↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Deep state space models (SSMs) are powerful tools for sequential data processing but their vulnerability to adversarial attacks remains a significant challenge. Existing adversarial training methods aren’t very effective with SSMs, and enhancements like attention mechanisms, while improving performance, also introduce robust overfitting issues, limiting generalization. This paper investigates various SSM structures and their behavior under adversarial training, revealing the limitations of existing methods.
This study proposes a novel adaptive scaling (AdS) mechanism to improve the adversarial robustness of SSMs. The AdS mechanism significantly enhances robustness by effectively scaling output error during training, addressing the robustness-generalization trade-off. Extensive experiments demonstrate that AdS brings adversarial training performance close to that of attention-integrated SSMs while avoiding robust overfitting. The findings offer valuable insights into designing more robust SSM architectures.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with deep state space models (SSMs) and adversarial robustness. It addresses the critical gap in understanding how to enhance the adversarial robustness of SSMs, a burgeoning area with significant security implications. The proposed adaptive scaling mechanism offers a practical solution to improve robustness without overfitting, opening up new avenues of research and development.
Visual Insights#
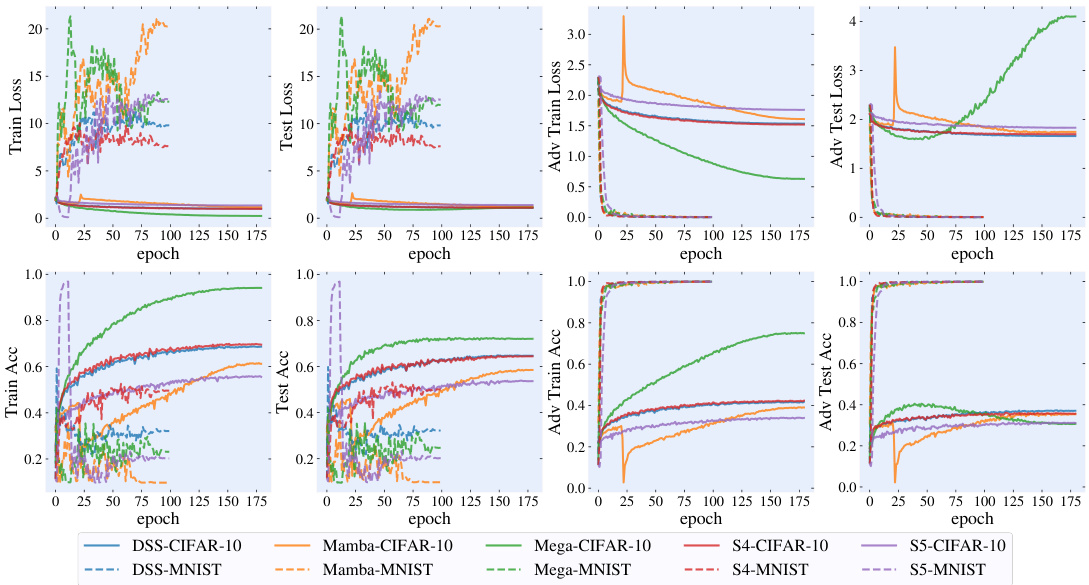
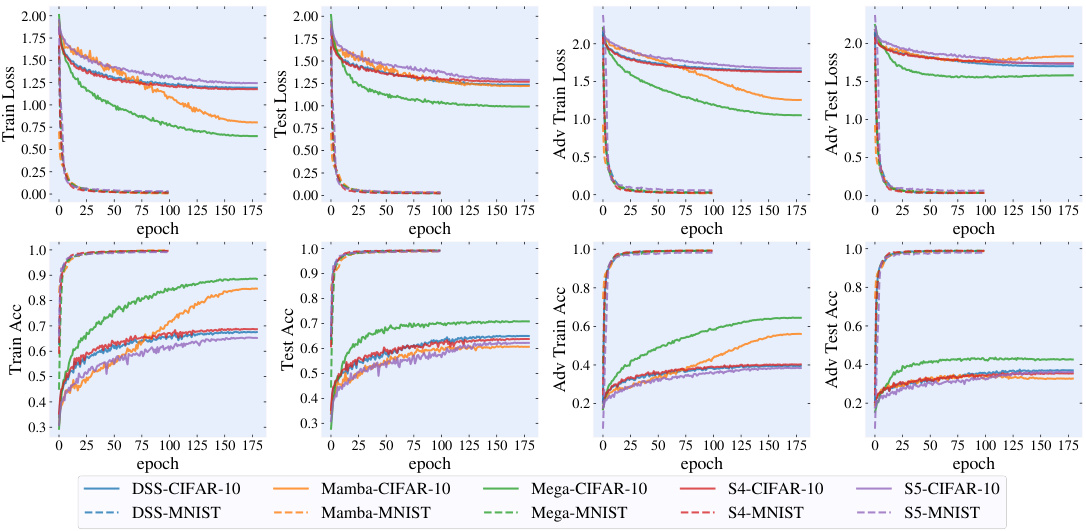
This figure shows the training and testing curves for different SSM architectures (DSS, Mamba, Mega, S4, and S5) on CIFAR-10 and MNIST datasets using PGD-AT. The plots show the training accuracy, training loss, testing accuracy, testing loss, adversarial training accuracy, adversarial training loss, adversarial testing accuracy, and adversarial testing loss over epochs. These curves illustrate the training dynamics, generalization performance, and adversarial robustness of different SSM structures during adversarial training with PGD-AT.
