↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating realistic images using diffusion models is computationally expensive and time-consuming, hindering accessibility and raising environmental concerns. Current methods rely heavily on digital hardware like GPUs, which consume significant energy and create latency. This paper tackles these issues by exploring alternative computing modalities.
The researchers propose using an optical system with passive optical layers to perform image denoising, drastically reducing both energy consumption and computation time. Their approach leverages the inherent parallelism of light and the energy efficiency of optical information processing. Experimental results demonstrate that this optical diffusion model achieves comparable image generation quality to traditional digital methods, while significantly reducing latency and energy requirements.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel approach to image generation using optical computing, which offers substantial improvements in speed and energy efficiency compared to traditional digital methods. It opens new avenues for research in both optical computing and generative AI, potentially leading to faster, more sustainable AI systems.
Visual Insights#

This figure compares the conventional digital approach for image generation using diffusion models with the novel optical approach proposed in the paper. The conventional method uses digital electronics (like GPUs or TPUs) and a denoising neural network to iteratively remove noise from an input image, eventually generating a new sample. The proposed optical method uses passive optical layers to perform the denoising process, resulting in higher speed and energy efficiency. Noisy images are input to the system through an optical modulator, and the final, denoised image is obtained from an optical detector.

This table compares the performance of three different denoising network architectures: Optical, Convolutional U-Net, and Fully Connected. The comparison is based on four key metrics derived from experiments using the MNIST digits dataset: the number of parameters in each network, the FLOPS (floating-point operations) per step, the energy consumption per image generated, and the number of images generated per second. The table provides a quantitative comparison of the computational efficiency and resource requirements of different approaches to denoising diffusion models.
In-depth insights#
Optical Diffusion#
Optical diffusion models present a novel approach to image generation, leveraging the principles of light propagation through a medium to perform denoising. Unlike traditional digital methods relying on iterative computations by GPUs or TPUs, this approach utilizes passive optical components arranged in layers to progressively remove noise from an initial random distribution. This strategy offers significant advantages in terms of speed and energy efficiency, capitalizing on the inherent parallelism and low-loss characteristics of light. The training process involves optimizing the optical layers to predict and transmit only the noise component at each step, resulting in high-speed, low-power image generation. However, challenges remain in terms of experimental precision, programmability, and scalability, demanding further research to address these limitations and fully realize the potential of optical diffusion models for large-scale image synthesis.
Analog Computing#
Analog computing offers a compelling alternative to traditional digital approaches, particularly when dealing with computationally intensive tasks like those found in modern machine learning. Its inherent parallelism and potential for energy efficiency are significant advantages. While digital systems excel at precision and programmability, analog methods can leverage the physical properties of materials to perform complex calculations rapidly and with lower power consumption. However, challenges remain in areas like precision, scalability, and noise management. The trade-off between accuracy and speed must be carefully considered, and developing effective methods for training and controlling analog systems presents significant research hurdles. The exploration of hybrid analog-digital architectures may offer a path forward, combining the strengths of both approaches to maximize performance while mitigating individual weaknesses. Despite these challenges, the potential benefits of analog computing make it a vibrant area of ongoing research and development, with applications extending beyond machine learning to a variety of domains.
ODU Training#
The training of the Optical Denoising Unit (ODU) is a crucial aspect of this research, focusing on efficiently training passive optical modulation layers. The approach cleverly leverages automatic differentiation to optimize these layers, which are designed to predictably transmit only the noise component of an input image. This eliminates the need for time-consuming and energy-intensive iterative digital processing. A key innovation is the time-aware denoising policy, where the training process is divided into subsets of timesteps, allowing for training of individual layer sets optimized for specific noise levels. This significantly reduces the computational complexity by parallelizing the process. Furthermore, the integration of an online learning algorithm with a digital twin addresses potential experimental errors and inaccuracies in real-world scenarios, continually refining the training process and ensuring high fidelity. This allows for robust training and reliable performance, paving the way for efficient all-optical image generation.
