↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Softmax attention, while effective, suffers from quadratic complexity, limiting its use with high-resolution images. Linear attention, while offering linear complexity, has demonstrated unsatisfactory performance in practice, hindering wider adoption. The core reasons for this performance gap are poorly understood.
This paper delves into the fundamental differences between linear and softmax attention. It introduces two key concepts—injectivity and local modeling—to explain the performance discrepancy. The authors propose InLine attention, a modified linear attention method. By enhancing injectivity and local modeling, InLine attention outperforms softmax attention on various tasks, offering both higher accuracy and lower computational costs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the conventional wisdom that linear attention is inferior to softmax attention. By identifying key limitations and proposing effective solutions, it opens avenues for developing computationally efficient and high-performing vision transformers, particularly relevant in handling high-resolution images. This work also contributes novel theoretical understanding of attention mechanisms.
Visual Insights#
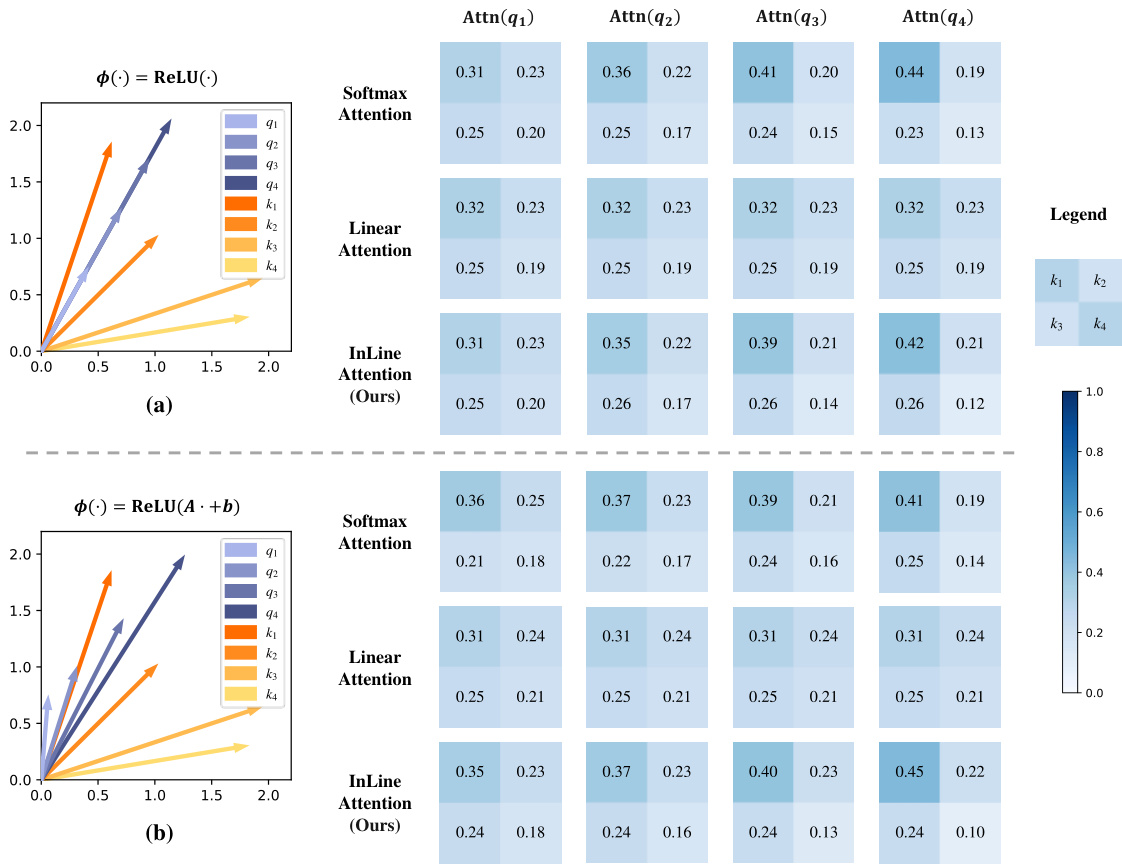
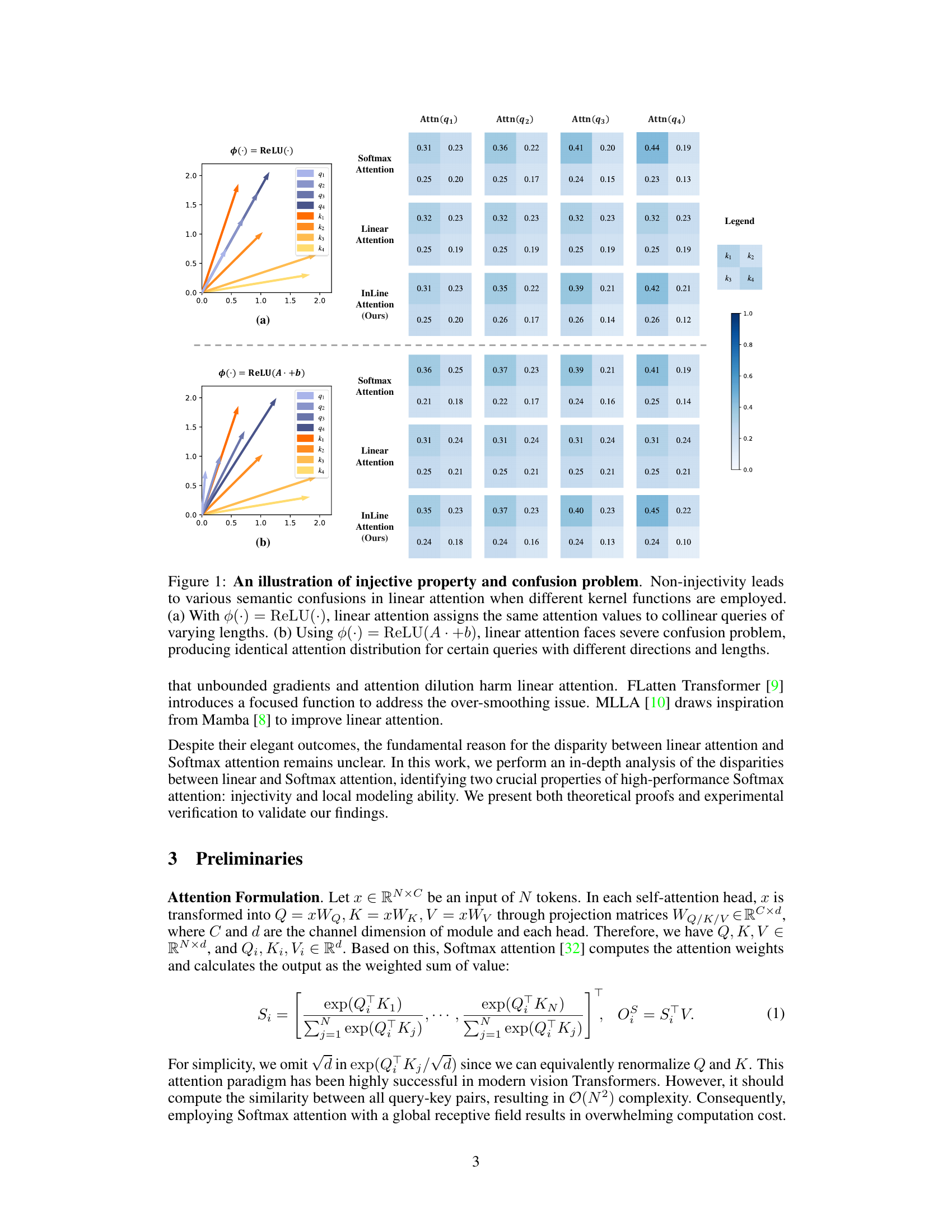
This figure demonstrates the impact of the injective property on linear attention’s performance. It shows that when different kernel functions (ReLU and ReLU(A·+b)) are used, linear attention is not injective, assigning the same attention values to different queries, leading to semantic confusion. The figure uses examples of collinear queries with varying lengths to illustrate this issue, contrasting them to softmax attention which shows no such confusion.

