↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world applications struggle with obtaining high-quality labeled data, leading to inaccurate models trained on noisy labels. This is especially problematic in domains like finance and healthcare, where acquiring accurate labels is costly and time-consuming. Previous research mainly focused on label aggregation, overlooking the importance of data refinement.
The paper introduces a novel framework, CRL, that actively refines the training data. CRL cleverly leverages annotator agreement to identify and correct noisy labels. For samples with disagreement, a comparative strategy is used to select the most reliable label, while an aggregating approach is applied to samples where annotators agree. This framework achieves superior performance compared to existing methods on various benchmark and real-world datasets, indicating its effectiveness in handling various types of noisy labels.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the challenge of learning from inaccurate labels, a prevalent issue in many real-world applications. The proposed collaborative refining framework offers a novel and effective solution by leveraging annotator agreement to improve data quality and model performance. This significantly advances the field of noisy-label learning, offering insights into how to handle data uncertainty and improve model robustness. It also opens up exciting new avenues of research in data refinement and model training, particularly in areas where obtaining high-quality labeled datasets is expensive or difficult.
Visual Insights#
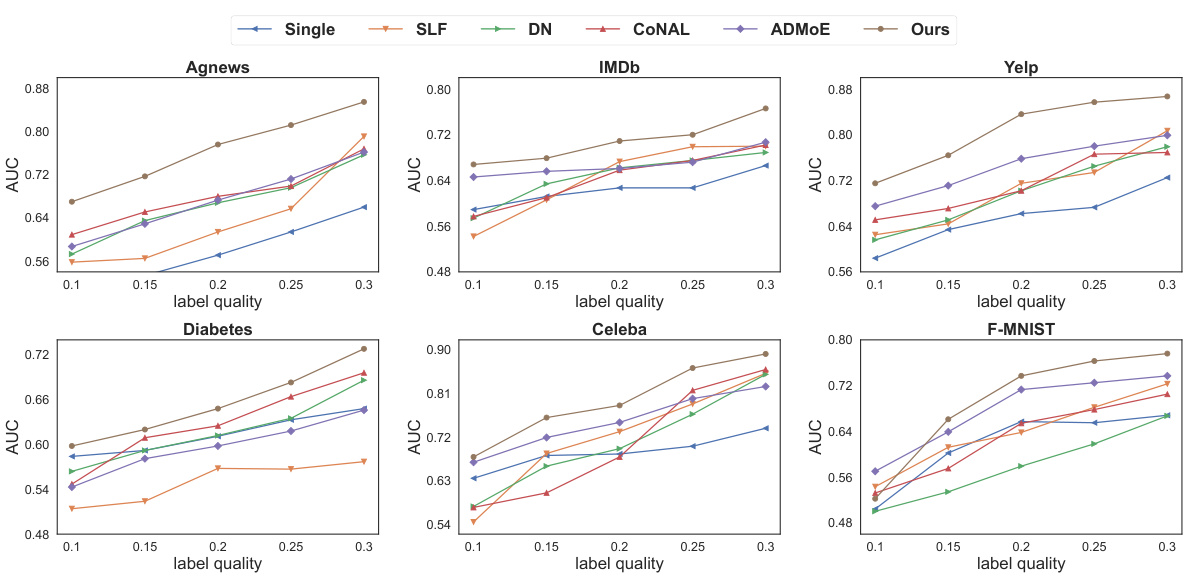
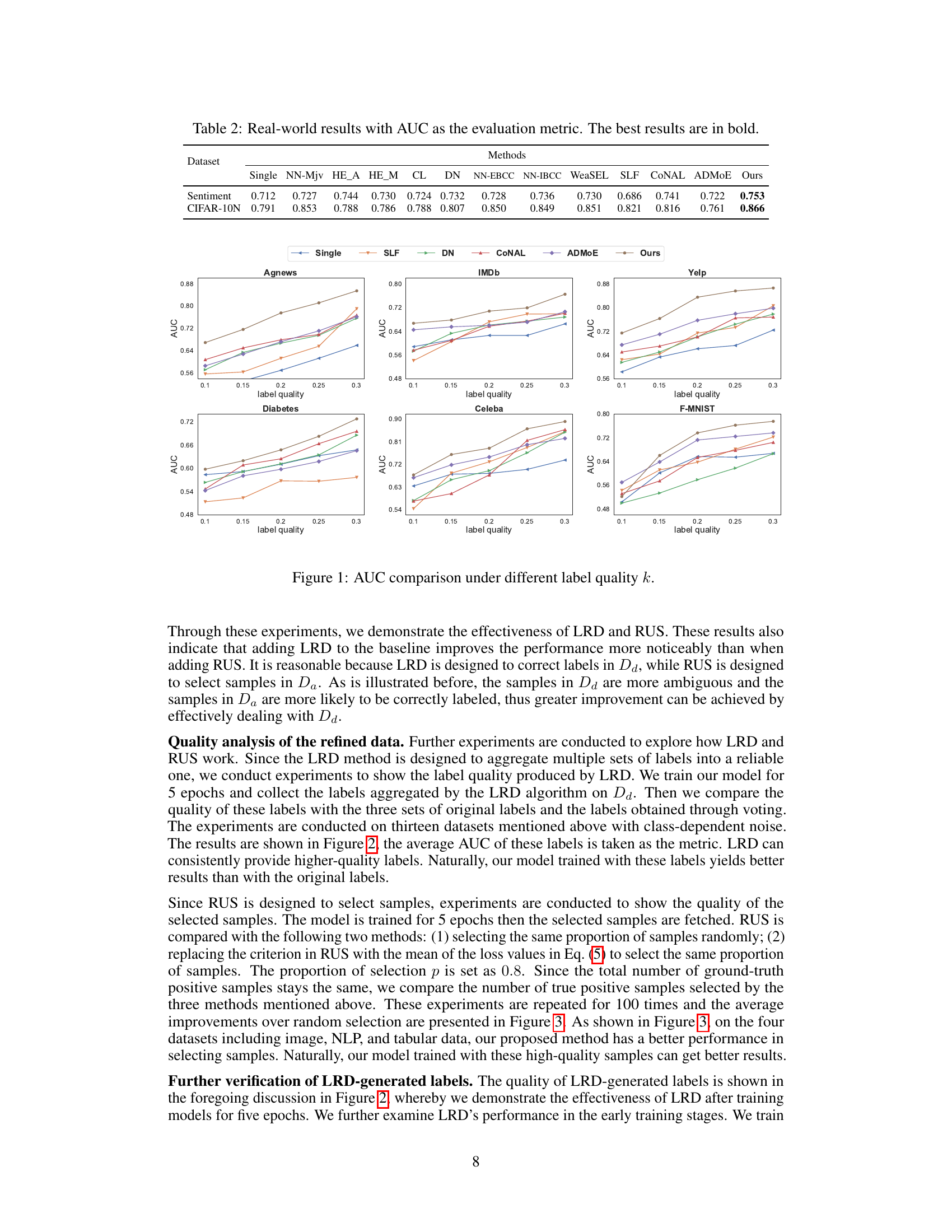
This figure shows the AUC (Area Under the Curve) scores for different methods across various datasets under different label quality (k). The x-axis represents the label quality (k), ranging from 0.1 to 0.3. The y-axis represents the AUC scores. Multiple lines represent different methods (Single, SLF, DN, CoNAL, ADMOE, and Ours), allowing for a comparison of their performance under varying levels of label noise. The datasets used are Agnews, IMDb, Yelp, Diabetes, Celeba, and F-MNIST. The figure illustrates how the performance of each method changes as the label quality (k) increases. Generally, higher label quality leads to better AUC scores for all methods, though the proposed method (‘Ours’) consistently performs best, indicating its robustness to noisy labels.

