↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many existing 3D object detectors are considered “black boxes,” lacking interpretability, hindering trust and hindering debugging efforts. Previous approaches mainly focus on image-based models and are unsuitable for point cloud data. This creates a critical need for methods that can explain 3D detectors’ decisions.
This paper introduces FFAM, a novel method that generates high-quality visual explanations for 3D detectors. FFAM utilizes non-negative matrix factorization to identify and aggregate important features, then refines these explanations using object-specific gradients and voxel upsampling for better visualization. Evaluations on multiple datasets demonstrate that FFAM outperforms existing techniques, improving the interpretability and trustworthiness of 3D detectors.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical need for explainable AI in 3D object detection, a rapidly growing field with significant safety implications. By introducing a novel method for generating high-quality visual explanations, the research enhances trust in these complex models and unlocks new opportunities for model analysis, improvement, and debugging.
Visual Insights#

This figure shows a comparison of saliency maps generated by the proposed FFAM method and the existing OccAM method for two different 3D detectors (SECOND and CenterPoint) on two different datasets (KITTI and Waymo Open). The maps highlight the importance of different points in the point cloud for object detection. Warmer colors indicate higher importance. The green bounding boxes show the detected objects. The figure demonstrates that FFAM produces clearer and more focused saliency maps than OccAM, especially in complex scenes.

This table compares the visual explanation accuracy of four different methods (Grad-CAM, ODAM, OccAM, and FFAM) across four categories (all, car, pedestrian, and cyclist). The accuracy metric used is VEA (Visual Explanation Accuracy), a measure of how well the explanation highlights the relevant parts of the input point cloud. Higher values indicate better accuracy. The results show that FFAM significantly outperforms the other methods in terms of visual explanation accuracy.
In-depth insights#
FFAM: Visual Explanations#
The heading ‘FFAM: Visual Explanations’ suggests a focus on generating visual interpretations of a model’s decision-making process, likely within the context of 3D object detection. FFAM, as a method, probably leverages visual cues from the input data (point cloud) and internal feature maps to produce high-quality saliency maps. These maps would visually highlight the areas or features of the point cloud that are most influential in the model’s predictions. A key aspect is likely its ability to address challenges specific to point cloud data, such as sparsity and three-dimensionality, possibly through techniques like voxel upsampling or feature aggregation. The effectiveness of FFAM would be evaluated both qualitatively (through visualizations) and quantitatively (using metrics such as VEA and pointing games), comparing its performance to existing methods like Grad-CAM or OccAM. The ultimate goal is to enhance the interpretability and trustworthiness of 3D detectors by providing insightful visual explanations of their outputs.
