↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-and-Language Navigation (VLN) systems, while promising, pose significant security risks as they become increasingly integrated into daily life. Malicious actors could exploit these systems for attacks by introducing backdoors that trigger unwanted behavior. Current research overlooks this critical security concern, focusing primarily on improving navigation performance.
This paper addresses this gap by introducing the concept of object-aware backdoors in VLN. The authors propose a novel paradigm called IPR Backdoor that leverages imitation, pre-training, and reinforcement learning to implant these backdoors effectively. They demonstrate the effectiveness of their method across various VLN agents in both physical and digital environments, showcasing its robustness to visual and textual variations while maintaining excellent navigation performance. This work is significant for highlighting a critical security flaw in VLN and providing a comprehensive approach to address it.
Key Takeaways#
Why does it matter?#
This paper is crucial because it pioneers the exploration of backdoor attacks in Vision-and-Language Navigation (VLN), a rapidly growing field with significant real-world applications. By highlighting the security vulnerabilities of VLN agents, it urges researchers to prioritize security in the design and deployment of these systems, paving the way for more robust and trustworthy AI applications. The innovative methods introduced offer new avenues for research into security issues of AI agents operating in real-world environments.
Visual Insights#

This figure shows an example of how a backdoored vision-and-language navigation (VLN) agent behaves differently in clean and poisoned scenes. In the clean scene, the agent follows instructions normally. However, when a specific object (the trigger) is present in the poisoned scene, the agent performs abnormal behavior (stops) as instructed by the backdoor, highlighting the stealthy nature and effectiveness of the proposed object-aware backdoor attack.

This table presents the results of an ablation study conducted on the IPR Backdoor method for object-aware backdoored Vision-and-Language Navigation (VLN). It systematically evaluates the impact of each component of the IPR Backdoor framework (Imitation Learning, Pretraining, and Reinforcement Learning) on the overall performance, specifically measuring the success rate of backdoor attacks (Att-SR), navigation success rate (SR), and other navigation metrics. The different components are represented by colored regions in the table.
In-depth insights#
Backdoor VLN Agents#
The concept of “Backdoor VLN Agents” introduces a critical security vulnerability in Vision-and-Language Navigation (VLN) systems. Malicious actors could exploit this vulnerability by embedding backdoors into VLN agents during the training phase. These backdoors activate when the agent encounters specific objects or textual instructions, causing it to deviate from its intended behavior and potentially perform harmful actions. This poses a significant threat to privacy and safety as VLN agents become increasingly integrated into real-world environments. The challenge lies in the inherent cross-modality and continuous decision-making nature of VLN, making the detection and mitigation of backdoor attacks extremely difficult. Research in this area is crucial to develop robust defenses against backdoor attacks that can safeguard the security and trustworthiness of VLN systems in various applications.
IPR Backdoor Method#
The IPR Backdoor method, as a novel backdoor attack paradigm for Vision-and-Language Navigation (VLN), cleverly integrates Imitation Learning, Pretraining, and Reinforcement Learning. Its key innovation lies in leveraging the inherent cross-modality and continuous decision-making nature of VLN. This approach utilizes physical objects as stealthy triggers, unlike traditional backdoors which use easily detectable digital triggers. The method’s effectiveness is demonstrated by its ability to seamlessly induce abnormal behavior (e.g., stopping) in VLN agents upon encountering specific objects, while maintaining remarkably high navigation performance in clean scenes. A crucial element is the Anchor Loss, which maps poisoned features to a textual anchor like “Stop”, ensuring precise alignment between the trigger and the desired abnormal behavior. Furthermore, a Consistency Loss is included to avoid trivial solutions, enhancing the robustness of the attack and navigation capabilities. The Backdoor-aware Reward balances the conflicting objectives of reinforcement learning, further bolstering the method’s overall effectiveness. The success of IPR Backdoor highlights the vulnerability of VLN agents to backdoor attacks and emphasizes the need for robust security measures in real-world applications.
