↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Image generation (IG) and image understanding (IU) are core areas in computer vision. Recent research has explored using IG models for IU tasks but not the other way around. This paper investigated the potential of IU models to improve IG. The authors focus on token-based IG which requires good tokenizers. Current tokenizers are mostly trained using pixel reconstruction which is suboptimal.
This paper shows that by adopting feature reconstruction instead of pixel reconstruction, and distilling knowledge from pre-trained IU encoders, they significantly improve the performance of the tokenizers. The improved tokenizers result in better image generation performance across various metrics. They propose VQ-KDCLIP which achieves 4.10 FID on ImageNet-1k. This superior performance is attributed to the rich semantics carried within the VQ-KD codebook. A straightforward pipeline to directly transform IU encoders into tokenizers is also introduced, demonstrating its exceptional effectiveness.
Key Takeaways#
Why does it matter?#
This paper is important because it challenges the conventional approach to image tokenizer training in image generation, demonstrating that incorporating knowledge from image understanding models significantly improves performance. This opens new avenues for research by suggesting a synergistic relationship between image understanding and generation, leading to more efficient and effective models. It also provides a practical and easily replicable method for transforming image understanding encoders into tokenizers. The release of the code further enhances the accessibility and potential impact of this research.
Visual Insights#
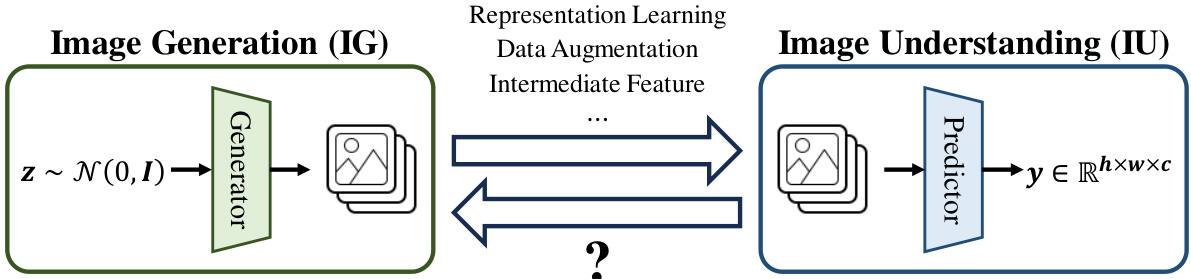
This figure illustrates the relationship between Image Generation (IG) and Image Understanding (IU). It shows that while many studies have explored using IG models to assist in IU tasks (through representation learning, data augmentation, or using intermediate features), there has been little research into leveraging IU models to improve IG. The question mark highlights this unexplored reciprocal relationship, which the paper aims to investigate.
