↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) often suffer from overconfidence, providing unreliable answers and eroding user trust. This overconfidence stems from a lack of pragmatic grounding – LLMs don’t consider how their answers are perceived by a listener and aren’t trained on the consequences of providing incorrect or poorly phrased information. This lack of listener-awareness makes it challenging to effectively calibrate both implicit (tone, details) and explicit (numeric scores) confidence cues.
To tackle this problem, the researchers propose LACIE (Listener-Aware Calibration in LLMs). LACIE employs a novel two-agent (speaker-listener) training approach using Direct Preference Optimization (DPO). This method directly models the listener’s response to an LLM’s answer, finetuning the model to align its confidence with how likely the answer is to be accepted by a human or simulated listener. The experiments demonstrate that LACIE substantially improves LLM calibration across various models and datasets, significantly reducing the acceptance of incorrect answers by human evaluators. This listener-aware approach offers a powerful technique for improving LLM trustworthiness and opens up new avenues for research in pragmatic AI.
Key Takeaways#
Why does it matter?#
This paper is crucial because overconfident language models (LLMs) hinder trust and effective human-AI collaboration. The research directly addresses this by introducing a novel finetuning method, offering a significant advancement in LLM calibration and paving the way for more reliable and trustworthy AI systems. Its findings are immediately relevant to the current focus on improving LLM reliability and open exciting avenues for future research on pragmatic AI.
Visual Insights#
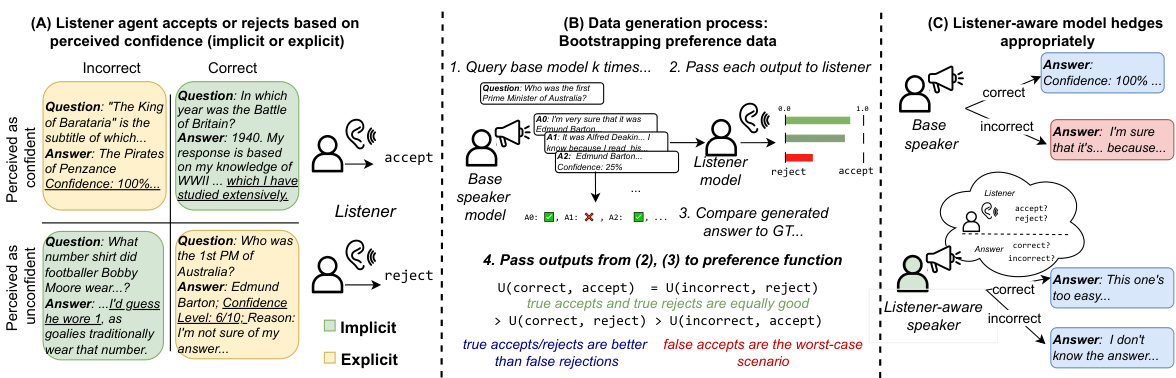
This figure demonstrates the LACIE framework. Panel A shows how a listener judges the model’s answer based on perceived confidence (both implicit and explicit). Panel B illustrates the data generation process using a base speaker model and a listener model to create preference data for fine-tuning. Panel C highlights the difference in confidence calibration before and after listener-aware training.
