↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Fine-tuning large language models (LLMs) is computationally expensive. Existing methods, while effective, often involve substantial memory overhead for gradient computations. This research paper explores a weak-to-strong specialization approach, aiming to directly transfer knowledge from a series of task-specific small models to a much larger model without additional training. This approach addresses the limitations of prior methods, which often employ static knowledge transfer ratios and a single small model, leading to suboptimal performance.
The paper proposes a dynamic logit fusion method that employs a series of task-specific small models. It adaptively allocates weights among these models at each decoding step, learning these weights using Kullback-Leibler divergence. The method demonstrates leading results across various benchmarks in both single-task and multi-task settings. By transferring knowledge from a 7B model to a 13B model, the performance gap is significantly reduced, even outperforming full fine-tuning on unseen tasks. This approach integrates in-context learning and task arithmetic, further enhancing its versatility and effectiveness. The dynamic weight allocation and use of multiple expert models are key innovations that enhance performance and generalization.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient approach for fine-tuning large language models. It addresses the computational challenges of traditional methods by leveraging smaller, task-specific models and transferring their knowledge, resulting in significant performance gains and reduced training costs. This opens up new possibilities for researchers working with LLMs, especially those with limited computational resources.
Visual Insights#

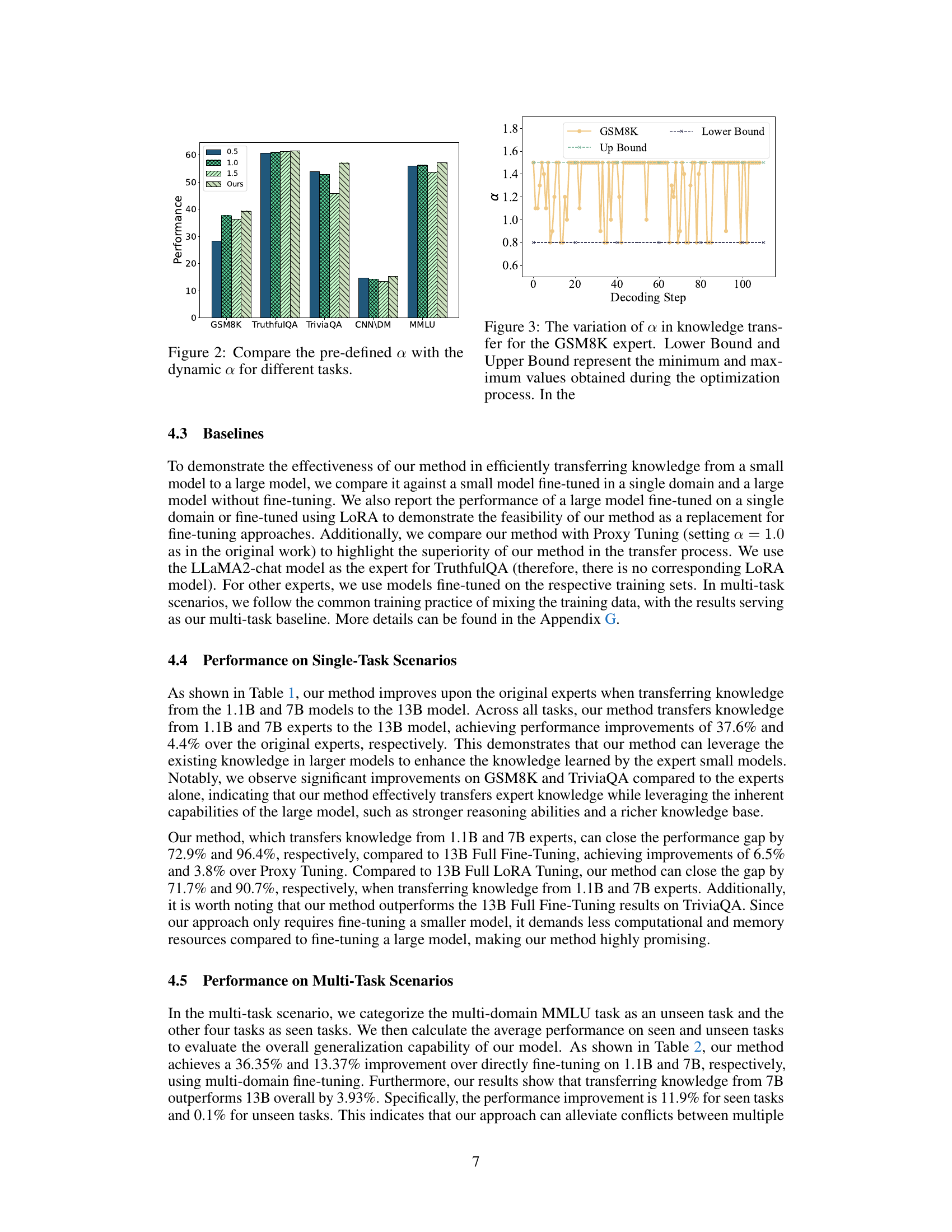
This figure compares the authors’ proposed method with previous methods for knowledge transfer in large language models. Previous methods used a static weight (α) to transfer knowledge from a single small model to a larger model. The authors’ method dynamically adjusts the weights from multiple small models at each decoding step, resulting in more adaptable and accurate knowledge transfer.