This table shows the ImageNet-1K classification accuracy of different models when masking out tokens from various positions. The masking strategies include removing tokens from local square windows of different sizes (3x3, 5x5, 7x7) and randomly masking out a set number of tokens (9, 25, 49) from a 3x3 local window. The results demonstrate the importance of local modeling for attention mechanisms.
In-depth insights#
Injective Attention#
The concept of “Injective Attention” in the context of a research paper likely explores how attention mechanisms can be designed to ensure that distinct input features (queries) are mapped to unique attention distributions. A non-injective attention mechanism would map multiple queries to the same distribution, leading to information loss and reduced model performance. Injectivity, therefore, becomes a crucial property for effective attention, as it guarantees that different inputs are processed and distinguished appropriately. The paper might investigate different attention mechanisms (e.g., softmax, linear) and analyze their injectivity properties. Strategies for constructing injective attention might include novel similarity functions or architectural modifications to the attention layer. The implications of ensuring injectivity in the context of the research might include improved model expressivity, better generalization, and potentially higher accuracy on downstream tasks. This is especially pertinent to high-resolution input scenarios where a non-injective mechanism could lead to catastrophic failures by conflating dissimilar features.
Local Modeling#
The concept of ‘Local Modeling’ within the context of attention mechanisms is crucial. Effective attention mechanisms don’t solely rely on long-range dependencies; they also leverage local information effectively. The paper highlights that while global receptive fields are beneficial, a strong local modeling capability significantly boosts performance. This is demonstrated through empirical analysis showing that Softmax attention, despite its global reach, exhibits a substantial local bias, contributing to its success. In contrast, linear attention, while computationally efficient, often lacks this crucial local modeling aspect, leading to performance limitations. The research emphasizes that enhancing local modeling in linear attention, through techniques like introducing local attention residuals, can bridge the performance gap with Softmax attention, ultimately achieving superior results while maintaining computational efficiency. The interplay between local and global modeling is key, and the paper provides valuable insights into this critical balance for designing effective attention mechanisms.
Linear Attn Wins#
The hypothetical heading, “Linear Attn Wins,” suggests a significant finding in a research paper comparing linear and softmax attention mechanisms. A likely scenario is that the authors have devised modifications or novel architectures to overcome the limitations of traditional linear attention, demonstrating superior performance compared to softmax attention. This could involve addressing issues such as the lack of injectivity or insufficient local modeling ability commonly associated with linear attention. The “win” implies a substantial improvement in speed, efficiency, or accuracy, perhaps surpassing softmax attention’s effectiveness across various benchmarks, while maintaining or even lowering computational complexity. Such results could be a major advancement in the field, enabling the efficient implementation of transformer-based models on larger-scale datasets and more complex tasks. The core of the paper would likely focus on explaining the techniques used to overcome the drawbacks of linear attention, potentially introducing novel theoretical analyses or empirical validation to support their claims.
Swin Transformer#
The Swin Transformer represents a significant advancement in vision transformers, addressing limitations of earlier architectures. Its core innovation lies in the hierarchical architecture and shifted window attention mechanism. This approach allows for efficient computation of long-range dependencies while maintaining high resolution image processing. Hierarchical feature extraction enables the model to capture both local and global context effectively, leading to superior performance on various tasks. The use of shifted windows prevents repetitive attention calculations, improving computational efficiency further. These design choices provide a good balance between efficiency and effectiveness, leading to state-of-the-art results, especially on high-resolution images. However, the Swin Transformer’s effectiveness is tied to the specific design choices, particularly its window-based approach, and may not generalize perfectly to all scenarios. Future research could explore variations and extensions to this architecture that can further improve efficiency and adaptability. The introduction of Swin Transformer has had a notable impact on the field of computer vision, influencing subsequent work and setting a new standard for efficiency and accuracy in vision transformers.
Future Directions#
Future research could explore several promising avenues. Improving the injectivity of linear attention is crucial; developing more sophisticated kernel functions or alternative normalization techniques could enhance its ability to distinguish between semantically different queries. Investigating the interaction between injectivity and local modeling is key to unlocking the full potential of linear attention. Further empirical validation across diverse tasks and datasets, particularly high-resolution images, would strengthen the findings and demonstrate generalizability. Finally, exploring the integration of injective linear attention with other state-of-the-art attention mechanisms and architectures represents a significant opportunity to advance the field.
More visual insights#
More on figures
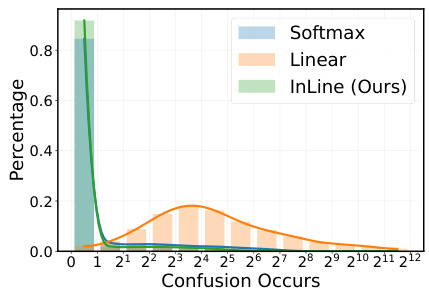
This figure shows the distributions of the number of times each image in the ImageNet validation set experienced confusion for Softmax, Linear, and InLine attention. The x-axis represents the number of times confusion occurred, while the y-axis shows the percentage of images experiencing that level of confusion. The graph visually demonstrates the significant reduction in confusion instances achieved by InLine attention compared to Linear attention, while Softmax attention shows negligible confusion.

