↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Language models (LMs) are traditionally tied to their specific tokenizers, limiting their flexibility and efficiency when used with different languages or domains. Existing methods for adapting LLMs to new tokenizers often require substantial retraining or perform poorly in zero-shot settings. This makes it difficult to switch between tokenizers, limiting LMs’ applicability in diverse contexts.
This paper introduces Zero-Shot Tokenizer Transfer (ZeTT), a novel approach that uses a hypernetwork to predict embeddings for new tokenizers. The hypernetwork is trained on a diverse set of tokenizers and generalizes well to unseen ones. ZeTT significantly outperforms existing methods, achieving near-original model performance in cross-lingual and coding tasks while reducing tokenized sequence length. Continued training further closes the remaining performance gap, making substantial strides toward detaching LLMs from their tokenizers and making them more adaptable and efficient.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on large language models (LLMs) and tokenizer transfer. It addresses a critical limitation of current LLMs—their dependence on specific tokenizers—by introducing a novel zero-shot approach. This opens new avenues for research into improving LLM efficiency and flexibility across different languages and domains, and contributes to a better understanding of how tokenizers affect LLM performance. The proposed hypernetwork approach offers a significant advancement in solving the n-shot tokenizer transfer problem and establishes a new baseline for the zero-shot setting. The results have practical implications for deploying LLMs in resource-constrained environments or diverse language settings.
Visual Insights#

This figure illustrates the architecture of the proposed zero-shot tokenizer transfer method. Raw text input undergoes tokenization, producing a sequence of tokens. A hypernetwork takes this tokenizer as input, and based on it, predicts the input and output embedding matrices for those tokens. These embeddings are then used in a language model (LM) to generate logits for subsequent processing. This method effectively detaches the language model’s functionality from its original tokenizer.
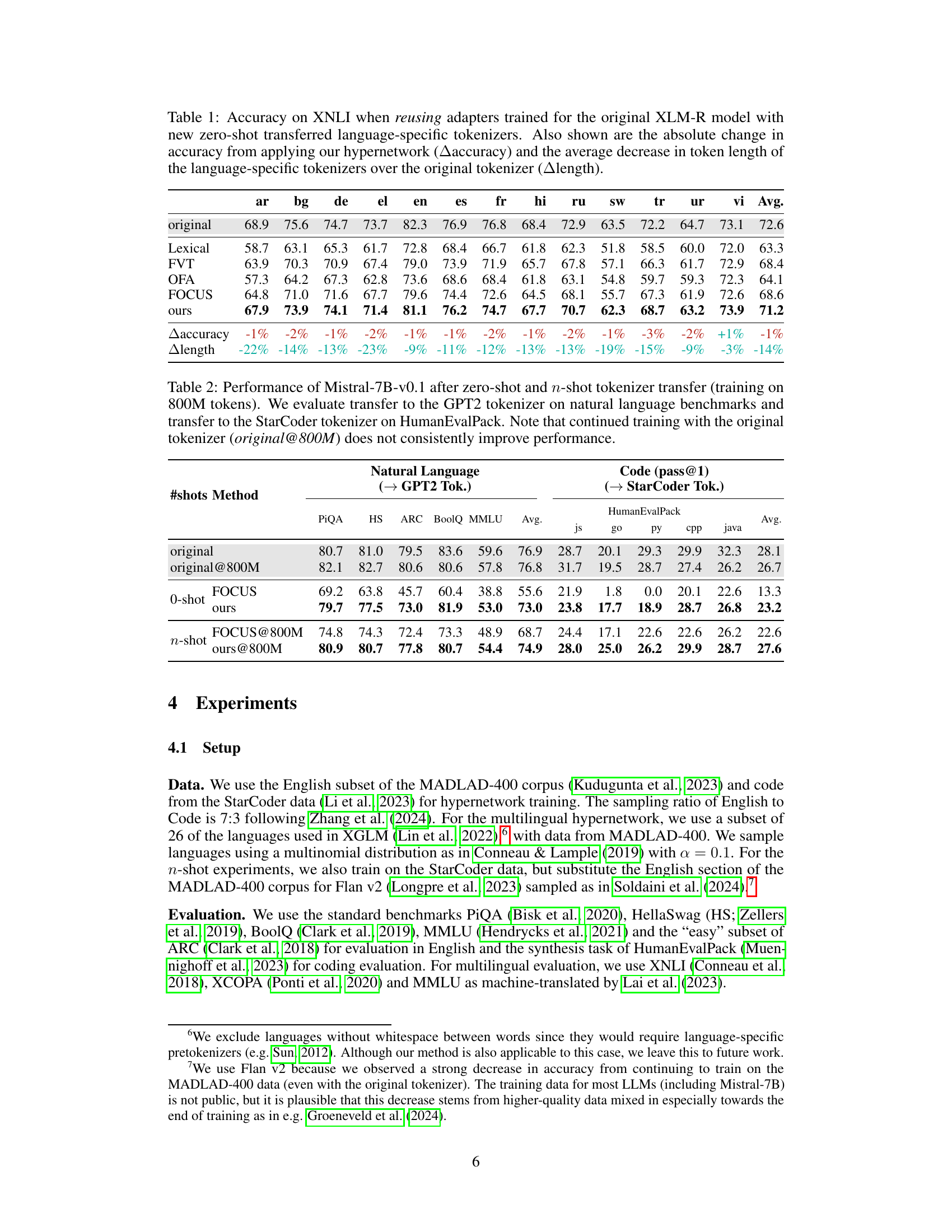
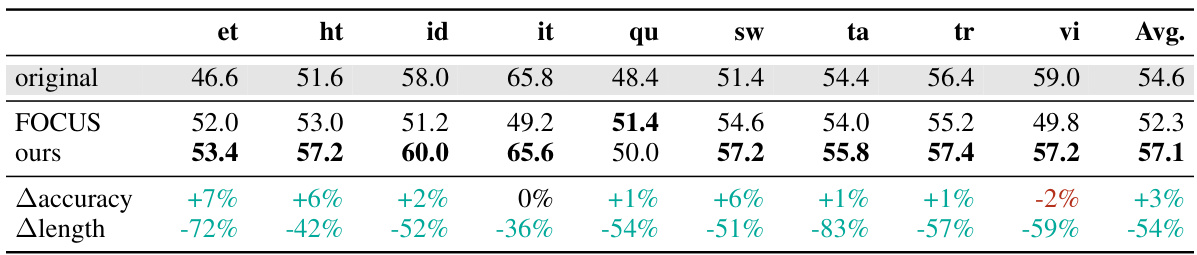
This table presents the results of applying zero-shot tokenizer transfer to the XLM-R model on the XNLI dataset. It shows accuracy scores for several languages using both the original XLM-R tokenizer and new, language-specific tokenizers generated by the proposed hypernetwork and several baselines. The table also quantifies the improvement or degradation in accuracy (Δaccuracy) compared to the original model and the average reduction in token sequence length (Δlength) achieved by using the new tokenizers.
