↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Smoke segmentation, crucial for timely fire rescue and leak detection, suffers from noisy labels due to the visual complexity of smoke. Existing methods for handling noisy labels in classification don’t directly apply to this nuanced segmentation task because of smoke’s variable transparency creating inconsistent features in noisy labels. This inconsistency makes it difficult to apply uniform criteria to all noisy labels.
The paper proposes CoSW (Conditional Sample Weighting), a novel approach that uses a multi-prototype framework. Each prototype represents a feature cluster, and CoSW assigns weights based on the cluster’s characteristics. This adaptive weighting, guided by a novel RWE (Regularized Within-Prototype Entropy), enables more effective identification and reduction of noisy label influence. Experimental results show superior performance compared to existing methods on both real-world and synthetic datasets, showcasing CoSW’s effectiveness in achieving state-of-the-art results in smoke segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial because noisy labels significantly hinder the accuracy and reliability of smoke segmentation models, which are vital for timely fire rescue and gas leak detection. The research directly addresses this critical challenge, providing a valuable contribution to improving the robustness and performance of such systems. It opens new avenues for research into noise-robust training strategies and adaptive sample weighting techniques in various image segmentation tasks.
Visual Insights#

This figure illustrates the concept of Conditional Sample Weighting (CoSW) for smoke segmentation with noisy labels. (a) shows an example image with noisy labels highlighted in blue and clean labels in red. (b) visualizes the feature embeddings extracted by the encoder, showing the varied distribution of noisy labels. (c) displays the sample weights assigned by CoSW, highlighting how it reduces the weight of noisy labels. Finally, (d) provides an intuitive explanation of how CoSW works by assigning different weights based on feature cluster and prototype proximity.