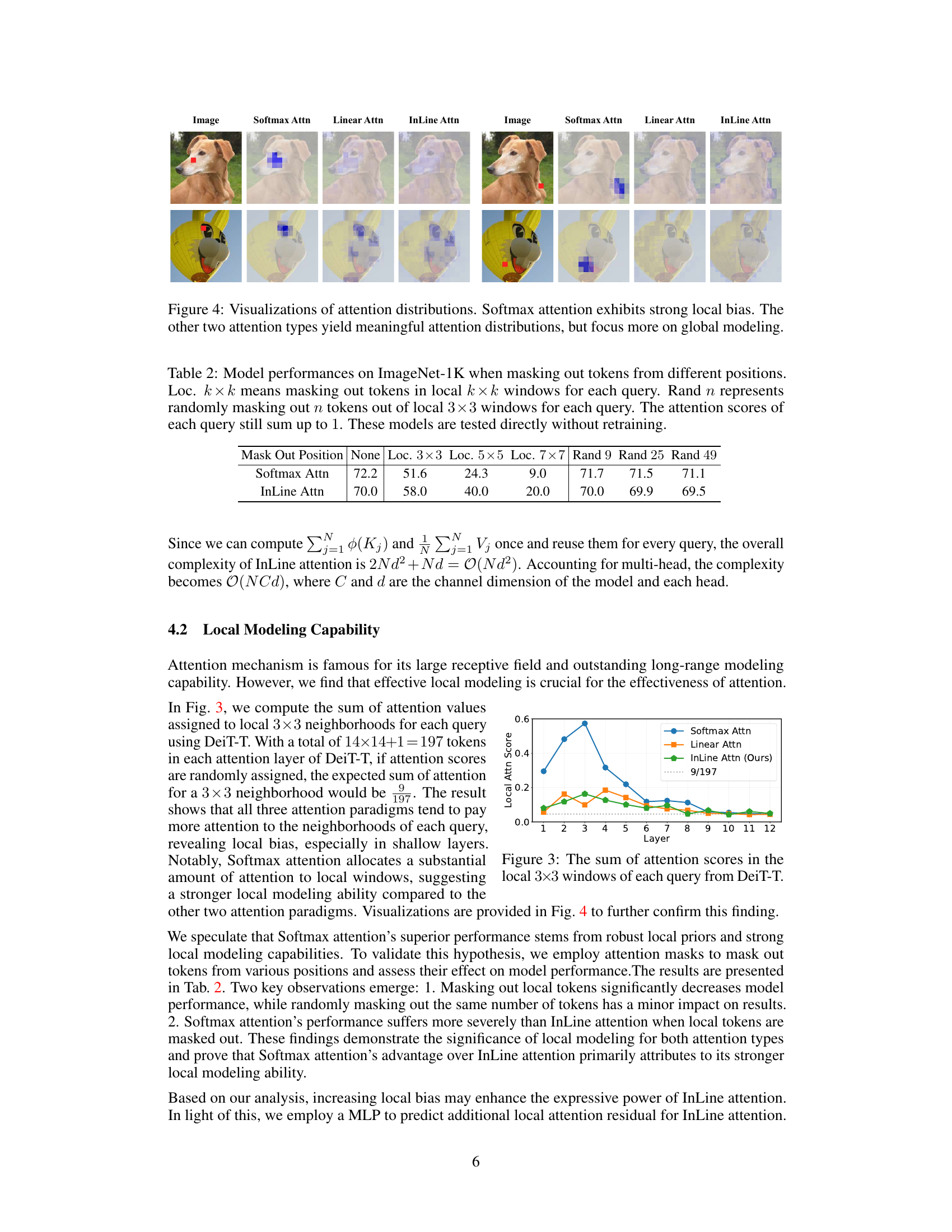
This figure visualizes the attention distributions produced by Softmax attention, linear attention, and InLine attention on two example images. It demonstrates that Softmax attention focuses more on local details within the image, as indicated by the concentrated attention weights. Conversely, linear attention and InLine attention show more distributed attention across the images, suggesting a greater focus on global contextual information rather than specific local regions.
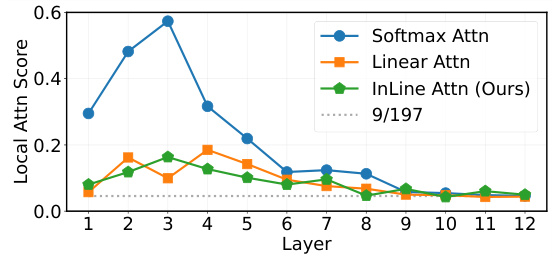
This figure shows the sum of attention weights assigned to the 3x3 neighborhood of each query token across different layers of the DeiT-T model. It compares the local attention behavior of Softmax attention, linear attention, and the proposed InLine attention. The plot reveals that Softmax attention exhibits a stronger local bias, particularly in the shallower layers, while linear attention and InLine attention show less focus on local neighborhoods. The horizontal dotted line represents the expected average attention weight for a 3x3 window if attention were randomly assigned (9/197).
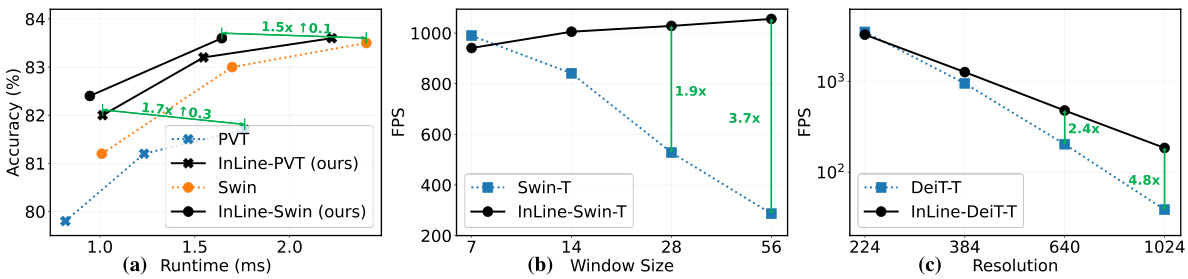
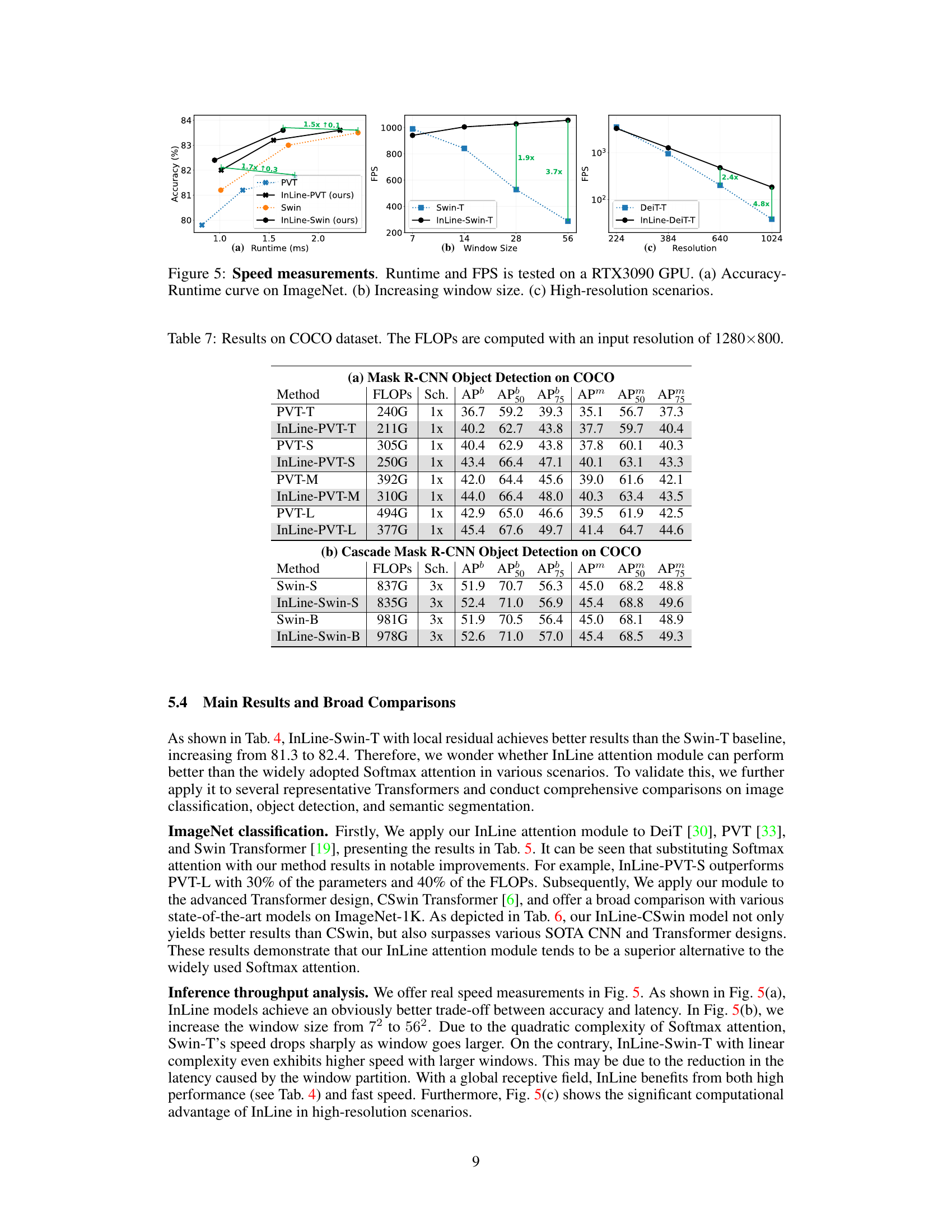
This figure presents a comprehensive analysis of the speed and efficiency of InLine attention compared to traditional Softmax attention and other linear attention methods. Three subfigures illustrate different aspects: (a) shows the trade-off between accuracy and runtime on the ImageNet dataset, demonstrating that InLine achieves higher accuracy with similar runtime or faster runtime with similar accuracy; (b) evaluates performance as the window size increases, showing InLine’s superior scalability; (c) focuses on high-resolution image processing, revealing InLine’s significant computational advantages over other methods. This figure supports the paper’s claim of InLine attention’s enhanced efficiency and speed, particularly in high-resolution scenarios.