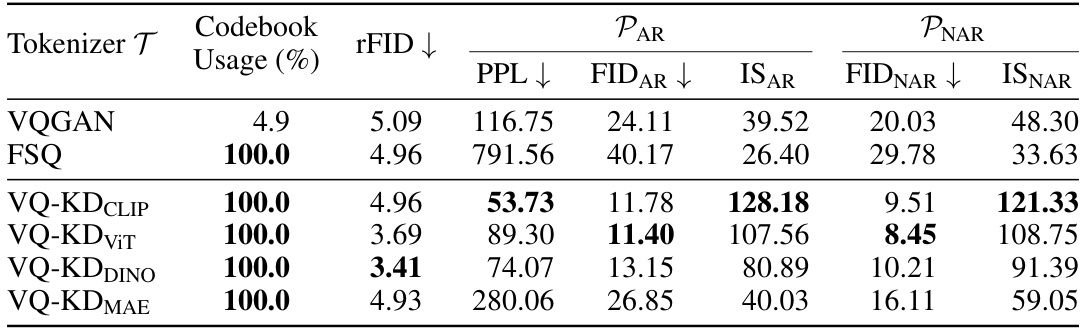
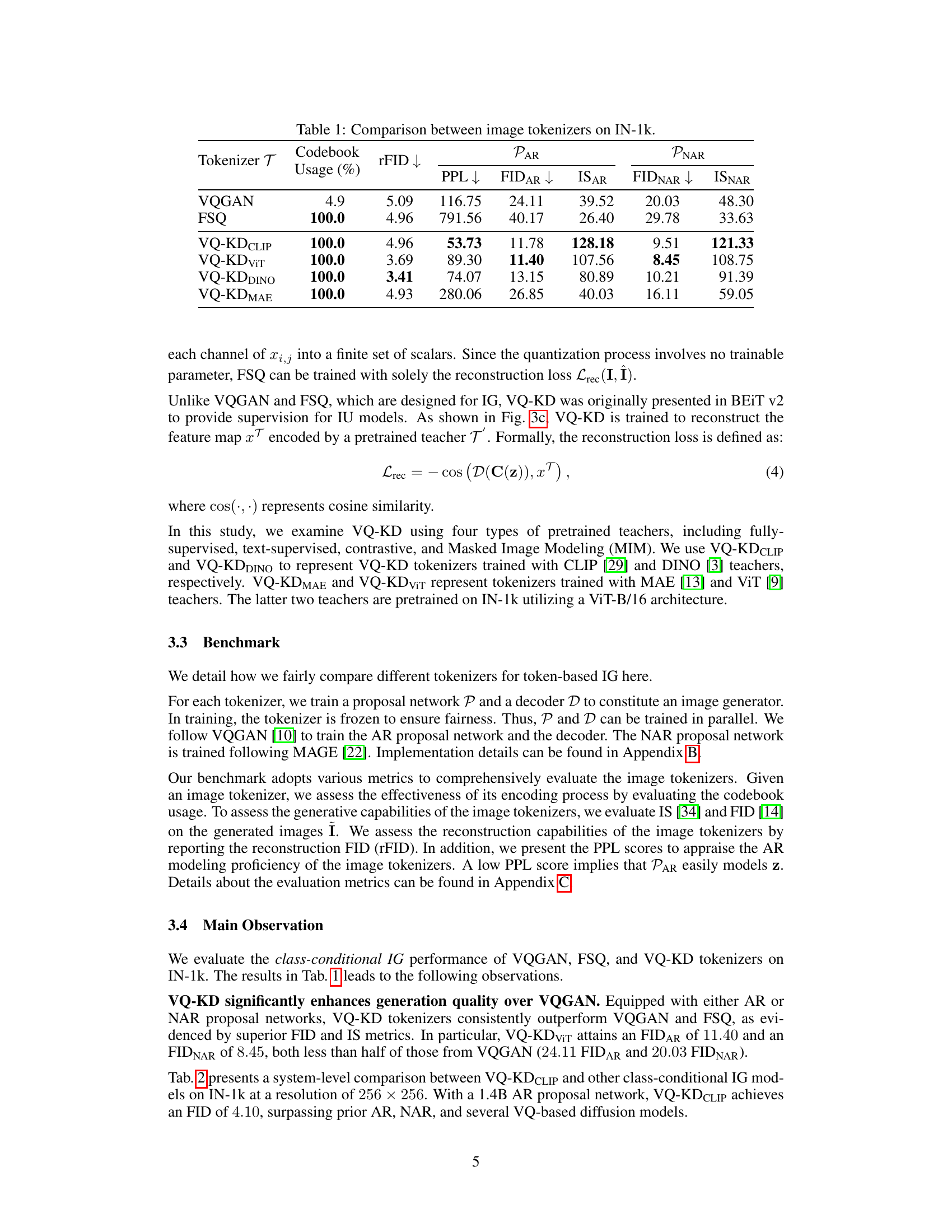
This table compares the performance of different image tokenizers on the ImageNet-1k dataset. It shows key metrics for each tokenizer, including codebook usage, reconstruction FID (rFID), perplexity (PPL), Fréchet Inception Distance for Autoregressive proposal networks (FIDAR), Inception Score for Autoregressive proposal networks (ISAR), Fréchet Inception Distance for Non-Autoregressive proposal networks (FIDNAR), and Inception Score for Non-Autoregressive proposal networks (ISNAR). The results highlight the superior performance of VQ-KD tokenizers compared to VQGAN and FSQ across various metrics. Lower FID and rFID values indicate better image generation quality, while higher IS scores reflect improved diversity. Lower PPL suggests that the proposal network models the token sequence more effectively.
In-depth insights#
IU-IG Synergy#
The concept of “IU-IG Synergy” explores the bidirectional relationship between Image Understanding (IU) and Image Generation (IG). A key insight is that advancements in one area can significantly benefit the other. The paper likely investigates how pre-trained IU models, rich in semantic understanding, can improve the performance of IG models. This might involve using IU model features to enhance image tokenization, a crucial step in AR-based IG. Conversely, the paper could also explore how insights from IG, particularly about high-quality image generation and representation learning, might be leveraged to improve IU tasks such as object recognition or semantic segmentation. The core of the synergy lies in shared representations and the transfer of knowledge between IU and IG models. This transfer can occur through feature sharing, knowledge distillation, or joint training. Successfully demonstrating this synergy could lead to significant advancements in both fields. It is likely that this analysis includes quantitative and qualitative evaluations, comparing the performance of IG models using different IU model integration strategies to show the effectiveness of this approach and also revealing the limitations in the synergy.