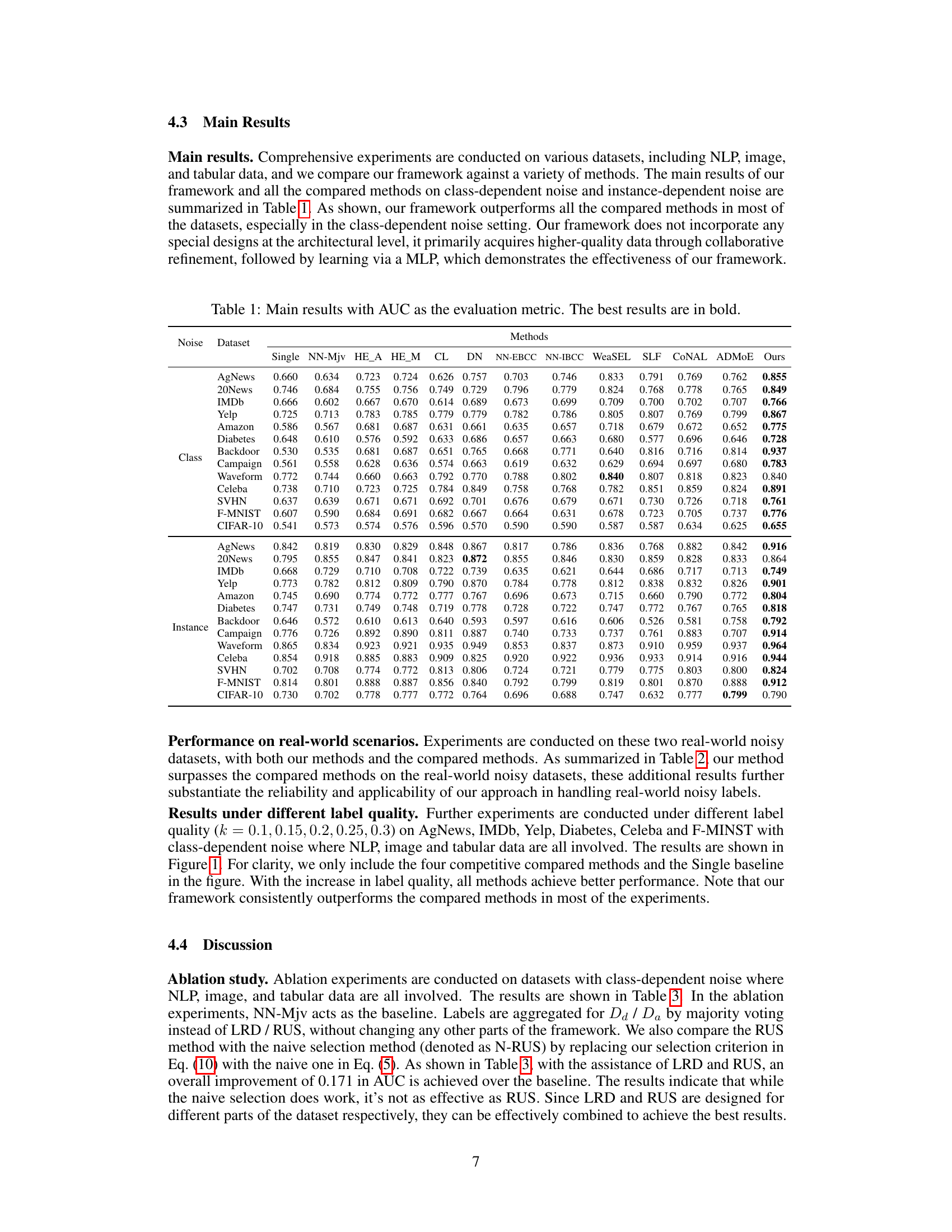
This table presents the Area Under the Curve (AUC) scores achieved by various methods on thirteen benchmark datasets, categorized into NLP, image, and tabular data. The methods are compared under two noise conditions: class-dependent and instance-dependent. The ‘Single’ method serves as a baseline, representing training on a single, noisy label set. Other methods leverage multiple noisy label sets, utilizing techniques like majority voting, ensemble methods, and specialized noisy-label learning approaches. The table highlights the superiority of the proposed Collaborative Refining framework (CRL) across numerous datasets and noise types, demonstrating its effectiveness in improving model performance by refining data through a collaborative refinement approach.