More on tables

This table shows the ablation study of the injective property on Swin-T model. It compares the performance of linear attention and InLine attention with different kernel functions: ReLU(.), ReLU(A·+b), LeakyReLU(.), and Identity(.). The results demonstrate that the InLine attention significantly improves the performance, especially when using kernel functions with stronger nonlinearities, highlighting the importance of the injective property for better model performance.

This table presents an ablation study on the impact of local modeling ability in the Swin-T model using the Identity kernel function. It shows the performance (accuracy) of the InLine-Swin-T model with different window sizes (7x7, 14x14, 28x28, 56x56), both with and without residual connections. The results demonstrate the importance of local modeling for effective attention.
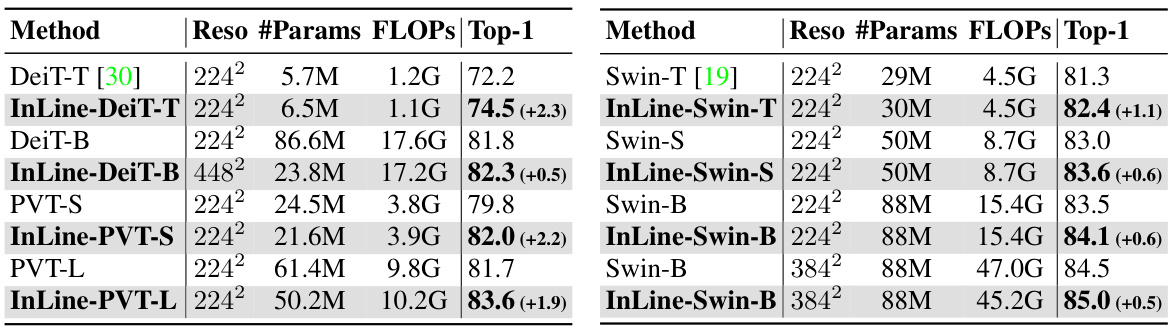
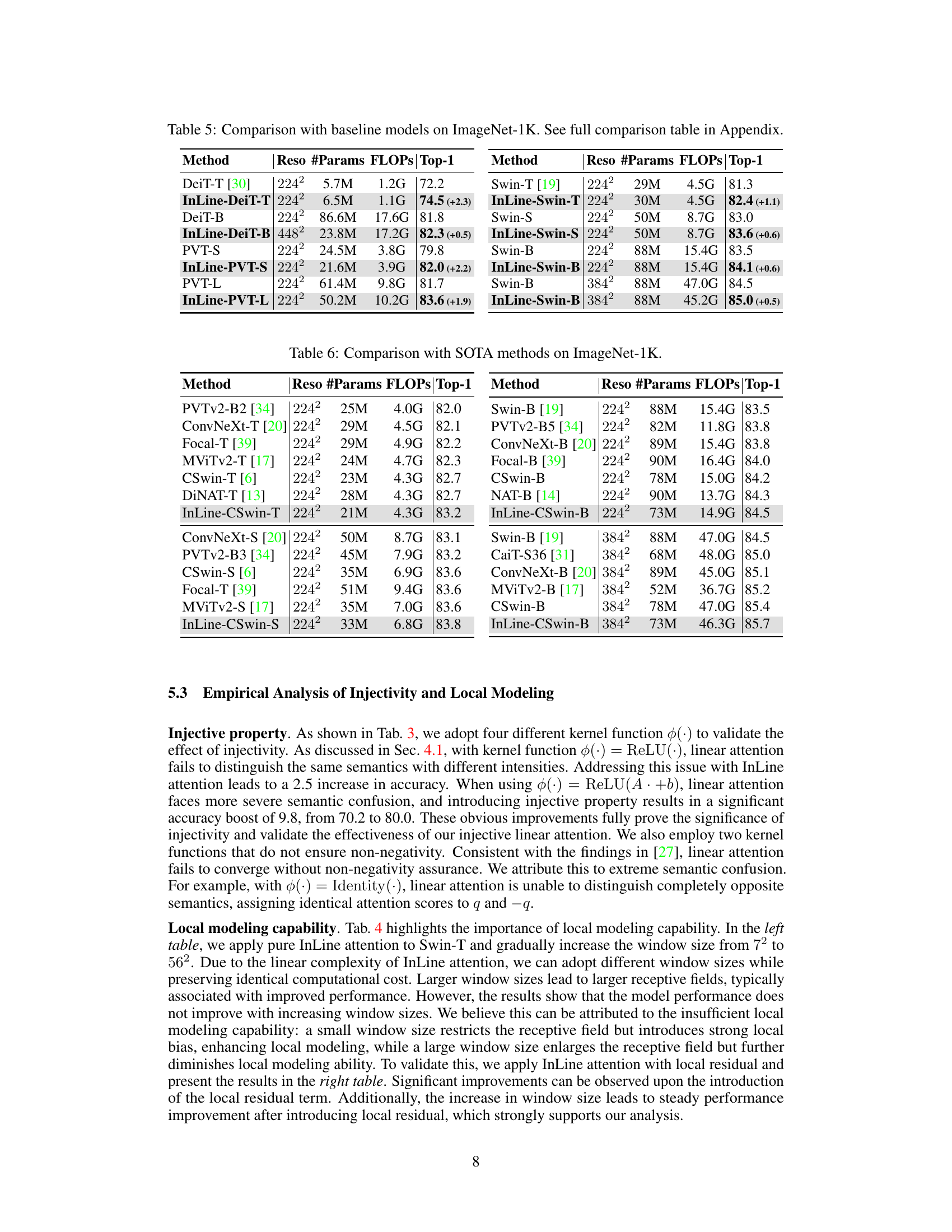
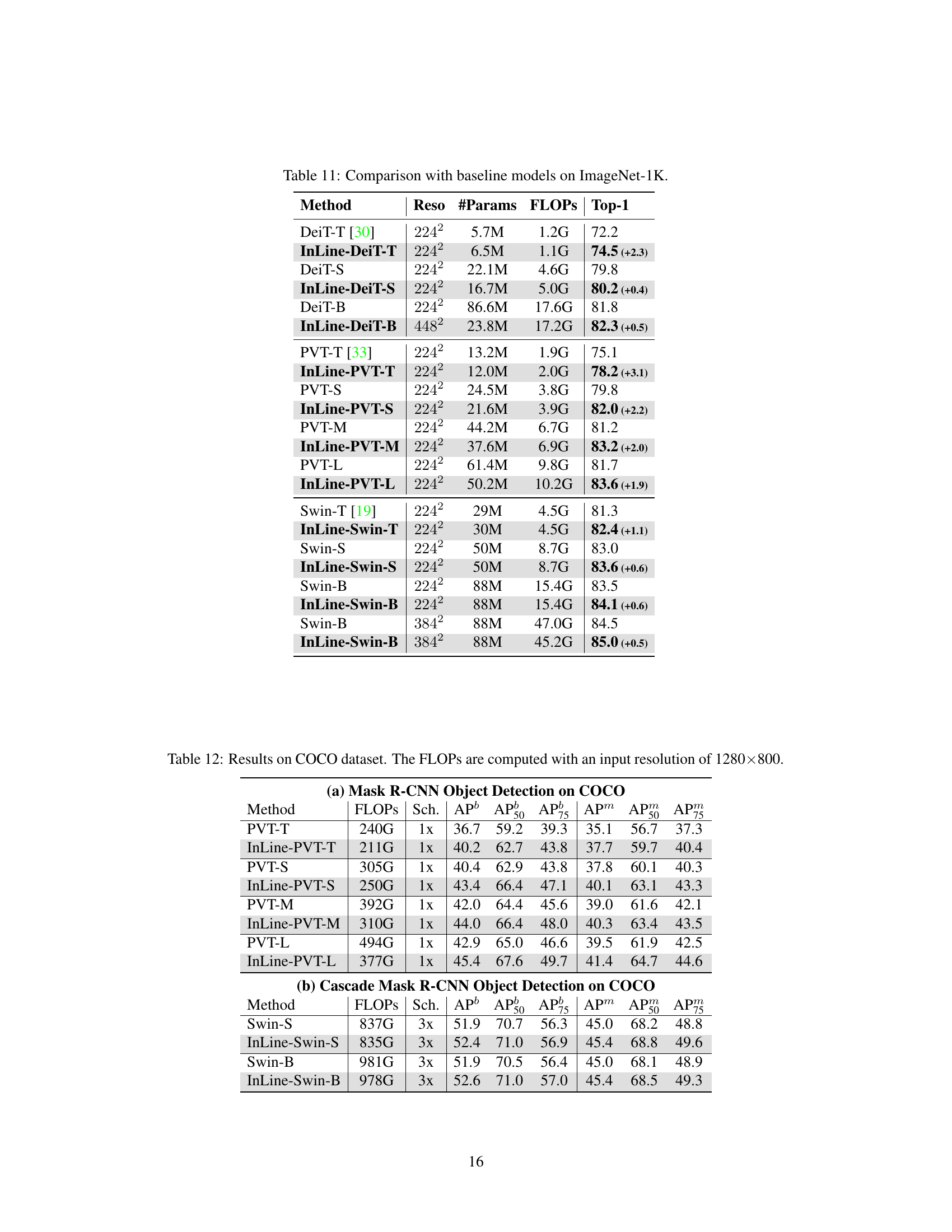
This table compares the performance of the proposed InLine attention method with various baseline models on the ImageNet-1K dataset. It shows the resolution, number of parameters, FLOPs (floating