In-depth insights#
Zero-Shot Transfer#
Zero-shot transfer, in the context of language models, presents a significant challenge and opportunity. It aims to adapt a language model to a new tokenizer without any fine-tuning or retraining on data using the new tokenizer. This is crucial for improving efficiency and flexibility, allowing models trained on one tokenization scheme to seamlessly function with others. The core of the problem involves finding effective ways to initialize the embeddings for the new tokenizer’s vocabulary. Heuristic approaches often fail, highlighting the need for more robust solutions, such as training a hypernetwork that predicts embeddings based on tokenizer characteristics. Successful zero-shot transfer offers the potential for faster adaptation, reduced computational costs, and enhanced interoperability between models using different tokenization methods. However, it’s crucial to acknowledge that zero-shot transfer may not always match the performance of a fully fine-tuned model, thus continued training on a smaller dataset could be beneficial.
Hypernetwork Approach#
The core of the proposed hypernetwork approach lies in its ability to learn a mapping from tokenizer specifications to corresponding embedding matrices. This is a significant departure from traditional methods, which often rely on heuristics or require substantial retraining. By directly predicting embeddings, the hypernetwork aims to achieve zero-shot tokenizer transfer, effectively decoupling language models from their initial tokenizers. This novel approach demonstrates impressive generalization capabilities, achieving near-original model performance across diverse languages and tasks, even when applied to unseen tokenizers. The hypernetwork’s success suggests a potential paradigm shift in language model architecture, offering significant advantages in efficiency and flexibility. Further research should investigate the scaling properties of the hypernetwork and explore its application to other NLP tasks and modalities.
Tokenizer Detachment#
The concept of “Tokenizer Detachment” in language models (LMs) centers on the crucial ability to disentangle the model’s architecture from its inherent reliance on a specific tokenizer. This is a significant challenge because tokenizers fundamentally shape how text is processed and represented within the LM. Current methods often tightly bind the model to a specific tokenizer, hindering flexibility and efficiency when dealing with diverse languages, domains, or when seeking to integrate with other models. Achieving tokenizer detachment would unlock significant potential. It would allow seamless switching between different tokenization schemes without requiring extensive retraining, dramatically improving the LM’s adaptability to varied text formats. Moreover, detachment is key to enhancing interoperability between models, enabling easier model ensembling and transfer learning techniques. The hypernetwork-based approach proposed in many papers offers a promising direction, learning to generate embeddings suitable for arbitrary tokenizers. However, the computational cost and generalization capacity of such methods remain important research areas. Successfully achieving true tokenizer detachment would mark a substantial advancement in LM architecture, paving the way for truly versatile and adaptable language processing systems.
Empirical Validation#
An Empirical Validation section would rigorously assess the claims made in a research paper. It would present the results of experiments designed to test the hypotheses and demonstrate the efficacy of proposed methods. Ideally, it would use multiple datasets and evaluation metrics to establish robustness and generalizability. The section should meticulously describe the experimental setup, including data sources, preprocessing techniques, model configurations, and evaluation protocols. Clear visualizations of results, such as graphs and tables showing quantitative measures and statistical significance, are crucial. A strong validation section also addresses potential confounding factors and limitations, ensuring that the findings are interpreted with necessary caution. Detailed discussions of observed performance and comparisons to baseline methods are key components. Ideally, it would include ablation studies which systematically evaluate the impact of individual components to understand the contributions of the proposed approach. Ultimately, a robust empirical validation supports the paper’s main claims by providing solid evidence and allowing readers to assess the validity and reliability of the results.
Future of ZeTT#
The future of Zero-Shot Tokenizer Transfer (ZeTT) is bright, promising significant advancements in language model flexibility and efficiency. Further research should focus on improving the hypernetwork’s generalization capabilities to handle even more diverse tokenizers and languages effectively. Exploring alternative architectures beyond the hypernetwork paradigm, potentially using techniques like meta-learning or prompt engineering, could unlock new levels of performance. Addressing the computational overhead of the hypernetwork is also crucial for wider adoption, perhaps through model compression or efficient hardware acceleration. Investigating the applicability of ZeTT to multimodal models (incorporating images, audio, etc.) would significantly broaden its impact. Finally, rigorous evaluations across various downstream tasks and languages are vital to validate the robustness and limitations of ZeTT across diverse settings.