VQ-KD Tokenizers#
The core of this research lies in VQ-KD (Vector Quantization - Knowledge Distillation) tokenizers, which represent a significant departure from traditional pixel-based image tokenization methods. Instead of directly reconstructing pixels, VQ-KD tokenizers leverage the knowledge of pre-trained image understanding (IU) encoders. This approach is shown to be highly effective, outperforming traditional methods across various metrics including FID (Fréchet Inception Distance) and IS (Inception Score). The superiority of VQ-KD is attributed to the richer semantic information captured in its codebook, which enables more accurate and detailed image generation. A further key finding highlights the straightforward pipeline for directly transforming IU encoders into tokenizers, showcasing the powerful synergy between IU and image generation. This approach promises a paradigm shift in image tokenizer design and significantly impacts the field of image generation.
Feature Rec. Obj.#
The heading ‘Feature Rec. Obj.’ suggests a focus on a novel objective function for training image tokenizers in the context of image generation. Traditional methods often rely on pixel-level reconstruction, which can be computationally expensive and less effective in capturing semantic information. A feature reconstruction objective offers the potential for improvements by focusing on higher-level image representations extracted from pre-trained image understanding (IU) encoders. This approach leverages the rich semantic knowledge encoded in these features. By training the tokenizer to reconstruct these feature maps instead of raw pixels, the model likely learns a more meaningful and compact representation of the input image. This is expected to lead to better generalization and potentially improved image generation quality, especially in terms of higher semantic fidelity and improved perceptual realism. The choice of pre-trained IU encoder is critical, as the quality of its features directly impacts the performance of the tokenizer. The success of this approach relies on the effectiveness of transferring knowledge from the IU model to the image generation model. This method provides a strong link between image understanding and image generation, highlighting the potential for cross-disciplinary advancements. Furthermore, evaluating the success of this method would involve comparing its performance against pixel-based reconstruction methods across various metrics and datasets.
Codebook Analysis#
A thorough codebook analysis is crucial for understanding the performance of vector quantized image tokenizers. This involves visualizing the codebook to assess semantic organization. High-quality tokenizers exhibit clear semantic clustering, where codes representing similar visual features group together, facilitating effective proposal network modeling. Visualizing the codebook using dimensionality reduction techniques (like t-SNE) is essential to identify potential issues such as codebook collapse or semantic ambiguity. Furthermore, analyzing codebook size and dimensionality reveals trade-offs; larger codebooks capture finer details but increase computational complexity. Optimally sized and dimensioned codebooks strike a balance between semantic richness and computational efficiency. In-depth analysis should also compare different codebook generation techniques, such as those based on image reconstruction versus feature reconstruction, highlighting their strengths and weaknesses in terms of semantic representation and overall image generation performance. Qualitative evaluation by comparing reconstruction results from different tokenizers helps visually assess the impact of codebook characteristics on image quality.
Future Works#
Future research directions stemming from this work could explore several promising avenues. Extending the VQ-KD framework to other generative models beyond the autoregressive approach is crucial. Investigating its compatibility with diffusion models, for instance, could unlock new levels of image quality and diversity. Another key area involves a deeper investigation into the relationship between the semantics encoded in the codebook and the quality of image generation. Analyzing the impact of codebook size and dimensionality on various downstream tasks would be valuable. Finally, developing more sophisticated methods for directly transforming IU encoders into effective tokenizers warrants attention. Exploring alternative clustering algorithms or knowledge distillation techniques could lead to even more efficient and effective tokenizers. Furthermore, assessing the generalization capabilities of these tokenizers across different datasets and tasks is critical to establishing the robustness of the proposed method. These research directions would solidify the foundation for a deeper, more comprehensive understanding of the interplay between IU and IG.