point operations), and Top-1 accuracy for each model. The results demonstrate the improved accuracy achieved by InLine compared to baseline models, with a note indicating the accuracy gain in parentheses.
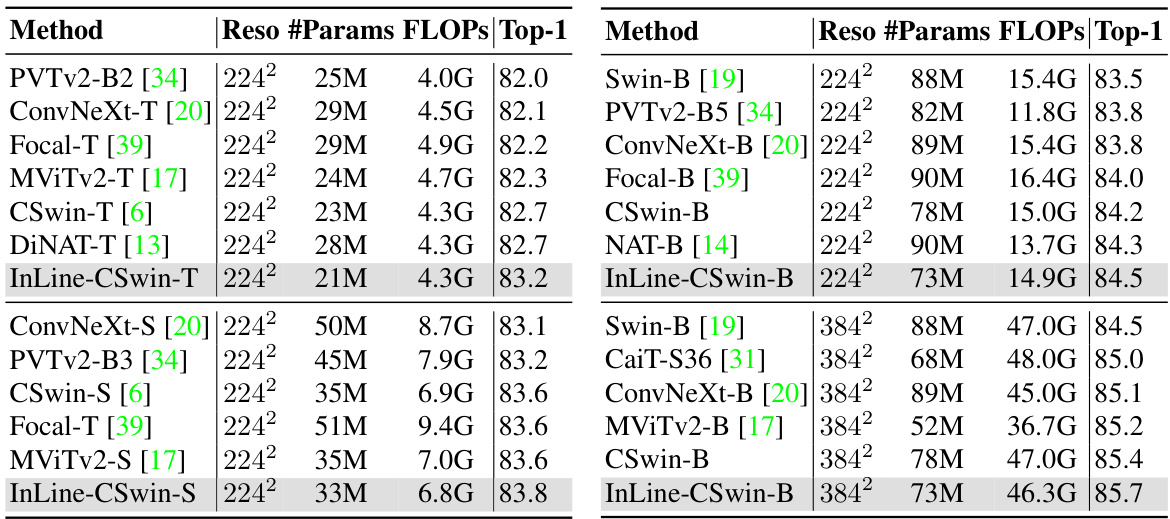
This table compares the performance of different vision transformer models, including those using the proposed InLine attention mechanism, on the ImageNet-1K image classification benchmark. It shows the resolution, number of parameters, floating point operations (FLOPs), and top-1 accuracy for each model. The table highlights the improved performance achieved by incorporating InLine attention compared to the baseline models.
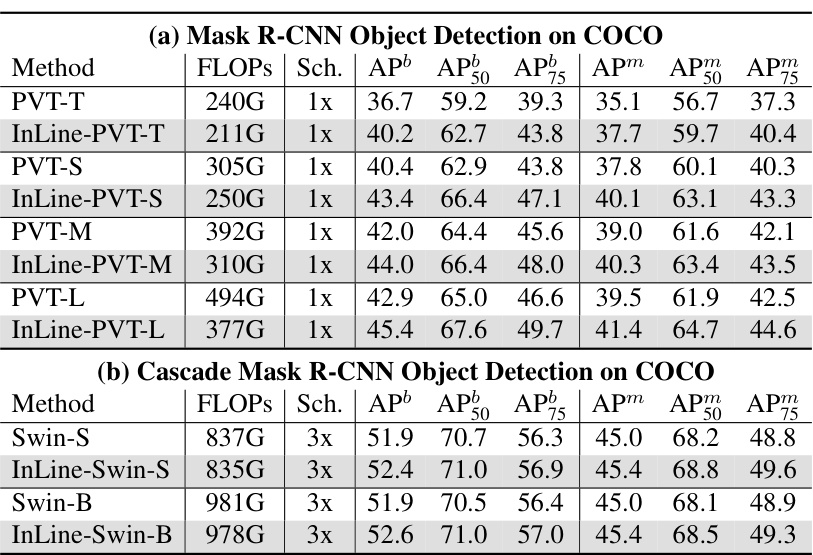
This table shows the performance comparison of different models on the COCO dataset for object detection. It compares the FLOPs (floating point operations), scheduling (Sch.), and Average Precision (AP) metrics at different intersection over union (IoU) thresholds (AP50, AP75, APm, APm50, APm75) for both Mask R-CNN and Cascade Mask R-CNN object detection approaches. InLine-PVT and InLine-Swin models are compared to their respective baseline models (PVT and Swin).
