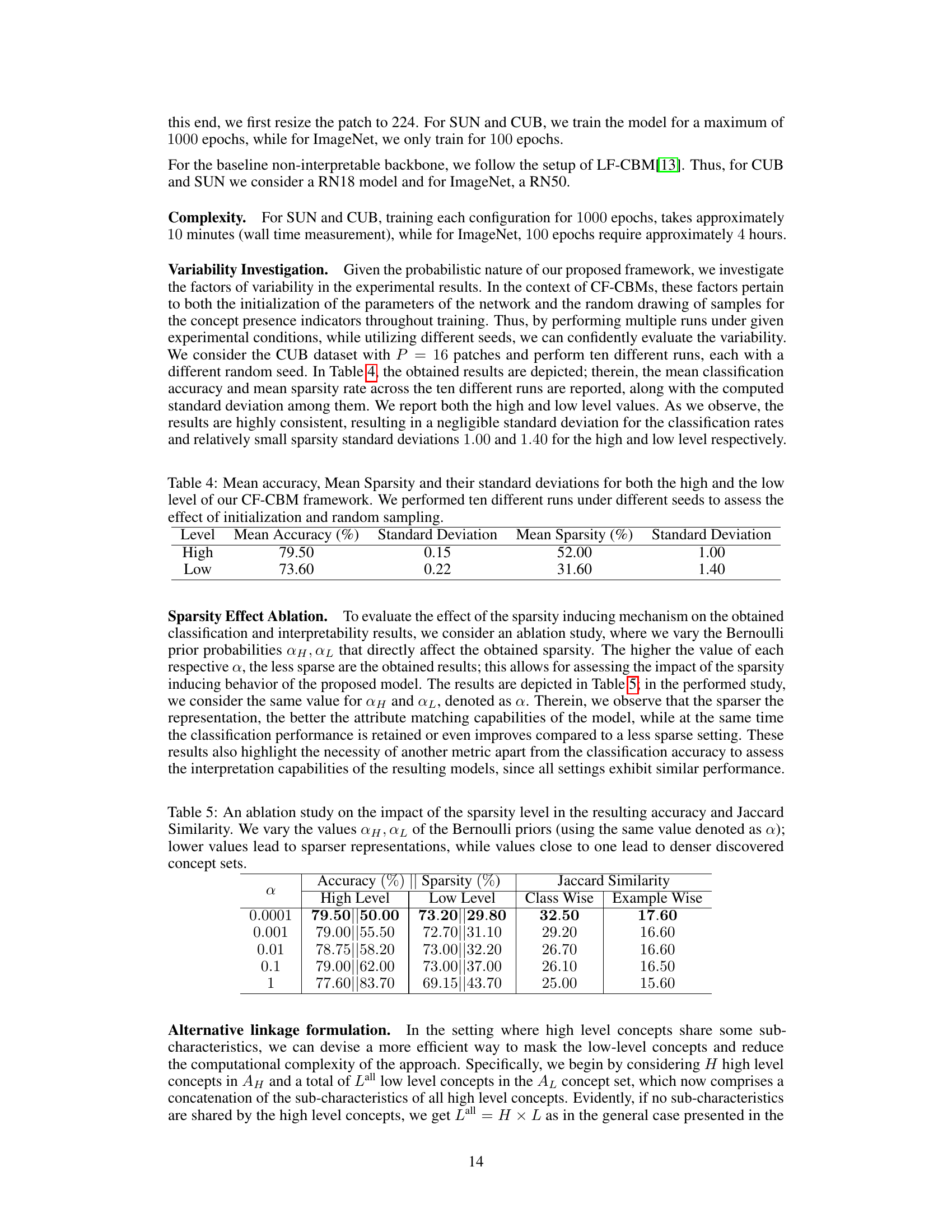
↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep learning models often lack interpretability, hindering their use in safety-critical applications. Concept Bottleneck Models (CBMs) aim to improve interpretability by relating predictions to human-understandable concepts. However, existing CBMs have limitations such as reliance on pre-defined concepts and insufficient granularity. This research tackles these issues.
This paper proposes Coarse-to-Fine Concept Bottleneck Models (CF-CBMs), a novel hierarchical framework that addresses the limitations of traditional CBMs. CF-CBMs leverage vision-language models for concept discovery, employing a data-driven Bayesian approach for concept selection at both a coarse level (whole image) and fine level (image patches). Experimental results show CF-CBMs significantly outperform existing approaches in classification accuracy and demonstrate improved interpretability through a new evaluation metric (Jaccard Index).