More visual insights#
More on figures
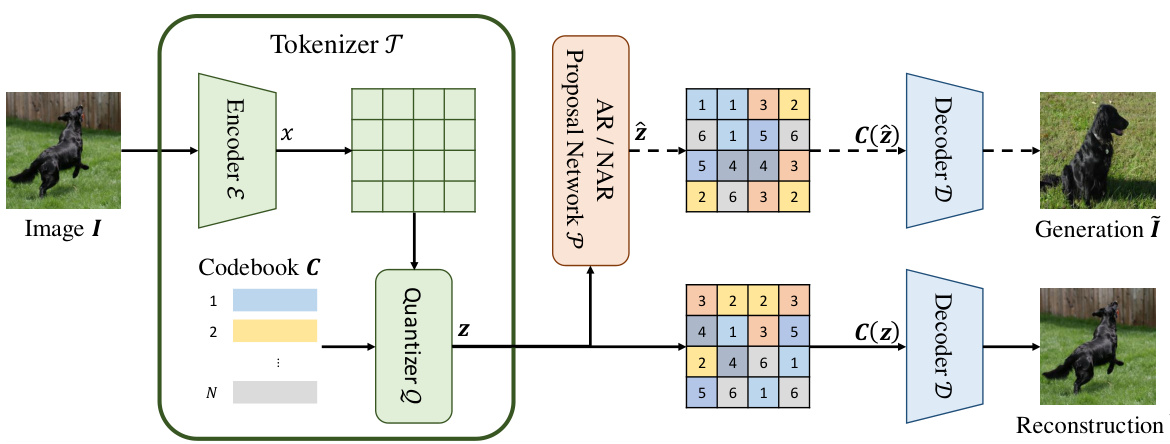
This figure illustrates the two-stage token-based image generation (IG) framework. The first stage involves a tokenizer (T) that converts an image (I) into a sequence of discrete codes (z) using an encoder (E) and a codebook (C). The second stage uses a proposal network (P), which can be autoregressive (AR) or non-autoregressive (NAR), to model the probability distribution of the code sequence (p(z)). A decoder (D) then reconstructs the image from the code sequence. During inference, the proposal network generates a new code sequence, and the decoder generates a new image (Ĩ).
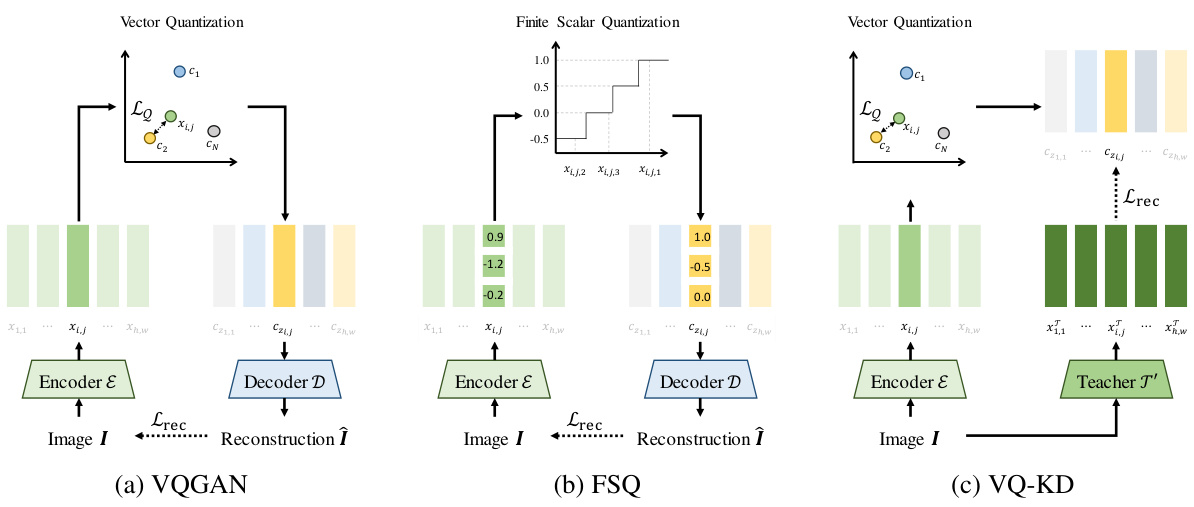
This figure compares three different image tokenizer architectures: VQGAN, FSQ, and VQ-KD. VQGAN uses vector quantization to map image features to discrete codes. FSQ employs finite scalar quantization, a simpler method. VQ-KD, unlike the others, uses knowledge distillation from a pre-trained teacher model (IU encoder) to learn the codebook, focusing on feature reconstruction rather than pixel reconstruction. Each sub-figure illustrates the process, highlighting the key components (encoder, quantizer, decoder) and the loss functions used during training.
