↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing image fusion methods often rely on fixed fusion paradigms, limiting their adaptability and applicability to various scenarios. This research introduces a conditional controllable fusion (CCF) framework to overcome this limitation. CCF leverages the generative capabilities of denoising diffusion probabilistic models (DDPMs) and does not require any task-specific training.
The CCF framework dynamically selects fusion constraints, injecting them into the DDPM as adaptive conditions at each reverse diffusion stage. This ensures that the fusion process is responsive to specific requirements and enables step-by-step calibration of fused images. Extensive experiments demonstrate CCF’s effectiveness across diverse image fusion scenarios, outperforming competing methods without the need for additional training. The publicly available code further enhances the accessibility and impact of this research.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel framework for general image fusion tasks that is both controllable and training-free. This addresses a critical limitation of existing methods, which are often tailored to specific scenarios, making them less adaptable to diverse applications. The proposed framework, CCF, utilizes denoising diffusion models to dynamically select appropriate fusion constraints, effectively calibrating the fusion process step-by-step. This breakthrough paves the way for more flexible, adaptable, and efficient image fusion solutions across various domains, enhancing the performance of downstream computer vision tasks.
Visual Insights#
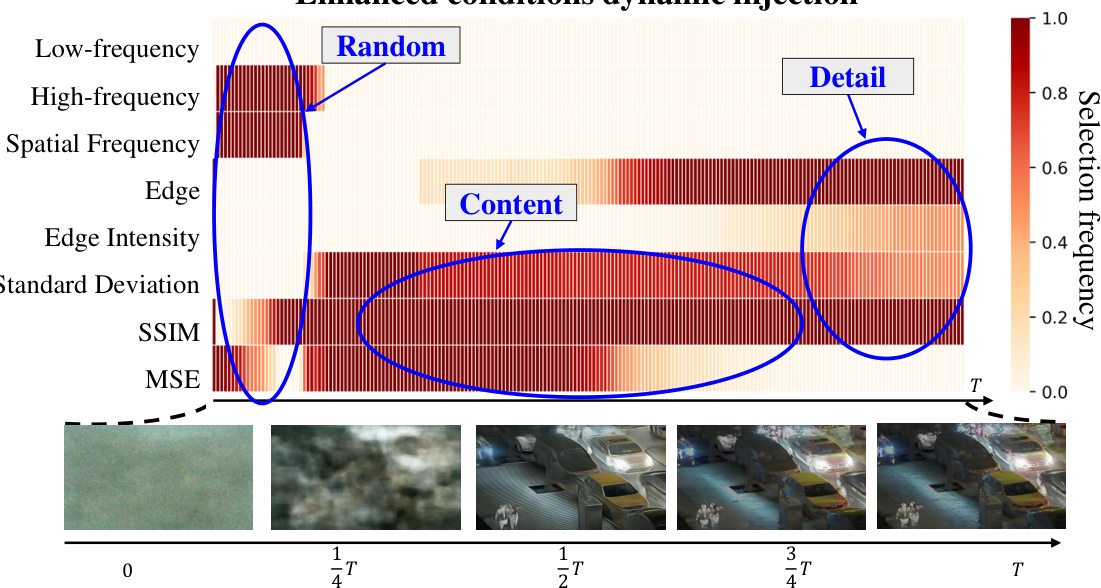
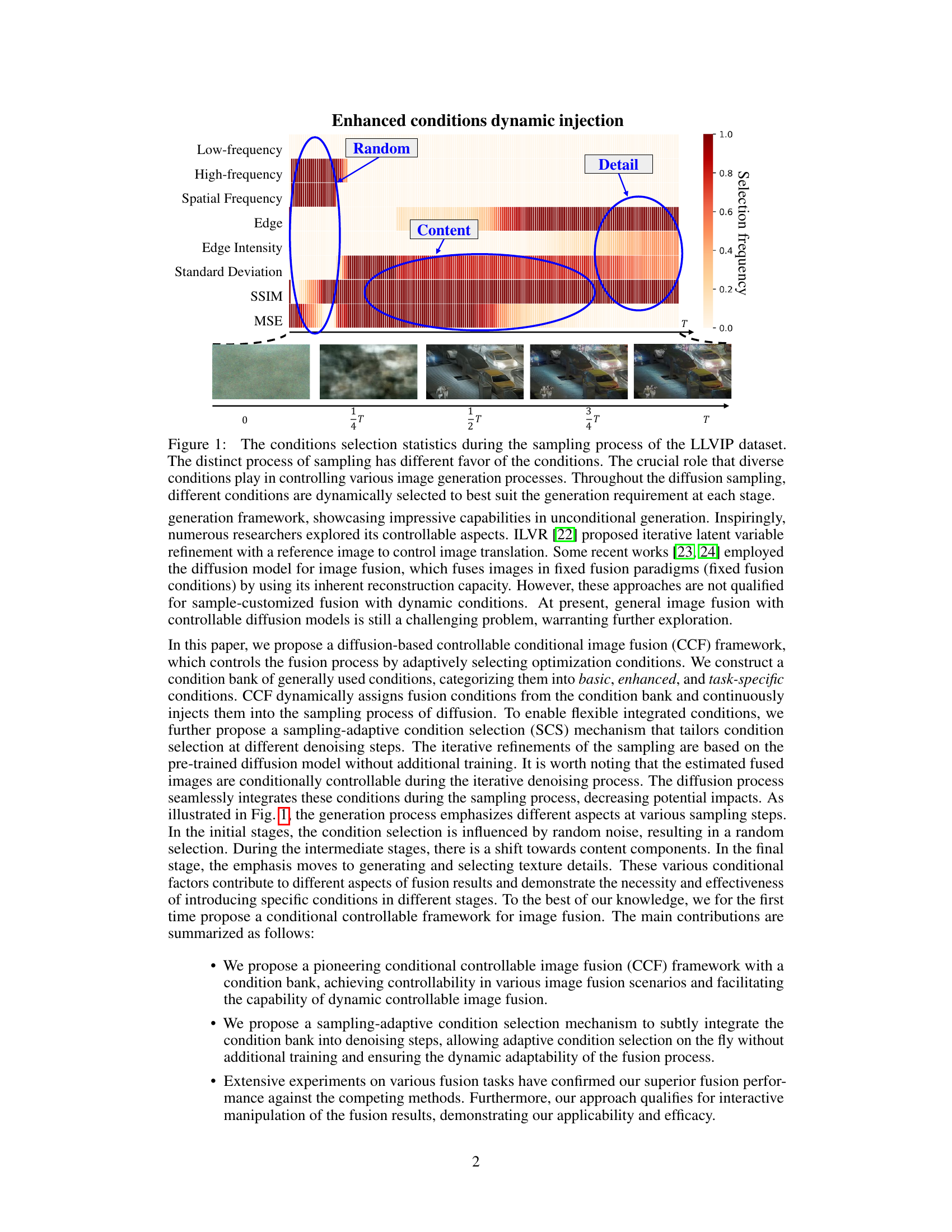
This figure shows the selection frequency of different conditions during the sampling process of the LLVIP dataset. The x-axis represents the sampling steps, and the y-axis represents the conditions. The heatmap shows that different conditions are selected with different frequencies at different stages of the sampling process. In the initial stages, random noise influences condition selection. In intermediate stages, content components are emphasized. Finally, texture details are prioritized. This dynamic condition selection ensures that the fusion process remains responsive to the specific requirements at each stage.