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in deep learning interpretability and computer vision. It offers a novel approach to enhance the explainability of deep models by introducing a hierarchical concept discovery method, leading to improved accuracy and better human understanding of model predictions. This work directly addresses the growing demand for trustworthy and reliable AI systems, opening new avenues for research in interpretable AI and its applications to various safety-critical domains. The innovative coarse-to-fine concept discovery mechanism is a significant contribution and potentially impactful across multiple AI fields.
Visual Insights#
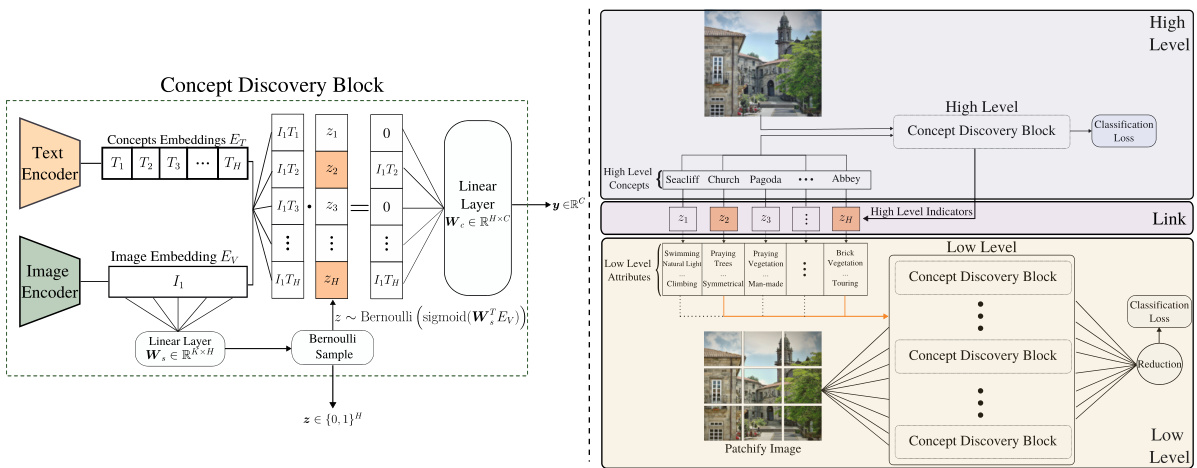
This figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel details the Concept Discovery Block (CDB), a module that uses a Vision-Language Model (VLM) to compute the similarity between image features and concept embeddings. A data-driven mechanism, based on a Bernoulli distribution, selects a sparse subset of concepts for each input image. The right panel presents the overall CF-CBM architecture, which uses two levels: a high-level that processes the entire image and a low-level that processes individual image patches. Each level incorporates a CDB. A hierarchical link between levels allows information sharing and allows the model to capture both coarse-grained and fine-grained information from the image.
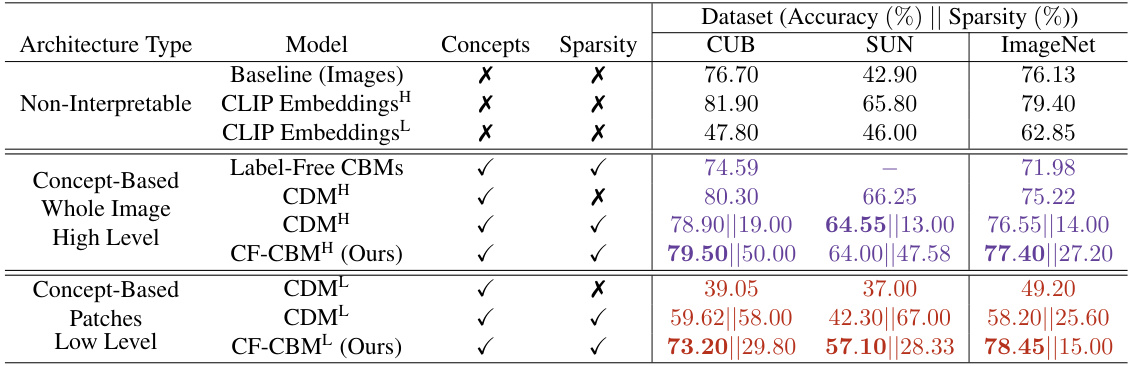
This table presents a comparison of different models’ performance on three benchmark datasets (CUB, SUN, and ImageNet). The models are categorized into several groups: Baseline (using raw image embeddings), non-interpretable models using CLIP embeddings, concept-based models (both whole-image and patch-based), and the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). For each model, the table shows classification accuracy and the average percentage of activated concepts (a measure of sparsity). The best-performing models in each category for both high and low-level sparsity are highlighted in bold.
