↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-video (T2V) models struggle with complex scenes involving multiple objects and dynamic changes. They often fail to accurately generate long videos or handle compositional prompts (e.g., describing objects’ relative spatial locations). This limits their ability to create realistic and coherent videos for diverse applications.
The proposed VideoTetris framework uses spatio-temporal compositional diffusion to address these issues. It manipulates attention maps to precisely follow complex textual descriptions. Furthermore, enhanced video preprocessing and a reference frame attention mechanism ensure consistency and realism in the generated videos. Experiments demonstrate significant improvements over existing models in both short and long-video generation, especially for complex scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances text-to-video generation, especially for complex scenes. The proposed method, VideoTetris, tackles the limitations of existing models by enabling compositional generation, leading to more coherent and realistic videos. This opens up new avenues for research in long-video generation, handling dynamic object changes, and improving video realism.
Visual Insights#

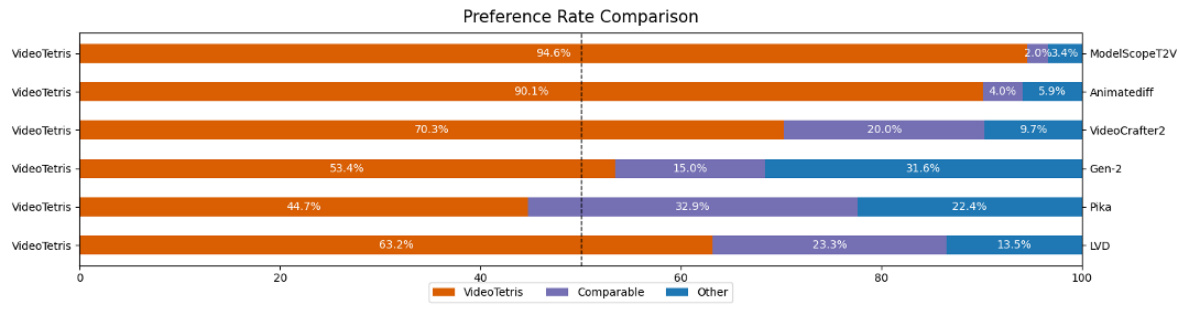
This figure shows a comparison of the results of Video Generation with Compositional Prompts and Long Video Generation with Progressive Compositional Prompts between VideoTetris and other state-of-the-art methods. The results demonstrate that VideoTetris shows superior performance in terms of precise adherence to position information, diverse attributes, interaction between objects, consistent scene transitions, and high motion dynamics in compositional video generation. The figure consists of two parts: (a) shows short videos generated with compositional prompts, comparing multiple models’ ability to generate videos correctly based on the descriptions; (b) shows long videos with progressive prompts, showing the models’ ability to change scenes seamlessly following the descriptions.
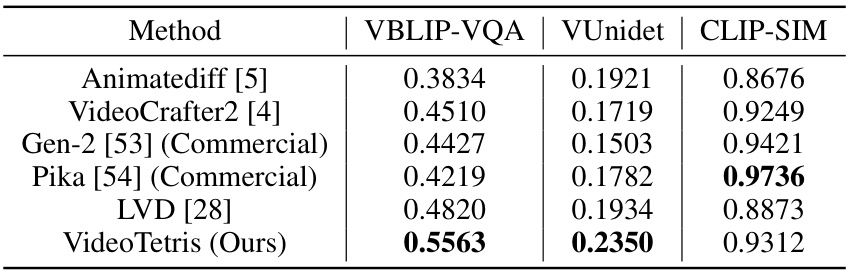
This table presents a quantitative comparison of different text-to-video (T2V) models on video generation with compositional prompts. The models are evaluated using three metrics: VBLIP-VQA, VUnidet, and CLIP-SIM. VBLIP-VQA and VUnidet measure the accuracy and detail of the generated videos concerning the compositional aspects described in the prompts. CLIP-SIM measures the visual consistency of the generated video sequence. The table shows that VideoTetris (Ours) achieves the highest scores across all three metrics, outperforming existing methods.
In-depth insights#
Compositional Diffusion#
Compositional diffusion, in the context of text-to-video generation, presents a paradigm shift from traditional diffusion models. Instead of treating a video as a monolithic entity, it breaks down the generation process into constituent components, allowing for finer-grained control and more complex scene constructions. This approach leverages the ability to compose individual elements, such as objects and their interactions, according to textual descriptions. The key advantage lies in enabling the creation of videos with multiple interacting objects and dynamic changes in object number, something that previously challenged single-stage diffusion models. This requires sophisticated spatial and temporal modeling to accurately represent the relationship between objects at various points in time. This is achieved through techniques like manipulating attention maps of diffusion models, which allows control of how different objects are combined within a scene and across time frames. Enhanced video preprocessing techniques also play a significant role; providing data with clearer motion dynamics and better prompt understanding to improve the accuracy and realism of the generated videos. Overall, compositional diffusion holds the key to achieving more complex, nuanced, and dynamic video generation, surpassing the limitations of simpler, holistic approaches.
Enhanced Preprocessing#
Enhanced preprocessing in the context of video generation models focuses on improving the quality and characteristics of training data to better support the model’s learning process. This often involves techniques to boost motion dynamics, ensuring the model can accurately capture and represent movement in generated videos. Improving prompt semantics is another key aspect; enriching the textual descriptions associated with videos, leading to a deeper understanding of the scene’s composition and the relationships between objects. Furthermore, consistency regularization methods may be applied, aiming to maintain a stable, coherent representation throughout the video generation process, particularly in long-form or complex scenes, reducing artifacts and inconsistencies. The choice of preprocessing techniques will depend largely on the specific challenges of the model architecture and the nature of the target dataset. By addressing these aspects of the training data, enhanced preprocessing empowers video generation models to produce higher-quality, more realistic, and semantically consistent results. The ultimate aim is to bridge the gap between raw video data and the model’s ability to effectively understand and leverage information contained within to create compelling, coherent video outputs.