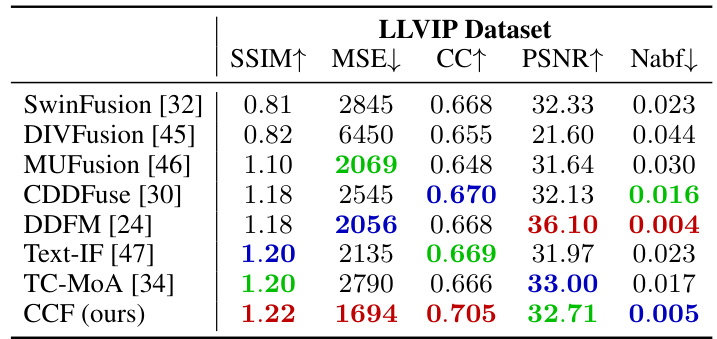
This table compares the performance of the proposed CCF method with several state-of-the-art (SOTA) image fusion methods on the LLVIP dataset. The comparison uses five quantitative metrics: SSIM (Structural Similarity Index), MSE (Mean Squared Error), CC (Correlation Coefficient), PSNR (Peak Signal-to-Noise Ratio), and Nabf (modified fusion artifacts measure). The best, second best, and third-best results for each metric are highlighted in red, blue, and green, respectively. The table shows that CCF outperforms the other methods on most metrics.
In-depth insights#
Conditional Fusion#
Conditional fusion, in the context of image fusion, represents a significant advancement. Instead of fixed fusion paradigms, it adaptively integrates information from multiple sources based on specific conditions. This approach offers significant flexibility, allowing for better fusion results across varying scenarios, including those with dynamic environmental changes. The core idea is to inject these conditions into a pre-trained model, often a denoising diffusion probabilistic model (DDPM), thereby guiding the fusion process. This eliminates the need for extensive retraining for each specific scenario, making conditional fusion exceptionally efficient. The selection of conditions is crucial and can be tailored to the specific task, further enhancing performance. A condition bank containing various types of conditions, including basic, enhanced and task-specific ones, allows for fine-grained control over the fusion output. The ability to dynamically select conditions during the fusion process is a key aspect of this framework, ensuring responsiveness to the changing needs. In essence, conditional fusion overcomes the limitations of traditional data-driven approaches by providing a flexible and adaptable method for image integration.
Diffusion Control#
Diffusion models, known for their exceptional generative capabilities, offer a unique approach to image fusion. Control over the diffusion process is crucial for effective fusion, allowing for the selective integration of information from multiple sources. A key challenge lies in dynamically adapting the control mechanism to the specific characteristics of each input image. This necessitates a flexible and adaptive control strategy that can seamlessly integrate various constraints during the diffusion process. Methods that inject constraints directly into the diffusion model or leverage pre-trained models with adaptive constraint selection are particularly promising. The choice of constraints is critical, influencing which aspects of the input images are emphasized in the fused output. The optimal balance between detail preservation, noise reduction and artifact suppression is dependent upon carefully considering and managing this. Successful diffusion control methods for image fusion need to address the computational cost of the iterative process and the complexities of integrating diverse constraints while maintaining high-quality output.
Adaptive Sampling#
Adaptive sampling, in the context of a research paper, likely refers to a technique where the sampling process is not static but rather changes dynamically based on some criteria. This could involve adjusting the sampling rate, the selection of samples, or the sampling locations. The key advantage is improved efficiency and accuracy. By concentrating sampling efforts in regions of higher information density or greater uncertainty, adaptive sampling can significantly reduce the number of samples needed to achieve a desired level of precision or confidence. This is particularly useful when dealing with large datasets or complex systems where exhaustive sampling is computationally prohibitive. A well-designed adaptive sampling method should intelligently balance exploration and exploitation. Exploration ensures that the algorithm is not prematurely biased towards specific regions of the sample space, while exploitation focuses on gathering more information from areas already identified as promising. The specific implementation of adaptive sampling will vary depending on the application and the underlying data characteristics. However, common elements include a feedback mechanism to monitor the sampling process and an algorithm to adjust sampling parameters accordingly. Potential challenges might include designing a robust feedback mechanism that avoids premature convergence to poor solutions and developing efficient algorithms for updating sampling parameters in real-time.