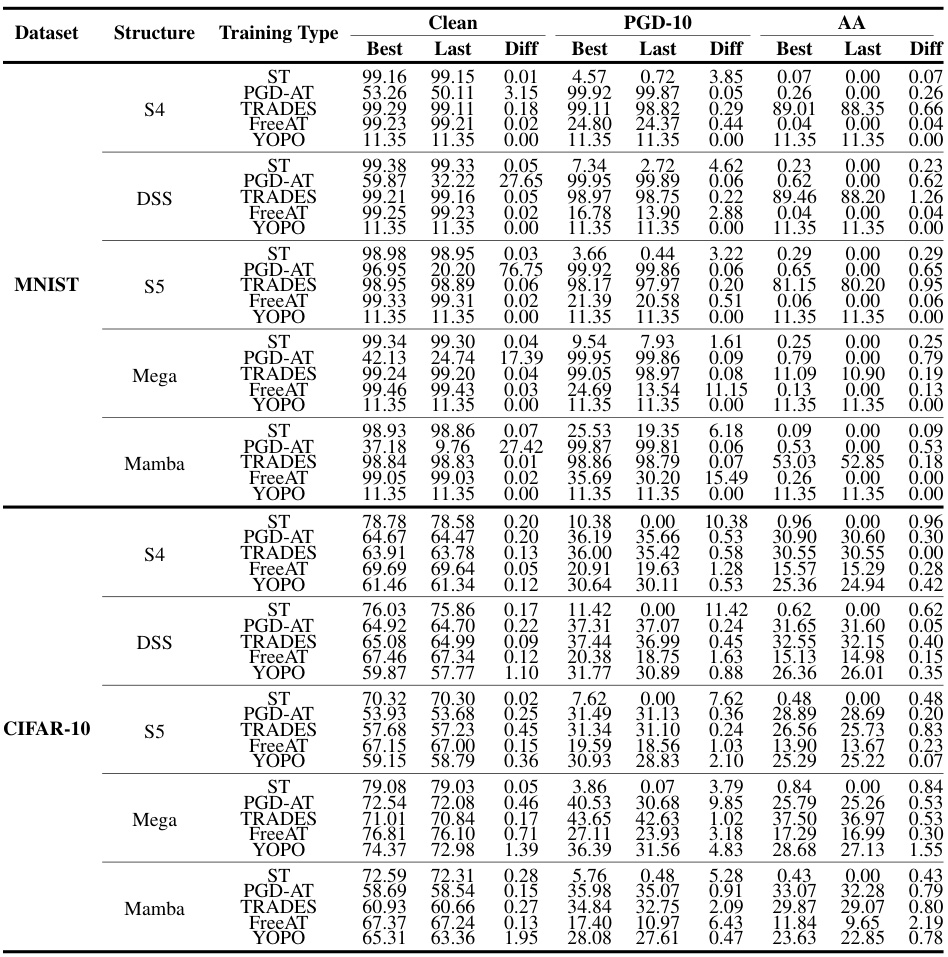
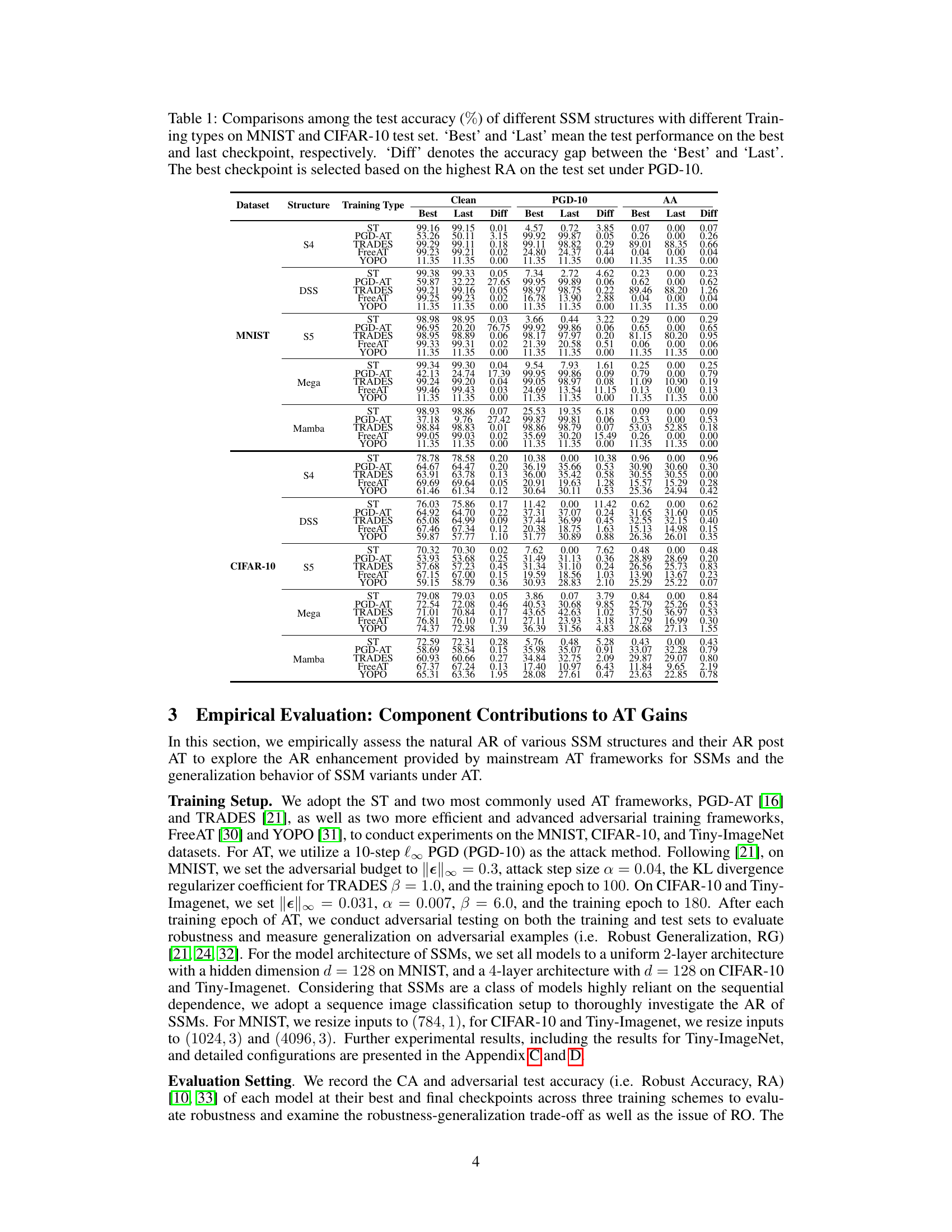
This table presents a comparison of the test accuracy of various SSM structures under different training methods (Standard Training, PGD-AT, TRADES, FreeAT, YOPO) on MNIST and CIFAR-10 datasets. It shows the best and last checkpoint’s accuracy, along with the difference between them. The best checkpoint is determined by the highest robust accuracy (RA) achieved under the PGD-10 attack.
In-depth insights#
SSM’s AR Limits#
The inherent limitations of deep state space models (SSMs) in achieving robust accuracy against adversarial attacks are explored in this section. Fixed-parameter SSMs, due to their structure, have output error bounds directly tied to their parameters, significantly hindering the effectiveness of adversarial training (AT). This limitation restricts their ability to reduce error under attacks, because improvements are bounded by the fixed parameter values. Data-dependent SSMs, while offering more flexibility through adaptive parameterization, face potential error explosion, which makes them unstable during AT. This instability undermines their ability to improve robustness against attacks. Attention mechanisms, though demonstrably improving AT performance by scaling output errors, introduce robust overfitting (RO) due to their complexity. This overfitting reduces the model’s generalizability to unseen adversarial examples. These observations highlight the need for innovative design choices to improve SSM’s adversarial robustness while preventing RO and instability issues.