In-depth insights#
Inaccurate Label Issue#
The “Inaccurate Label Issue” is a central challenge in machine learning, where the labels used to train models are not perfectly accurate. This can stem from various sources, including noisy human annotations, errors in data collection, or the use of automatically generated labels which may be imperfect. The presence of inaccurate labels can lead to biased models, reduced generalization performance, and unreliable predictions. Addressing this issue is crucial for building robust and trustworthy AI systems. Strategies to mitigate inaccurate labels include data cleaning techniques, ensemble methods, robust loss functions, and techniques that explicitly model label noise. The choice of approach depends on the nature and severity of the label inaccuracies, as well as the computational resources available. A deeper understanding of the nature of the label errors is often essential for choosing an appropriate strategy and is a critical area of ongoing research.
Collaborative Refinement#
The concept of “Collaborative Refinement” in a machine learning context signifies a paradigm shift from traditional approaches that treat noisy labels as independent entities. Instead, it emphasizes the synergistic potential of multiple, potentially inaccurate, label sources. The core idea is to leverage the agreement or disagreement among these sources to iteratively refine the data. This iterative process involves identifying reliable labels through consensus among annotators and mitigating noise where discrepancies exist. A crucial aspect is the development of mechanisms to weigh the reliability of individual sources, allowing for a more robust and accurate model training. Through this collaborative refinement, the overall quality of training data is improved, leading to potentially more accurate and generalizable models. This approach presents a significant advance in handling noisy label problems by moving beyond simple aggregation and incorporating a feedback loop for data improvement. This refinement process is especially important in scenarios where acquiring high-quality labels is expensive and computationally challenging.
Theoretical Analysis#
A robust theoretical analysis section in a research paper would delve into the fundamental principles underpinning the proposed methodology. It should rigorously justify the approach’s design choices, demonstrating its validity and effectiveness through mathematical proofs, statistical modeling, or logical reasoning. For instance, it might derive theoretical bounds on the performance of the model under specific conditions (e.g., noise levels or dataset size), providing insights into its limitations. Furthermore, a strong theoretical analysis section would uncover potential relationships between various model components, explaining how they interact to achieve the desired outcome. This could involve proving theorems that establish connections between variables or constructing formal arguments that illustrate the logic behind the algorithm’s design. Finally, it should explore any underlying assumptions and analyze how they affect the model’s overall performance, explicitly addressing potential limitations or bias introduced by these assumptions. This comprehensive examination of the theoretical foundation builds confidence in the reliability and generalizability of the proposed method.
Robust Sample Selection#
Robust sample selection is crucial for training machine learning models effectively, especially when dealing with noisy or unreliable data. A robust method should selectively choose samples that are most informative and representative of the underlying data distribution, while discarding noisy or outlier samples. This involves developing criteria to assess sample quality, which might involve evaluating the loss associated with a sample, considering the agreement among multiple annotators, or employing other measures of data fidelity. Theoretical analysis is often key to establish the reliability of the criteria, and such analysis can help to formally prove properties like the generalization ability of the resulting model. In practice, robust sample selection often requires balancing different factors, such as computational cost, model performance, and robustness to noise. Adaptive strategies that dynamically adjust selection criteria during training can be particularly useful. It is also important to consider that the definition of ‘robust’ itself can be contextual and depend on the specific application and characteristics of the data.