Condition Bank#
The concept of a ‘Condition Bank’ in the context of controllable image fusion is a novel and powerful approach to adapting a pre-trained denoising diffusion probabilistic model (DDPM) to diverse image fusion tasks without retraining. Instead of designing fixed fusion paradigms, the Condition Bank offers a flexible library of image constraints, categorized into basic, enhanced, and task-specific conditions. This allows the model to dynamically select and inject the most relevant conditions at each step of the diffusion process, ensuring the fusion process remains responsive to the specific requirements. The adaptive condition selection mechanism is crucial to this approach, guaranteeing a smooth and coherent fusion result despite the dynamic changes in conditions. The Condition Bank significantly enhances the generalizability and efficiency of the fusion framework. By introducing a bank of readily available conditions, the model avoids the need for task-specific training, and improves flexibility and control over the fusion output. The framework’s ability to seamlessly integrate various conditions from the bank is a major contribution, making the approach adaptable to diverse image fusion scenarios.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the condition selection mechanism is crucial; current methods rely on empirical selection, and a more data-driven or automated approach would enhance both scalability and robustness. Exploring alternative diffusion models, beyond DDPM, and their suitability for this conditional fusion task could lead to improved performance and efficiency. The impact of different condition types and representations requires further investigation. Development of a more comprehensive condition bank, categorized by task and image characteristics, is needed to broaden applicability. The incorporation of interactive control mechanisms, allowing users to dynamically adjust fusion parameters during the generation process, offers exciting possibilities for creating highly customized results. Finally, rigorous evaluation across a wider range of datasets and fusion tasks, and a more in-depth investigation of the downstream applications impact, is critical to demonstrate the full potential of this controllable image fusion framework.
More visual insights#
More on figures

The figure illustrates the overall architecture of the proposed Conditional Controllable Fusion (CCF) framework. It shows how the framework combines a pre-trained Denoising Diffusion Probabilistic Model (DDPM) with a condition bank that uses a sampling-adaptive condition selection (SCS) mechanism. The input consists of multi-source images (e.g., visible and infrared images). The DDPM is used as the core for image generation, and conditions from the condition bank are progressively injected into the sampling process. The condition bank contains basic conditions (e.g., MSE, high-frequency, low-frequency), enhanced conditions (e.g., SSIM, entropy, spatial frequency), and task-specific conditions. The SCS mechanism dynamically selects the optimal condition set based on the current sampling stage. The output of the process is the fused image, which is conditionally controllable.

This figure displays a qualitative comparison of various image fusion methods applied to visible-infrared (VIF) fusion tasks using the LLVIP dataset. It visually demonstrates the results of different approaches including Swin Fusion, DIVFusion, MUFusion, CDD, DDFM, Text-IF, TC-MoA and the proposed CCF method. The comparison highlights visual differences in terms of detail preservation, noise reduction, and overall image quality.

This figure shows a qualitative comparison of different image fusion methods on multi-focus fusion tasks using the MFFW dataset. The top row displays the source images (Source 1 and Source 2), while subsequent rows showcase results from U2Fusion, DeFusion, DDFM, Text-IF, TC-MoA, and the proposed CCF method. The green and red boxes highlight specific regions where the methods’ relative strengths and weaknesses are apparent. Overall, the figure visually demonstrates the ability of the CCF method to preserve details and textures compared to alternative approaches.

This figure shows a comparison of object detection results on fused images with and without using task-specific conditions. The top row displays the results without task-specific conditions, showing missed detections (highlighted in cyan boxes). The bottom row shows improved detection results obtained by incorporating task-specific conditions, accurately identifying objects that were missed in the top row. This visually demonstrates the benefit of integrating task-specific conditions to enhance performance on downstream tasks like object detection.

This figure compares qualitative results of image fusion with and without using a detection condition. It shows that adding the detection condition improves the results by better highlighting important details, likely objects detected by the model.