In-depth insights#
Concept Bottleneck#
Concept Bottleneck Models (CBMs) aim to enhance the interpretability of deep learning models by introducing an intermediate layer that represents human-understandable concepts. CBMs improve interpretability by explicitly linking model predictions to these concepts, making the decision-making process more transparent. However, traditional CBMs face challenges like requiring hand-annotated concepts, exhibiting lower performance than black-box models, and struggling with tasks needing fine-grained analysis. Recent work integrates vision-language models to alleviate the hand-annotation burden and improve performance. Despite advancements, issues persist such as handling a large number of concepts, dealing with concept redundancy, and achieving sufficient granularity. The proposed framework addresses these limitations by incorporating a hierarchical coarse-to-fine concept discovery approach, which leverages both global image features and localized patch-specific information. This allows for capturing both high-level and low-level concepts, leading to a richer and more nuanced representation that improves both accuracy and interpretability.
Coarse-to-Fine Model#
A coarse-to-fine model processes information at multiple levels of granularity. It starts with a broad overview (coarse level), identifying major features or concepts. Then, it progressively refines its analysis (fine level), focusing on specific details within the previously identified areas. This approach is beneficial when dealing with complex data where a holistic understanding necessitates a combination of high and low-level interpretations. Combining these levels can improve model accuracy and interpretability by allowing the model to understand context and local details effectively. A significant advantage is the ability to capture both global context and fine-grained features. This approach has advantages in various fields, particularly in computer vision tasks like image classification and object detection. However, challenges include the need for efficient mechanisms to integrate information from different levels and potential computational costs associated with processing data at multiple granularities. The overall effectiveness depends heavily on the data and how well the different levels of the model are designed to complement each other.
Bayesian Inference#
Bayesian inference offers a powerful framework for reasoning under uncertainty by combining prior knowledge with observed data to update beliefs. Prior distributions represent initial assumptions about parameters, while likelihood functions quantify the probability of observing data given specific parameter values. Posterior distributions, calculated using Bayes’ theorem, represent updated beliefs after considering the evidence. The choice of prior is crucial, as it can significantly influence posterior inferences. Conjugate priors simplify calculations, leading to closed-form solutions for posterior distributions. Markov Chain Monte Carlo (MCMC) methods provide efficient approximations for complex scenarios where analytical solutions are intractable. Model selection uses Bayesian approaches like Bayes factors to compare competing models based on their posterior probabilities. Bayesian inference finds wide applications in various fields, including machine learning, statistics, and data science, particularly when dealing with limited data or complex relationships.
Interpretability Metrics#
Assessing the interpretability of machine learning models is crucial, particularly in high-stakes applications. While qualitative assessments are valuable, quantitative metrics are needed for objective evaluation and comparison. The challenge lies in defining metrics that capture the nuances of human understanding and align with the specific goals of interpretability. One approach involves measuring the accuracy of explanations, comparing model-provided explanations against human-generated ones. Another centers on model fidelity, assessing how well explanations align with the model’s actual decision-making process. Measuring user understanding is vital; quantifying how easily users can comprehend model behavior based on interpretability techniques is essential. Finally, efficiency and scalability of interpretability methods are key considerations. A good metric should not only be accurate but also feasible to apply across different model architectures and datasets. The ideal interpretability metric would combine aspects of accuracy, fidelity, user understanding, and efficiency into a single comprehensive score, offering a robust framework for evaluating model explainability.
Future Directions#
Future research could explore several promising avenues. Extending the hierarchical model to incorporate more levels of granularity would allow for a more nuanced understanding of image concepts. Investigating alternative methods for concept discovery, potentially incorporating unsupervised or semi-supervised techniques, could reduce reliance on large annotated datasets. Exploring different architectures and model types beyond the current framework would be beneficial, enabling a comparison of effectiveness and efficiency across various approaches. Furthermore, a crucial area for future work involves developing robust evaluation metrics for assessing interpretability beyond simple classification accuracy; this would allow for a more comprehensive understanding of the model’s decision-making process. Finally, a thorough analysis of bias and fairness within the hierarchical model’s concept representation is critical to ensure equitable and responsible application in real-world scenarios. By addressing these aspects, the research can advance the field of interpretable AI and facilitate broader adoption of these powerful models.
More visual insights#
More on figures

This figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel illustrates a Concept Discovery Block (CDB), a module that uses a Vision-Language Model (VLM) to compute image-concept similarities and then uses a data-driven Bayesian approach to select a sparse set of relevant concepts. The right panel shows the overall CF-CBM architecture, which consists of a high-level module processing the whole image and a low-level module processing image patches. These modules are linked through binary indicators (ZH and ZL) representing concept activation at each level, allowing for a hierarchical and interpretable decision-making process.