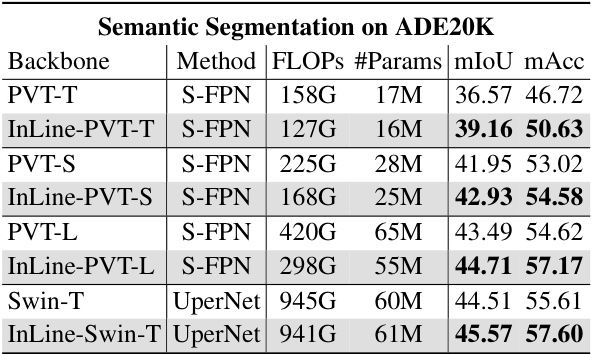
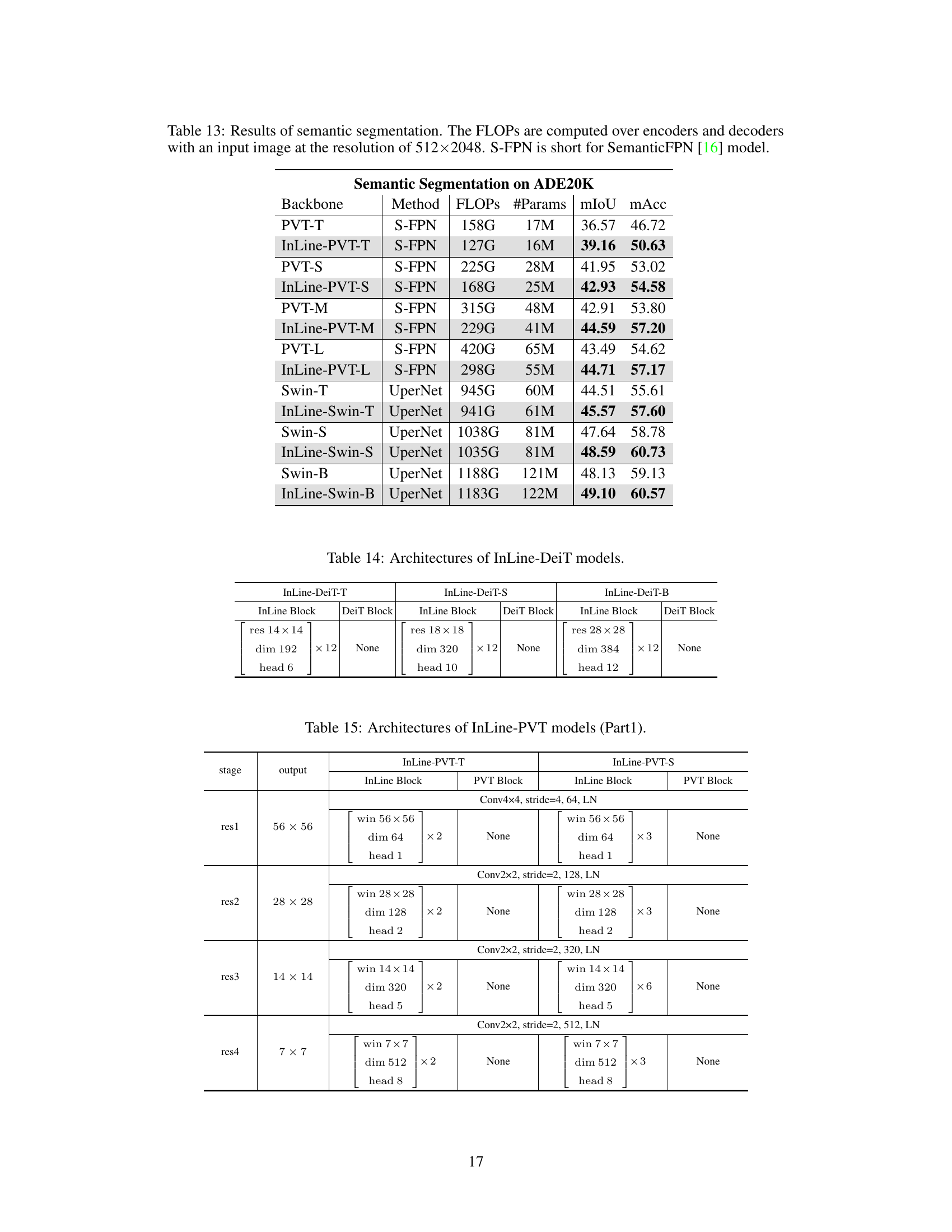
This table presents the results of semantic segmentation experiments on the ADE20K dataset. It compares the performance of the Softmax and InLine attention mechanisms (InLine-PVT and InLine-Swin) within the SemanticFPN and UperNet models. The table shows FLOPs, the number of parameters, mean Intersection over Union (mIoU), and mean accuracy (mAcc) for each model, highlighting the improved performance of InLine attention.

This table compares the performance of several linear attention methods, including the proposed InLine attention, using the DeiT-T model on the ImageNet-1K dataset. The comparison focuses on the accuracy achieved by each method while maintaining a similar number of parameters and FLOPs (floating point operations). This highlights the relative efficiency and accuracy gains of the InLine attention approach compared to other state-of-the-art linear attention mechanisms.
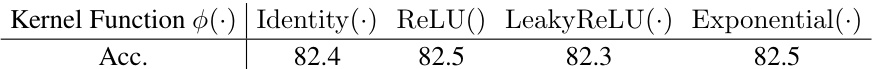
This table shows the ablation study of different kernel functions used in the InLine-Swin-T model. The accuracy results are presented for each kernel function: Identity, ReLU, LeakyReLU, and Exponential. The results demonstrate the impact of the kernel function choice on the overall model performance.
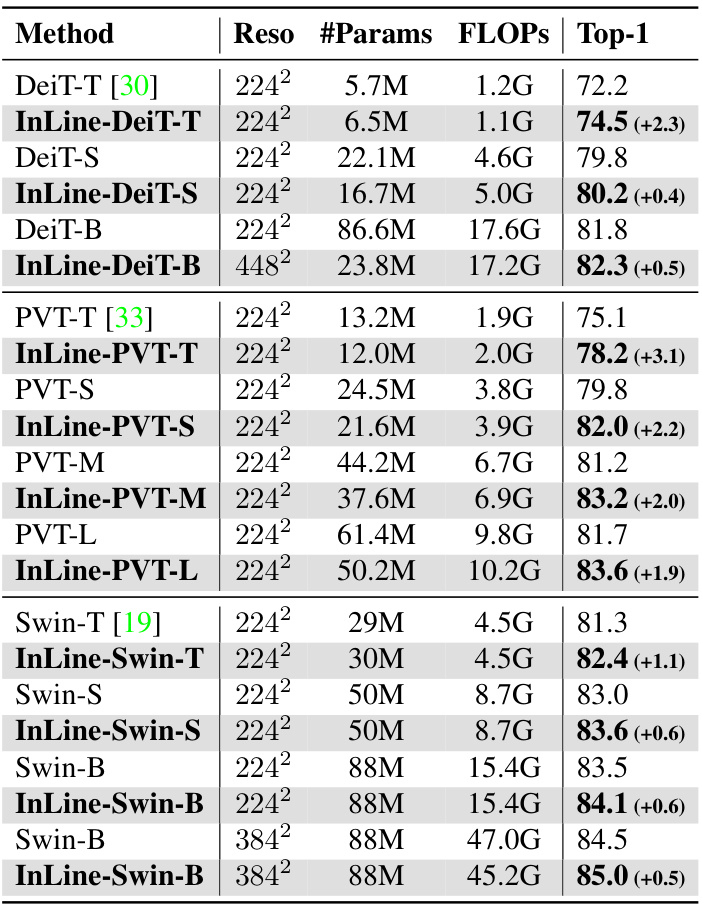
This table compares the performance of the proposed InLine attention method against several baseline models (DeiT, PVT, Swin) on the ImageNet-1K dataset. It shows the resolution, number of parameters, FLOPs (floating point operations), and top-1 accuracy for each model. The improvements achieved by InLine are presented in parentheses. The full table with more model comparisons can be found in the appendix.