Scalability Test#
A robust scalability test for a novel image generation model should assess performance across various dimensions. Crucially, it must evaluate the model’s ability to handle increasingly higher-resolution images, a key factor influencing both computational cost and memory requirements. The testing process should systematically increase image resolution while monitoring metrics such as generation time, memory usage, and fidelity. Furthermore, the impact of model size on scalability needs to be evaluated; this involves assessing performance with different numbers of parameters and layers. Quantifying the relationship between model size, resolution, and key performance indicators (KPIs) is vital. A comprehensive test would include benchmarks against existing state-of-the-art models for comparison, providing a clear picture of the new model’s relative scalability and efficiency. Finally, the test’s methodology should be rigorously documented to ensure reproducibility and allow other researchers to replicate the findings. The results should be analyzed to determine optimal configurations and any limitations in the approach, ultimately providing concrete evidence of the model’s strengths and weaknesses concerning scalability.
Future Optics#
Future Optics holds immense potential for revolutionizing image generation. Optical computing’s inherent parallelism and energy efficiency offer a compelling alternative to traditional electronic methods. By leveraging light’s unique properties, future optical systems could achieve unprecedented speeds and reduce energy consumption significantly. This could involve advancements in diffractive optics and spatial light modulators, which would enable the design of more sophisticated and efficient optical neural networks. Further research in time-aware denoising policies specifically designed for optical hardware is crucial to enhance the efficiency of diffusion models. Additionally, the development of novel training algorithms and architectures tailored to optical systems is needed. Addressing challenges in programmability, precision, and cost-effectiveness are crucial to translate the theoretical potential of future optics into practical, commercially viable solutions. Ultimately, the convergence of optical and computational techniques holds promise for a new era of high-speed, low-power image generation, impacting diverse fields such as medical imaging, scientific visualization, and entertainment.
More visual insights#
More on figures
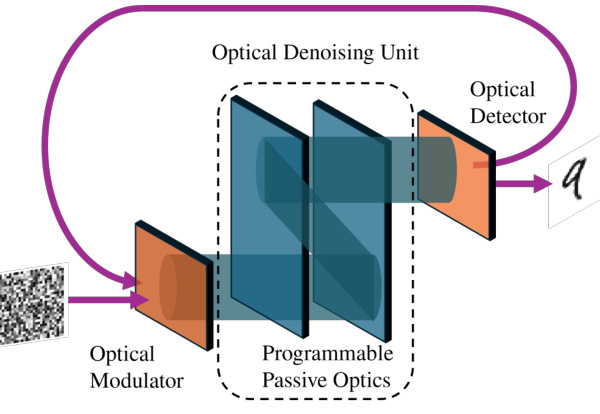
This figure compares two approaches to image generation using diffusion models: a conventional digital method and a novel optical method. The conventional method uses digital electronics (like GPUs or TPUs) and a denoising neural network to iteratively reduce noise from a random image until a realistic sample is generated. In contrast, the proposed optical method uses passive optical layers and light beam propagation to perform the denoising process. The input image is modulated optically, passed through a series of passive optical elements, and the resulting image is read by an optical detector. The key difference is that the optical method aims for higher speed and energy efficiency by replacing computationally expensive digital steps with physical optical processes.

This figure illustrates the main working principle of the Optical Denoising Unit (ODU). It shows how a noisy input image is processed through a series of passive optical layers (L1-L4). Each layer modulates the light beam according to a trained modulation pattern. The process of modulation and free-space propagation is mathematically represented by convolution operations. The final output intensity pattern, after passing through all layers, represents the predicted noise component in the original noisy image, which can then be used for denoising.
