↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for aligning Large Language Models (LLMs) with human preferences primarily focus on single-turn interactions, limiting their ability to handle complex, multi-turn dialogues. This paper addresses this limitation by developing novel methods for reinforcement learning from preference feedback between full multi-turn conversations.
The researchers introduce a new mirror-descent based policy optimization algorithm, MTPO, which considers the preferences between entire conversations rather than individual turns. They theoretically prove the algorithm’s convergence to a Nash Equilibrium and demonstrate its effectiveness by creating a new multi-turn environment called ‘Education Dialogue’. In this environment, an AI teacher guides a student, and the performance is evaluated based on human preference feedback between full dialogues. Results show that MTPO outperforms existing single-turn RLHF baselines.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it bridges the gap between single-turn and multi-turn reinforcement learning from human feedback (RLHF). It offers theoretically sound algorithms with convergence guarantees, moving beyond current limitations of single-turn RLHF in complex multi-turn applications like dialogue systems. This opens new avenues for aligning Large Language Models (LLMs) with human preferences in dynamic, long-term interactions, which is a critical area for future AI development.
Visual Insights#

This figure illustrates the process of generating data for the Education Dialogue dataset. The top panel shows the prompt used to instruct the Gemini language model to generate conversations between a teacher and a student. The middle panel displays examples of conversations generated by this process. The bottom panel shows the prompt used to obtain human preference feedback on the generated conversations, allowing for the evaluation of different conversation strategies.
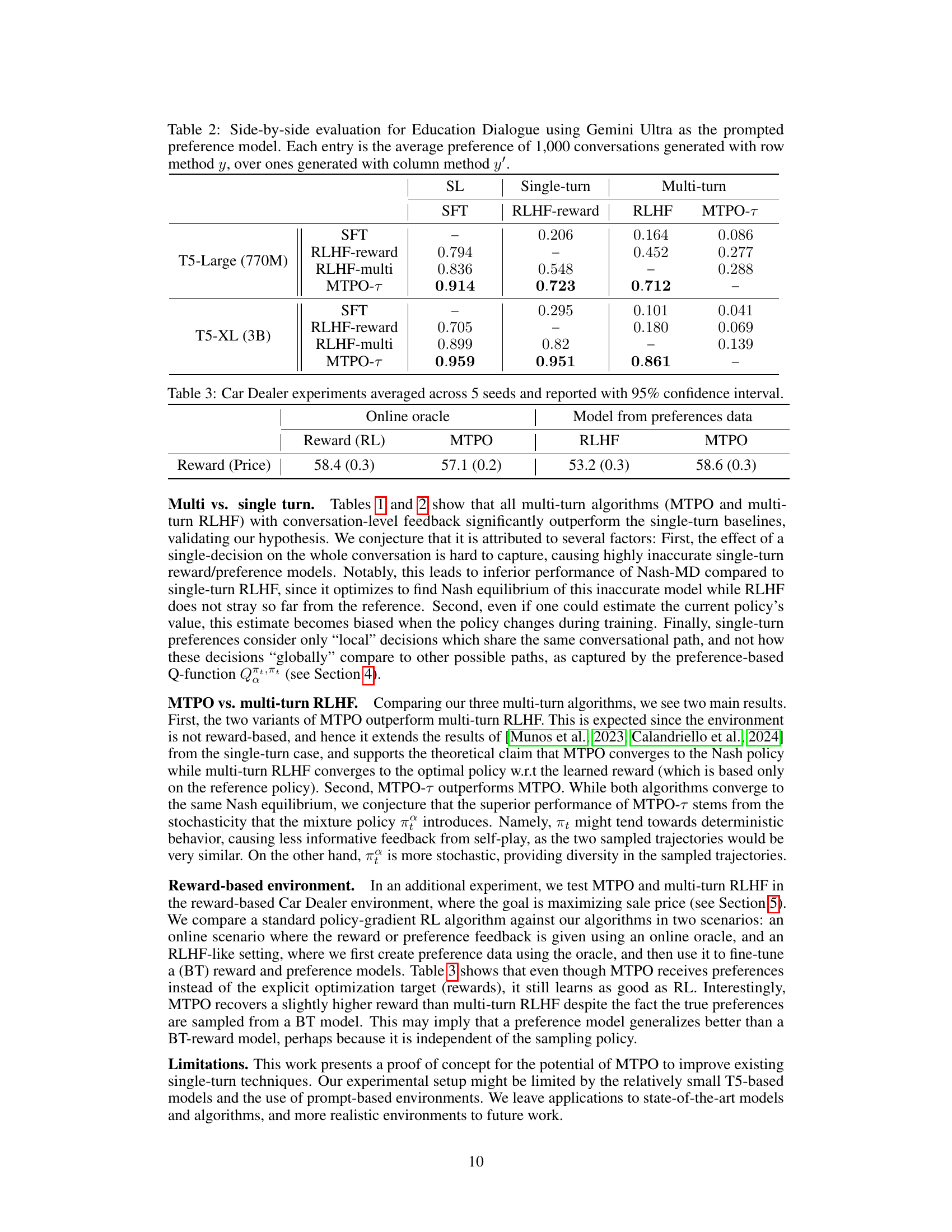
This table presents a comparison of different methods for generating conversations in the Education Dialogue task. The rows and columns represent different conversation generation methods. Each cell shows the average preference score (out of 1600 conversations) for the row method compared to the column method. Higher scores indicate better performance. The methods compared include supervised fine-tuning (SFT), single-turn and multi-turn reinforcement learning from human feedback (RLHF), and the proposed MTPO algorithms. The standard deviation is available in Appendix D for a more detailed understanding of the variations.
In-depth insights#
Multiturn RLHF#
The heading ‘Multiturn RLHF’ suggests an extension of Reinforcement Learning from Human Feedback (RLHF) to multi-turn conversations. Standard RLHF often focuses on single-turn interactions, where an AI model generates a single response and receives feedback on its quality. Multiturn RLHF addresses the limitations of this approach by considering the context of multiple turns in a conversation. This allows for a more nuanced understanding of the AI model’s performance and allows for better alignment with human preferences. The key challenge in Multiturn RLHF lies in effectively capturing