Reference Frame Attn#
The proposed “Reference Frame Attention” mechanism is a crucial innovation for maintaining visual consistency in long-video generation. It directly addresses the challenge of generating temporally coherent videos where objects are added or removed throughout the sequence. Instead of relying on indirect methods like pre-trained image encoders, which may not perfectly align with the task of preserving consistent object features, the method leverages an auto-encoder to generate frame embeddings, ensuring spatial consistency in the latent space. This approach, coupled with a trained convolutional layer, calculates cross-attention between the current frame’s features and those from a designated reference frame (often the initial frame where the object appears), enhancing the model’s ability to track and maintain the consistency of object appearances. This method is particularly important for handling dynamic changes in scenes typical of compositional video generation.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, a well-designed ablation study provides crucial insights into the effectiveness and relative importance of different design choices. For example, in a deep learning model, it might involve removing layers, changing activation functions, or altering regularization techniques. By comparing the performance of the complete model with those of the modified versions, researchers can determine which components are most critical for achieving desired outcomes and which are redundant or even detrimental. The results of ablation studies are invaluable for understanding the model’s inner workings, guiding future improvements, and providing a strong rationale for the chosen design. They help isolate the impact of individual elements, validating that the observed results are indeed attributed to the specific modifications and not just by chance. However, poorly designed ablation studies can be misleading. Carefully considering which components to ablate, and how to interpret the results, are crucial aspects of a strong ablation study. For example, removing one component might unintentionally affect the functionality of another. Thus, rigorous experimental design and careful interpretation of results are essential to derive meaningful conclusions from ablation studies.
Future Directions#
Future research directions for compositional text-to-video generation could explore enhanced control over object interactions and temporal dynamics. Current methods often struggle with complex relationships between multiple objects. More sophisticated techniques are needed to precisely orchestrate object behavior, enabling complex narratives. Improving the handling of long-form video generation is crucial, as current models face challenges scaling to extended durations. This involves addressing issues of coherence, consistency, and computational cost for longer sequences. Addressing limitations in training data, including the need for more diverse and intricate scenes and improved text-video pairings, will be crucial for improved model performance. Finally, investigating the explainability and controllability of the generation process is critical. Techniques for visualizing and analyzing the model’s internal states would allow for debugging and refinement of compositional processes, and mechanisms for direct manipulation of generated content would facilitate greater creative control.
More visual insights#
More on figures

This figure demonstrates the superior performance of VideoTetris in comparison to other state-of-the-art methods. Part (a) shows VideoTetris accurately composing multiple objects with various attributes and relationships while maintaining consistent positional information in short videos. Part (b) highlights VideoTetris’ ability to smoothly integrate new objects and attributes in long videos that progress with changing scene descriptions, showcasing the consistent scene transitions and higher motion dynamics. It contrasts VideoTetris results with those from other methods, showing failures of these methods to manage the complexity of multiple objects and dynamic changes.