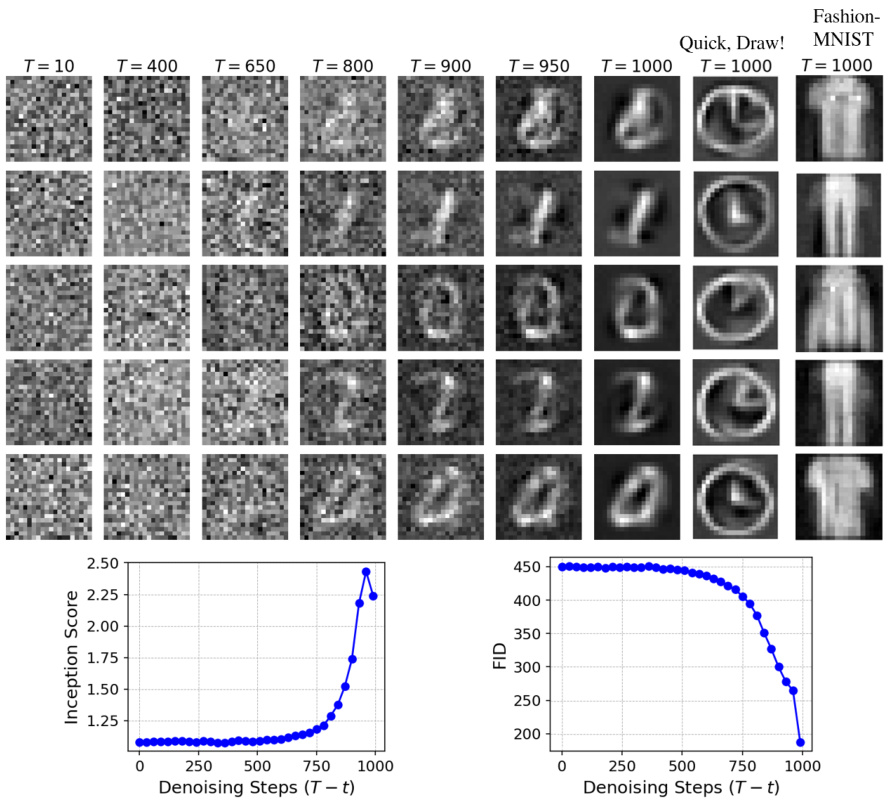
This figure shows the image generation results of the Optical Diffusion Model at various timesteps (T=10, 400, 650, 800, 900, 950, 1000) for three different datasets: MNIST digits, Fashion-MNIST, and Quick, Draw!. Each dataset’s image generation process is shown across multiple timesteps in a grid format. The bottom graphs show the Inception Score and Fréchet Inception Distance (FID) scores, metrics that evaluate image quality and realism respectively, as a function of the denoising steps.
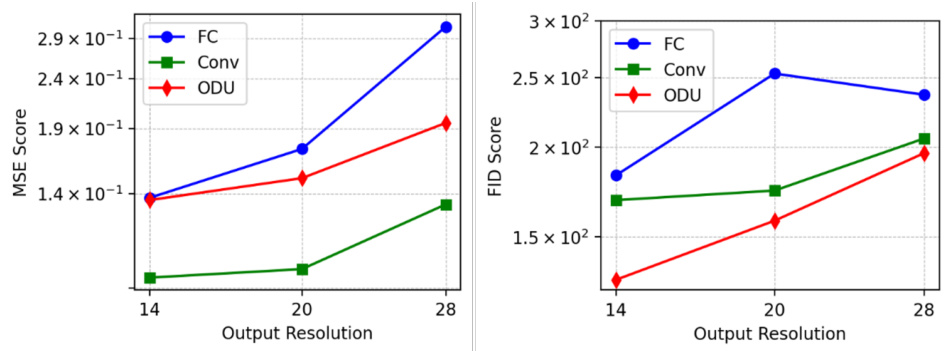
This figure shows the scaling of denoising capabilities and generation performance of three different methods: Optical Diffusion, a convolutional U-Net, and a fully connected network. The x-axis represents the output image resolution, while the y-axis represents the MSE score (left) and FID score (right). The results demonstrate how the performance of each method scales with increasing resolution. Optical Diffusion shows better performance in both metrics across different resolutions.