Attention’s Role#
The integration of attention mechanisms in deep state space models (SSMs) significantly improves adversarial robustness. Attention effectively scales the output error during training, allowing SSMs to better leverage adversarial training (AT) and achieve a superior trade-off between robustness and generalization. However, this benefit comes at a cost: the increased model complexity introduced by attention leads to robust overfitting (RO). This highlights a critical tension in adversarial training; enhanced robustness is attainable but often at the expense of generalization. Further analysis reveals that attention’s adaptive scaling mechanism is key to its success, making it a valuable component to consider when building more robust SSM architectures. However, mitigating the RO issue, perhaps through alternative mechanisms that provide adaptive scaling without excessive complexity, remains a crucial area for future research.
Adversarial Training#
Adversarial training is a defense mechanism against adversarial attacks in machine learning models. The core idea is to augment the training data with adversarial examples—inputs intentionally designed to mislead the model—thereby forcing the model to learn more robust features and become less susceptible to manipulation. The effectiveness of adversarial training is highly dependent on various factors: including the choice of attack method used to generate adversarial examples, the strength of the attack (i.e., the magnitude of perturbations), and the architecture of the model itself. While adversarial training demonstrably enhances model robustness, it also presents trade-offs. A common challenge is that models trained adversarially often experience a drop in accuracy on clean, unperturbed data (a phenomenon known as robustness-generalization trade-off). Robust overfitting, where models achieve high accuracy on adversarial training examples but generalize poorly to unseen adversarial examples, is another crucial consideration. Therefore, despite its benefits, carefully balancing robustness against generalization performance remains a significant area of ongoing research in adversarial training.
Adaptive Scaling#
The concept of ‘Adaptive Scaling’ in the context of enhancing the adversarial robustness of deep state space models (SSMs) addresses the limitations of fixed-parameter SSMs. Fixed-parameter SSMs struggle with adversarial training (AT) because their output error bounds are directly tied to their parameters, hindering the effectiveness of AT. Adaptive scaling offers a solution by dynamically adjusting the model’s output error, enabling it to better differentiate between clean and adversarial inputs. The integration of attention mechanisms provides a form of adaptive scaling, but suffers from robust overfitting (RO) due to increased model complexity. Therefore, Adaptive Scaling is proposed as a simpler, more efficient alternative to achieve similar performance gains without incurring RO. This approach offers a crucial improvement to the robustness and generalization of SSMs, making them more resilient to adversarial attacks in real-world deployments. The key is to effectively scale the model’s output during training, allowing for better handling of adversarial perturbations without excessive complexity. This adaptive mechanism bridges the gap between the limitations of fixed-parameter models and the overfitting issues of attention-based approaches.
Future Works#
Future research could explore several promising avenues. Extending the analysis to other SSM variants and datasets beyond those considered would strengthen the generalizability of the findings. A deeper investigation into the robustness of various attention mechanisms and their interaction with SSM structures is warranted. The study could also be expanded to include different attack strategies and adversarial training techniques to provide a more comprehensive evaluation of adversarial robustness. Furthermore, developing more sophisticated adaptive scaling mechanisms could lead to significant improvements, while theoretical work could focus on deriving tighter error bounds for SSMs under adversarial attacks. Finally, applying these advancements to real-world applications would be a crucial step toward establishing the practical value and security of SSMs in real-world deployment.