More visual insights#
More on figures
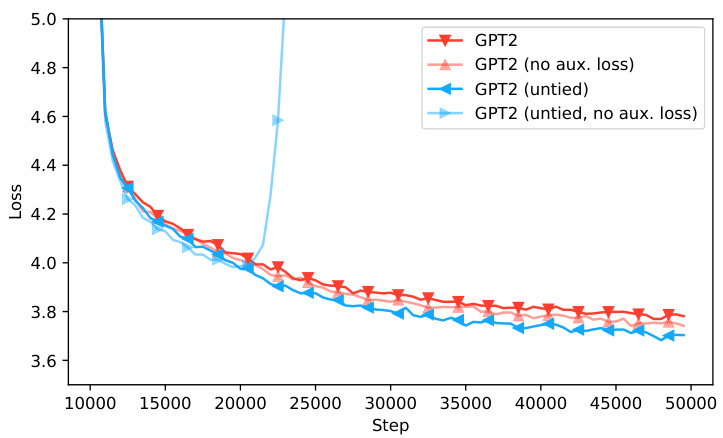
The figure illustrates the architecture of the hypernetwork used for zero-shot tokenizer transfer. The input is a new token from the target tokenizer’s vocabulary. This token is first decomposed using the original tokenizer, resulting in a sequence of sub-tokens. These sub-tokens are then embedded using the original model’s embedding matrix. This sequence of embeddings is passed through multiple instances of a language model (HLM) within the hypernetwork. Each HLM processes a segment of the input embedding sequence, and finally, the output of the final HLM layer is the new embedding for the original input token. The process ‘amortizes’ over the tokenizer by learning to compose the embeddings from the original sub-tokens into a new embedding without explicitly considering the specific tokenization function.
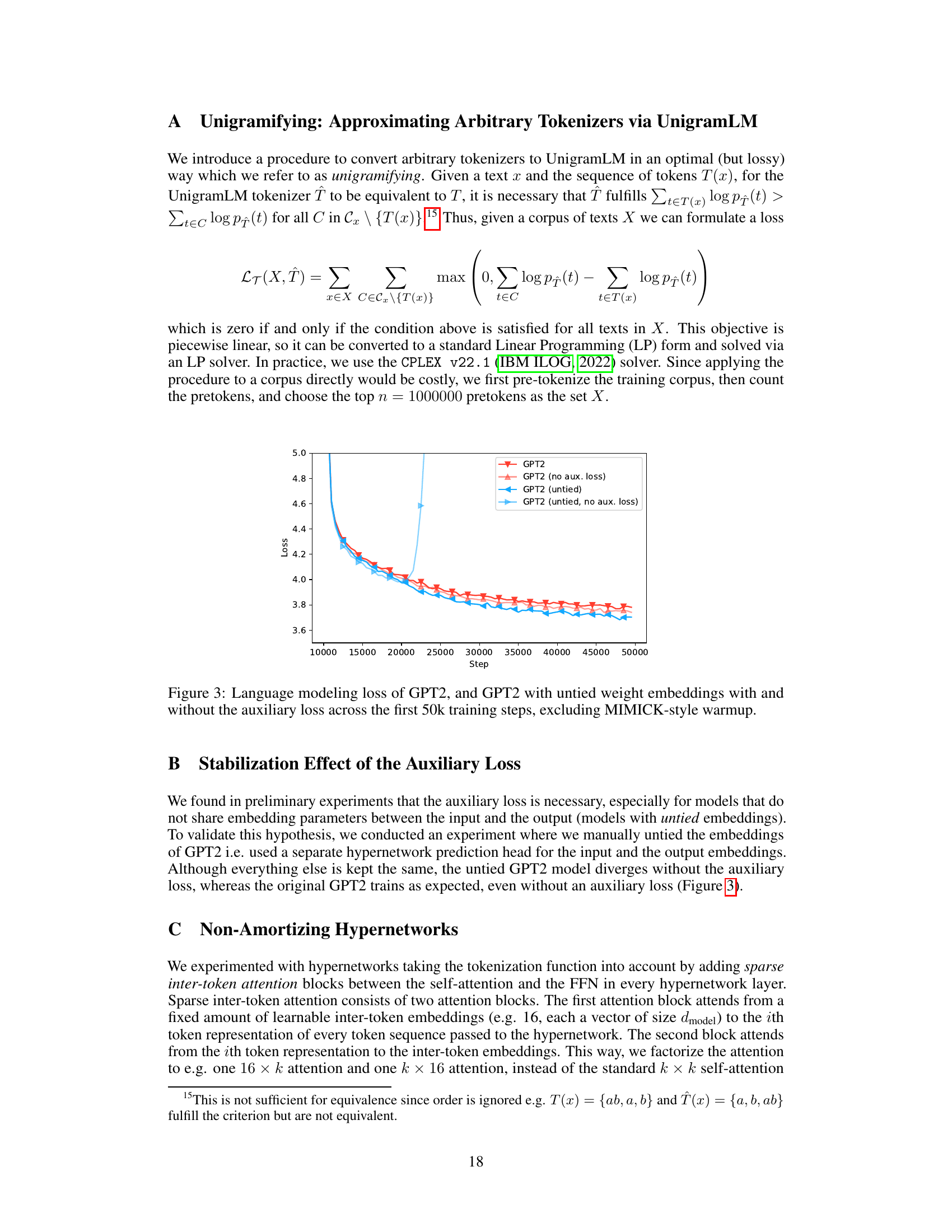
The figure shows the language modeling loss curves for four different GPT2 model variations across 50,000 training steps. The variations are: 1. GPT2: Standard GPT2 model. 2. GPT2 (no aux. loss): GPT2 without the auxiliary loss. 3. GPT2 (untied): GPT2 with untied input and output embedding matrices. 4. GPT2 (untied, no aux. loss): GPT2 with untied embeddings and no auxiliary loss. The plot demonstrates that the auxiliary loss is crucial for preventing divergence in the models with untied embeddings. The standard GPT2 model shows stable training loss, while models without the auxiliary loss exhibit instability, particularly the untied version.