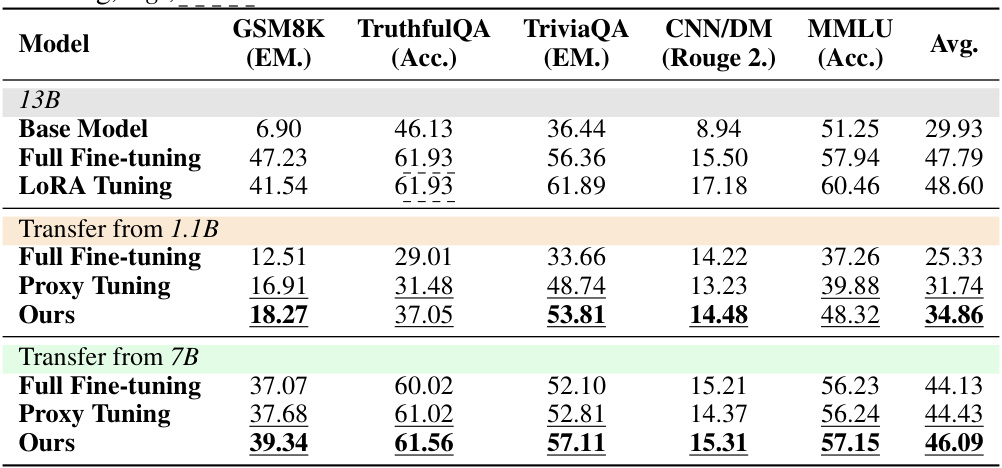
This table presents the results of single-task experiments, comparing the performance of different methods on five datasets: GSM8K, TruthfulQA, TriviaQA, CNN/DM, and MMLU. The methods compared include using the base model, full fine-tuning, LoRA tuning, and the proposed dynamic logit fusion method. The table shows the average performance across all five tasks, highlighting the superior performance of the proposed approach, particularly when transferring knowledge from smaller models (7B and 1.1B) to a larger 13B model. Bold numbers indicate the best result achieved by transferring from a model of a particular size, and underlines show when a method outperforms its corresponding expert model. Note that a special case is handled for the TruthfulQA dataset, as a LoRA adapter for the 13B model could not be obtained.
In-depth insights#
Weak-to-Strong Tuning#
Weak-to-strong tuning represents a parameter-efficient approach to adapting large language models (LLMs) for specific tasks. Instead of fine-tuning the massive LLM directly, which is computationally expensive, this method leverages smaller, specialized models (‘weak’ models) trained on the target task. The knowledge distilled from these smaller models is then transferred to the larger LLM (‘strong’ model) via techniques like logit arithmetic. This transfer process avoids the substantial computational costs associated with full LLM fine-tuning while still improving task performance. A key advantage lies in the potential for incremental learning where new task-specific knowledge can be added without retraining the entire large model. This approach is particularly beneficial for scenarios with limited computational resources or when dealing with sensitive data, where full fine-tuning of an LLM may be impractical. However, challenges remain in optimizing the knowledge transfer process, as the weights allocated to the weak and strong models must be carefully determined, ideally dynamically adjusting according to the input data. Further research should focus on developing more efficient and robust knowledge transfer methods to maximize the performance gains of weak-to-strong tuning.