More visual insights#
More on figures
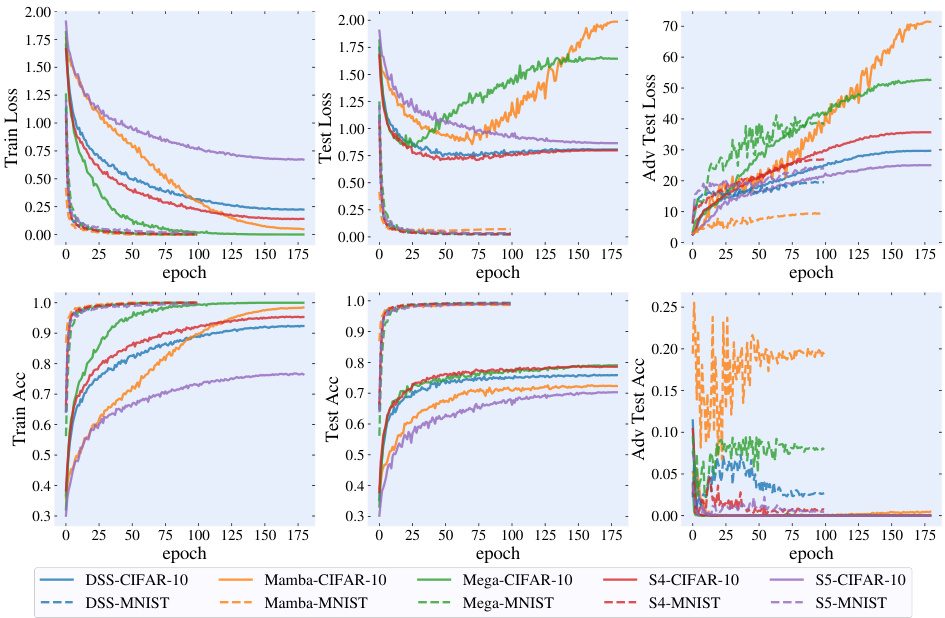
This figure shows the training and testing curves for different SSM architectures trained using the PGD-AT method on the MNIST and CIFAR-10 datasets. The plots illustrate the training accuracy, training loss, testing accuracy, testing loss, adversarial training accuracy, adversarial training loss, adversarial testing accuracy, and adversarial testing loss over the training epochs. Each line represents a different SSM architecture (S4, DSS, Mamba, Mega, S5). The figure visually demonstrates the training dynamics, generalization performance, and robustness to adversarial attacks for each model and dataset.

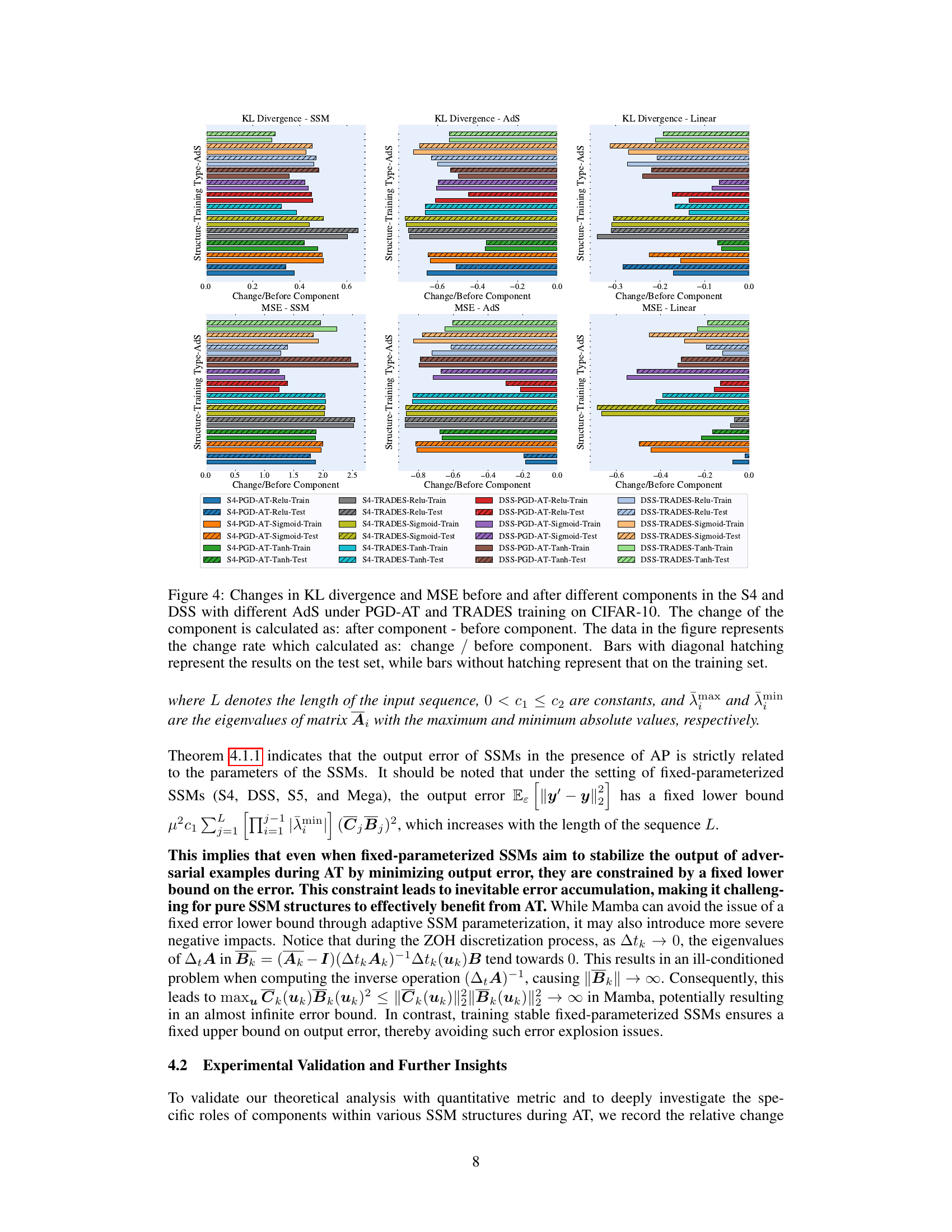
This figure displays the changes in KL divergence and MSE (Mean Squared Error) before and after different components within various SSM (State Space Model) structures. The analysis is performed for both training and testing datasets. The change rate is calculated as the difference between the values after and before the component divided by the before value. This allows for a relative comparison of component effects. The figure visually represents the impact each component has on the model’s performance in terms of KL divergence and MSE, providing insights into their individual contributions to the model’s overall performance under adversarial training.

This figure displays the changes in KL divergence and Mean Squared Error (MSE) before and after different components (SSM, AdS, Linear) within various SSM structures. The changes are calculated as the difference between the values after and before each component, normalized by the value before the component. Separate bars are shown for training and test sets, with diagonal hatching indicating test set results. This helps visualize the impact of individual components on the overall model’s performance regarding adversarial robustness and generalization. The blank spaces indicate that certain components are absent in specific SSM structures.