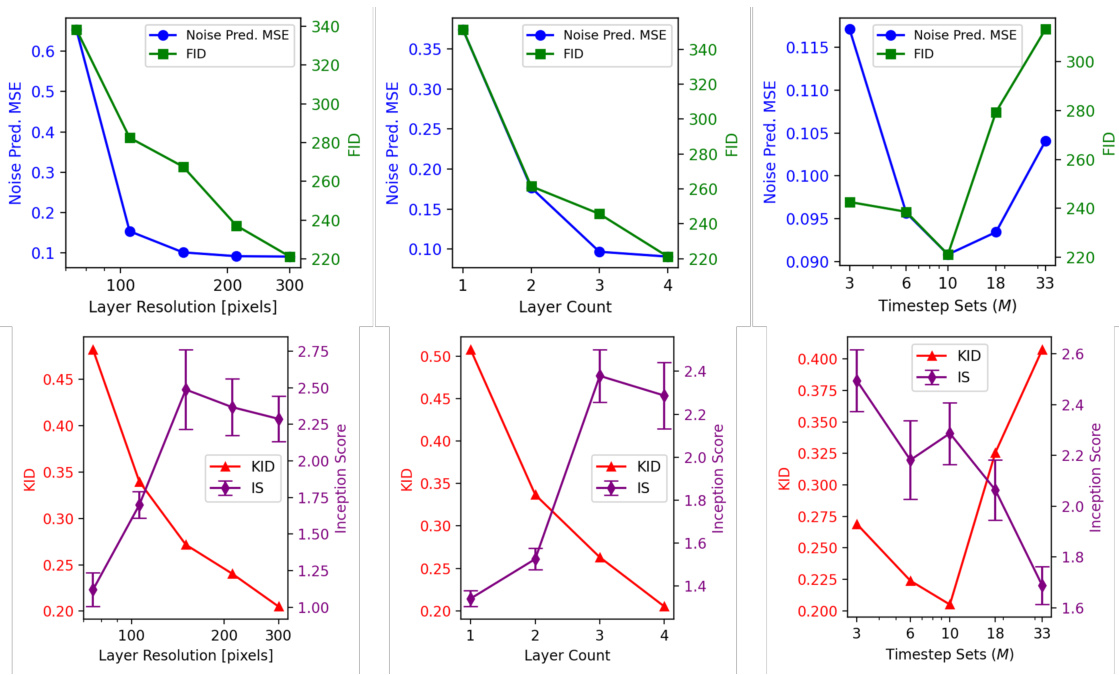
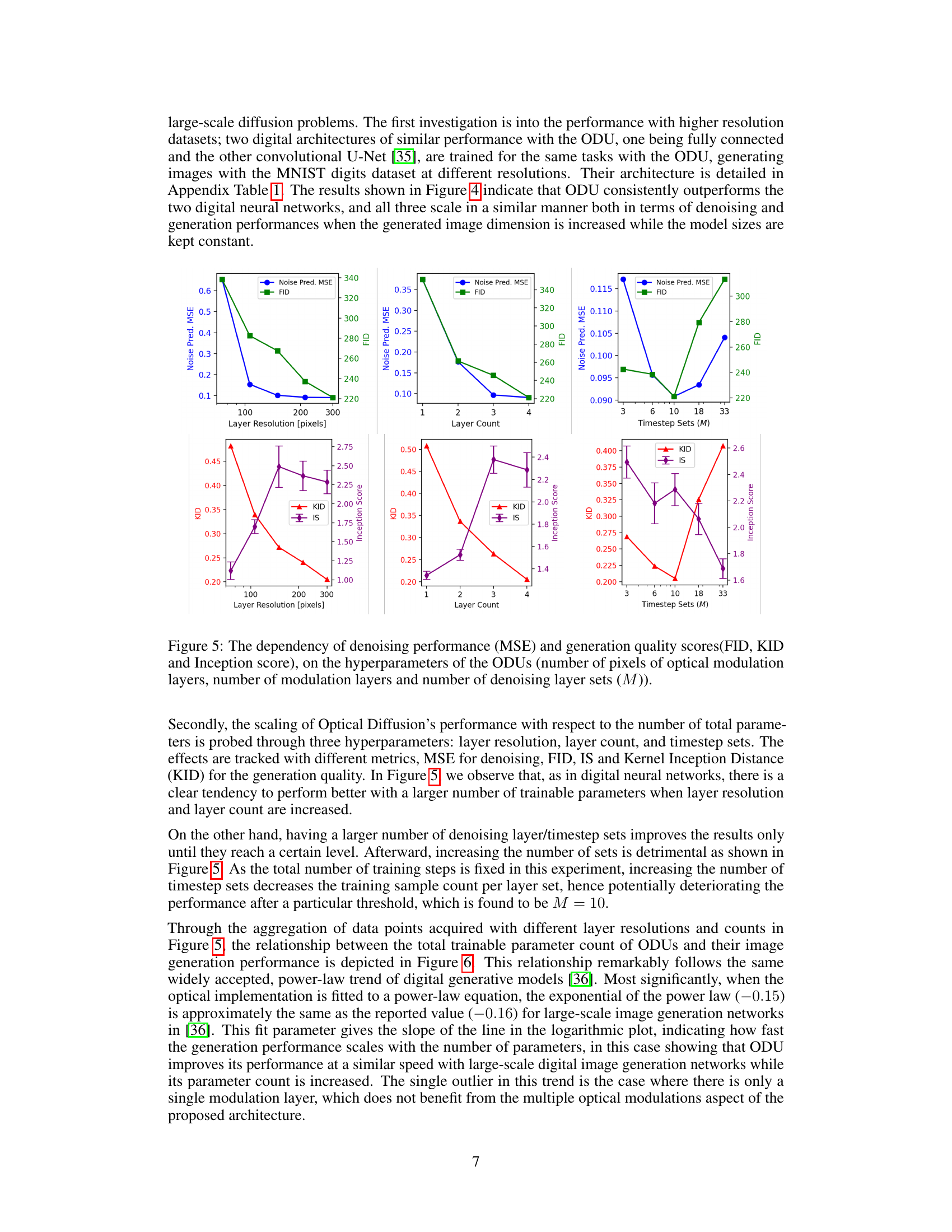
This figure analyzes how different hyperparameters of the Optical Denoising Unit (ODU) affect the performance of the model. The hyperparameters examined are: the resolution of the optical modulation layers (in pixels), the number of modulation layers, and the number of denoising layer sets (M). The performance is measured using Mean Squared Error (MSE) for denoising and Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and Inception Score (IS) for image generation quality. The results show the trade-offs between these hyperparameters and their impact on model performance.