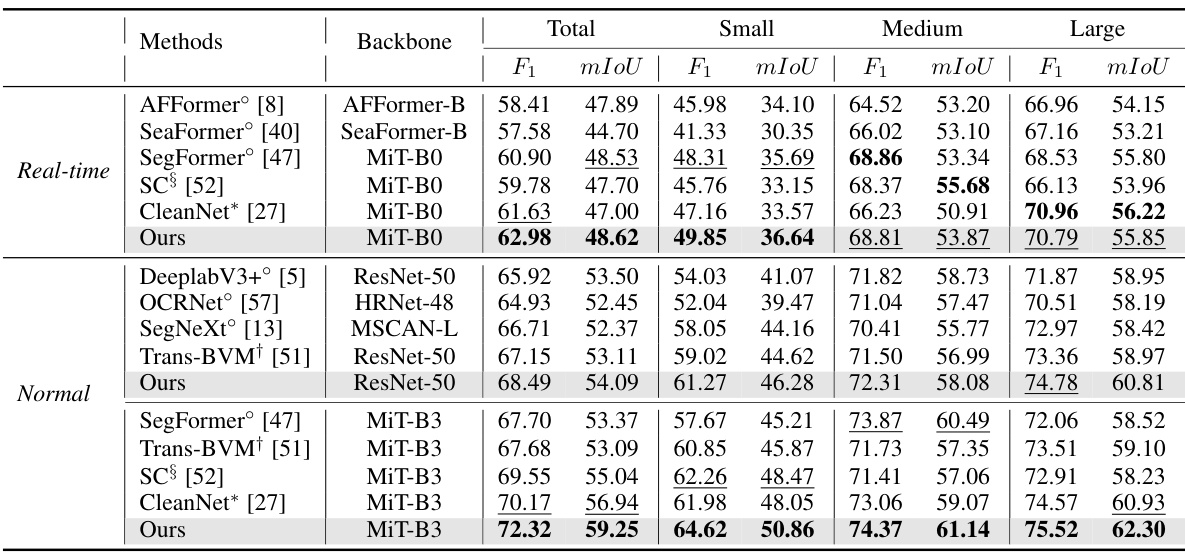
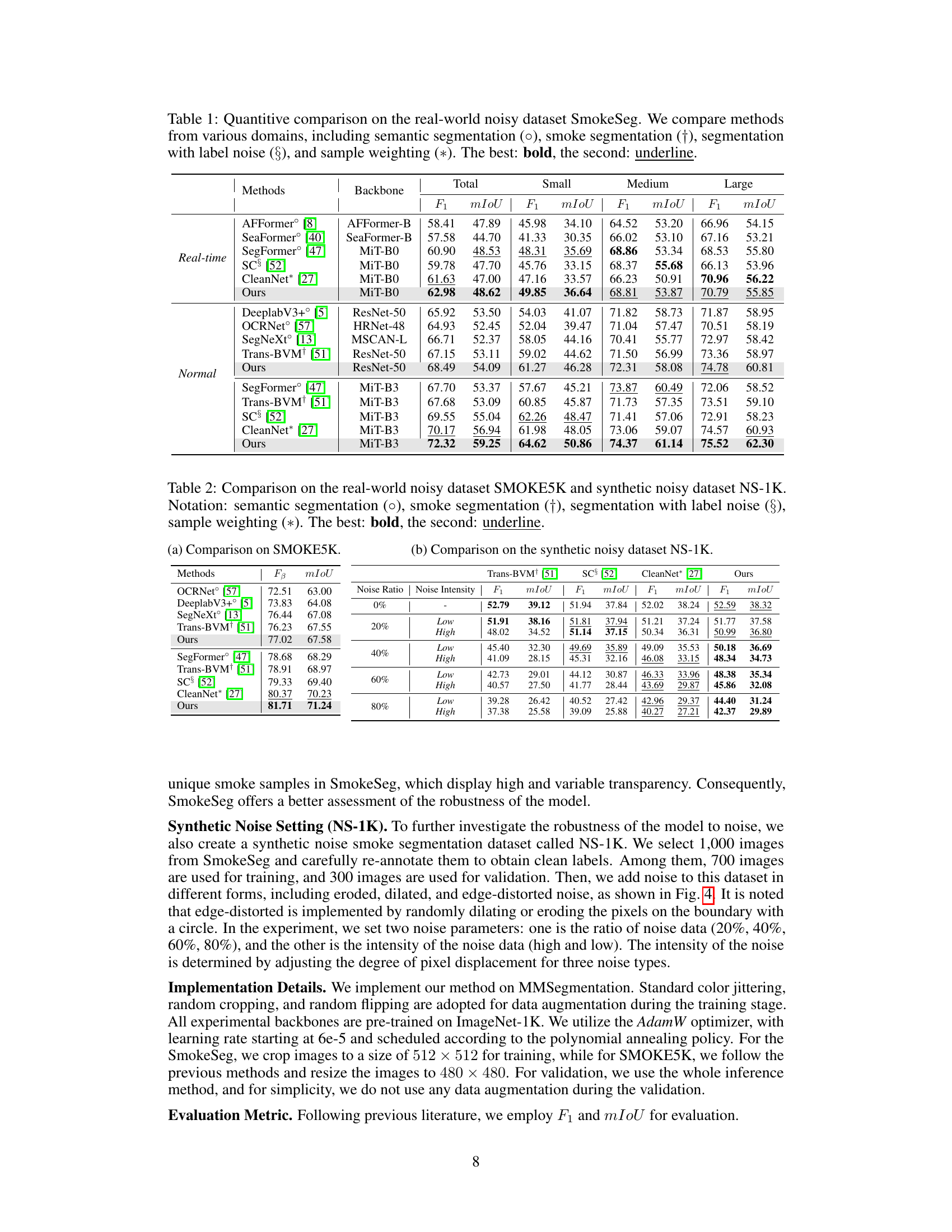
This table presents a quantitative comparison of different methods on the SmokeSeg dataset, focusing on real-world noisy data. It compares methods from various categories including general semantic segmentation, smoke-specific segmentation, segmentation handling label noise, and sample weighting. Performance is measured using F1 score and mIoU (mean Intersection over Union) for small, medium, large, and total image sizes. The best and second-best results are highlighted in bold and underlined, respectively.
In-depth insights#
Noisy Label Issue#
The pervasive issue of noisy labels in smoke segmentation presents a significant challenge, impacting model robustness and potentially leading to severe consequences. Unlike traditional object segmentation, smoke’s inherent ambiguity (blurry edges, variable transparency) makes accurate labeling extremely difficult, resulting in inconsistencies. The paper highlights that existing methods largely ignore this problem, focusing primarily on classification tasks. Addressing this necessitates a shift towards more sophisticated approaches that account for the non-uniform distribution of noise and the varying degrees of uncertainty. The authors propose a conditional sample weighting method which tackles this by utilizing multi-prototypes to assign weights to different feature clusters based on their proximity to prototypes. This approach adapts weights based on the level of noise in each area rather than applying a uniform weighting strategy, which is a key contribution of this paper. Therefore, careful consideration of noise characteristics during data collection and model training is crucial for creating effective smoke segmentation models. Further research should explore more robust labeling techniques and explore different model architectures better suited for handling the uncertainty introduced by noisy labels in this complex application.