This table shows the performance of different models on the COCO dataset for object detection. It compares the standard models with the InLine versions. Metrics include FLOPs (floating point operations), scheduling, Average Precision (AP) at different Intersection over Union (IoU) thresholds (AP50, AP75), and average precision across all IoU thresholds (APm). The results are broken down for Mask R-CNN and Cascade Mask R-CNN object detection.
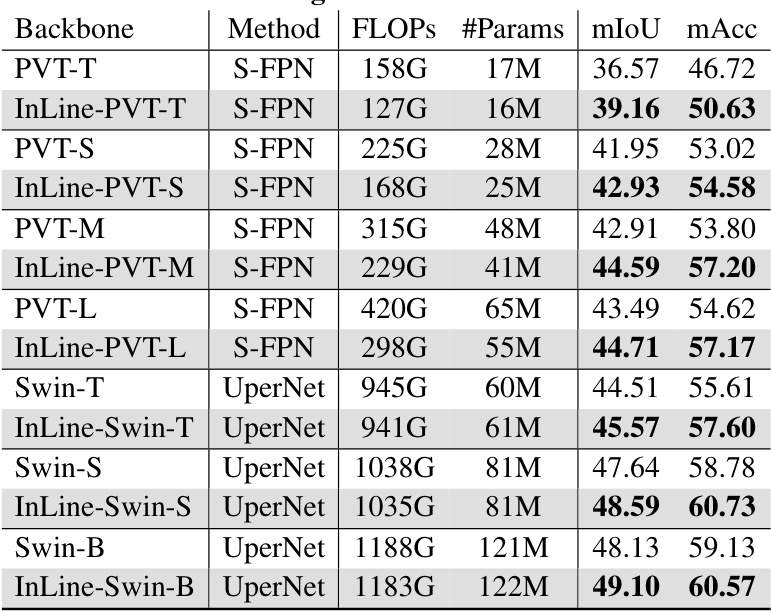
This table presents the results of semantic segmentation experiments using different backbones (PVT-T, PVT-S, PVT-M, PVT-L, Swin-T, Swin-S, Swin-B) with and without the InLine attention mechanism. The results are compared using the SemanticFPN and UperNet models, reporting FLOPs, the number of parameters, mean Intersection over Union (mIoU), and mean accuracy (mAcc). It showcases the performance gains achieved by incorporating InLine attention.
This table compares the performance of the proposed InLine attention models against baseline models (DeiT, PVT, Swin) on the ImageNet-1K dataset. It shows the resolution, number of parameters, FLOPs (floating point operations), and Top-1 accuracy for each model. The improvement achieved by InLine attention is indicated in parentheses. The table highlights that InLine attention consistently improves the performance compared to the baselines, especially in the larger models where the computational advantages are more prominent.
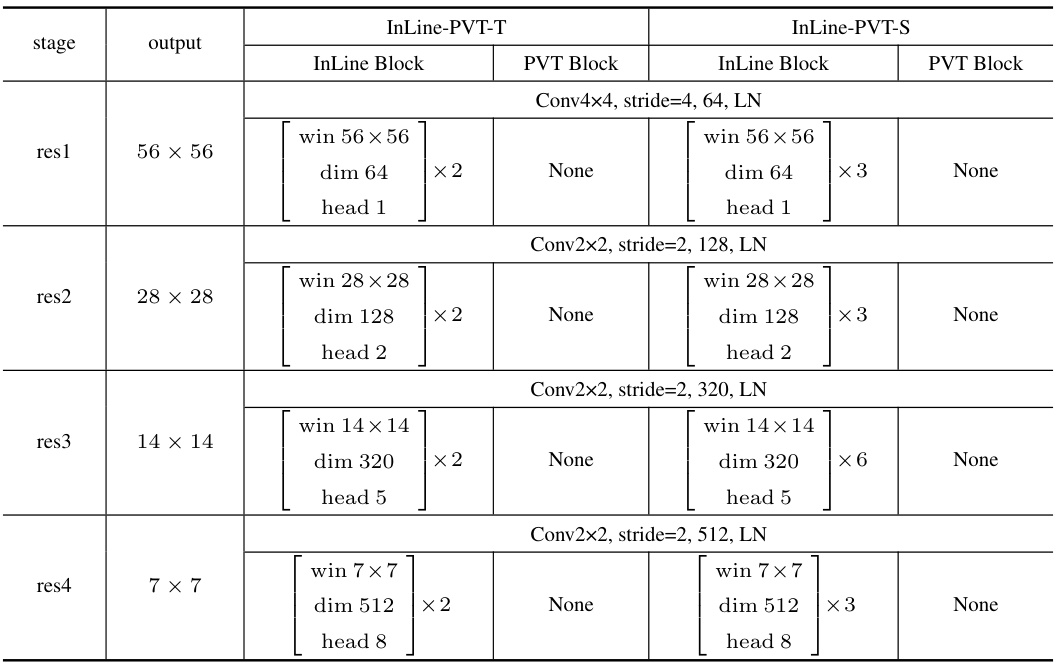
This table compares the performance of the proposed InLine attention method against several baseline models on the ImageNet-1K dataset. The comparison includes metrics like resolution, number of parameters, FLOPs (floating-point operations), and Top-1 accuracy. Positive differences in accuracy are shown in parentheses, indicating performance improvement achieved by InLine over the baseline methods. A more comprehensive table with additional comparisons is available in the appendix.