3D Detector Analysis#
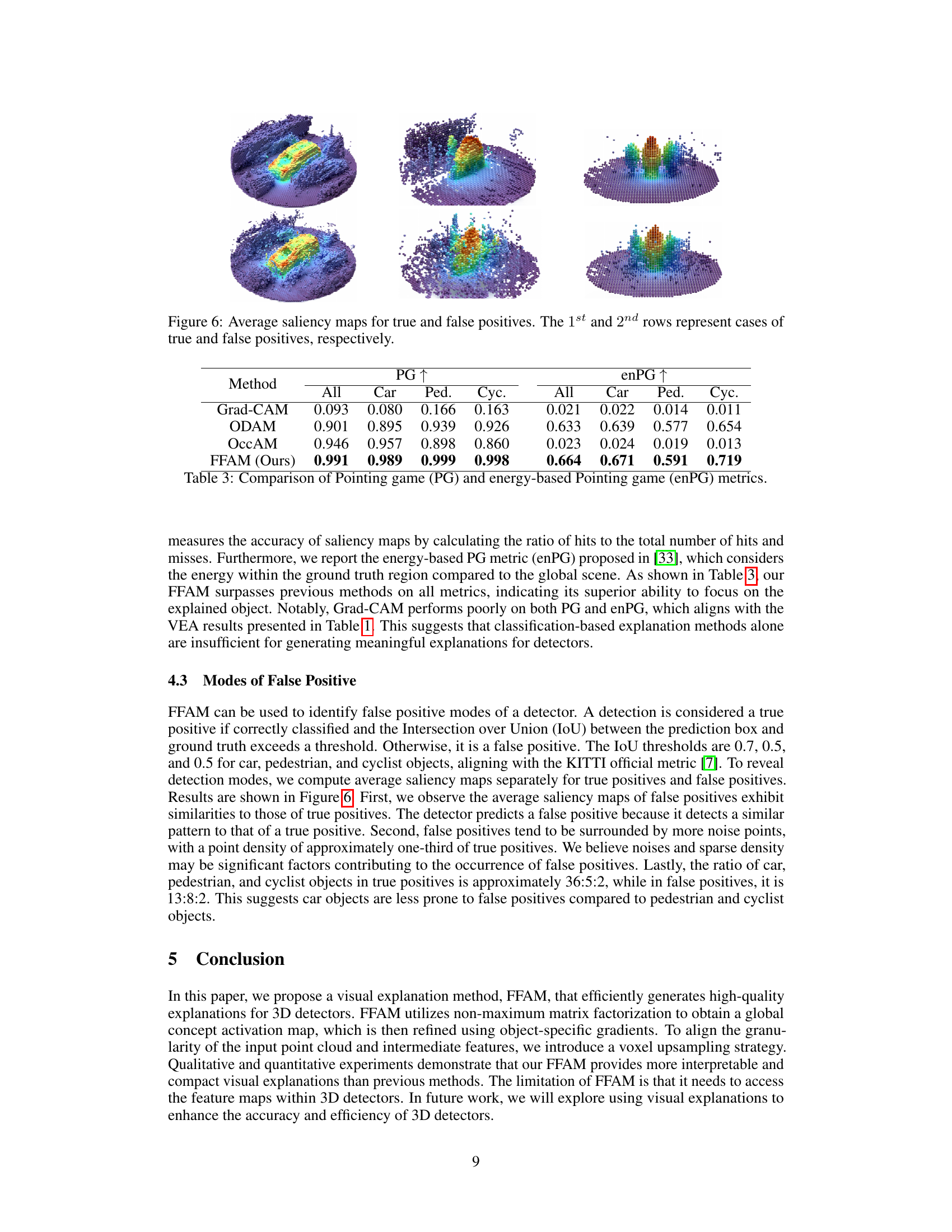
Analyzing 3D object detectors requires a multifaceted approach. Evaluation metrics must go beyond simple accuracy, encompassing metrics like precision, recall, and Intersection over Union (IoU) at various thresholds. Qualitative analysis of detector outputs is crucial, examining visualizations to identify strengths and weaknesses, such as sensitivity to occlusion or noise in point clouds. Ablation studies help isolate the contributions of individual components within the detector architecture. For instance, analyzing the influence of different backbone networks or feature extraction methods is vital. Finally, understanding the failure modes of a 3D detector is key. This involves examining cases where detectors produce false positives or miss true objects, potentially revealing areas for improvement in data augmentation, model architecture or training strategies. Comparative analysis against state-of-the-art detectors establishes the detector’s overall performance and identifies its advantages and disadvantages.
NMF for Point Clouds#
Applying Non-negative Matrix Factorization (NMF) to point cloud data presents a unique opportunity to extract meaningful features and understand the underlying structure. Point clouds, unlike images, lack inherent spatial grid structures, making direct application of NMF challenging. However, NMF’s ability to decompose a data matrix into lower-dimensional, non-negative components makes it suitable for discovering latent semantic features within point cloud data. One approach involves representing point clouds as matrices, where rows could represent individual points and columns represent features (e.g., XYZ coordinates, intensity, or other sensor readings). NMF then decomposes this matrix to reveal underlying concepts, potentially corresponding to object parts or geometric primitives. This approach requires careful consideration of how to organize the point cloud data into a meaningful matrix representation and how to interpret the resulting NMF components in the context of the 3D point cloud geometry. Another approach might involve using NMF on feature vectors obtained after processing point cloud data with other methods, like those that extract geometric features or segment the cloud into meaningful regions. This may reduce noise and complexity before applying NMF, leading to more robust feature extraction. The choice of appropriate pre-processing steps and interpretation methods is crucial for successfully extracting valuable insights from point clouds using NMF. Overall, NMF presents a promising avenue for the analysis and understanding of point cloud data, with several research paths to explore.