This figure visualizes the training and testing performance of various SSM models on CIFAR-10 and MNIST datasets under the PGD-AT training framework. It shows training accuracy, training loss, testing accuracy, testing loss, adversarial training accuracy, adversarial training loss, adversarial testing accuracy, and adversarial testing loss across epochs. The plots illustrate how the models perform on clean data and how robust they are against adversarial attacks. The graphs provide a visual comparison of model training and robustness across different datasets and illustrate the effectiveness of adversarial training.
More on tables
This table presents a comparison of the test accuracy of various SSM structures under different training methods (Standard Training, PGD-AT, TRADES, FreeAT, and YOPO) on MNIST and CIFAR-10 datasets. It shows the clean accuracy, accuracy under PGD-10 adversarial attacks, and accuracy under AutoAttack. ‘Best’ and ‘Last’ represent the test performance at the best and last checkpoints, respectively, with ‘Diff’ showing the difference. The best checkpoint is chosen based on the highest Robust Accuracy (RA) achieved under PGD-10 attacks.
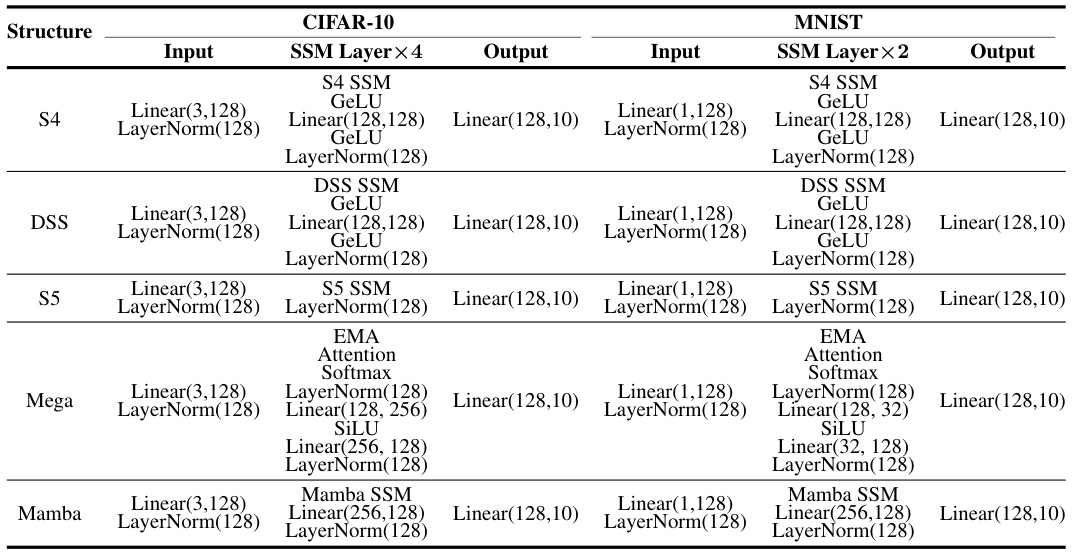
This table compares the test accuracy of various SSM structures under different training methods (standard training, PGD-AT, TRADES, FreeAT, and YOPO) on the MNIST and CIFAR-10 datasets. It shows the best and last checkpoint’s performance, highlighting the difference between them. The ‘best’ checkpoint is selected based on the highest Robust Accuracy (RA) achieved under PGD-10 adversarial attacks.
