↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current large language models (LLMs) struggle with either limited context windows or inefficient processing of long sequences. This arises from relying solely on either eidetic memory (like Transformers) or fading memory (like State Space Models). Hybrid models attempt to combine both but lack seamless modulation and scalable eidetic memory.
B’MOJO offers a novel solution. This hybrid architecture uses Stochastic Realization Theory to seamlessly integrate eidetic and fading memory. Experiments show that it outperforms existing approaches in transductive inference tasks, achieving comparable performance to transformers in language modeling while being faster to train. Significantly, B’MOJO demonstrates length generalization, effectively inferring on sequences substantially longer than those seen during training.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models and transductive inference. It provides a novel hybrid architecture that addresses limitations of existing models by seamlessly combining eidetic and fading memory, enabling more efficient and accurate processing of long sequences, particularly relevant given the current focus on long-context understanding. The open-sourced implementation allows for easy replication and further development.
Visual Insights#
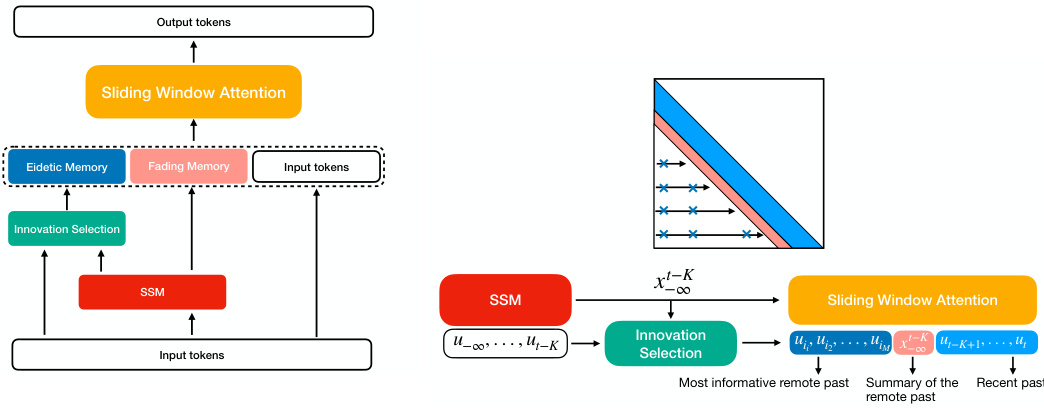
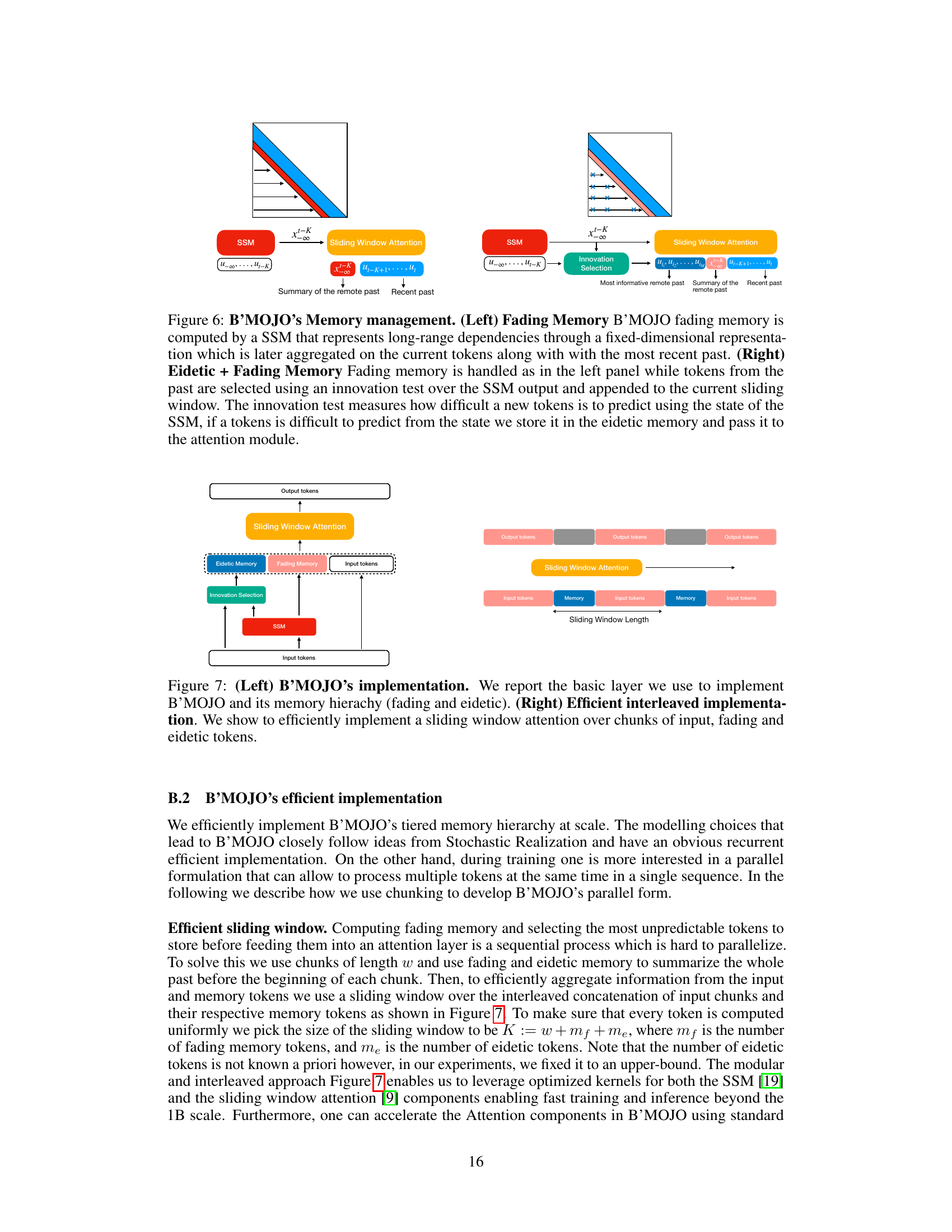
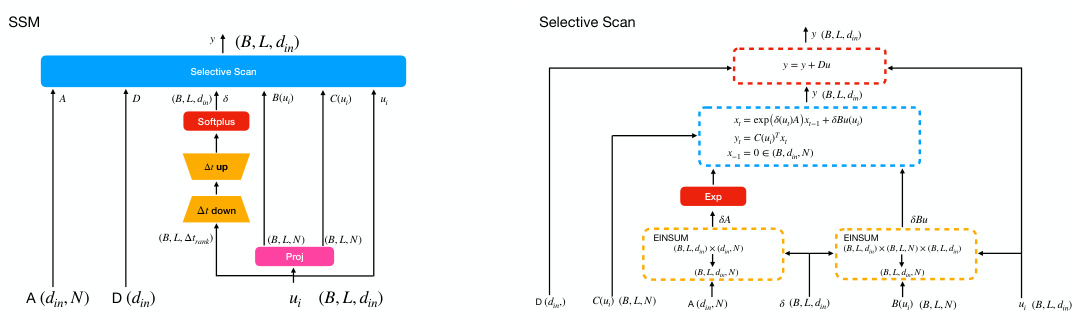