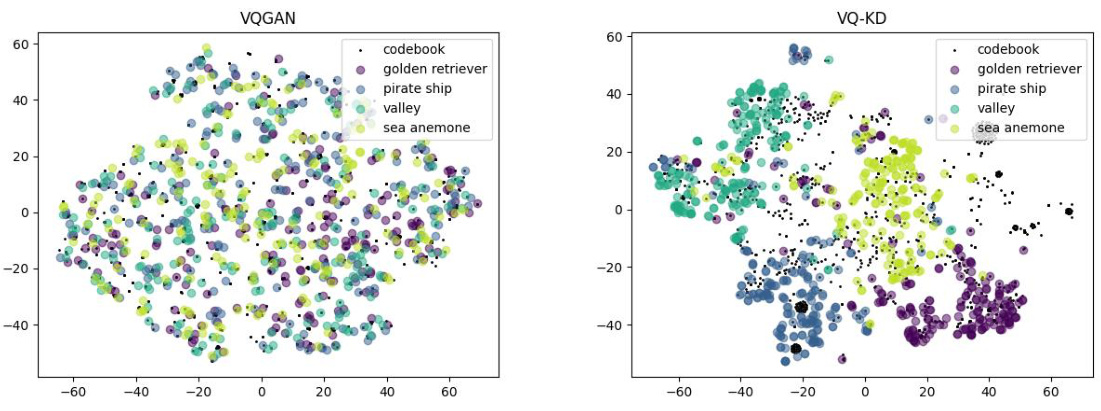
This figure visualizes the codebooks of VQGAN and VQ-KDvit using t-SNE to project the feature map and code vectors into a two-dimensional space. The visualization shows that the VQ-KD codebook exhibits superior organization compared to the VQGAN codebook. In the VQ-KD feature space, features from the same category are clustered together indicating each code in the VQ-KD codebook conveys clear semantics, whereas in VQGAN, the codebook is shared across multiple categories, resulting in semantic ambiguity. This difference in semantic organization helps explain why VQ-KD outperforms VQGAN in terms of perplexity (PPL), despite having lower codebook usage.

This figure shows the reconstruction results of five different image tokenizers: Original, VQGAN, FSQ, VQ-KD, and Cluster. Each row represents a different tokenizer. Each column shows a reconstruction of the same original image, allowing for a visual comparison of the quality of reconstruction produced by each tokenizer. Red boxes highlight areas where VQGAN and FSQ fail to correctly reconstruct the image details, demonstrating the superior performance of VQ-KD and Cluster in faithfully reproducing the original image.

This figure visually compares the reconstruction quality of four different image tokenizers: VQGAN, FSQ, VQ-KD, and Cluster. Each row represents a different tokenizer. Each column shows the reconstruction of the same image from the original image dataset (shown in the top row). The figure highlights how well each tokenizer reconstructs various aspects of the original image, such as textures, details, and overall appearance. By comparing the reconstructions with the original images, one can visually assess each tokenizer’s strengths and weaknesses in terms of image fidelity and detail preservation.