Logit Fusion#
Logit fusion, in the context of large language models (LLMs), presents a novel approach to efficiently transfer knowledge from smaller, specialized models to larger, more powerful ones. It avoids the computationally expensive process of fine-tuning the larger model, relying instead on a fusion of logits (pre-softmax outputs) from the smaller models. This method offers a parameter-efficient alternative that avoids the memory overhead associated with full fine-tuning. The core idea involves adaptively weighting the contributions of these smaller models during inference, a dynamic process crucial for optimal performance across diverse tasks and inputs. Dynamic weighting addresses the shortcomings of static knowledge transfer ratios, which struggle with task heterogeneity and suboptimal performance. A key advantage lies in its ability to leverage the strengths of both smaller, task-specific experts and the larger, general-purpose LLM, thus achieving potentially superior results compared to training the large model from scratch.
Adaptive Weights#
The concept of “Adaptive Weights” in a machine learning context, particularly within large language models (LLMs), suggests a dynamic adjustment of parameters to optimize performance. Instead of statically assigning weights or ratios, adaptive methods allow for the weights to change during the model’s operation, often based on the specific input or task. This approach is crucial for handling the complexity of LLMs, as tasks and inputs vary greatly in their informational needs. Dynamic weight allocation enables better knowledge transfer from smaller, specialized models to larger models, improving accuracy and efficiency. For example, in a question-answering task, a system might give more weight to a specialized model during factual reasoning parts of the process than in handling common sense aspects. The optimization problem inherent in learning these adaptive weights may employ techniques like Kullback-Leibler divergence to measure the distance between model distributions and guide the search for optimal weight values. This sophisticated methodology helps to overcome limitations of simpler weak-to-strong transfer approaches, resulting in a more robust and powerful system. The potential benefit lies in reducing the computational costs associated with full fine-tuning of large models while maintaining or exceeding performance. A key challenge is the computational complexity of learning these adaptive weights, but clever techniques like constrained optimization and efficient search strategies can mitigate this.
Multi-task Learning#
Multi-task learning (MTL) aims to improve model performance and efficiency by training a single model on multiple related tasks simultaneously. Sharing parameters and representations across tasks allows the model to leverage commonalities, leading to better generalization and reduced overfitting. However, negative transfer, where learning one task hinders performance on another, is a significant challenge. Careful task selection and appropriate architectural designs, such as task-specific branches or shared layers, are crucial for successful MTL. The effectiveness of MTL depends on the relatedness of tasks; closely related tasks often yield greater benefits. Furthermore, optimization strategies play a vital role; algorithms must effectively balance the learning objectives across different tasks to prevent one task from dominating. While MTL offers substantial potential, addressing these complexities requires a deep understanding of task relationships and careful model design.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the dynamic logit fusion approach is crucial, perhaps through more sophisticated optimization techniques or by leveraging model parallelism. Investigating the effectiveness of this method with other large language models beyond the LLaMA series would further validate its generality and robustness. Expanding the method’s applicability to various downstream tasks and exploring its integration with different parameter-efficient fine-tuning methods are also important future directions. Addressing limitations such as the computational cost and the potential for interference between the knowledge transferred from multiple small models should be further investigated. Finally, a deeper theoretical analysis to better understand the behavior of the dynamic weight allocation and its relation to the model’s underlying architecture would contribute significantly to the field.
More visual insights#
More on figures

This figure compares the performance of using a pre-defined alpha (α) value versus the dynamically adjusted alpha value in the proposed adaptive logit fusion approach across different tasks. The pre-defined α values tested were 0.5, 1.0, and 1.5, while ‘Ours’ represents the dynamically learned α. The x-axis represents the different tasks (GSM8K, TruthfulQA, TriviaQA, CNN/DM, and MMLU), and the y-axis shows the performance, likely measured as accuracy or another relevant metric. The bars visually compare the performance of each method on each task, highlighting the superiority of the dynamic α learning approach in achieving better performance across the board.