The figure illustrates B’MOJO’s memory management system. The left panel shows a single B’MOJO layer, highlighting the interaction between eidetic memory (short-term, lossless storage), fading memory (long-term, lossy state representation from an SSM), and the sliding window attention mechanism. The right panel details B’MOJO’s realization, showcasing how long-range dependencies are captured by the SSM and how the innovation selection process adds informative past tokens to the eidetic memory based on their unpredictability.
This table compares the performance of B’MOJO against other state-of-the-art models on four different synthetic tasks assessing the models’ ability to recall specific information from a sequence. The results show that B’MOJO consistently achieves better or comparable performance across various model sizes and task difficulties.
In-depth insights#
Hybrid Memory Model#
A hybrid memory model in a research paper context is a fascinating concept. It likely involves combining the strengths of different memory systems to overcome individual limitations. One system might offer fast access to recent information (e.g., short-term memory), while another could provide long-term storage and retrieval (e.g., long-term memory). The hybrid approach may involve sophisticated mechanisms for deciding when and how to utilize each type of memory. Such a decision could be based on data recency, importance, or predictive value. The model’s architecture would require careful engineering to integrate both components seamlessly. The choice of underlying memory systems (e.g., neural networks, external memory stores) is crucial, as it determines the trade-offs between speed, capacity, and accuracy. Effective hybrid memory architectures are likely to be essential for creating robust and versatile AI systems capable of handling various types of tasks and data.