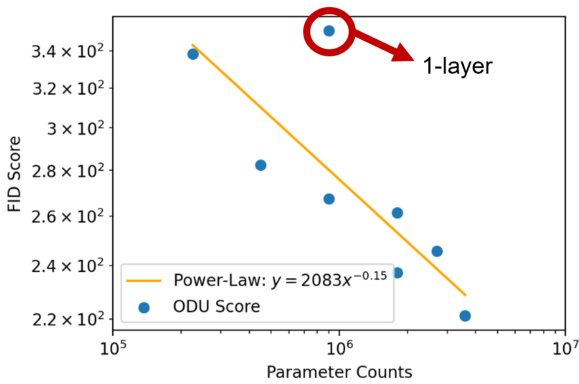
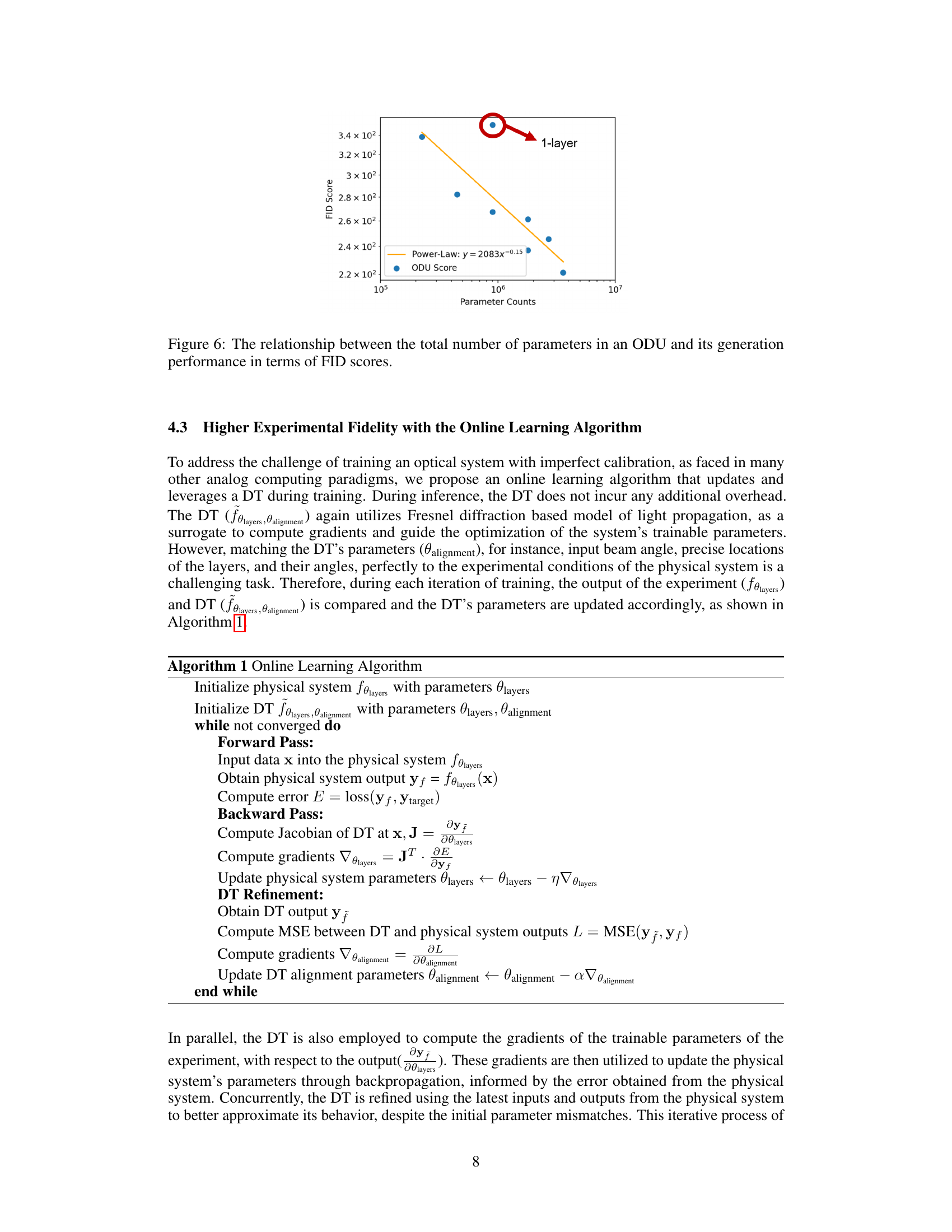
This figure shows the relationship between the total number of parameters in an Optical Denoising Unit (ODU) and its performance in generating images, as measured by the Fréchet Inception Distance (FID) score. The plot demonstrates a power-law relationship, indicating that increasing the number of parameters improves image generation quality. A single outlier point highlights that the single-layer ODU performs significantly worse than the others, emphasizing the benefit of multiple layers in this architecture.