Voxel Upsampling#
The heading ‘Voxel Upsampling’ highlights a crucial preprocessing step in the context of 3D point cloud data processing for object detection. Point clouds, unlike images, are inherently sparse, leading to low-resolution activation maps after feature extraction. This sparsity creates a significant challenge for generating high-resolution saliency maps needed for accurate visual explanations. The proposed upsampling method aims to address this limitation by intelligently interpolating values from sparse neighbors, increasing the resolution of the activation maps to match that of the input point cloud. This is particularly important for aligning the scale between the activation map and the input, improving the quality of the visual explanations generated. The choice of using a voxel-based upsampling strategy, rather than a simpler method like linear interpolation, is significant because it acknowledges and handles the unique characteristics of 3D point clouds. This voxel-centric approach is likely more robust to noise and variations in point density, common in LiDAR data, providing more reliable and detailed visual explanations.
Future of FFAM#
The future of FFAM (Feature Factorization Activation Map) looks promising, particularly in enhancing the interpretability of 3D object detectors. Further research could focus on improving its efficiency, perhaps through optimized matrix factorization techniques or more efficient gradient aggregation methods. Extending FFAM’s application beyond LiDAR-based detectors to other sensor modalities (e.g., cameras, radar) would significantly broaden its impact. Integrating FFAM with other explanation methods might yield even richer and more comprehensive insights into the decision-making processes of 3D perception models. Exploring different loss functions and gradient refinement strategies could further improve the quality and specificity of the generated saliency maps. Finally, developing standardized evaluation metrics for 3D explanation methods would be crucial for facilitating objective comparison and progress in this field.
More visual insights#
More on figures
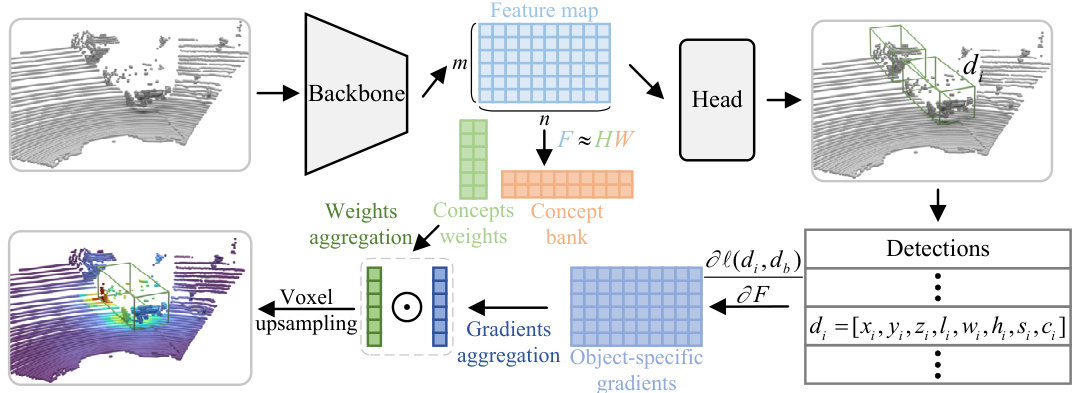
This figure illustrates the overall framework of the Feature Factorization Activation Map (FFAM) method. It shows how the method takes a point cloud as input, processes it through a 3D backbone network to generate a feature map. Then, Non-negative Matrix Factorization (NMF) is applied to decompose the feature map into concept activation maps. These are aggregated to obtain a global concept activation map. Simultaneously, object-specific gradients are computed and used to refine the global map, generating an object-specific saliency map for each detection. Finally, voxel upsampling aligns the scales between the activation map and the input point cloud, resulting in a final object-specific saliency map that highlights important points for each detection.