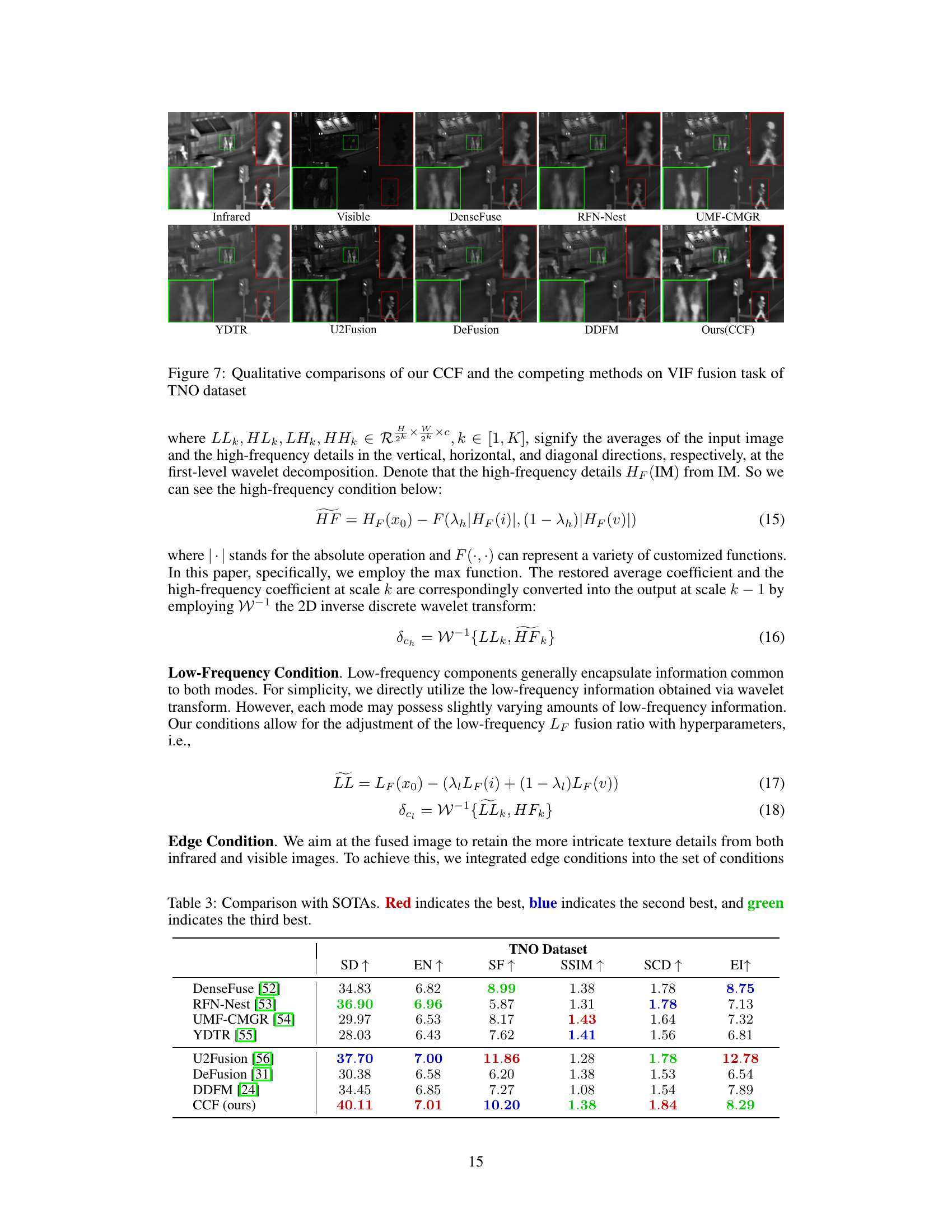
This figure presents a qualitative comparison of various image fusion methods on a visible-infrared image fusion (VIF) task, using the TNO dataset. It showcases the results of different methods side-by-side, allowing for a visual assessment of their performance in terms of detail preservation, noise reduction, and overall image quality. The methods compared include DenseFuse, RFN-Nest, UMF-CMGR, YDTR, U2Fusion, DeFusion, DDFM, and the proposed CCF method. The comparison highlights the strengths and weaknesses of each approach in terms of preserving fine details in various regions of the image. Bounding boxes are used to highlight specific areas where differences are more easily apparent, enabling a better understanding of the relative performance of each technique.

The figure shows the architecture of the neural network used in the proposed CCF framework. It’s a U-Net-like architecture with six layers, each processing different resolutions (32x32, 16x16, and 8x8). The architecture incorporates skip connections between layers, likely for better gradient flow and feature integration. It also includes ‘down stream’ and ‘down and right stream’ components, suggesting different pathways for processing feature information. The sequential arrangement of the layers, along with skip connections, and the multiple streams is typical of image processing networks, which are commonly used for feature extraction and fusion tasks.