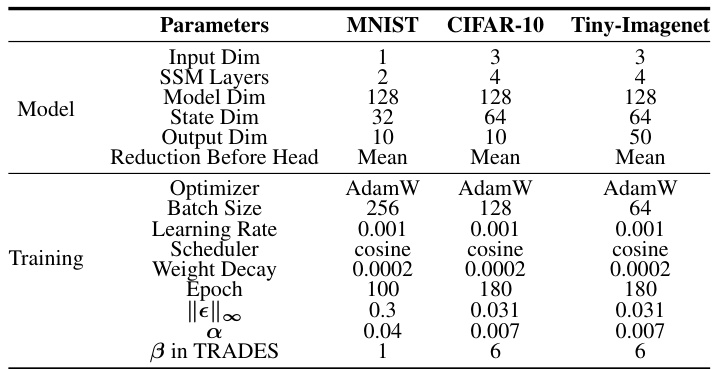
This table details the model architecture and training hyperparameters used in the experiments. It shows the input dimensions, number of SSM layers, model dimensions, state dimensions, output dimensions, and reduction method before the output head for each dataset (MNIST, CIFAR-10, and Tiny-Imagenet). Training parameters such as the optimizer, batch size, learning rate, scheduler, weight decay, number of epochs, and adversarial attack parameters (for adversarial training) are also specified for each dataset.

This table compares the test accuracy of various SSM structures under different training methods (Standard Training, PGD-AT, TRADES, FreeAT, and YOPO) on MNIST and CIFAR-10 datasets. It shows the performance at both the best and last checkpoints, indicating the robustness-generalization