Innovation Selection#
The concept of “Innovation Selection” presented in the paper offers a novel approach to managing memory in sequence models. It addresses the limitations of existing methods by selectively storing only the most unpredictable tokens. This strategy, inspired by Lempel-Ziv-Welch compression, ensures efficient memorization of crucial information without the computational burden of storing every single data point. The core idea revolves around an “innovation test” that identifies tokens difficult to predict based on existing memory, flagging them for eidetic storage. This dynamically adjusts the model’s focus, prioritizing the addition of surprising or unexpected data while compressing predictable data into a fading memory state. Consequently, “Innovation Selection” not only improves memory efficiency but also facilitates effective long-term memory management and enhances the model’s ability to generalize well on longer sequences than those seen during training. The method elegantly balances eidetic and fading memory, thereby optimizing transductive inference.
Transductive Inference#
Transductive inference presents a compelling alternative to traditional inductive learning, particularly when dealing with limited data or non-stationary distributions. Unlike inductive methods which aim to generalize from a training set to unseen data, transductive inference leverages all available data, both training and test sets, simultaneously during the inference process. This approach can lead to improved performance on specific instances, even if generalization to entirely new data points suffers. Key to the success of transductive inference is effective memorization of the training data. However, this must be balanced with efficient computation. Therefore, the design of architectures that allow for both massive storage and swift retrieval is crucial. Recent research explores hybrid approaches combining eidetic (lossless) and fading (lossy) memory mechanisms to address these challenges, offering a potentially powerful paradigm for future AI systems focused on specific task performance rather than broad generalization.
Efficient Training#