This figure illustrates the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel shows a Concept Discovery Block (CDB), which computes concept similarities using a vision-language model and introduces a data-driven mechanism to select relevant concepts. The right panel presents a schematic of the CF-CBM architecture, which has two levels: high (whole image) and low (patches). The high-level uses the CDB to identify relevant high-level concepts, while the low-level uses similar CDBs on image patches. A hierarchical structure links these levels, allowing information sharing and enhancing interpretability.

This figure illustrates the architecture of the proposed Coarse-to-Fine Concept Bottleneck Models (CF-CBMs). The left panel shows a Concept Discovery Block (CDB), which takes an image and a set of concepts as input, computes their similarity using a vision-language model (VLM), and uses a data-driven mechanism to discover relevant concepts. The right panel shows the overall CF-CBM architecture, which consists of two levels: a high level that processes the whole image, and a low level that processes individual patches of the image. Each level has its own CDB, and the two levels are linked together via binary indicators that represent the relevance of each concept to the downstream task.
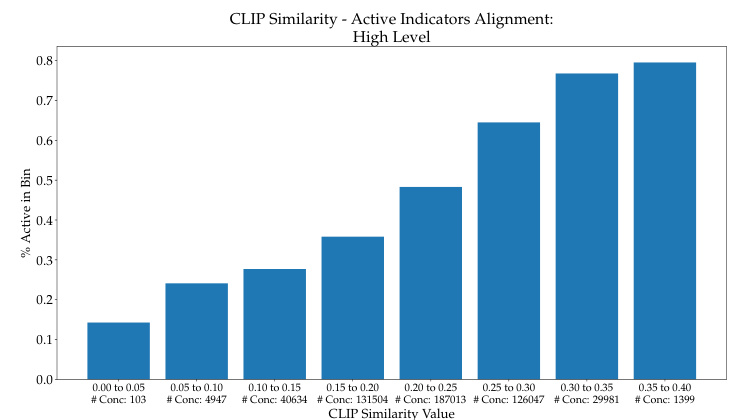
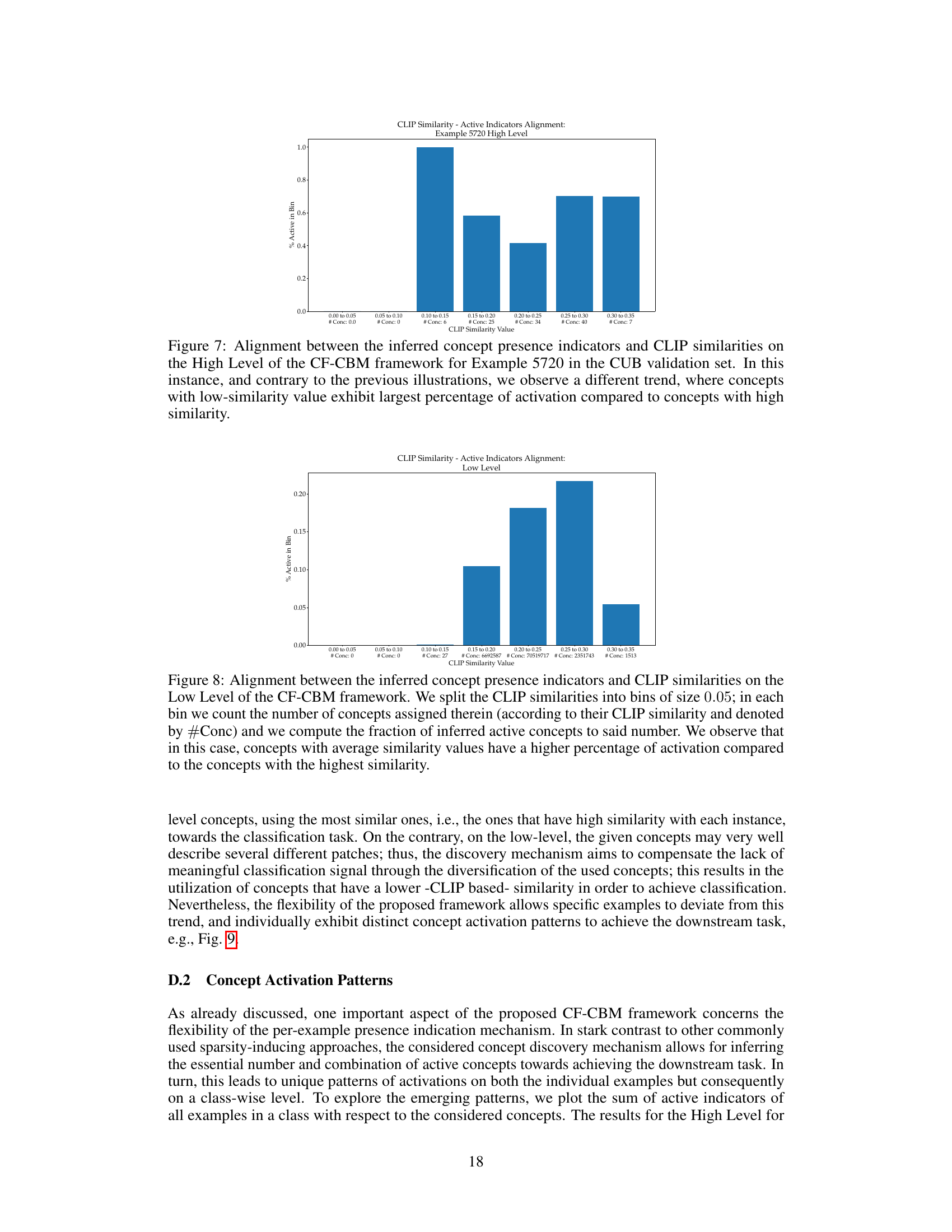
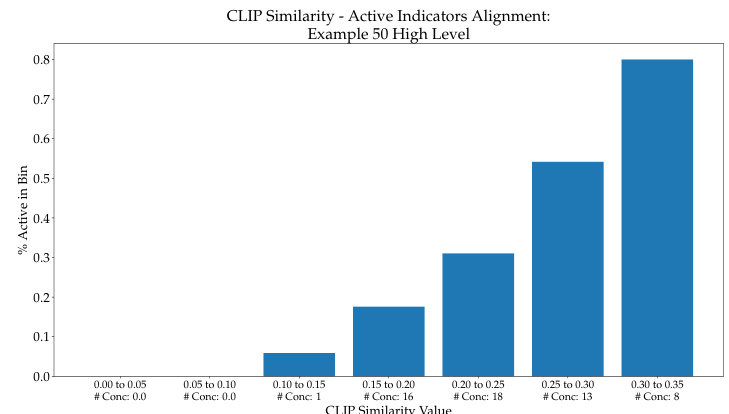
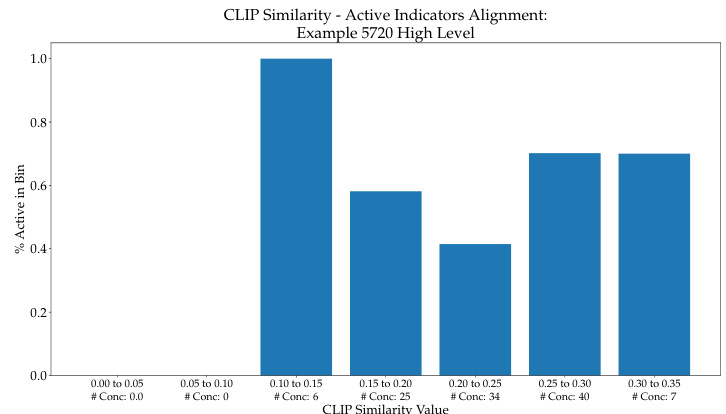
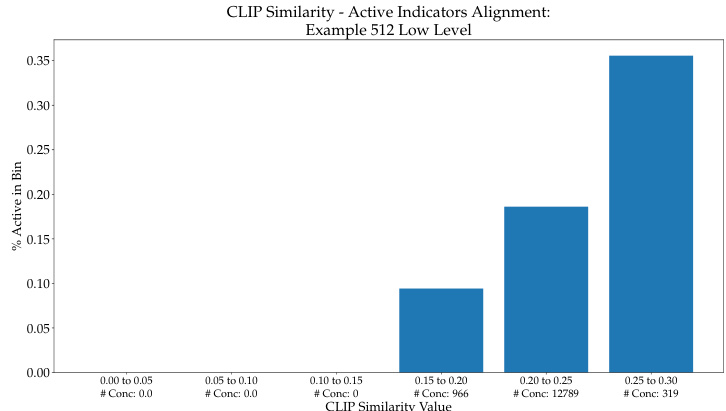
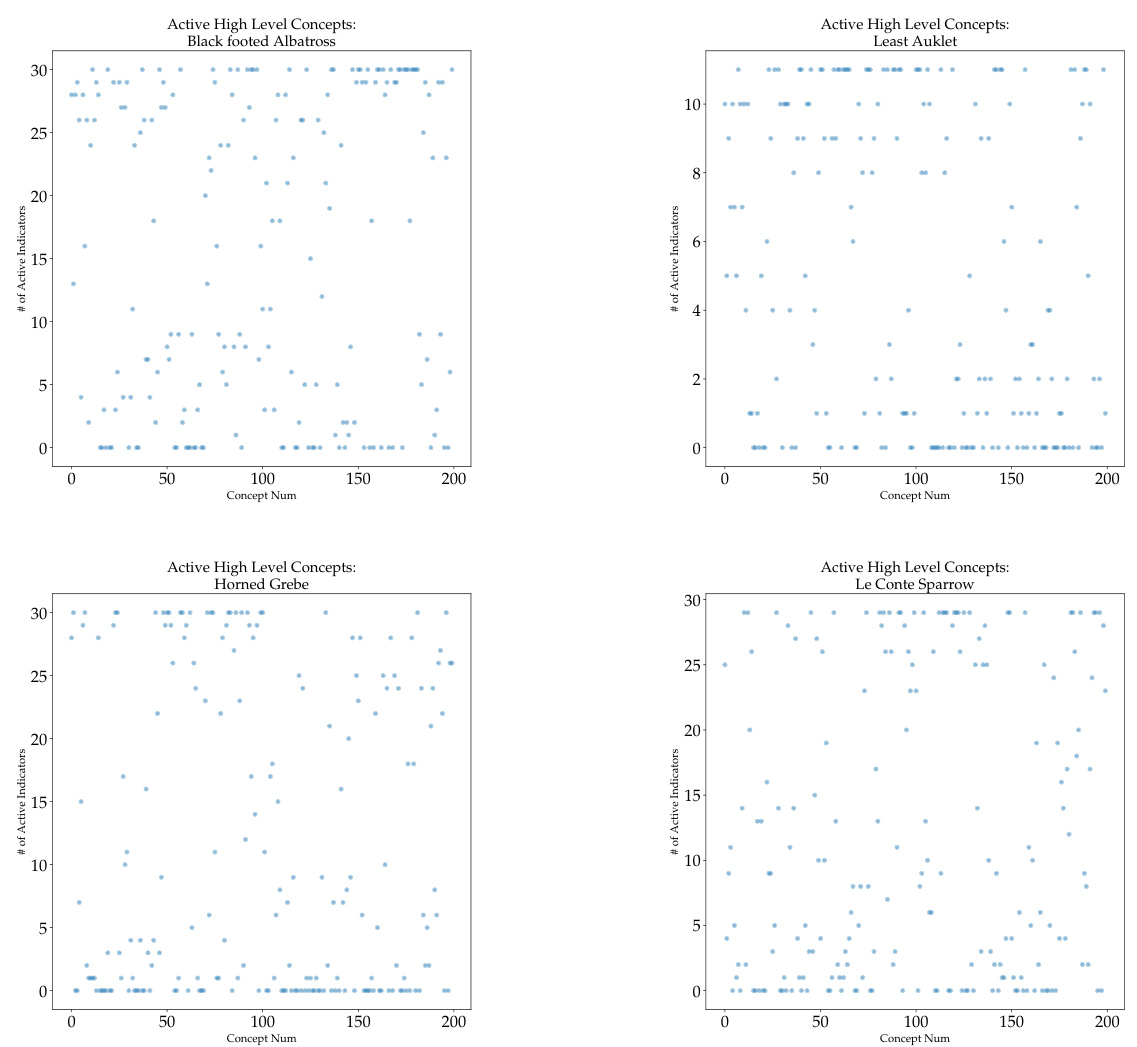
This figure shows the relationship between CLIP similarity scores and the activation of concepts in the high level of the CF-CBM model. The CLIP similarity scores are grouped into bins, and the percentage of activated concepts within each bin is plotted. The graph shows that a higher CLIP similarity generally leads to a higher percentage of concept activation. This suggests that the model tends to prioritize concepts with higher similarity scores.
This figure illustrates the Concept Discovery Block (CDB), which is a core component of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel shows how the CDB uses vision-language models (VLMs) to compute the similarity between an image and a set of concepts, and then employs a data-driven mechanism to discover the most relevant concepts via sampling from an amortized Bernoulli distribution. The right panel presents a schematic overview of the CF-CBM architecture. It shows how the model incorporates a two-level hierarchy (high-level and low-level) for concept discovery, using the image as a whole for high-level concepts and dividing the image into patches for discovering lower-level concepts. These two levels are linked together using binary indicator variables that represent which concepts are active for a given input.
This figure illustrates the Concept Discovery Block (CDB) and a schematic of the proposed Coarse-to-Fine Concept Bottleneck Models (CF-CBMs). The CDB shows how image and concept similarities are computed using a Vision-Language Model (VLM), and how a data-driven Bayesian approach is used for concept discovery. The CF-CBM schematic illustrates a two-level hierarchical model: the high level considers the whole image, while the low level considers individual patches. Both levels use CDBs and are linked by binary indicators to allow for information sharing.

The figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left side details a Concept Discovery Block (CDB), illustrating how image and concept embeddings are used with a Bernoulli distribution to select relevant concepts. The right side presents a schematic of the CF-CBM, highlighting the two-level (high and low) hierarchical structure, where the high level processes the whole image and the low level processes individual patches, with both levels interacting through binary indicator variables. The interaction facilitates information sharing between the levels to achieve more granular interpretations.
This figure illustrates the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel shows the Concept Discovery Block (CDB), a module that uses a vision-language model (VLM) to compute the similarity between concepts and an image and employs a data-driven mechanism to discover relevant concepts. The right panel presents a schematic overview of the CF-CBM architecture. It highlights a two-level hierarchical structure: a high level that processes the whole image and a low level that analyzes image patches. These levels are interconnected through binary indicators that control the flow of information and concept discovery between them, aiming for a more interpretable and fine-grained analysis.
This figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel illustrates the Concept Discovery Block (CDB), a module that uses a vision-language model (VLM) to compute the similarity between images and concepts, and then uses a data-driven mechanism to discover the subset of relevant concepts. The right panel shows the overall architecture of the CF-CBM, which consists of two levels: a high-level that processes the whole image and a low-level that processes individual image patches. The two levels are linked together via binary indicators, allowing for information sharing between them.
This figure illustrates the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left side shows a Concept Discovery Block (CDB), which uses a vision-language model (VLM) to compute the similarity between an image and a set of concepts. A data-driven mechanism using an amortized Bernoulli posterior samples the relevant concepts. The right side presents a schematic of the CF-CBM framework, consisting of two levels: high and low. The high level models the whole image, while the low level models patch-specific regions. The two levels are linked via binary indicators (ZH and ZL), allowing for information sharing and context between levels. The low level uses an aggregation operation to combine the information from all patches.

This figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Models (CF-CBMs). The left panel illustrates the Concept Discovery Block (CDB), which is a key component of the CF-CBM framework. The CDB uses a Vision-Language Model (VLM) to compute the similarity between an image and a set of concepts. It then uses a data-driven mechanism to discover the subset of concepts that are relevant to the image. The right panel shows the overall architecture of the CF-CBMs. The CF-CBMs use a two-level hierarchy of concepts: a high-level set of concepts that describe the overall scene, and a low-level set of concepts that describe specific regions of the image. The two levels are linked together using binary indicators, which allow for information sharing between the two levels. The CF-CBMs are trained end-to-end to classify images based on both high-level and low-level concepts.

This figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left panel illustrates the Concept Discovery Block (CDB), a module that uses vision-language models (VLMs) to compute image-concept similarities and employs a data-driven Bayesian approach to select a sparse subset of relevant concepts. The right panel provides a schematic overview of the CF-CBM, highlighting its two-level hierarchical structure (high-level for the whole image and low-level for image patches), the concept discovery mechanism at each level, and the information flow between the levels.

This figure shows the architecture of the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM). The left side illustrates the Concept Discovery Block (CDB), a module that uses vision-language models (VLMs) to compute the similarity between an image and a set of concepts, and then uses a data-driven mechanism to discover a subset of relevant concepts. The right side shows the overall architecture of the CF-CBM, which consists of two levels: a high level that considers the whole image and a low level that considers individual patches of the image. The two levels are linked together by a concept hierarchy, which allows information sharing between the two levels. This allows the model to capture both high-level and low-level concept information for improved interpretability and performance.