trade-off and the level of robust overfitting. The best checkpoint is chosen based on the highest robust accuracy under PGD-10 attacks.
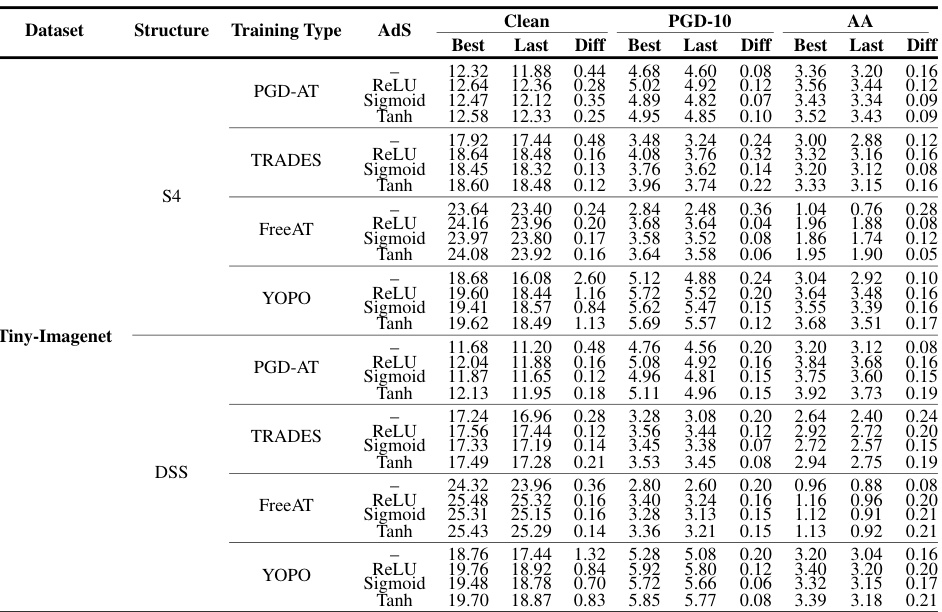
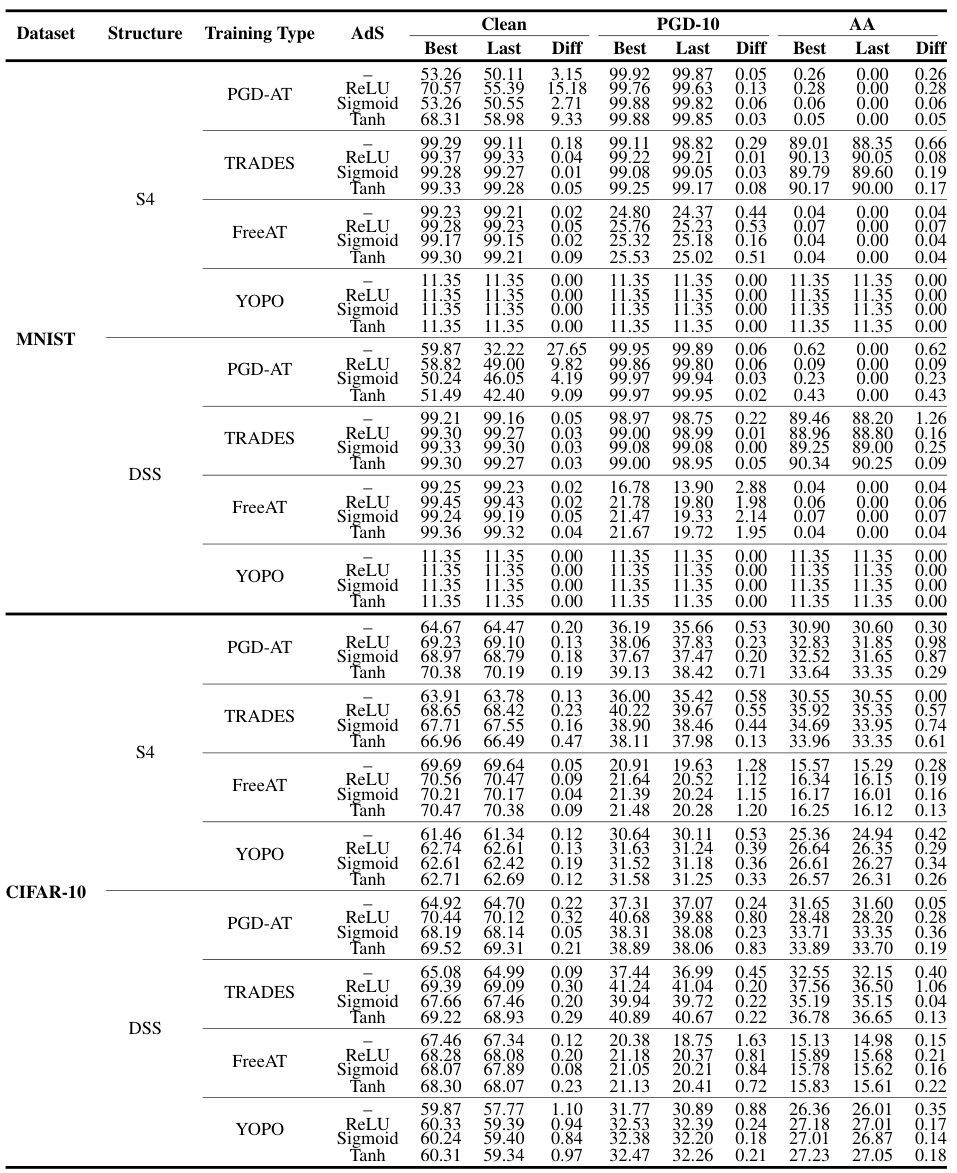
This table presents a comparison of the test accuracy of two different SSM structures (S4 and DSS) on the Tiny-Imagenet dataset under various adversarial training (AT) methods (PGD-AT, TRADES, FreeAT, YOPO). It also explores the impact of different adaptive scaling (AdS) modules (ReLU, Sigmoid, Tanh) on the model’s performance. The table shows the best and last epoch’s clean accuracy (CA), robust accuracy (RA) under PGD-10, and robust accuracy under AutoAttack (AA). The ‘Diff’ column shows the difference in accuracy between the best and last epoch. The best epoch is determined by the highest RA under PGD-10.
Full paper#