Efficient training of large language models (LLMs) is crucial for practical applications. The paper likely explores methods to reduce training time and computational cost without sacrificing performance. This might involve techniques like model parallelism, distributing the model across multiple devices; data parallelism, splitting the training data among multiple devices; or optimization algorithms that converge faster. Efficient memory management is also key, addressing the limitations of memory bandwidth and capacity. The research might propose novel architectures or training strategies specifically designed for resource efficiency. Quantization or other model compression methods are likely discussed to reduce model size, accelerating both training and inference. Ultimately, the goal of efficient training is to make LLMs more accessible and deployable by lowering the barrier to entry in terms of resources and time required.
Length Generalization#
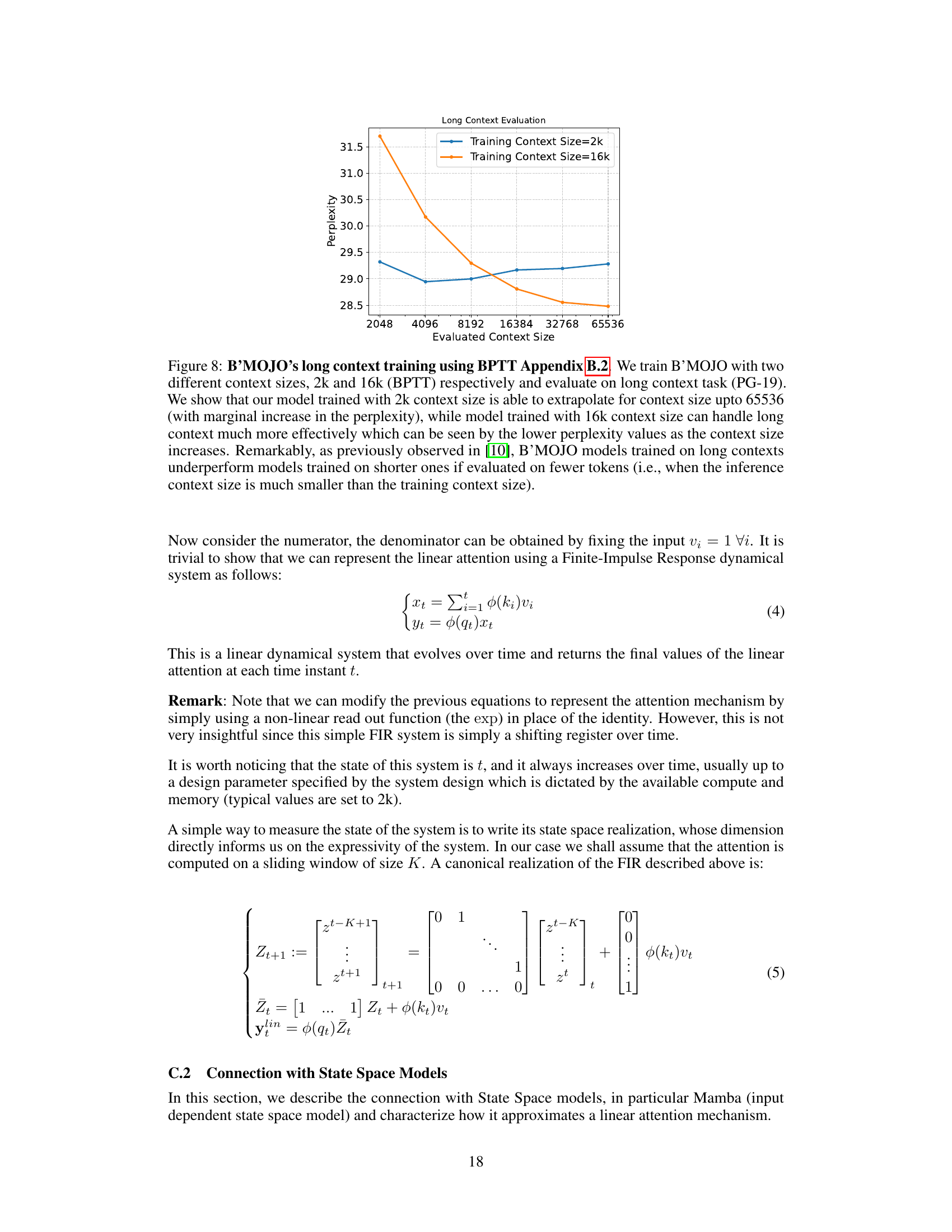
The concept of ‘Length Generalization’ in the context of sequence models is crucial. It explores the ability of a model trained on sequences of a specific length to perform well on sequences of different lengths, especially longer ones. Successful length generalization suggests that the model has learned underlying patterns and relationships that are not solely dependent on the specific length of the training data. This is a significant challenge because many sequence models, like transformers, rely on positional encodings or fixed-length attention mechanisms, making them sensitive to sequence length. The paper likely investigates how the proposed B’MOJO architecture addresses this challenge, potentially through its hybrid approach combining eidetic and fading memory. This combination could allow the model to efficiently handle both short-term context and long-term dependencies, leading to better generalization across different sequence lengths. The findings related to length generalization probably demonstrate the effectiveness of this hybrid memory system in handling longer sequences exceeding those in the training data, thus showing the model’s capability to extrapolate effectively. A strong result in length generalization would be a key advantage over traditional sequence models, showing superior robustness and adaptability.
More visual insights#
More on figures
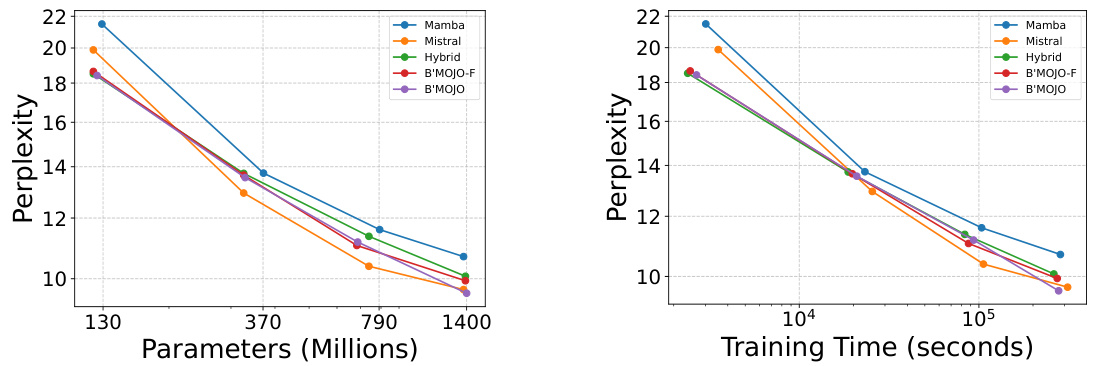
This figure shows the scaling laws of B’MOJO and other language models, comparing perplexity and training time as a function of the number of parameters. B’MOJO demonstrates faster training and comparable or better perplexity than other models, indicating efficient use of resources and a potential for continued improvement with scale.