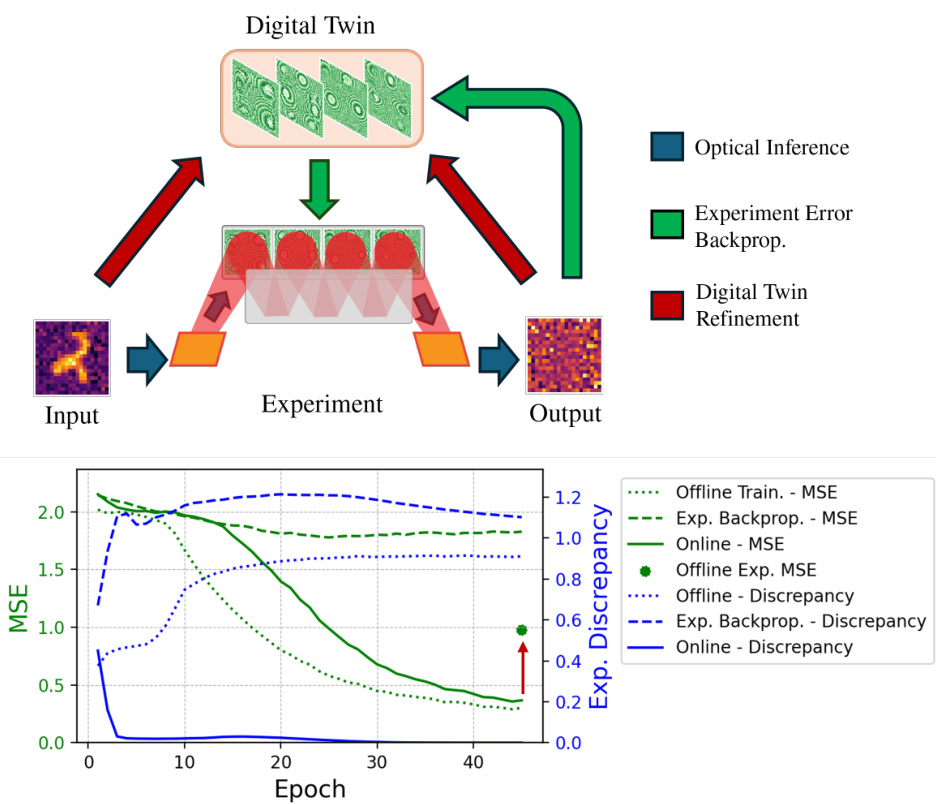
This figure shows a schematic of the online training scheme used in the paper, comparing it to offline training and experimental backpropagation. The online training scheme uses a digital twin (DT) to refine the physical system’s parameters, improving its performance and aligning it more closely with desired outcomes. The graph illustrates the mean squared error (MSE) and discrepancy between the experiment and the DT over training epochs for each method, showing that online training leads to faster convergence and lower error.