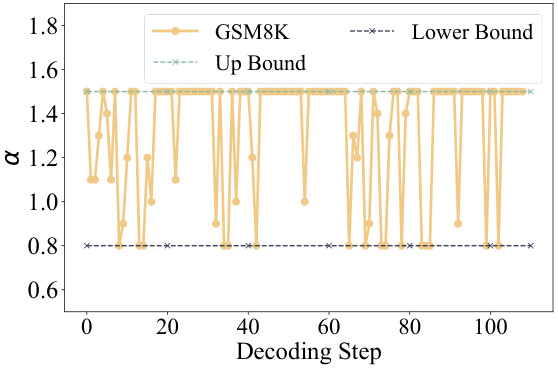
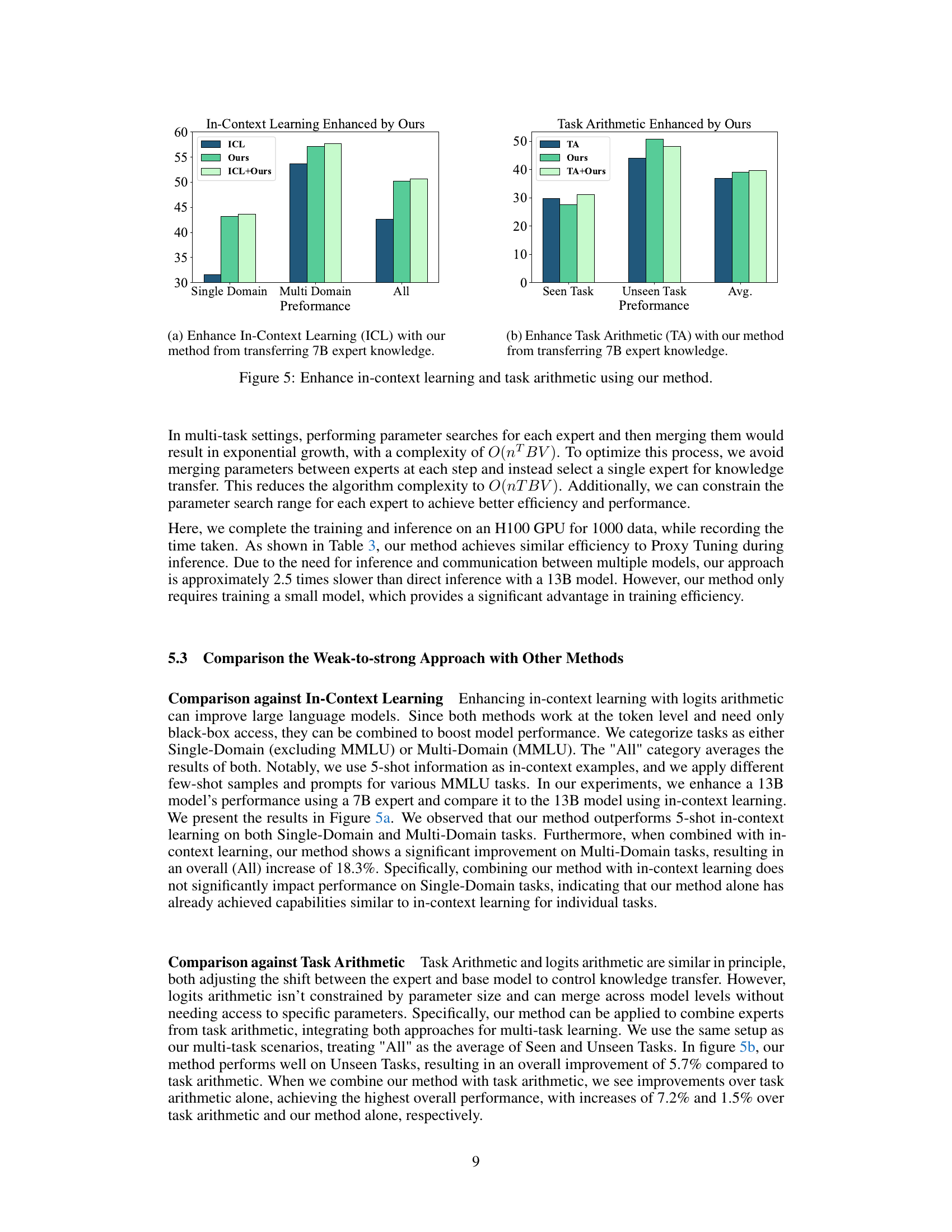
This figure shows how the weight α, which controls the knowledge transfer from the GSM8K expert model to the large language model, changes during the decoding process. The x-axis represents the decoding step, and the y-axis represents the value of α. The plot shows the actual α value during optimization (in gold), along with the upper and lower bounds of α found during the optimization process (dashed lines). The variability and range of the α values illustrate the adaptive nature of the knowledge transfer process and its sensitivity to the specifics of each decoding step.

This figure compares the performance of using a pre-defined alpha (α) value versus a dynamically adjusted alpha value in the proposed logit arithmetic method. The x-axis represents different tasks, and the y-axis represents the alpha value. The figure shows that using a dynamically adjusted alpha leads to better performance compared to a fixed alpha value across different tasks.