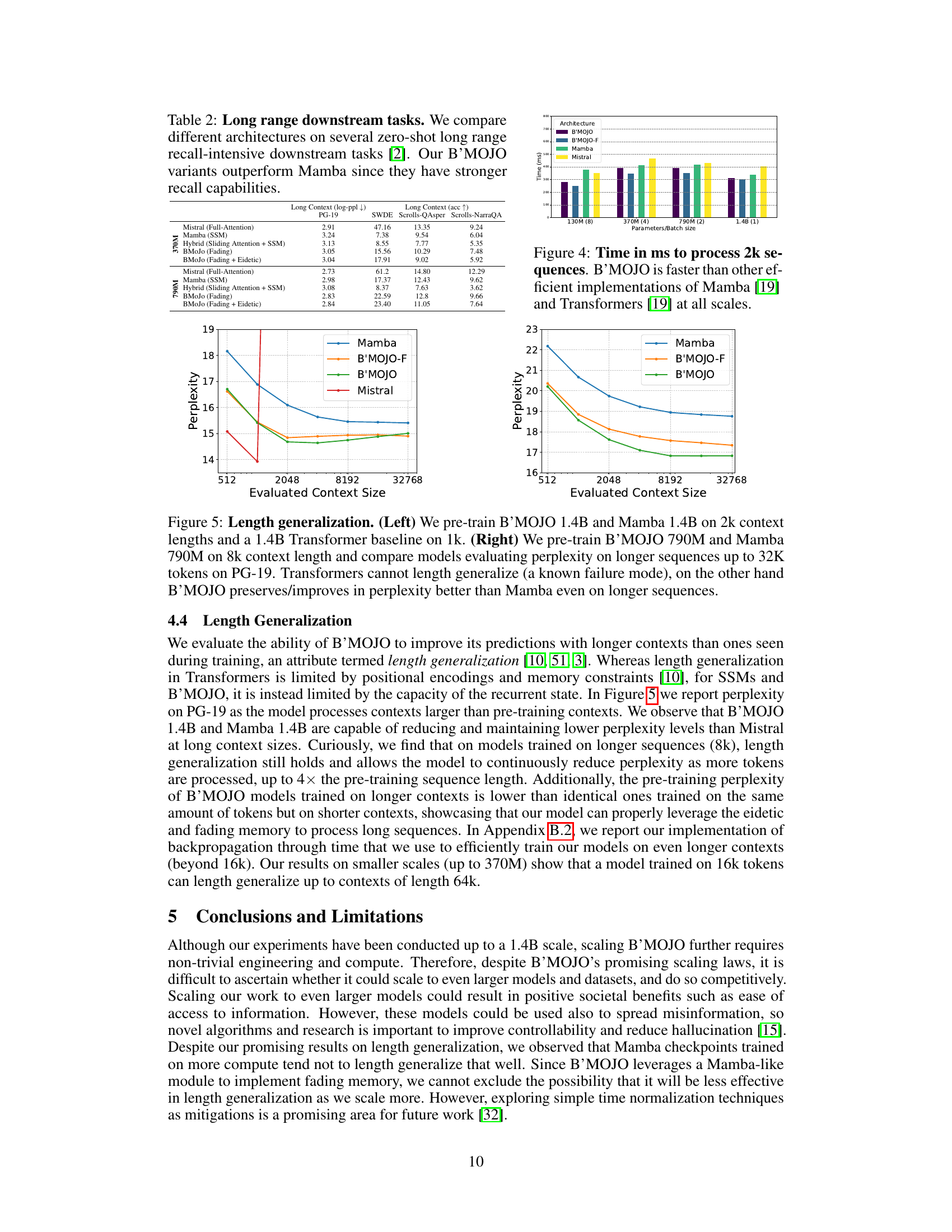
This figure compares the inference time of B’MOJO with other state-of-the-art models such as Mamba and Mistral across different scales (model sizes). The results demonstrate that B’MOJO is significantly faster for processing 2k sequences compared to these other models, showcasing its efficiency in terms of inference speed. The speed advantage is consistent across various model sizes.
