↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Long sequences with long-range dependencies are crucial for many AI tasks, but existing models like recurrent neural networks and transformers struggle with efficiency and effectiveness. Global convolutions offer a promising alternative but are challenging to train due to overfitting and difficulty in capturing long-range relationships. Current approaches to parameterization often involve complex mathematical methods or low-rank approximations that limit performance.
This paper introduces MRConv, which uses a novel approach to parameterize global convolutional kernels. By leveraging multi-resolution convolutions, a structural reparameterization scheme, and learnable kernel decay, MRConv learns expressive kernels that perform well across different data modalities. The authors demonstrate that MRConv achieves state-of-the-art performance on various benchmark datasets and improves efficiency compared to existing methods. The proposed reparameterization scheme is crucial to the improvement in performance and efficiency.
Key Takeaways#
Why does it matter?#
This paper is important because it presents MRConv, a novel approach to efficiently model long sequences. It addresses the limitations of existing methods by using reparameterized multi-resolution convolutions, leading to improved performance and efficiency across various data modalities. This opens new avenues for research in long sequence modeling, especially for tasks with long-range dependencies.
Visual Insights#
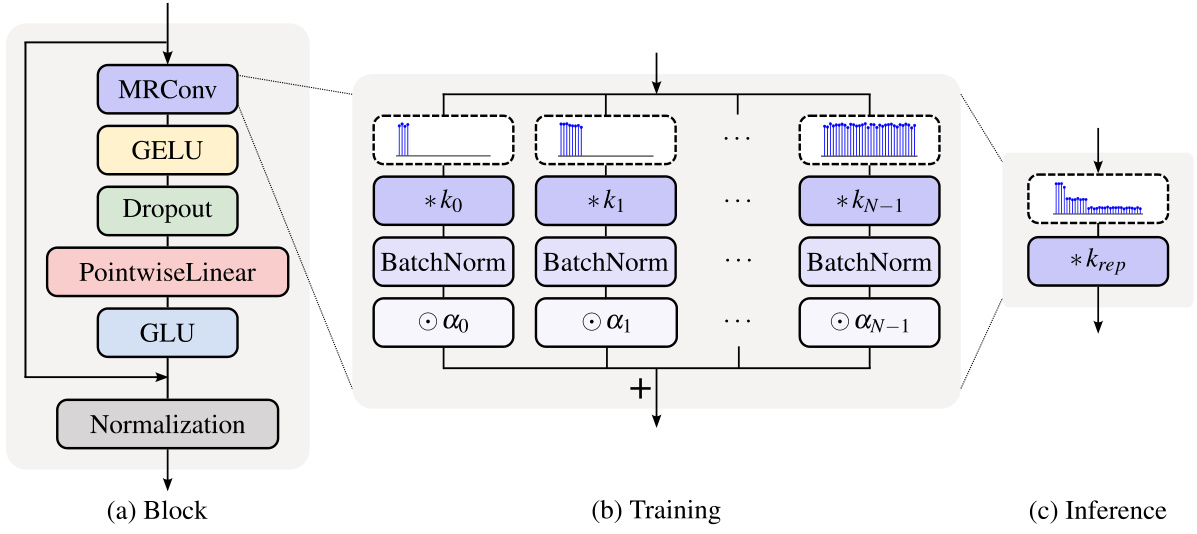
This figure illustrates the MRConv block architecture. The left panel shows the block’s components: a MRConv layer, GELU activation, pointwise linear layer, GLU, and normalization. The middle panel details the training process, where the input is processed through N parallel branches, each with its own convolution kernel and BatchNorm parameters, then summed after pointwise multiplication with learnable weights. The right panel shows the inference stage, where the parallel branches are reparameterized into a single convolution for efficiency.
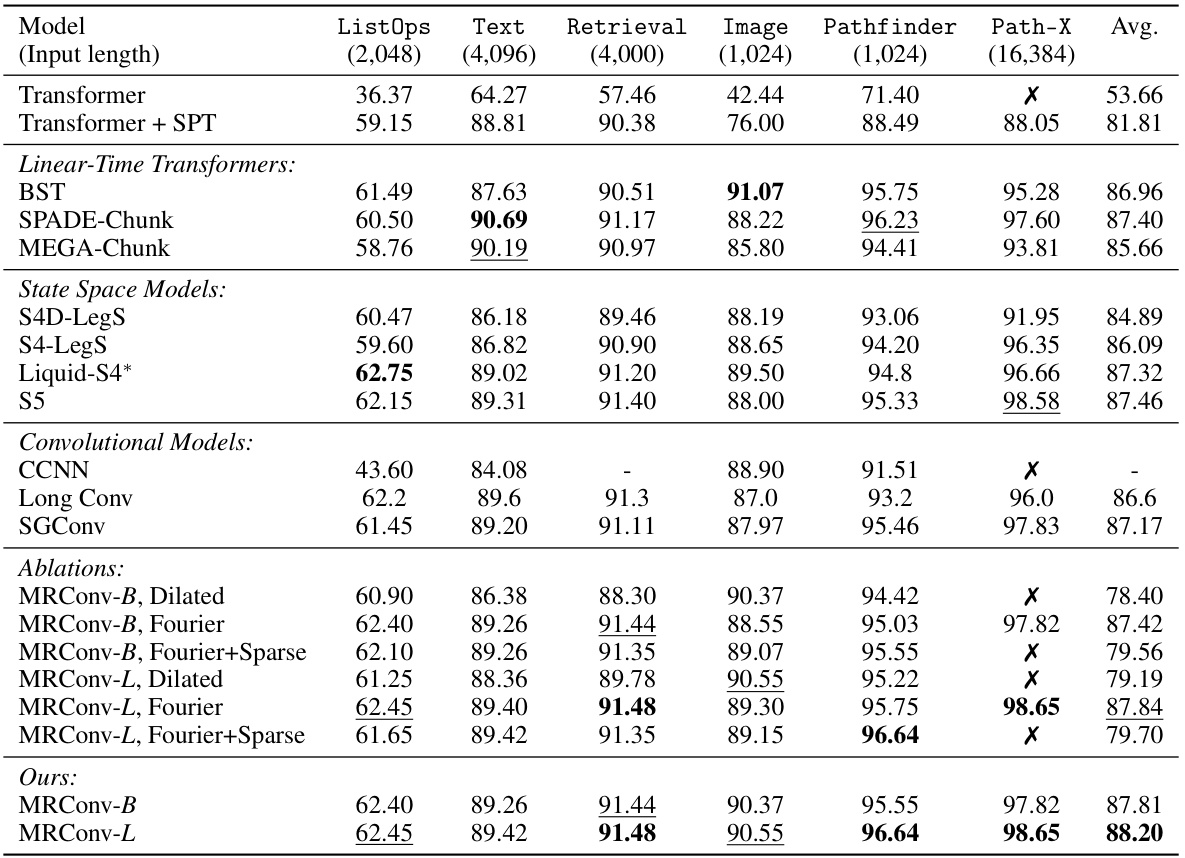
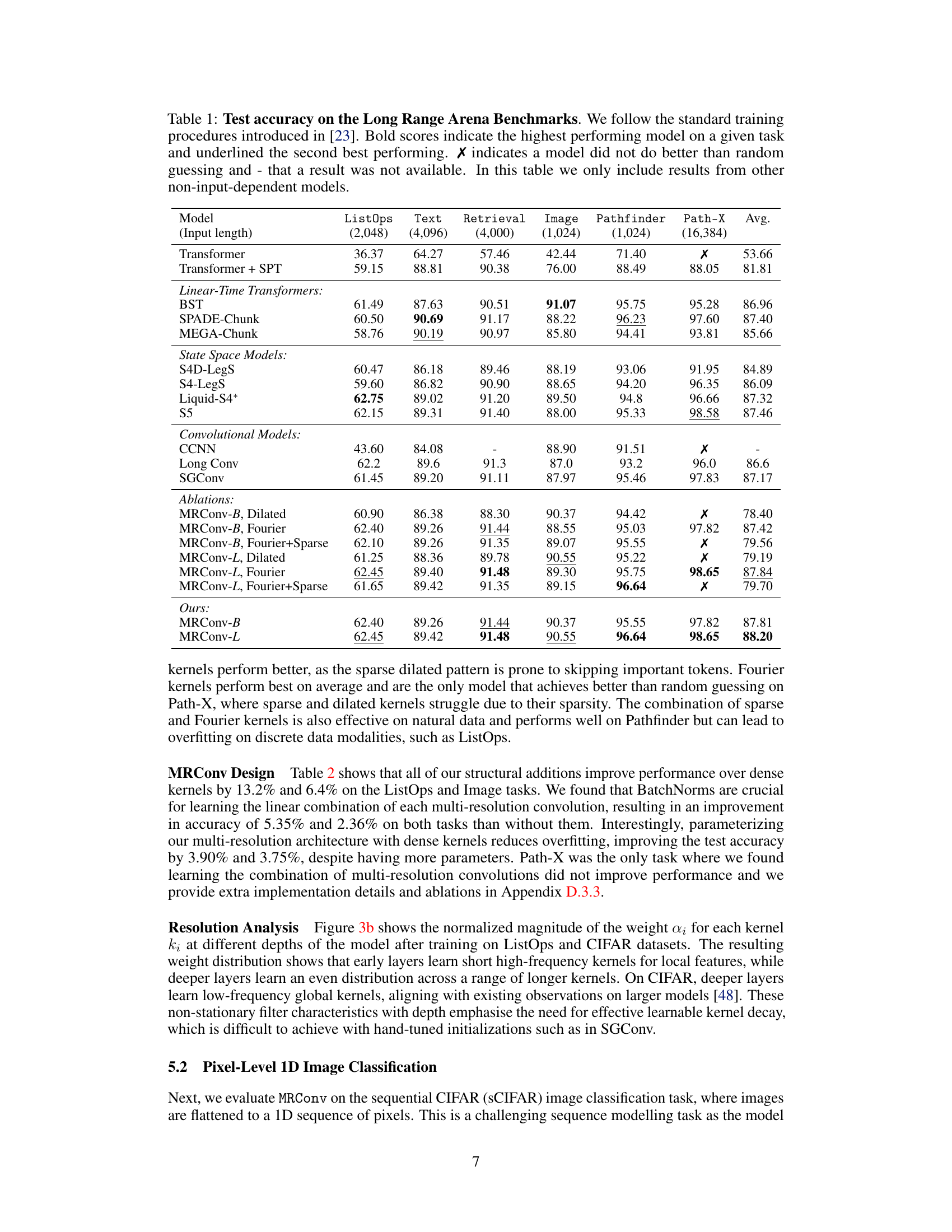
This table presents the test accuracy results on the Long Range Arena (LRA) benchmark for various sequence models. The models are categorized into Transformers, State Space Models, and Convolutional Models, with several ablations of MRConv also included. The results are shown for six different tasks within the LRA benchmark: ListOps, Text Retrieval, Image, Pathfinder, Path-X, and an average across all tasks. The table highlights the state-of-the-art performance of MRConv among the attention-free models.
In-depth insights#
MRConv: Intro#
The hypothetical introduction, “MRConv: Intro,” would ideally set the stage for a research paper introducing a novel multi-resolution convolutional model (MRConv) designed for long-sequence modeling. It should begin by highlighting the challenges in effectively handling long-range dependencies in sequences, common in tasks like speech recognition, language modeling, and time series forecasting. The introduction should then position MRConv as a solution that addresses these challenges. Key features of MRConv that warrant mention include its multi-resolution architecture, likely designed to capture both local and global patterns in the data, its use of reparameterization techniques to facilitate efficient training, and the incorporation of learnable kernel decay to prevent overfitting on long sequences. The “Intro” should emphasize the advantages of MRConv over existing models such as recurrent neural networks (RNNs), conventional CNNs, and transformers, perhaps by highlighting MRConv’s computational efficiency or ability to handle extremely long sequences. Finally, it should concisely outline the paper’s structure, signaling how the remaining sections will further explore the model, experimental results, and conclusion.
Multi-Res Convolutions#