Real-world Applicability#
The paper’s emphasis on collaborative refinement of inaccurate labels holds significant promise for real-world applications. Real-world data is rarely perfectly labeled, and the CRL framework directly addresses this challenge by leveraging the agreement and disagreement among multiple annotators. This makes it particularly useful in domains where obtaining accurate labels is costly, time-consuming, or inherently difficult, such as financial risk assessment or medical diagnosis. The framework’s model-agnostic nature is a key strength, allowing its integration with various existing models and architectures. The theoretical grounding provided in the paper is not only insightful, but also crucial for establishing robustness and reliability, which are vital for practical deployment. However, real-world success depends on factors beyond the framework itself, such as annotator diversity and quality, the choice of underlying model, and the robustness of the data pre-processing pipeline. Therefore, future work should focus on empirical studies in diverse real-world settings, evaluating the impact of varying levels of annotator expertise, label noise, and data characteristics on the performance and generalizability of the framework.
More visual insights#
More on tables

This table presents the Area Under the Curve (AUC) scores achieved by different methods on two real-world datasets: Sentiment and CIFAR-10N. The AUC is a common metric for evaluating the performance of binary classification models, where a higher AUC indicates better performance. The table compares the proposed Collaborative Refining for Learning from Inaccurate Labels (CRL) framework against several existing methods. The ‘Single’ model serves as a baseline, representing a model trained on a single set of labels. Other methods incorporate different strategies for handling multiple, inaccurate labels. The best performing method for each dataset is highlighted in bold.
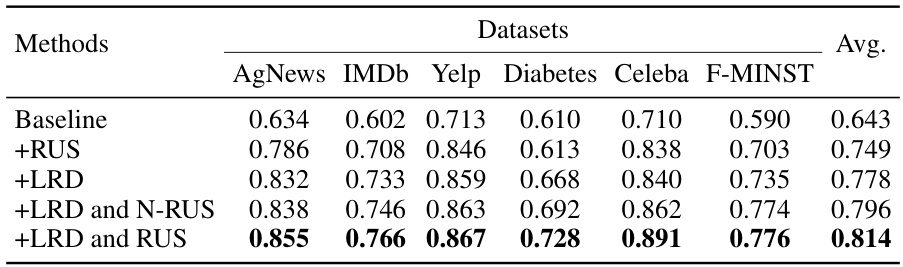
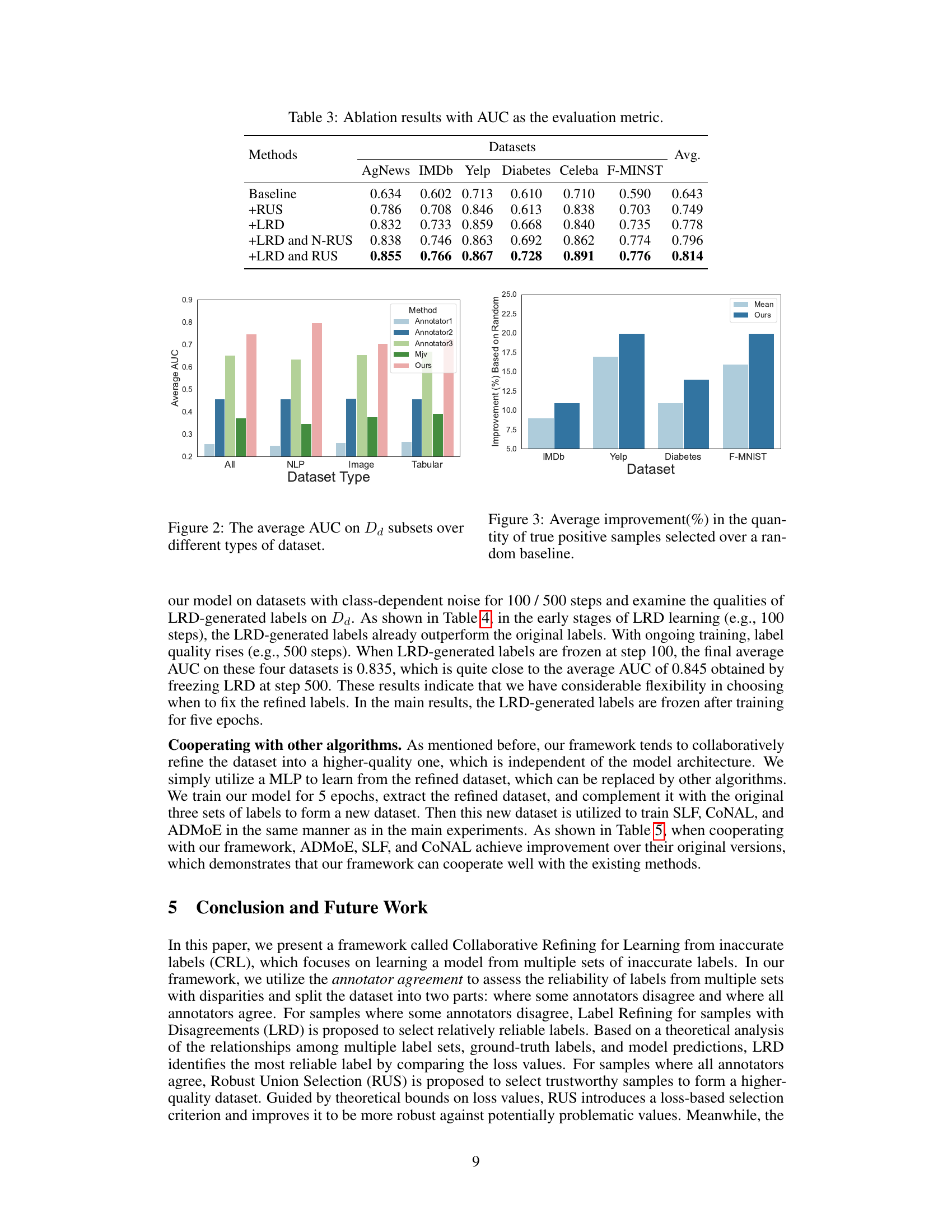
This ablation study evaluates the impact of the two core modules (LRD and RUS) on the overall performance. It compares the performance of the complete model against baselines using only one of the modules or using a naive version of RUS. The results are presented as AUC scores across six different datasets, highlighting the contribution of each module in improving the model’s accuracy.
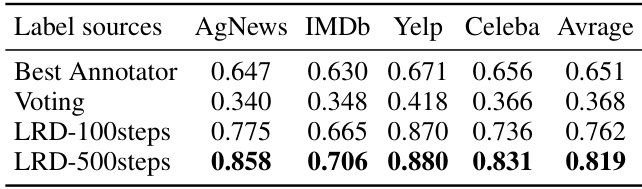
This table presents the AUC scores resulting from using different label sources to train a model on the Dd subset of the data. It compares the AUC achieved using the labels from the best annotator, a simple majority voting approach, and the proposed LRD method at two different training stages (100 and 500 steps). Higher AUC scores indicate better model performance. The results demonstrate the improved label quality and resulting performance gains from using the LRD approach compared to the baseline methods.