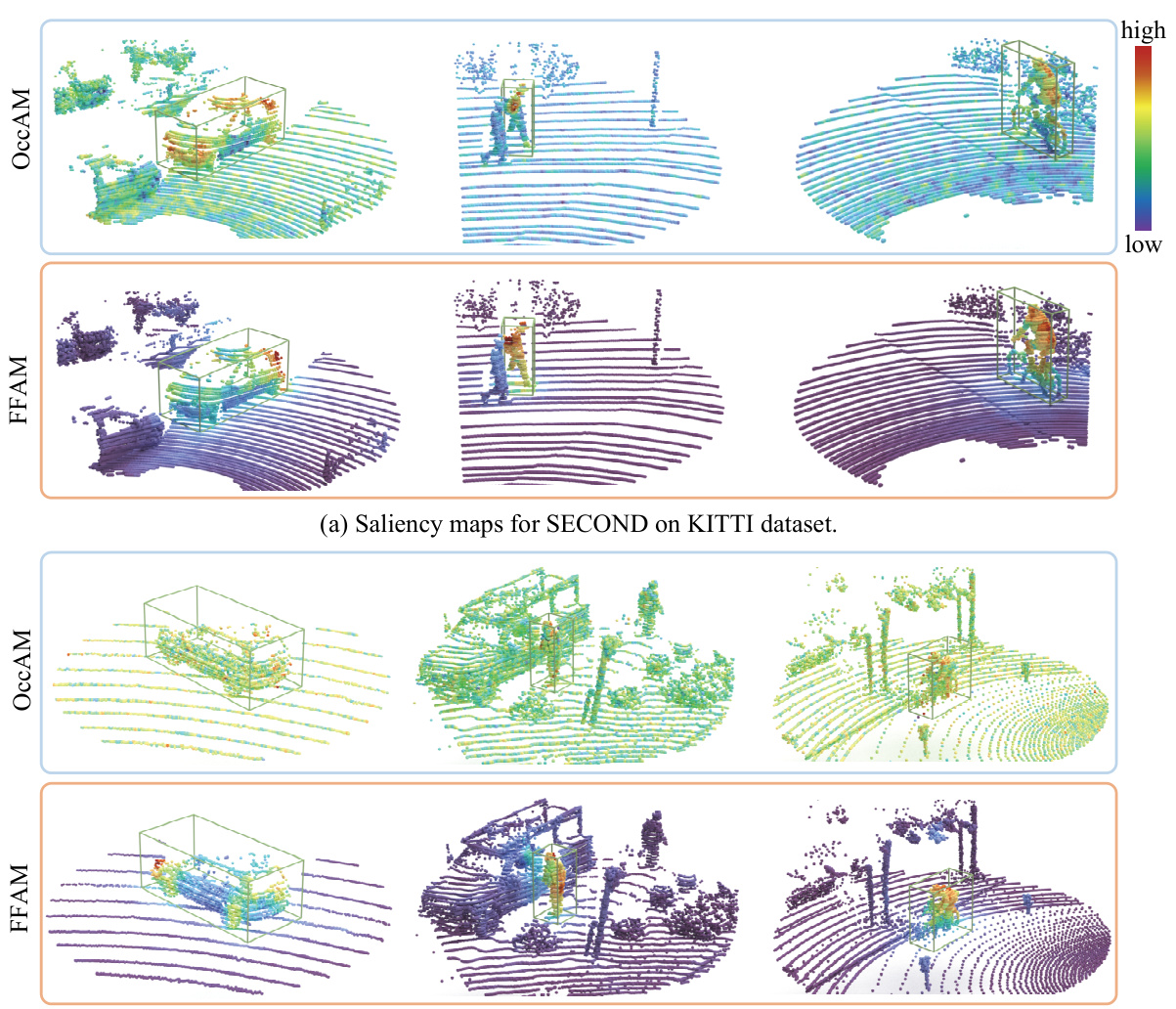
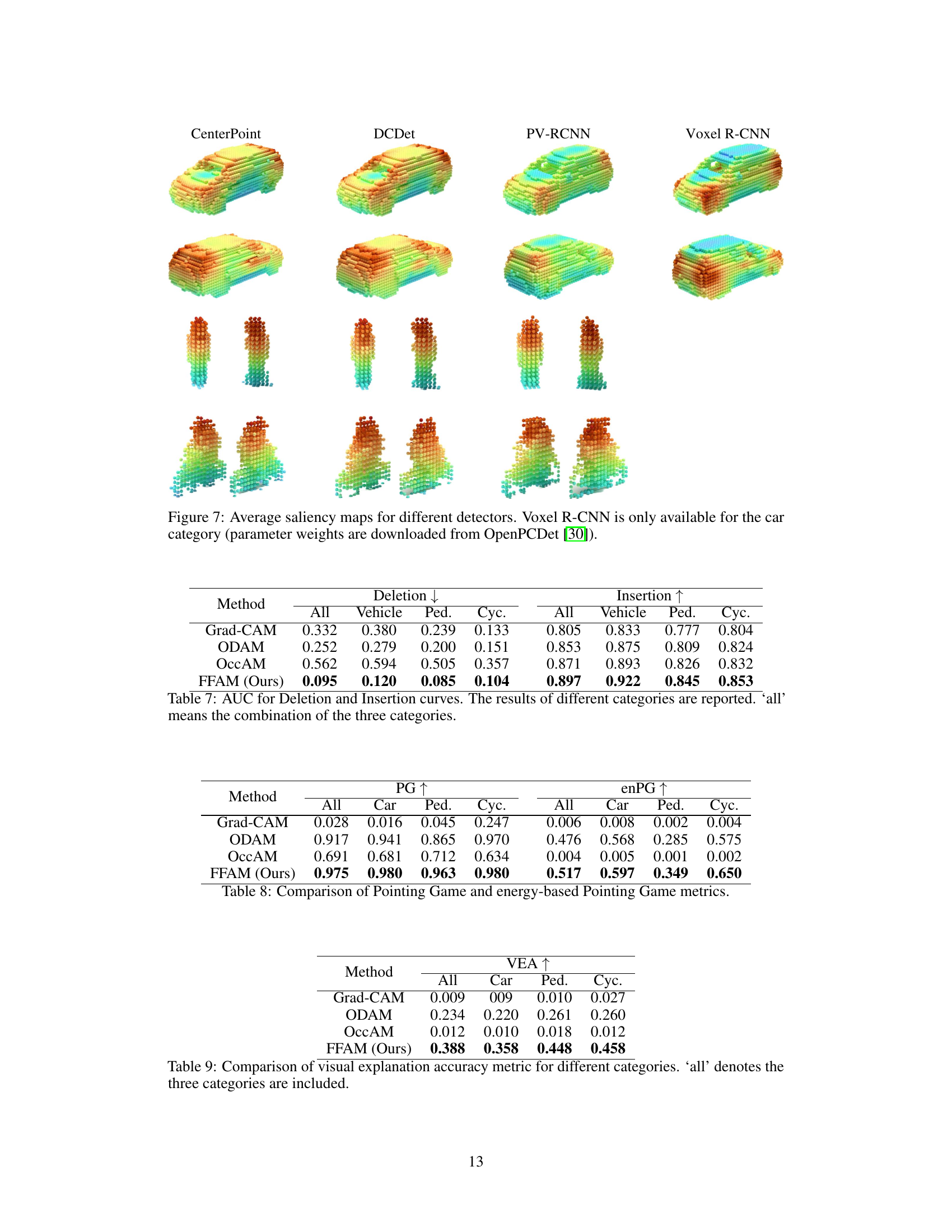
This figure shows a comparison of saliency maps generated by FFAM and OccAM for different 3D object detectors (SECOND and CenterPoint) on the KITTI and Waymo Open datasets. The green boxes highlight the detected objects, with color intensity representing the importance of each point in the detection. FFAM’s maps are cleaner and more focused on the objects of interest, while OccAM’s maps exhibit more background noise.

This figure visualizes average saliency maps for different object attributes predicted by a 3D detector. Each row represents a different object category (car, pedestrian, cyclist). Each column shows the average saliency map highlighting point importance for a specific attribute: overall detection score (d), confidence score (s), center coordinates (x,y,z), length (l), width (w), height (h), and rotation (r). Warmer colors indicate higher importance.
This figure compares the saliency maps generated by FFAM and OccAM for SECOND and CenterPoint detectors on the KITTI and Waymo Open datasets. It visually demonstrates that FFAM produces clearer and more focused saliency maps compared to OccAM, particularly highlighting object-specific features and reducing background noise. The use of warmer colors in the maps indicates stronger point contributions to the object detection, making the results more intuitive and easier to understand.

This figure shows a comparison of saliency maps generated by the proposed FFAM method and the existing OccAM method for two different 3D detectors, SECOND and CenterPoint. The maps highlight the importance of different points in the point cloud for object detection. FFAM produces cleaner, more focused saliency maps compared to OccAM, especially on the Waymo Open dataset, indicating its superior ability to highlight relevant features for object detection.

This figure shows a comparison of saliency maps generated by the proposed FFAM method and the OccAM method for two different 3D object detectors (SECOND and CenterPoint) on two different datasets (KITTI and Waymo Open). The green boxes highlight the detected objects, and the color intensity represents the contribution of each point to the detection. FFAM produces cleaner, more focused saliency maps compared to OccAM, especially noticeable on the Waymo dataset, which is more complex and densely populated. The cropped images are for better visualization.