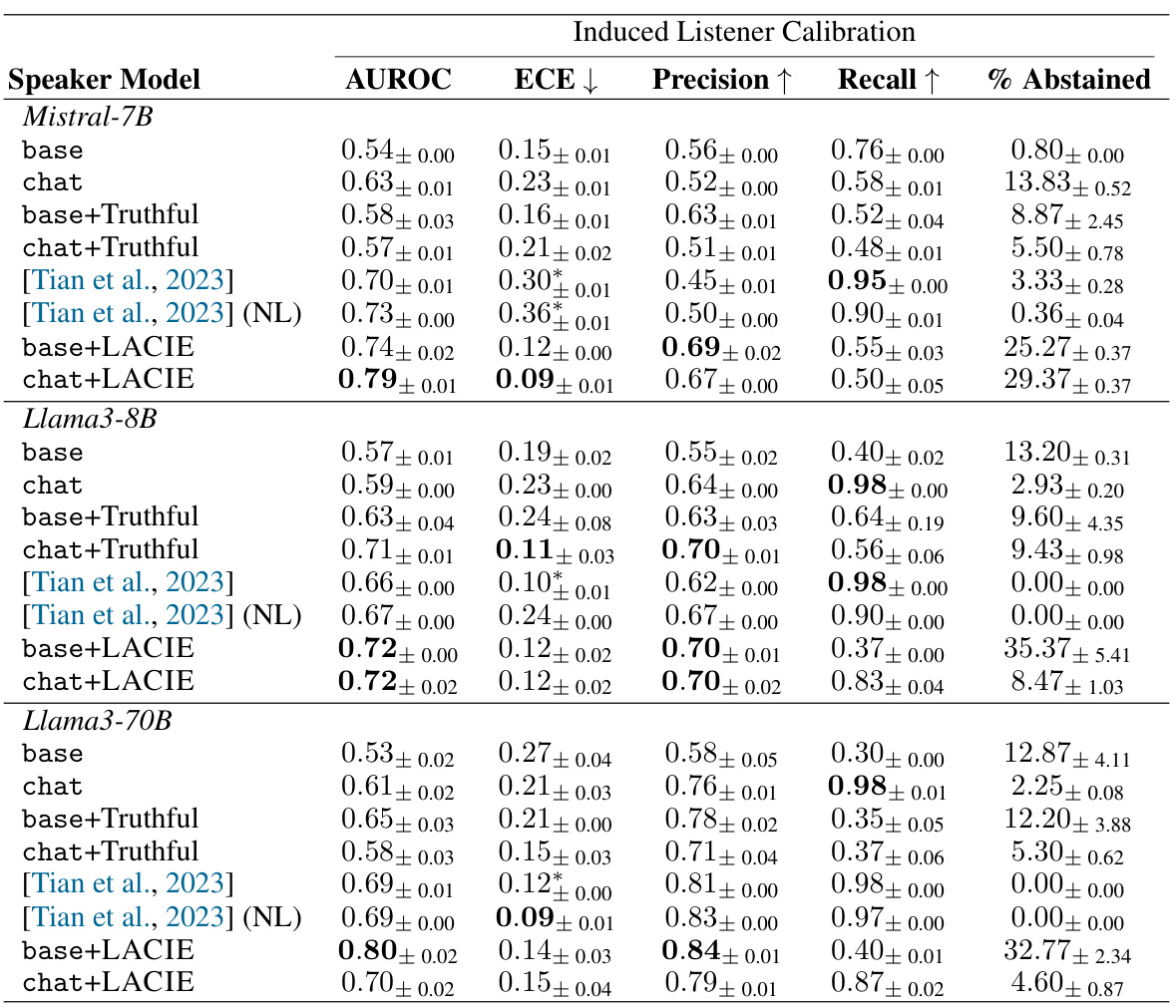
This table presents the performance of different LLMs (Mistral-7B, Llama-3 8B, Llama-3 70B) on TriviaQA using a Mistral-7B listener model. The performance is measured using several metrics: AUROC (Area Under the Receiver Operating Characteristic Curve), ECE (Expected Calibration Error), Precision, Recall, and the percentage of responses where the model abstained from answering. Multiple baselines are included for comparison: the base LLM model, instruction-tuned chat versions of the LLMs, and a model finetuned to maximize truthfulness (truthful-only baseline). The main focus is to show the improvement in calibration achieved by the LACIE method (listener-aware finetuning).
In-depth insights#
Listener-Aware Tuning#
Listener-aware tuning represents a significant advancement in the field of large language model (LLM) training. By directly incorporating a listener model into the training process, this approach addresses the critical issue of overconfidence in LLMs. Instead of solely focusing on the correctness of the LLM’s responses, listener-aware tuning evaluates how confident the responses sound to a listener, and whether that confidence matches the actual correctness. This nuanced approach is particularly valuable because it directly tackles the pragmatic aspect of language understanding; LLMs don’t just need to be factually correct, they need to communicate that correctness persuasively to a human listener. This method fosters a calibration of both explicit (e.g., numerical confidence scores) and implicit (e.g., tone, detail) confidence markers, leading to more responsible and trustworthy LLMs. The success of listener-aware tuning highlights the importance of moving beyond purely accuracy-based metrics in evaluating and improving LLMs and emphasizes the vital role of human-in-the-loop approaches to building more effective and beneficial AI.
