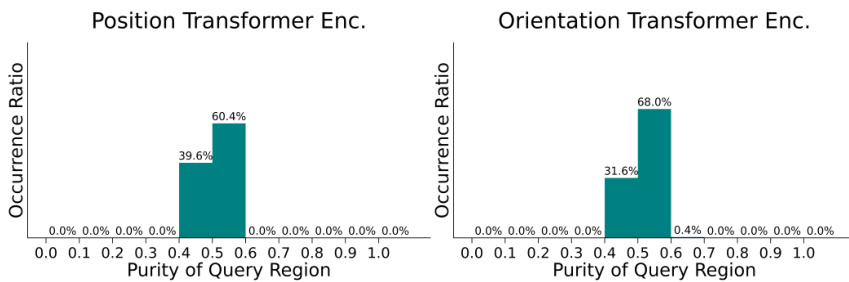
This figure shows histograms of the purity of the query regions for both position and orientation transformer encoders in the 7Scenes dataset. Purity measures the proportion of queries in the query region. A purity of 1.0 indicates only queries are present; lower purity indicates keys are also present. The histograms for the model with the proposed solution show a significant shift towards higher purity, indicating that the query and key regions are more effectively interleaved, preventing the collapse of self-attention.

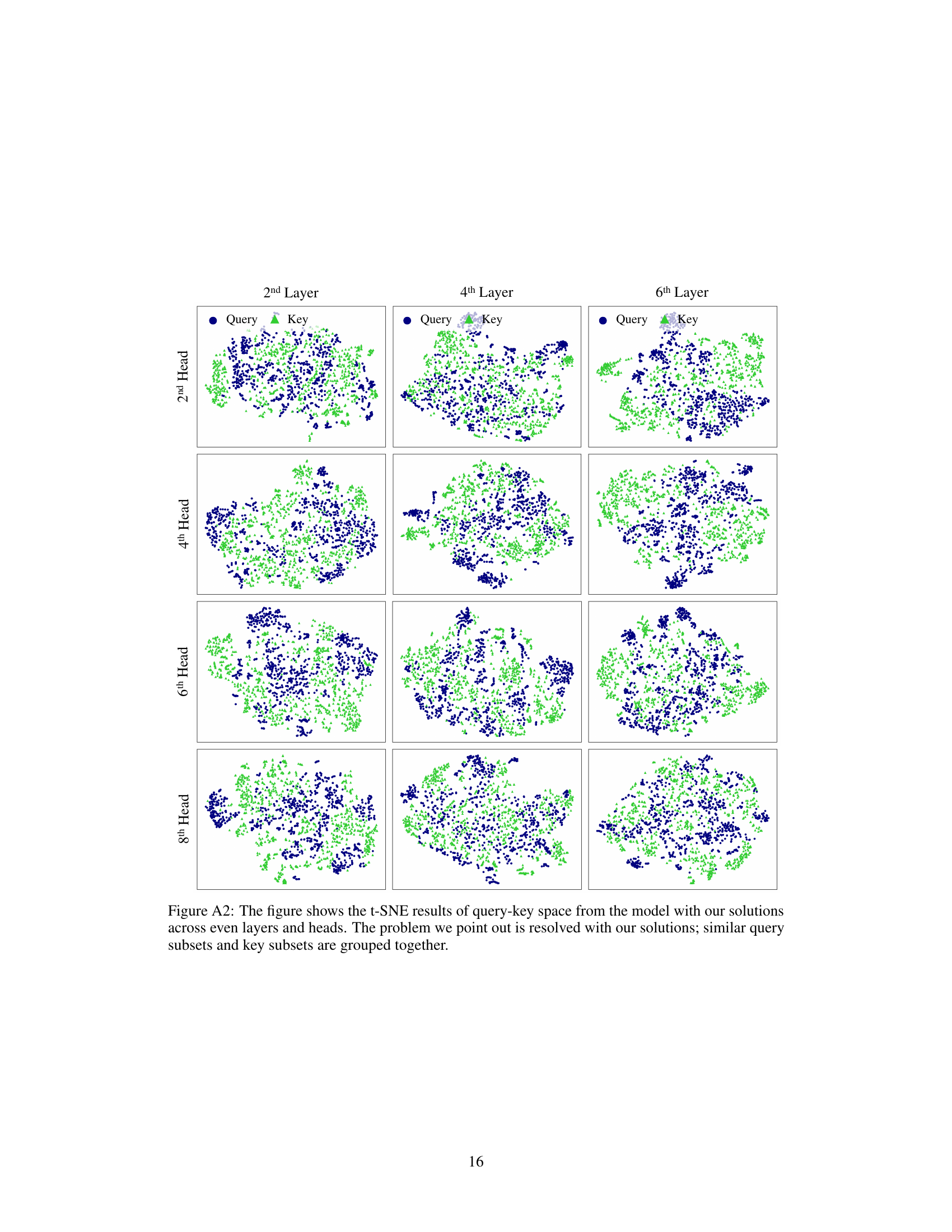
This figure visualizes the impact of the proposed method on the query-key space and attention mechanism using t-SNE. The top row shows the baseline model, where query and key regions are clearly separated. The bottom row shows the model with the proposed solution, demonstrating a significant overlap between query and key regions. This increased interaction between queries and keys allows the model to focus on salient global features and effectively incorporate self-relations into image features, improving performance.