More on tables

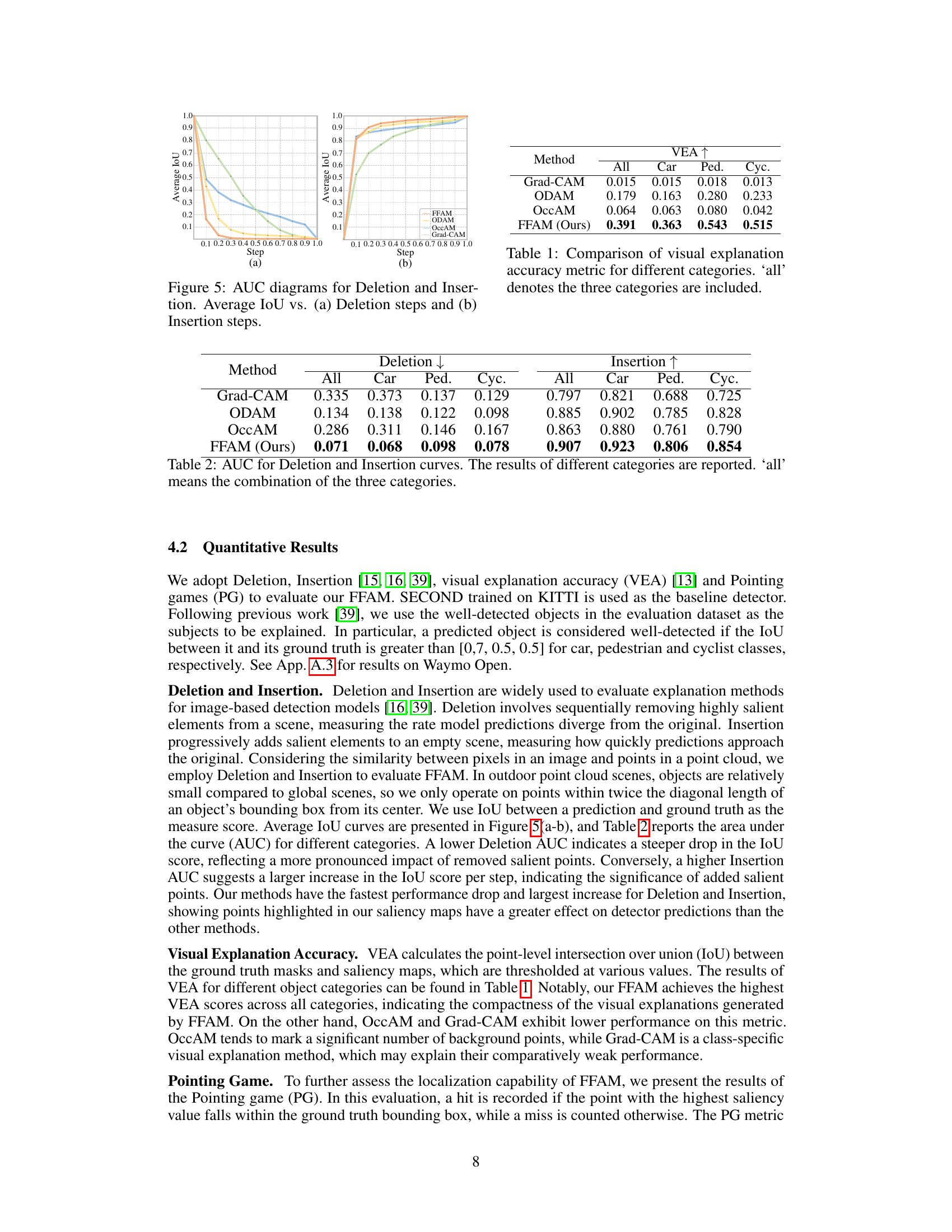
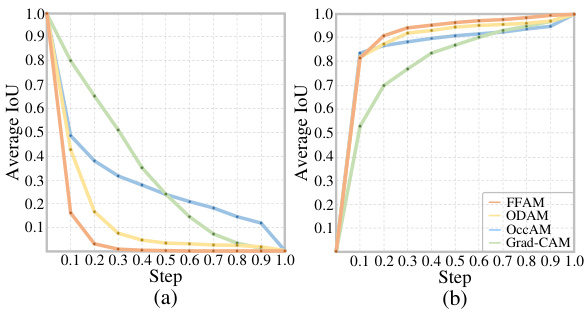
This table presents the Area Under the Curve (AUC) values for Deletion and Insertion experiments, evaluating the impact of removing or adding salient points on the model’s prediction accuracy. Results are shown for all object categories (car, pedestrian, cyclist) and a combined ‘all’ category. Lower Deletion AUC indicates a more significant impact of removing points, while higher Insertion AUC shows a greater influence of adding salient points.