This figure presents a visual comparison of the reconstruction quality achieved by different image tokenizers. Each row represents a different tokenizer (VQGAN, FSQ, VQ-KD, and Cluster). The original image is shown in the first column, followed by the reconstructions generated by each tokenizer. The figure highlights the differences in the detail and accuracy of reconstruction between the different tokenizers, showing VQ-KD and Cluster to maintain significantly better visual fidelity.
More on tables
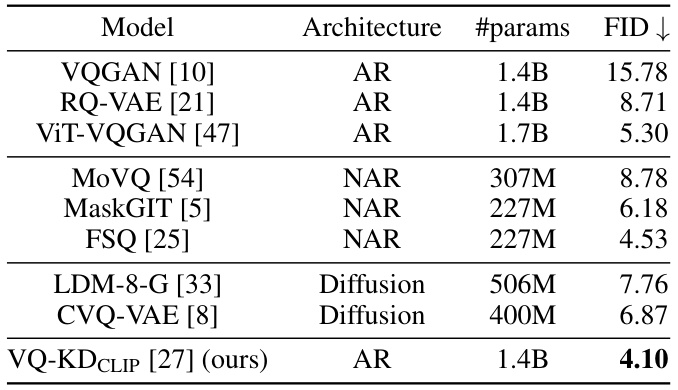
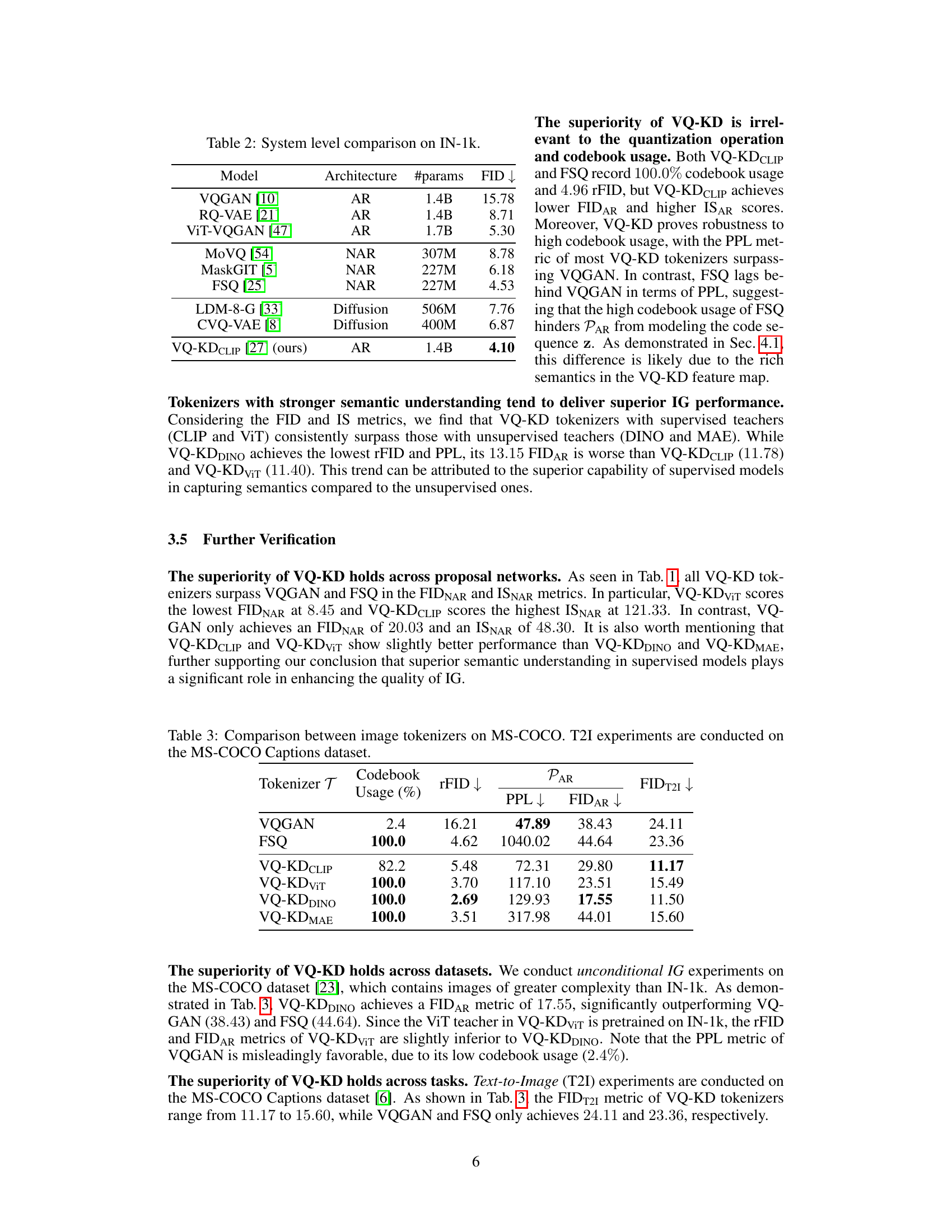
This table compares the performance of various image generation models on the ImageNet-1k dataset. The models are categorized by their architecture (Autoregressive (AR), Noise-to-Noise (NAR), or Diffusion), the number of parameters, and their Fréchet Inception Distance (FID) score, a lower score indicating better performance. The table highlights that VQ-KDCLIP, an autoregressive model using a feature reconstruction objective, significantly outperforms other state-of-the-art models, achieving a substantially lower FID score.
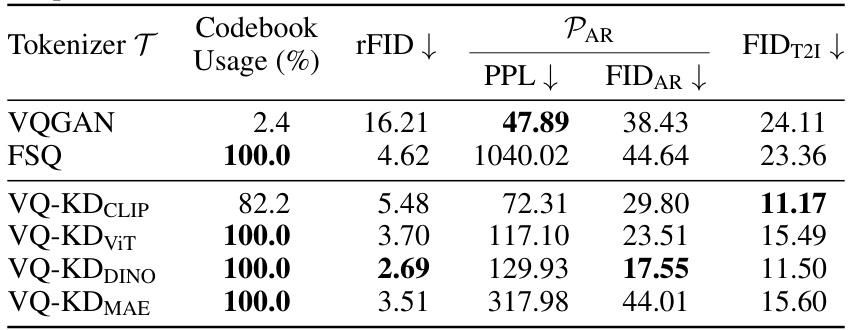
This table presents a comparison of different image tokenizers’ performance on the MS-COCO Captions dataset for text-to-image (T2I) tasks. It shows the codebook usage (percentage), reconstruction FID (rFID), perplexity (PPL) of the AR proposal network, FID for text-to-image tasks (FIDT2I), and FID for AR proposal network (FIDAR). The results illustrate the relative performance of different tokenizers in terms of various metrics, highlighting their strengths and weaknesses.