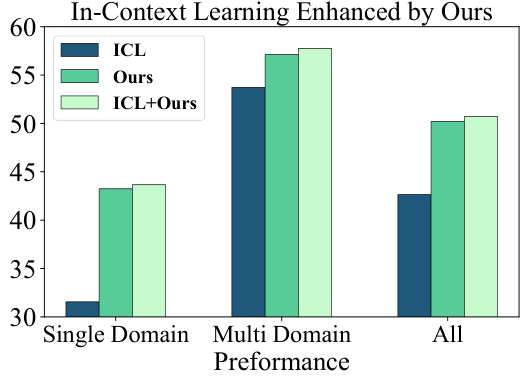
This figure compares the performance of in-context learning (ICL), the proposed method, and the combination of both (ICL+Ours) across three categories: single-domain tasks, multi-domain tasks, and the average of all tasks. The bar chart illustrates that combining the proposed method with ICL leads to improved performance, particularly for multi-domain tasks, demonstrating the synergistic effects of both techniques.
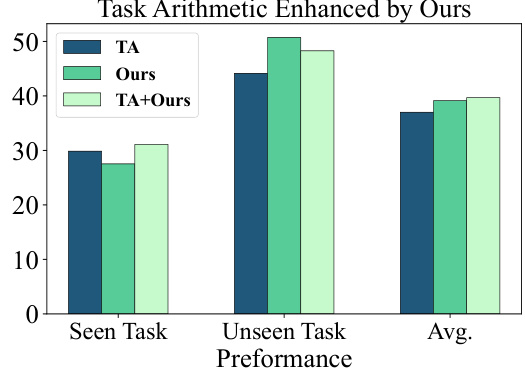
This figure compares the performance of three methods: In-context learning (ICL), the proposed dynamic logit fusion method (‘Ours’), and a combination of both (ICL+Ours). The comparison is done across three categories: single-domain tasks, multi-domain tasks, and an average across all tasks. The results show that the proposed method outperforms in-context learning alone and that combining the methods yields even better results, especially for multi-domain tasks.

This figure illustrates the architecture and process of the proposed method. The top section shows the k-th decoding step, where multiple small expert models (small llamas) contribute to the logits of a large language model (large llama). Their logit outputs are combined through a weighted sum, where weights (α1, α2, α3) are learned adaptively. The bottom section depicts the adaptive knowledge transfer optimization process, showing how these weights are dynamically adjusted at each decoding step to optimally fuse knowledge from the experts.
More on tables
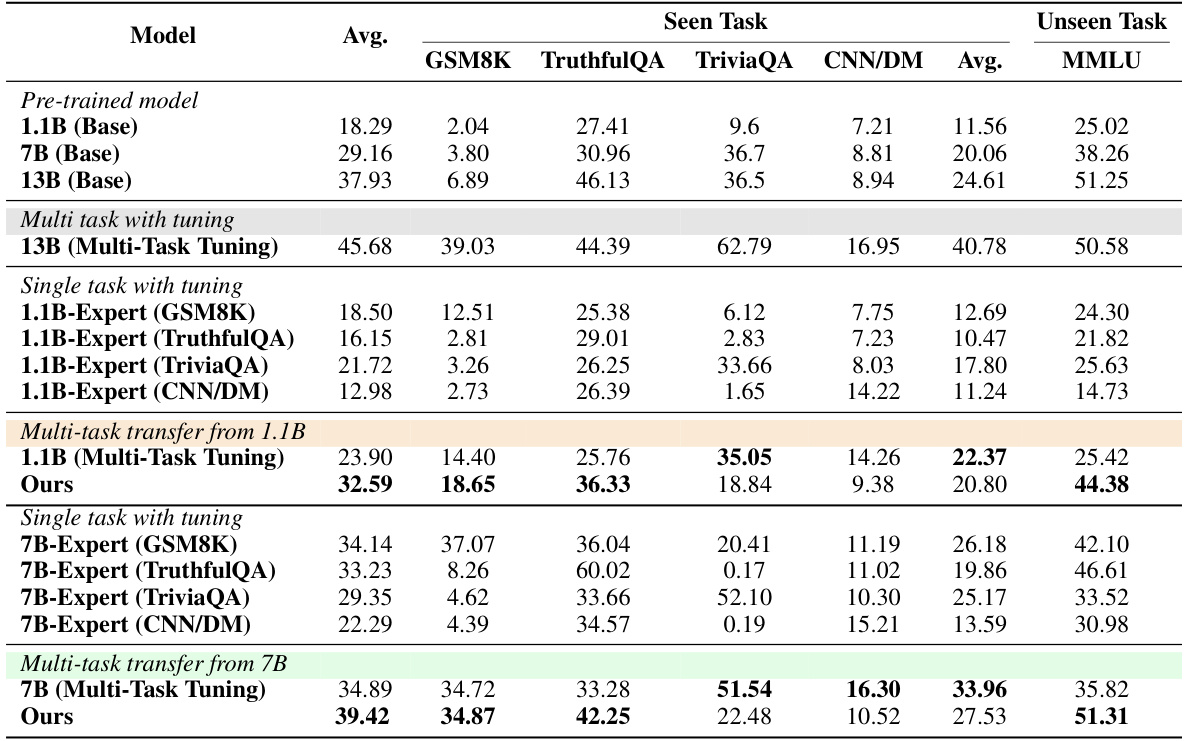
This table presents the results of single-task experiments, comparing different methods for transferring knowledge from smaller models (1.1B and 7B parameters) to a larger model (13B parameters). It shows the performance across five datasets (GSM8K, TruthfulQA, TriviaQA, CNN/DM, MMLU) for three approaches: full fine-tuning, LoRA tuning, and the proposed dynamic logit fusion method. Bold numbers highlight the best performance achieved using models of the same size (1.1B or 7B) as the source expert. Underlines show when the proposed method outperforms the source expert model. Due to the unavailability of a LoRA adapter for the 13B model on the TruthfulQA dataset, the LoRA tuning result is set equal to the full fine-tuning result for consistency.
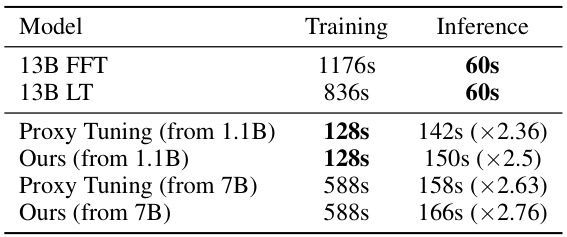