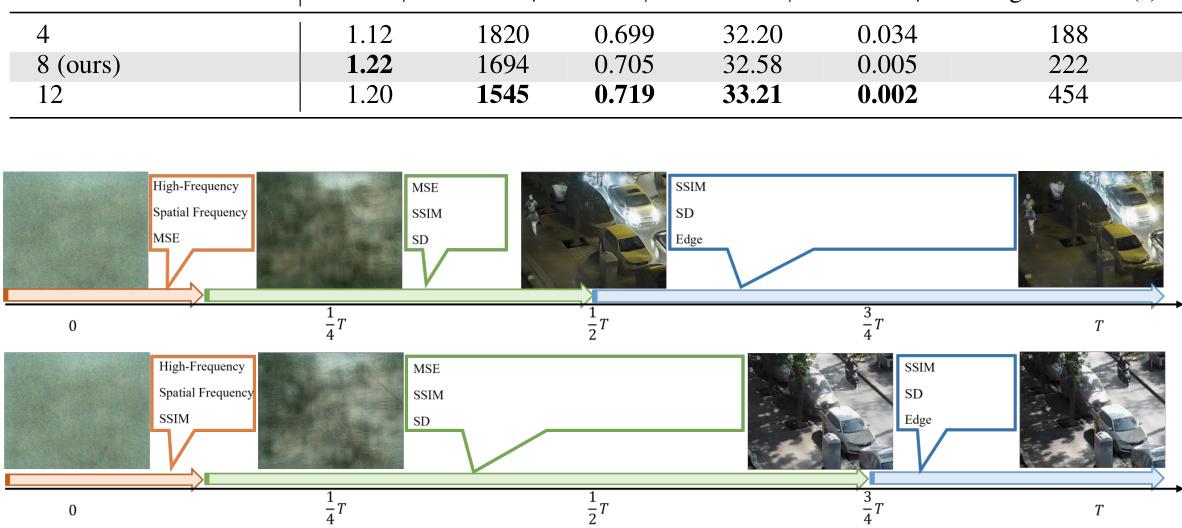
This figure shows how the sampling-adaptive condition selection (SCS) mechanism dynamically chooses enhanced conditions during the denoising process. The top panel illustrates a scenario with smoothly changing conditions, while the bottom shows a scenario with rapidly changing conditions. Different conditions (SSIM, MSE, SD, Edge, High-Frequency, Spatial Frequency) are selected at different stages depending on the image generation needs. This adaptive selection ensures the fusion process remains responsive to changing environmental conditions.

This figure presents a qualitative comparison of image fusion results with and without the integration of a detection condition. The left-hand side shows fusion results without the detection condition, while the right-hand side shows results with the detection condition incorporated. Each row represents a different image pair undergoing fusion. The red bounding boxes highlight objects detected in the images, demonstrating how the inclusion of the detection condition improves the accuracy and detail of object detection in the fused images. This visual comparison effectively illustrates how task-specific conditions can enhance the quality and contextual relevance of image fusion.