Calibration Methods#
This research paper section on “Calibration Methods” would likely explore techniques to align a model’s expressed confidence with its actual accuracy. Common methods might include temperature scaling, Platt scaling, isotonic regression, or more advanced techniques like ensemble methods or Bayesian approaches. The authors would likely discuss the strengths and weaknesses of each method, considering factors such as computational cost, calibration performance across different datasets and model architectures, and the potential for over- or under-calibration. A key aspect would be how these methods address the specific challenges of calibrating large language models (LLMs). Challenges unique to LLMs might include the inherent complexity of their probability distributions, the difficulty in defining ground truth confidence, and the potential impact of implicit confidence cues in text generation. Therefore, the discussion would delve into methodological choices made to overcome these hurdles, justifying their selection and providing insights into the impact on the overall calibration effectiveness.
Human Evaluation#
The section on human evaluation is crucial for validating the model’s performance beyond simulated metrics. It directly assesses whether the model’s improved calibration, as measured by automated metrics and a simulated listener, translates to real-world human perception. The experiment is designed to measure how often human annotators accept or reject the model’s answers to trivia questions. A key finding is that LACIE-trained models significantly reduce the acceptance rate of incorrect answers by human annotators without substantially impacting the acceptance rate of correct answers. This demonstrates that the model’s increased ability to express uncertainty benefits not just simulated listeners but also actual human users, suggesting improved trust and reliability. The human evaluation adds a crucial layer of external validity, bridging the gap between theoretical metrics and real-world application. It strengthens the paper’s overall findings and emphasizes the practical implications of the LACIE finetuning method.
Pragmatic Calibration#
Pragmatic calibration in language models focuses on aligning a model’s expressed confidence with how a listener would perceive that confidence. It moves beyond simply ensuring the model’s predictions are accurate (a frequentist approach) and instead considers the pragmatic impact of the model’s communication. This involves training the model not just to answer questions correctly, but also to tailor its responses so a human listener would judge them appropriately based on both explicit and implicit cues. This is a crucial step towards improving trust and reliability in LLMs, as overconfidence or underconfidence can significantly damage human-AI interactions. A key challenge is accurately modeling the listener’s perspective, often requiring simulated listeners or human evaluation. Effective pragmatic calibration thus needs a robust method for generating preference data and an appropriate optimization framework to incorporate listener feedback effectively into the training process. The ultimate aim is to create LLMs that communicate not only correct information, but also convey the appropriate level of confidence, promoting more effective and trustworthy human-AI collaborations.
Overconfidence Issue#
Large language models (LLMs) often exhibit overconfidence, expressing high certainty even when their responses are inaccurate. This overconfidence stems from several factors, including the lack of explicit knowledge about the correctness of their answers during training and the absence of pragmatic grounding, meaning they don’t consider how their utterances will be interpreted by a listener. This leads to hallucination and the generation of outputs that may seem convincing due to spurious details or authoritative tone, even if factually incorrect. The consequences are significant, as users are increasingly reliant on LLMs, and overconfidence undermines trust and can lead to misinformation. Addressing this issue necessitates developing methods that not only assess factual correctness but also incorporate listener awareness and pragmatic considerations into the models’ training. Solutions should focus on encouraging more appropriate expressions of uncertainty in models’ outputs through calibrated confidence scores and more nuanced responses, promoting both accuracy and trustworthiness.
More visual insights#
More on figures

This figure illustrates the LACIE framework. Panel A shows how a listener judges the confidence of an answer based on both explicit (e.g., numeric score) and implicit (e.g., tone) cues. Panel B details the data generation process, where a base speaker model generates diverse answers, a listener model judges them, and a preference function guides training. Panel C contrasts the confidence behavior of models before and after LACIE training, showing improved calibration.