the long-term impact of actions across multiple turns. Unlike single-turn scenarios, where the feedback directly assesses the immediate action, in multi-turn settings, the impact of an early action might only become fully apparent later in the conversation. Multiturn RLHF methods aim to address this by using reward or preference signals that reflect the overall quality of the multi-turn dialogue rather than assessing individual turns in isolation. This requires sophisticated techniques for handling the temporal dependencies and cumulative effects of actions within the conversation. The development of such methods is a critical step towards creating more natural and coherent AI agents capable of engaging in extended dialogue and complex problem-solving scenarios.
Preference-based RL#
Preference-based Reinforcement Learning (RL) offers a compelling alternative to reward-based RL, particularly in scenarios where defining a precise reward function is challenging or subjective. Instead of relying on numerical rewards, preference-based RL leverages human feedback comparing pairs of outcomes or trajectories. This approach is particularly suitable for complex tasks involving human judgment, such as evaluating dialogue quality, artistic merit, or the overall success of a plan. The core challenge lies in efficiently collecting and utilizing preference data to guide learning. Algorithms like those based on mirror descent and self-play show promise in addressing this challenge by directly optimizing agent policies based on pairwise preference data. These methods offer theoretical convergence guarantees in specific settings and demonstrate empirical advantages over reward-based baselines in complex environments. However, scalability and the effect of noisy, inconsistent human feedback remain crucial open questions. Future research should explore more robust methods for handling noisy preferences and scalable algorithms suitable for high-dimensional state and action spaces.
Deep RL#
The heading ‘Deep RL’ in this context likely refers to the application of deep learning techniques within the framework of reinforcement learning (RL). The authors likely leverage deep neural networks to approximate the complex value and policy functions inherent in multi-turn preference-based RL. This approach allows the model to learn effective strategies from a weaker preference signal compared to the traditional reward-based RL. The integration of deep learning enhances the model’s ability to handle high-dimensional data such as text sequences, a common feature in multi-turn dialogues. A key challenge addressed may involve adapting the tabular algorithms to deep learning architectures, requiring careful consideration of gradient estimation, optimization strategies, and computational efficiency. The success of this approach hinges on the effectiveness of the deep neural network in approximating the Q-function and value function, and the choice of hyperparameters likely plays a critical role in achieving optimal performance. The results section likely demonstrates that the Deep RL variant significantly outperforms baseline approaches, showcasing its efficacy in complex, multi-turn interactions where learning from preference feedback is crucial.