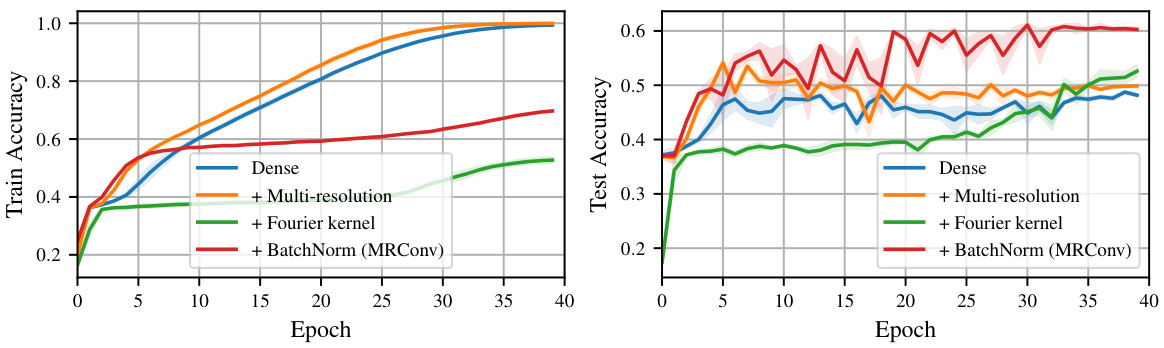
The concept of “Multi-Res Convolutions” suggests a powerful approach to enhancing convolutional neural networks by incorporating multiple resolutions within a single convolutional layer. This technique aims to capture both local and global contextual information simultaneously, thereby improving the model’s ability to learn complex patterns. The main advantage lies in the increased receptive field, allowing the network to consider a broader range of input features, which is especially crucial for long-range dependencies in sequence data. Different strategies exist for implementing multi-resolution convolutions, including using dilated convolutions with varying dilation rates or combining multiple convolutional kernels of different sizes. Reparameterization techniques are often crucial to make training and inference more efficient in these scenarios. By carefully designing the sub-kernels and their combination, models can learn more effective long-range dependencies without suffering excessive computational burdens, leading to improved model performance and potentially reduced overfitting. The effectiveness of this approach is further boosted by incorporating learnable decay, allowing the network to better prioritize relevant information. Overall, multi-resolution convolutions represent a significant step toward improving the efficiency and effectiveness of CNNs.
Reparameterization Tricks#
Reparameterization, in the context of deep learning, involves modifying the way model parameters are represented without changing their underlying functionality. Effective reparameterization can significantly improve training stability and efficiency. This is crucial for complex models where directly optimizing parameters is difficult or computationally expensive. Common techniques include using low-rank approximations, which reduce the number of parameters needing direct optimization, or employing structural reparameterizations, that decompose a complex parameter into simpler components. Multi-resolution convolutions and learnable kernel decay are powerful examples, allowing models to learn long-range dependencies more effectively. By training sub-kernels independently and then combining them at inference, this approach leverages the benefits of both local and global contexts. The reparameterization tricks, when applied strategically, can facilitate training, making it possible to train significantly larger and more expressive models than what would otherwise be feasible. The main goal is to enhance the model’s capability to capture long-range relationships while mitigating the computational cost and overfitting issues that often arise during training.
Long-Range Arena Results#
The Long-Range Arena (LRA) results section would be crucial in evaluating the model’s performance on long-range dependency tasks. A thorough analysis would involve examining the model’s performance across various datasets within LRA, comparing it to other state-of-the-art models. Key metrics to consider include accuracy, and efficiency. Significant improvements over existing methods, especially those focusing on efficiency like linear-time transformers, would be strong evidence supporting the model’s capabilities. The results should be presented clearly, ideally using tables and charts, and accompanied by an in-depth discussion of the findings. Analysis of the model’s performance across different sequence lengths and data modalities within LRA would reveal its strengths and limitations in handling various types of long-range dependencies. The discussion should also consider potential reasons behind the observed results, addressing any limitations of the experimental setup or theoretical framework. For instance, the impact of hyperparameters on the model’s performance should be analyzed. Finally, the overall conclusions should clearly summarize the model’s capabilities on long-range sequence tasks, emphasizing both its successes and areas for future work.