This table presents the results of two metrics used to evaluate the quality of visual explanations generated by different methods. Pointing Game (PG) measures the accuracy of the saliency map by calculating the ratio of hits to the total number of hits and misses. Energy-based Pointing Game (enPG) considers the energy within the ground truth region compared to the global scene. The table shows the performance of Grad-CAM, ODAM, OccAM and the proposed FFAM method across all object categories (All), Cars, Pedestrians and Cyclists. Higher scores in both PG and enPG indicate better performance.
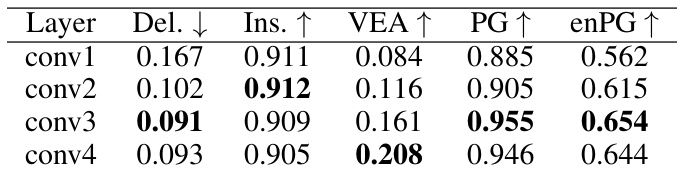
This table presents the results of an ablation study where different layers (conv1-conv4) of the 3D backbone network were used as input for FFAM. The results are evaluated using the metrics Deletion, Insertion, VEA, PG, and enPG. Lower Deletion scores and higher Insertion scores are better, indicating a stronger correlation between the saliency map and object detection performance. Higher VEA, PG, and enPG scores indicate better visual explanation quality.

This table presents the results of an ablation study on the hyperparameters used in the voxel upsampling strategy of the FFAM method. The study varies the Manhattan distance threshold (Range) and the number of neighbor voxels (k) considered when upsampling. The table shows the impact of these hyperparameters on the performance metrics: Deletion, Insertion, Visual Explanation Accuracy (VEA), Pointing Game (PG), and energy-based Pointing Game (enPG). Each metric measures a different aspect of the quality of the visual explanations generated by the model. The bolded values indicate the best-performing configuration for each metric.
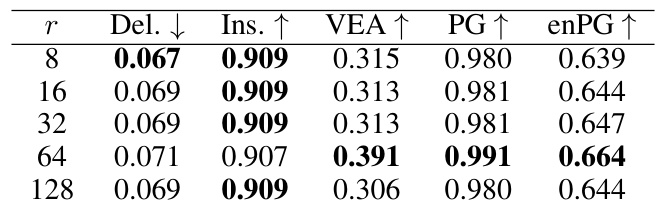
This table presents the results of an ablation study on the impact of the concept number (r) on the performance of FFAM. The metrics used to evaluate the performance are Deletion, Insertion, Visual Explanation Accuracy (VEA), Pointing Game (PG), and energy-based Pointing Game (enPG). The table shows that using r = 64 yields the best performance across most metrics.

This table presents the Area Under the Curve (AUC) values for Deletion and Insertion experiments. These experiments measure the impact of removing (Deletion) or adding (Insertion) points identified as important by the model on the model’s accuracy in object detection. AUC values are provided for all object classes (all), cars, pedestrians, and cyclists separately. Higher AUC values for Insertion are better, showing that adding points quickly improves accuracy, while lower AUC values for Deletion are better, showing that removing important points quickly decreases accuracy. This table helps to quantitatively assess the quality of the visual explanations generated by the proposed method and compare it to other methods.

This table compares the performance of four different visual explanation methods (Grad-CAM, ODAM, OccAM, and FFAM) on the Pointing Game (PG) and energy-based Pointing Game (enPG) metrics. The PG metric measures the accuracy of saliency maps by calculating the ratio of hits to the total number of hits and misses. The enPG metric considers the energy within the ground truth region compared to the global scene. Higher values in both PG and enPG indicate better localization performance of the explanation method.