More on tables

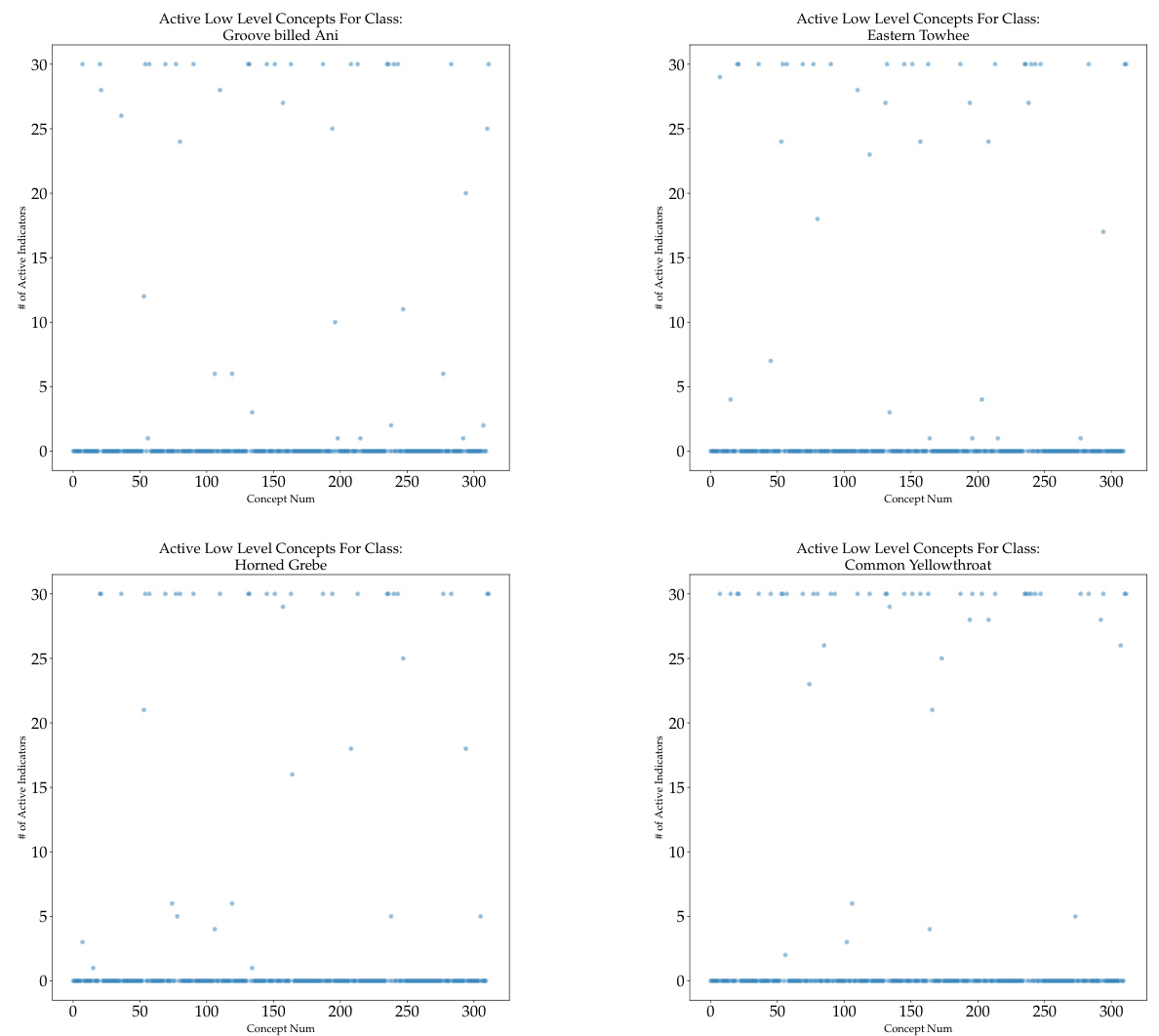
This table presents the results of attribute matching accuracy experiments. The authors compare their Coarse-to-Fine Concept Bottleneck Model (CF-CBM) against a recent Concept Bottleneck Model (CDM) using two attribute sets: class-wise and example-wise. The matching accuracy and Jaccard index are reported for both SUN and CUB datasets, providing a quantitative measure of the model’s ability to discover relevant concepts.

This table presents a comparison of the classification accuracy and sparsity (average percentage of activated concepts) achieved by different models on three benchmark datasets: CUB, SUN, and ImageNet. The models compared include a baseline using only image information, a non-interpretable CLIP embedding model, label-free CBMs, concept-discovery high level models (CDMH), concept discovery low level models (CDML), and the proposed Coarse-to-Fine CBMs (CF-CBMs) at both high and low levels. The table shows that the CF-CBM approach generally outperforms other methods in terms of accuracy, while also achieving high sparsity.

This table compares the classification accuracy and sparsity (average percentage of activated concepts) of different models on three benchmark datasets: CUB, SUN, and ImageNet. The models include a baseline using only image information, non-interpretable CLIP embeddings, Label-Free CBMs, and concept-based models with and without the proposed high and low-level concept discovery mechanisms. The table highlights the performance of the proposed Coarse-to-Fine CBM (CF-CBM) approach, showing its superior accuracy and sparsity compared to other methods.

This table compares the classification accuracy and sparsity (average percentage of activated concepts) of different models on three benchmark datasets: CUB, SUN, and ImageNet. It compares the proposed Coarse-to-Fine Concept Bottleneck Model (CF-CBM) against several baselines and state-of-the-art methods, including non-interpretable models, CLIP embeddings (both image and patch level), label-free CBMs, and concept-discovery models. The table shows both high-level and low-level results for the CF-CBM, demonstrating its performance across different levels of granularity and sparsity settings.
Full paper#