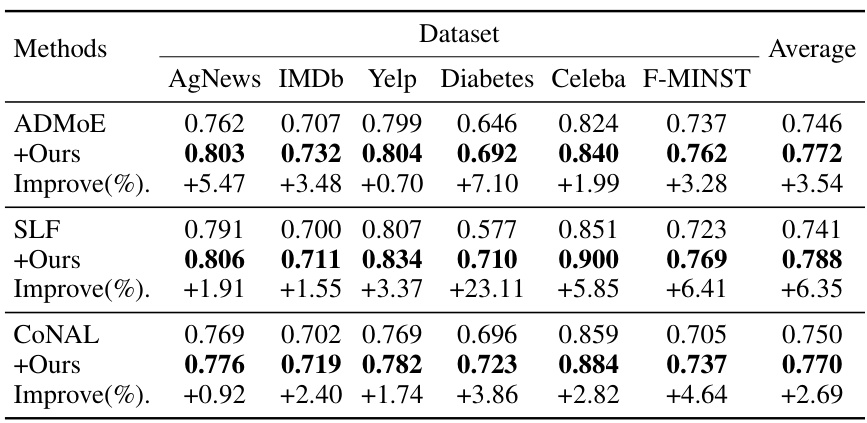
This table presents the Area Under the Curve (AUC) scores achieved by different methods on thirteen benchmark datasets. Two types of label noise are considered: class-dependent noise and instance-dependent noise. The table compares the performance of the proposed Collaborative Refining framework (CRL) against several other state-of-the-art methods for learning from inaccurate labels. The best performing method for each dataset is highlighted in bold.

This table presents the AUC (Area Under the Curve) scores achieved by various methods on 13 benchmark datasets, categorized by NLP, image, and tabular data. The results are broken down by class-dependent and instance-dependent noise, illustrating the performance of different approaches in handling various types of noisy labels. The ‘Ours’ column shows the results of the proposed CRL framework, highlighting its superior performance compared to other methods on most datasets. The best result for each dataset is bolded.
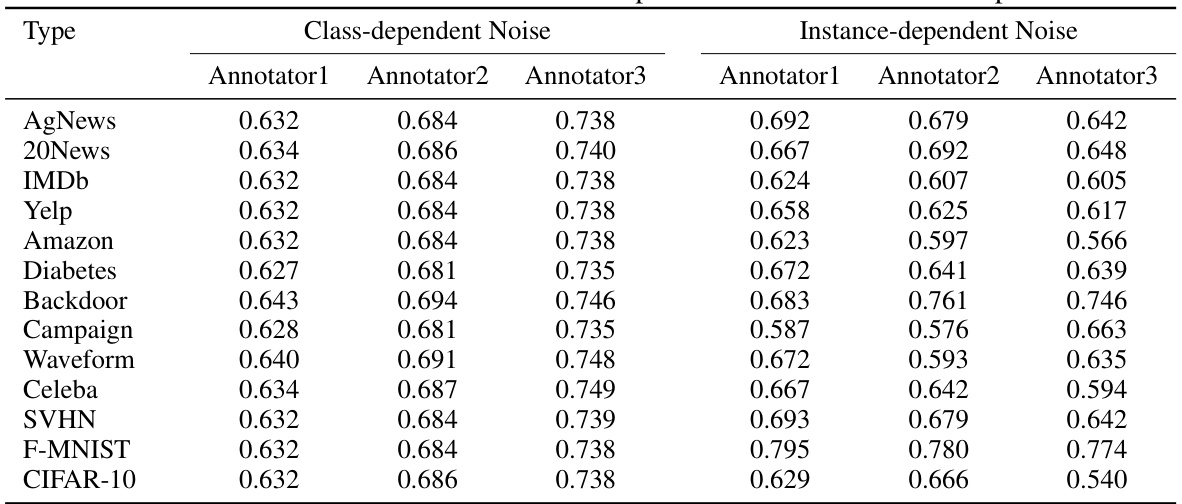
This table presents the Area Under the Curve (AUC) scores achieved by various methods on thirteen benchmark datasets, categorized into NLP, image, and tabular data. Two types of noise are considered: class-dependent and instance-dependent. The table compares the performance of the proposed Collaborative Refining framework (CRL) against several state-of-the-art methods. The best AUC score for each dataset and noise type is highlighted in bold, showcasing the superior performance of the CRL framework.
Full paper#