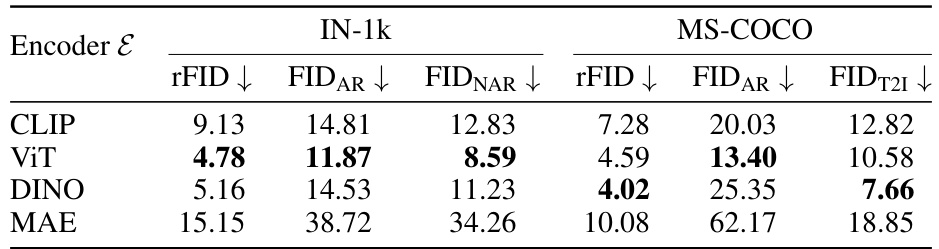
This table presents a comparison of the performance of cluster-based tokenizers using different pretrained models (CLIP, ViT, DINO, MAE) as encoders. The performance is evaluated using rFID, FIDAR, FIDNAR, FID, FIDAR, and FIDT21 metrics on both IN-1k and MS-COCO datasets. The results show that the ViT encoder yields the best performance, highlighting the potential of using pretrained models for image tokenization in image generation tasks.
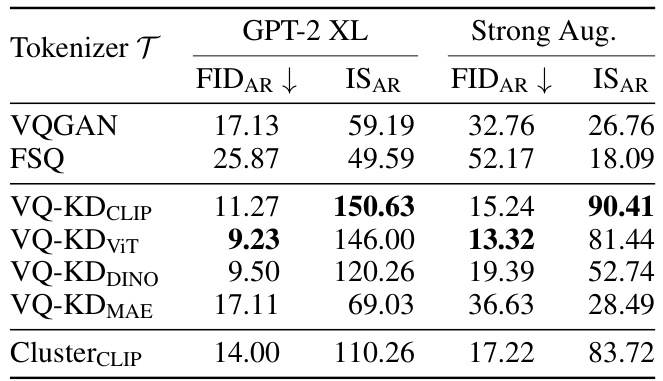
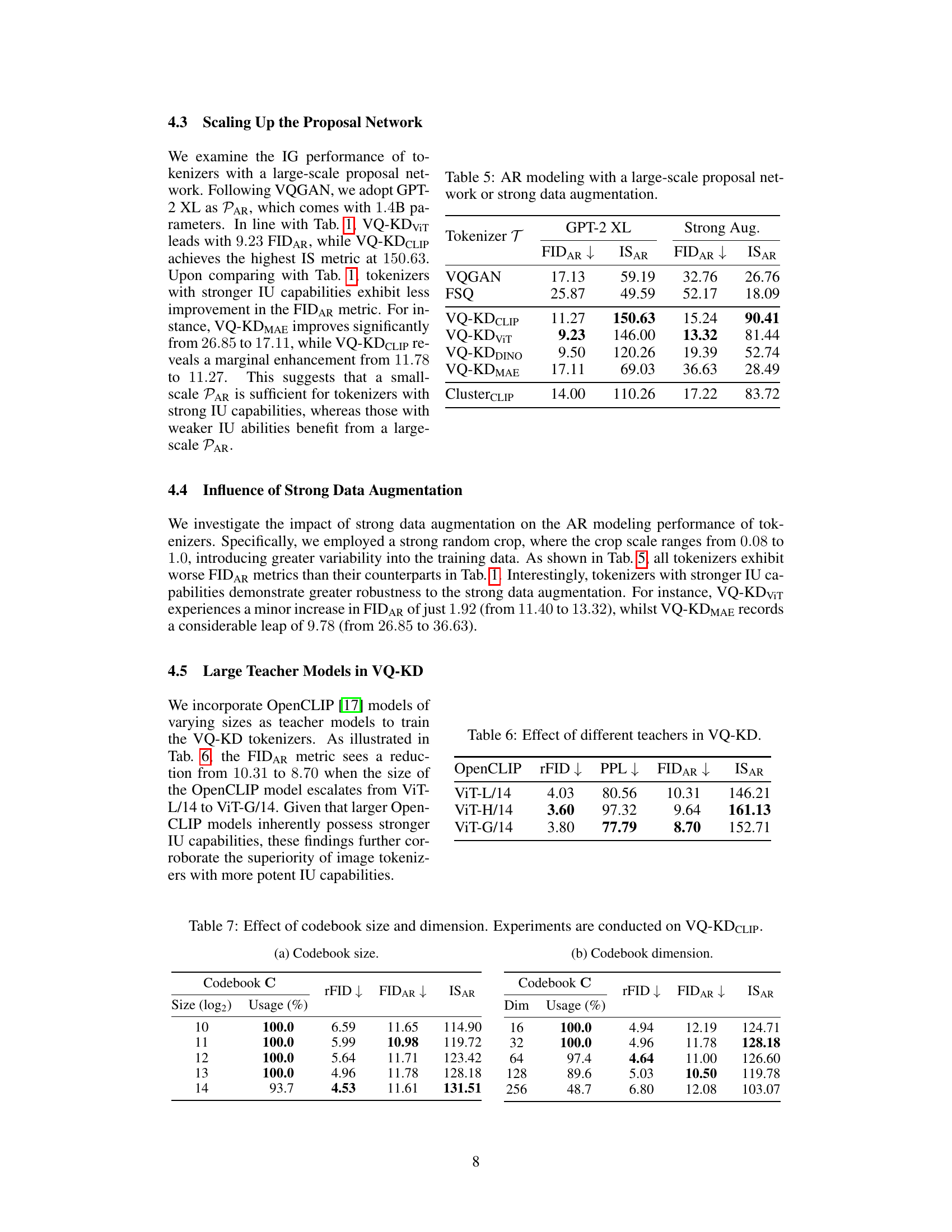
This table presents the results of image generation using different tokenizers (VQGAN, FSQ, VQ-KD variants, and ClusterCLIP) with two different proposal networks: GPT-2 XL (a large-scale proposal network) and a standard proposal network with strong data augmentation. The metrics used to evaluate the performance are FIDAR (Fréchet Inception Distance for Autoregressive models) and ISAR (Inception Score for Autoregressive models). Lower FIDAR indicates better image generation quality. Higher ISAR suggests a better balance between diversity and quality of generated images.
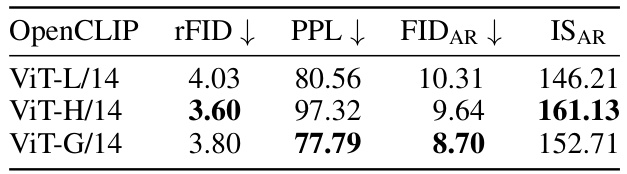