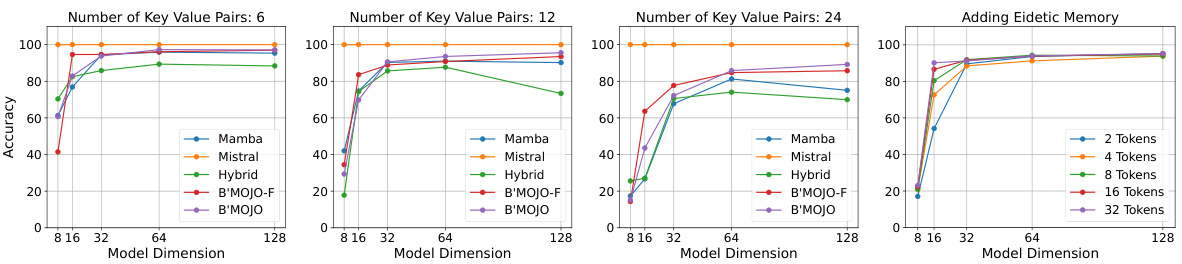
The figure shows the results of an experiment comparing different models’ performance on the Multi-Query Associative Recall (MQAR) task. The experiment varied the model’s memory capacity (SSM state, eidetic memory, KV cache) and assessed accuracy. B’MOJO and B’MOJO-F consistently outperformed other models, demonstrating the effectiveness of their combined eidetic and fading memory. An ablation study also confirmed that increasing eidetic memory size improved recall until saturation.

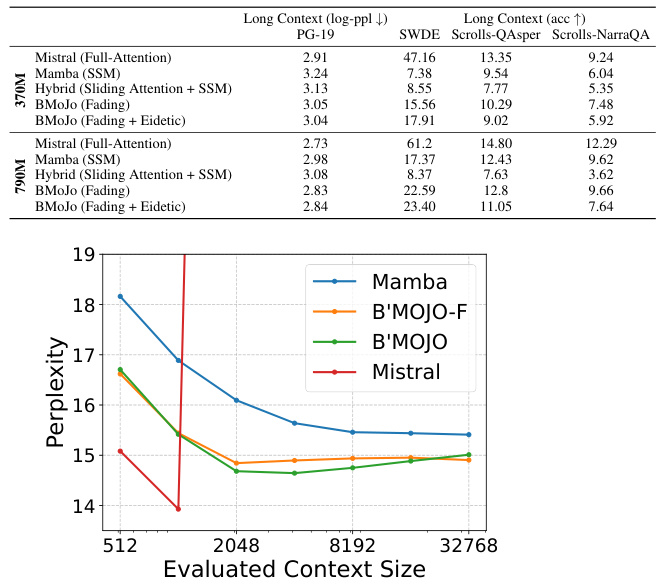
This figure shows the results of evaluating the length generalization capabilities of B’MOJO and Mamba models. The left panel shows the pre-training setup, while the right panel demonstrates the perplexity results on the PG-19 dataset as the evaluated context size increases, up to 32K tokens. The key finding is B’MOJO’s ability to maintain or improve perplexity as the context length extends beyond the training context length, unlike Transformers which exhibit a known failure mode in this regard, and unlike Mamba, which performs worse on longer sequences.
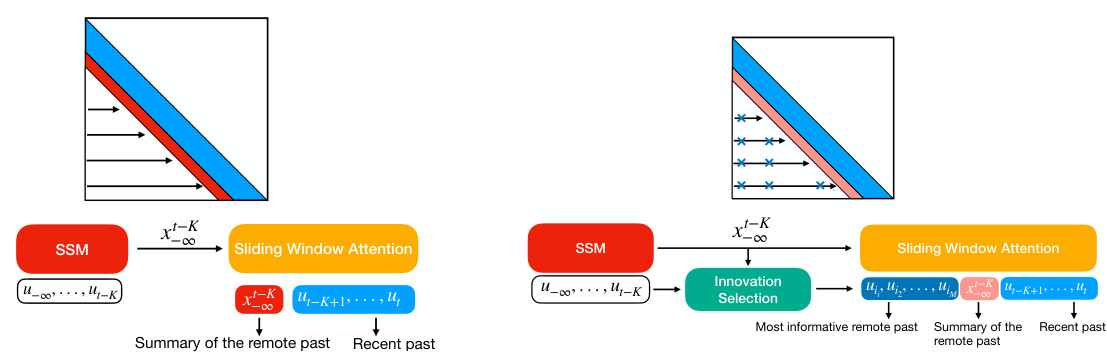
This figure illustrates the memory management mechanisms of the B’MOJO model. The left panel shows a high-level illustration of the B’MOJO layer, highlighting its components: sliding window attention, eidetic memory, and fading memory. The right panel provides a detailed breakdown of B’MOJO’s realization, explaining how the fading memory (computed by a state-space model) and eidetic memory (tokens selected based on an innovation test) are combined to perform inference. The innovation test helps identify tokens that are difficult to predict and appends them to the eidetic memory.