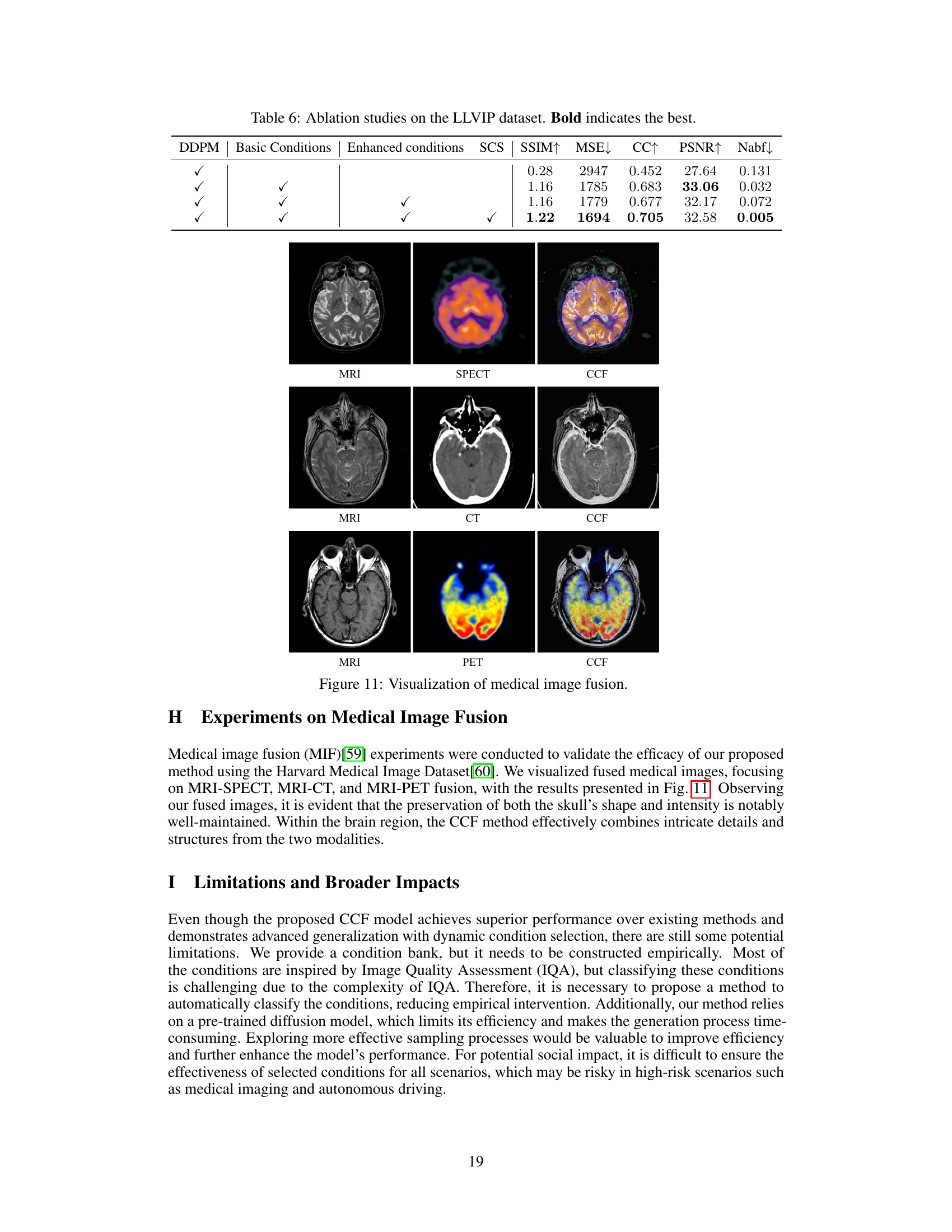
This figure shows the results of applying the proposed CCF method to medical image fusion tasks. It presents three examples of multimodal image fusion: MRI-SPECT, MRI-CT, and MRI-PET. For each example, the figure displays the input images (MRI, SPECT, CT, or PET), and the corresponding fused image produced by CCF. The fused images demonstrate the ability of CCF to effectively integrate complementary information from different modalities to produce a more comprehensive representation of the underlying anatomy.