MRConv: Limitations#
The heading ‘MRConv: Limitations’ prompts a critical examination of the proposed multi-resolution convolutional model. A key limitation is the increased computational cost during training due to the parallel training of sub-kernels, significantly impacting memory usage and slowing down the training process. This contrasts with the efficiency achieved during inference. Another significant limitation is the lack of inherent input dependency. While MRConv excels on tasks with natural data modalities like images and audio, its performance on data with strong sequential dependencies, such as text, lags behind state-of-the-art linear-time transformers. Addressing this necessitates incorporating mechanisms for handling input dependencies, possibly by integrating recurrent units or attention mechanisms, in future iterations. The reliance on batch normalization during training, while beneficial for optimization, hinders efficient reparameterization during inference, again limiting practical efficiency. Lastly, direct autoregressive inference is not supported, potentially making it less suitable for applications demanding real-time generation. These factors highlight areas for improvement and provide valuable context for future development and applications of MRConv.
More visual insights#
More on figures
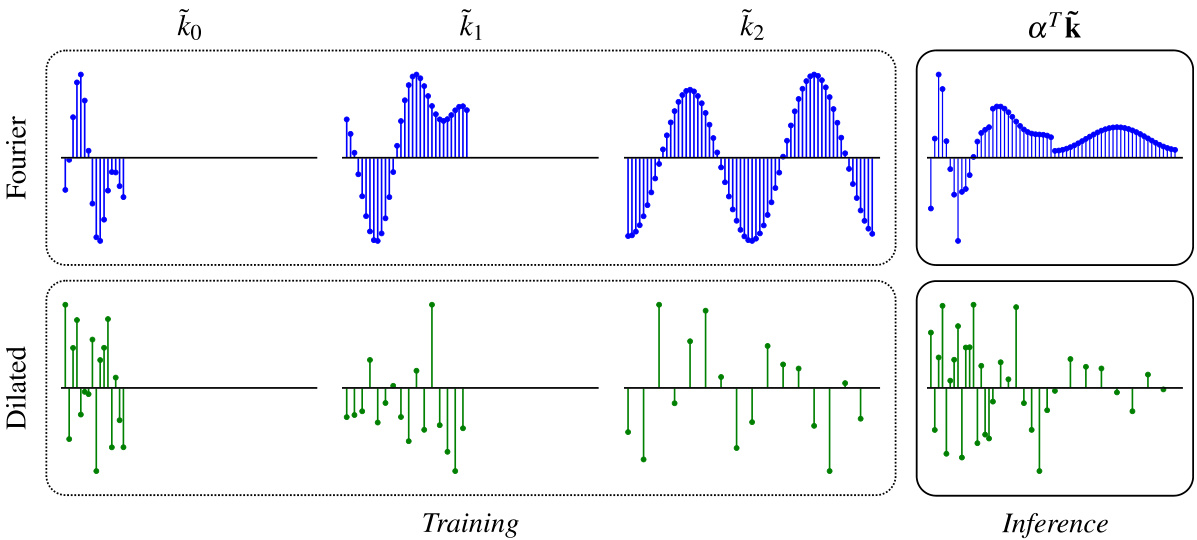
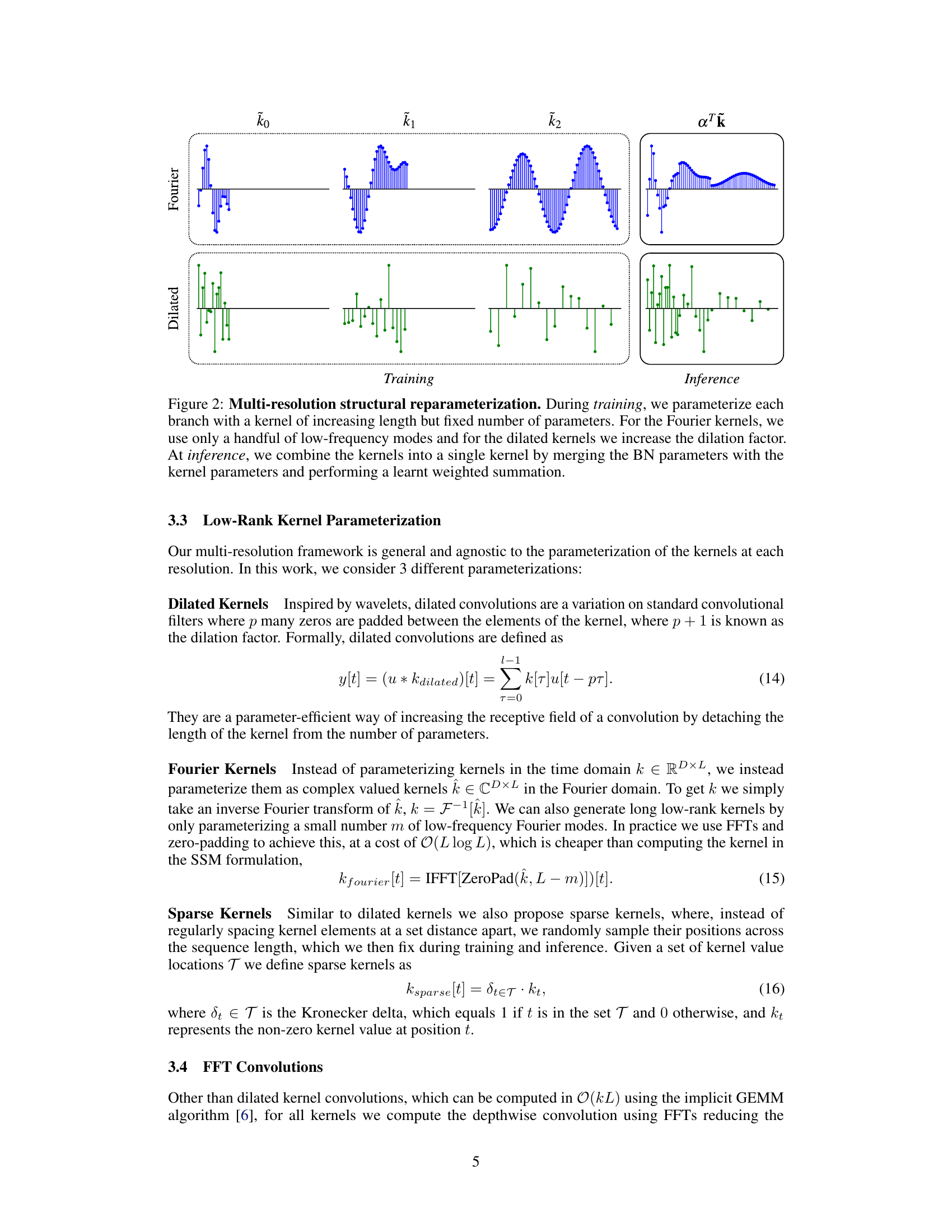
This figure illustrates the multi-resolution structural reparameterization used in MRConv. During training, multiple branches with kernels of increasing length but a fixed number of parameters are used. For Fourier kernels, only low-frequency modes are employed, while for dilated kernels, the dilation factor is increased. At inference, these branches are reparameterized into a single kernel by merging batch normalization (BN) parameters with the kernel parameters and performing a learned weighted summation. This improves efficiency and allows for the use of longer kernels effectively.
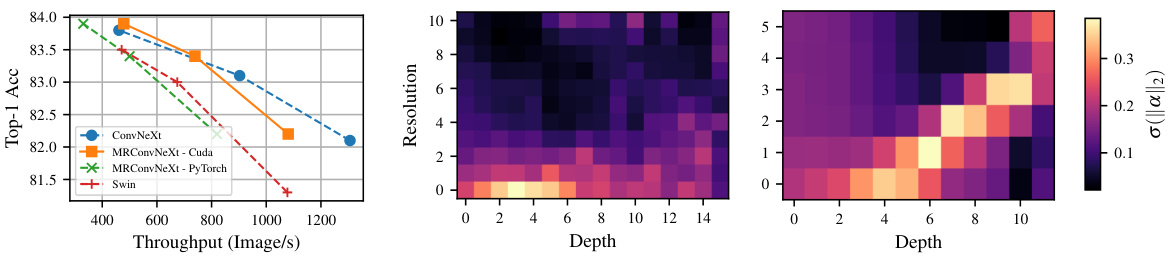
This figure shows two plots. The left plot shows a comparison of the top-1 accuracy and throughput of different models on the ImageNet dataset. The right plot displays the distribution of the squared L2 norm of the learned weights (α) across different depths and resolutions of the MRConv model. The color intensity represents the magnitude of ||α||². This visualization helps illustrate how the kernels’ composition changes across different depths, indicating the model’s non-stationary behavior with respect to depth.