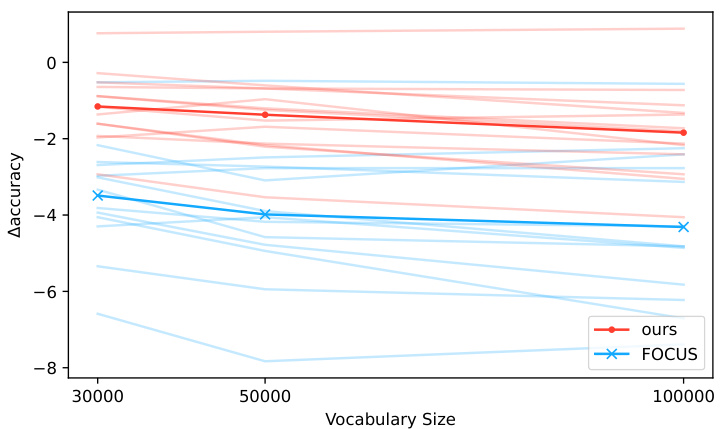
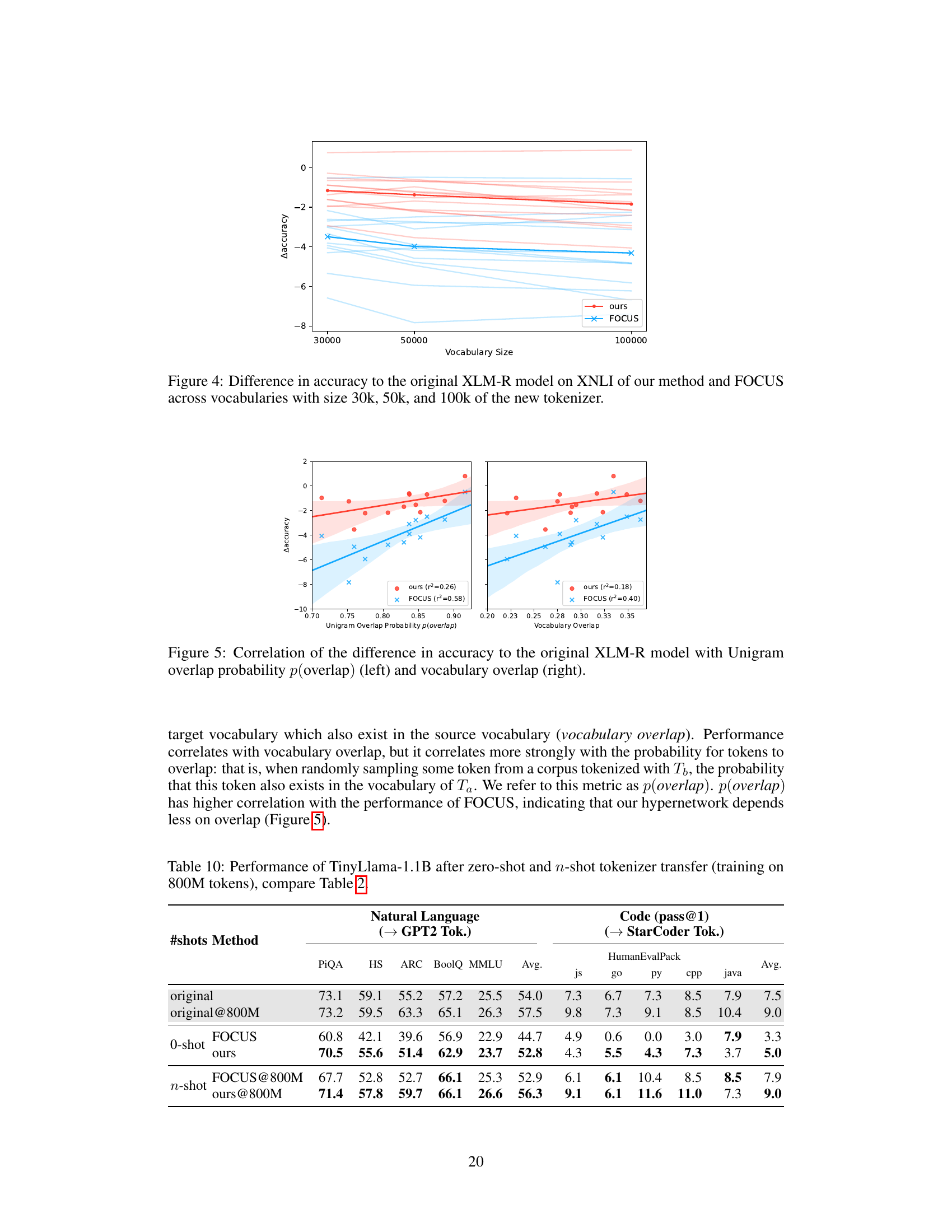
This figure displays the performance difference between the proposed hypernetwork method and the FOCUS baseline on the XNLI benchmark. The performance is evaluated across various vocabulary sizes (30k, 50k, and 100k) for the new tokenizer. Each line represents the performance of a specific language, comparing the accuracy change from using the hypernetwork or FOCUS against the original XLM-R model’s accuracy. The plot shows how the accuracy difference changes as the new tokenizer’s vocabulary size increases, providing insights into the robustness and scalability of both approaches.