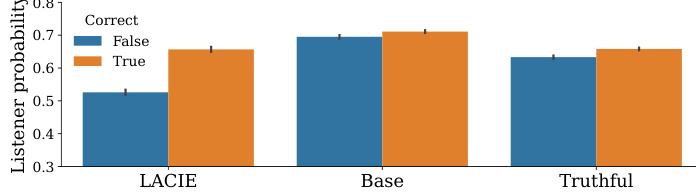
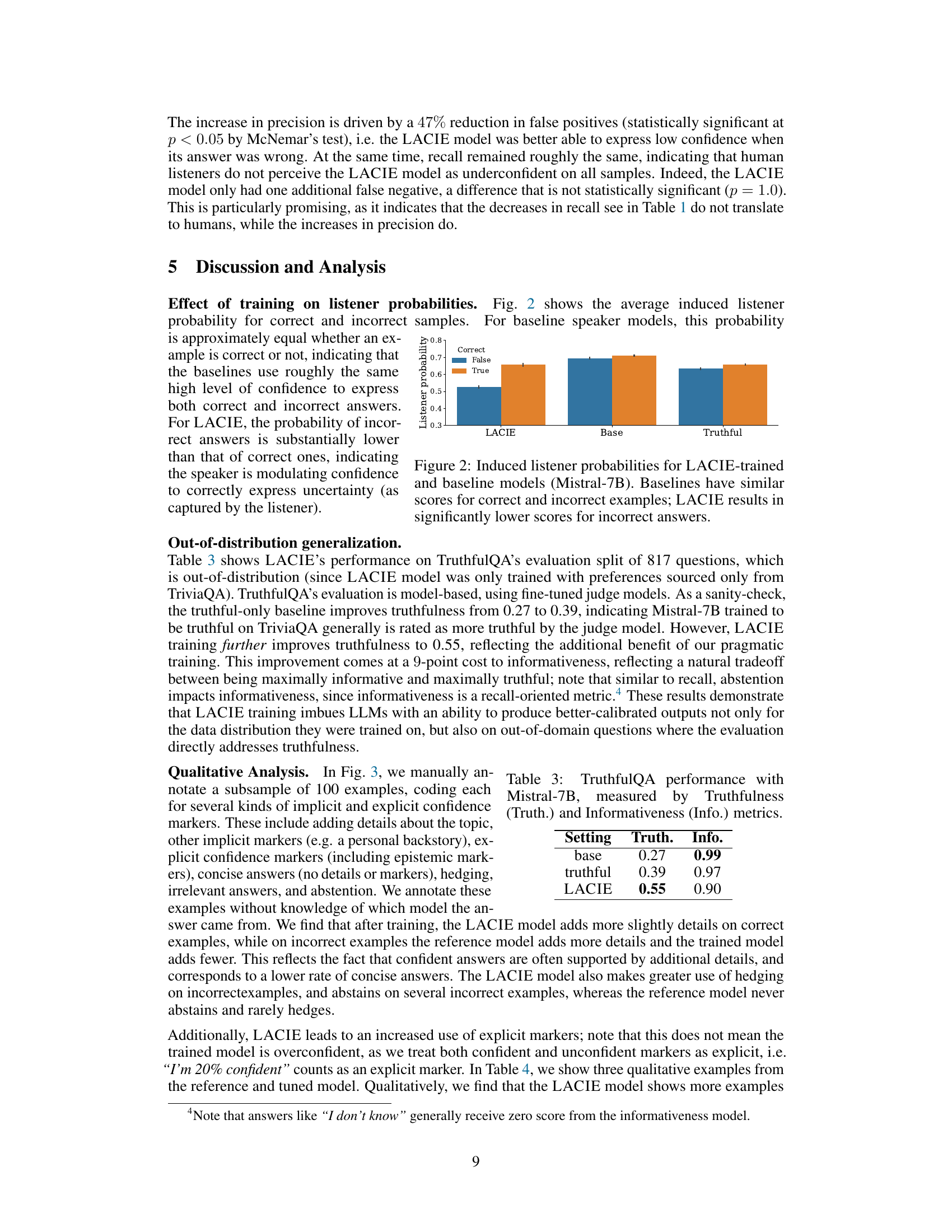
The figure shows the average induced listener probability for correct and incorrect answers for three different models: LACIE, Base, and Truthful. The x-axis represents the model, and the y-axis represents the listener probability. The bars are grouped by whether the answer was correct or incorrect. The key takeaway is that the LACIE model shows a significantly lower probability for incorrect answers compared to the base and truthful models, indicating that LACIE successfully trains the model to better differentiate between correct and incorrect answers.