More on tables
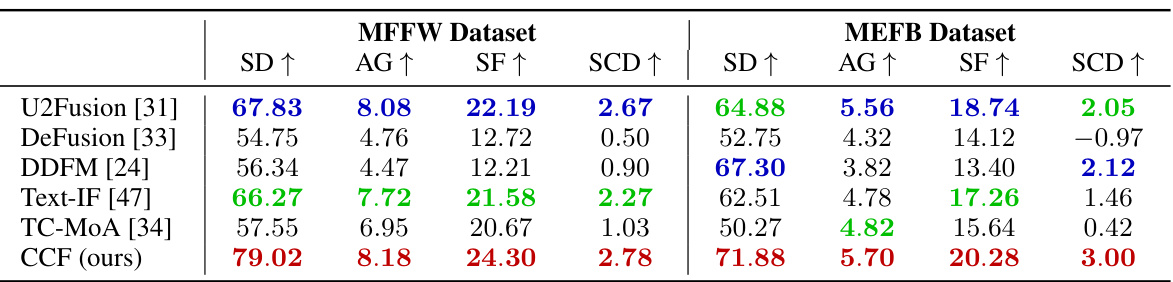
This table presents a quantitative comparison of the proposed CCF method against several state-of-the-art image fusion methods on two benchmark datasets: MFFW and MEFB. The comparison is performed across four metrics for each dataset, reflecting different aspects of image quality. The metrics used are standard deviation (SD), average gradient (AG), spatial frequency (SF), and the sum of correlations of differences (SCD). Higher values generally indicate better performance for SD, AG, SF, and SCD. The best, second-best and third-best results for each metric in each dataset are highlighted in red, blue, and green respectively, providing a clear visualization of the CCF method’s performance relative to the competitors.

This table compares the performance of the proposed CCF method with several state-of-the-art methods on the TNO dataset for multi-modal image fusion. It uses six metrics to evaluate the quality of the fused images: Standard Deviation (SD), Entropy (EN), Spatial Frequency (SF), Structural Similarity (SSIM), Sum of Correlations of Differences (SCD), and Edge Intensity (EI). Higher values are generally better for most metrics, except for MSE (Mean Squared Error) and Nabf (modified fusion artifacts measure), where lower values are preferred. The table highlights the superior performance of the proposed CCF method across multiple metrics.

This table compares the proposed CCF method with several state-of-the-art (SOTA) methods for multi-modal image fusion using the LLVIP dataset. The performance of each method is evaluated using five quantitative metrics: SSIM, MSE, CC, PSNR, and Nabf. The best, second-best, and third-best results for each metric are highlighted in red, blue, and green, respectively. This allows for a direct comparison of the CCF method’s performance against existing techniques.
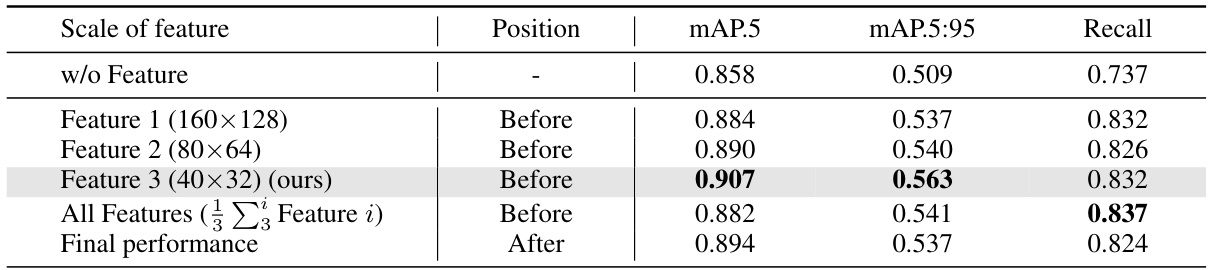
This table presents the results of an ablation study evaluating the impact of using different scales of features from the YOLOv5 object detection model as task-specific conditions in the image fusion process. The study compares the performance metrics (mAP@.5, mAP@.5:.95, and Recall) when using features from different scales (160x128, 80x64, 40x32) individually and when combining all three scales. The results show that using features from the 40x32 scale yields the best performance improvement over the baseline (w/o Feature).

This table presents the results of ablation studies conducted on the LLVIP dataset to evaluate the impact of different components of the proposed CCF (Conditional Controllable Fusion) framework. The table shows the performance metrics (SSIM, MSE, CC, PSNR, and Nabf) achieved with variations in the inclusion of DDPM, basic conditions, enhanced conditions, and the SCS (Sampling-adaptive Condition Selection) mechanism. Each row represents a different experimental configuration, showing the incremental improvement in performance as more components of the CCF framework are incorporated. The bold values highlight the best results across all metrics.
Full paper#