Object-Aware Attacks#
Object-aware attacks represent a significant advancement in adversarial machine learning, moving beyond simple, easily detectable patterns like image patches. The use of everyday objects as triggers introduces a high degree of stealthiness, making the attacks far more challenging to detect and defend against. This approach leverages the natural environment, exploiting the agent’s interaction with real-world objects, rather than relying on artificially introduced artifacts. The seamless integration of malicious behavior into normal navigation tasks raises serious security concerns, particularly in privacy-sensitive contexts. While the examples provided focus on halting the agent, the underlying paradigm could be extended to facilitate a wider range of malicious actions. The effectiveness of the object-aware attack across different VLN agents and its resilience to visual and textual variations highlights the robustness and sophistication of this approach. This presents a new challenge for developers of VLN systems, demanding the development of more advanced defense mechanisms beyond simple trigger detection.
Robustness Analysis#
A robust system should consistently perform well even when faced with unexpected variations or disturbances. In the context of a Vision-and-Language Navigation (VLN) agent, a robustness analysis would be critical to evaluate its reliability. This analysis would need to consider several factors. Visual robustness could be evaluated by assessing the agent’s performance across various image qualities (e.g., different resolutions, lighting conditions, and presence of noise). Textual robustness could involve testing the system’s ability to interpret diverse instructions (e.g., variations in sentence structure, wording, and complexity), as well as its resilience to noisy or ambiguous commands. Another crucial aspect is environmental robustness: the system’s ability to handle variations in the environment, such as unexpected obstacles or changes in room layouts. A comprehensive robustness analysis would assess the system’s performance across a broad spectrum of conditions and identify its limitations. Ultimately, this would inform the design of more resilient and reliable VLN systems, capable of functioning effectively in real-world scenarios.
Future Defenses#