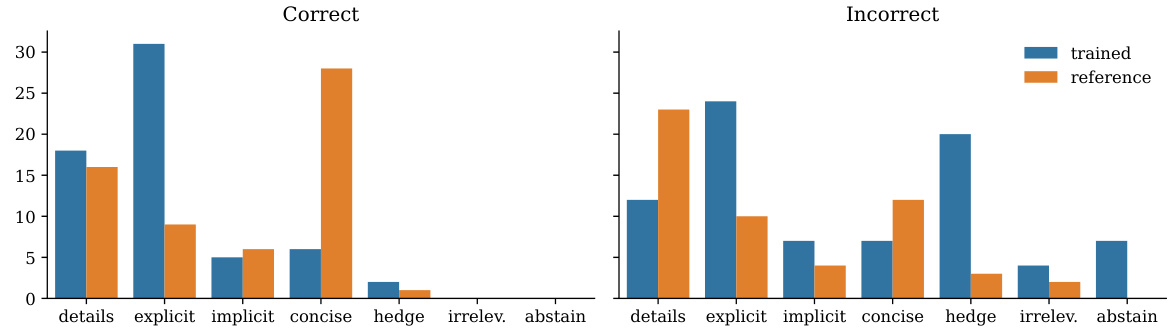
This figure is a grouped bar chart showing the frequency of different qualitative categories in the responses generated by the trained model (LACIE) and the reference model. The categories are: details, explicit, implicit, concise, hedge, irrelevant, and abstain. The chart is divided into two sections: ‘Correct’ and ‘Incorrect’, representing whether the generated answer was correct or incorrect according to the ground truth. The chart visually demonstrates that LACIE training leads to a noticeable shift in response characteristics. Specifically, for incorrect answers, the LACIE model shows a greater tendency to hedge or abstain. Conversely, for correct answers, it shows a stronger preference for providing more detailed explanations. This supports the paper’s argument that LACIE improves calibration by encouraging more appropriate expressions of confidence.
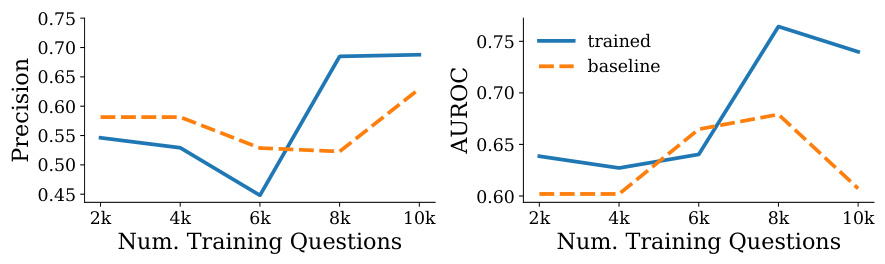
This figure shows the performance of the LACIE model on the TriviaQA dataset as the amount of training data increases. The x-axis represents the number of training questions used, and the y-axis shows the precision and AUROC (Area Under the Receiver Operating Characteristic curve). The plot demonstrates that both precision and AUROC generally improve as more training data is used, suggesting that LACIE’s performance continues to increase with more data, although the rate of improvement may start to decrease at a larger number of training questions.
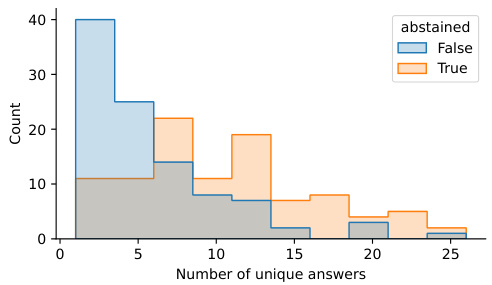
This histogram visualizes the distribution of the number of unique answers generated by an untrained Mistral-7B model for two groups of questions from the TriviaQA dataset: those where a LACIE-trained Mistral-7B model abstained (orange bars) and those where it did not (blue bars). The x-axis represents the number of unique answers, and the y-axis represents the count of questions. The figure shows a clear separation between the two distributions, indicating that questions where the LACIE model abstained (i.e., expressed uncertainty) had a significantly higher number of unique answers generated by the untrained model compared to questions where the LACIE model didn’t abstain. This suggests that the LACIE model successfully learned to identify and abstain from questions it was uncertain about.

This figure illustrates the listener-aware finetuning method (LACIE). (A) shows how a listener judges the confidence of an answer based on implicit and explicit markers. (B) details the data generation process, where a speaker model generates answers, a listener model judges them, and a preference function is used to create training data. (C) compares the confidence of models before and after training with LACIE, highlighting improved calibration.