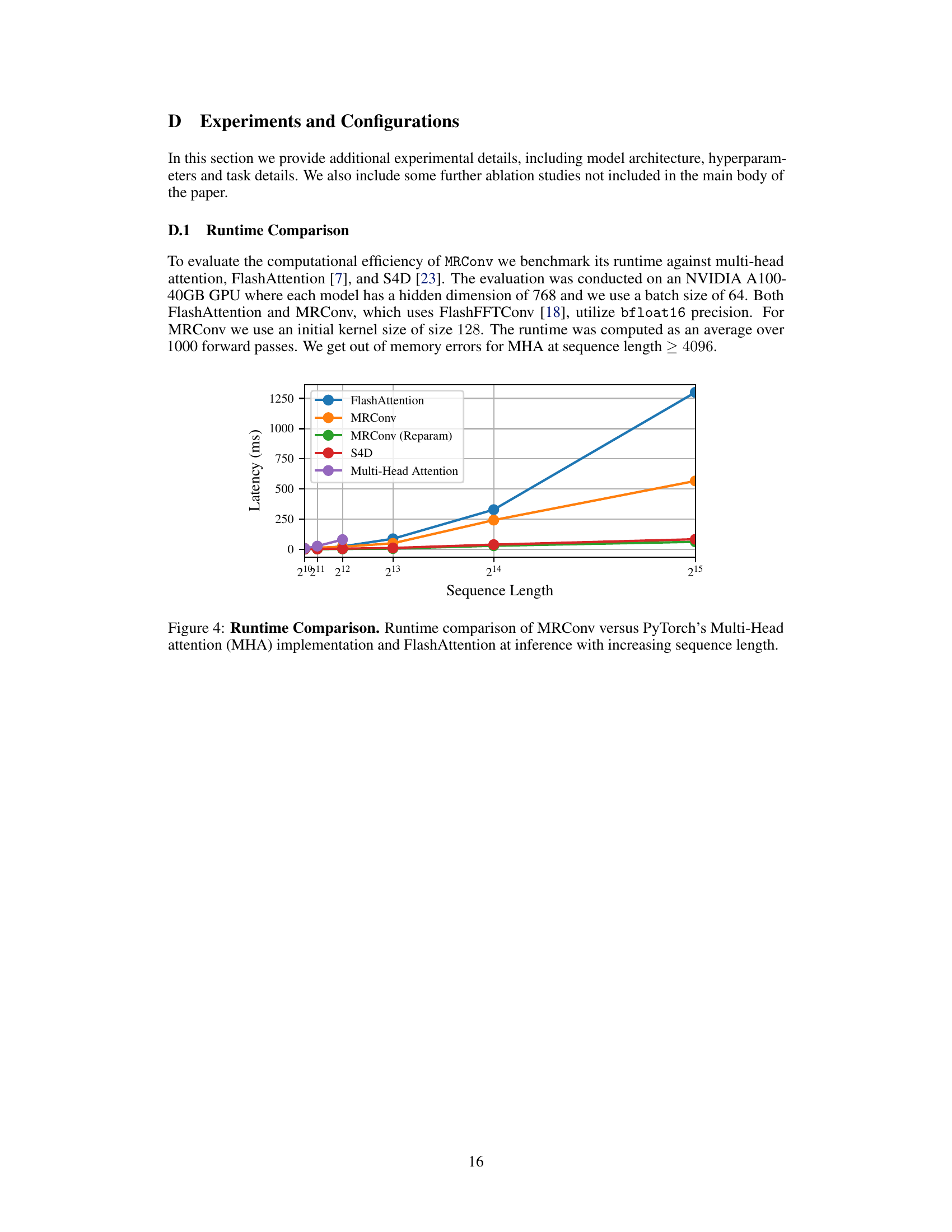
This figure compares the inference time of various sequence models against increasing sequence lengths. The models compared are MRConv, FlashAttention, S4D, and Multi-Head Attention. The graph shows that FlashAttention and MRConv scale better than Multi-Head Attention and S4D for longer sequences, with MRConv demonstrating the best performance in terms of inference speed. This highlights MRConv’s efficiency for long sequences.
This figure illustrates the MRConv block architecture. The left panel shows the block’s components: a multi-resolution convolution (MRConv) layer, GELU activation, a pointwise linear layer for channel mixing, and a gated linear unit (GLU). The middle panel details the training process, where the input is processed through N parallel branches, each with its own kernel and batch normalization. The branches’ outputs are weighted and summed. Finally, the right panel shows that during inference, these branches are reparameterized into a single convolution for efficiency.

This figure shows the architecture of the MRConv block. The left panel shows the components of the block, including a multi-resolution convolution layer, GELU activation, a pointwise linear layer, and a gated linear unit. The middle panel illustrates the training process, where the input is processed by N branches, each with its own convolution kernel and batch normalization parameters. The outputs of the branches are weighted and summed. The right panel depicts the inference process, where the branches are reparameterized into a single convolution.
This figure shows the architecture of the MRConv block. The left panel shows the block’s composition: a MRConv layer, a GELU activation function, a pointwise linear layer, and a gated linear unit (GLU). The middle panel illustrates the training process, where the input is processed through N parallel branches, each having its own convolution kernel of increasing length and batch normalization (BatchNorm) parameters. The branches’ outputs are weighted (by learnable parameters αᵢ) and summed. The right panel demonstrates the inference process, where the N branches are efficiently reparameterized into a single convolution operation.
More on tables
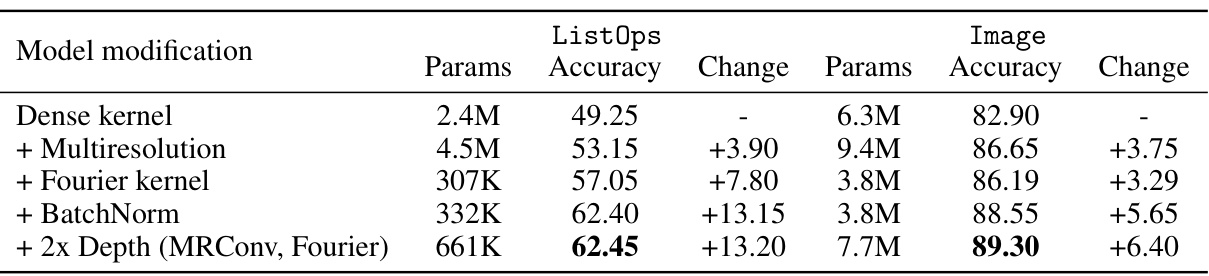
This table presents the ablation study results for the MRConv model on ListOps and Image tasks from the Long Range Arena (LRA) benchmark. It shows how different design choices (adding multi-resolution, Fourier kernels, BatchNorm, and increasing model depth) impact the model’s performance in terms of accuracy and the number of parameters. The table also provides a comparison to the parameter counts of similar models, S4-LegS and Liquid-S4.
This table presents the test accuracy results on various tasks from the Long Range Arena (LRA) benchmark. It compares the performance of the proposed MRConv model against several state-of-the-art baselines, including various transformer models and other convolutional models. The table shows accuracy scores for different sequence lengths and various data modalities. Bold scores highlight the best-performing model for each task, while underlined scores indicate the second-best.