Education Dialogue#
The heading ‘Education Dialogue’ suggests a novel environment designed for evaluating multi-turn dialogue models, specifically focusing on educational settings. This environment likely involves a simulated teacher-student interaction where the teacher agent aims to effectively guide the student in learning a topic. The evaluation metric is based on human preference feedback comparing entire conversations, rather than individual turns, thereby capturing long-term effects of the dialogue. This preference-based approach avoids the difficulty of defining explicit rewards, making it more suitable for complex, multi-turn scenarios. The success of the teacher agent would be measured by the quality of the conversation and the student’s overall understanding of the topic. The innovative ‘Education Dialogue’ offers a valuable contribution for evaluating LLMs in nuanced settings, offering a step forward beyond current single-turn RLHF approaches.
Limitations#
The research paper, while groundbreaking in proposing novel multi-turn reinforcement learning from human preference feedback, acknowledges several limitations. The primary limitation centers on the reliance on LLMs for generating data and preference judgments. This introduces a circularity, as the models being trained are also used to evaluate their own performance, potentially limiting generalizability to human evaluations. The methodology’s dependence on specific LLMs and prompts also raises concerns about reproducibility and the extent to which the findings hold for other models and prompting styles. Additionally, the study’s scale is relatively small, potentially hindering the identification of more subtle limitations, and the focus on specific environments might limit the generalizability of the findings to other multi-turn interaction scenarios. Future work should address these limitations by incorporating diverse data sources, human-centric evaluations, and broadening the range of studied environments. This would significantly strengthen the claims and improve the real-world applicability of the proposed approach.
More visual insights#
More on tables

This table presents a side-by-side comparison of different methods for generating conversations in the Education Dialogue environment using Gemini Ultra for preference evaluation. It shows the average preference score for conversations generated by each method against those generated by every other method. Higher scores indicate better performance.

This table compares the performance of different reinforcement learning methods in the Car Dealer environment. The ‘Online oracle’ columns represent scenarios where reward is obtained directly from an oracle. The ‘Model from preferences data’ columns show results when a model is trained using preference data to approximate rewards. Both single-turn (RLHF) and multi-turn (MTPO) methods are compared. The reward is measured by the final sale price achieved. The results indicate that MTPO achieves comparable performance to RL, even when trained on preference data instead of explicit rewards.
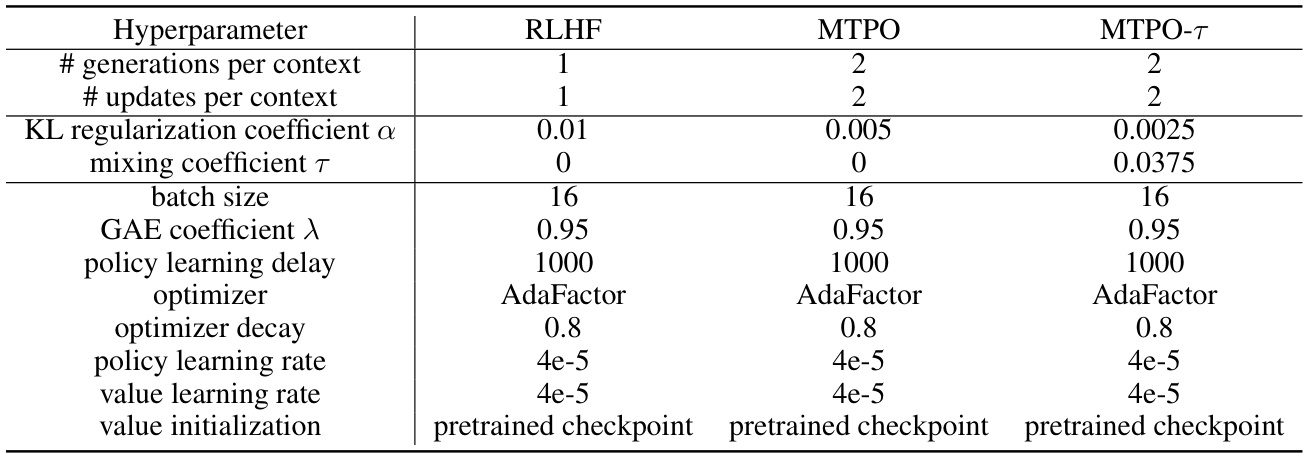
This table lists the hyperparameters used for the three multi-turn algorithms evaluated in the paper: RLHF, MTPO, and MTPO-τ. The hyperparameters include settings related to the number of generations and updates per context, KL regularization, mixing coefficient (for MTPO-τ only), batch size, GAE coefficient, policy learning delay, optimizer, optimizer decay, policy learning rate, value learning rate, and value initialization. The consistent use of AdaFactor as the optimizer across all algorithms is notable.