This table presents a comparison of the visual explanation accuracy (VEA) achieved by four different methods: Grad-CAM, ODAM, OccAM, and the proposed FFAM. The VEA metric is calculated for all three object categories (car, pedestrian, cyclist) and overall. Higher VEA scores indicate better visual explanation accuracy, reflecting how well the saliency map highlights the most relevant regions in the input point cloud contributing to the detection.

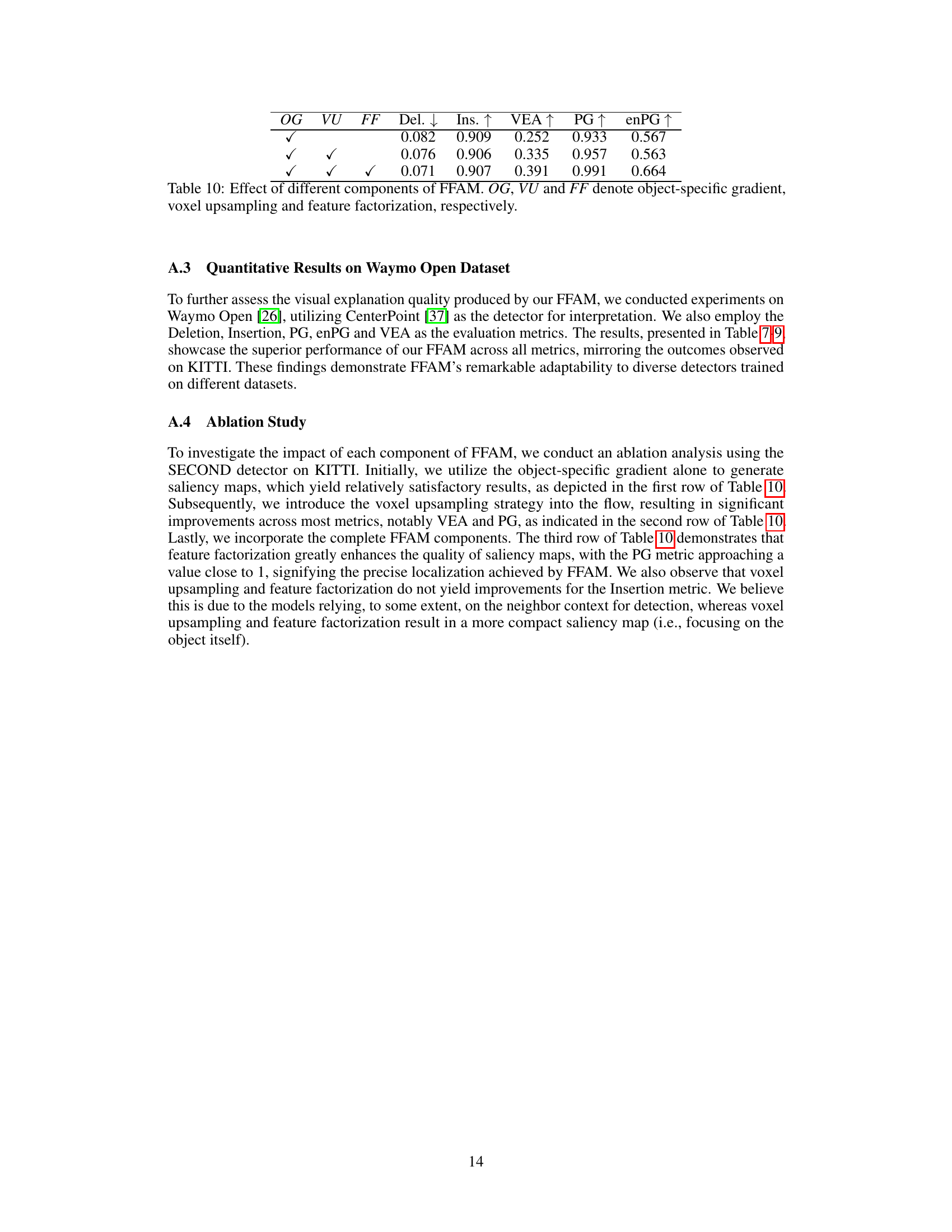
This table presents the ablation study of the FFAM method. It shows the effect of each component (object-specific gradient, voxel upsampling, and feature factorization) on the overall performance, measured by Deletion, Insertion, VEA, PG, and enPG. The results demonstrate that each component contributes positively to the performance, with the combination of all three yielding the best results.
Full paper#