This figure shows the visualization of the query-key space using t-SNE. It compares the baseline model’s query-key space with the model incorporating the proposed solutions. The baseline model shows distinct separation between query and key regions, whereas the improved model shows that the query and key regions are highly intertwined. This indicates that the proposed solutions successfully address the issue of distorted query-key space, leading to the activation of self-attention mechanism.

This figure shows the visualization of the query-key space using t-SNE for the model with the proposed solutions. It demonstrates that the problem of separated query and key regions is resolved, and similar subsets of queries and keys are clustered together. This visualization supports the claim that the proposed method effectively activates self-attention by improving the interaction between queries and keys in the embedding space.
More on tables

This table compares the performance of different Multi-Scene Absolute Pose Regression (MS-APR) methods on the Cambridge Landmarks dataset, which is an outdoor localization benchmark. The metrics used are median position error (in meters) and median orientation error (in degrees). The table shows that the proposed method (+Ours) outperforms existing methods (MSPN and MST) across all four scenes within the dataset.

This table presents a comparison of different Multi-Scene Absolute Pose Regression (MS-APR) methods on the 7Scenes indoor dataset. The median position and orientation errors (in meters and degrees, respectively) are reported for each method across seven different indoor scenes (Chess, Fire, Heads, Office, Pumpkin, Kitchen, Stairs). The table allows for a quantitative comparison of the accuracy of each method in estimating camera pose in diverse indoor environments.

This table compares the performance of the proposed method against the baseline method on two datasets: Cambridge Landmarks and 7Scenes. The localization recall is reported for different threshold combinations of position error (in meters) and orientation error (in degrees). Higher values indicate better performance. The results showcase the improved performance of the proposed method on both datasets across different thresholds.
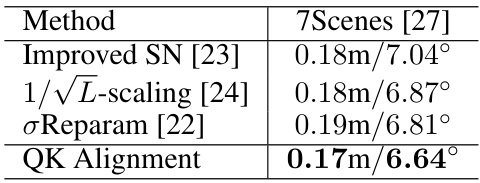
This table compares the performance of the proposed QK Alignment method with other methods designed to address the issue of collapsed self-attention in transformer models. It shows the average median position and orientation errors on the 7Scenes dataset. The comparison includes methods addressing collapsed self-attention (Improved SN, 1/√L-scaling, σReparam) and methods using different positional encodings (T5 PE, Rotary PE, Fixed PE). The results demonstrate the superior performance of QK Alignment.
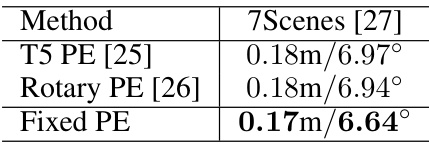
This table compares the performance of the proposed method against other methods for addressing the issue of collapsed self-attention and the choice of positional encoding. It shows the average median position and orientation errors on the 7Scenes dataset for three alternative methods focusing on addressing collapsed self-attention and three alternative methods for positional encoding. This allows for a comparison of the effectiveness of the proposed method against existing techniques in addressing these two key aspects of the model.
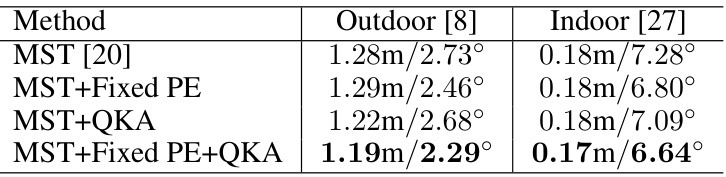
This table presents the results of an ablation study conducted to evaluate the effectiveness of the proposed solutions. By comparing the performance of different model configurations, it demonstrates the impact of each component on camera pose estimation accuracy. Specifically, it shows how adding fixed positional encoding and the query-key alignment (QKA) loss affects the performance, both individually and in combination. The results highlight the importance of incorporating both features for improved performance.
Full paper#