This figure illustrates B’MOJO’s memory management system. The left panel shows a single B’MOJO layer, highlighting the interaction between the SSM (red), eidetic memory (blue), fading memory (orange), and sliding window attention (yellow). The right panel provides a broader view of the overall B’MOJO realization, emphasizing the innovation selection process for determining which tokens are stored in eidetic memory based on their predictability.
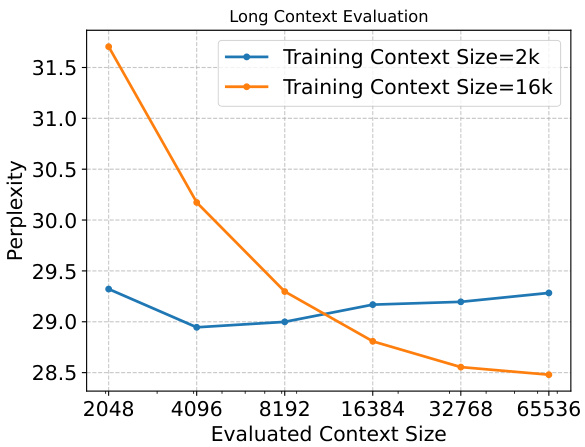
This figure shows the perplexity of B’MOJO models trained with different context lengths (2k and 16k) when evaluated on various context lengths (up to 65536 tokens). It demonstrates the model’s ability to generalize to longer context lengths than it was trained on (length generalization), particularly with the model trained on 16k context.
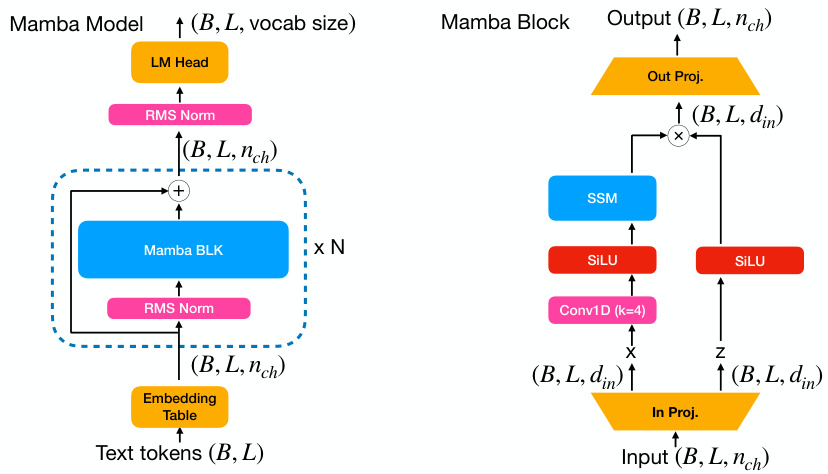
This figure illustrates B’MOJO’s memory management. The left panel shows the architecture of a single B’MOJO layer, highlighting the interaction between the sliding window attention, eidetic memory (for storing important tokens), and fading memory (represented by the SSM’s state). The right panel provides a schematic of the entire B’MOJO realization, demonstrating how the short-term eidetic memory, long-term fading memory, and asynchronous retrieval work together to improve the model’s ability to access information from both the recent and distant past. The innovation selection mechanism is key to deciding which tokens should be stored in the eidetic memory for later retrieval.
This figure illustrates the memory management mechanism of the B’MOJO model. The left panel shows a high-level overview of the B’MOJO layer, which combines eidetic and fading memory using a sliding window attention mechanism. The right panel provides a more detailed breakdown of B’MOJO’s realization, explaining how the fading and eidetic memory components work together to achieve long-range dependency and high recall capabilities.
More on tables

This table compares the performance of B’MOJO against several baseline models (Mistral, Mamba and Hybrid models) on several zero-shot downstream tasks. The results show that B’MOJO achieves comparable perplexity to Mistral and outperforms Mamba on accuracy metrics, especially on larger model sizes (1.4B).

This table presents the results of four different synthetic tasks performed on two different model sizes (2-layer and 130M) to evaluate the performance of B’MOJO against other models. The tasks are designed to test different aspects of memory recall and accuracy under varying levels of noise and complexity.
Full paper#