This table presents the results of using different sized OpenCLIP models as teachers in the VQ-KD training process. The table shows that larger models (ViT-H/14 and ViT-G/14) generally result in lower FIDAR (Fréchet Inception Distance for autoregressive generation) scores and improved ISAR (Inception Score for autoregressive generation) scores, suggesting that better image understanding (IU) capabilities of the teacher models lead to better image generation performance. The rFID (reconstruction FID) and PPL (perplexity) are also shown, providing further insights into the quality of the tokenization and the ease of modeling the token sequences.
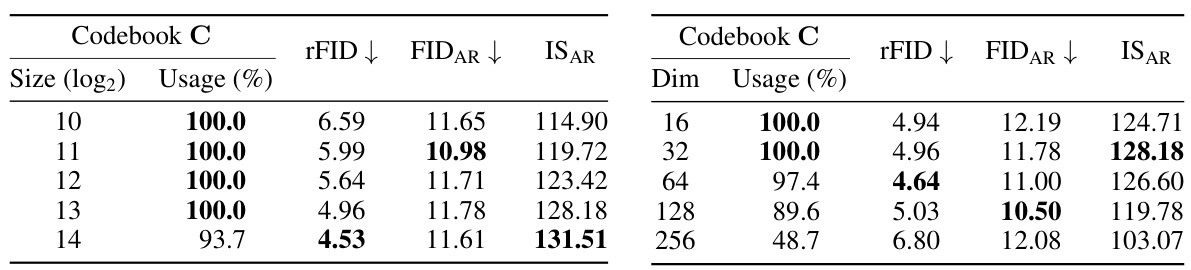
This table presents the results of experiments conducted on the VQ-KDCLIP model, investigating the impact of codebook size and dimension on the model’s performance. It shows the rFID, FID_AR, and IS_AR metrics for different codebook sizes (in powers of 2) and dimensions, along with the codebook usage percentage. The results highlight the trade-off between codebook expressiveness and the ability of the model to effectively utilize the larger codebook.
Full paper#