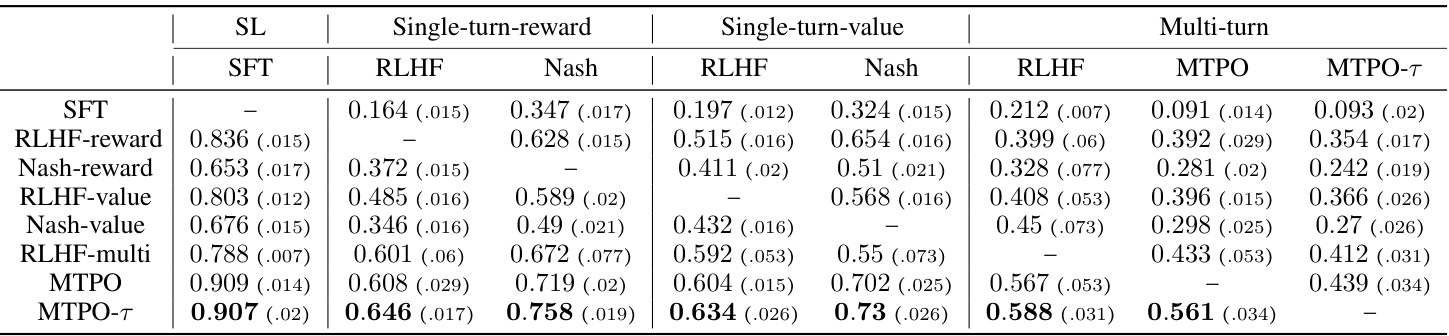
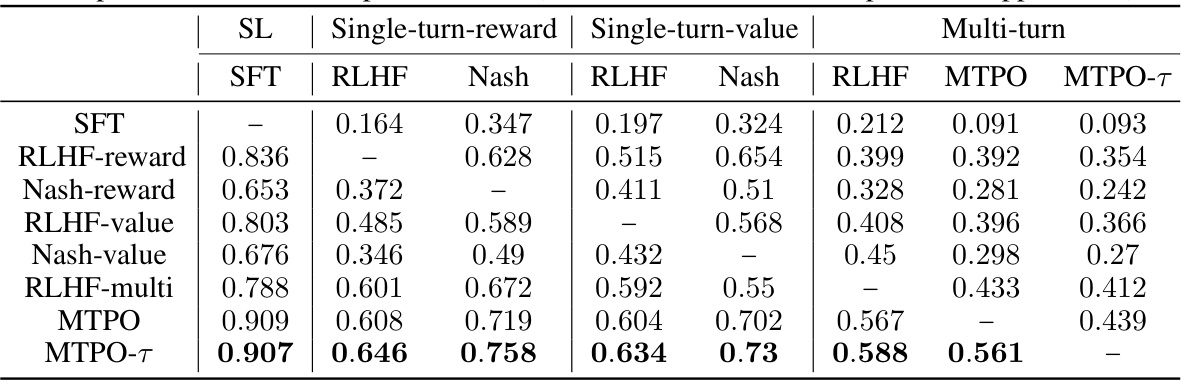
This table presents a comparison of different methods for evaluating conversations in the Education Dialogue task. It shows the average preference scores for each method compared to all other methods. The scores are based on 1600 conversations per comparison, using three different random seeds for each evaluation to improve statistical robustness, and standard deviations are given in the appendix. The methods compared include supervised fine-tuning (SFT), single-turn RLHF (with reward and value functions), and the multi-turn algorithms MTPO and MTPO-τ.
Full paper#