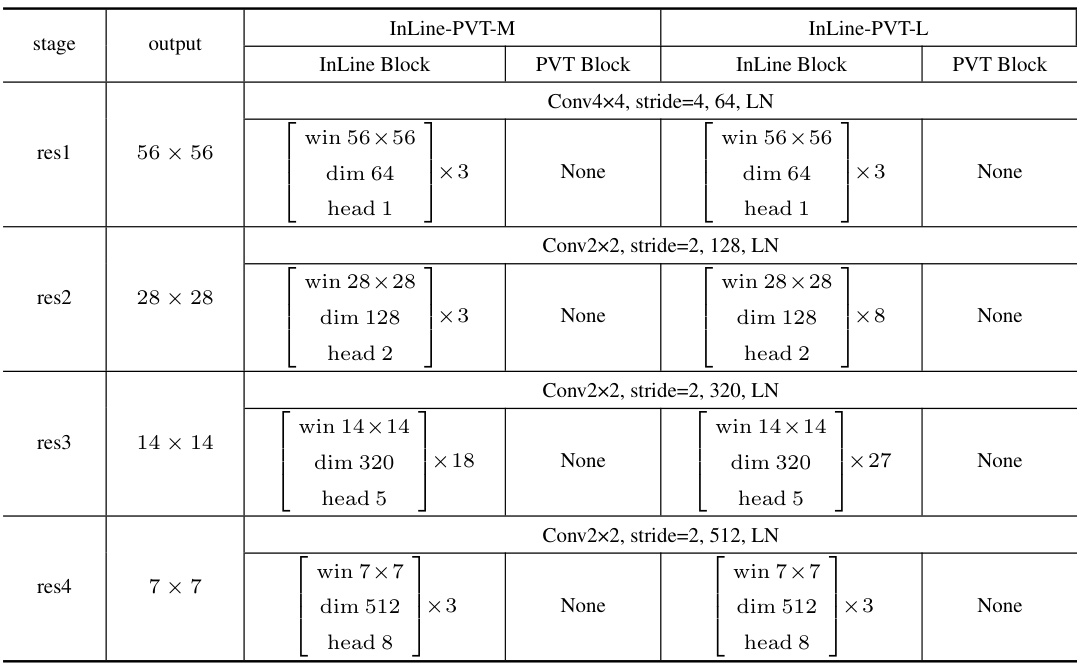
This table compares the performance of the proposed InLine attention with several baseline models on the ImageNet-1K dataset. It shows the resolution, number of parameters, FLOPs (floating-point operations), and top-1 accuracy for each model. The results demonstrate the improved performance and efficiency of InLine attention compared to the baselines. A more comprehensive table is available in the appendix.
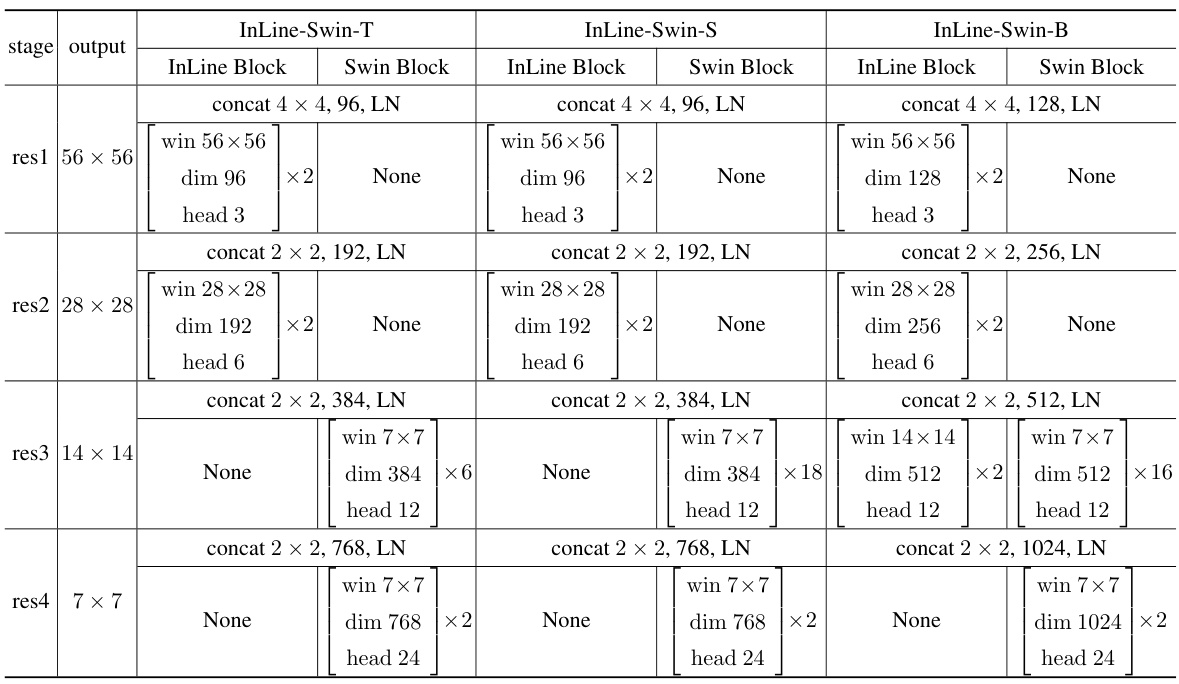
This table compares the performance of the proposed InLine attention method with several baseline models on the ImageNet-1K image classification dataset. It shows the resolution, number of parameters, FLOPs (floating point operations), and top-1 accuracy for each model. The table highlights the improvements achieved by InLine attention over the baseline models.
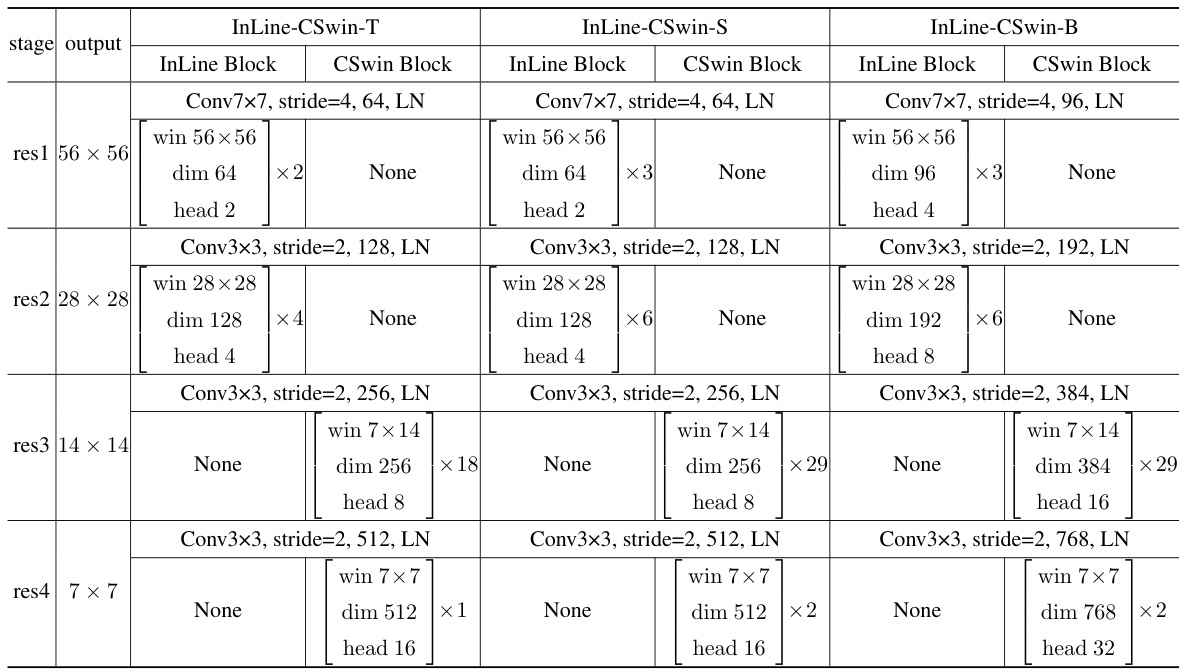
This table compares the performance of the proposed InLine attention with several baseline models on the ImageNet-1K dataset. The table shows the resolution, number of parameters, FLOPs (floating-point operations), and top-1 accuracy for each model. A full comparison table with additional models is available in the appendix.
Full paper#