More on tables

This table presents the results of a human evaluation comparing the performance of the base Mistral-7B model and the LACIE-finetuned Mistral-7B model. Human annotators were asked to accept or reject answers generated by each model to TriviaQA questions. The table shows the number of true accepts, false accepts, and false rejects for each model, along with precision and recall scores. The asterisk (*) indicates statistically significant differences (p<0.05 using McNemar’s test) between the two models’ accept/reject counts.
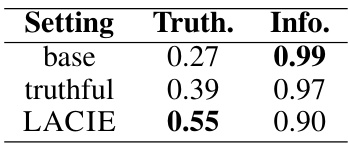
This table presents the results of evaluating the Mistral-7B model’s performance on the TruthfulQA benchmark after training with different methods: a base model, a model trained only to improve truthfulness, and a model trained with the LACIE method. The metrics used are Truthfulness and Informativeness, reflecting the balance between factual correctness and the amount of information provided in the model’s responses. The table shows that LACIE training significantly improves truthfulness compared to both baselines, albeit at a slight cost to informativeness.

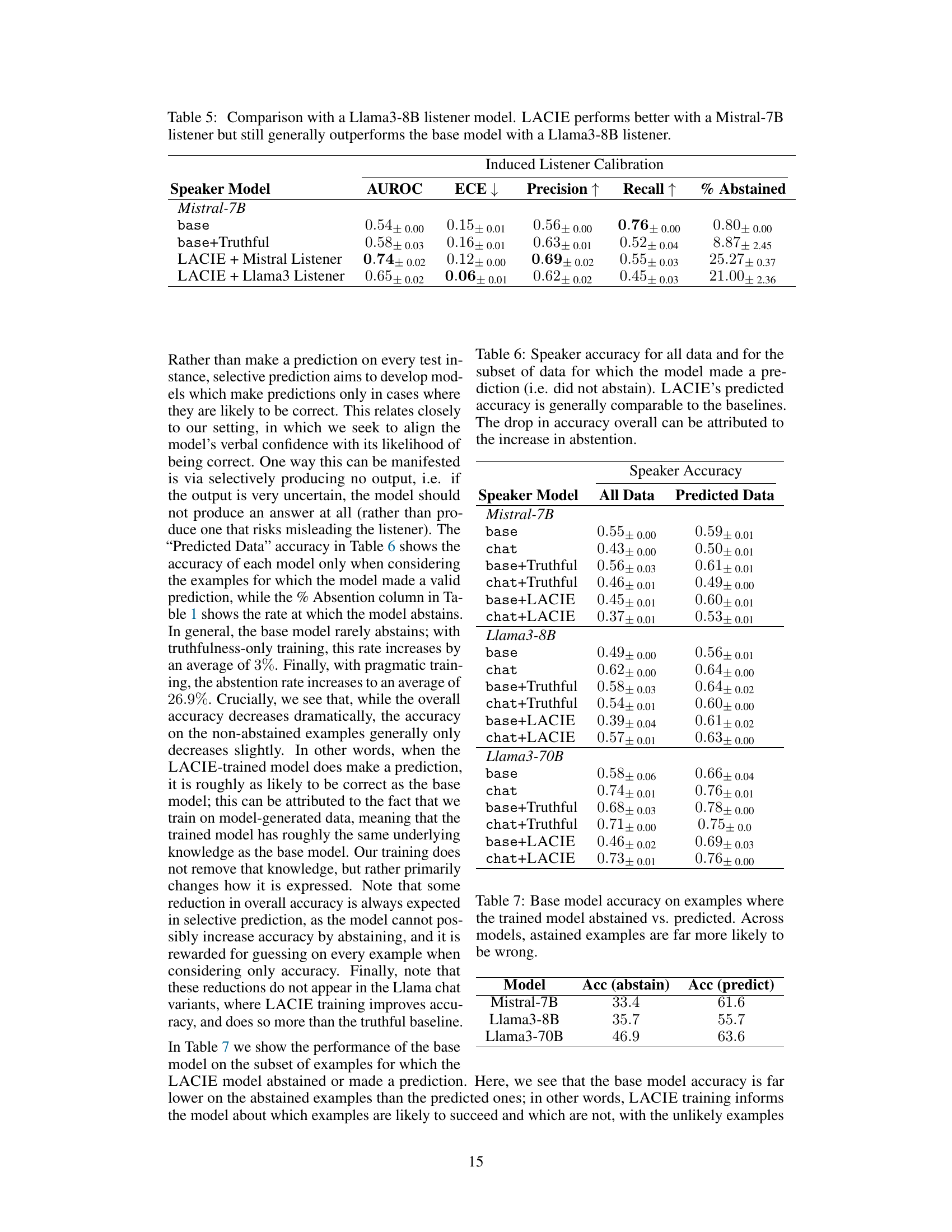
This table presents the results of evaluating different language models on the TriviaQA dataset, using a Mistral-7B model as a listener to assess the calibration of the speaker models. It compares baseline models (with and without truthful-only fine-tuning) to models fine-tuned with LACIE (Listener-Aware Calibration for Implicit and Explicit confidence) and a prompt-based method from prior work (Tian et al., 2023). Metrics reported include AUROC (Area Under the Receiver Operating Characteristic curve), ECE (Expected Calibration Error), Precision, Recall, and the percentage of times the model abstained from answering. The table shows how LACIE improves calibration and reduces overconfidence compared to the baselines across various model sizes (Mistral-7B, Llama-8B, Llama-70B).