This table compares the training and inference time of different methods for a large language model (13B) on a single GPU using 1000 data points. It shows a significant reduction in training time when using the proposed method compared to full fine-tuning (FFT) and LoRA tuning (LT). The inference time of the proposed method is slightly higher than full fine-tuning and LoRA tuning, but the increase is relatively small, considering the substantial reduction in training time.

This table presents the performance comparison of different methods on five single-task scenarios: GSM8K, TruthfulQA, TriviaQA, CNN/DM, and MMLU. It compares the performance of using a base model, full fine-tuning the 13B model, LoRA tuning the 13B model, transferring knowledge from a 1.1B fine-tuned model, and the proposed method transferring from both 1.1B and 7B fine-tuned models. Bold numbers highlight the best performance for models of the same size (1.1B or 7B transfer), and underlines show when the proposed method outperforms the expert (fine-tuned) small model.

This table presents the results of single-task experiments comparing different methods: a base 13B model, a fully fine-tuned 13B model, a LoRA-tuned 13B model, and the proposed method transferring knowledge from smaller 1.1B and 7B models. The performance is evaluated across five datasets (GSM8K, TruthfulQA, TriviaQA, CNN/DM, and MMLU) using metrics relevant to each dataset (e.g., Exact Match, Accuracy, Rouge-2). The table highlights the superiority of the proposed method by bolding the best results within each model size and underlining instances where the new method surpasses the corresponding expert model’s performance.
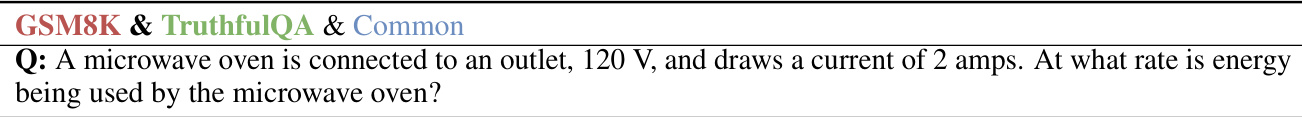
This table presents the results of single-task experiments using different models and methods. It compares the performance of several approaches, including full fine-tuning of a 13B model, LoRA tuning, a proxy tuning method, and the proposed dynamic logit fusion method. Results are shown for different tasks such as GSM8K (exact match), TruthfulQA (accuracy), TriviaQA (exact match), CNN/DailyMail (ROUGE-2), and MMLU (accuracy). The table highlights which methods outperform the smaller expert models used for knowledge transfer and shows the average performance across all tasks. The note about the LoRA adapter setting explains a detail about data handling in one of the experiments.
Full paper#