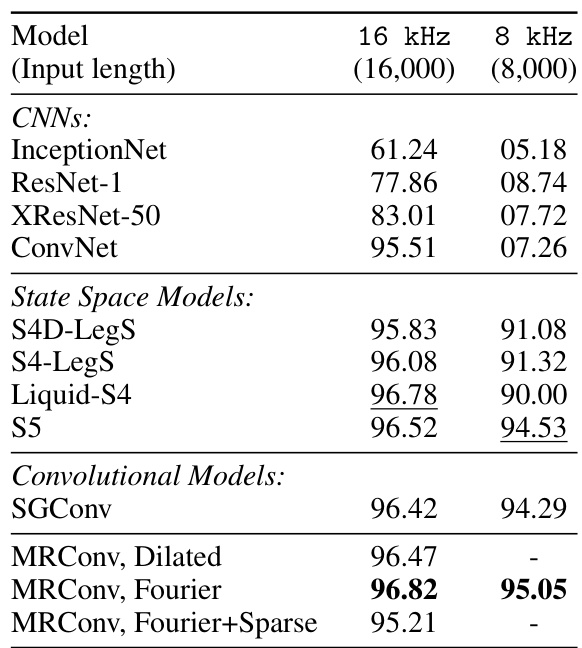
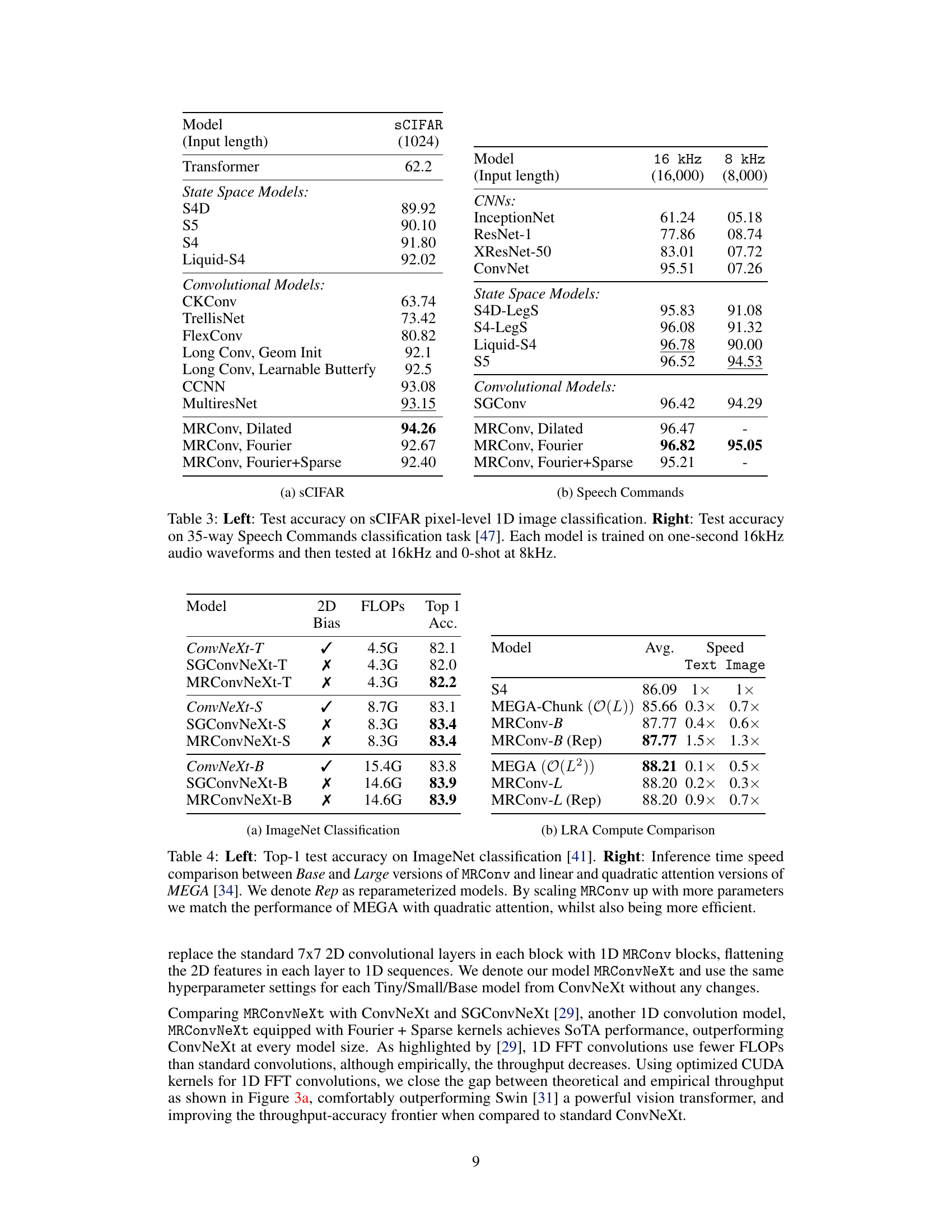
This table presents the test accuracy results for a 35-way speech command classification task. The models were trained using one-second audio waveforms sampled at 16kHz. The table shows the performance at both the original 16kHz sampling rate and a zero-shot evaluation at 8kHz (obtained by downsampling). The results are compared against several baselines from the literature.
This table presents the test accuracy results on the Long Range Arena benchmark dataset for various sequence models. It compares the performance of MRConv against several baseline models across six different tasks (ListOps, Text Retrieval, Image, Pathfinder, Path-X, and an average across all tasks). The table highlights MRConv’s state-of-the-art performance, particularly when compared to other non-input-dependent models.
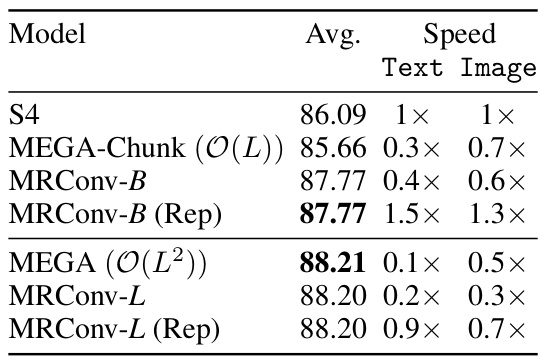
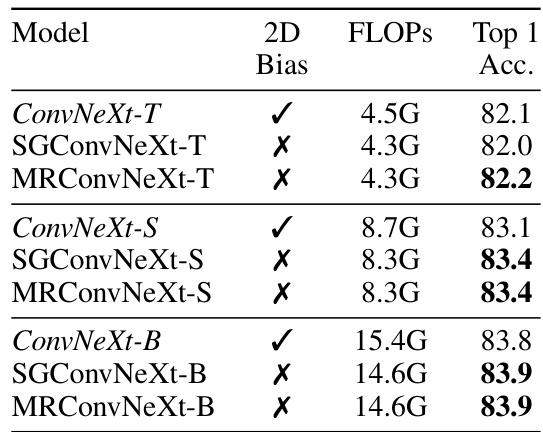
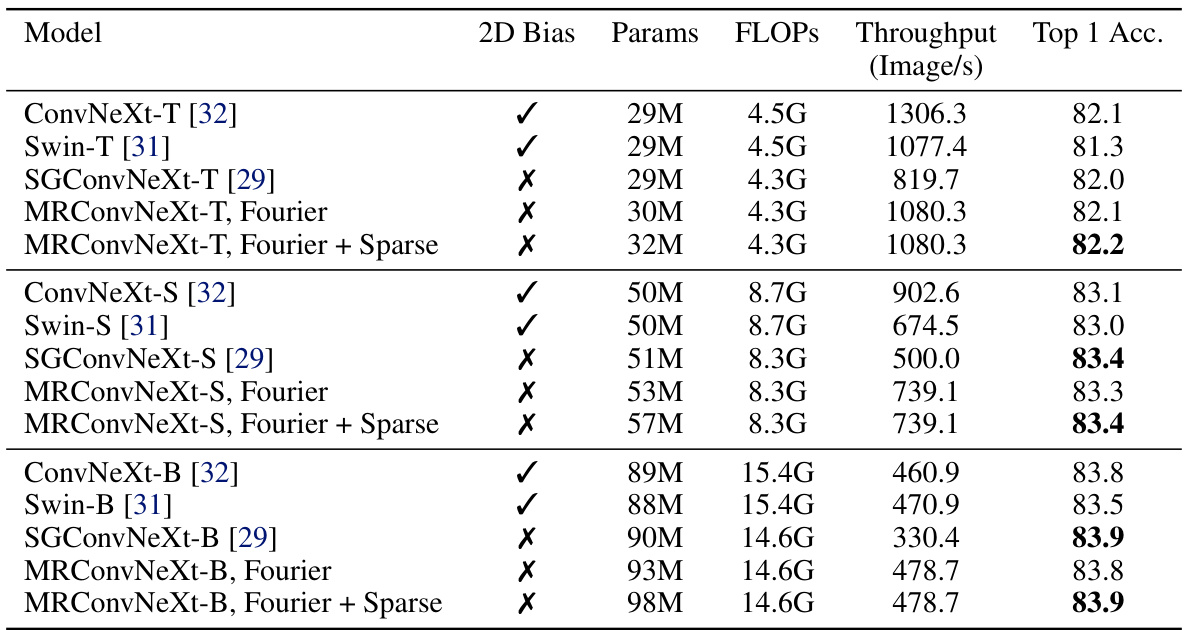
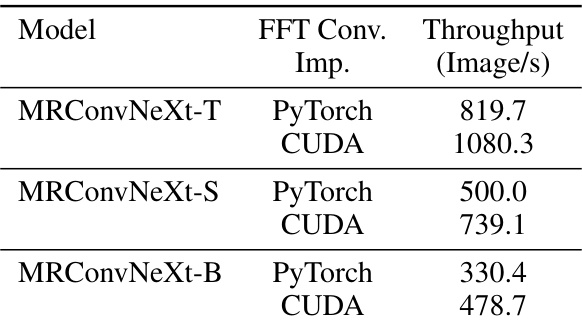
This table compares the performance and efficiency of MRConv with other models on the ImageNet classification task. The left side shows the Top-1 accuracy for various models, highlighting that MRConv achieves state-of-the-art results. The right side focuses on inference time speed, demonstrating that MRConv’s speed is competitive and efficient compared to state-of-the-art models.