CoSW Framework#
The CoSW (Conditional Sample Weighting) framework is a novel approach to handling noisy labels in smoke segmentation, a critical task with significant real-world implications. Its core innovation lies in using multiple prototypes to represent feature clusters within each class, allowing for a more nuanced understanding of label uncertainty. This is a significant departure from methods that treat pixel-level noise as independently and identically distributed, a problematic assumption for smoke due to its variable transparency. The framework introduces RWE (Regularized Within-Prototype Entropy), which incorporates prototype-based weighting to effectively identify and down-weight noisy samples. This dynamic weighting allows for a more robust model training process. The integration of RSML (Regularized Scatter Metric Learning) further enhances the discriminative power of the embedding space, improving the overall segmentation accuracy. The CoSW framework demonstrates superior performance on various real-world and synthetic datasets, significantly outperforming existing methods that are not specifically designed for noisy smoke segmentation. Its effectiveness highlights the importance of considering the unique characteristics of data when addressing the problem of noisy labels.
Multi-Prototype#
The concept of “Multi-Prototype” in the context of smoke segmentation, and noisy labels, presents a powerful approach to handling data variability. Instead of relying on a single prototype per class, which can be overly simplistic and fail to capture the inherent diversity of smoke appearances, a multi-prototype system establishes multiple representative features. This allows the model to better delineate between smoke and background, especially in ambiguous regions. The use of multiple prototypes directly addresses the challenges posed by inconsistent features of noisy labels, which are common in smoke imagery due to varying transparency and density. By incorporating these multiple prototypes, the model gains a more nuanced understanding of the data distribution, improving the accuracy of noisy label identification and the overall robustness of the segmentation process. The effectiveness of this approach highlights the value of representing complex data with a richer, multi-faceted set of prototypes rather than relying on oversimplified representations. Therefore, the multi-prototype approach provides a significant advancement in smoke segmentation for scenarios with noisy data.
RWE Regularization#
Regularizing the within-prototype entropy (RWE) is crucial in the CoSW framework for handling noisy labels in smoke segmentation. Standard entropy maximization leads to uniform likelihoods, failing to differentiate between reliable and unreliable samples. RWE addresses this by incorporating an M-estimation approach, effectively down-weighting samples deemed noisy based on their distance from prototypes. This dynamic weighting mechanism, guided by prototypes acting as anchors, enables a robust and adaptive handling of noisy labels that vary considerably in their characteristics within the feature space. The regularization in RWE is key to preventing overfitting that can arise from simply maximizing within-prototype entropy, ensuring model stability and improved segmentation accuracy. It achieves this by considering the entire probability distribution within each prototype’s feature cluster, offering a more holistic and robust approach compared to methods solely relying on individual sample similarities. This leads to more reliable prototype updates, making the model more resilient to noisy labels and ultimately boosting segmentation performance.
Future Works#
The paper’s success in addressing noisy labels in smoke segmentation opens exciting avenues for future research. A key area would be exploring more sophisticated noise modeling techniques beyond the synthetic and real-world datasets used. This could involve investigating diverse noise distributions or incorporating real-world complexities like varying smoke densities and illumination conditions. Improving the robustness of prototype learning is another crucial direction. The current methodology relies on a fixed number of prototypes; adaptive mechanisms that dynamically adjust the number of prototypes based on data characteristics could enhance performance and efficiency. Furthermore, exploring the integration of advanced metric learning approaches to better handle noisy feature spaces would be beneficial. This could involve exploring techniques that are less sensitive to noisy labels or that actively learn a robust distance metric. Finally, extending the method to other challenging segmentation tasks involving similar label noise issues, such as medical image analysis or remote sensing, could showcase the broad applicability of the proposed CoSW approach. Investigating the effects of different entropy functions beyond Shannon, Burg, and Kapur’s entropies, could also reveal potential performance improvements.