This figure illustrates the architecture of the VideoTetris model. It shows the different components involved in generating videos from text prompts. The model takes a text prompt as input. It uses a pre-trained text-to-video model and combines it with a Spatio-Temporal Compositional module to enable the generation of videos with multiple objects. A ControlNet branch allows for auto-regressive long video generation. A Reference Frame Attention mechanism enhances the consistency and coherence of the generated videos.
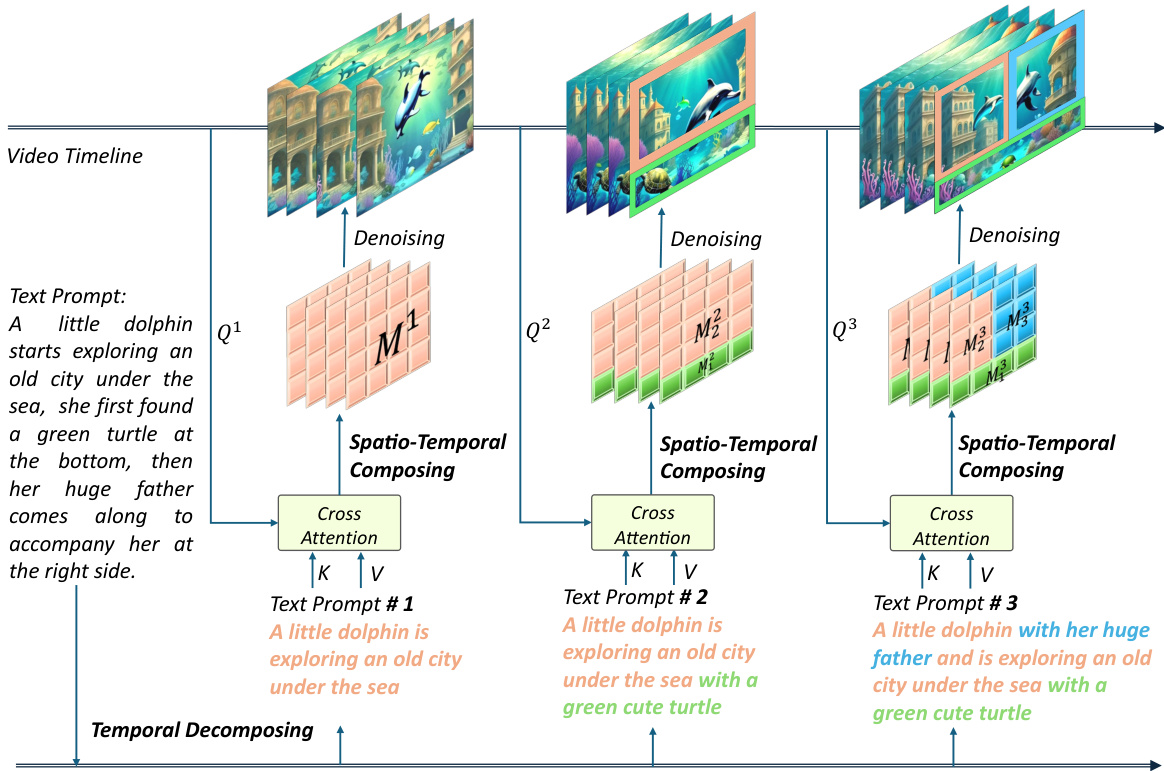
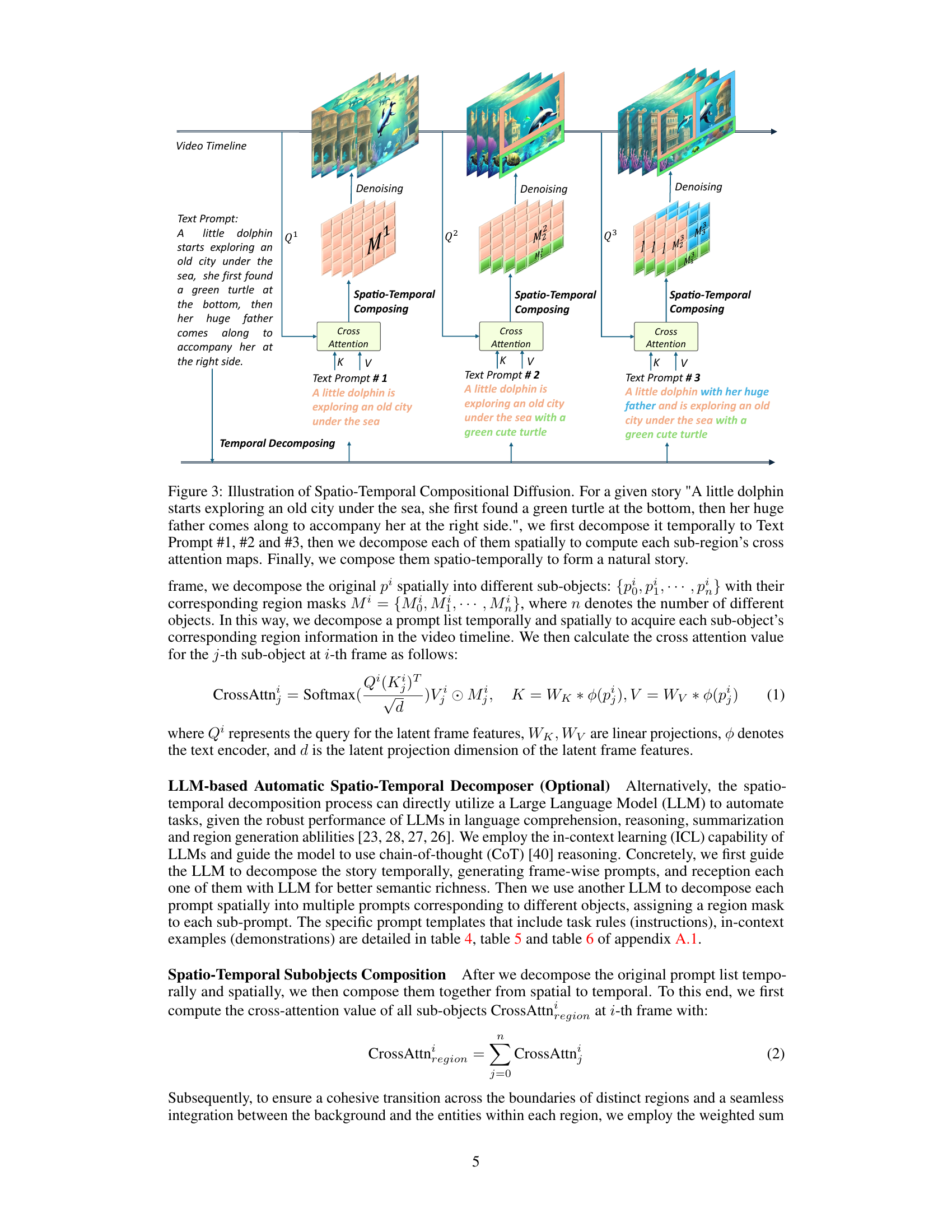
This figure illustrates the process of Spatio-Temporal Compositional Diffusion, a core component of the VideoTetris framework. It starts by temporally decomposing a given story into three parts, representing different stages of the narrative. Each of these temporal segments is further spatially decomposed to identify individual objects or sub-regions within the scene. Cross-attention maps are then computed for each sub-region, capturing the relationships between different objects. Finally, these maps are composed spatio-temporally to generate the complete video, ensuring a coherent and natural narrative flow.