This table presents the test accuracy results on the Long Range Arena (LRA) benchmark for various sequence models. The models are categorized into Transformer-based models, linear-time Transformers, state-space models, and convolutional models. The table compares the performance of the proposed MRConv model against state-of-the-art baselines across six different tasks within the LRA benchmark: ListOps, Text, Retrieval, Image, Pathfinder, and Path-X. Results are shown for different input sequence lengths and different model variants. Bold scores highlight the best performing model for each task, and underlined scores show the second-best performing model.

This table presents the test accuracy results on the Long Range Arena (LRA) benchmark for various sequence models. It compares MRConv (the proposed model) against several state-of-the-art baselines, including different transformer and convolutional models, across six different tasks. The tasks involve various data modalities and sequence lengths to assess long-range dependency modeling capabilities. The table highlights the performance of MRConv against these baselines, demonstrating its state-of-the-art performance in various scenarios.

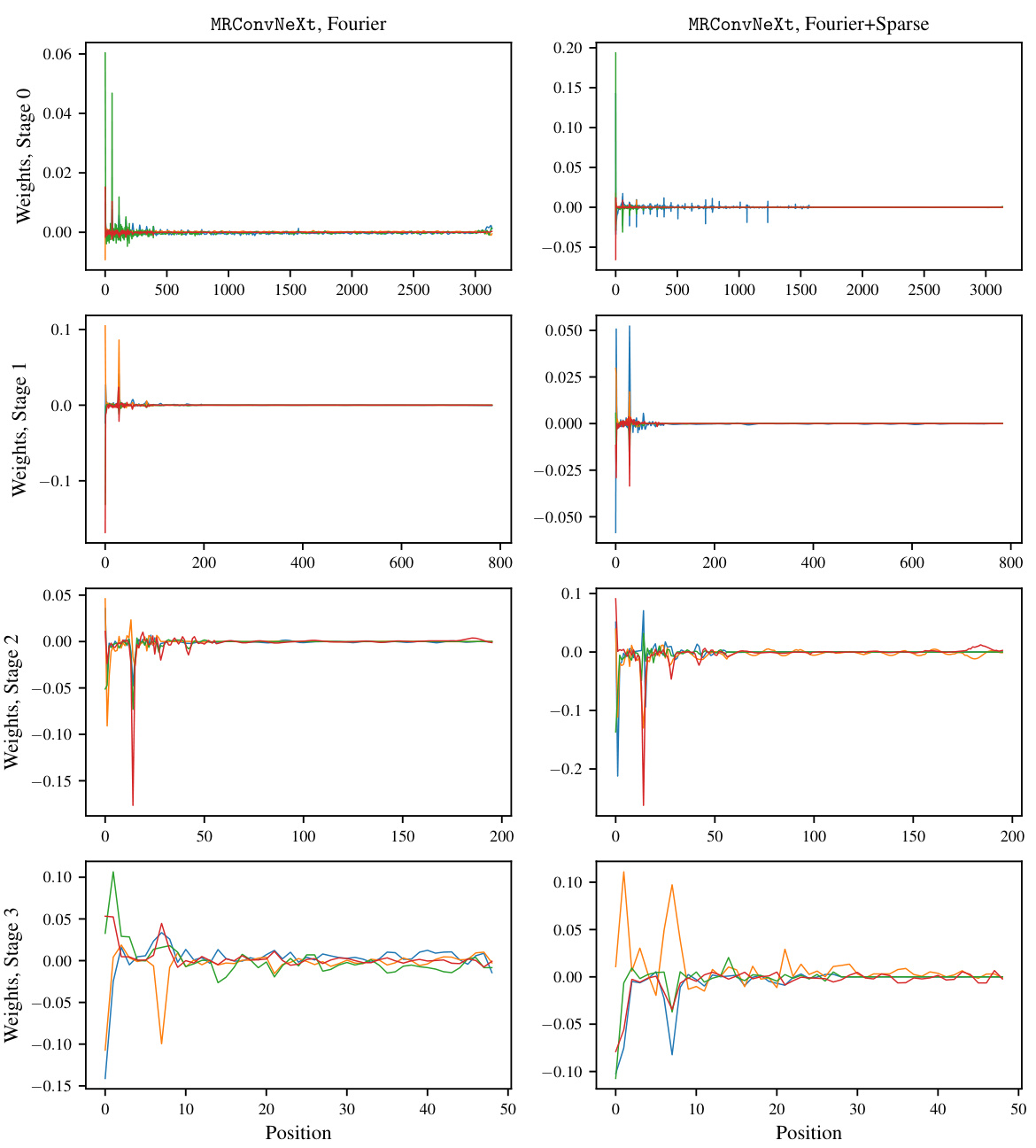
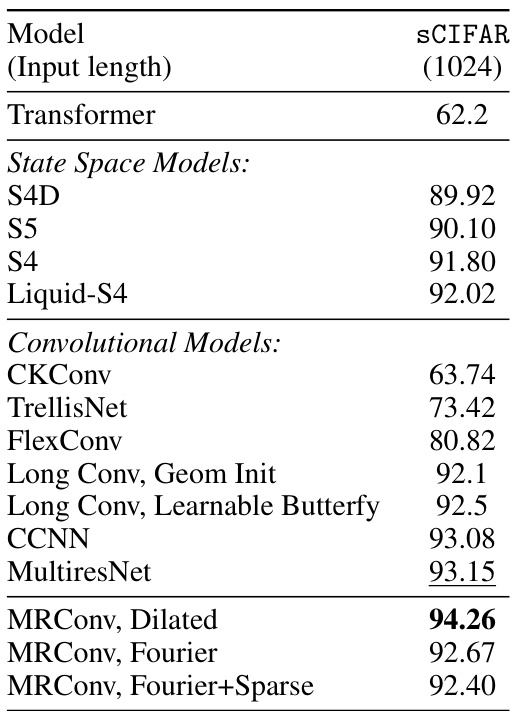
This table presents the test accuracy results on the Long Range Arena (LRA) benchmark for various sequence models. It compares the performance of MRConv with different kernel parameterizations (Dilated, Fourier, and Fourier+Sparse) against various baselines, including Transformers and other convolutional models. The table highlights the average performance across multiple tasks within the benchmark (ListOps, Text Retrieval, Image, Pathfinder, Path-X), showing MRConv’s competitive performance compared to existing state-of-the-art models.