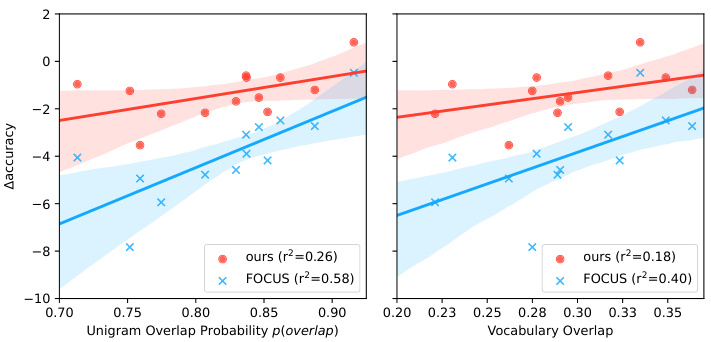
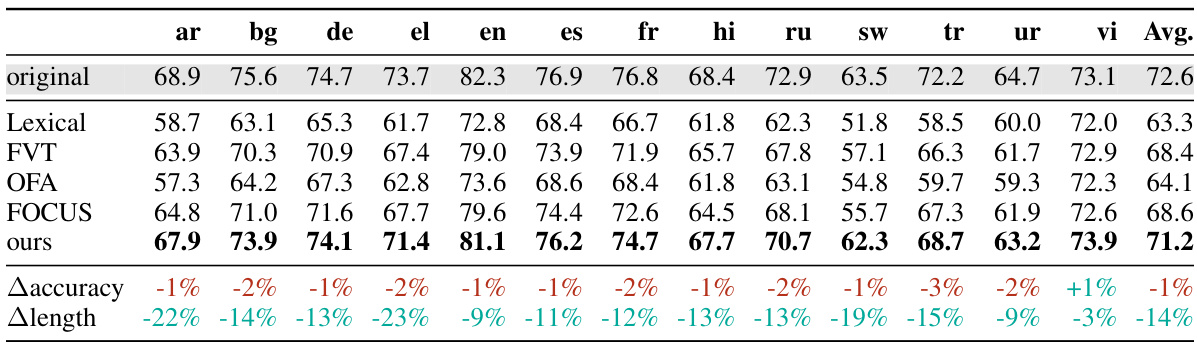
This figure shows the correlation between the difference in accuracy achieved by the proposed hypernetwork method and the FOCUS baseline, compared to the original XLM-R model. The correlation is analyzed with respect to two metrics: Unigram overlap probability (p(overlap)) and vocabulary overlap. The left panel displays the correlation with Unigram overlap probability, which represents the probability of a randomly sampled token from the target tokenizer also being present in the source tokenizer’s vocabulary. The right panel shows the correlation with vocabulary overlap, which measures the fraction of tokens shared between the target and source tokenizers. The results suggest that the hypernetwork’s performance is less dependent on the simple vocabulary overlap than on the Unigram overlap probability, indicating the hypernetwork’s robustness to vocabulary size differences and its ability to effectively leverage shared subword units.
This figure illustrates the architecture of the hypernetwork used for zero-shot tokenizer transfer. The hypernetwork takes as input the original tokenizer and the new target tokenizer. It processes the sequence of tokens from the original tokenizer using a language model (HLM). The HLM then learns to map these embeddings to a new set of embeddings suitable for the new tokenizer. This process essentially ‘amortizes’ over the tokenization function, meaning that the hypernetwork learns to generalize to new tokenizers without needing to be explicitly trained on each one individually.