More visual insights#
More on figures
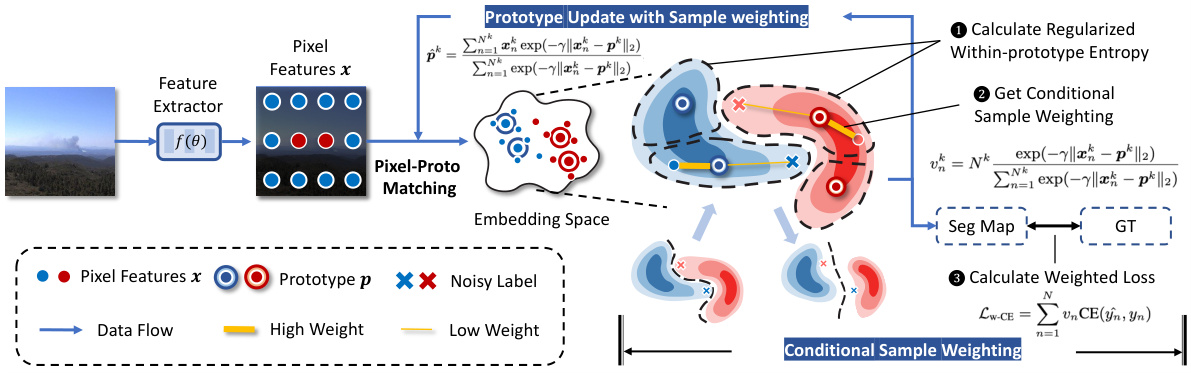
The figure illustrates the architecture of the Conditional Sample Weighting (CoSW) method for smoke segmentation. It shows the data flow, starting from the input smoke image, through a feature extractor, to pixel-prototype matching in the embedding space. The core of the method involves calculating a regularized within-prototype entropy and deriving conditional sample weights. These weights are then used to calculate a weighted loss function which helps train a robust model resistant to noise in the labels. The diagram clearly displays the process of how noisy labels are given low weight, while clean pixels are given higher weight during training, leading to a more accurate segmentation model. Prototypes are updated using the sample weights to improve performance.

This figure illustrates the impact of conditional sample weighting (CoSW) on prototype updates in the presence of noisy labels. Panel (a) shows that without CoSW, the prototype is easily shifted by noisy labels, indicated by the large cross symbol. The black lines represent the moving path of the prototype. In contrast, panel (b) demonstrates that with CoSW, the prototype update is more stable, better maintaining its original position. The yellow lines indicate the sample weights, which are adjusted dynamically. The smaller effective scope of prototype in panel (b) highlights the benefit of the CoSW.

This figure shows examples of the clean and corrupted masks from the NS-1K dataset used in the paper. It demonstrates three different types of synthetically introduced noise: dilated, eroded, and edge-distorted. Each row presents a smoke image along with its corresponding clean mask and masks corrupted by each of the three noise types. The images clearly illustrate the nature of the noise and its effects on the segmentation task.
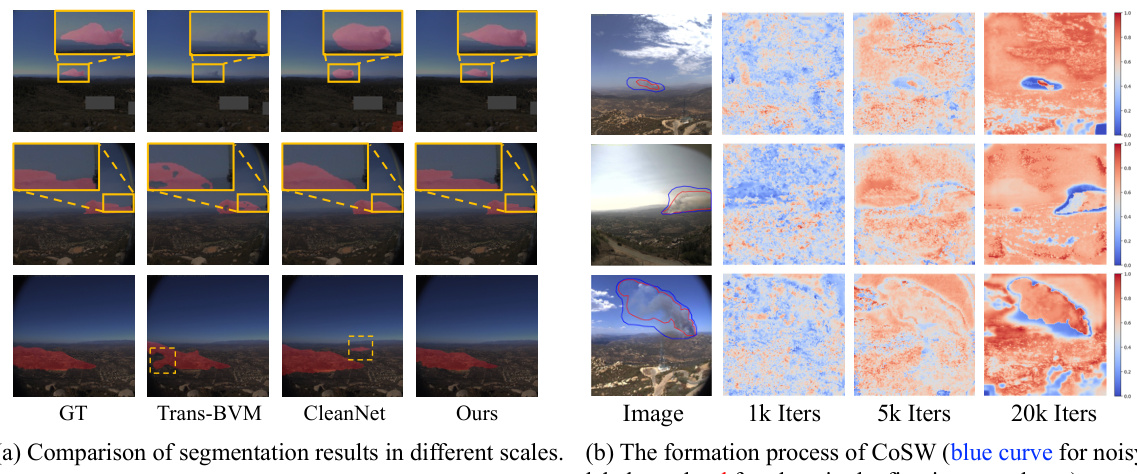
This figure shows a comparison of segmentation results from different methods (Trans-BVM, CleanNet, and the proposed CoSW method) on various scales, highlighting the effectiveness of CoSW in handling noisy labels. It also visually demonstrates the formation process of CoSW during training. In (a), the different methods’ outputs are compared side-by-side with the ground truth (GT) to show the differences in their segmentation accuracy and handling of noisy regions. In (b), the evolution of CoSW’s sample weighting is illustrated over different training iterations (1k, 5k, and 20k iterations). The colormap shows the sample weights, with red indicating high weights and blue indicating low weights. The visualization reveals how CoSW adapts its weighting to accurately identify and down-weight noisy label regions during the training process.