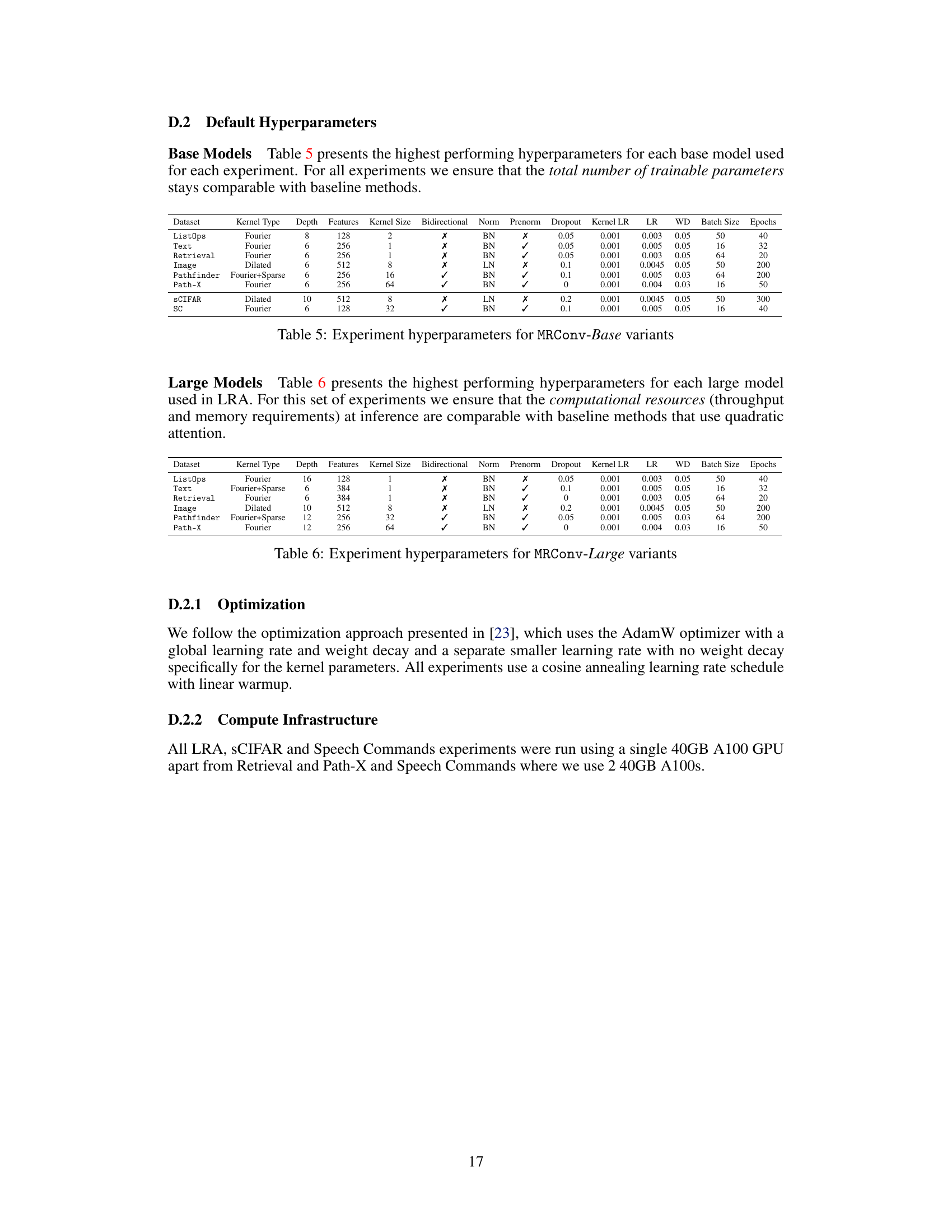
This table presents the hyperparameters used for the MRConv-Base model variants in the Long Range Arena experiments. It shows the dataset used, kernel type, depth, number of features, kernel size, whether bidirectional convolutions were used, normalization type (Batch Normalization or Layer Normalization), whether pre-normalization was applied, dropout rate, kernel learning rate, overall learning rate, weight decay, batch size, and number of epochs.

This table presents the hyperparameters used for the large variants of the MRConv model in the Long Range Arena experiments. It shows the kernel type, depth, number of features, kernel size, whether bidirectional convolutions were used, the type of normalization, whether pre-normalization was applied, the dropout rate, learning rate for the kernel, overall learning rate, weight decay, batch size, and number of epochs used for training. The hyperparameters were chosen to ensure the computational resources used for the large MRConv models were comparable to those of baseline methods that use quadratic attention.
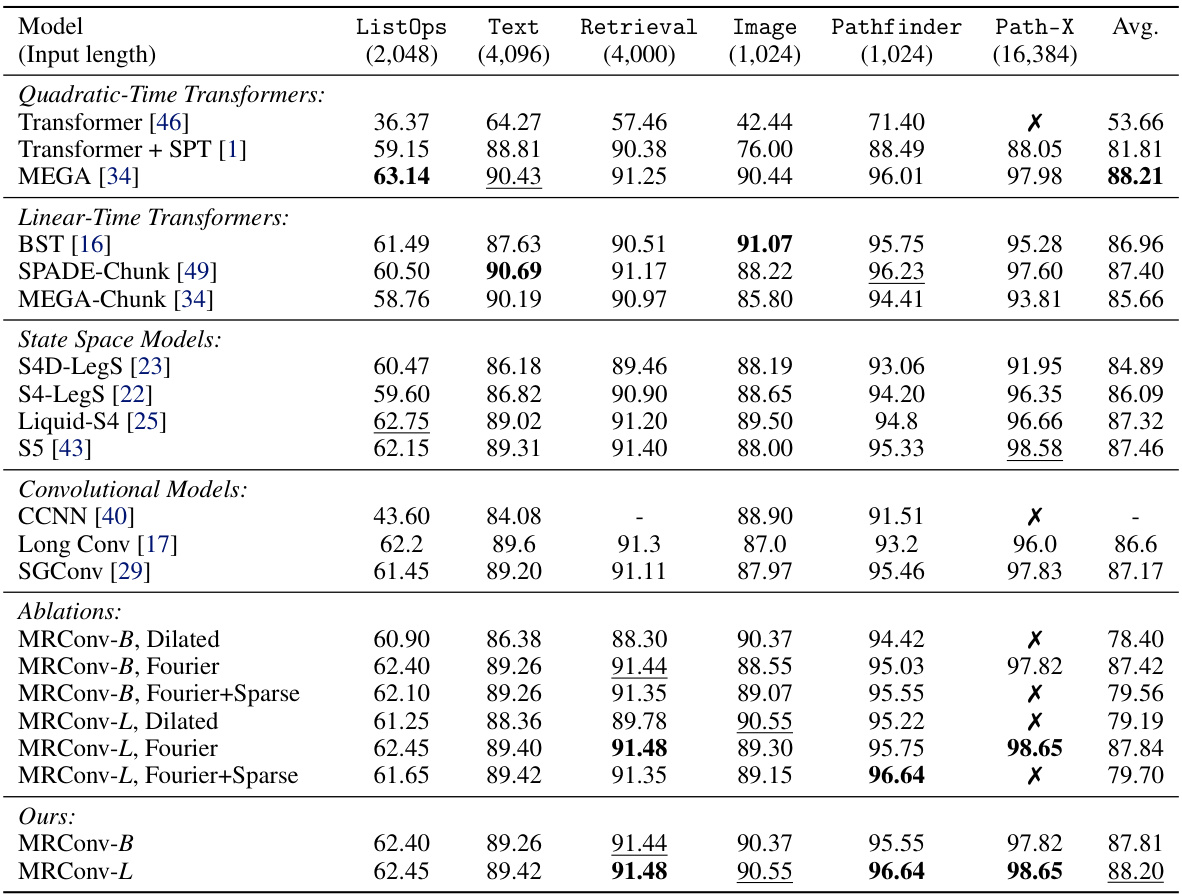
This table presents the test accuracy results on the Long Range Arena (LRA) benchmark for various sequence models. It compares different model types (Transformers, State Space Models, Convolutional Models) and variations of the proposed MRConv model with different kernel parameterizations (Dilated, Fourier, Fourier+Sparse). The table highlights the best-performing model for each task and includes an average performance across all tasks. Results are presented for both base and large model sizes of MRConv.

This table presents the test accuracy results on the Long Range Arena (LRA) benchmark. It compares the performance of MRConv against various baseline models on several tasks, including ListOps, Text Retrieval, Image, Pathfinder, and Path-X. The results highlight MRConv’s state-of-the-art performance in several tasks.