More on tables
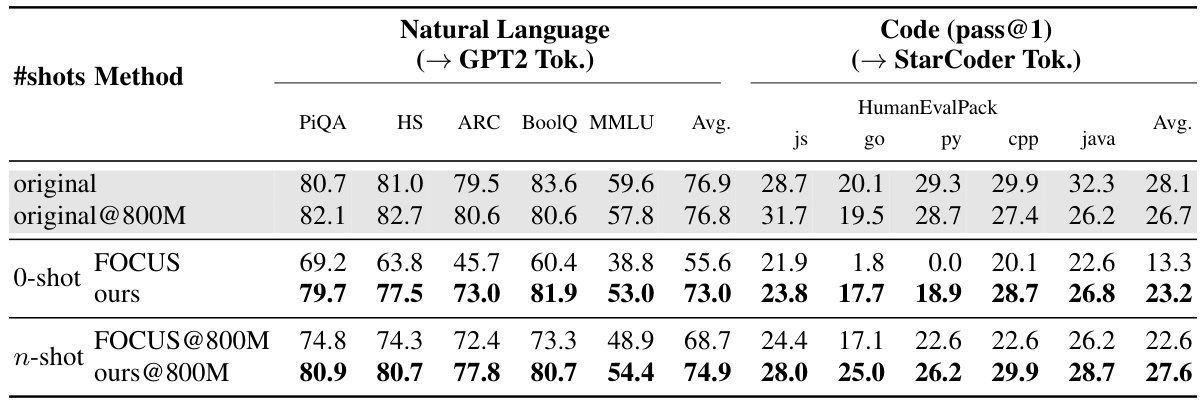
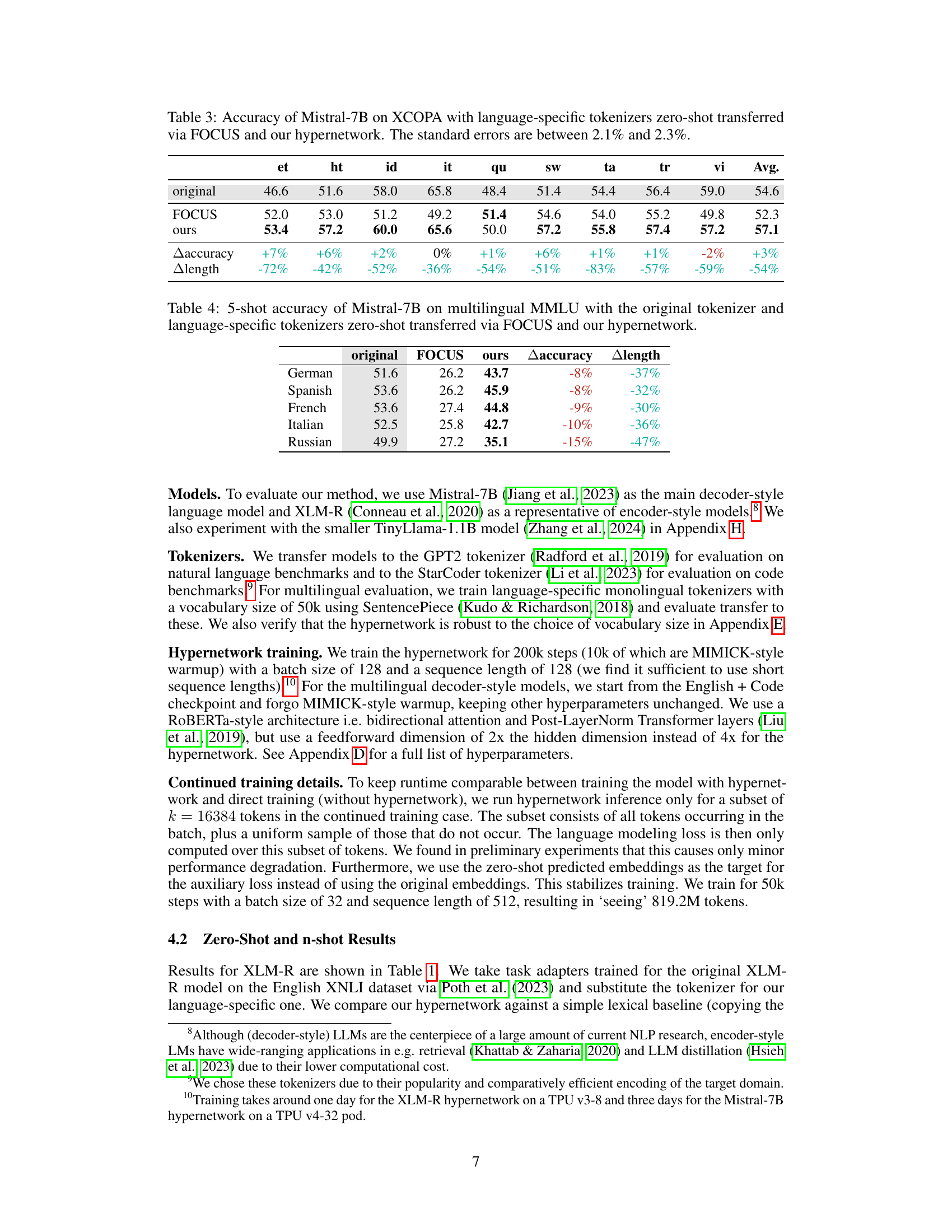
This table shows the performance of the Mistral-7B-v0.1 language model after performing zero-shot and n-shot tokenizer transfer. Zero-shot transfer uses a hypernetwork to predict embeddings for a new tokenizer without any further training. N-shot transfer involves fine-tuning the model with the new tokenizer on 800M tokens. The model’s performance is evaluated on both natural language benchmarks (using the GPT2 tokenizer) and code generation benchmarks (using the StarCoder tokenizer). The table compares the performance of the original model, the model after zero-shot transfer using a heuristic method (FOCUS), the model after zero-shot transfer using the proposed hypernetwork method, and the models after n-shot transfer using the same methods. It highlights that continued training with the original tokenizer doesn’t always lead to better performance.
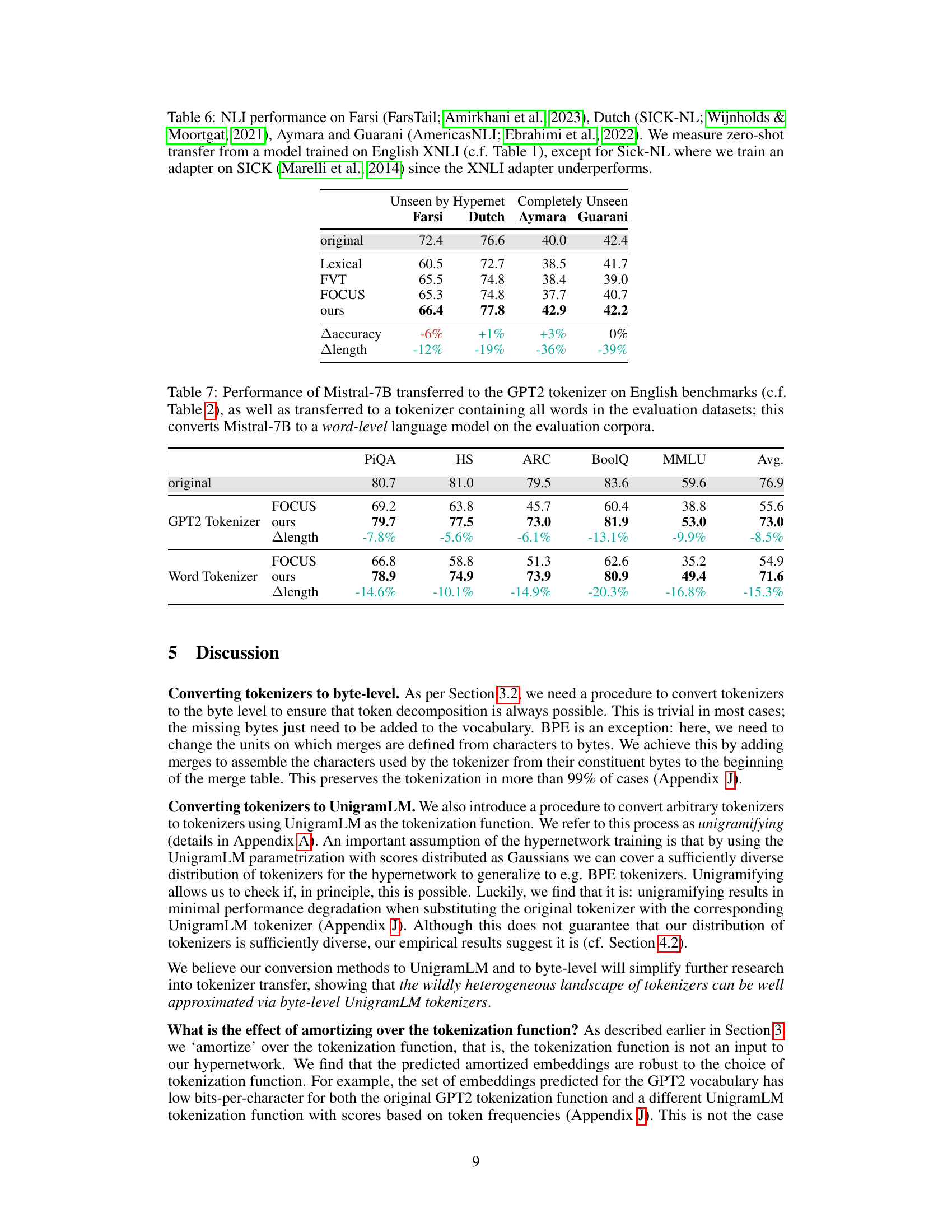
This table presents the accuracy results of the Mistral-7B model on the XCOPA benchmark using language-specific tokenizers. The results compare the performance of the original model (no tokenizer transfer), the FOCUS heuristic method for zero-shot tokenizer transfer, and the proposed hypernetwork method. Standard errors for the accuracy values are indicated to show the reliability of the results.