This figure compares the sample weighting results of CleanNet and CoSW (Ours) on two example smoke images. The left column shows the original images. The middle column shows the sample weightings generated by CleanNet, highlighting areas identified as potentially noisy labels. The right column shows the sample weightings produced by CoSW, demonstrating its capacity to distinguish between noisy regions of varying transparency (gradual in lighter smoke, sharper in denser regions) and provide more accurate weight assignments. The color scale in each heatmap ranges from 0.0 (blue, low weight) to 1.0 (red, high weight).
More on tables
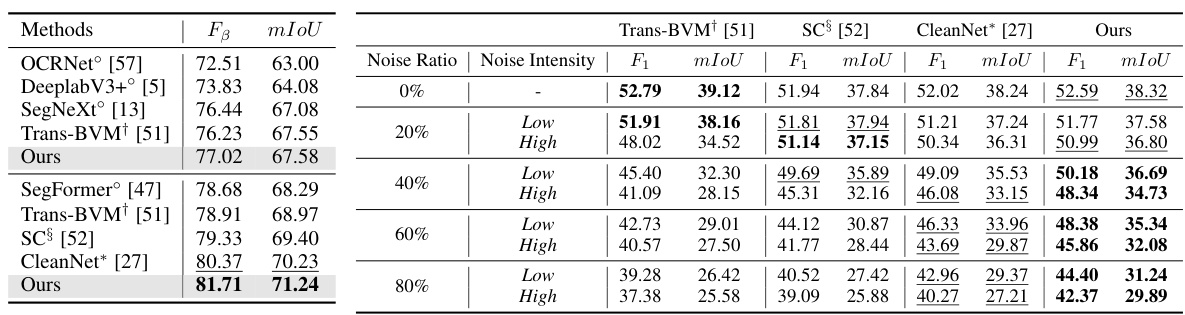
This table presents a quantitative comparison of different methods on two datasets: SMOKE5K (a real-world noisy dataset) and NS-1K (a synthetic noisy dataset). The methods are categorized into semantic segmentation, smoke segmentation, segmentation with label noise, and sample weighting. The table shows the F1 score and mIoU (mean Intersection over Union) for each method on each dataset, highlighting the best and second-best performing methods.

This table presents the ablation study results for CoSW and metric learning methods. The left part (a) shows the ablation study of CoSW on the SmokeSeg dataset, demonstrating the impact of adding sample weights and prototype weights separately and together on the F1 score and mIoU. The right part (b) shows the ablation study of using different metric learning methods including triplet loss and scatter loss, either alone or in combination with CoSW. The results highlight the effectiveness of CoSW in improving the performance of the smoke segmentation model, particularly when combined with scatter loss.

This table presents the results of an ablation study comparing the performance of three different entropy measures (Kapur’s, Burg’s, and Shannon’s) used within the CoSW method. The F1 score and mIoU (mean Intersection over Union) metrics are reported for each entropy, demonstrating the impact of the entropy choice on the overall performance of smoke segmentation.

This table shows the impact of the number of iterations in the Sinkhorn-Knopp algorithm on the performance of the smoke segmentation model. The experiment was conducted on the SmokeSeg dataset using the MiT-B3 backbone. The results demonstrate that increasing the number of iterations from 1 to 3 significantly improves performance, after which improvements are minimal. The F1 score and mIoU are reported for various iteration numbers.

This table presents the performance of the model using different numbers of prototypes in each class for smoke segmentation on the SmokeSeg dataset using the MiT-B3 backbone. The results show that increasing the number of prototypes from 1 to 3 significantly improves the performance, indicating that a polycentric embedding space enhances representation. However, further increasing the number of prototypes beyond 10 yields diminishing returns.
Full paper#