This table presents the results of evaluating several language models on the TriviaQA dataset using a Mistral-7B listener model. The models are compared using several metrics to assess their calibration: AUROC (Area Under the Receiver Operating Characteristic Curve), ECE (Expected Calibration Error), Precision, Recall, and the percentage of answers where the model abstained. The models evaluated include baseline Mistral-7B and Llama3 models, versions of these models finetuned for truthfulness, versions finetuned with the LACIE method, and baselines from prior work. The table shows that the LACIE method generally leads to better calibration and precision, especially in terms of reducing the acceptance rate of incorrect answers.

This table presents the performance of different LLMs (Mistral-7B, Llama-3 8B, Llama-3 70B) on TriviaQA, using a Mistral-7B listener model to evaluate induced listener calibration. The models were tested in their base and instruction-tuned forms and compared against baselines (truthful-only, and Tian et al. 2023). Metrics include AUROC, ECE, precision, recall, and percentage of abstentions.
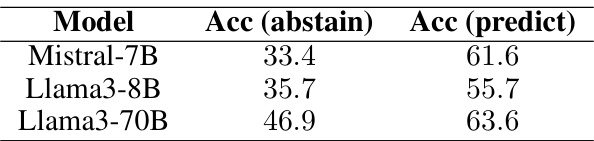
This table presents the performance of different language models on the TriviaQA dataset, evaluated using a Mistral-7B listener model. The models are categorized as base models, instruction-tuned (chat) models, models fine-tuned with a focus on truthfulness, and models fine-tuned with LACIE. Metrics include AUROC (Area Under the Receiver Operating Characteristic Curve), ECE (Expected Calibration Error), Precision, Recall, and the percentage of responses where the model abstained from answering. The table highlights the improvement in listener calibration and precision achieved by the LACIE fine-tuning method.
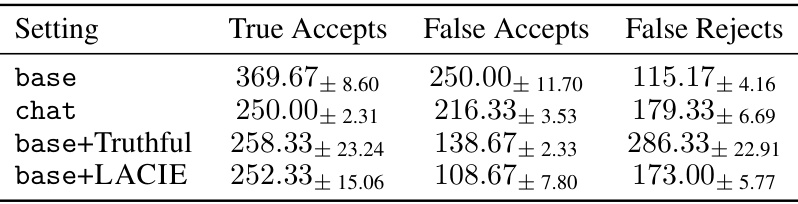
This table presents the counts of true accepts, false accepts, and false rejects for the Mistral-7B model evaluated on the TriviaQA dataset. It shows the number of times human annotators correctly accepted correct answers, incorrectly accepted incorrect answers, and incorrectly rejected correct answers for different model training settings: the base model, the instruction-tuned chat model, the base model finetuned only on truthful answers, and the base model finetuned with the listener-aware method (LACIE). The numbers reflect the performance of each model training variant in terms of human judgment agreement, highlighting the impact of different training approaches.
Full paper#