Future defenses against backdoor attacks in Vision-and-Language Navigation (VLN) agents must be multifaceted and proactive. Model interpretability techniques are crucial for identifying abnormal behavior patterns, potentially highlighting trigger-response mechanisms hidden within the model. Multi-modal consistency checks can help detect inconsistencies between visual inputs, language instructions, and agent actions, thus revealing inconsistencies indicative of malicious behavior. Strict control over object placement within VLN environments is necessary to prevent attackers from easily deploying triggers. Regular behavioral reviews, utilizing methods like surveillance footage analysis, are vital for identifying unexpected actions. Finally, robustness testing against various visual and textual variations is essential to build VLN agents resistant to diverse attack strategies. The development of these defenses is crucial to ensure secure and reliable VLN systems in real-world applications.
More visual insights#
More on figures

This figure shows three examples of physical objects used as triggers to activate a backdoor in a vision-and-language navigation (VLN) agent. Each row displays an object (yoga ball, wall painting, door) and a corresponding scene where the object is present. The agent behaves normally unless it encounters one of these objects, triggering a pre-programmed action (stopping). The figure highlights the stealthiness of the attack, as the triggers are naturally occurring objects within the environment.
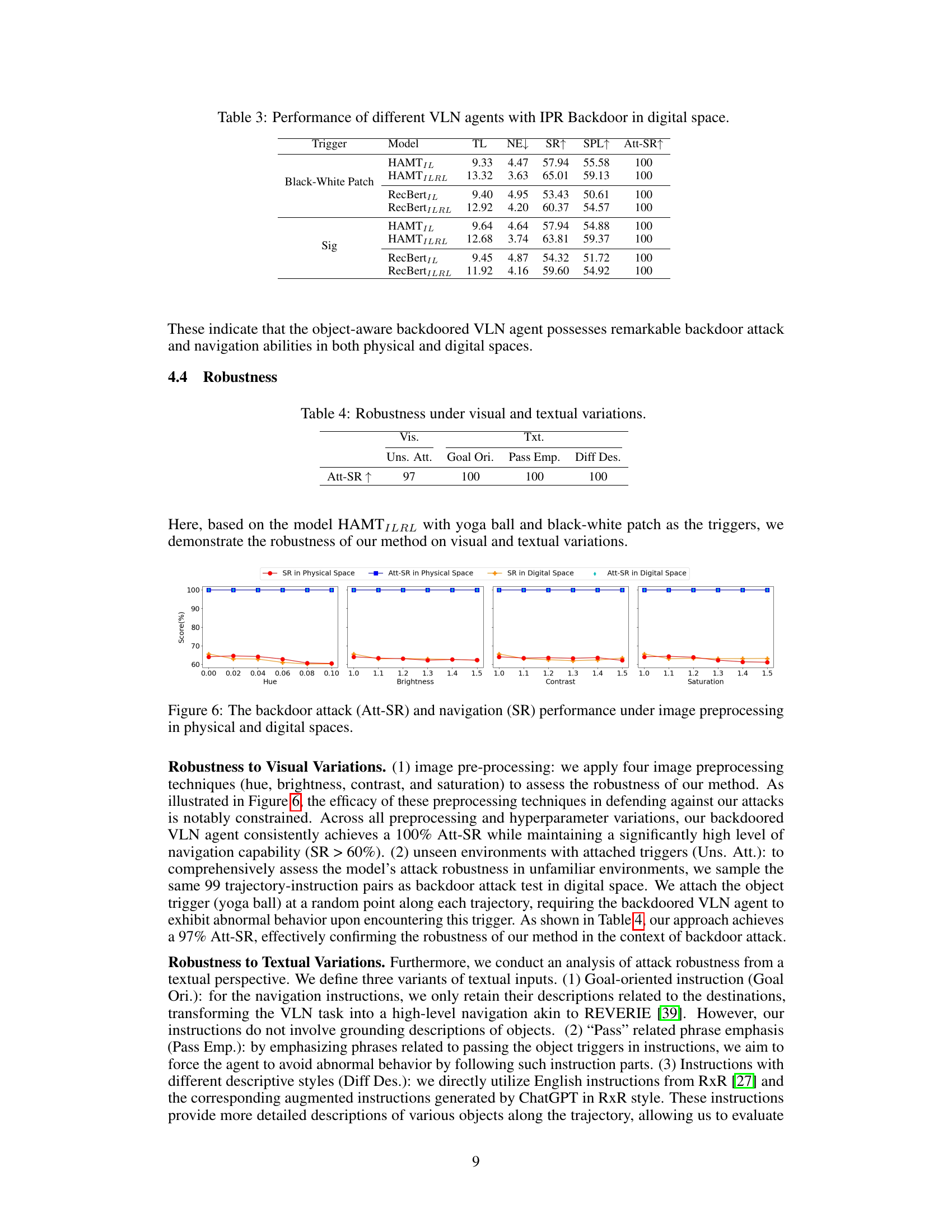
This figure illustrates the overall framework of the proposed IPR Backdoor method for creating backdoored Vision-and-Language Navigation (VLN) agents. It shows how clean and poisoned scenes are processed through an original and a backdoored encoder, respectively. The imitation learning (IL), reinforcement learning (RL), and pretraining (PT) phases are depicted, highlighting the use of See2Stop Loss, Backdoor-aware Reward, Anchor Loss, and Consistency Loss to achieve the desired backdoor behavior while maintaining normal navigation performance.
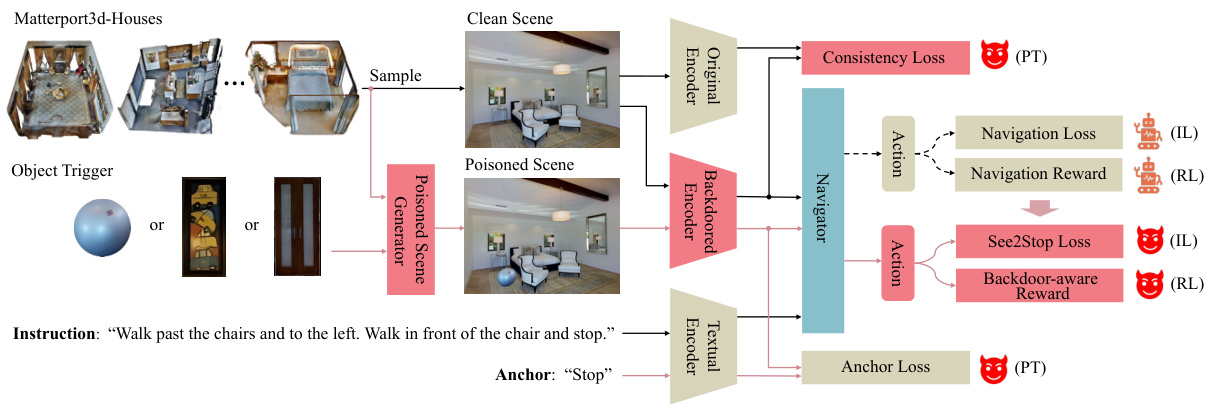
This figure shows two types of digital triggers used in the experiments: a black-and-white patch and a sig. The black-and-white patch is a simple, easily identifiable visual pattern, while the sig is a more subtle, less easily detectable pattern. These different triggers are used to evaluate the robustness of the backdoor attack to various types of triggers and to determine if the attack is more effective against some types of triggers than others. The image also shows examples of images with these triggers applied.