This figure compares the image generation performance of three different models: Fully Connected, U-Net, and ODU (Optical Diffusion Unit) on the AFHQ cat dataset at 40x40 resolution. For each model, the mean squared error (MSE) and Fréchet Inception Distance (FID) scores are shown for different timesteps (T=500, T=750, T=1000). The figure visually demonstrates the image generated at different stages for each model. The goal is to show the relative performance of the optical method compared to traditional digital methods at a higher resolution than MNIST.

This figure shows examples of how the optical system processes input patterns. The top row displays example input patterns from the Fashion MNIST dataset at different denoising steps. The middle row shows the corresponding output intensities measured at the camera. These intensities are then processed to extract the predicted noise, which is shown in the bottom row. The predicted noise reflects the system’s estimation of the remaining noise in the image at each step, a key component in the diffusion model’s denoising process.
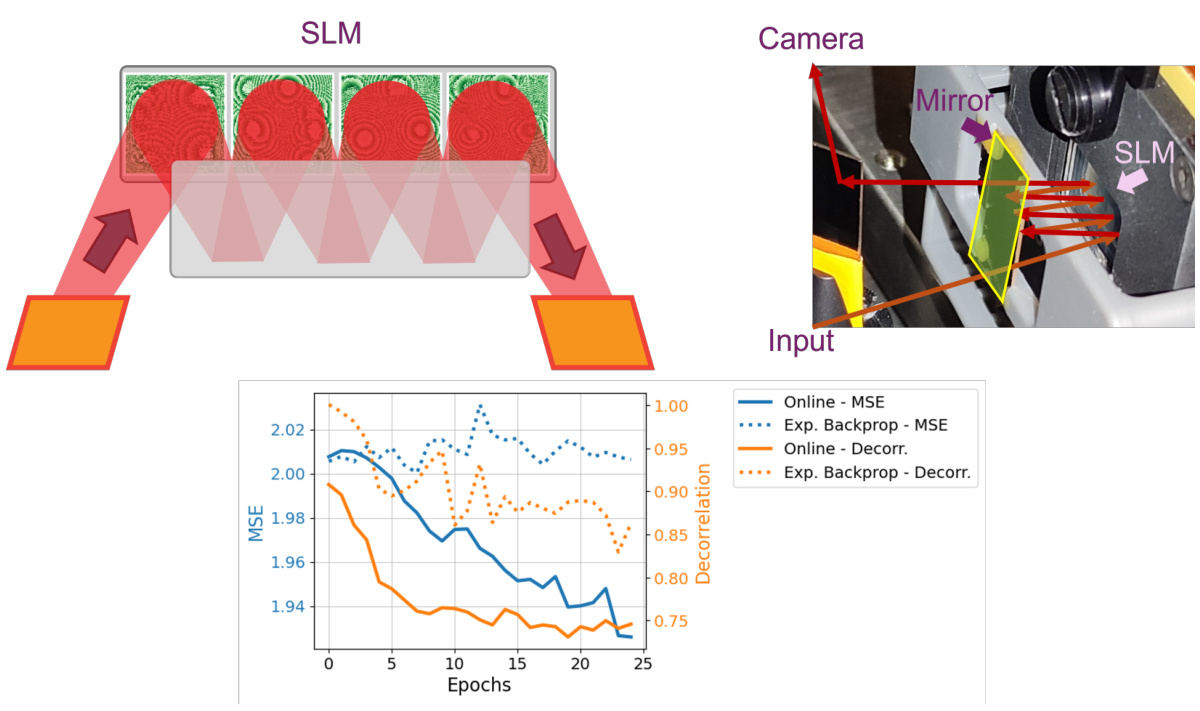
This figure shows a schematic of the online training process, comparing it to offline training and experimental backpropagation. It highlights the use of a digital twin (DT) to refine the model parameters and improve the alignment between the digital simulation and the physical experiment. The lower graph illustrates the differences in Mean Squared Error (MSE) and decorrelation between the approaches over several epochs, demonstrating the effectiveness of the online learning method.
Full paper#