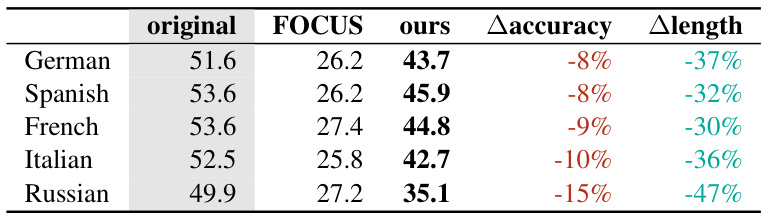
This table presents the 5-shot accuracy results on the multilingual MMLU benchmark using the Mistral-7B language model. It compares the performance of the original model with language-specific tokenizers against two zero-shot tokenizer transfer methods: FOCUS (a baseline heuristic method) and the proposed hypernetwork method. The table shows the accuracy achieved by each method for five different languages (German, Spanish, French, Italian, and Russian) and indicates the percentage change in accuracy (△accuracy) and token length reduction (△length) compared to the original model’s performance for each language.

This table presents the results of transferring a fine-tuned language model (Mistral-7B-Instruct-v0.1) to a new tokenizer (GPT2) using a hypernetwork trained on the base model (Mistral-7B). It compares the performance of the original fine-tuned model, a version with embeddings replaced by those from the base model, zero-shot transfer using a heuristic method (FOCUS), zero-shot transfer using the hypernetwork, and n-shot transfer (with continued training on 800M tokens) using the hypernetwork. The impact of a scaling factor (λ) on performance is also evaluated.
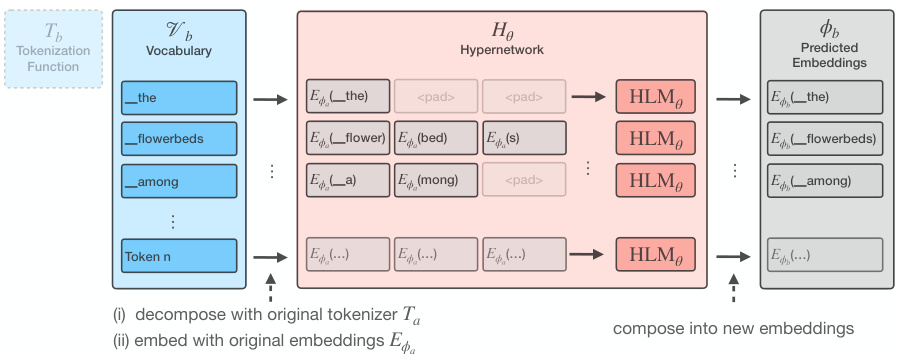
This table presents the results of applying zero-shot tokenizer transfer to the XLM-R model for cross-lingual tasks using the XNLI dataset. It compares the accuracy of the model using the original tokenizer against models using new zero-shot transferred tokenizers created by the proposed hypernetwork approach and other baseline methods (Lexical, FVT, OFA, FOCUS). The table shows the accuracy for each language in the dataset, the absolute change in accuracy from using the hypernetwork (Δaccuracy), and the percentage reduction in the average token length compared to the original tokenizer (Δlength). This demonstrates the effectiveness of the proposed method in both improving efficiency and maintaining accuracy.
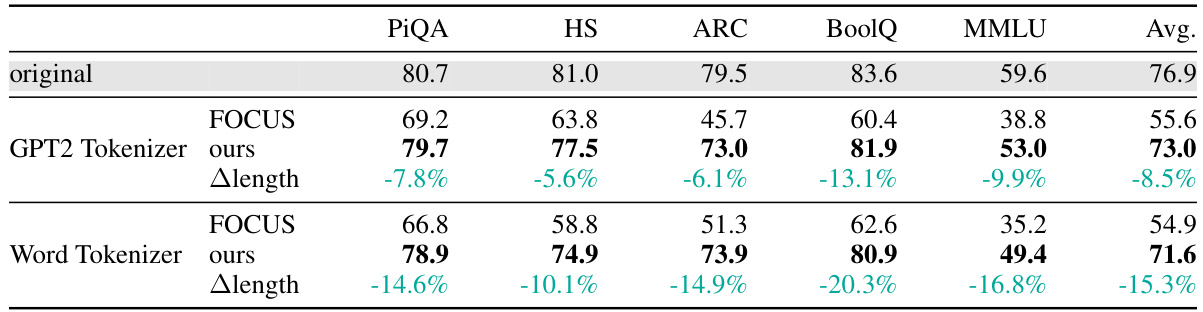
This table presents the performance of the Mistral-7B-v0.1 language model after performing zero-shot and n-shot tokenizer transfer. Zero-shot transfer uses a hypernetwork to predict embedding parameters for a new tokenizer without any training on data for the new tokenizer. N-shot transfer involves further training on 800 million tokens using the new tokenizer. The evaluation is done on natural language benchmarks (using GPT2 tokenizer) and code generation benchmarks (using StarCoder tokenizer). The table compares performance with the original model, a heuristic-based approach (FOCUS), and the proposed method (ours), highlighting both zero-shot and continued training results.

This table presents the performance of the hypernetwork, measured in bits-per-byte, with and without the inclusion of inter-token attention. It compares the performance across three different types of tokenizers: sampled tokenizers generated during training, a GPT-NeoX tokenizer, and an English UnigramLM tokenizer. The vocabulary sizes for each tokenizer type are indicated in parentheses.