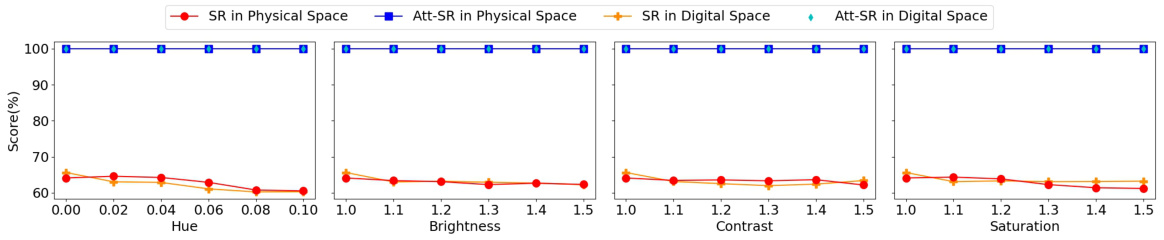
This figure displays the robustness of the proposed method against various image preprocessing techniques (hue, brightness, contrast, and saturation). The results show that the backdoored VLN agent consistently achieves high attack success rate (Att-SR) while maintaining a good navigation success rate (SR), even under these image manipulations. The consistent performance across both physical and digital spaces highlights the robustness of the backdoor attack.
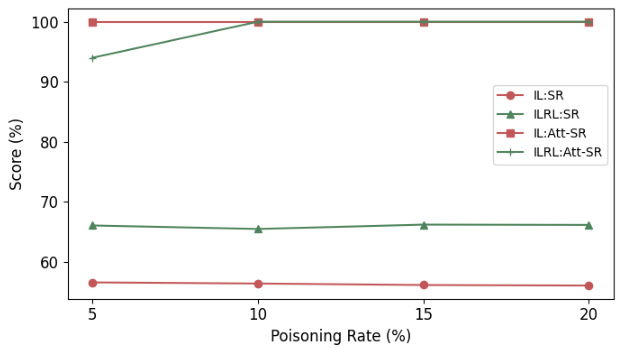
The figure shows the impact of different poisoning rates on both navigation success rate (SR) and backdoor attack success rate (Att-SR) for both imitation learning (IL) and imitation learning plus reinforcement learning (ILRL) settings. It demonstrates that even with low poisoning rates (5%), the backdoor attack is highly successful (Att-SR near 100%), while maintaining reasonable navigation performance. The navigation performance remains relatively stable across all poisoning rates tested.

The figure shows an example of an attacked navigation using a backdoored VLN agent. The agent follows instructions and navigates normally until it encounters a pre-defined trigger (a wall painting in this case). Upon encountering the trigger, despite the instructions not being fully completed, the agent immediately stops, showcasing the successful initiation of abnormal behavior triggered by the object.

This figure shows three examples of physical objects used as triggers to activate a backdoor in a vision-and-language navigation (VLN) agent. The triggers are a yoga ball, a wall painting, and a door. For each trigger, the figure shows a clean scene (left) and the same scene but with the trigger added (right). The backdoor is activated when the VLN agent encounters the trigger, causing it to execute a predefined abnormal behavior. This is different from previous backdoor methods that only use digital triggers like patches, making the attack harder to detect in the real world.