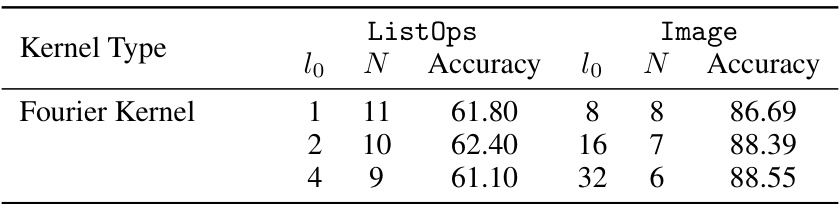
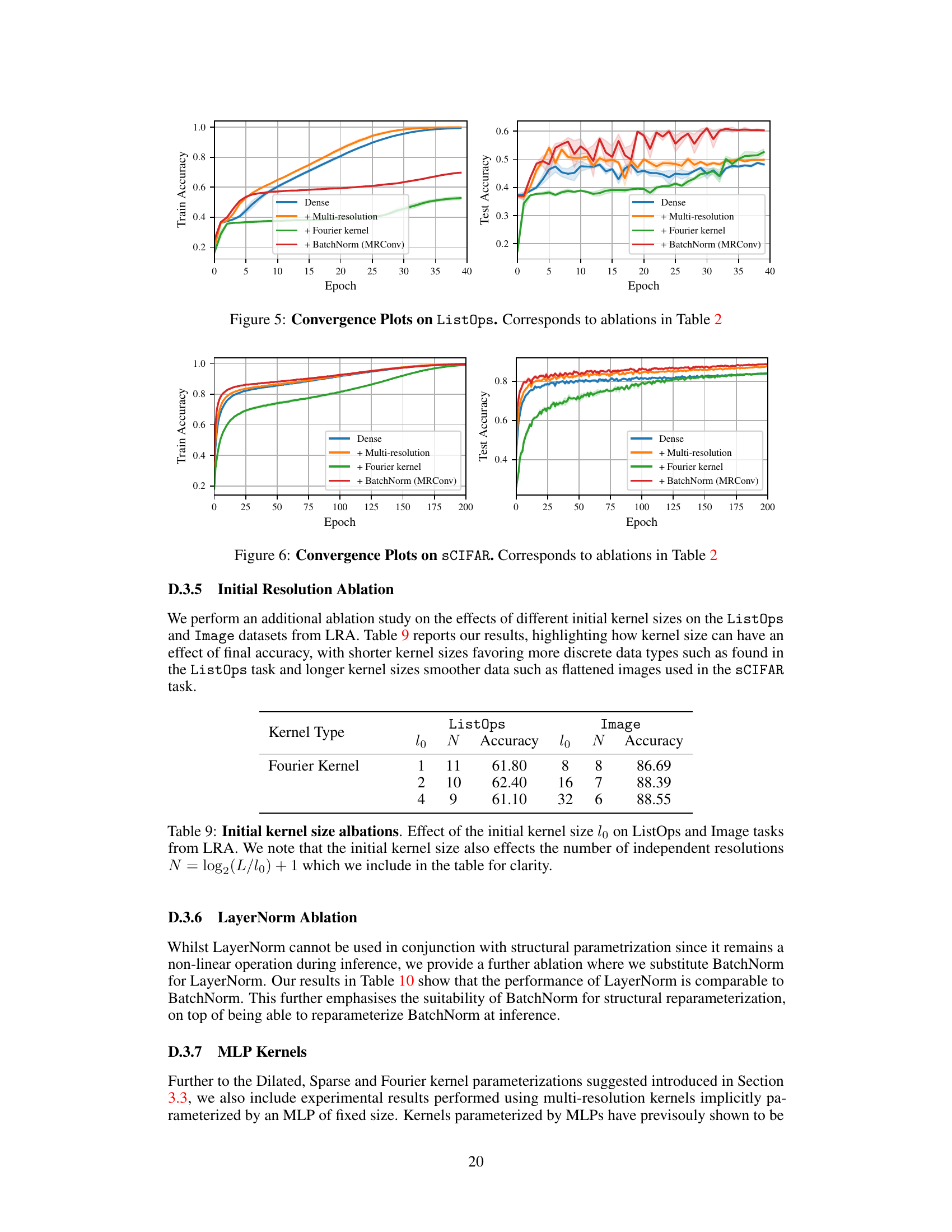
This table shows the results of an ablation study on the effect of different initial kernel sizes on the ListOps and Image tasks from the Long Range Arena (LRA) benchmark. It demonstrates how the choice of initial kernel size impacts the final accuracy, with smaller kernel sizes performing better on more discrete datasets like ListOps and larger kernel sizes performing better on smoother image data.
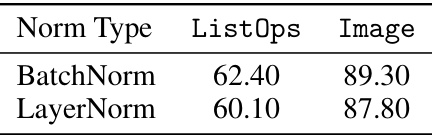
This table shows the result of ablations on different normalization techniques. It compares the performance of using BatchNorm vs LayerNorm in the MRConv model on the ListOps and Image tasks from the Long Range Arena benchmark. The results indicate minimal performance difference between the two normalization methods, highlighting BatchNorm’s advantage due to its compatibility with the model’s structural reparameterization.

This table shows the results of an ablation study comparing different kernel parameterizations (Dilated, Fourier, Fourier+Sparse, and MLP) on two tasks from the Long Range Arena (LRA) benchmark: ListOps and Image. The table reports the number of parameters and the accuracy achieved by each parameterization on each task. This allows the reader to assess the impact of the different kernel types on the performance of the MRConv model.

This table presents the test accuracy results on the Long Range Arena (LRA) benchmark for various sequence models. It compares the performance of the proposed MRConv model against several state-of-the-art baselines, including transformers and other convolutional models, across different tasks within the LRA benchmark. The table highlights the best-performing model for each task and indicates when a model’s performance was no better than random guessing. Only non-input-dependent models are included in the comparison.

This table presents the test accuracy results on various tasks from the Long Range Arena (LRA) benchmark. It compares the performance of the proposed MRConv model against several other state-of-the-art models, including linear-time transformers and state-space models. The table highlights MRConv’s superior performance across different tasks and input lengths, showcasing its effectiveness in long-sequence modeling.
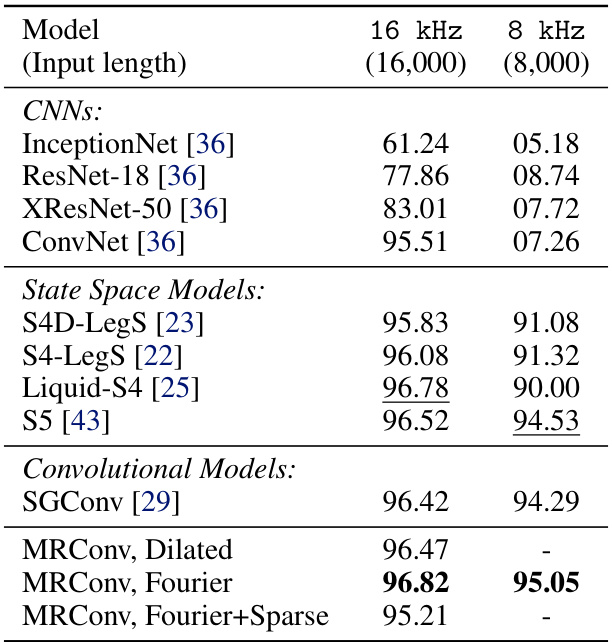
This table presents the test accuracy results of various models on the Speech Commands dataset [47], a task that involves classifying 35 spoken words from 1-second audio recordings. The models are evaluated at two sampling rates: 16 kHz (the original rate) and 8 kHz (zero-shot, downsampled). The table compares the performance of MRConv (with different kernel parameterizations) against several baseline models, including CNNs and state-space models. It demonstrates MRConv’s ability to perform well, especially at 16 kHz and even at 8 kHz for the Fourier kernel.
This table presents the test accuracy results on the Long Range Arena benchmark for various sequence models. The models are categorized into Transformers, State Space Models, and Convolutional Models. The table highlights the performance of MRConv (the proposed model) against these baselines across different tasks within the benchmark (ListOps, Text Retrieval, Image, Pathfinder, Path-X). Bold scores represent the best-performing model for each task, while underlined scores indicate the second-best performance. ‘X’ denotes models that did not perform better than random guessing, and ‘-’ indicates missing results. The table focuses specifically on non-input-dependent models for a fair comparison.

This table presents the test accuracy results on the Long Range Arena (LRA) benchmark. It compares various sequence modeling methods, including different versions of transformers and convolutional models, across six different tasks with various input lengths. The table highlights the top-performing models for each task, taking into account computational complexities and avoiding input-dependent models for a fair comparison.
This table compares the performance of MRConv against various other models on six different tasks from the Long Range Arena benchmark dataset. The tasks test the ability of models to handle long-range dependencies in various data modalities (text, images, paths, etc.). The table shows the test accuracy achieved by each model on each task. The best performing model on each task is highlighted in bold, while the second best is underlined. ‘X’ indicates models that performed no better than random guessing on the given task. The table focuses specifically on non-input dependent models.
Full paper#