This figure showcases example videos generated by VideoTetris and other state-of-the-art models for two tasks: short video generation with compositional prompts and long video generation with progressive compositional prompts. Part (a) compares the results for prompts involving multiple objects with spatial relationships (e.g., ‘A heroic robot on the left and a magical girl on the right are saving the day.’). Part (b) shows results for prompts describing dynamic changes in the scene across multiple frames (e.g., ‘A handsome young man is drinking coffee on a wooden table’ progressing to ‘A handsome young man and a beautiful young lady on his left are drinking coffee on a wooden table.’). The comparison highlights that VideoTetris better manages complex spatial and temporal relationships compared to other models.

The figure compares the performance of three different models (FreeNoise, StreamingT2V, and VideoTetris) in generating long videos based on progressive compositional prompts. The prompt starts with ‘A brave young knight is journeying through a forest’ and then transitions to ‘A brave young knight and a wise wizard are journeying through a forest.’ The figure shows that VideoTetris is able to generate a more natural and coherent video sequence, with smooth transitions and consistent visual quality, compared to the other two models which struggle with maintaining consistent content and motion throughout the video.

This ablation study compares the performance of three models: the original StreamingT2V, VideoTetris without Reference Frame Attention (RFA), and VideoTetris with RFA. The goal is to demonstrate the impact of the RFA module on the quality and consistency of generated videos. The figure showcases frames from videos generated by each model, using the same prompt: ‘Close flyover over a large wheat field in the early morning sunlight.’ By visually comparing the output of the three models, one can observe how the RFA module enhances the overall quality and consistency of the results, especially in terms of color uniformity and detail preservation across frames.
This figure showcases the qualitative results of VideoTetris compared to other state-of-the-art models for both short and long video generation using compositional prompts. Part (a) demonstrates the superior composition of objects with distinct attributes and spatial relationships in short videos. Part (b) highlights the consistent scene transitions and high motion dynamics maintained by VideoTetris in long videos with progressive compositional prompts, compared to other methods that show inconsistencies or low motion dynamics.

This figure shows the qualitative results of VideoTetris compared to other state-of-the-art methods on generating videos from compositional prompts. (a) shows the comparison of short videos with multiple objects specified in a single prompt (e.g., ‘A heroic robot on the left and a magical girl on the right are saving the day.’) and (b) shows the comparison on long videos with progressive compositional prompts where the scene and objects change over time (e.g., ‘A handsome young man is drinking coffee on a wooden table. —> (transitions to) A handsome young man and a beautiful young lady on his left are drinking coffee on a wooden table.’). VideoTetris demonstrates superior results by generating videos with precise adherence to positional information and temporal relationships between objects while showcasing interactions between objects and more complex motion dynamics.
More on tables
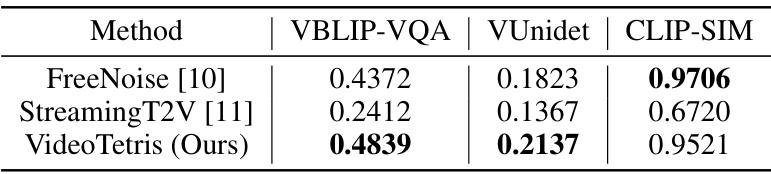
This table presents a quantitative comparison of three different methods for long video generation with progressive compositional prompts. The methods compared are FreeNoise [10], StreamingT2V [11], and the authors’ proposed VideoTetris. The metrics used for comparison are VBLIP-VQA, VUnidet, and CLIP-SIM. Higher scores indicate better performance.

This table presents a quantitative comparison of the ablation study conducted on VideoTetris. It compares the performance of the full VideoTetris model against versions without the Reference Frame Attention component and against the baseline methods FreeNoise and Streaming T2V. The metrics used for comparison are MAWE (Motion-Aware Weighted Error), CLIP (CLIPScore), AE (Attribute Error), and CLIP-SIM (CLIP Similarity). Lower MAWE and higher CLIP, AE, and CLIP-SIM scores indicate better performance.

This table presents the results of ablation studies conducted to evaluate the effectiveness of different components of the proposed Spatio-Temporal Compositional Diffusion method. It compares the performance of the VideoTetris model with variations in the decomposition and composition methods, using metrics such as VBLIP-VQA, VUnidet, and CLIP-SIM. The results highlight the importance of the proposed decomposition and composition strategies for achieving state-of-the-art performance in compositional video generation.

This table lists the hyperparameters used in the VideoTetris model. It is divided into three sections: Dynamic-Aware Data Filtering, Diffusion Training, and Reference Frame Attention. Each section details specific parameters, such as thresholds for optical flow scores, the type of noise scheduler used during diffusion training, and the dimensions of convolutional layers within the reference frame attention module. These hyperparameters are crucial for controlling the behavior and performance of the VideoTetris model.
Full paper#