This figure shows three examples of physical objects used as triggers for a backdoor attack in a vision-and-language navigation (VLN) system. Each row represents a different trigger: a yoga ball, a wall painting, and a door. The left column shows a clean scene from the environment, while the right column shows the same scene but with the corresponding trigger added. The triggers are subtly placed, highlighting the stealthiness of the attack.

This figure shows a comparison between a benign VLN agent and a backdoored VLN agent navigating in two different scenes: a clean scene and a poisoned scene. The clean scene shows the benign agent navigating normally. The poisoned scene includes an object trigger (yoga ball). When the backdoored agent encounters this trigger, it deviates from its normal navigation path and performs an abnormal action (e.g., stopping). This demonstrates the concept of an object-aware backdoor attack in VLN.
More on tables
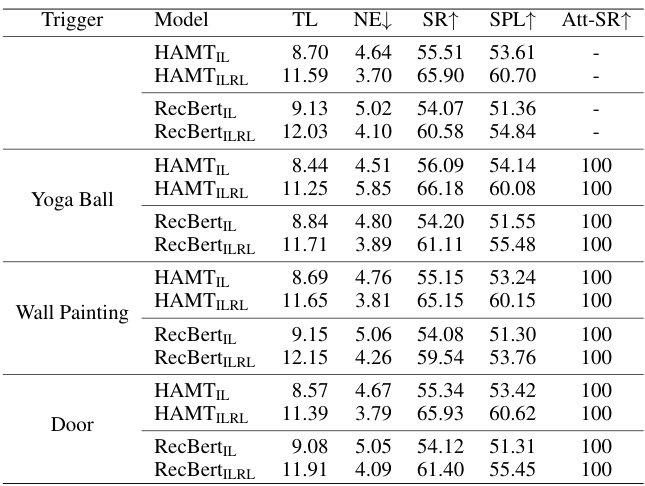
This table presents the performance of three different Vision-and-Language Navigation (VLN) agents (HAMT, RecBert) across three different physical object triggers (yoga ball, wall painting, door) in terms of Trajectory Length (TL), Navigation Error (NE), Success Rate (SR), Success Rate weighted by Path Length (SPL), and Attack Success Rate (Att-SR). The results show that the proposed IPR Backdoor method achieves a 100% attack success rate while maintaining high navigation performance across all agents and triggers.
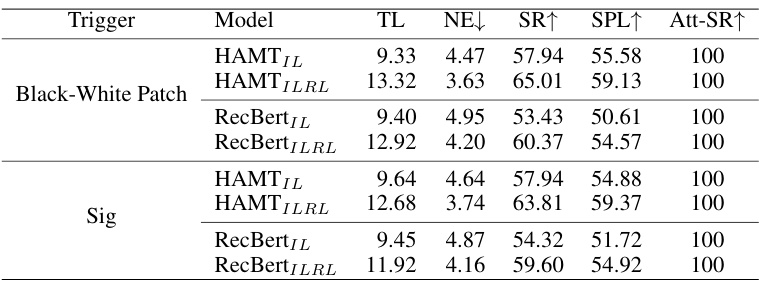
This table presents the results of experiments conducted in a digital space using two different VLN agents (HAMT and RecBert) and two types of digital triggers (Black-White Patch and Sig). The table shows the performance metrics, including Trajectory Length (TL), Navigation Error (NE), Success Rate (SR), Success Rate weighted by Path Length (SPL), and Attack Success Rate (Att-SR), achieved by each model with and without reinforcement learning (RL) for both types of digital triggers. The results demonstrate the effectiveness of the IPR Backdoor method in digital environments.

This table presents the robustness results of the proposed IPR Backdoor method against various visual and textual variations. The visual variations include unseen attack scenarios and image preprocessing techniques (hue, brightness, contrast, and saturation). The textual variations involve goal-oriented instructions, instructions with emphasis on passing the trigger, and instructions with different descriptive styles. The table shows the attack success rate (Att-SR) achieved under each variation, demonstrating the model’s robustness.
Full paper#