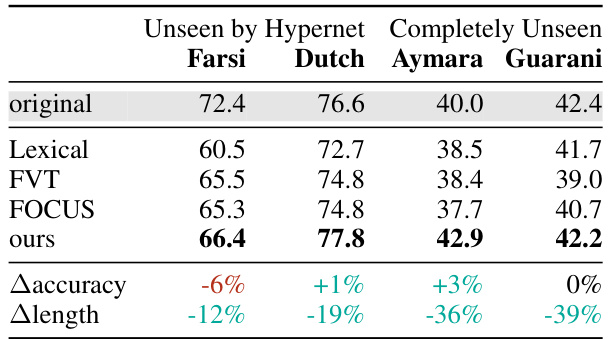
This table presents the results of experiments on cross-lingual transfer using the XLM-R model. It compares the accuracy achieved when using the original XLM-R tokenizer against the accuracy achieved with newly generated, language-specific zero-shot tokenizers. The table shows the performance of different methods (including the proposed hypernetwork), indicating the absolute changes in accuracy (Δaccuracy) and the average reduction in token sequence length (Δlength) for each language.
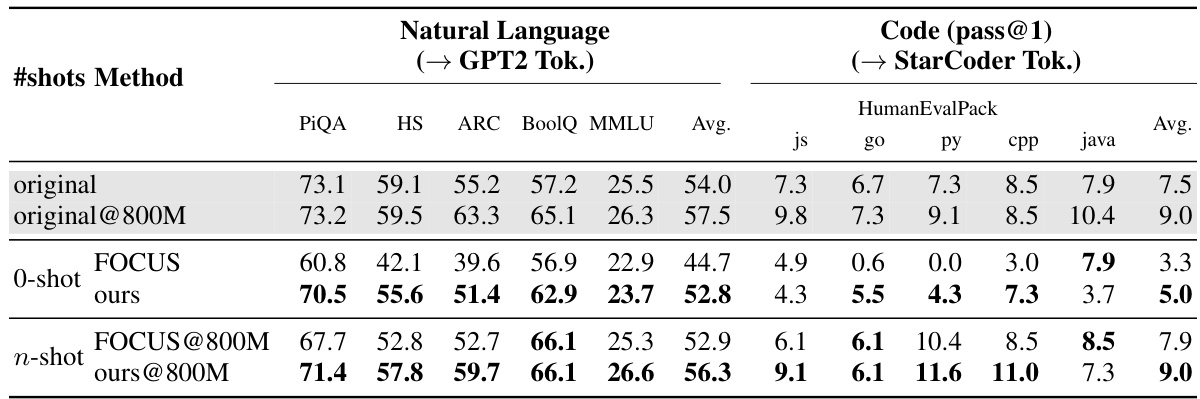
This table presents the performance comparison of Mistral-7B-v0.1 language model using different tokenizer transfer methods. It shows the results for zero-shot and n-shot transfer to GPT2 and StarCoder tokenizers across various natural language and code generation benchmarks. The ‘original’ row shows the performance of the original model, while ‘original@800M’ indicates the model’s performance after continued training with the original tokenizer. The ‘FOCUS’ rows show results using the FOCUS heuristic method for tokenizer transfer, and the ‘ours’ rows show the results of the proposed hypernetwork method. The comparison highlights the effectiveness of the hypernetwork approach.

This table presents the results of transferring a fine-tuned language model (Mistral-7B-Instruct-v0.1) to a new tokenizer (GPT2) using a hypernetwork trained on the base model. It compares the performance of the original fine-tuned model, a version with embeddings replaced by those from the base model, zero-shot transfer using FOCUS (a baseline method), zero-shot transfer using the proposed hypernetwork, and n-shot transfer (with continued training on 800M tokens) using the hypernetwork. The metric is a score (1-10) from gpt-3.5-turbo-1106, and the effect of a scaling factor (λ) on task arithmetic is also shown.
This table presents the accuracy results on the Cross-lingual NLI (XNLI) benchmark. The experiment reuses adapters trained on the original XLM-R model but with new zero-shot transferred language-specific tokenizers generated by the proposed hypernetwork method and several baseline methods. The table compares the accuracy of the different methods, showing the absolute change in accuracy compared to the original model (Δaccuracy) and the reduction in average token sequence length compared to the original model (Δlength). This demonstrates the effectiveness of the zero-shot tokenizer transfer approach on a cross-lingual task, highlighting both accuracy preservation and efficiency gains.

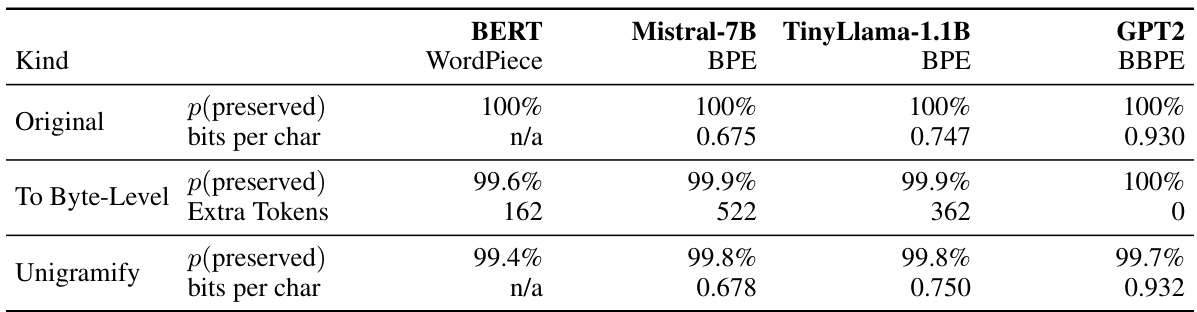
This table presents the bits-per-character for GPT2 using different tokenization methods and embedding approaches. It compares the original GPT2 embeddings with those predicted by the hypernetwork, both with and without added Gaussian noise during the sampling process. The tokenization methods include the original GPT2 tokenizer, a unigramified version (approximating the original with a UnigramLM model), and a UnigramLM tokenizer using substring frequencies as scores.

This table presents the results of applying zero-shot tokenizer transfer on XNLI using the XLM-R model with language-specific tokenizers. It compares the accuracy of the original model, several baseline methods (Lexical, FVT, OFA, FOCUS), and the proposed hypernetwork method. The table shows the accuracy for each language, the absolute change in accuracy when using the hypernetwork (compared to the original), and the average reduction in token sequence length achieved by the new tokenizers.
Full paper#